MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
动机
多模态指令数据进化 框架。该框架通过对精细化感知、认知推理和交互进化的有机结合进行迭代优化,从而生成更加复杂、多样的图文指令数据集,并显著提升 MLLM 的能力。
目前的困境:
- 以改网络结构为主的"模型驱动"方法边际收益递减,难以再明显提升智能水平。
- 现有"数据驱动"方法虽然放大了图文指令数据规模,但指令 多样性不足、复杂度不够、对齐粒度偏粗 :
- 任务形式单一,泛化到真实场景能力弱;
- 缺少多步视觉推理,难以应对复杂任务;
- 多关注常见大物体,忽略小物体和细节,容易产生幻觉。
- 高质量、复杂且多样的图文指令数据稀缺,是当前 MLLM 发展的核心瓶颈。
改进方向(MMEvol):
- 转向更高效的"数据进化"思路,而非继续堆结构或数据量。
- 提出 MMEvol 框架,利用强 MLLM 自动迭代进化指令数据,从三个方向提升数据质量:
- 细粒度感知进化:强化对图像细节、小物体的刻画;
- 认知推理进化:拉长多步推理链,增强复杂任务处理能力;
- 交互进化:丰富指令表达形式,提高任务多样性。
- 通过"进化 + 筛除"的循环,在较小数据规模下构建 高质量、高复杂度、多样化 的图文指令集,从而显著提升 MLLM 在多种视觉-语言任务上的表现。
3 Method
3.1 Seed Data Curation
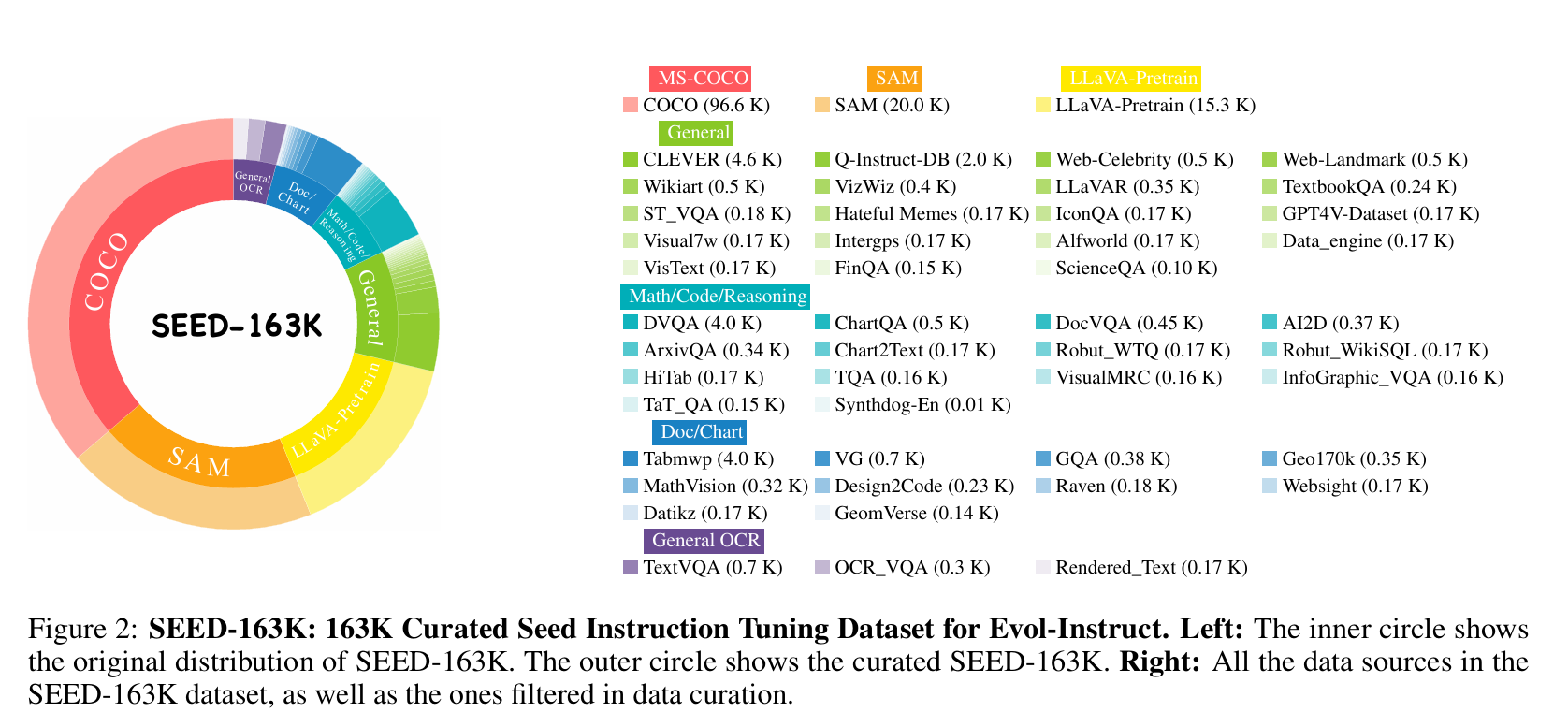
种子指令数据主要来源于 LLaVA-Instruct 和 ShareGPT4V ,并补充了从 Cambrain-1 中采样的科学类与图表类数据。整个过程对数据进行了精细筛选与清洗,以确保较高的数据质量和多样性。
对于仅包含图像描述(caption-only)的样本,我们使用 OpenAI GPT-4o mini API 生成结构化的指令数据。经过数据合并与过滤之后,最终得到一个包含 163K 条指令样本的综合数据集,其中每条指令都与一张独立图像配对。该数据集作为我们 Evol-Instruct 框架的基础。
LLaVA-Instruct 是一个基于 COCO 数据集,并使用 OpenAI ChatGPT API 生成的图文指令数据集。该数据集中的图文指令格式主要包括三类:对话式问答、整体性描述以及复杂推理。
另一方面,ShareGPT4V 则是基于 SAM 、COCO 等数据源的图文对,通过 OpenAI GPT-4V API 构建或改写而成,以在图像描述中引入更丰富的细节。LLaVA-Instruct 和 ShareGPT4V 都在推动 MLLM 的发展方面发挥了重要作用 ,并被广泛使用。
我们首先整合了这两个数据集中包含指令数据列表的样本;对于仅有整体描述但缺少指令数据的样本,则借助 GPT-4o-mini API 生成补全指令,方式与 LLaVA-Instruct 类似,最终得到一个规模为 133K 的组合数据集。为进一步保证种子数据的多样性,我们还额外引入了科学图表相关数据:具体而言,从 Cambrain-1 中采样了 30K 条数据,涵盖代码生成、图表解读、科学问答、文档理解和数学推理等多种图文指令类型。最终,我们构建了规模为 163K 的种子图文指令数据集。
3.2 Methodological Details
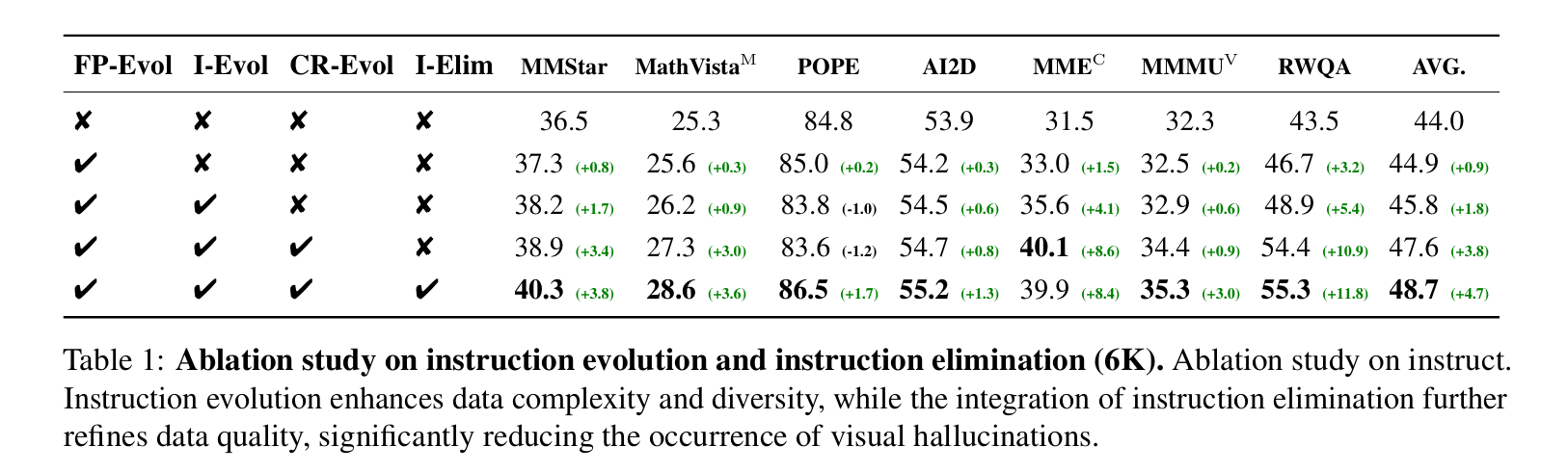
图文指令数据的进化天然受到视觉信息的约束,进化后的指令必须与图像内容保持高度对齐,以避免产生幻觉。这使得图文指令的数据多样性进化变得尤为困难:模型在尝试引入有意义变化时,很容易偏离以图像为依据的内容。此外,当提升指令数据的复杂度时,又常常会出现"浅层推理"现象,即 MLLM 无法给出深入、结构化的回答。
如图 1 所示,我们通过设计一个结构化的进化框架来应对这些挑战,该框架引入了四个关键域:视觉对象域、原子能力域、视觉操作域和指令格式域。这些域对指令数据进行标准化约束,保证进化过程中的数据质量与多样性。
其中,视觉对象域显式包含图像中出现的物体,将指令的进化限制在与图像相关的内容上,从而减少幻觉。我们进一步定义了原子能力域,用九种图文推理所需的关键能力进行刻画,包括五种以视觉为中心的能力------定位、指代、计算、光学字符识别(OCR)和存在性判断,以及四种以语言为中心的能力------关系描述、场景理解、行为预测和世界知识关联。原子能力域提升了数据在能力维度上的多样性,使模型能够处理更广泛的多模态任务。
为缓解浅层推理问题,我们引入视觉操作域,将问题求解组织为多步的视觉操作链,每一步都显式对应某种视觉原子能力,从而保证视觉推理过程具有结构性和可解释性。最后,指令格式域则定义了多种交互形式,使模型能够应对多样化的任务表达方式。上述设计共同提升了图文指令数据的多样性与复杂度,从而增强了指令进化整体的有效性。
细粒度感知进化(Fine-grained Perceptual Evolution)。
细粒度感知进化的目标,是最大化从图像中提取细致的视觉信息,尤其关注那些常被忽略的、非主要视觉对象。在现有数据集中,大多数指令都围绕显著目标展开,而出现频率较低的长尾对象往往被忽视。缺乏这类多样性会削弱模型的泛化能力,当模型遇到不常见的视觉元素时,更容易产生幻觉并降低鲁棒性。
为解决这一问题,细粒度感知进化通过生成引入新视觉对象的指令,来拓展数据集中对罕见和欠代表元素的覆盖范围。通过挖掘那些此前被忽略但具有视觉意义的信息,该方法同时增强了视觉对齐能力与模型的鲁棒性。其进化提示模板与具体流程示意如图 3 所示。

认知推理进化(Cognitive Reasoning Evolution)。
