LPDDR新闻整理
-
- 冲击14.4GHz!LPDDR6内存标准正式发布
- 14.4GHz超高频惊人!LPDDR6内存标准正式发布
- 三星宣布将首发LPDDR6内存:起手超10G,未来冲击14.4G
- [ISSCC 2026前瞻:两巨头的内存对决](#ISSCC 2026前瞻:两巨头的内存对决)
- LPDDR6来了,高通首发,存储带宽比算力更重要
冲击14.4GHz!LPDDR6内存标准正式发布
2025-07-10
JEDEC今天正式发布了LPDDR6内存标准,规范编号JESD209-6,可显著提升移动设备、AI应用的性能、能效、安全。
性能方面,LPDDR6采用双子通道架构,保持最小访问间隔32字节的同时,允许更灵活的操作。
1、每颗裸片(Die)支持两个子通道,每个子通道分为12个数据信号线(DQ),优化通道性能。
2、每个子通道包含4个指令/寻址(CA)指令,优化减少焊球数量,改进数据访问速度。
3、支持静态能效模式,可支持更大容量,最大化利用bank资源。
4、支持弹性数据访问,实时突发长度控制,支持32/64字节访问。
5、支持动态写入NT-ODT(非目标片上终止),可以根据负载需求调整ODT,改进信号完整性。
不过,JEDEC并未规定LPDDR6的数据传输率(频率),根据此前说法起步就超过了10Gbps,可以达到10667Mpbps,而最高可以做到14400Mbps,也可以说是14.4GHz。
相比之下,LPDDR5起步为6400Mbps,LPDDR5X提升至8533Mpbs,SK海力士自己做的LPDDR5T则能跑到9600Mbps。能效方面,LPDDR6进一步降低了电压和功耗,采用VDD2供电,并且采用双电源供电。
其他节能特性还有:
1、交替时钟命令输入,提高性能和能效。
2、低功耗动态电压频率吊证(DVFSL),在低频率运行时减少VDD2供电,从而节省功耗。
3、动态效率模式,采用单个子通道接口,适合低功耗、低带宽场景。
4、支持部分自刷新、主动刷新,降低刷新功耗。
安全性和可靠性方面,LPDDR6也有了很大的提升。
1、支持每行激活计数(PRAC),支持内存数据完整性。
2、支持预留元模式(Carve-Out Meta),通过为关键任务分配特定内存区域,提高整体系统可靠性。
3、支持可编程链路保护机制、ECC纠错校验。
4、支持命令/地址(CA)奇偶校验、错误擦洗、寸内自测试(MBIST),以增强错误检测能力和系统可靠性。
Advantest、Cadence、Synopsys、三星、SK海力士、美光、高通、联发科等半导体测试厂商、内存芯片厂商、终端厂商都表达了对LPDDR6的支持和期待。
至于LPDDR6内存何时落地,估计就看下半年的新一代骁龙、天玑平台了!
