MiniCPM-V 4.5
MiniCPM-V 4.5 是MiniCPM-V系列中最新且功能最强大的模型。该模型基于Qwen3-8B和SigLIP2-400M构建,总参数量为8B。与之前的MiniCPM-V和MiniCPM-o模型相比,它在性能上有显著提升,并引入了新的有用功能。MiniCPM-V 4.5的主要特点包括:
-
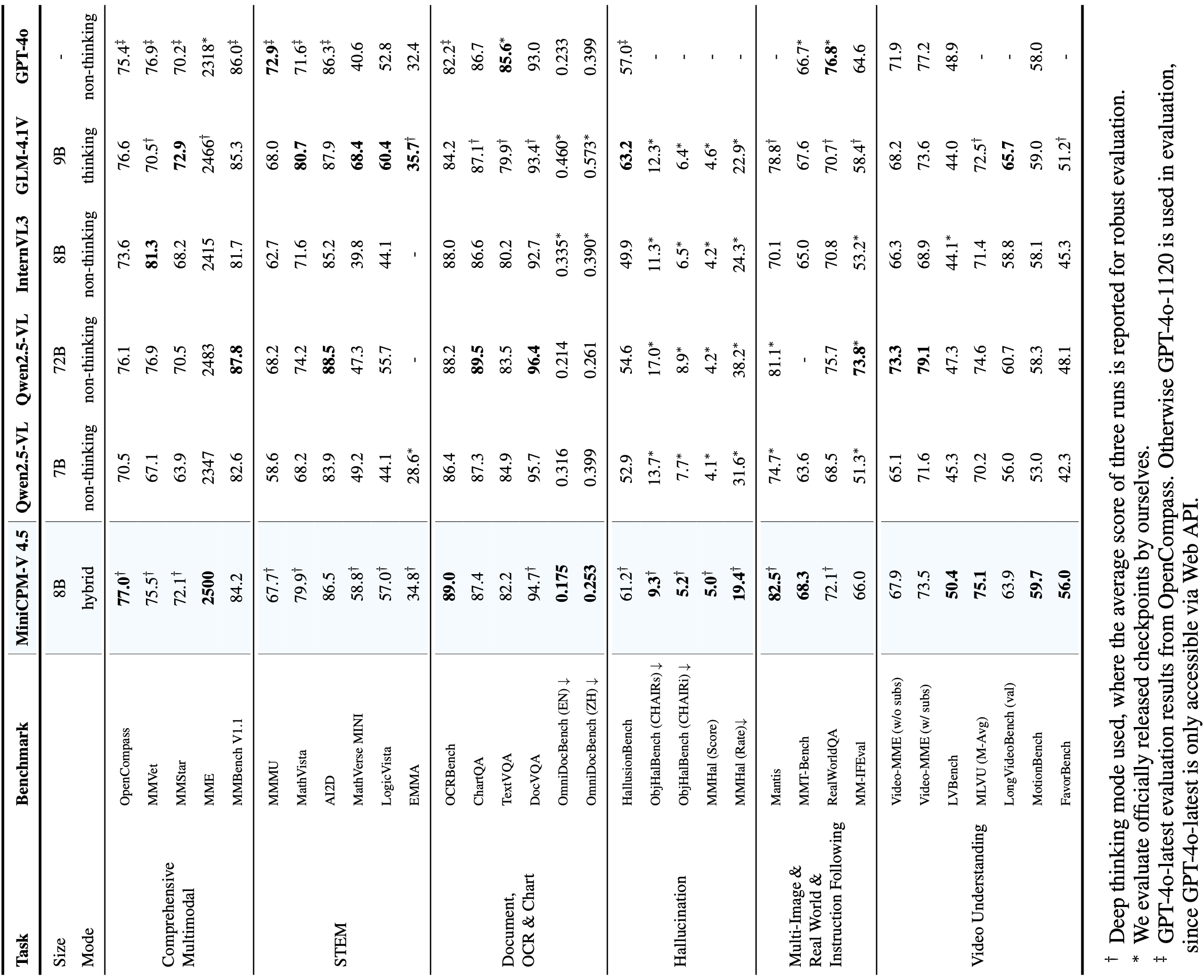
🔥 最先进的视觉-语言能力。 MiniCPM-V 4.5在OpenCompass(一个涵盖8个流行基准测试的综合评估)上平均得分为77.0。仅用8B参数,它就超越了广泛使用的专有模型如GPT-4o-latest、Gemini-2.0 Pro以及强大的开源模型如Qwen2.5-VL 72B 在视觉-语言能力方面,使其成为参数量低于30B的MLLM中性能最佳的模型。
-