推理能力是多模态大语言模型(MLLM)的基础能力之一。然而,现有的指令数据集(如 LLaVA-Instruct(Liu et al., 2024b))大多由简单的问答对构成,缺乏详细的推理过程描述。这限制了模型在处理复杂推理任务(如多模态智能体交互和视觉推理)时的能力。
为此,我们提出了**视觉操作链(visual manipulation chain)**的概念,将四种以视觉为中心的推理能力抽象为结构化的视觉操作。这些以文本形式描述的操作函数,为多模态任务中的"逐步推理"提供了一套结构化流程。通过显式地生成并融入多步视觉推理过程,我们构建了一种可扩展的指令复杂度定义框架。
在认知推理进化过程中,我们通过不断加深视觉推理步骤的层数,迭代式地增强指令数据的复杂度,从而生成更加复杂、细腻的指令。这一进化过程使 MLLMs 能够形成对视觉概念和推理模式的更丰富理解。其进化提示模板与具体流程如图 4 所示。

交互进化(Interactive Evolution)。
现有多数模型仅支持少数几种预定义的指令形式。例如,LLaVA-Instruct 主要包含对话式问答、复杂推理和全局描述等任务形式。类似地,手工构建的数据集(如 ALLaVA(Chen et al., 2024a))也受到标注者专业能力的限制,指令格式的类型较为单一,难以设计出多样化的任务结构。基于这类有限指令形式训练出来的模型,往往难以很好地遵循复杂、多变的用户指令,从而削弱了其在真实多模态交互场景中的实用性。
为克服这一局限,我们提出了交互进化方法,自动生成多种多样的指令形式,从而丰富 MLLMs 的交互体验范围。该方法确保模型能够在更广谱的指令格式上进行训练,从而提升其处理真实世界多模态查询的能力。其进化提示模板与具体流程如图 5 所示。

指令筛除(Instruction Elimination)。
在每一轮进化之后,我们都会从多个维度对进化得到的指令数据进行评估,以衡量本轮进化是否有效。那些在质量或表现上体现出"进化收益"的指令会被保留,而未达到预期改进效果的指令则会被丢弃。通过这种选择性保留机制,可以确保只有高质量、经过精炼的指令数据被用于训练 MLLMs。相应的指令筛除提示模板及其流程示意如图 6 所示。

