词元(token)和嵌入(embedding)
想象一下,你是一个刚来到地球的外星人,完全不懂人类的语言和文字。你的任务是要理解《哈利·波特》这本书。
概念
词元
你首先会怎么做?你会把整本书拆成一个个最小的、你能识别的零件。
- 对于英文: 你可能把
"Harry Potter and the Sorcerer's Stone"拆成["Harry", "Potter", "and", "the", "Sorcerer", "'s", "Stone"]。 - 对于中文: 你可能把
"哈利·波特与魔法石"拆成["哈","利","·","波","特","与","魔","法","石"]。
在AI大模型中,这个最小的零件就是 「词元」 。它可能是一个词("Harry")、一个子词("ing")、一个标点(.),甚至是一个汉字("哈")。
词元的作用: 把人类能读懂的、千变万化的文本,数字化成一个模型能处理的、由固定ID组成的序列。就像乐高说明书把一座城堡,转换成了一系列标准积木的编号列表。
所以,词元是文本的"数字身份证号"。
嵌入
现在,你手里有一大堆写着数字(词元ID)的卡片,但你依然不理解故事。你需要知道:
"Harry"和"Potter"这两个词元为什么总是挨在一起?"魔法"和"咒语"这两个词元有什么内在联系?"爱"和"恨"这两个词元有什么对立关系?
这时,你需要一个神奇的词典 。这本词典不是告诉你一个词的定义,而是给每个词元分配一个独特的"灵魂坐标"。
这个坐标不是一个数字,而是一个高维向量 (比如由768个数字组成的一个列表)。我们把这个向量叫做 「嵌入」。
嵌入的魔力在于:
- 意义相近的词,坐标也相近。
"国王"和"君主"的嵌入向量,在高维空间里距离很近。"奔跑"和"冲刺"的嵌入向量也很近。
- 词的语义关系可以通过向量运算体现。
- 经典的例子:
"国王"的嵌入 -"男人"的嵌入 +"女人"的嵌入 ≈"女王"的嵌入。 "巴黎"-"法国"+"意大利"≈"罗马"。
- 经典的例子:
- 它包含了丰富的语义信息。
- 比如
"苹果"的嵌入,可能既包含了水果 的语义(靠近"香蕉"、"橙子"),也包含了科技公司的语义(靠近"iPhone"、"微软"),具体取决于上下文。
- 比如
所以,嵌入是词元的"灵魂向量"或"语义坐标",它让冷冰冰的数字ID有了丰富的含义和关系。
整体理解
让我们把整个过程串起来:
- 输入文本:
"一只聪明的猫" - 词元化: 模型有一个"拆解手册"(分词器),把这句话拆成最小的标准零件(词元),并查表找到它们的ID。比如:
["一", "只", "聪明", "的", "猫"]->[101, 102, 103, 104, 105]。 - 嵌入查找: 模型有一个"零件灵魂库"(嵌入矩阵)。它根据ID
[101, 102, 103, 104, 105],去库里取出对应的5个"灵魂向量"(嵌入)。此时,"猫"这个ID105,就变成了一个能代表"猫"的所有特性(哺乳动物、宠物、会喵叫、毛茸茸...)的向量。 - 模型理解: 模型的核心神经网络开始工作。它不再看原始的"猫"字,而是分析
"猫"这个嵌入向量 ,与"聪明"、"一只"这些向量的关系。它通过复杂的计算,理解了"这是一只具有高智力特征的猫科动物"。 - 生成输出: 当需要续写时,比如你问
"它做了什么?",模型会基于它理解的"聪明猫"的语义,计算出下一个最可能出现的词元嵌入,比如"抓老鼠"或"打开了门",然后再把嵌入转换回我们能读的词元ID,最终变成文字。
一句话总结:
- 词元是
文本 -> 数字ID的映射,解决"是什么"的问题。 (这是猫,ID是105)。 - 嵌入是
数字ID -> 语义向量的映射,解决"意味着什么、和谁有关"的问题。 (这个ID105代表一个毛茸茸、会喵喵叫、常作为宠物的哺乳动物,并且它和"狗"的向量在某些维度上接近,在另一些维度上远离)。
实现
安装
python
%%capture
!pip install --upgrade transformers==4.41.2 sentence-transformers==3.0.1 gensim==4.3.2 scikit-learn==1.5.0 accelerate==0.31.0 peft==0.11.1 scipy==1.10.1 numpy==1.26.4下载并运行一个大语言模型
第一步是将模型加载到 GPU 上以实现更快的推理。注意,我们分别加载模型和分词器,并保持这种分离状态,以便分别探索它们。此处的代码和上节一样
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct", # 加载微软的Phi-3小型指令调优模型(4K上下文)
device_map="cuda", # 自动将模型权重分配到GPU上
torch_dtype="auto", # 自动选择最佳的数据类型(如float16)以优化内存使用
trust_remote_code=False, # 出于安全考虑,不加载远程自定义代码
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct") # 加载对应的分词器调用
python
prompt = "Write a thank-you letter to Xiao Ming, thanking him for helping you with math tutoring over the weekend."