转载自:https://t.10jqka.com.cn/pid_476496735.shtml,仅用作学习,如有侵权,删除;
14.4GHz超高频惊人!LPDDR6内存标准正式发布
2025-07-10
目前大多数手机和轻薄本正在使用的内存类型都是LPDDR5内存,LPDDR5X则是性能更好的LPDDR5内存,本质上没有区别。距离LPDDR5内存上市已经过去了5年多的时间了,也是时候开始准备下一代内存产品了。目前制定内存标准的JEDEC固态技术协会就正式发布了JESD209-6,即最新的低功耗双倍数据速率6(LPDDR6)标准。
核心参数方面,LPDDR6内存的频率将从10667Mbps起步,最高可达14400Mbps。同时其位宽也得到进一步增加,单通道从16bit升级到24bit,这意味着通常使用四通道内存的手机产品的内存位宽从64bit升级到96bit,8通道的笔记本产品则是从的128bit升级到192bit,显存带宽显然也是随之大幅提升,对于集成显卡的性能表现有着非常大的助力。

对比上一代LPDDR5标准,全新的LPDDR6带来了一系列改进,从结构设计、能耗优化以及安全性上带来了多项升级,包含双重子通道架构设计、VDD2供电以及PRAC每行激活计数的支持等等新功能和新设计,将会给用户带来更强的性能,更低的功耗以及更好的安全表现。JEDEC表示,JESD209-6旨在显著提升多种应用场景(包括移动设备和人工智能)的内存速度与效率,新版 JESD209-6 LPDDR6 标准是内存技术的重大进步,在性能、能效和安全性方面均有提升。

此前的消息显示,三星可能将在今年下半年提供新一代LPDDR6内存的量产,SK海力士和长鑫存储也有望在年内或者明年初实现量产。这意味着在今年下半年到明年上半年发布的新旗舰手机当中,我们就有希望看到全新的LPDDR6内存了,搭配新一代旗舰芯片能够带来怎样的性能表现也十分值得期待。而轻薄本产品则有可能到2026年中甚至下半年才有希望用上新一代的LPDDR6内存。
转载自如下网站,仅供学习之用,如有侵权,后台私信删除。
https://baijiahao.baidu.com/s?id=1837243723845239310\&wfr=spider\&for=pc
