这篇文章介绍了 Index-ASR,一个由哔哩哔哩团队开发的大规模、基于大语言模型(LLM)的自动语音识别(ASR)系统。其主要研究内容可概括为以下几点:
一、研究背景与动机
-
现状: 基于LLM的ASR系统在语义理解和上下文一致性方面表现出色,但仍存在两大关键问题:
-
幻觉问题: 在噪声环境下容易产生过长、重复且与语音输入不符的幻觉输出。
-
定制化支持不足: 对灵活、细粒度的上下文(如用户自定义热词)识别支持有限。
-
-
目标: 设计一个同时具备强鲁棒性 (抗噪声)和强上下文定制能力的ASR系统。
二、核心创新:Index-ASR 系统
这是一个三阶段的LLM-based ASR框架,核心特点是数据驱动 和模块化训练。
-
模型架构:
-
音频编码器: 基于Conformer-Transformer的注意力编码器-解码器模型,用于提取稳健的语音特征。
-
音频适配器: 桥接音频编码器和LLM,进行特征对齐和降维。
-
LLM解码器: 基于Qwen3-8B,根据处理后的语音特征和文本/上下文提示生成转录文本。
-
-
关键数据策略:
-
噪声增强数据: 训练数据中包含大量带真实背景噪声的语音,直接针对噪声鲁棒性问题。
-
上下文丰富数据: 构建了包含热词 和摘要的上下文数据,用于训练模型的上下文理解和指令跟随能力。
-
-
三阶段训练范式:
-
阶段一(音频编码器训练): 独立训练一个稳健的语音编码器。
-
阶段二(监督微调-SFT):
-
SFT1:冻结编码器和LLM,仅训练适配器以实现音-文模态对齐。
-
SFT2:微调解码器和适配器,使用LoRA技术微调LLM,提升整体识别性能。
-
-
阶段三(上下文监督微调): 在上下文数据上进一步微调,增强模型对热词和篇章级上下文的理解与利用能力。
-
三、主要实验结果与结论
-
高准确率: 在多个开源基准(如LibriSpeech, GigaSpeech)和内部测试集上达到先进水平。
-
强噪声鲁棒性: 在噪声严重的测试集(如GigaSpeech和内部嘈杂领域)上表现最佳或接近最佳,显著缓解了幻觉问题。
-
有效的上下文定制能力: 在上下文ASR测试集上,引入上下文信息后:
-
平均词错误率(WER)降低43%。
-
平均热词召回率提升33%。
-
证明模型能有效利用热词列表等上下文提示。
-
四、局限性与未来方向
-
语言支持有限: 目前仅支持中英文,计划推出多语言版本。
-
数据规模: 训练数据规模相比工业级模型仍有提升空间。
-
不支持流式识别: 未来计划增加流式ASR功能,以适用于实时场景。
Index-ASR 的核心贡献是 :通过系统性地整合大规模噪声数据 和上下文增强数据 ,并结合分阶段、模块化的训练策略 ,成功构建了一个同时具备优异噪声鲁棒性 和强大上下文定制能力 的LLM-based ASR系统,为将高性能ASR应用于复杂、真实的场景提供了有效的解决方案。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
近年来,自动语音识别(ASR)取得了显著进展,这主要得益于基于大语言模型(LLM)的ASR范式的出现。尽管在各类开源基准测试上表现出色,但现有的基于LLM的ASR系统仍存在两个关键局限性。首先,它们容易产生幻觉错误,常常生成过长且重复的输出,而这些输出并未很好地基于声学输入。其次,它们对灵活且细粒度的上下文定制支持有限。为了解决这些挑战,我们提出了 Index-ASR,一个旨在同时增强鲁棒性并支持可定制热词识别的大规模基于LLM的ASR系统。Index-ASR的核心思想在于将LLM与富含背景噪声和上下文信息的大规模训练数据相结合。实验结果表明,我们的 Index-ASR 在开源基准测试和内部测试集上都取得了优异的性能,突显了其在现实世界ASR应用中的鲁棒性和实用性。
1 引言
近年来,自动语音识别(ASR)取得了显著进展,这主要得益于模型参数量和数据规模的扩展12; 6; 26; 11; 28; 13,以及与大语言模型(LLMs)的深度融合。早期的工作,如 Whisper19,通过将模型规模扩展到15亿参数并在68万小时的多语言语音数据上进行训练,验证了缩放定律的有效性,在多种语言上实现了强大的识别性能。随着LLM的快速发展,ASR范式已逐渐从传统的基于注意力的端到端编码器-解码器(AED)框架2; 5转向基于LLM的ASR架构3; 24; 1; 18; 20; 15。最近的模型,如 Seed-ASR3、FireRedASR24、FunAudio-ASR1 和 Qwen3-ASR-Flash18 已经证明,结合LLM可以显著提高ASR性能,特别是在改善语义消歧和产生更连贯、上下文更一致的转录方面。
在基于LLM的ASR时代,词错误率(WER)不再是评估识别性能的唯一指标。除了WER,另外两个维度变得尤为关键。首先,对噪声语音的鲁棒性 至关重要。我们观察到,严重的背景噪声很容易在基于LLM的ASR中引发幻觉行为,常常导致过长且重复的输出。因此,增强基于LLM的ASR模型的噪声鲁棒性是一个紧迫且重要的研究挑战。其次,上下文感知识别已成为一项重要能力。利用LLM强大的指令跟随特性,一个理想的基于LLM的ASR系统应支持灵活的上下文定制,例如用户定义的热词,以提高对领域特定术语的识别。
基于上述考虑,我们提出了 Index-ASR,一个基于大规模真实世界数据训练的基于LLM的语音识别框架。Index-ASR 展现出几个显著特点:
-
*高语音识别准确率。 通过数据规模、模型能力和LLM集成架构设计的协同进步,Index-ASR 在公共基准测试和内部测试集上都取得了强大的性能。
-
*对噪声语音的强鲁棒性。 通过在训练中融入大量真实的、受噪声污染的语音,Index-ASR 显著增强了鲁棒性,有效缓解了基于LLM的ASR系统中常见的幻觉现象。
-
*可定制的热词识别能力。 利用LLM强大的上下文建模和指令跟随能力,Index-ASR 支持在推理过程中动态注入用户定义的热词,从而能够准确识别罕见或领域特定的术语。
本报告的其余部分组织如下。第2节概述了Index-ASR的架构。第3节和第4节分别描述了训练数据和整体训练范式。第5节展示了实验结果,第6节讨论了当前工作的局限性以及我们未来的计划。最后,第7节总结了报告。
2 模型架构
Index-ASR 由一个音频编码器、一个音频适配器和一个基于LLM的解码器组成,如图1所示。音频编码器负责从输入语音中提取高级表示。音频适配器通过执行时间下采样并将这些表示投影到语言模型所需的适当维度,进一步处理这些表示。解码器基于 Qwen3-8B25 构建,它根据处理后的语音特征和文本提示自回归地生成转录输出。
关于文本提示,除了指令提示外,Index-ASR 还支持上下文提示。具体来说,当提供用户定义的线索(如热词列表或段落级摘要)时,模型可以更可靠地识别低频词和领域特定术语。
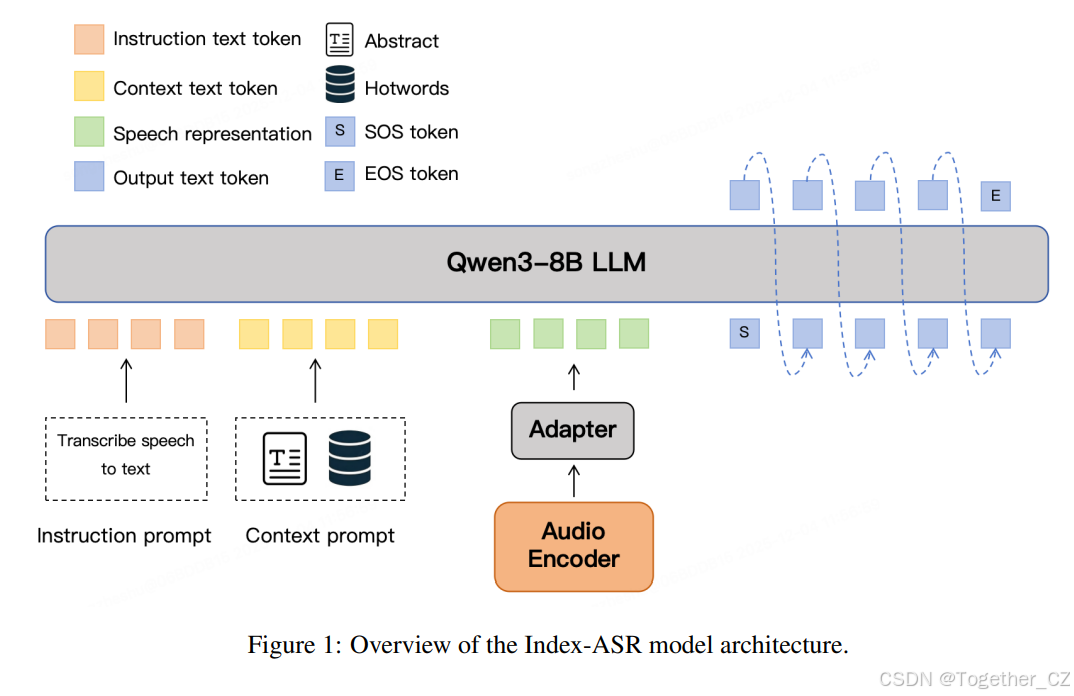
图 1:Index-ASR 模型架构概览。
3 数据
音频编码器训练数据
为了训练音频编码器,我们主要采用覆盖中文和英文的大规模开源ASR语料库,并辅以内部标注数据。开源资源包括 LibriSpeech16、GigaSpeech6、WenetSpeech28 和 AISHELL-28。此外,我们整合了内部标注的语音数据,以进一步增强数据多样性并提高模型鲁棒性。
监督微调数据
在监督微调阶段,除了上述数据集,我们进一步整合了开源的多语言 LibriSpeech 语料库171以及内部伪标签数据。
脚注1:我们仅使用MLS数据集中的英文ASR数据。
上下文监督微调数据
在上下文监督微调阶段,构建了两种类型的上下文数据。第一种是热词上下文数据,利用 DeepSeek-V314 从每个ASR样本中提取关键词或领域特定术语。第二种是摘要上下文数据,通过拼接与给定视频相关的所有转录文本,并提示 DeepSeek-V3 生成简洁摘要来获得。
4 训练
Index-ASR 的训练包括三个阶段:音频编码器训练、监督微调和上下文监督微调。监督微调和上下文监督微调的训练配置如表1所示。

音频编码器训练
遵循 FireRedASR,我们首先在 Wenet 框架27; 29 下训练一个基于注意力的编码器-解码器模型,该模型集成了 Conformer 编码器9 和 Transformer 解码器21。采用这种架构是为了共同利用 Conformer 对语音特征局部和长程依赖性的建模能力,以及 Transformer 在序列转换上的强大性能。训练后,AED模型的编码器组件用于初始化下游基于LLM的ASR系统中的音频编码器,从而为后续基于LLM的ASR训练提供更稳健的起点。
监督微调
监督微调(SFT)包括两个连续阶段。
阶段1: 音频编码器和LLM的参数被冻结。仅在适配器模块上进行训练,该模块被优化以有效将编码器的声学表示映射到LLM的语义空间,从而实现音频和文本模态之间的对齐。
阶段2: 为了进一步加强模型的识别性能,对音频编码器和适配器进行全参数微调,同时使用 LoRA10 对 LLM 进行微调。
上下文监督微调
通过利用LLM的指令跟随能力,将上下文信息整合到提示中使模型能够更可靠地识别和转录专有名词。因此,在SFT训练之后,我们在第3.3节所述的上下文数据上进一步训练 Index-ASR,以增强其上下文建模能力。为了防止在没有上下文信息的场景下可能出现的性能下降,第3.2节所述的部分ASR数据也被纳入训练过程。
5 评估
评估设置
我们在公开可用的ASR基准测试和内部测试集上评估 Index-ASR 以及几个开源语音识别模型19, 7, 23, 24。对于开源基准测试,我们在 AIShell-28、LibriSpeech16、GigaSpeech6 和 WenetSpeech28 的测试集上进行评估。考虑到上述大多数测试集相对干净且包含的背景噪声有限,我们在具有复杂背景噪声的内部测试集上进一步评估了 Index-ASR 和其他开源模型的鲁棒性。此外,在 AIShell-1 热词测试集4、ContextASR-Bench22 和内部上下文 ASR 测试集上进行了实验,以评估 Index-ASR 的上下文定制能力。
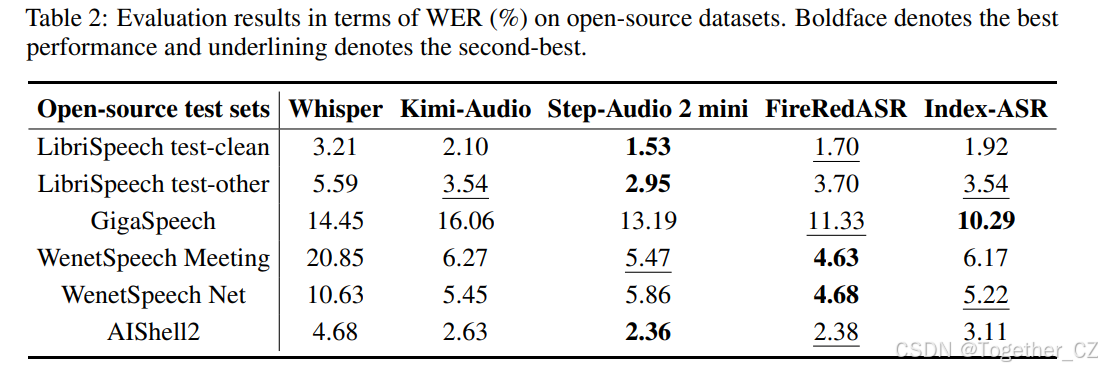
在开源测试集上的评估
表2所示的结果表明,所有评估的模型在开源测试集上都表现出强大的识别性能。然而,在有噪声的 GigaSpeech 测试集上,我们的模型在比较的开源系统中获得了最佳性能,证明了其在具有挑战性的声学条件下具有卓越的鲁棒性。
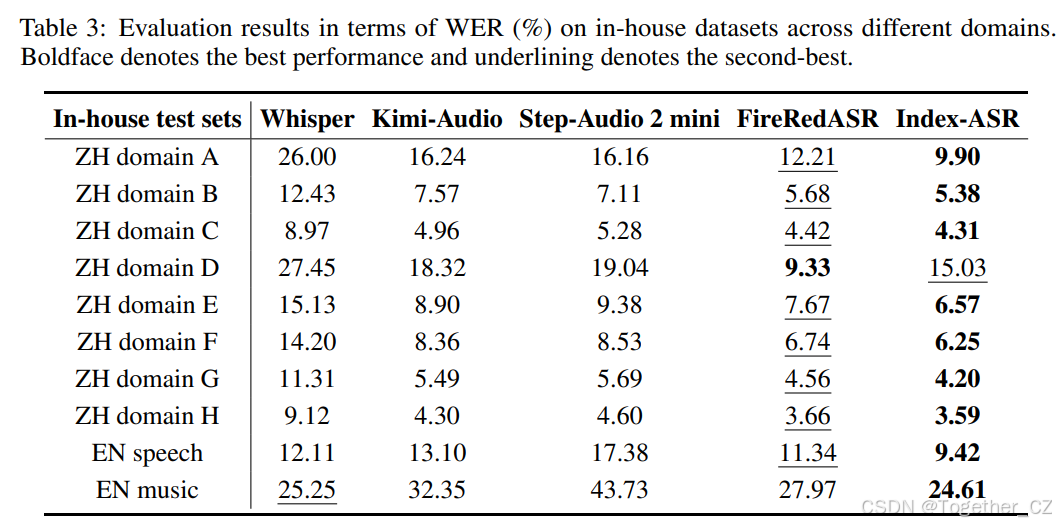
在内部测试集上的评估
如表3所示,我们的 Index-ASR 模型在内部测试领域中实现了最先进(SOTA)的性能。值得注意的是,在音频录音经常包含大量背景噪声的领域A和领域E中,我们的模型仍然提供了强大的识别准确率,进一步强调了其在声学挑战场景下的强鲁棒性。
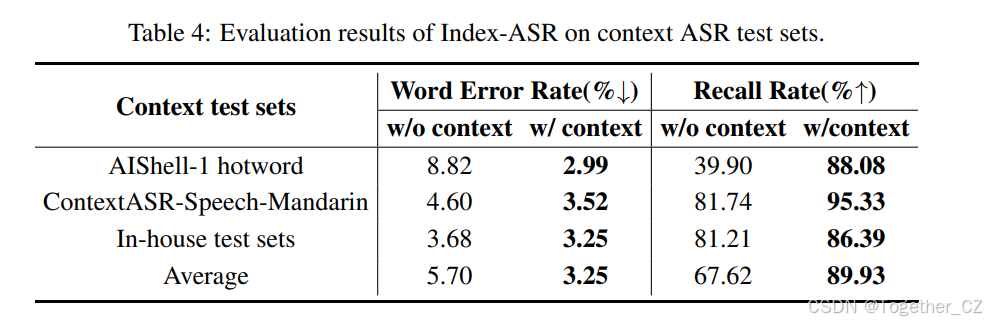
在上下文 ASR 测试集上的评估
为了评估 Index-ASR 的上下文感知识别能力,我们在几个上下文 ASR 测试集上评估了该模型。如表4所示,与无上下文设置相比,将上下文信息纳入输入中导致了性能的大幅提升。具体来说,平均 WER 降低了 43%,而平均热词召回率提高了 33%。这些结果表明,Index-ASR 能够有效地利用上下文线索,表明其强大的上下文建模能力以及遵循上下文指令的能力。
6 局限性与未来计划
尽管在各种评估中取得了优异的结果,我们的 Index-ASR 仍存在一些局限性。首先,当前模型仅支持中文和英文,没有覆盖其他语言。我们计划未来发布 Index-ASR 的多语言版本。其次,与工业ASR模型使用的数据集相比,当前训练语料库的规模仍然有限。最后,当前模型不支持流式ASR。因此,引入流式能力是后续改进的一个重要方向。
7 结论
在本文中,我们提出了 Index-ASR,一个基于大规模噪声增强和上下文丰富数据训练的大规模基于LLM的ASR系统。通过利用这种以数据为中心的设计,Index-ASR 展示了对噪声语音的强鲁棒性和增强的上下文感知识别能力。在开源基准测试和内部测试集上的广泛实验结果表明,Index-ASR 始终表现出强大的性能,特别是在具有复杂背景噪声的挑战性声学条件下。展望未来,未来的工作将专注于扩展 Index-ASR 以支持更广泛的语言,并引入流式识别能力,以进一步提高其在现实场景中的适用性。