4 Experiments
1. 基准与评测设置
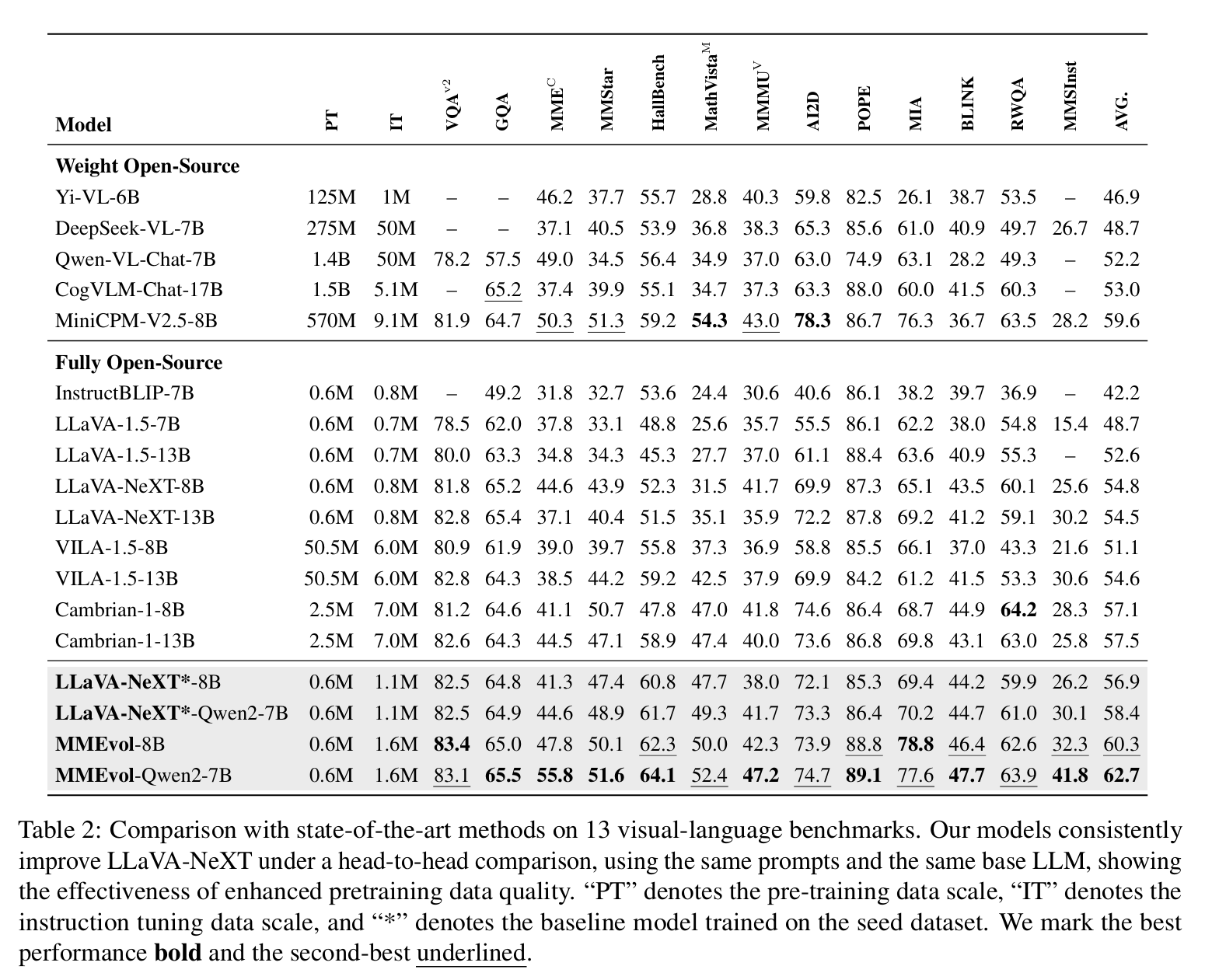
- 一共选用了 13 个视觉-语言基准任务,其来源与评测能力在表 11 中列出。
- 除了传统视觉-语言任务,还加入了一些更"前沿"的评测,用来更全面检验进化数据的质量,代表性例子包括:
- MIA(Qian et al., 2024):开放域指令跟随 benchmark,用于严格评估模型对多样化指令的遵从能力。
- MM-SelfInstruct(Zhang et al., 2024b):视觉推理 benchmark,重点考察模型在真实场景中常见视觉推理任务上的视觉感知与推理能力。
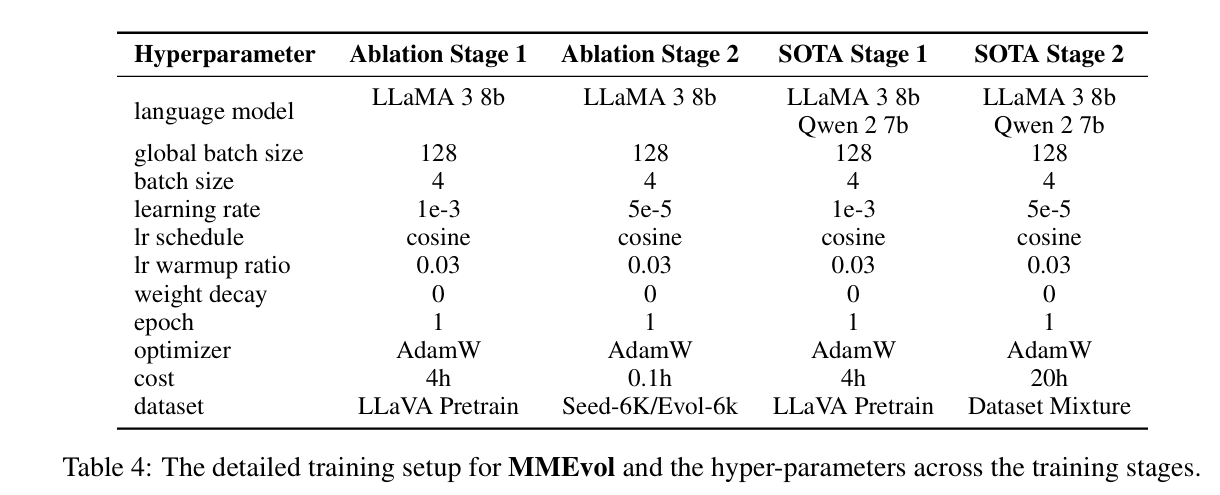
2. 实现与训练细节
2.1 数据设置
- 预训练阶段 :使用 LLaVA-Pretrain 595K(Liu et al., 2024b)进行图文对齐训练。
- 消融实验 :
- 分别在 种子数据 与 进化后数据(MMEvol 生成) 上独立微调模型,
- 以此直接对比是否使用进化数据带来的性能提升。
- SOTA 对比实验 :
- 使用进化后的指令数据 + 其他公开数据集(包含 Cambrain-1(Tong et al., 2024)中的样本)进行微调,
- 将结果与现有最新方法进行比较。
- 更细的数据配置在附录 C 中补充说明。
2.2 模型架构
- 采用 LLaVA-NeXT 架构,整体由三部分组成:
- LLM:用于下一 token 预测;
- 视觉编码器:提取视觉特征;
- 图文投射器(image-text projector):对齐视觉与文本模态。
- 具体用到的语言模型配置:
- 消融实验:Llama3-8B-Instruct;
- 与其他方法对比:沿用作者此前的 SOTA 设置,使用 Llama3-8B-Instruct 与 Qwen2-7B-Instruct。
- 视觉编码器:采用 CLIP-ViT-L (Radford et al., 2021),
- 通过简单线性层作为图像模态与文本模态之间的映射"桥梁"。
2.3 训练策略
-
整体遵循主流的 两阶段训练范式:
- Vision-Language Pre-training(视觉-语言预训练)
- Visual Instruction Tuning(视觉指令微调)
-
训练细节:
- LLM 和 ViT:分别预训练;
- Projector:随机初始化;
- 初始对齐:先用预对齐数据集进行图文特征对齐;
- 之后再用视觉-语言指令数据集做指令微调。
-
硬件与优化配置:
- 设备:8 × A100 GPU
- global batch size:128
- 优化器:AdamW
- 学习率:
- 预训练阶段:5 × 10⁻⁵
- 指令微调阶段:2 × 10⁻⁵
- 每个阶段训练 1 个 epoch ,并使用 3% warm-up 策略。
-
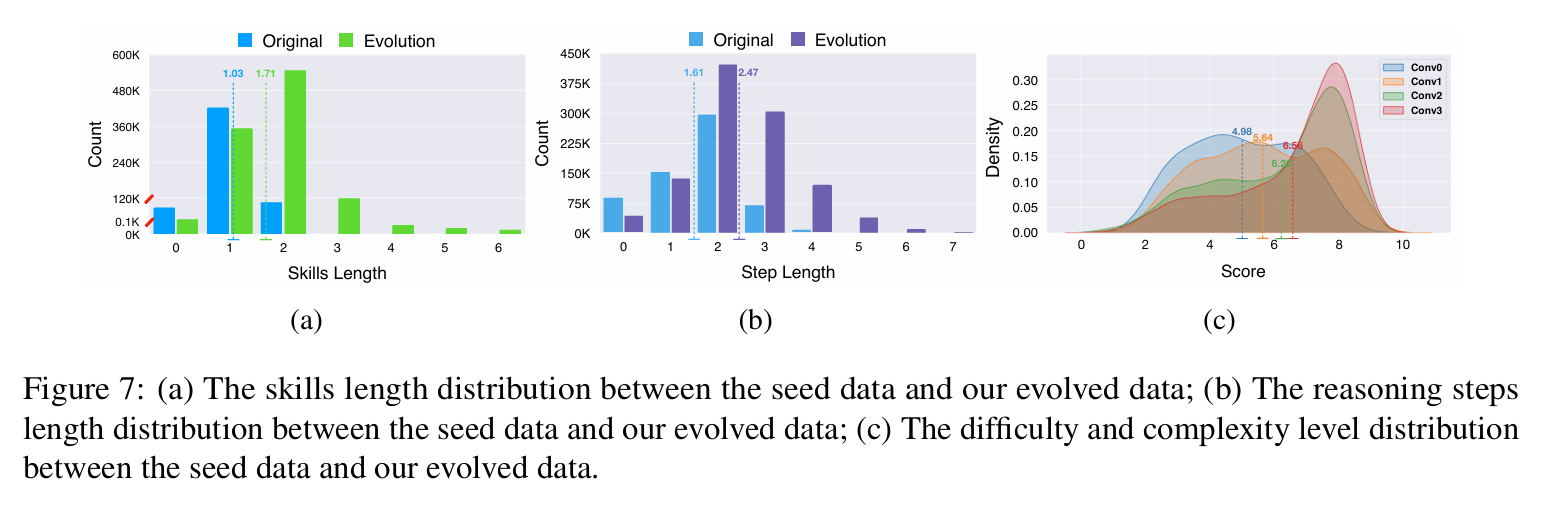
经过三轮进化与筛选,我们共获得了 447K 条兼具多样性与复杂度的高质量图文指令数据 。这些数据与 ALLaVA 指令数据集合并后,构成训练配方中规模为 600K 的指令数据部分。
为确保与其他方法的公平对比,我们将这些指令数据与其他常用的图文数据一起组合,形成最终的训练配方,如表 3 所示。需要指出的是,我们发现 DataEngine(Tong et al., 2024)中的数据包含大量有害或图文不匹配的样本,因此我们使用 OpenAI GPT-4o API 对其进行过滤,最终保留了 20K 条有效的图文指令数据。