🎬 高效的高帧率和长视频理解。 借助新的统一3D重采样器对图像和视频进行处理,MiniCPM-V 4.5现在可以实现96倍的视频令牌压缩率,其中6帧448x448的视频可以被联合压缩成64个视频令牌(大多数MLLM通常需要1,536个令牌)。这意味着模型可以在不增加LLM推理成本的情况下感知更多的视频帧。这带来了在Video-MME、LVBench、MLVU、MotionBench、FavorBench等上的最先进的高帧率(高达10FPS)视频理解和长时间视频理解能力。
-
⚙️ 可控的混合快速/深度思考。 MiniCPM-V 4.5支持既高效又具有竞争力的快速思考,也支持更复杂的深度思考问题解决。为了覆盖不同用户场景中的效率和性能权衡,这种快速/深度思考模式可以以高度可控的方式切换。
-
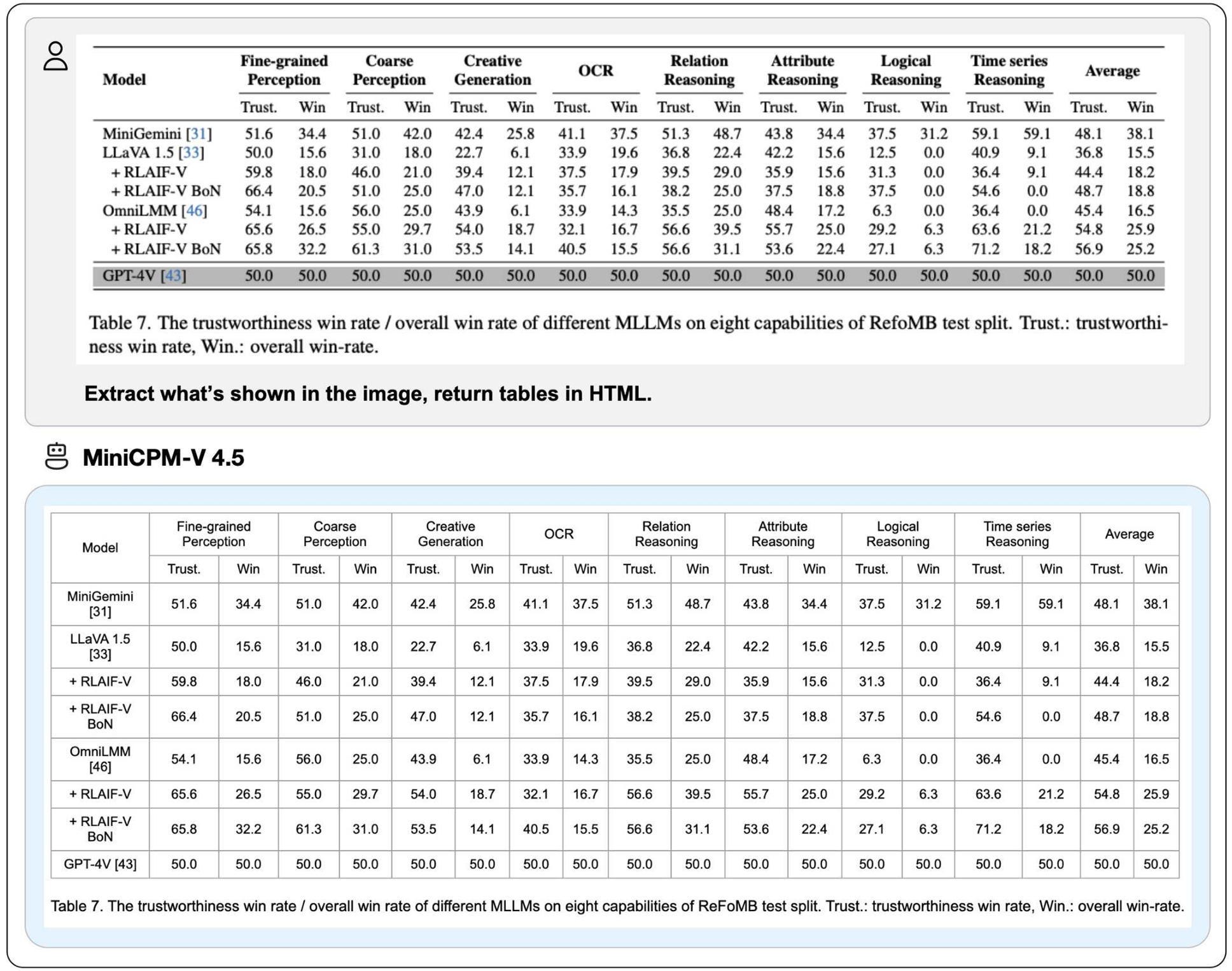
💪 强大的OCR、文档解析等功能。 基于LLaVA-UHD架构,MiniCPM-V 4.5可以处理任何宽高比并高达180万像素(例如1344x1344)的高分辨率图像,使用的视觉令牌数量比大多数MLLM少4倍。该模型在OCRBench上的表现领先,超越了GPT-4o-latest和Gemini 2.5等专有模型 。它还在OmniDocBench上实现了通用MLLM中PDF文档解析能力的最佳表现。基于最新的RLAIF-V和VisCPM技术,它表现出可信的行为 ,在MMHal-Bench上优于GPT-4o-latest,并支持超过30种语言的多语言能力。
-
💫 易于使用。 MiniCPM-V 4.5可以通过多种方式轻松使用:(1) llama.cpp 和 ollama 支持本地设备上的高效CPU推理,(2) int4, GGUF 和 AWQ 格式的量化模型提供16种大小选择,(3) SGLang 和 vLLM 支持高吞吐量和内存高效的推理,(4) 使用 Transformers 和 LLaMA-Factory 进行新领域和任务的微调,(5) 快速 本地WebUI演示,(6) 针对iPhone和iPad优化的 本地iOS应用程序,以及 (7) 在 服务器 上的在线Web演示。请参阅我们的Cookbook获取完整使用说明!
