语音转文本ASR工具合集汇总过几个ASR项目或模型,本文继续汇总,并做简单介绍和部分初步实战。
注:缺乏深入实战,和问题记录,请勿喷。
Omnilingual ASR
论文,项目首页,Meta开源(GitHub,2.4K Star,207 Fork),支持1600种语言,其中超过500种语言是首次被任何ASR系统覆盖。
ASR系统面临的根本困境是数据稀缺性悖论:英语、中文等主流语言拥有海量训练数据,模型性能不断提升;而低资源语言却陷入"数据贫瘠→模型失效→更少人使用"的死亡螺旋。7B-LLM-ASR系统在1600多种语言上实现最先进的性能,78%的语言字符错误率(CER)低于10。
传统方法如Whisper Large和MMS,虽然在高资源语言上表现优异,但遇到低资源语言时就会出现严重问题:大量"空白转录"(直接输出空文本)、跨语言混淆(将一种语言误识别为另一种)、以及无法处理的语音变异。技术局限本质上源于传统架构的固定输出空间设计------模型只能处理训练时见过的有限语言集合。扩展新语言意味着从头收集数万小时数据、重新训练整个模型,成本高达数百万美元。
技术突破
- 数据:构建史上最大低资源语言语音库
Meta与全球社区合作,通过与Mozilla Foundation的Common Voice、Lanfrica/NaijaVoices等组织合作,直接与当地社区合作,收集350种传统ASR从未见过的语言数据。Omnilingual ASR Corpus的语料库,是目前最大的低资源语言语音数据集。
- 双解码器
- 扩展的wav2vec 2.0:将自监督学习预训练扩展到70亿参数,学习到极其鲁棒的语音表征能力。这种大规模预训练让模型能够捕捉到跨语言的共性特征。
- 双解码器体系:创新性地结合CTC解码器和LLM式Transformer解码器。CTC解码器负责处理语音到文本的对齐问题,而LLM风格的解码器则引入了类似大语言模型的上下文学习能力。
- 上下文学习:模型可以通过少量示例学习全新的语言,实现真正的"零样本"泛化能力。实现零样本学习:模型套件可以通过上下文学习教授新语言。
利用自监督学习和少样本学习技术,极大降低训练数据的需求。
模型家族:
| 模型类型 | 参数量 | 适用场景 | 相对速度 |
|---|---|---|---|
| omniASR-CTC-300M | 3.25亿 | 移动设备、边缘计算 | 96倍 |
| omniASR-CTC-7B | 65亿 | 服务器端高精度识别 | 16倍 |
| omniASR-LLM-7B | 78亿 | 零样本学习、新语言扩展 | 基准速度 |
对于训练时完全未见过的语言,Omnilingual ASR通过其上下文学习能力,仅需5-10个示例就能实现可用的识别精度,而传统方法则需要成千上万的标注样本。
py
pip install omnilingual-asr
uv add omnilingual-asr
from omnilingual_asr.models.inference.pipeline import ASRInferencePipeline
pipeline = ASRInferencePipeline(model_card="omniASR_LLM_7B")
audio_files = ["/path/to/audio1.flac", "/path/to/audio2.wav"]
lang = ["eng_Latn", "deu_Latn"] # 指定语言代码
transcriptions = pipeline.transcribe(audio_files, lang=lang, batch_size=2)languagecode_script格式
数据集
py
pip install "omnilingual-asr[data]"
from datasets import load_dataset
from omnilingual_asr.models.inference.pipeline import ASRInferencePipeline
omni_dataset = load_dataset("facebook/omnilingual-asr-corpus", "lij_Latn", split="train", streaming=True)VoiceCraft
论文,开源(GitHub,8.4K Star,799 Fork)AI驱动的语音处理平台,提供ASR、TTS等能力,项目主页。
ASR居然不支持麦克风,需上传音频文件?
TTS,可通过手动输入文本或上传TXT文件来生成语音,支持多种声音选择(性别、音色和风格)。
Handy
官网,开源(GitHub,7.9K Star,520 Fork)本地语音转文字引擎工具,不是语音输入法,基于OpenAI Whisper和Parakeet V3,完全离线、不联网、不上传、不偷数据。
技术栈:
- Silero VAD过滤静音,只说有效内容
- Whisper模型(小/中/Turbo/大),支持GPU加速
- Parakeet V3,CPU优化,自动语言检测,中文识别准确率吊打国内输入法
| 平台 | 支持情况 |
|---|---|
| Windows | x64,支持NVIDIA、Intel、AMD GPU加速 |
| MacOS | Intel+Apple Silicon全支持,M1/M2识别速度飞快 |
| Linux | Ubuntu 22.04/24.04测试通过,支持Vulkan加速 |
| 模型 | 优点 | 缺点 | 适合人群 |
|---|---|---|---|
| Whisper Small | 速度快,中文准 | 复杂术语略差 | 日常办公、写日报 |
| Whisper Medium | 准确率提升 | 占用1.5GB内存 | 写文档、写技术文章 |
| Whisper Turbo | 速度+准确率平衡 | 模型大 | GPU设备 |
| Parakeet V3 | CPU优化,自动语言检测 | 英文更强 | 老电脑、低功耗设备 |
实战
模型选择
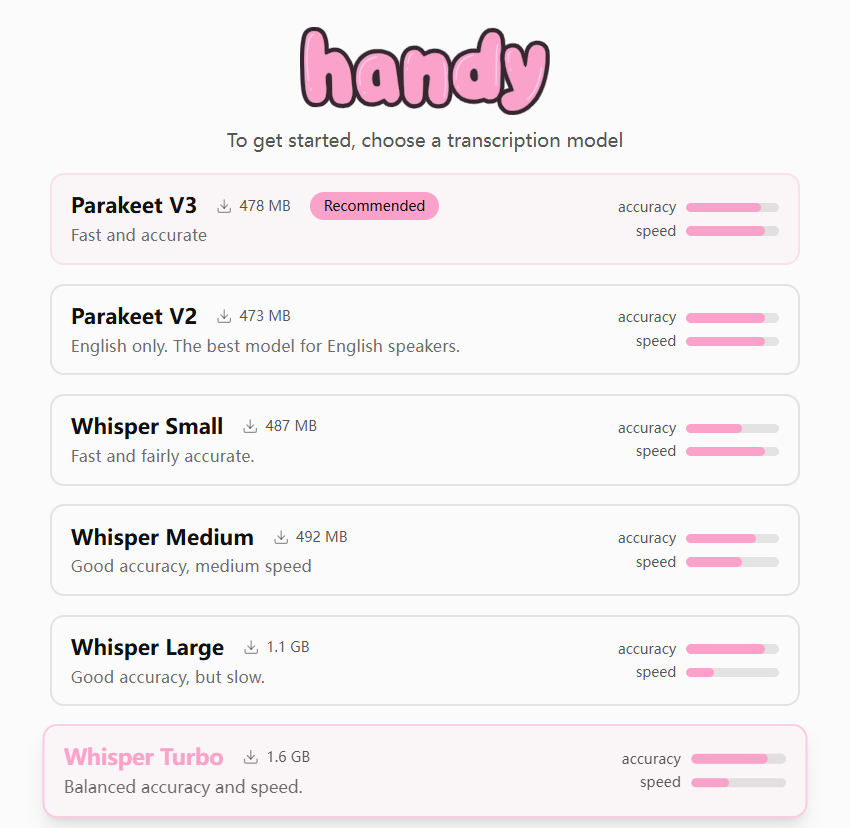
设置如下
高级设置
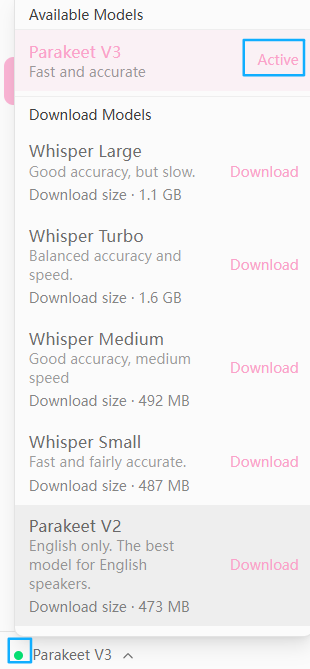
问题
使用Parakeet模型时,说中文,不支持识别(识别为英文):
下载Whisper Small成功,
本地存储地址为:C:\Users\<username>\AppData\Roaming\com.pais.handy

切换到此模型,应用闪退??打开Windows任务管理器,查看进程使用
技巧:说Let's go自动切英文,说我们开始自动切中文。
FireRedASR
论文,开源(GitHub,1.6K Star,149 Fork)。
Smart Turn
开源(GitHub,1.1K Star,63 Fork)语义VAD(Voice Activity Detection,语音活动检测)模型,目前支持语言包括阿拉伯语、孟加拉语、中文等23种。
开源模型:
最新v3.1版本的两个改进:
- 新增三家数据合作伙伴提供的真实人声数据集,英语识别准确率从88.3%提升到95.6%:
- Liva AI:专注不同情绪状态下的对话转折
- Midcentury:提供12种语言的跨文化对话样本
- MundoAI:采集16种语言的方言变体
- 首次推出32MB未量化版本,在NVIDIA L40S上推理仅需2毫秒
训练数据组成,80%是TTS生成,另外20%是上述三家机构提供的真实人声;团队发现真实人声中那些真实的微妙的呼吸声、语气词等"噪声",恰恰是判断说话状态的关键。而这个发现将如何准确判断用户是否说完这个决策过程压缩到12毫秒,相比之下其他OCR模型要0.5-1秒才能判断。
CPU环境,模型文件仅8.68M,建议设置两个环境变量,可减少线程竞争带来的性能损耗:
OMP_NUM_THREADS=1
OMP_WAIT_POLICY="PASSIVE"GPU环境,模型文件仅32.4 MB。
WEST
技术报告,WE Speech Toolkit缩写,开源(GitHub,153 Star)语音工具箱,以LLM为核心,打通语音识别、合成、理解、对话全流程。通过Sequence Packing技术,WEST在处理1w条语音时,比传统静态批处理快2.4倍,GPU利用率提升至73.87%,兼顾效率与稳定性。
关键特性
- LLM驱动:充分复用成熟的技术生态,让语音任务与LLM生态无缝衔接,降低技术迁移成本:
- 兼容HuggingFace等平台开源模型,如LLaMA、QWen、Mistral;
- 采用Sequence Packing、Flash Attention等LLM训练技术,大幅提升训练效率;
- 统一数据格式:受文本LLM训练范式的启发,语音大模型的训练通常分为两个阶段:预训练和微调。预训练阶段通常利用大规模数据集,微调阶段采用较小规模高质量数据集。为了支持上述两个训练阶段并考虑数据存储和读取效率,设计两种数据格式:
- 预训练数据格式:此数据包含语音和可选文本标签,且数据量较大,一般为百万级,支持tar、JSON两种格式。
- 微调数据格式:使用
role-content格式,方便支持多轮微调训练,对于语音理解、对话和多轮交互等任务至关重要。
- 全任务覆盖:支持识别、合成、理解、对话任务,具有可扩展性:
- TouchASU:由语音编码器、投影仪和LLM组成。用于支持语音识别、语音理解和语音问答任务;
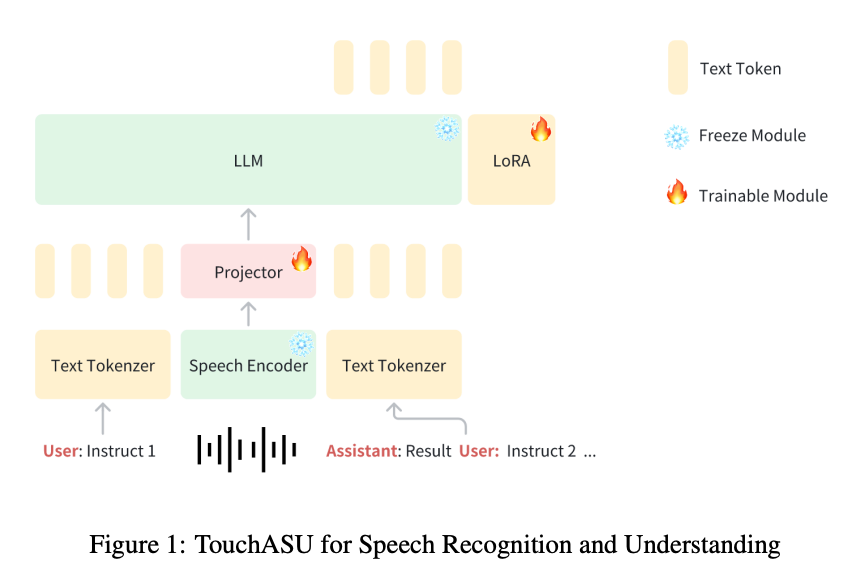
- TouchTTS:由TouchTTS、TouchFlow、声码器三部分组成。TouchTTS负责文本到语音token建模,TouchFlow将语音token转化为梅尔谱特征,然后声码器将其转换为音频
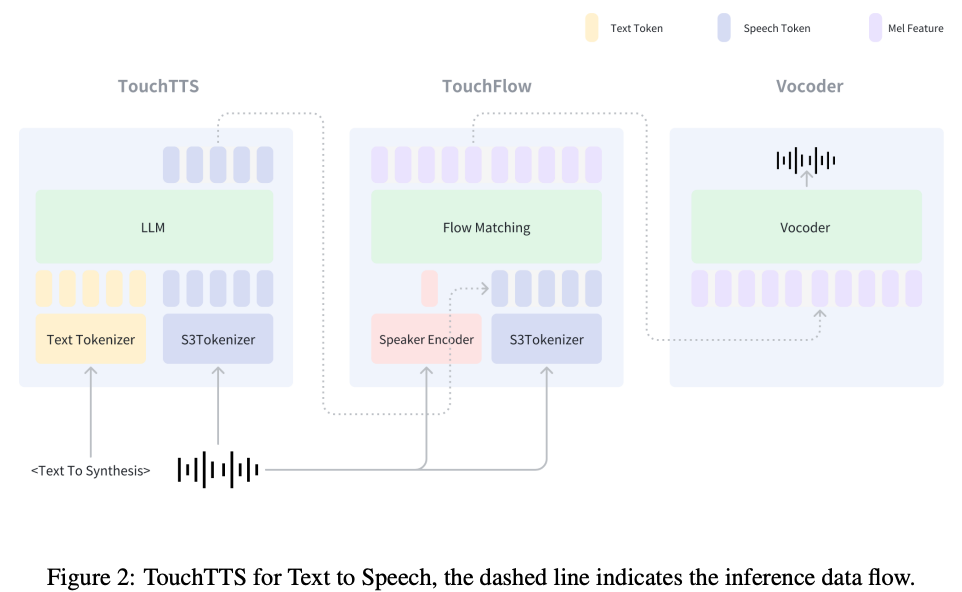
- TouchChat:参考Qwen2.5-omni设计,由TouchASU和TouchTTS组成,TouchASU负责理解语音,TouchTTS负责生成语音回复。
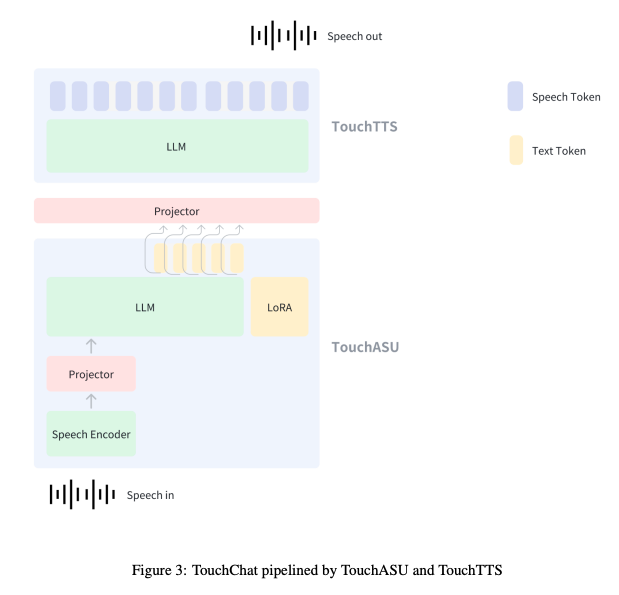
- TouchASU:由语音编码器、投影仪和LLM组成。用于支持语音识别、语音理解和语音问答任务;
- 可扩展性:支持适配开源模型,目前已支持OSUM-echat;用户也能基于基础组件自定义模型。
Kroko ASR
官网,专为边缘计算场景设计的开源(GitHub,115 Star,9 Fork)ASR模型,模型权重托管在HF,官方文档。支持集成FreeSwitch、Asterisk、FreePBX等电话系统平台。
特性:
- CPU优化:可在单个CPU核心上实现极快的转录速度,可处理8-10个并发流,显著降低硬件成本和能耗;
- 边缘设备部署:模型体积小巧(约70MB),可直接在用户本地设备、移动应用或浏览器中运行,非常适合需要离线或本地处理的应用场景;
- Whisper、Parakeet级别的准确性:基于CC-BY模型构建,专为实时电话通信而调整;
- 集成简单:直接在拨号方案中使用
kroko_transcribe或通过API使用uuid_kroko_transcribe; - 低延迟串流:支持实时音频流处理,能提供即时响应的语音转文字体验,适用于语音助手、实时客服辅助和会议记录等需要即时反馈的场景;
- 注重隐私:由于数据在本地处理(本地部署或设备端处理),敏感语音数据不会上传到云端服务器,提供更高的数据隐私保护和合规性;
- 开源与商业结合:核心引擎是完全开源的,提供社区版(免费用于非商业用途)和付费的专业版模型,用户可以根据项目需求选择最合适的方案。
拓展
FreeSwitch
英文官网,中文官网,开源(GitHub,4.5K Star,1.7K Fork)跨平台电话软交换平台,提供高扩展性和灵活性的实时音视频通信(VoIP)、多媒体路由、即时消息和会议功能,支持SIP及WebRTC等多种通信协议,可用于构建PBX(Private Branch Exchange,电话交换机)、软交换、语音网关等,广泛应用于呼叫中心、电信应用及各种通信解决方案中。
核心特点
- 开源与跨平台:基于C/C++开发,在多种操作系统上运行
- 协议支持:支持SIP、H.323、IAX2、WebRTC等
- 功能丰富:包括呼叫控制、语音/视频会议、IVR(交互式语音应答)、录音、传真(T.38)等
- 高扩展性:模块化设计,易于集成第三方库,通过API进行扩展
- 灵活部署:可作为独立的软交换机、PBX、媒体网关或核心引擎
主要用途
- 企业PBX:构建功能强大的内部电话系统
- 呼叫中心:实现智能路由、IVR、录音等
- 电信网关:连接不同通信协议的设备
- 多媒体应用:支持音视频通信和会议系统
Asterisk
官网,开源(GitHub,2.9K Star,1.2K Fork)基于计算机的PBX系统,可将普通电脑变成功能强大的通信服务器,为小型企业、呼叫中心和运营商提供支持,用于构建IP PBX、VoIP网关等。
FreePBX
官网,开源基于Web的IP PBX系统管理平台,建立在Asterisk软交换框架之上,提供图形化界面,让用户能够简单方便地配置和管理一个功能齐全的电话系统,实现企业通信功能,如分机、呼叫路由、IVR、语音邮件、呼叫录音等,是企业级通信解决方案,具有高度灵活性和可定制性。
主要功能
- 分机管理:创建、管理内部分机;
- 呼叫路由:灵活设置呼入和呼出呼叫的走向;
- 交互式语音应答:IVR,自动语音导航菜单,如按1转接XX部门;
- 呼叫排队/振铃组:用于呼叫中心或客服团队;
- 语音邮件:Voicemail,语音留言功能;
- 呼叫录音:记录通话内容;
- 模块化:可按需添加额外功能模块,扩展系统能力。
优势
- 开源免费:基础功能免费,降低部署成本;
- 灵活性高:高度可定制,适应不同规模企业的需求;
- 功能强大:提供传统电话系统所有功能,并有更多增值功能;
- 易于使用:Web界面简化配置和管理,降低技术门槛。