三星宣布将首发LPDDR6内存:起手超10G,未来冲击14.4G
2025-11-10
目前手机AI越来越火爆,因此手机厂商也和电脑厂商一样,需要追求更高的带宽,于是LPDDR6内存也就顺理成章地提上了议程,并且厂商也在加速研发,目前三星宣布将会在CES 2026上全球首发LPDDR6内存,速度超过10Gbps,当然三星也表示未来随着技术的进步,LPDDR6内存将会达到14.4Gbps的速度,这可比现在的LPDDR5X速度高出不少,估计也是为了迎合更加复杂的AI需求。
国际存储组织在今年7月份最终确定了LPDDR6内存的标准,存储厂商也紧锣密鼓地研发相关的产品,其中三星已经确认将会在CES 2026上首发全新的LPDDR6内存,起步带宽就将达到10.7Gbps,而目前海力士的LPDDR5T应该算是最快的LPDDR5系列内存,其速度为9600Mbps,还是不如LPDDR6。除此之外三星也表示希望能够将LPDDR6的速度提升到14.4Gbps,此外借助12nm制程工艺降低内存的功耗。
除了超过10Gbps的速度之外,三星也表示AI对于IO性能提出了更高的要求,因此三星也扩展了IO性能,从而提升AI运行的效率。除了三星之外,包括海力士、美光等厂商也正在测试LPDDR6内存,预计将会在CES 2026带来更多的消息,就是现在这内存的价格直接起飞,估计明年手机厂商就将迎来新的一轮涨价潮。
转载自:https://baijiahao.baidu.com/s?id=1848380326292479707\&wfr=spider\&for=pc,仅用作学习, 如有侵权告知删除;
ISSCC 2026前瞻:两巨头的内存对决
2025-11-27
内存竞赛日趋激烈,韩国芯片巨头正积极研发新技术以满足人工智能领域日益增长的需求。
据报道,三星电子和SK海力士将在2026年国际固态电路大会(ISSCC)上展示一系列新一代DRAM解决方案。SK海力士将推出其最新的GDDR7和LPDDR6,用于图形和移动应用;而三星电子则将发布HBM4。
SK海力士发布新一代GDDR7和LPDDR6内存
报告指出,SK海力士推出了单引脚带宽为48 Gb/s、容量为24 Gb的GDDR7显存。该芯片采用对称双通道设计,面向GPU、AI边缘推理和游戏等高带宽应用。
此次SK海力士计划推出的GDDR7 DRAM的非标准规格是其关注的焦点。尽管业界此前预期下一代GDDR7的峰值速度约为32-37 Gbps,但SK海力士将在ISSCC会议上发表论文,展示其48 Gbps的运行速度和24 Gb的密度,这展示了SK海力士在技术上的领先优势。
与目前的 28 Gbps GDDR7 相比,传输速度提升了 70% 以上。每个芯片的带宽达到 192 GB/s,高于现有 28 Gbps 产品约 112 GB/s 的带宽------这是一项技术突破,从根本上重塑了图形 DRAM 的性能范式。
SK海力士首次发布了 14.4 Gb/s 的 LPDDR6 内存。与 LPDDR5(9.6 Gb/s)相比,LPDDR6 的带宽大幅提升,定位为面向高性能智能手机、AI PC 和具备生成式 AI 功能的边缘设备的移动 DRAM 解决方案。
三星发布用于人工智能加速器的下一代HBM4
三星电子发布了其新一代HBM4内存,容量高达36GB,带宽达3.3TB/s。HBM4采用1c DRAM工艺制造,并改进了其TSV(硅通孔)架构,以降低通道间信号延迟,从而提供未来AI加速器所需的高带宽和低功耗数据传输。
三星的HBM4相比前几代产品,带宽有了显著提升。更重要的是,它满足了领先的GPU和AI ASIC制造商对3TB/s以上吞吐量的要求,预计将从明年开始在AI服务器加速器中得到广泛应用。
三星目前正与英伟达就明年HBM4的价格进行谈判。消息人士表示,英伟达在与SK海力士敲定HBM4供应合同仅一周后,便邀请三星电子参与谈判。报道还指出,由于HBM4需求超过供应,且没有强烈的降价动力,三星电子内部的目标是使其12层HBM4内存的价格与SK海力士的价格持平。
巨头联手,要把GPU核心封装到HBM上
关于存储产品另一个值得关注的技术进展是,报道称英伟达携手 Meta、三星电子、SK 海力士等科技巨头,为提升 AI 性能,正探索将 GPU 核心集成至下一代 HBM(高带宽存储器)的技术方案。
据多位业内人士透露,Meta 和英伟达正在积极探讨此方案,并已开始与三星电子、SK 海力士进行合作洽谈。该技术旨在打破传统计算架构中内存与处理器分离的模式,通过在 HBM 的基底裸片(Base Die)中植入 GPU 核心,实现计算与存储的深度融合。
