目录
[1. 什么是事务?](#1. 什么是事务?)
[1.1 定义与解释](#1.1 定义与解释)
[1.2 事务的ACID特性](#1.2 事务的ACID特性)
[2. 为什么要使用事务?](#2. 为什么要使用事务?)
[3. 事务的使用](#3. 事务的使用)
[3.1 查看支持事务的存储引擎](#3.1 查看支持事务的存储引擎)
[3.2 开启事务、提交事务、回滚事务](#3.2 开启事务、提交事务、回滚事务)
[a. 开启一个事务,执行后回滚](#a. 开启一个事务,执行后回滚)
[b. 开启一个事务,执行后提交](#b. 开启一个事务,执行后提交)
[c. 保存点](#c. 保存点)
[3.3 自动/手动提交每条SQL语句的事务](#3.3 自动/手动提交每条SQL语句的事务)
[4. 事务的隔离性和隔离级别](#4. 事务的隔离性和隔离级别)
[4.1 什么是隔离性与隔离级别](#4.1 什么是隔离性与隔离级别)
[4.2 查看隔离级别](#4.2 查看隔离级别)
[4.3 设置隔离级别](#4.3 设置隔离级别)
[5. 不同隔离级别之间存在的问题](#5. 不同隔离级别之间存在的问题)
[5.1 读未提交 --> 脏读](#5.1 读未提交 --> 脏读)
[5.2 读已提交 --> 不可重复读](#5.2 读已提交 --> 不可重复读)
[5.3 可重复读 --> 幻读](#5.3 可重复读 --> 幻读)
[5.4 串行化](#5.4 串行化)
[5.5 易混淆点解析](#5.5 易混淆点解析)
1. 什么是事务?
1.1 定义与解释
MySQL 事务(Transaction)是一组不可分割的数据库操作序列,这些操作要么全部执行成功,要么全部执行失败,最终使数据库从一个一致性状态切换到另一个一致性状态。
假设你要从账户A转账100元到账户B,这需要两步操作:
-
UPDATE账户A的新余额 = 原余额1000 - 100 = 900 -
UPDATE账户B的新余额 = 原余额1000 + 100 = 1100
转账前A和B的总余额是1000+1000=2000,转账后A和B的总余额是900+1100=2000,也就是说总余额在转账前后的状态是一致的。(两步都执行成功)
在此过程中如果账户A被扣了100元,但是账户B并没有收到这100块,说明转账这一事物并没有完成或者发生了异常,事物必须回滚,把这一百块钱退还给账户A。(第2步执行失败,两步都执行失败)
如果没有事务,可能会出现的问题:
第一步执行成功,账户A扣了100元。
第二步执行前,数据库崩溃了,或者程序出错了。
结果:账户A的钱没了,账户B的钱没到账。总余额严重不一致!
使用事务就可以保证:
两步操作被"打包"成一个事务。
如果任何一步失败,整个事务会回滚,账户A的扣款操作也会被撤销,就像什么都没发生过一样。
只有两步都成功,事务才会提交,更改才永久生效。
1.2 事务的ACID特性
事务的核心特性是ACID,这是数据库事务必须遵循的四大基本准则,确保了事务执行的可靠性和数据的一致性,具体如下:
| 特性 | 解释 | 转账例子中的体现 |
|---|---|---|
| A tomicity 原子性 | 事务是最小单元,不可再分割。⼀个事务中的所有操作,要么全部成功,要么全部失败回滚。 | 扣款和加款必须同时成功或同时失败,不能只完成一半。 |
| C onsistency 一致性 | 事务使数据库从一个一致状态 转变到另一个一致状态,不会破坏数据完整性。 | 转账前后,两个账户的总金额保持不变(符合++业务逻辑和规则++)。 |
| I solation 隔离性 | 多个并发事务之间相互隔离,互不干扰。这是通过事务隔离级别来控制的。 | 在你转账过程中,另一个查询事务不会看到你中途扣了款但还没加款的"中间状态"。 |
| D urability 持久性 | 事务一旦提交 ,其对数据的修改就是永久性的,即使系统故障也不会丢失。 | 转账成功后,即使数据库服务器立刻断电,重启后账户余额也是转账后的结果。 |
2. 为什么要使用事务?
