1、Solr 分布式查询协调节点(Coordinator Node)
介绍
协调节点(Coordinator Node)是 SolrCloud 分布式架构的核心枢纽,专门负责接收客户端查询请求、拆解请求到多个分片、聚合分片结果并返回最终响应,是分布式查询的 "大脑"。
1. 核心定义
协调节点本身不强制存储业务数据(生产环境建议仅作为调度节点,不承载数据),其核心价值是对分布式查询的全生命周期管理:从请求接入到结果聚合,屏蔽底层分片的分布式特性,让客户端感知不到多分片的存在。
2. 核心职责
| 职责项 | 具体说明 |
|---|---|
| 请求接收 | 监听 HTTP/HTTPS/SolrJ 等客户端请求,兼容 Solr 标准查询语法(q、fq、facet、sort 等) |
| 分片路由 | 从 ZooKeeper 获取集合(Collection)的元数据(分片列表、路由规则),确定需查询的分片 |
| 并行查询分发 | 将子查询并行发送到目标分片的 Leader/Replica(可配置优先查副本,减轻 Leader 压力) |
| 结果聚合 | 处理全局排序、分页、facet 统计、分组(group)、高亮等,解决分布式边界问题(如分页去重) |
| 容错与重试 | 分片节点超时 / 失败时,自动重试该分片的其他副本;分片不可用时可配置返回部分结果或抛错 |
| 响应格式化 | 将聚合后的结果转为 JSON/XML 等格式返回给客户端 |
3. 分布式查询完整工作流程
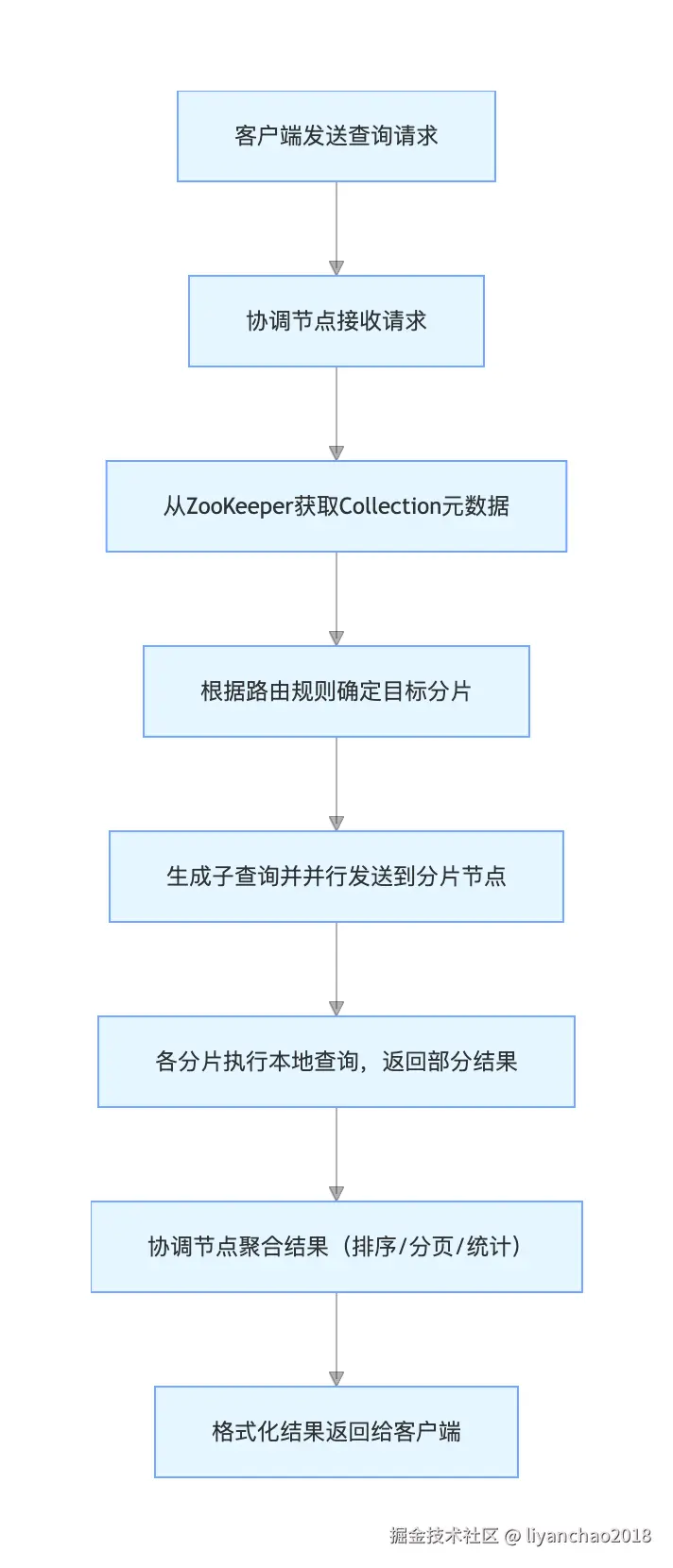
关键细节:
- 聚合阶段是性能核心:深分页(start/rows 大)会导致协调节点需拉取所有分片的大量数据,建议用 Cursor 替代;
- 分片选择逻辑:默认优先查 Replica,可通过
shard.preference=leader强制查 Leader。
4. 配置与优化
(1)专用协调节点配置(生产推荐)
SolrCloud 中所有节点默认都可作为协调节点,若需专用协调节点(仅调度、不存数据),需:
1.修改 solr.xml,关闭该节点的分片加载:
xml
<solrcloud>
<shardHandlerFactory name="shardHandlerFactory" class="HttpShardHandlerFactory">
<int name="socketTimeout">60000</int>
<int name="connTimeout">5000</int>
</shardHandlerFactory>
<!-- 禁止该节点承载分片 -->
<bool name="enableShardHandler">true</bool>
<bool name="joinCluster">true</bool>
</solrcloud>- 该节点不分配任何 Collection 的分片(创建 Collection 时指定数据节点)。
(2)性能优化要点
- 开启分片级缓存(filterCache、queryResultCache),减少重复计算;
- 控制并行分片数(通过
shards.max参数),避免协调节点线程耗尽; - 聚合密集型场景(如 facet),增加协调节点的内存(建议 8G+);
- 避免深分页:用
cursorMark替代start/rows,降低聚合压力。
5. 协调节点与其他节点的区别
| 节点类型 | 核心功能 | 是否存储数据 | 资源侧重 |
|---|---|---|---|
| 协调节点 | 查询调度、结果聚合 | 建议否 | CPU / 内存(聚合) |
| 分片 Leader | 写请求处理、副本同步 | 是 | 磁盘 / 网络(同步) |
| 分片 Replica | 读请求分担、容灾 | 是 | CPU / 磁盘(查询) |
二、SolrCloud 的核心模式(含路由模式)及适用场景
SolrCloud 的 "模式" 核心分为路由模式 (文档分片规则)和部署模式(节点 / 分片部署策略),其中路由模式是分布式设计的核心。
1. 核心路由模式(文档分片规则)
路由模式决定文档被分配到哪个分片,直接影响查询性能和数据分布。