HBM 作为一种通过垂直堆叠多个 DRAM 芯片实现的高性能存储器,专为处理人工智能(AI)所需的海量数据而设计,其最底层的基底裸片目前主要负责内存与外部设备间的通信。
即将于明年量产的HBM4 已计划在基底裸片上集成控制器,以提升性能和效率。而此次讨论的"GPU 核心内嵌"方案,则是在此基础上更进一步的重大技术跨越,它将原本集中于主 GPU 的运算功能部分转移至 HBM 内部。
将GPU 核心植入 HBM 的主要目的在于优化 AI 运算的效率,通过将运算单元与存储单元的物理距离缩至最短,可以显著减少数据传输延迟和随之产生的功耗,从而减轻主 GPU 的负担。
这种"存内计算"的思路,被视为突破当前 AI 性能瓶颈的关键路径之一,有助于构建更高效、更节能的 AI 硬件系统。要实现这一设想仍面临诸多技术挑战。首先,HBM 基底裸片受限于硅通孔(TSV)工艺,可用于容纳 GPU 核心的物理空间非常有限。
其次,GPU 运算核心是高功耗单元,会产生大量热量,因此如何有效解决供电和散热问题,防止过热成为性能瓶颈,是该技术能否落地的关键。
转载自,https://news.qq.com/rain/a/20251127A066ZD00,仅用作学习,如有侵权,后台私信告知删除。
LPDDR6来了,高通首发,存储带宽比算力更重要
DRAM内存行业高度集中,三大巨头,SK Hynix、三星和美光合计市场占有率达95%,三巨头足以掌控标准,表面上看DRAM标准是JEDEC控制的,实际在标准正式公布前,三巨头就会有量产产品问世。还有一些IP巨头,如存储控制器IP巨头新思科技,在2024年就能够提供LPDDR6控制器的IP。新思科技在2024年5月发布一篇PPT,名字就叫LPDDR6 A Deep Into the JEDEC Press Release。
三星已经确认LPDDR6将于2025年下半年量产,第一个使用LPDDR6的是高通即将于2025年10月底发布的骁龙8至尊二代,汽车领域应该也会有至尊二代座舱和Ride,鉴于汽车至尊一代刚刚开始推广,至尊二代估计要等到明年了。据说苹果也有意使用。