⽀持事务的数据库能够简化我们的编程模型,不需要我们去考虑各种各样的潜在错误和并发问题 。在使⽤事务过程中,要么提交,要么回滚,不用去考虑网络异常、服务器宕机等其他因素,因此 我们经常接触的事务本质上是数据库对 ACID 模型的⼀个实现,是为应⽤层服务的。
事务的本质是一种契约:
对开发者的承诺:"你只需关注业务逻辑,我来保证数据安全"。
对业务的承诺:"要么完全成功,要么完全失败,不会有中间状态"。
对系统的承诺:"故障恢复后,数据依然一致"。
3. 事务的使用
3.1 查看支持事务的存储引擎
要使⽤事务那么数据库就要⽀持事务,在MySQL中⽀持事务的存储引擎是InnoDB,可以通过 show engines 语句查看:
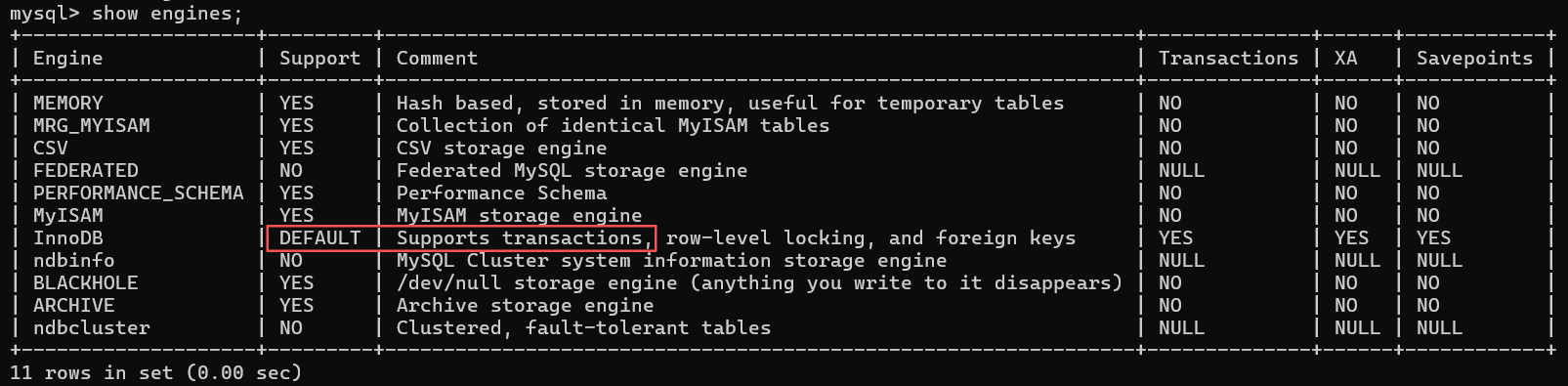
可以看到InnoDB是默认支持事务的。
3.2 开启事务、提交事务、回滚事务
开始⼀个新的事务
方式一:start transaction;
方式二:begin;
提交当前事务,造成永久性更改
commit;
回滚当前事务,取消其更改
rollback;
begin关键字是MySQL特有的,start关键字符合SQL标准。
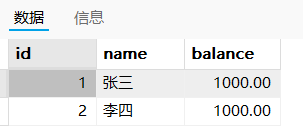
在演示示例前,要准备好要用的表和数据:
sqlCREATE TABLE `bank_account` ( `id` bigint PRIMARY KEY AUTO_INCREMENT, `name` varchar(255) NOT NULL, # 姓名 `balance` decimal(10, 2) NOT NULL # 余额 ); INSERT INTO bank_account(`name`, balance) VALUES('张三', 1000); INSERT INTO bank_account(`name`, balance) VALUES('李四', 1000); SELECT * FROM bank_account;
a. 开启一个事务,执行后回滚
-- 张三给李四转账100块钱,完成后回滚到转账前
sql
start transaction;
update bank_account set balance = balance - 100 where name = '张三';
# 在事物执行中途查看变化
SELECT * FROM bank_account;
update bank_account set balance = balance + 100 where name = '李四';
# 在事务的结尾查看结果
SELECT * FROM bank_account;
rollback;
# 回滚后查看结果
SELECT * FROM bank_account;
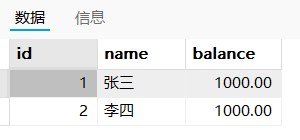
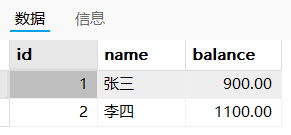
中间状态:张三有900,李四有1000
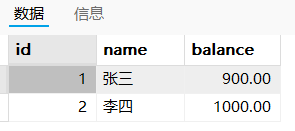
在事物的结尾看到的结果:张三有900,李四有1100【满足一致性】
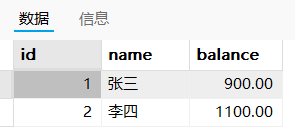
回滚到事物开始前的状态:张三有1000,李四有1000【满足一致性】
b. 开启一个事务,执行后提交
-- 张三给李四转账100块钱,完成后提交这个事物
sql
begin;
update bank_account set balance = balance - 100 where name = '张三';
SELECT * FROM bank_account; # 在事务执行过程中查看结果
