我们使用了神经网络的方式,用了pytorch重新对信贷数据集进行处理。
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import os
# 设置随机种子以保证结果可复现
torch.manual_seed(42)
np.random.seed(42)
# --- 1. 数据预处理 ---
def load_and_preprocess_data(filepath):
print("Loading data...")
df = pd.read_csv(filepath)
# 删除 Id 列
if 'Id' in df.columns:
df = df.drop('Id', axis=1)
print(f"Original shape: {df.shape}")
# 处理 'Current Loan Amount' 异常值 (99999999.0 通常表示无限制或错误)
# 替换为 NaN 然后进行插补,或者替换为最大有效值。
# 这里我们替换为 NaN 并使用中位数插补,如果数量太多也可以直接删除。
# 先检查一下数量。
outlier_mask = df['Current Loan Amount'] == 99999999.0
df.loc[outlier_mask, 'Current Loan Amount'] = np.nan
# 解析 'Years in current job'
# 映射关系: '< 1 year'->0, '1 year'->1, ..., '10+ years'->10
def parse_years(x):
if pd.isna(x): return np.nan
if '<' in x: return 0
if '+' in x: return 10
return int(x.split()[0])
df['Years in current job'] = df['Years in current job'].apply(parse_years)
# 插补缺失值
# 数值列
num_cols = df.select_dtypes(include=[np.number]).columns
for col in num_cols:
if col != 'Credit Default':
# 使用中位数以增强鲁棒性
median_val = df[col].median()
df[col].fillna(median_val, inplace=True)
# 类别列
cat_cols = df.select_dtypes(include=['object']).columns
for col in cat_cols:
mode_val = df[col].mode()[0]
df[col].fillna(mode_val, inplace=True)
# 编码类别变量 (One-Hot 编码)
df = pd.get_dummies(df, columns=cat_cols, drop_first=True)
print(f"Processed shape: {df.shape}")
# 划分数据
X = df.drop('Credit Default', axis=1).values
y = df['Credit Default'].values
# 70% 训练集, 15% 验证集, 15% 测试集
# 第一次划分: 训练集 (70%) 和 临时集 (30%)
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 第二次划分: 验证集 (总量的 15% -> 临时集的 50%) 和 测试集 (总量的 15% -> 临时集的 50%)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42, stratify=y_temp)
# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
X_test = scaler.transform(X_test)
return X_train, y_train, X_val, y_val, X_test, y_test, df.drop('Credit Default', axis=1).columns
# --- 2. PyTorch 数据集 ---
class CreditDataset(Dataset):
def __init__(self, X, y):
self.X = torch.FloatTensor(X)
self.y = torch.FloatTensor(y).unsqueeze(1) # 二分类需要 (N, 1) 的形状
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# --- 3. 神经网络模型 ---
class CreditNN(nn.Module):
def __init__(self, input_dim):
super(CreditNN, self).__init__()
# 3 个隐藏层: 128 -> 64 -> 32
self.layer1 = nn.Linear(input_dim, 128)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(0.3)
self.layer2 = nn.Linear(128, 64)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(0.3)
self.layer3 = nn.Linear(64, 32)
self.relu3 = nn.ReLU()
self.output = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.dropout1(self.relu1(self.layer1(x)))
x = self.dropout2(self.relu2(self.layer2(x)))
x = self.relu3(self.layer3(x))
x = self.sigmoid(self.output(x))
return x
# --- 4. 训练函数 ---
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs=100, patience=10):
train_losses = []
val_losses = []
train_accs = []
val_accs = []
best_val_loss = float('inf')
epochs_no_improve = 0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
print(f"Training on {device}")
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct_train = 0
total_train = 0
for X_batch, y_batch in train_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
running_loss += loss.item()
predicted = (outputs > 0.5).float()
total_train += y_batch.size(0)
correct_train += (predicted == y_batch).sum().item()
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = correct_train / total_train
train_losses.append(epoch_train_loss)
train_accs.append(epoch_train_acc)
# 验证
model.eval()
running_val_loss = 0.0
correct_val = 0
total_val = 0
with torch.no_grad():
for X_batch, y_batch in val_loader:
X_batch, y_batch = X_batch.to(device), y_batch.to(device)
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
running_val_loss += loss.item()
predicted = (outputs > 0.5).float()
total_val += y_batch.size(0)
correct_val += (predicted == y_batch).sum().item()
epoch_val_loss = running_val_loss / len(val_loader)
epoch_val_acc = correct_val / total_val
val_losses.append(epoch_val_loss)
val_accs.append(epoch_val_acc)
print(f"Epoch [{epoch+1}/{num_epochs}] "
f"Train Loss: {epoch_train_loss:.4f} Acc: {epoch_train_acc:.4f} | "
f"Val Loss: {epoch_val_loss:.4f} Acc: {epoch_val_acc:.4f}")
# 早停检查
if epoch_val_loss < best_val_loss:
best_val_loss = epoch_val_loss
epochs_no_improve = 0
# 保存最佳模型
torch.save(model.state_dict(), 'best_credit_model.pth')
else:
epochs_no_improve += 1
if epochs_no_improve >= patience:
print("Early stopping triggered!")