LPDDR6与LPDDR5最大区别一是速度,二是总线宽度。速度方面,LPDDR6起步是10.6Gbps,然后有12.8Gbps、14.4Gbps和16.0Gbps几档,目前三星的LPDDR5X就有10.667Gbps,LPDDR5T则有9.6Gbps,LPDDR6为了凸显优势,大部分厂家都会选择12.8Gbps和14.4Gbps,早期JEDEC定的标准最高是14.4Gbps,但就像LPDDR5早期定的标准最高是8.5Gbps一样,后期肯定会超过,LPDDR6至少会到16.0Gbps。
LPDDR时间线
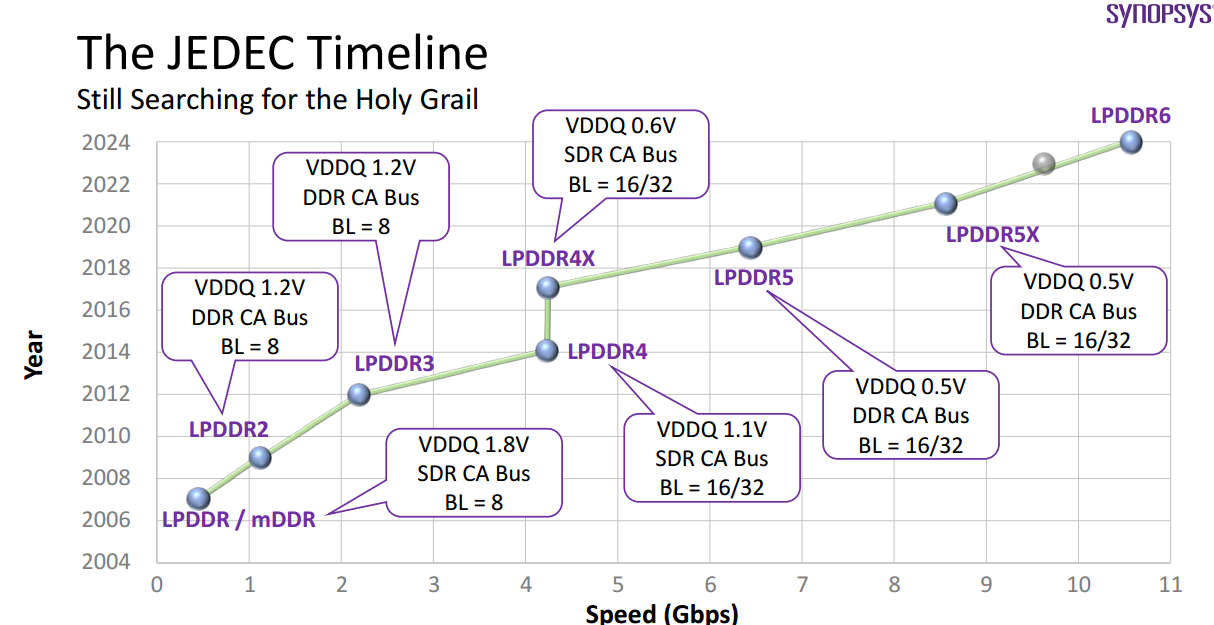
图片来源:JEDEC
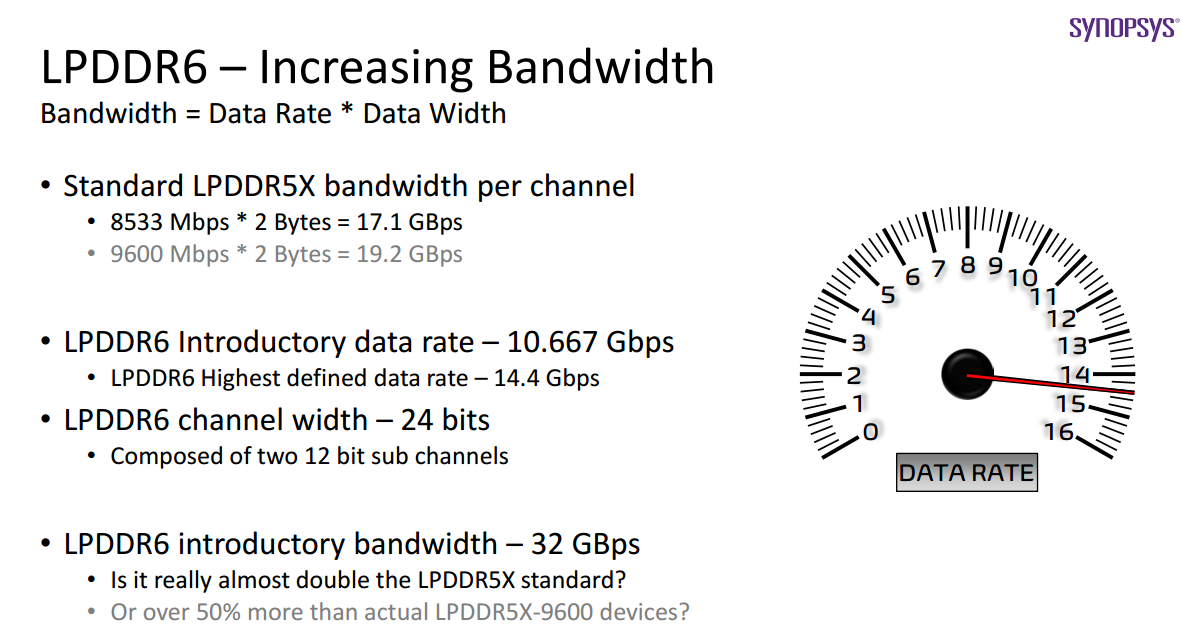
LPDDR6与LPDDR5区别之二是总线宽度,LPDDR5是16位单通道,LPDDR6是24位,由两个12-bit通道合并而成,某些苛刻应用如车载和工业领域,可以留一个通道做备份,一个通道数据丢失,另一个可以补上。不过数据系统还是32位或64位,因此LPDDR6的有效带宽计算比较复杂,LPDDR6在SoC的位宽和LPDDR5完全不同,LPDDR5常见的是96、128、256bit,LPDDR6则是72、96、144、288bit。标准LPDDR5X的理论带宽是8533Mbps (2.1GHz * 32Bits) * 2Bytes (16Bits DQ data per channel) = 17.1Gbps,初级LPDDR6的理论带宽是10.667Gbps (2.7GHz * 32Bits) * 3Bytes (24Bits DQ data channels) = 32Gbps。相比LPDDR5x,LPDDR6的Command Bus上多了一个CA/CS pin。在保留大部分LPDDR5/5x的signals基础上,增加了一个ALERT信号。
LPDDR6有效位宽计算
图片来源:新思科技
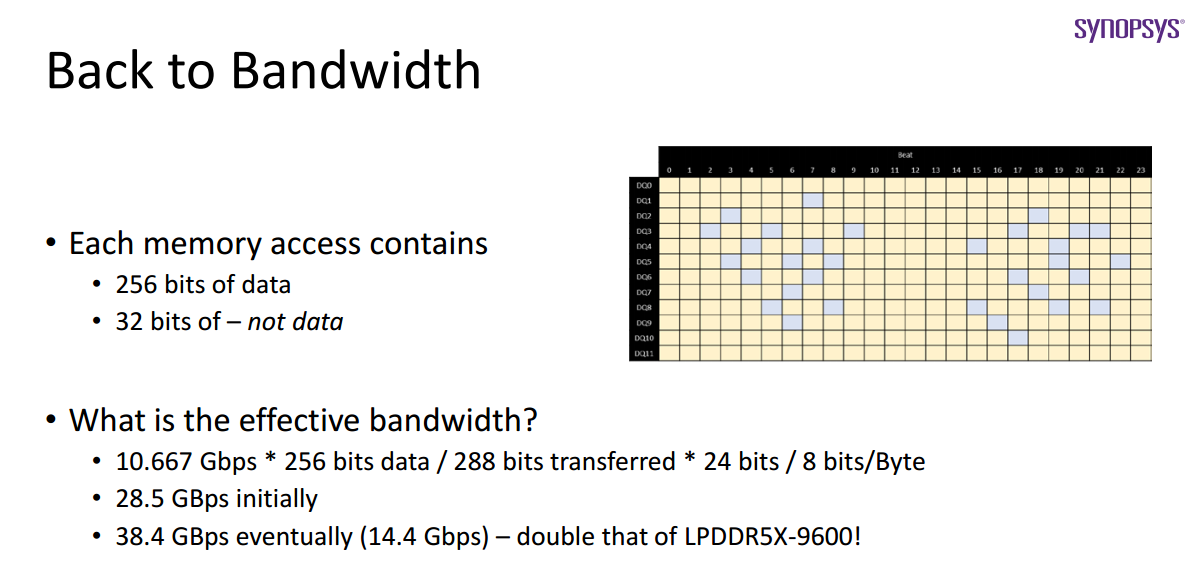
因为大部分缓存是256或512位宽,为避免来回转换,288bits拆分为了256 data bits + 32 non-data bits。