update bank_account set balance = balance + 100 where name = '李四';
SELECT * FROM bank_account; # 在事务的结尾查看结果
commit;
SELECT * FROM bank_account; # 提交后查看结果中间状态:张三有900,李四有1000
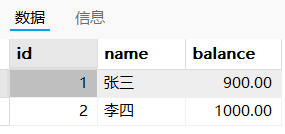
在事物的结尾看到的结果:张三有900,李四有1100【满足一致性】
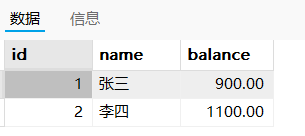
提交了事物,正式完成了修改:张三有900,李四有1100【满足一致性】
c. 保存点
在事务执⾏的过程中设置保存点,回滚时指定保存点可以把数据恢复到保存点的状态:
语法:
savepoint 保存点名称;
rollback to 保存点名称;
- 一个事物中可以设置多个保存点,方便测试人员的调试。
-- 示例:一个事物中按顺序完成"张三转账给李四100块"、"张三再次转账100块"、"插入一个新账户王五"
sql
START TRANSACTION;
# a.张三给李四转100块
SELECT * FROM bank_account;
update bank_account set balance = balance - 100 where name = '张三';
update bank_account set balance = balance + 100 where name = '李四';
SELECT * FROM bank_account;
SAVEPOINT sp1;
# b.张三再给李四转100块
update bank_account set balance = balance - 100 where name = '张三';
update bank_account set balance = balance + 100 where name = '李四';
SELECT * FROM bank_account;
savepoint sp2;
# c.插入一个账户王五
insert into bank_account values(3,'王五',5000);
SELECT * FROM bank_account;
rollback to sp2; # 1.回滚到sp2记录点
SELECT * FROM bank_account;
rollback to sp1; # 2.回滚到sp1记录点
SELECT * FROM bank_account;
ROLLBACK; # 3.回滚到start之前
SELECT * FROM bank_account;a操作
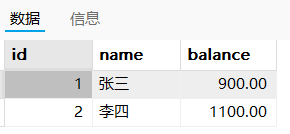
a操作之前:张三900,李四1100
a操作之后(b操作之前):张三800,李四1200
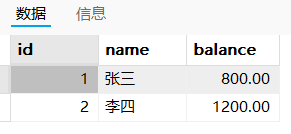
b操作
b操作之后(c操作之前):张三700,李四1300
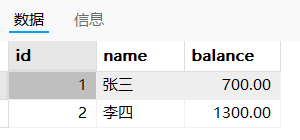
c操作
b操作之后:张三700,李四1300,王五5000
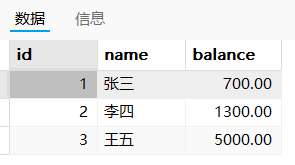
- 回滚到保存点sp2:张三700,李四1300
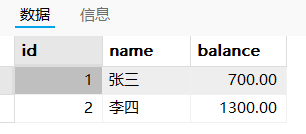
- 回滚到保存点sp1:张三800,李四1200

- 回滚到start之前:张三900,李四1100
3.3 自动/手动提交每条SQL语句的事务
其实,我们平时执行的每一条SQL语句都是一个微小的事务,但是我们并没有手动提交事物,这是因为MySQL默认是自动提交事务的。
