现在已经是AI时代了,我之前学过一些AI的东西,所以后续开始分享一些AI相关的内容了。
如AI工具,AI科普,AI最新技术等等,大家一起拥抱AI,学习AI,利用AI。
文章内容收录到个人网站,方便阅读 :hardyfish.top/
对于大多数人来说,处理大量的提示词非常令人头疼,几乎没人愿意花费大量的时间去精心设计这些词。
用户更倾向于用一句话、一个简单指令,来表达需求。
所以,上下文工程做的事情就是基于用户的上下文来补充信息。
但这里的上下文与大模型的上下文维度有所不同:
大模型的上下文通常是基于单次输入的上下文,而这里所指的上下文则是用户的全部历史数据。
- 甚至可能追溯到用户最初使用平台时的数据。
在上下文的处理上,通常采用的方式大体相似,包括检索召回、知识库、向量库、知识图谱等。
- 但关键问题在于如何高效地利用和整合这些数据。
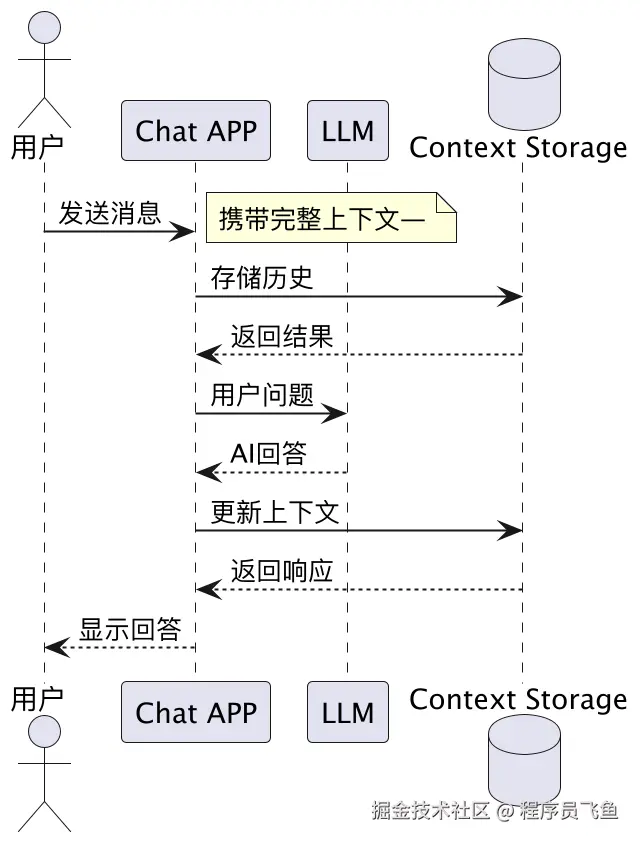
那现在基于大语言模型的聊天应用中的上下文是怎么处理的?
大模型作为纯粹的推理引擎,不记住任何历史信息。
- 应用层负责维护完整的对话历史。
每次向模型发起请求时,都需要携带完整的上下文。
但当应用场景是 Agentic AI 时,上下文管理的复杂度会很高。
Agentic AI 具备任务分解、多步骤执行、自主思考和工具调用等高级能力。
这些能力的实现都依赖于更加丰富和复杂的上下文结构。
比如单Agent场景
假设一个任务被 Agent 分解成了 10 个子任务,每个子任务需要调用两次工具才能完成。
那么这个大任务总共会产生 41 条新增的上下文记录:
- 1 条初始的任务分解思考,加上 10 个子任务各自产生的 4 条记录(1 次工具调用请求 + 1 次工具调用返回,重复两次)。
那目前业界是如何在 Agent 应用上管理上下文的呢?