# 将输入提示转换为词元ID
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
# tokenizer将文本转换为模型能理解的数字序列
# return_tensors="pt"表示返回PyTorch张量
# .to("cuda")将张量移动到GPU上
# 生成文本
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=100 # 限制生成的新词元数量为100个
)
# 打印输出
print(tokenizer.decode(generation_output[0])) # 将生成的词元ID解码回可读文本生成结果:
Write a thank-you letter to Xiao Ming, thanking him for helping you with math tutoring over the weekend.
Answer
Dear Xiao Ming,
I hope this letter finds you well. I wanted to take a moment to express my heartfelt gratitude for the time and effort you dedicated to helping me with my math tutoring over the weekend. Your patience, clear explanations, and encouragement made a significant difference in my understanding of the subject.
Your ability to break down complex problems into manageable steps was incredibly helpful, and
探索词元化过程
python
print(input_ids)输出:
tensor([[14350, 263, 6452, 29899, 6293, 5497, 304, 1060, 29653, 341,
292, 29892, 6452, 292, 1075, 363, 19912, 366, 411, 5844,
260, 3406, 292, 975, 278, 4723, 355, 29889]],
device='cuda:0')
可以看到输入的提示被转换成了数字(词元ID)。让我们逐个解码查看:
python
for id in input_ids[0]:
print(tokenizer.decode(id))输出:
Write
a
thank
-
you
letter
to
X
iao
M
ing
,
thank
ing
him
for
helping
you
with
math
t
utor
ing
over
the
week
end
.关键观察:
"thanking"被拆分为"thank"和"ing"两个子词"tutoring"被拆分为"t"、"utor"、"ing""weekend"被拆分为"week"和"end"
检查生成输出的完整词元序列:
python
generation_output输出:
tensor([[14350, 263, 6452, 29899, 6293, 5497, 304, 1060, 29653, 341,
292, 29892, 6452, 292, 1075, 363, 19912, 366, 411, 5844,
260, 3406, 292, 975, 278, 4723, 355, 29889, 13, 13,
13, 29937, 673, 13, 13, 29928, 799, 1060, 29653, 341,
292, 29892, 13, 13, 29902, 4966, 445, 5497, 14061, 366,