查看当前事务是否⾃动提交,可以使⽤以下语句:
show variables like 'autocommit';
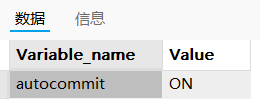
"on"表示数据库此时是自动提交事物的。
可以通过以下语句修改事务为自动或⼿动提交
设置事务为⾃动提交
方式1:SET AUTOCOMMIT=1;
方式2:SET AUTOCOMMIT=ON;
设置事务为⼿动提交
方式1:SET AUTOCOMMIT=0;
方式2:SET AUTOCOMMIT=OFF;
注意事项:
- 手动提交模式下,单条SQL语句会自动开启事物,不需要显式使用 start;但不会自动提交,需要显式使用 commit。
- 只要显式使用 start 或 begin 开启的事物,都必须通过通过 commit 提交才能持久化保存。【这与自动/手动模式无关,与是否显式开启有关。】
4. 事务的隔离性和隔离级别
4.1 什么是隔离性与隔离级别
同一个MySQL服务可以同时被多个客户端访问,每个客户端执行的DML语句是以事务为基本单位的。
假设事物没有隔离性,那么不同的客户端 在对(同⼀张表中的)同⼀条数据进行修改的时候,就可能出现相互影响的情况。
为了保证不同的事务之间在执行的过程中不受影响,那么事务之间就需要相互隔离,这种特性就是隔离性。
事务间不同程度的隔离,称为事务的隔离级别。
不同的隔离级别在性能和安全⽅⾯做了取舍,有 的隔离级别注重并发性,有的注重安全性,有的则是并发和安全适中;在MySQL的InnoDB引擎中事务 的隔离级别有四种,分别是:
- read uncommitted:读未提交
- read committed:读已提交
- repeatable read:可重复读(默认)
- serializable:串行化
其中,"可重复读"是MySQL的InnoDB引擎中默认的隔离级别。
【MyISAM不支持事务,所有语句都自动提交,不可回滚,也就没有隔离级别的说法】
4.2 查看隔离级别
事务的隔离级别分为全局作用域 和会话作用域。
| 维度 | 全局作用域 | 会话作用域 |
|---|---|---|
| 生效范围 | 数据库实例级,影响所有后续新建会话 | 单个会话级,仅影响当前连接,独立于全局范围 |
| 生效时机 | 修改后,仅新创建的会话生效,已有会话不受影响 | 修改后立即生效,当前会话后续事务直接使用 |
| 生命周期 | 仅在数据库实例运行期间有效,重启后恢复配置文件默认值(如 my.cnf) | 随会话断开(连接关闭)立即失效,重新连接后继承当前全局值 |
查看不同作⽤域事务的隔离级别,可以使⽤以下的方式:
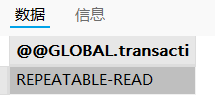
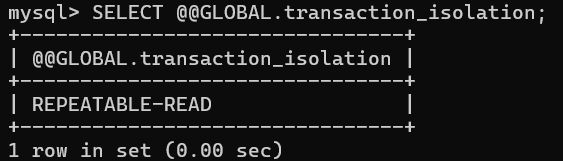
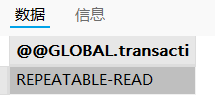
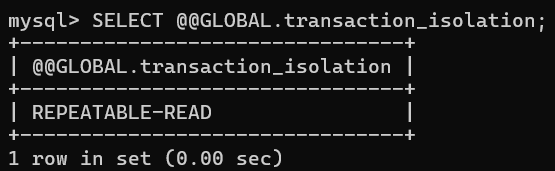
# 查看全局作用域下的隔离级别:
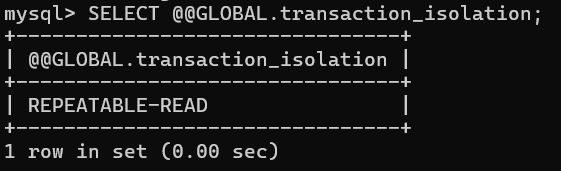
SELECT @@GLOBAL.transaction_isolation;
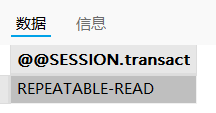
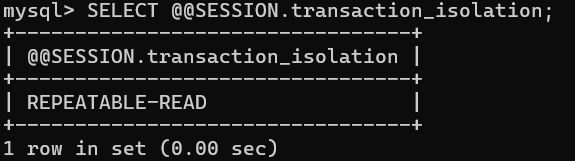
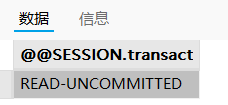
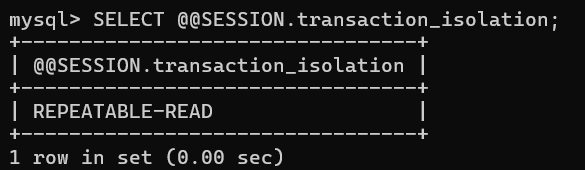
# 查看会话作用域下的隔离级别:
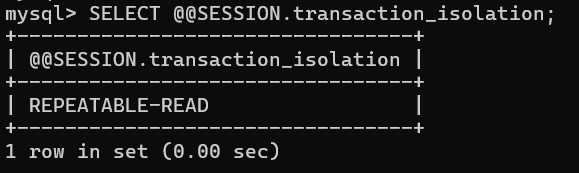
SELECT @@SESSION.transaction_isolation;