(1)哈希路由(隐式路由,默认)
-
逻辑:基于
uniqueKey字段的 MD5 哈希值对分片数取模,公式:shard_id = hash(uniqueKey) % num_shards; -
配置方式(创建 Collection):
bash# 无需指定router.name,默认compositeId(底层哈希) solr create -c my_col -n my_config -shards 3 -replicationFactor 2 -
特性:数据分布均匀、运维简单、分片数固定(扩缩容需拆分分片);
-
适用场景:✅ 无明确业务分区规则(如通用全文检索、电商商品库);✅ 读 / 写请求均匀,无热点分片;❌ 需按业务维度(如地区)查询特定分片(需全分片扫描,性能低)。
(2)复合 ID 路由(显式路由)
-
逻辑:
uniqueKey采用路由键!文档ID格式(如region_01!10001),Solr 仅对 "路由键" 哈希路由,可将同路由键的文档集中到同一分片; -
配置方式:
bashsolr create -c my_col -n my_config -shards 3 -router.name compositeId # 显式指定复合ID路由 -
文档写入示例:
json{ "id": "region_01!10001", // 路由键=region_01,文档ID=10001 "title": "北京订单", "region": "region_01" } -
特性:可按业务维度定向查询分片(如查北京订单仅查 region_01 对应的分片)、数据分布可控;
-
适用场景:✅ 有明确业务分区(地区、时间、用户组);✅ 大部分查询仅针对特定分区(如按地区查订单、按时间查日志);❌ 路由键设计不当易导致热点分片(如某地区数据量远大于其他)。
(3)自定义路由
-
逻辑:实现
SolrCloudRouter接口,自定义路由规则(如多字段组合、业务优先级路由); -
配置方式:
-
开发自定义路由类(实现
SolrCloudRouter),打包放入 Solrlib目录; -
创建 Collection 时指定:
bashsolr create -c my_col -n my_config -shards 4 -router.name com.mycompany.MyCustomRouter
-
-
特性:高度灵活、适配复杂业务规则;
-
适用场景:✅ 业务规则复杂(如基于地区 + 时间组合路由、按文档类型路由);✅ 海量数据且分片规则需动态调整;❌ 开发 / 维护成本高,需充分测试。
(4)单分片路由
- 逻辑:Collection 仅 1 个分片,所有文档路由到该分片(哈希路由的特例);
- 配置方式:
solr create -c my_col -shards 1; - 特性:无分布式聚合开销、查询性能最高;
- 适用场景:✅ 数据量小(百万级以内)、查询响应要求极高(如小型网站站内搜索);✅ 测试环境、临时数据存储。
2. 其他关键模式(部署 / 扩展)
(1)静态分片模式
- 逻辑:分片数创建时固定,扩缩容需手动执行
splitshard(拆分分片)或createshard; - 适用场景:数据增长可预测(如常规业务系统),运维成本低。
(2)动态分片模式
- 逻辑:基于自定义路由 / 第三方工具,根据数据量 / 业务规则自动创建分片;
- 适用场景:数据爆发式增长(如日志采集、物联网数据),需自动扩缩容。
(3)对等副本模式(Solr 8.0+)
- 逻辑:基于 Raft 协议,无 Leader/Replica 区分,所有副本平等处理读写;
- 特性:更高可用性(无 Leader 单点)、写请求可分发到任意副本;
- 适用场景:金融、核心业务系统等对可用性要求极高的场景。
三、总结
- 协调节点是 SolrCloud 分布式查询的核心,生产环境建议配置专用协调节点(不存数据)提升聚合性能;
- 路由模式选择核心:无业务分区用哈希路由 ,有业务分区用复合 ID 路由 ,复杂规则用自定义路由;
- 部署模式需结合数据增长、可用性要求:常规场景用静态分片,高可用场景用对等副本,海量数据用动态分片。