
1. 一段话总结
Wan 是阿里巴巴推出的开源大规模视频生成基础模型套件,基于扩散Transformer范式,通过创新的时空变分自动编码器(Wan-VAE) 、规模化预训练策略等核心技术,具备领先性能、全面性、消费级效率、开源性 四大关键特征:提供1.3B(仅需8.19GB VRAM,适配消费级GPU)和14B参数模型,覆盖文本到视频、图像到视频等8类下游任务,是首个支持中英双语视觉文本生成的模型,14B版本在多个基准测试中超越主流开源及商业模型(如Sora、HunyuanVideo),所有代码和模型已开源(https://github.com/Wan-Video/Wan2.1),旨在推动视频生成领域的技术创新与产业应用。

2. 思维导图(mindmap)
mindmap
## 🔹 模型概述
- 名称:Wan 视频生成模型
- 开发团队:Alibaba Group Wan Team
- 核心架构:扩散Transformer(DiT)+ 流匹配(Flow Matching)
- 开源地址:https://github.com/Wan-Video/Wan2.1
## 🔹 核心特点
- 领先性能:14B模型超越开源/商业模型
- 全面性:1.3B/14B双模型,8类下游任务
- 消费级效率:1.3B仅需8.19GB VRAM
- 开源性:开放源码+全模型
## 🔹 关键技术
- 数据处理:四步清洗、时空质量筛选、密集字幕生成
- 模型设计:Wan-VAE(4×8×8压缩)、2D上下文并行
- 训练策略:图像预训练→联合训练→微调,混合精度优化
- 推理优化:扩散缓存、FP8量化、8-bit FlashAttention
## 🔹 下游应用
- 基础任务:文本到视频、图像到视频
- 扩展任务:视频编辑、个性化生成、相机运动控制
- 创新任务:实时视频生成、音频同步生成
## 🔹 评估体系
- 自建基准:Wan-Bench(14个细粒度指标)
- 第三方基准:VBench(14B总分86.22%)
- 评估维度:动态质量、图像质量、指令遵循度
## 🔹 局限与展望
- 局限:大运动细节保真度、模型计算成本、领域适配性
- 展望:扩大数据/模型规模、优化效率、社区共建3. 详细总结
一、引言:模型背景与核心目标
- 背景:Sora等模型推动视频生成技术爆发,但开源模型存在性能、能力、效率三大差距
- 目标:推出高性能、多能力、高效率的开源视频基础模型,填补开源与商业模型鸿沟
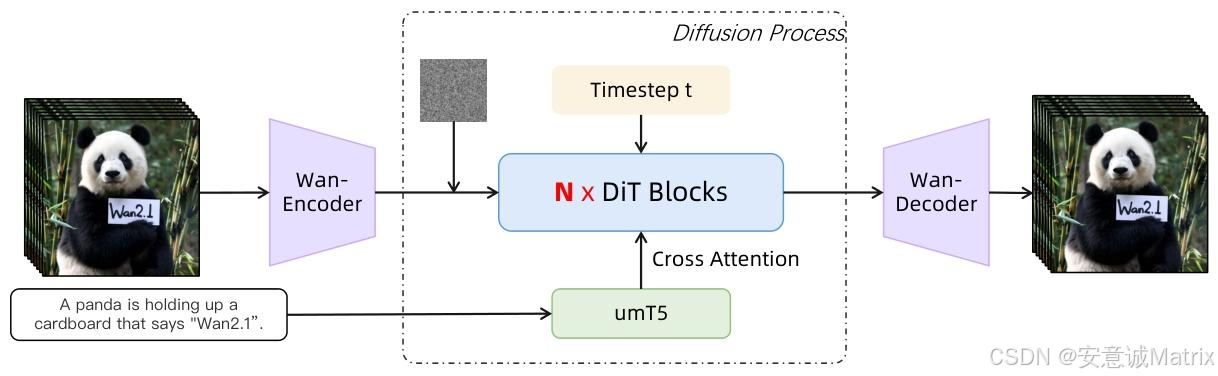
- 核心创新:融合Diffusion Transformers与Flow Matching,引入全时空注意力机制
二、核心特点与关键参数
| 模型版本 | 参数量 | 显存需求 | 核心优势 | 适用场景 |
|---|---|---|---|---|