- 在 MySQL 中,@@ 是引用系统变量的标识前缀,用来获取或设置 MySQL 内置的系统参数值。
InnoDB 默认的隔离级别是可重复读:
4.3 设置隔离级别
设置事务的隔离级别或访问模式,可以使⽤以下语法:
方式一:
set golbal \| session transaction isolation level 隔离级别 \| 访问模式 ;
- 通过 GLOBAL 和 SESSION 分别指定不同作⽤域的事务隔离级别。如果不填写,则默认是回话作用域。
- 可填写的隔离级别有4种:
- READ UNCOMMITTED # 读未提交
- READ COMMITTED # 读已提交
- REPEATABLE READ # 可重复读
- SERIALIZABLE # 串行化
- 可填写的访问模式有2种:
- READ WRITE # 表示事务可以对数据进行读写
- READ ONLY # 表示事务是只读,不能对数据进行读写
方式二:
修改隔离级别:
set golbal \| session transaction_isolation = 隔离级别;
修改访问模式:
set golbal \| session transaction_read_only = 访问模式;
- 修改隔离级别要用transaction_isolation ,修改访问模式用transaction_read_only。
- 等号右边的取值如下:(通常是字符串,注意横杠)
隔离级别:
'READ-UNCOMMITTED'
'READ-COMMITTED'
'REPEATABLE-READ'
'SERIALIZABLE'
访问模式:(没有像 'READ WRITE' 、'READ-ONLY'这样的取值)
1 或 'OFF' # 表示读写
0 或 'ON' # 表示只读
方式三:
修改隔离级别:
例如:SET @@SESSION.transaction_isolation = 隔离级别;
修改访问模式:
例如:SET @@SESSION.transaction_read_only = 访问模式;
- 用@@引用变量时,要注意**"作用域" 与 "系统变量名" 之间有一个** 小点 .
- 等号右边可填入的值与方式二相同。
隔离级别与访问模式的区别:
| 维度 | 事务隔离级别 | 事务访问模式 |
|---|---|---|
| 管控目标 | 事务之间的并发数据可见性(如避免脏读、不可重复读) | 事务自身的操作权限范围(能否执行写操作) |
| 核心作用 | 保证并发场景下的数据一致性 | 限制事务的操作类型,防止误写 / 控制资源消耗 |
-- 示例:演示两个客户端在其中一个客户端 修改回话作用域的隔离级别后,两者隔离级别的变化
- 修改前:
a. 全局的隔离级别:可重复读
b. 将被修改隔离级别的客户端:
该用户的回话作用域:可重复读
c. 其他客户端:
该类用户的回话作用域:可重复读
# 修改其中一个客户端的回话作用域为读未提交:
sql
set session transaction isolation level READ UNCOMMITTED;2.修改后:
a. 全局的隔离级别:会话作用域的修改独立于全局,全局作用于依旧是可重复读
b. 将被修改隔离级别的客户端:
该用户的回话作用域:读未提交
c. 其他客户端:会话作用域的修改仅影响执行改SQL语句的客户端,其他客户端的会话隔离级别不受影响
该类用户的回话作用域:可重复读
5. 不同隔离级别之间存在的问题
5.1 读未提交 --> 脏读
1. 脏读的含义
在 READ UNCOMMITTED 隔离级别下,事务之间在读取数据时不做任何限制。虽然这样的并发性能非常高,但是会出现大量的数据安全问题。
其中最大的问题就是脏读:假设事务A要修改数据,事务B要读取数据,事务B读取到另一个事务A未提交的修改 ,后续该事务A可能会回滚,回滚后事务B读取的 数据是****无效的。
- 脏读发生始于未完成提交的事务操作,不针对(不同事务之间访问的) 是同一个表还是同一行数据。
2. "脏读"现象的代码演示
-- 示例:客户B读到客户A未提交的数据
所有事务开始前,账户表中存在的数据:
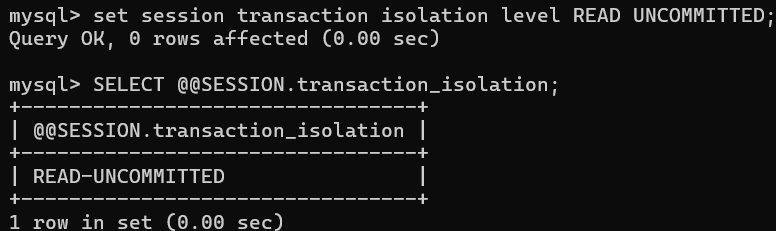
设置客户端B(负责读取数据)的回话隔离级别为读未提交:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| 会话(客户端)A开启事务A | 会话(户端)B开启事务B |
| # 开启事务A 
 | |
| |
| # 写入一条新数据 
 # 查看新结果集
# 查看新结果集  | |
| |
| | # 开启事务B  |
|
| | # 查询账户表的数据,有3条记录  |
|
| # 不提交,选择回滚数据 
 | |
| |
| | # 再次查询,变成2条记录了  |
|
事务B前后两次查询到的结果不一致,说明发生了脏读。事务B第一次读到的用户A未提交的**"无效脏数据"**。
补充:"脏读"与"读脏数据"
最需要注意的是,不要把 "读脏数据" 理解成**"某个事务把数据读脏了,使得真实表存储的数据都是无效的"** 。它的意思是**"某个事务对数据进行了一次无效地读取"**。
脏读 (Dirty Read)
是一种现象/问题:事务隔离级别中的一个专业术语
描述的是**"** 一个事务读取到了另一个未提交事务 修改的数据**"**的异常现象
读脏数据 (Reading Dirty Data)
是一种行为/操作:某个事务执行了读取脏数据的行为"事务具体做了什么"
描述的是**"** 某个事务执行了读取脏数据的行为**"**
5.2 读已提交 --> 不可重复读
1. 不可重复读的含义
在读已提交的隔离级别下,事务读取到的都是已提交的数据,彻底解决了脏读的问题。假设回话A开启了事务A,事务A会执行修改操作;此时会话B开启了事务B并进行查询,那么事务B只能查询到事务A开启之前的数据(上一次提交的数据) 。当事务A提交后,事务B才能查询到提交后的数据。
不过在读已提交的隔离级别下,仍然存在着隐患,其中最大的隐患是"不可重复读"。
异常现象:同一事务内两次读同一行 ,因为其他事务提交了对该行数据的修改,导致两次读取的数据不一致。
- 不可重复读发生在两个事务访问同一行数据(一个事务读取,一个事务修改)的情况,针对的是同一行数据。
2. "不可重复读"现象的代码演示
-- 示例:事务A要修改"李四"的数据,事务B要读取两次"李四"的数据,且刚好事物B读第2次之前事务A完成并提交了
所有事务开始前,账户表中存在的数据:

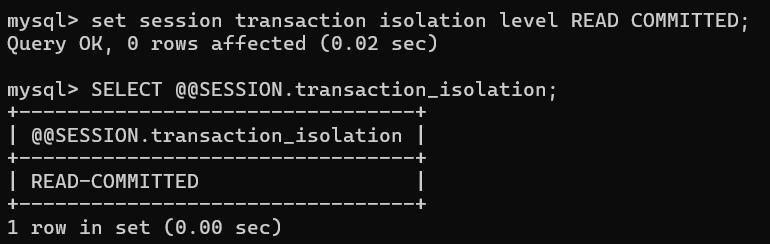
设置客户端B回话作用域的隔离级别为读已提交:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------|
| 会话(客户端)A开启事务A | 会话(客户端)B开启事务B |
| | # 开启事务B  |
|
| # 开启事物A 
 | # 第一次读取:张三900,李四1100 (此时"李四"的数据除事务B外无其他事务访问)
| # 第一次读取:张三900,李四1100 (此时"李四"的数据除事务B外无其他事务访问)  |
|
| # 修改"李四"的余额为2000 
 | |
| |
| | # 第二次读取:张三900,李四1100 (事务B的隔离级别是读已提交,此时事务A还 没提交,所以查询结果不变)  |
|
| # 提交事物 
 | |
| |
| | # 第三次读取:张三900,李四2000  |
|
可以看到,对同一行数据,事务B在事物A提交前后的读取结果并不一致,这就是不可重复读。
5.3 可重复读 --> 幻读
1. MySQL对于"不可重复读"的解决
在MySQL的InnoDB引擎中,"可重复读"级别采用了快照 的方式解决了"不可重复读"的现象。
简单了解:快照、活跃事务列表、事务ID
以订电影院座位类比:
- 事务ID = 你的票号(如:A100)
- 活跃事务列表 = 当前正在选座的人列表
- 一致性读视图 = 你进场时拍的"座位现状快照"
- 数据行 = 每个座位状态
- 你(事务B,票号A100)打开订票页面时,订票APP为你拍了快照。
- 你看到8排10座是空的(基于快照)。
- 实际上,小明(事务A)正在预订这个座位**(在活跃列表中)**。
- 但你不知道,因为你的快照是小明锁定8排10座(事务A修改数据)前拍的。
- 你最后订了6排8座的座位。直到你订完票 (事务B提交),你重新打开订票页面 (事务C的开启),(使用事务C的新快照) 你才知道座位被人选了。
深入了解快照:【非必需掌握的知识点,可以跳过】
快照的全称是一致性读视图(Consistent Read View)。 从使用角度看:它是一个视图;从实现角度看:它是一组可见性判断规则。
- 快照不能通过show tables看到,因为它不是一个真的视图。
- 事务在可见性判断规则下可以找到自己可见的版本,每个版本的数据是固定下来的,所以查找到的数据是重复的。
**事务ID:**每当一个新事务被启动时,InnoDB分配一个递增的全局唯一ID。**活跃事务列表:**通过存储事务ID的方式,用来记录所有进行中的事务。
- 注意,活跃的事务也代表着它没有被 commit 。
- 事务被提交后就会被剔除出活跃事务列表,所以列表中的最小ID对应着当前最老的事务。
在索引树中,数据页的数据行存储着该行最新的数据 + 指向旧版本数据的指针(详细一点是:键值key + 存储的数据 + 旧版本指针)。该指针指向的区域可以称为版本日志,该日志以链表 的形式连接起在该行中 存在过的旧版本数据 + 创建该版本的事务ID。
当"可重复读"级别的事务启动时会生成一个事务ID,该事务第一次使用查询语句 时,会获取此时活跃事务表中最小的事务ID(最老的事务)。
查询数据时,会先根据key找到数据行,然后读取数据行中的旧版本指针;通过指针找到版本日志,接着根据可见性判断规则来遍历链表:
- 若 创建该节点的事务ID > 当前事务的ID ,说明该节点对应的版本不可见,继续遍历下一个节点(上一个版本)。
- 若 最小的事务ID <= 创建该节点的事务ID <= 当前事务的ID :
- 若 创建该节点的事务ID == 当前事务的ID ,说明该版本的创建者和使用者是同一个,可见。
- 若 创建该节点的事务ID在 活跃事务列表,说明使用该版本的事务未提交,该版本不可见。
- 若 创建该节点的事务ID不在 活跃事务列表,说明没有事务使用该版本,该版本可见。【用"当前事务的ID"替换掉"创建该节点的事务ID"】
- 若 创建该节点的事务ID < 当前事务的ID ,说明该版本没有被任何事务占用,对当前事务可见。【用"当前事务的ID"替换掉"创建该节点的事务ID"】
修改 某行数据,就会自动创建并保留 该行数据的旧版本快照。
某个版本长时间没有事务访问时就会自动回收。
2. 幻读的含义
"可重复读"级别存在着幻读问题。
异常现象:同一事务内多次执行相同的范围查询语句 时,因其他事务提交了 "插入、删除数据行" 的操作 ,导致前后两次查询的结果集中出现 "新增的幻象行" 或 "消失的行" ,破坏了事务内范围数据的一致性。
- 幻读发生在两个事务访问同一范围内的数据 (一个事务读取,一个事务增删数据行) 的情况,针对的是多行数据的范围查询。
补充:虽然"可重复读"级别存在快照机制,但是快照是行级的,它只为每行数据单独记录其历史版本,而不是为整个表(或整个数据库)记录历史版本。所以快照不能解决幻读问题!!!
3. "幻读"现象的代码演示
-- 示例:事务A要对账户表新增"王五"的数据,事务B要对整个账户表读取2次,且刚好事务A新增数据并提交后事务B才读第2次
MySQL的"可重复读"级别使用了 Next-Key 锁,在很大程度上避免了幻读的问题。要想使幻读问题重现,只能用"读已提交"级别进行展示。
所有事务开始前,账户表中存在的数据:
客户端B回话作用域的隔离级别为读已提交:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| 会话(客户端)A开启事务A | 会话(客户端)B开启事务B |
| | # 开启事务B  |
|
| # 开启事务A 
 | # 第一次查询:共2行数据
| # 第一次查询:共2行数据  |
|
| # 新增一行数据"王五" 
 | |
| |
| # 提交事务A 
 | |
| |
| | # 第2次查询:共3行数据  |
|
事务B对同一个范围进行查询,两次查询出来的记录数不一致,说明发生了幻读。
5.4 串行化
进⼀步提升事务的隔离级别到 SERIALIZABLE ,此时所有事务串⾏执⾏,可以解决所有并发中的安全问题。
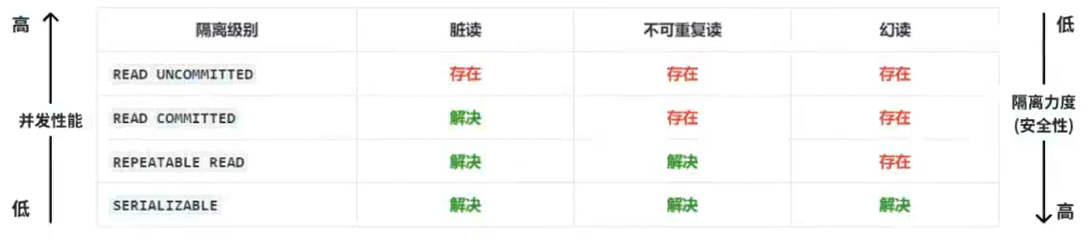
总结:不同隔离级别的性能与安全比较
5.5 易混淆点解析
易错1:"脏读"与"读脏数据"
最需要注意的是,不要把 "读脏数据" 理解成**"某个事务把数据读脏了,使得真实表存储的数据都是无效的"** 。它的意思是**"某个事务对数据进行了一次无效地读取"**。
脏读 (Dirty Read)
是一种现象/问题:事务隔离级别中的一个专业术语。
描述的是**"** 一个事务读取到了另一个未提交事务 修改的数据**"** 的异常现象。
读脏数据 (Reading Dirty Data)
是一种行为/操作:某个事务执行了读取脏数据的行为"事务具体做了什么"。
描述的是**"** 某个事务执行了读取脏数据的行为**"。**
易错2:"不可重复读"是不能多次读取数据吗?
"不可重复读"的意思是:对于同一行数据 ,保证不了在多次读取 中,读取到的数据都是一样的。
不是**"不可以重复读取数据"** ,而是**"不一定读到重复的数据"** ,最重要的是读取的对象必须是同一行数据。
易错3:幻读为什么被称为"幻读"?
使用同一条范围查询的SQL语句,多次查询出来的结果集却不同。新结果集可能比旧结果集多几条记录,也可能比旧结果集少几条记录。
**明明要查的范围一样的,却出现了忽"大"忽"小"的情况 ---> 就像一个幻影一样,没有一个固定的、清晰的成像。**这就是该异常现象被命名为"幻读"的原因。
易错4:可以说"幻读"是一种特殊的"不可重复读"吗?
从感觉上看,"幻读"像是一种范围上的"不可重复读"。但其实,"幻读"不是"不可重复读"中的一种,它们有着两种本质区别:
产生异常现象的来源不同:
- 不可重复读:源于另一个事务的修改操作。
- 幻读:源于另一个事务的新增、删除操作。
造成的一致性破坏不同:
- 不可重复读:破坏了值的一致性。
- 幻读:破坏了数据范围的一致性。
如果说"幻读"是一种范围上的"不可重复读",那么它的意思是"幻读"破坏了多个值的一致性【修改一个值是值的一致性被破坏,修改多个值也是值的一致性被破坏】;但在事实上,"幻读"破坏的是数据范围的一致性,两者处于不同维度。
易错5:"脏读"、"不可重复读"和"幻读"分别是在什么时候产生的错误?
脏读、不可重复读和幻读,它们都会导致同一事务内读取到不同的结果。但是三者也有时机上的区别:
【事务A要修改、新增或删除数据,事务B要多次读取数据】
- a.在事物A开启前
- b.在事物A进行时
- c.在事物A提交后
事务B在 b和a时期 或者 b和c时期 读到的两个结果不同,说明发生了脏读。
事务B在a和c时期 读到的两个结果不同,而且读取的数据 与 事务A修改的数据 是同一行,说明发生了不可重复读。
事务B在a和c时期 读到的两个结果不同,而且读取的多行数据 与 事务A进行插入删除操作所在的 是同一个范围,说明发生了幻读。
本期分享完毕,感谢大家的支持Thanks♪(・ω・)ノ