关键技术
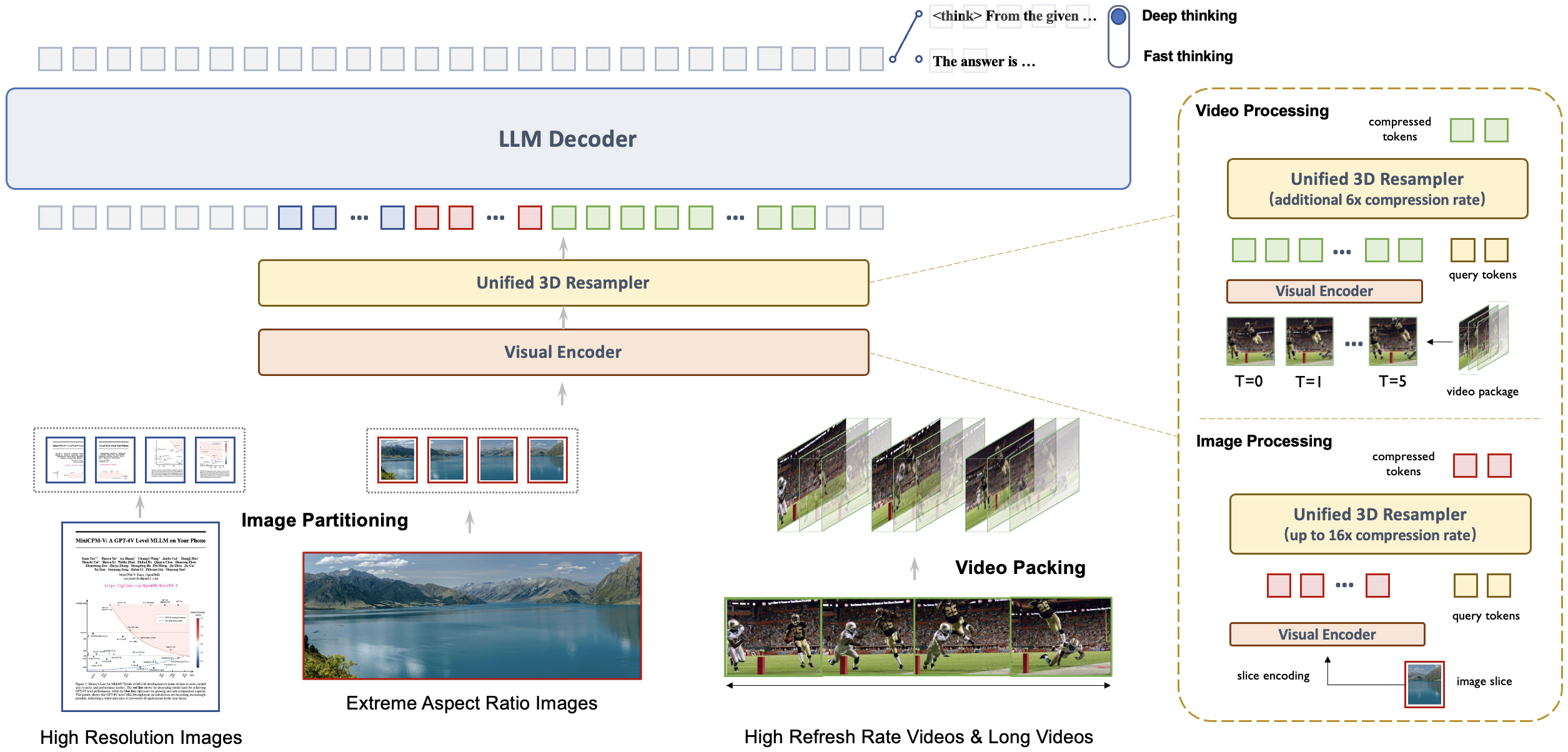
-
架构:统一的3D重采样器用于高密度视频压缩。 MiniCPM-V 4.5 引入了一种3D重采样器,克服了视频理解中的性能与效率之间的权衡。通过将多达6个连续的视频帧分组并联合压缩成仅64个token(与MiniCPM-V系列中单个图像使用的token数量相同),MiniCPM-V 4.5实现了96倍的视频token压缩率。这使得模型可以在不增加LLM计算成本的情况下处理更多的视频帧,从而实现高FPS视频和长视频理解。该架构支持图像、多图像输入和视频的统一编码,确保无缝的能力和知识转移。
-
预训练:OCR能力和文档知识的统一学习。 现有的多模态大语言模型在孤立的训练方法中学习OCR能力和文档知识。我们观察到这两种训练方法之间本质的区别在于图像中文本的可见性。通过以不同的噪声级别动态破坏文档中的文本区域,并要求模型重建文本,模型学会了在准确文本识别(当文本可见时)和基于多模态上下文的知识推理(当文本被严重遮挡时)之间自适应且恰当地切换。这消除了从文档中学习知识时对易出错的文档解析器的依赖,并防止了过度增强的OCR数据导致的幻觉,从而以最小的工程开销达到顶级的OCR和多模态知识性能。
-
后训练:结合多模态RL的混合快速/深度思考。 MiniCPM-V 4.5通过两种可切换模式提供了平衡的推理体验:日常使用中的快速思考模式以及处理复杂任务的深度思考模式。采用一种新的混合强化学习方法,模型同时优化这两种模式,显著提升了快速模式下的性能而不牺牲深度模式的能力。结合RLPR 和 RLAIF-V,它从广泛的多模态数据中概括出强大的推理技能,同时有效减少幻觉现象。
评估
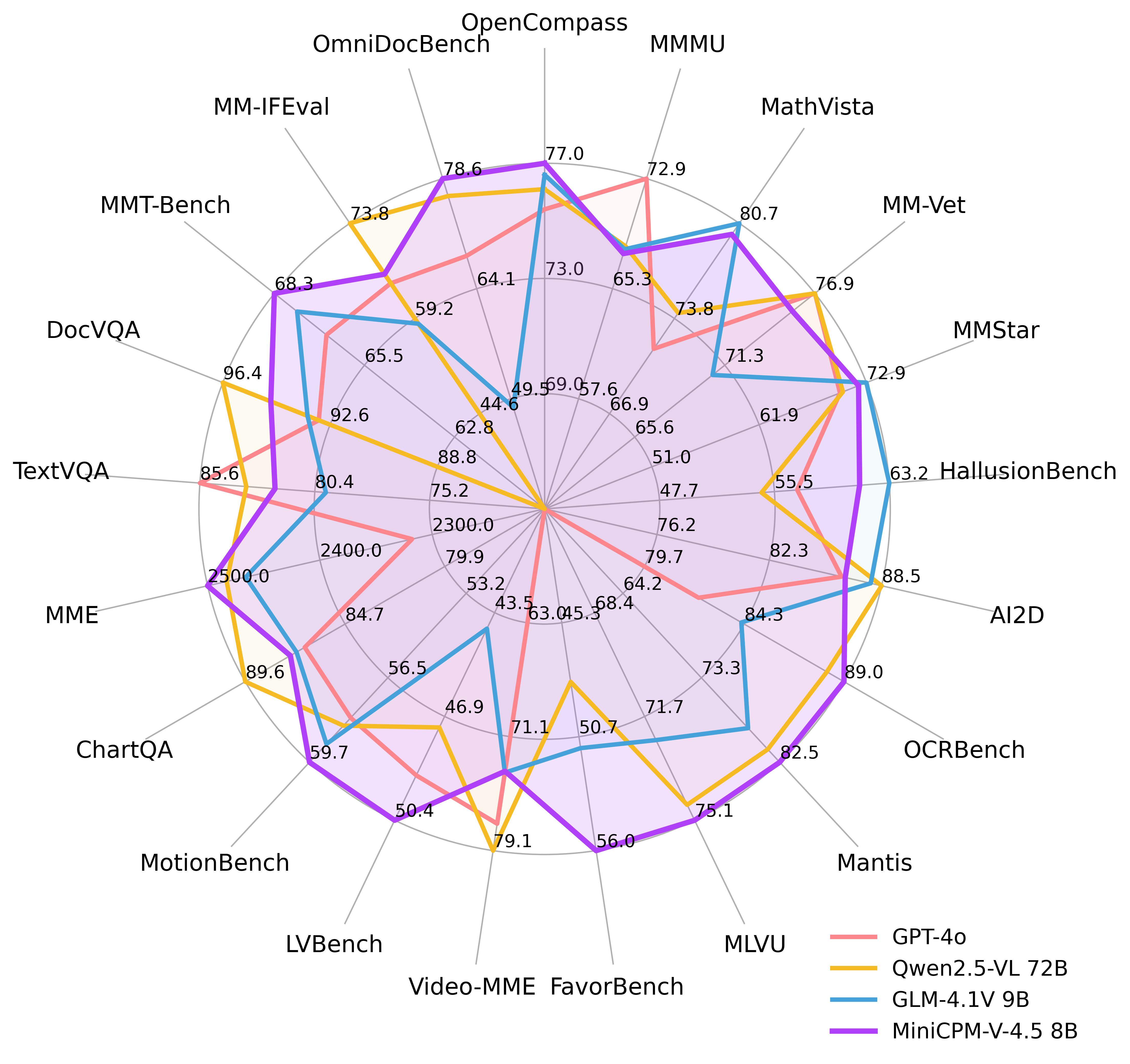
推理效率
OpenCompass
| 模型 | 大小 | 平均得分 ↑ | 总推理时间 ↓ |
|---|---|---|---|
| GLM-4.1V-9B-Thinking | 10.3B | 76.6 | 17.5h |
| MiMo-VL-7B-RL | 8.3B | 76.4 | 11h |