| Wan 1.3B | 1.3B | 8.19GB | 高效率、低资源消耗,性能超多数大尺寸开源模型 | 消费级GPU、实时生成场景 |
| Wan 14B | 14B | - | 高性能,全面超越开源模型及主流商业模型 | 专业级视频生成、复杂任务 |
三、关键技术细节
3.1 数据处理管道
- 核心原则:高质量、高多样性、大规模(数十亿图像+视频,万亿级tokens)
- 预处理流程:四步清洗(基础维度筛选→视觉质量评估→运动质量分级→视觉文本处理)
- 后处理优化:图像精选(专家模型+人工筛选)、视频分类(简单/复杂运动,12大类别)
- 密集字幕生成:基于LLaVA架构,支持10类视觉维度描述,性能比肩Gemini 1.5 Pro
3.2 模型设计与优化
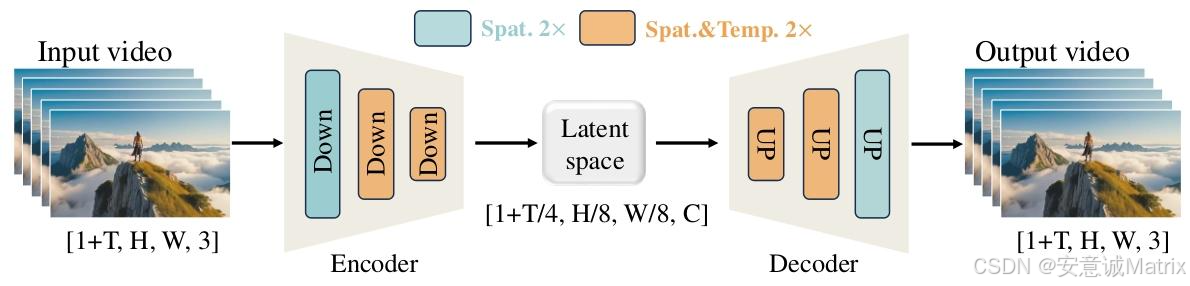
-
Wan-VAE:3D因果VAE,时空压缩比4×8×8,参数仅127M,重建速度比HunyuanVideo快2.5倍
-
训练策略:
- 图像预训练(256px文本到图像)
- 图像-视频联合训练(分三阶段:256px→480px→720px)
- 微调阶段(480px/720px分辨率,聚焦高质量数据)
-
并行与内存优化:2D上下文并行(Ulysses+Ring Attention)、激活卸载+梯度检查点,支持百万级token序列训练
3.3 推理优化技术
| 优化手段 | 效果提升 |
|---|---|
| 扩散缓存 | 推理性能提升1.62× |
| FP8量化 | DiT模块速度提升1.13× |
| 8-bit FlashAttention | 推理效率提升1.27× |
| 提示对齐(LLM重写) | 提升视频生成与指令匹配度 |
四、下游应用场景(8类核心任务)
- 文本到视频(T2V):支持大运动、高保真、多风格生成
- 图像到视频(I2V):基于参考图像生成动态序列,支持视频续播、帧转换
- 统一视频编辑:支持修复、扩展、深度控制等多任务,无需多模型部署
- 视频个性化:零样本身份保持,支持参考人脸生成定制视频
- 相机运动控制:支持平移、缩放、航拍等5类相机运动
- 实时视频生成:基于Streamer+LCM蒸馏,单4090 GPU达20 FPS
- 音频生成:视频到音频(V2A)同步,支持环境音+背景音乐
- 文本到图像(T2I):跨模态知识迁移,生成高保真图像
五、评估结果
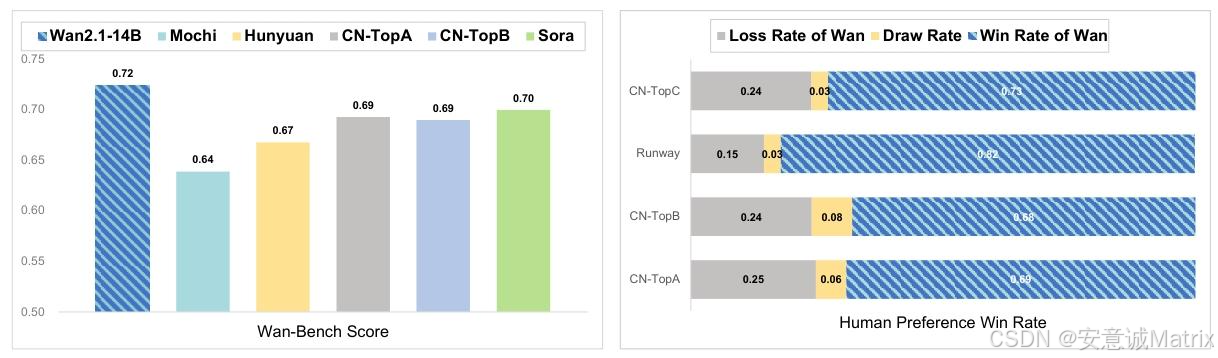
5.1 Wan-Bench 加权得分对比
| 模型 | 加权得分 | 核心优势维度 |
|---|---|---|
| Wan 14B | 0.724 | 物理合理性、空间位置精度 |
| Sora | 0.700 | 动态平滑度 |
| CN-TopA | 0.693 | 单目标准确性 |
| HunyuanVideo | 0.673 | 图像综合质量 |
5.2 VBench 性能排名(总分)
| 模型 | 总分 | 视觉质量得分 | 语义一致性得分 |
|---|---|---|---|
| Wan 14B | 86.22% | 86.67% | 84.44% |
| Sora | 84.28% | 85.51% | 79.35% |
| Wan 1.3B | 83.96% | 84.92% | 80.10% |
| HunyuanVideo | 83.24% | 85.09% | 75.82% |
六、局限与结论
- 局限:大运动场景细粒度细节保真度不足;14B模型推理成本较高(单GPU约30分钟);特定领域(教育、医疗)适配性有限
- 结论:Wan刷新视频生成基准,开源全模型及代码,未来将聚焦数据/模型规模化、效率优化及领域定制化
4. 关键问题
问题1:Wan模型的核心技术突破是什么,如何支撑其性能优势?
答案 :核心技术突破集中在三大方向:① 创新的Wan-VAE架构:3D因果设计,时空压缩比达4×8×8,参数仅127M,重建速度比主流方案快2.5倍,同时保证时序一致性;② 高效训练策略:采用"图像预训练→分阶段联合训练→微调"流程,结合2D上下文并行(Ulysses+Ring Attention)和激活卸载技术,支持14B参数模型的规模化训练;③ 精细化数据处理:四步清洗流程筛选高质量数据,密集字幕生成技术提升指令匹配度,中英双语视觉文本数据增强模型跨语言生成能力。这些技术共同支撑Wan在动态质量、图像保真度、指令遵循度上超越主流开源及商业模型。
问题2:Wan模型的1.3B和14B版本有何差异,分别适配什么场景?
答案:两者差异及适配场景如下表所示,核心差异体现在性能、资源需求和适用场景上:
| 维度 | Wan 1.3B | Wan 14B |
|---|---|---|
| 参数量 | 1.3B | 14B |
| 显存需求 | 8.19GB VRAM | 需专业级GPU(未明确标注,推理成本较高) |
| 性能表现 | 超越多数大尺寸开源模型,VBench总分83.96% | 超越Sora等商业模型,VBench总分86.22% |
| 核心优势 | 消费级效率,适配普通GPU | 顶尖性能,支持复杂任务 |
| 适配场景 | 个人创作、实时生成、轻量化部署 | 专业内容生产、企业级应用、科研创新 |
问题3:Wan模型的开源特性将对视频生成领域产生哪些影响?
答案:主要产生三大影响:① 降低技术门槛:开源1.3B和14B全模型及代码,让开发者无需从零构建,基于消费级GPU即可开展二次开发;② 推动社区创新:开放数据处理管道、训练策略、评估基准(Wan-Bench),为学术界提供高质量基础模型,加速视频生成技术迭代;③ 赋能产业应用:支持8类下游任务,覆盖内容创作、视频编辑、个性化生成等场景,帮助企业降低视频生产成本,拓展创意边界,尤其利好中小团队及创业公司。