上下文优化器会根据当前用户输入、任务目标和模型状态决定是否进行压缩。
还有采用何种压缩策略、丢弃哪些内容、存储为记忆,以及何时进行记忆回填等操作。
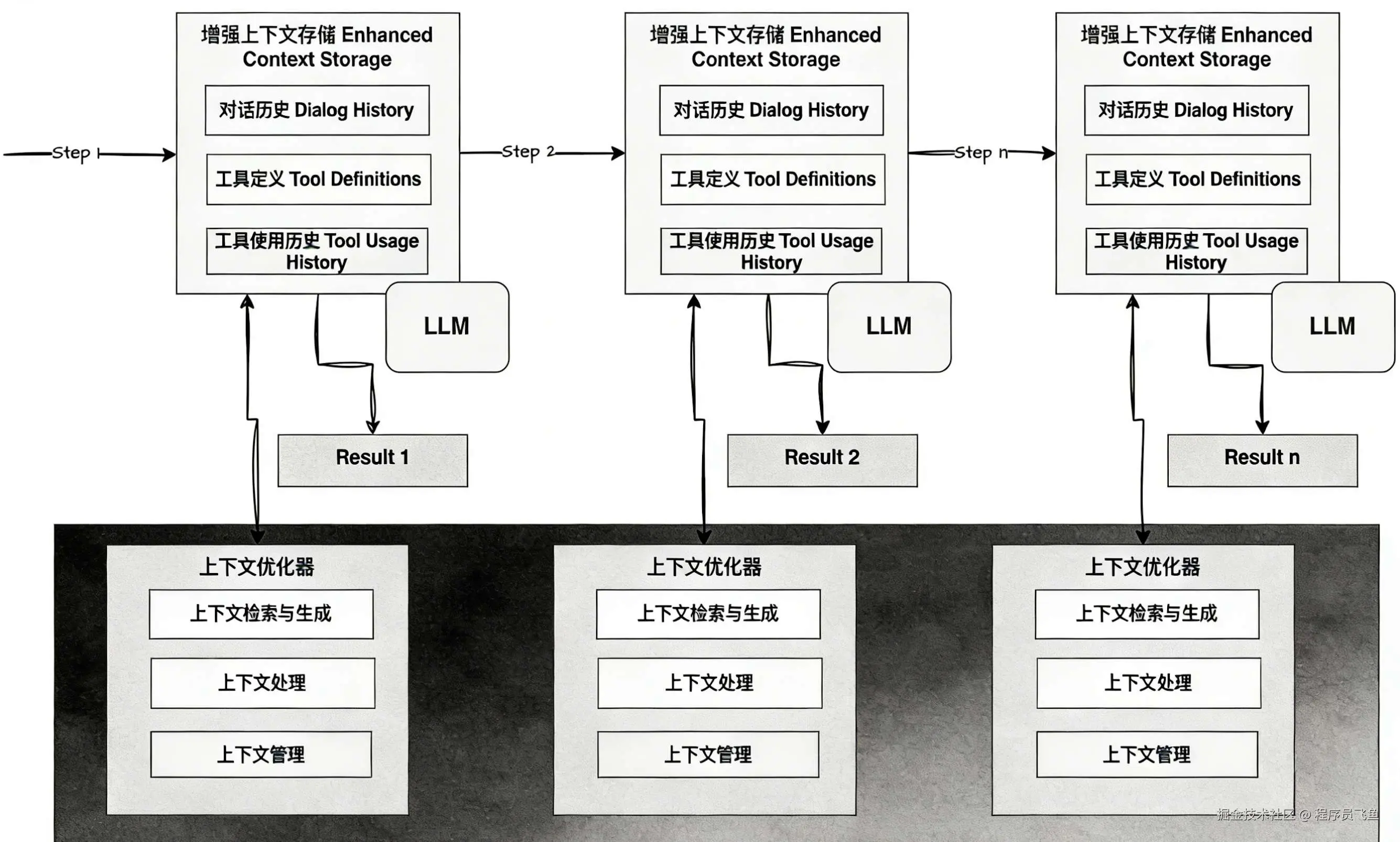
Context Engineering的具体实现方法(参考LangChain)
保存Context:
将Context筛选总结后保存到内存、硬盘等地方,在模型需要时再发送给它。
如ChatGPT的记忆功能,可将用户输入的信息存入记忆库。
选择Context:
静态选择:把永远重要、必须遵守的信息在每次请求时都放入Context。
- 如Cursor的Rules文件、Claude Code的Claude.md文件,确保AI行为符合预期。
动态选择:选择与用户问题最相关的内容放入Context。
如ChatGPT从记忆库中挑选相关记忆,从众多工具中挑选相关工具。
- 其中最有名的实现方式是Rag。
压缩Context:
Agent运行时,Context里会积累大量历史消息,最占空间的是模型输出、文本和工具执行结果。
Claude Code在使用量超过95%时,会运行AutocomPact程序对Context进行压缩。
隔离Context:
不同模块的Context互相隔离。
Lead Agent负责任务下发和归纳总结,Sub Agent有独立的工具、运行历史和记忆体系,Context互不影响。
Claude Code中也有类似的SubAgent概念。