1532, 29889, 306, 5131, 304, 2125, 263, 3256, 304, 4653,
590, 5192, 29888, 2152, 20715, 4279, 363, 278, 931, 322,
7225, 366, 16955, 304, 19912, 592, 411, 590, 5844, 260,
3406, 292, 975, 278, 4723, 355, 29889, 3575, 282, 24701,
29892, 2821, 7309, 800, 29892, 322, 18443, 882, 1754, 263,
7282, 4328, 297, 590, 8004, 310, 278, 4967, 29889, 13,
13, 10858, 11509, 304, 2867, 1623, 4280, 4828, 964, 10933,
519, 6576, 471, 29811, 14981, 8444, 29892, 322]],
device='cuda:0')
查看其中一些新生成的词元:
python
print(tokenizer.decode(13))
print(tokenizer.decode(29937))
print(tokenizer.decode(673))
print(tokenizer.decode(29928))
print(tokenizer.decode(799))
print(tokenizer.decode([29928,799]))输出 :

说明模型生成了"Dear:",其中"Subject"是由"Sub"(ID 29928)和"ject"(ID 799)两个词元组成的。
比较不同大语言模型的分词器
下面定义了六中颜色,为每个词元循环着色
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 定义颜色列表,用于可视化不同词元
colors_list = [
'102;194;165', '252;141;98', '141;160;203',
'231;138;195', '166;216;84', '255;217;47'
]
def show_tokens(sentence, tokenizer_name):
"""可视化显示句子如何被特定分词器切分"""
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
token_ids = tokenizer(sentence).input_ids
for idx, t in enumerate(token_ids):
# 使用ANSI转义码为每个词元着色
print(
f'\x1b[0;30;48;2;{colors_list[idx % len(colors_list)]}m' +
tokenizer.decode(t) +
'\x1b[0m',
end=' '
)测试文本包含多种元素:大小写、特殊字符、代码片段、数学表达式等:
python
text = """
English and CAPITALIZATION
🎵 鸟
show_tokens False None elif == >= else: two tabs:" " Three tabs: " "
12.0*50=600
"""1. BERT-base-uncased(不区分大小写):
python
show_tokens(text, "bert-base-uncased")输出结果
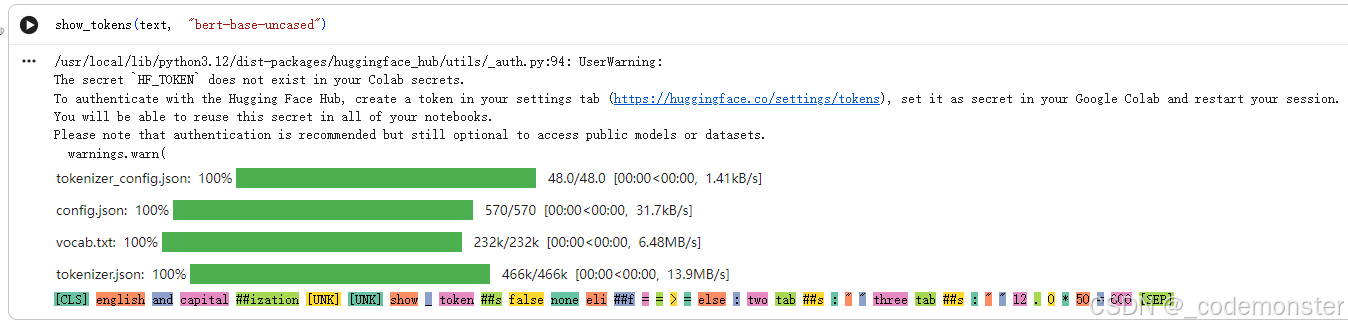
- 将所有字母转换为小写
- 使用WordPiece分词算法
"capitalization"被拆分为"capital"和##"ization"- 特殊符号
🎵和中文鸟被标记为[UNK](未知词元)