| MiniCPM-V 4.5 | 8.7B | 77.0 | 7.5h |
Video-MME
| 模型 | 大小 | 平均得分 ↑ | 总推理时间 ↓ | GPU内存 ↓ |
|---|---|---|---|---|
| Qwen2.5-VL-7B-Instruct | 8.3B | 71.6 | 3h | 60G |
| GLM-4.1V-9B-Thinking | 10.3B | 73.6 | 2.63h | 32G |
| MiniCPM-V 4.5 | 8.7B | 73.5 | 0.26h | 28G |
Video-MME 和 OpenCompass 的评估均使用了8块A100 GPU进行推理。Video-MME报告的推理时间包括了完整的模型端计算,但排除了视频帧提取的外部成本(具体取决于特定的帧提取工具),以确保公平比较。
示例



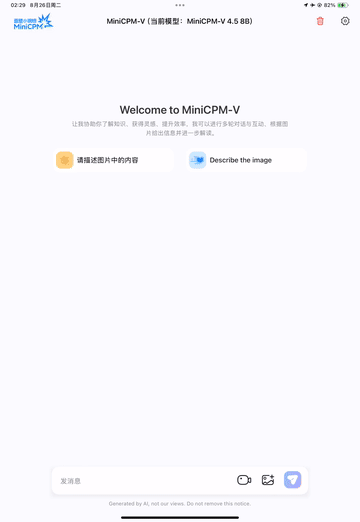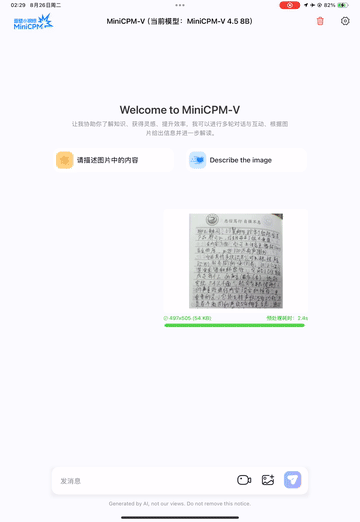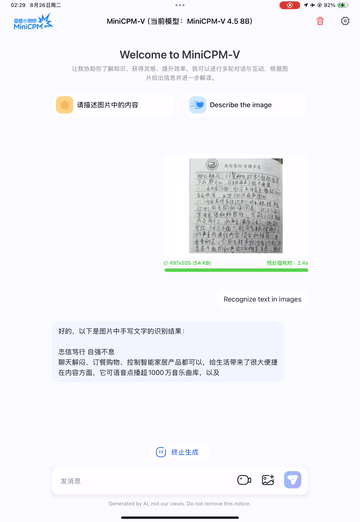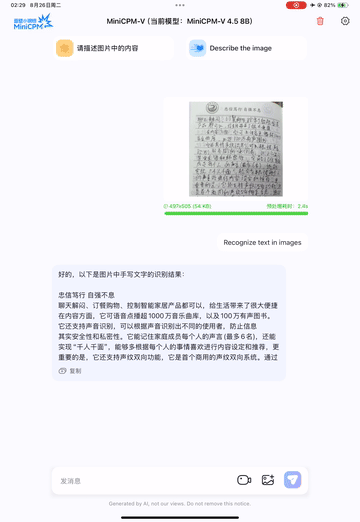
我们在iPad M4上部署了MiniCPM-V 4.5,使用iOS演示。演示视频是未经编辑的原始屏幕录制。
框架支持矩阵
| 类别 | 框架 | 指南链接 | 上游PR | 支持自(分支) | 支持自(发布) |
|---|---|---|---|---|---|
| 边缘(设备端) | Llama.cpp | Llama.cpp 文档 | #15575(2025-08-26) | master(2025-08-26) | b6282 |
| 边缘(设备端) | Ollama | Ollama 文档 | #12078(2025-08-26) | 合并中 | 等待官方发布 |
| 服务(云端) | vLLM | vLLM 文档 | #23586(2025-08-26) | main(2025-08-27) | v0.10.2 |