break
return train_losses, val_losses, train_accs, val_accs
# --- 5. 评估与可视化 ---
def evaluate_model(model, test_loader, feature_names):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load('best_credit_model.pth'))
model.to(device)
model.eval()
y_true = []
y_pred = []
y_scores = []
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.to(device)
outputs = model(X_batch)
y_scores.extend(outputs.cpu().numpy())
predicted = (outputs > 0.5).float()
y_pred.extend(predicted.cpu().numpy())
y_true.extend(y_batch.numpy())
y_true = np.array(y_true)
y_pred = np.array(y_pred)
y_scores = np.array(y_scores)
# 指标计算
acc = accuracy_score(y_true, y_pred)
prec = precision_score(y_true, y_pred)
rec = recall_score(y_true, y_pred)
auc = roc_auc_score(y_true, y_scores)
print("\n--- Test Set Evaluation ---")
print(f"Accuracy: {acc:.4f}")
print(f"Precision: {prec:.4f}")
print(f"Recall: {rec:.4f}")
print(f"AUC: {auc:.4f}")
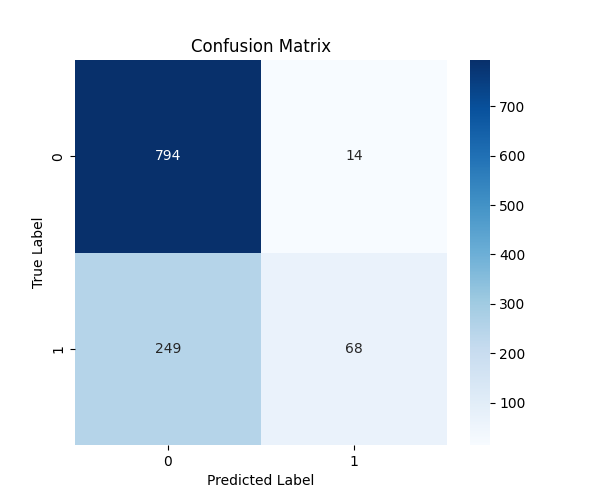
# 混淆矩阵
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.savefig('confusion_matrix.png')
print("Saved confusion_matrix.png")
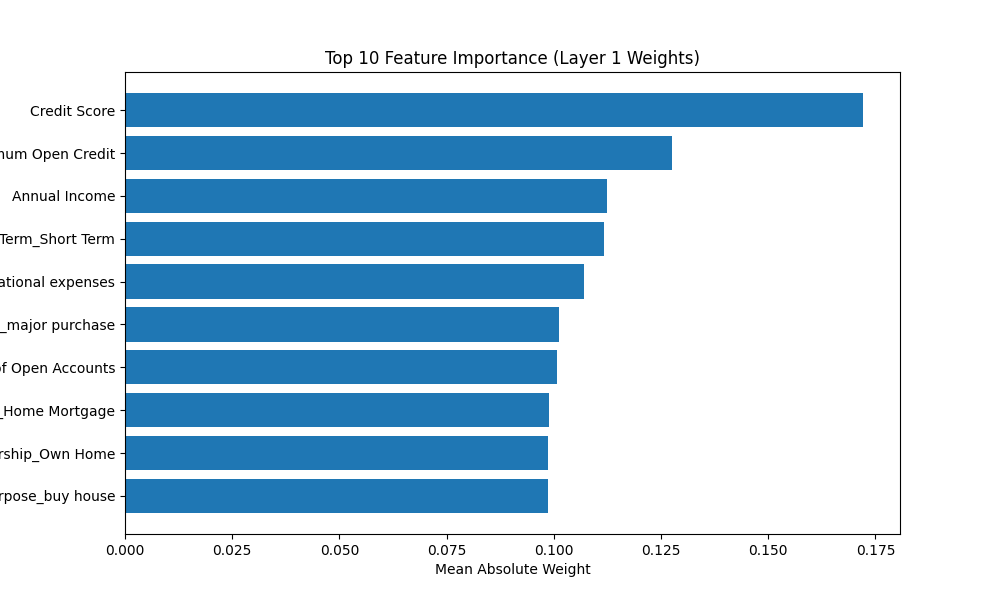
# 可视化第一层权重 (特征重要性近似)
# 我们取每个输入特征的权重的绝对值均值来观察其贡献
weights = model.layer1.weight.data.cpu().numpy()
feature_importance = np.mean(np.abs(weights), axis=0)
# 特征排序
sorted_idx = np.argsort(feature_importance)[-10:] # 取前10个
plt.figure(figsize=(10, 6))
plt.barh(range(10), feature_importance[sorted_idx])
plt.yticks(range(10), feature_names[sorted_idx])
plt.xlabel('Mean Absolute Weight')
plt.title('Top 10 Feature Importance (Layer 1 Weights)')
plt.savefig('feature_importance.png')
print("Saved feature_importance.png")
# --- 主程序执行 ---
if __name__ == "__main__":
# 加载数据
data_path = 'e:\\桌面\\Python60DaysChallenge-main\\data.csv'
X_train, y_train, X_val, y_val, X_test, y_test, feature_names = load_and_preprocess_data(data_path)
# 创建 DataLoader
batch_size = 64
train_dataset = CreditDataset(X_train, y_train)
val_dataset = CreditDataset(X_val, y_val)
test_dataset = CreditDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 初始化模型
input_dim = X_train.shape[1]
model = CreditNN(input_dim)
print(model)
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练
train_losses, val_losses, train_accs, val_accs = train_model(
model, train_loader, val_loader, criterion, optimizer, num_epochs=100, patience=10
)
# 绘制训练历史
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Val Loss')
plt.title('Loss Curve')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_accs, label='Train Acc')
plt.plot(val_accs, label='Val Acc')
plt.title('Accuracy Curve')
plt.legend()
plt.savefig('training_history.png')
print("Saved training_history.png")
# 评估
evaluate_model(model, test_loader, feature_names)结果如下: