一、模型可视化
1. nn.model自带的方法
python
# nn.Module 的内置功能,直接输出模型结构
print(model)
html
MLP(
(fc1): Linear(in_features=4, out_features=10, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=10, out_features=3, bias=True)
)
python
# nn.Module 的内置功能,返回模型的可训练参数迭代器
for name, param in model.named_parameters():
print(f"Parameter name: {name}, Shape: {param.shape}")
html
Parameter name: fc1.weight, Shape: torch.Size([10, 4])
Parameter name: fc1.bias, Shape: torch.Size([10])
Parameter name: fc2.weight, Shape: torch.Size([3, 10])
Parameter name: fc2.bias, Shape: torch.Size([3])可以将模型中带有weight的参数(即权重)提取出来,并转为 numpy 数组形式,对其计算统计分布,并且绘制可视化图表
python
# 提取权重数据
import numpy as np
weight_data = {}
for name, param in model.named_parameters():
if 'weight' in name:
weight_data[name] = param.detach().cpu().numpy()
# 可视化权重分布
fig, axes = plt.subplots(1, len(weight_data), figsize=(15, 5))
fig.suptitle('Weight Distribution of Layers')
for i, (name, weights) in enumerate(weight_data.items()):
# 展平权重张量为一维数组
weights_flat = weights.flatten()
# 绘制直方图
axes[i].hist(weights_flat, bins=50, alpha=0.7)
axes[i].set_title(name)
axes[i].set_xlabel('Weight Value')
axes[i].set_ylabel('Frequency')
axes[i].grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.subplots_adjust(top=0.85)
plt.show()
# 计算并打印每层权重的统计信息
print("\n=== 权重统计信息 ===")
for name, weights in weight_data.items():
mean = np.mean(weights)
std = np.std(weights)
min_val = np.min(weights)
max_val = np.max(weights)
print(f"{name}:")
print(f" 均值: {mean:.6f}")
print(f" 标准差: {std:.6f}")
print(f" 最小值: {min_val:.6f}")
print(f" 最大值: {max_val:.6f}")
print("-" * 30)
html
=== 权重统计信息 ===
fc1.weight:
均值: 0.192228
标准差: 0.938566
最小值: -1.381258
最大值: 2.418161
------------------------------
fc2.weight:
均值: 0.017777
标准差: 1.153885
最小值: -2.814914
最大值: 2.982998
------------------------------对比 fc1.weight 和 fc2.weight 的统计信息 ,可以发现它们的均值、标准差、最值等存在差异。这反映了不同层在模型中的作用不同。
权重统计信息可以为超参数调整提供参考。例如,如果发现权重标准差过大导致训练不稳定,可以尝试调整学习率,使权重更新更平稳;或者改变权重初始化方法,使初始权重分布更合理。如果最小值和最大值在训练后期仍波动较大,可能需要考虑调整正则化参数,防止过拟合或欠拟合。
2. torchsummary库的summary方法
python
from torchsummary import summary
# 打印模型摘要,可以放置在模型定义后面
summary(model, input_size=(4,))
html
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 10] 50
ReLU-2 [-1, 10] 0
Linear-3 [-1, 3] 33
================================================================
Total params: 83
Trainable params: 83
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
----------------------------------------------------------------该方法不显示输入层的尺寸,因为输入的神经网是自己设置的,所以不需要显示输入层的尺寸。
但是在使用该方法时,input_size=(4,) 参数是必需的,因为 PyTorch 需要知道输入数据的形状才能推断模型各层的输出形状和参数数量。
这是因为PyTorch 的模型在定义时是动态的,它不会预先知道输入数据的具体形状。nn.Linear(4, 10) 只定义了 "输入维度是 4,输出维度是 10",但不知道输入的批量大小和其他维度,比如卷积层需要知道输入的通道数、高度、宽度等信息。----并非所有输入数据都是结构化数据
因此,要生成模型摘要(如每层的输出形状、参数数量),必须提供一个示例输入形状,让 PyTorch "运行" 一次模型,从而推断出各层的信息。
summary 函数的核心逻辑是:
创建一个与 input_size 形状匹配的虚拟输入张量(通常填充零)
将虚拟输入传递给模型,执行一次前向传播(但不计算梯度)
记录每一层的输入和输出形状,以及参数数量
生成可读的摘要报告
3. torchinfo库的summary方法
torchinfo 是提供比 torchsummary 更详细的模型摘要信息,包括每层的输入输出形状、参数数量、计算量等。
python
from torchinfo import summary
summary(model, input_size=(4, ))
html
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
MLP [3] --
├─Linear: 1-1 [10] 50
├─ReLU: 1-2 [10] --
├─Linear: 1-3 [3] 33
==========================================================================================
Total params: 83
Trainable params: 83
Non-trainable params: 0
Total mult-adds (M): 0.00
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
==========================================================================================二、进度条功能
tqdm这个库最核心的逻辑如下
创建一个进度条对象,并传入总迭代次数。一般用with语句创建对象,这样对象会在with语句结束后自动销毁,保证资源释放。with是常见的上下文管理器,这样的使用方式还有用with打开文件,结束后会自动关闭文件。
更新进度条,通过pbar.update(n)指定每次前进的步数n(适用于非固定步长的循环)。
1. 手动更新
python
from tqdm import tqdm # 先导入tqdm库
import time # 用于模拟耗时操作
# 创建一个总步数为10的进度条
with tqdm(total=10) as pbar: # pbar是进度条对象的变量名
# pbar 是 progress bar(进度条)的缩写,约定俗成的命名习惯。
for i in range(10): # 循环10次(对应进度条的10步)
time.sleep(0.5) # 模拟每次循环耗时0.5秒
pbar.update(1) # 每次循环后,进度条前进1步
html
100%|██████████| 10/10 [00:05<00:00, 1.96it/s]unit 参数的核心作用是明确进度条中每个进度单位的含义,使可视化信息更具可读性。在深度学习训练中,常用的单位包括:
epoch:训练轮次(遍历整个数据集一次)。
batch:批次(每次梯度更新处理的样本组)。
sample:样本(单个数据点)
2. 自动更新
python
from tqdm import tqdm
import time
# 直接将range(3)传给tqdm,自动生成进度条
# 这个写法我觉得是有点神奇的,直接可以给这个对象内部传入一个可迭代对象,然后自动生成进度条
for i in tqdm(range(3), desc="处理任务", unit="epoch"):
time.sleep(1)
html
处理任务: 100%|██████████| 3/3 [00:03<00:00, 1.01s/epoch]三、模型推理
测试这个词在大模型领域叫做推理(inference),意味着把数据输入到训练好的模型的过程。
模型的评估模式简单来说就是评估阶段会关闭一些训练相关的操作和策略 ,比如更新参数 正则化等操作,确保模型输出结果的稳定性和一致性。
模型推理是训练好的模型对新输入数据(未见过的测试 / 实际数据)输出预测结果的过程,是模型从 "训练学习" 到 "实际应用" 的核心环节,也是模型价值落地的关键步骤(比如用训练好的 MLP 判断一朵新鸢尾花的品种)。
核心特点
- 仅前向传播:推理只执行 "输入→模型→输出" 的前向计算,无需反向传播(不需要更新权重);
- 追求效率:通常会关闭梯度计算、调整模型层的运行模式(如 Dropout/BatchNorm),减少计算开销;
数据对齐:输入数据的预处理(如归一化、维度)必须和训练时完全一致,否则结果无效。
四、对模型进行参数调整

最终结果如下:
html
=== 权重统计信息 ===
fc1.weight:
均值: -0.015790
标准差: 0.602542
最小值: -1.271320
最大值: 1.424051
------------------------------
fc2.weight:
均值: 0.059234
标准差: 0.450090
最小值: -0.760061
最大值: 1.850077
------------------------------
fc3.weight:
均值: -0.030019
标准差: 1.052675
最小值: -2.372552
最大值: 1.760848
------------------------------
html
使用设备: cpu
训练进度: 100%|██████████| 20000/20000 [00:21<00:00, 944.12epoch/s, Loss=0.0859]
Training time: 21.19 seconds与原模型对比
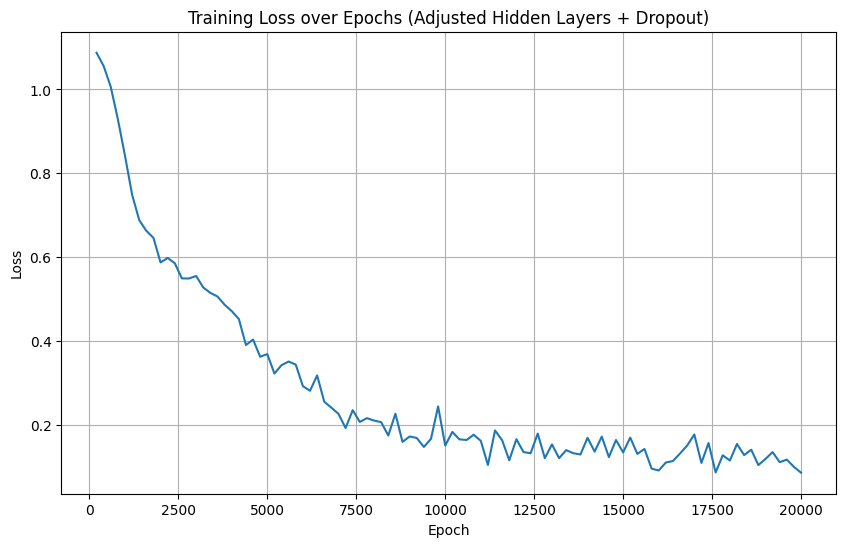
损失曲线特征
原模型 :损失曲线非常平滑,从初始~1.0 持续下降至 0.0650,后期几乎无波动。原因:原模型结构简单(仅 1 层隐藏层 + 10 个神经元),训练过程稳定,无随机化操作(无 Dropout)。
调整后模型 :损失曲线后期波动明显 ,从初始~1.0 下降至 0.0859,但过程中存在多次上下震荡。原因:模型加入了Dropout 层(训练时随机丢弃神经元),这是 Dropout 的 "正常波动"------ 通过随机化让模型避免过拟合,训练损失的波动是 Dropout 起作用的表现。
最终损失与泛化性
原模型最终损失(0.0650)略低于调整后模型(0.0859),但这是 "训练损失" 的差异:
原模型无 Dropout,训练损失是 "全神经元参与" 的结果,更易过拟合(测试集表现可能不如训练损失好);
调整后模型的训练损失是 "Dropout 随机丢弃神经元" 的结果,推理时 Dropout 会关闭(全神经元参与),实际测试集泛化能力通常会优于原模型。
结论
调整后的模型牺牲了训练效率与训练损失的 "平滑性",但通过增加复杂度(隐藏层 / 神经元)提升了拟合能力,同时通过 Dropout 降低了过拟合风险 ------ 是 "以训练成本换泛化能力" 的合理调整。
勇闯python的第37天@浙大疏锦行