| 服务(云端) | SGLang | SGLang 文档 | #9610(2025-08-26) | 合并中 | 等待官方发布 |
| 微调 | LLaMA-Factory | LLaMA-Factory 文档 | #9022(2025-08-26) | main(2025-08-26) | 等待官方发布 |
| 量化 | GGUF | GGUF 文档 | --- | --- | --- |
| 量化 | BNB | BNB 文档 | --- | --- | --- |
| 量化 | AWQ | AWQ 文档 | --- | --- | --- |
| 演示 | Gradio 演示 | Gradio 演示文档 | --- | --- | --- |
注意:如果您希望我们优先支持另一个开源框架,请通过此简短表单告诉我们。
=======================================================================
下面为调用主要代码,单张照片分析时间1-2秒:
=== 全局配置参数(统一管理,方便后续修改)===
MODEL_ID = "/home/demo/.cache/modelscope/hub/models/OpenBMB/MiniCPM-V-2_6"
IMAGE_FOLDER = "images/imgs"
IMG_EXTENSIONS = {".jpg", ".jpeg", ".png", ".JPG", ".JPEG", ".PNG", ".bmp", ".BMP", ".gif", ".GIF"}
=== 加载模型 量化 ===
print("正在加载模型...")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True)
model = AutoModel.from_pretrained(
MODEL_ID,
trust_remote_code=True,
device_map="cuda",
quantization_config=quantization_config
)
model.eval()
print("模型加载完成。")