2. BERT-base-cased(区分大小写):
python
show_tokens(text, "bert-base-cased")输出

- 保持原始大小写
"CAPITALIZATION"被拆分为多个子词:"CA"、##"PI"、##"TA"、##"L"、##"I"、##"Z"、##"AT"、##"ION"
3. GPT-2分词器:
python
show_tokens(text, "gpt2")输出
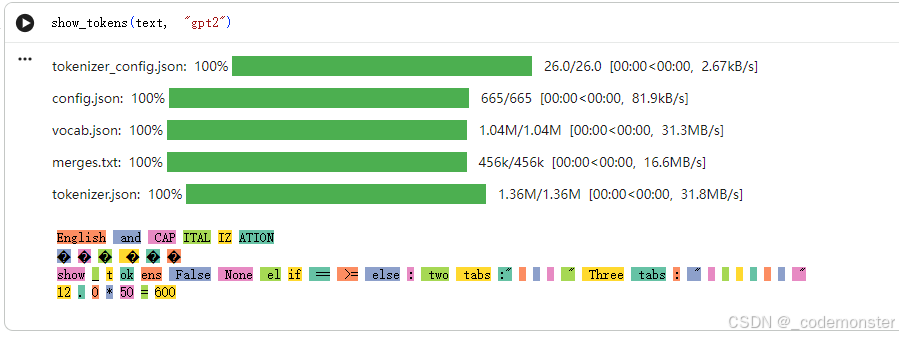
- 使用字节对编码(BPE)
- 保留空格作为词元的一部分
- 特殊字符用
�表示
4. Google Flan-T5:
python
show_tokens(text, "google/flan-t5-small")输出

- 使用SentencePiece分词
- 有特殊的开始/结束标记
</s>
5. GPT-4分词器(近似):
python
show_tokens(text, "Xenova/gpt-4")输出
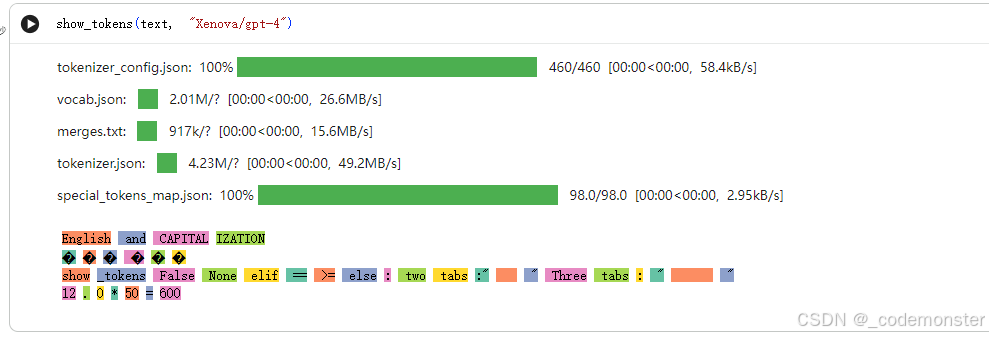
- 与GPT-2类似,但处理略有不同
6. Phi-3-mini(本节主模型):
python
show_tokens(text, "microsoft/Phi-3-mini-4k-instruct")输出

- 有特殊的开始标记
<s> "CAPITALIZATION"被拆分为"C"、"AP"、"IT"、"AL"、"IZ"、"ATION"
从语言模型获取上下文相关的词嵌入(以BERT为例)
python
from transformers import AutoModel, AutoTokenizer
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("microsoft/deberta-base")
# 加载语言模型(只获取嵌入,不用于生成)
model = AutoModel.from_pretrained("microsoft/deberta-v3-xsmall")
# 分词处理
tokens = tokenizer('Hello world', return_tensors='pt')
# 处理词元,获取模型输出
output = model(**tokens)[0] # [0]获取最后一层的隐藏状态
print(f"输出形状: {output.shape}") # 形状:[批次大小, 序列长度, 隐藏层维度]输出:
torch.Size(1, 4, 384)
1: 批次大小(一个句子)4: 序列长度(4个词元:CLS, Hello, world, SEP)384: 每个词元的嵌入维度
查看每个词元的嵌入向量:
python
output输出
tensor(\[\[-3.4816, 0.0861, -0.1819, ..., -0.0612, -0.3911, 0.3017,
0.1898, 0.3208, -0.2315, ..., 0.3714, 0.2478, 0.8048,
0.2071, 0.5036, -0.0485, ..., 1.2175, -0.2292, 0.8582,
-3.4278, 0.0645, -0.1427, ..., 0.0658, -0.4367, 0.3834]],
grad_fn=)
每个词元都有一个384维的向量表示,这些向量包含了丰富的上下文信息。
文本嵌入(用于句子和文档)
python
from sentence_transformers import SentenceTransformer
# 加载专门用于句子嵌入的模型
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
# 将文本转换为嵌入向量
vector = model.encode("Best movie ever!")
print(f"向量形状: {vector.shape}") # 输出:(768,)输出
向量形状: (768,)
这种嵌入将整个句子压缩为一个固定长度的向量,比如这里将"Best movie ever!"这个句子编码为768长度的向量,适用于:
- 语义搜索
- 文本相似度计算
- 聚类分析
大语言模型之外的词嵌入方法
使用预训练的词向量(GloVe)
python
import gensim.downloader as api
# 下载GloVe词向量(在维基百科上训练,50维)
model = api.load("glove-wiki-gigaword-50")
# 查找与"king"最相似的词
similar_words = model.most_similar([model['king']], topn=11)
print(similar_words)可能会报错
ImportError: cannot import name 'triu' from 'scipy.linalg' (/usr/local/lib/python3.12/dist-packages/scipy/linalg/init.py)
解决方法是安装最新的 gensim 和scipy
python
! pip uninstall gensim -y
! pip uninstall scipy -y
! pip install gensim
! pip install scipy输出
================================================== 100.0% 66.0/66.0MB downloaded
('king', 1.0000001192092896), ('prince', 0.8236179351806641), ('queen', 0.7839043140411377), ('ii', 0.7746230363845825), ('emperor', 0.7736247777938843), ('son', 0.766719400882721), ('uncle', 0.7627150416374207), ('kingdom', 0.7542161345481873), ('throne', 0.7539914846420288), ('brother', 0.7492411136627197), ('ruler', 0.7434253692626953)
关键特点:
- 静态嵌入(与上下文无关)
- 可以进行向量运算:king - man + woman ≈ queen
应用:基于嵌入的音乐推荐
song_hash.txt数据的内容格式如下

python
import pandas as pd
from urllib import request
# 获取播放列表数据集
data = request.urlopen('https://storage.googleapis.com/maps-premium/dataset/yes_complete/train.txt')
lines = data.read().decode("utf-8").split('\n')[2:] # 跳过前两行元数据
playlists = [s.rstrip().split() for s in lines if len(s.split()) > 1] # 过滤只有一个歌曲的播放列表
# 加载歌曲元数据
songs_file = request.urlopen('https://storage.googleapis.com/maps-premium/dataset/yes_complete/song_hash.txt')
songs = [s.rstrip().split('\t') for s in songs_file.read().decode("utf-8").split('\n')]
songs_df = pd.DataFrame(data=songs, columns=['id', 'title', 'artist'])
songs_df = songs_df.set_index('id') # 将ID设为索引
# 查看前两个播放列表
print('播放列表 #1:\n', playlists[0][:10], '...') # 只显示前10个歌曲
print('播放列表 #2:\n', playlists[1][:10], '...')输出
播放列表 #1:
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9' ...
播放列表 #2:
'78', '79', '80', '3', '62', '81', '14', '82', '48', '83' ...
训练Word2Vec模型:
python
from gensim.models import Word2Vec
# 训练Word2Vec模型
model = Word2Vec(
playlists, # 训练数据:播放列表
vector_size=32, # 嵌入向量维度
window=20, # 上下文窗口大小
negative=50, # 负采样数量
min_count=1, # 最小词频
workers=4 # 并行线程数
)
# 查找与特定歌曲相似的歌曲
song_id = 2172
similar_songs = model.wv.most_similar(positive=str(song_id))
print(f"与歌曲 #{song_id} 相似的歌曲:")
print(similar_songs[:5]) # 显示前5个
# 查看歌曲信息
print(f"\n歌曲 #{song_id} 的信息:")
print(songs_df.iloc[2172])输出
与歌曲 #2172 相似的歌曲:
('5549', 0.9961116909980774), ('2849', 0.9954611659049988), ('3167', 0.9941955208778381), ('10105', 0.994032621383667), ('2976', 0.9936418533325195)
歌曲 #2172 的信息:
title Fade To Black
artist Metallica
Name: 2172 , dtype: object
创建推荐函数:
python
import numpy as np
def print_recommendations(song_id):
"""打印歌曲推荐"""
# 获取最相似的歌曲ID
similar_songs = np.array(
model.wv.most_similar(positive=str(song_id), topn=5)
)[:,0] # 只取歌曲ID列
# 返回歌曲信息
return songs_df.iloc[similar_songs.astype(int)]
# 测试推荐系统
print("Metallica - Fade To Black 的推荐歌曲:")
print_recommendations(2172)
print("\n2Pac - California Love 的推荐歌曲:")
print_recommendations(842)输出
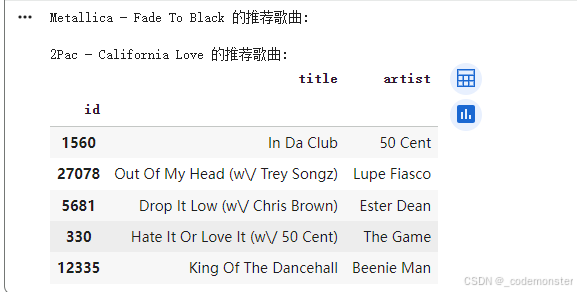
这个例子展示了如何使用词嵌入技术(Word2Vec)来创建音乐推荐系统,原理类似于自然语言处理:
- 播放列表类似于"句子"
- 歌曲类似于"词语"
- 经常一起出现的歌曲在嵌入空间中的位置相近