=== 分析单张图片 ===
def analyze_image(image_path: Path) -> dict:
try:
image = Image.open(image_path).convert("RGB")
提示词强化:强制模型输出具体描述(禁止无意义表述)
issue_types_str = "、".join(VALID_ISSUE_TYPES)
locations_str = "、".join(VALID_LOCATIONS:-1) + "、" + VALID_LOCATIONS-1
question = f"""必须输出JSON格式字符串,不得添加任何额外文字!
判断图中是否存在以下城市管理问题(仅可选):{issue_types_str}
JSON字段要求:
{{
"has_issue": true,
"issue_type": "XXX、XXX", // 仅从上述列表选择(可多选)
"location": "XXX", // 仅可选:{locations_str}
"description": "XXX", // 必须具体描述问题(例:左侧有摊贩占道经营,影响通行),80字内,不含地址/时间/GPS,禁止写无意义表述
"capture_time": "XXX", // 无则填"未识别"
"address": "XXX", // 无则填"未识别"
"GPS": "XXX" // 无则填"未识别"
}}
若不存在问题,仅输出JSON:{{"has_issue": false, "description": "无问题"}}
"""
msgs = {"role": "user", "content": question}
start_time = time.time()
raw_response = model.chat(
image=image,
msgs=msgs,
tokenizer=tokenizer
)
end_time = time.time()
torch.cuda.empty_cache()
analysis_time = round(end_time - start_time, 2)