RAS代表Reliability, Availability and Serviceability,DBI是Data Bus Inversion,32位数据只能在RAS和DBI中间选一个。DBI (Data Bus Inversion) 反转是在DDR4开始增加的一个功能,其工作原理实际很简单:当驱动器(控制器写入或DRAM读取)在总线上发送数据时,系统会统计逻辑"0"位的数量。如果某个数据通道中"0"的数量达到或超过5个,那么整个字节的数据将被反转,同时第9位DBI指示位会被置为低电平。这样做确保了在8个数据位和1个DBI位中,至少有5位处于"1"的状态。这也保证了在整个数据通道中,信号变化的最大总数只会是5个"1"变为9个"1",或者相反的情况。我们不会遇到所有位都从0变为1或从1变为0的极端情况。DBI技术限制了信号同时切换的数量,从而减小了SSN的影响,提高了信号完整性。同时减少了信号切换的次数,特别是高电平的切换次数,从而降低了功耗。
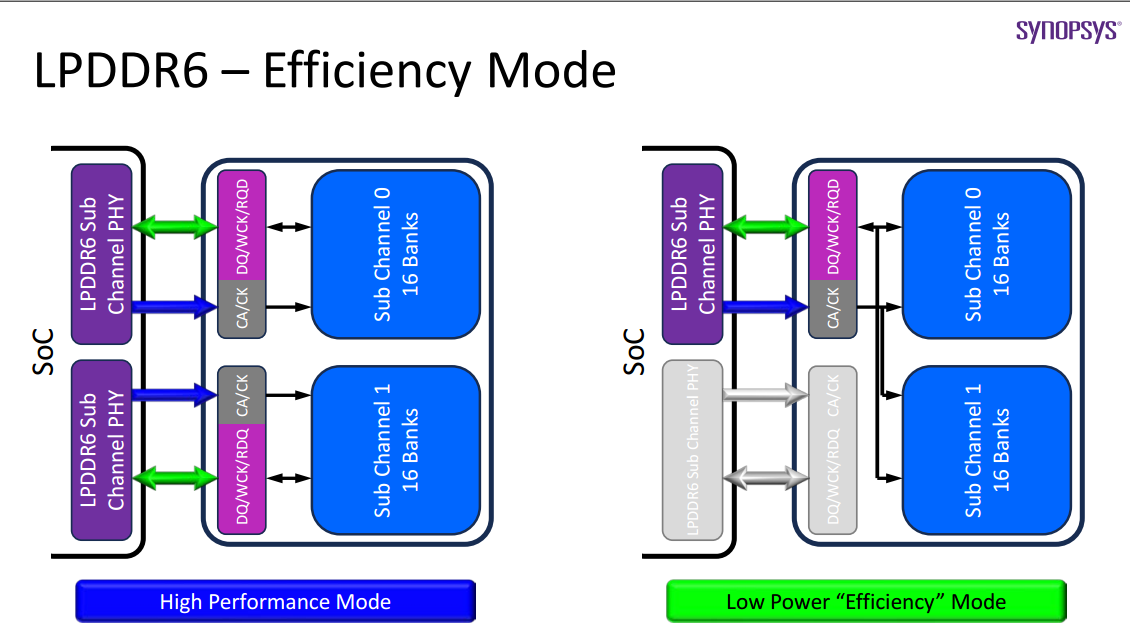
图片来源:JEDEC
允许PHY single channel管理2 Channels DRAM Banks,即高效模式,节约了成本,高性能模式可以选择高成本的双Phy模式。

图片来源:JEDEC
LPDDR6增加了ALERT信号,对Write Command下的ECC/EDC信息反查,支持通过4个fault寄存器确认16个不同Error。
不同存储技术的参数
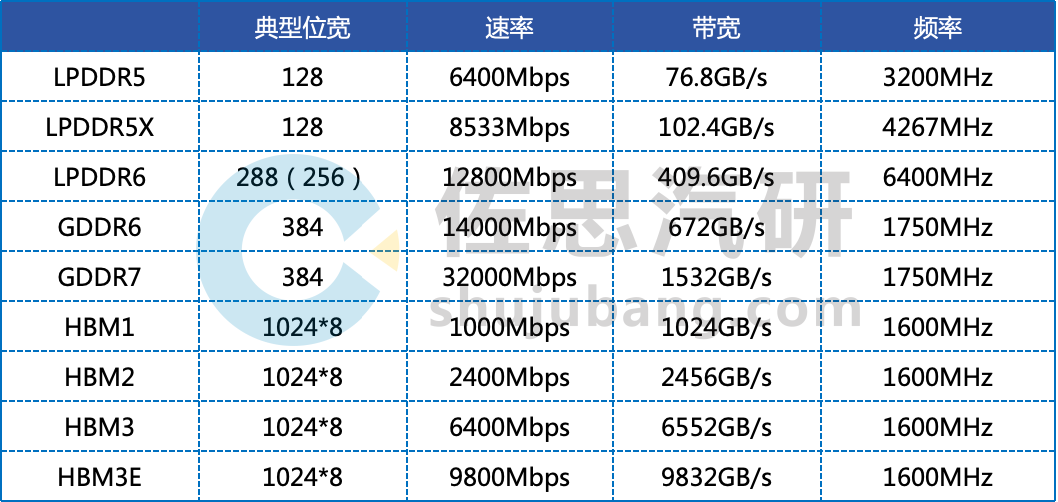
整理:佐思汽研
GDDR6/7和HBM都是高位宽,高传输速率,LPDDR则频率很高。也就是说GDDR6/7和HBM只适合做显存,不适合配合CPU做RAM,LPDDR则两者兼顾,除了特斯拉的HW4使用GDDR6外,所有SoC都是使用LPDDR,特斯拉也许是对存储带宽特别在意,才用GDDR6,但此举拉低了CPU的频率,除非遇到特别大的模型,否则提升不大。
当前的主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理过程可以分为两个阶段:
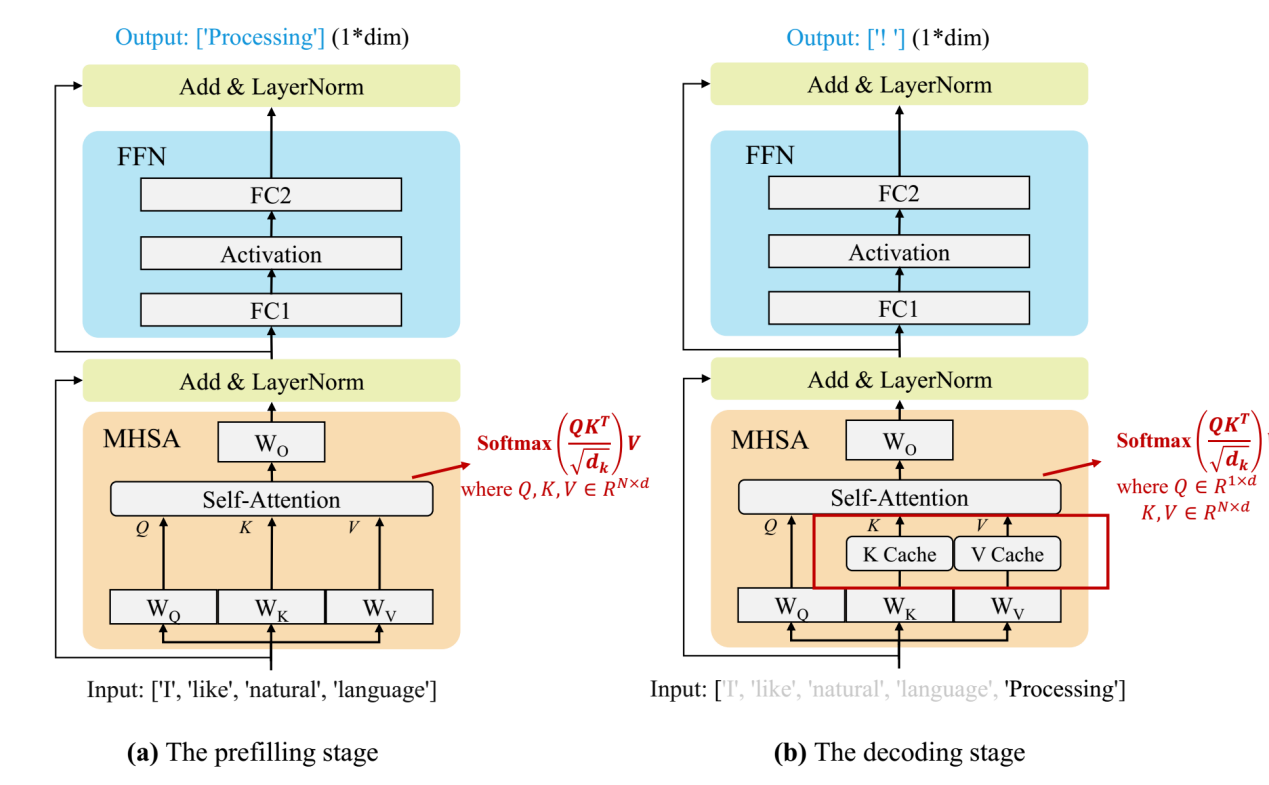
图片来源:论文《A Survey on Efficient Inference for Large Language Models》
Prefill:根据输入 Tokens(Recite, the, first, law, of, robotics) 生成第一个输出 Token(A),通过一次 Forward 就可以完成,在 Forward 中,输入 Tokens 间可以并行执行(类似 Bert 这些 Encoder 模型),因此执行效率很高。
Decoding:从生成第一个 Token(A) 之后开始,采用自回归方式一次生成一个 Token,直到生成一个特殊的 Stop Token(或者满足用户的某个条件,比如超过特定长度) 才会结束,在 Decoding 阶段 Token 是逐个生成的,上述的计算过程中每次都会依赖之前的结果,换句话说这是串行计算,而非GPU擅长的并行计算,GPU大部分时候都在等待数据搬运。加速的办法是计算当前 Token 时直接从KV Cache中读取而不是重新计算。对于通用LLM,应用场景是要考虑多个并发客户使用,即Batch Size远大于1,KV Cache的缓存量会随着Batch Size暴增,但在车里用户只有一个,就是自动驾驶端到端大模型,即Batch Size为1。
因为 Decoding 阶段 Token 逐个处理,使用 KV Cache 之后,上面介绍的 Multi-Head Attention 里的矩阵乘矩阵操作全部降级为矩阵乘向量即GEMV。除此之外,Transformer 模型中的另一个关键组件 FFN 中主要也包含两个矩阵乘法操作,但是 Token 之间不会交叉融合,也就是任何一个 Token 都可以独立计算,因此在 Decoding 阶段不用 Cache 之前的结果,但同样会出现矩阵乘矩阵操作降级为矩阵乘向量。Prefill阶段则是GEMM,矩阵与矩阵的乘法。
矩阵乘向量操作是明显的访存bound,而以上操作是LLM 推理中最主要的部分,这也就导致LLM 推理是访存 bound 类型。简单说,Prefill阶段完全取决于算力,Decoding阶段完全取决于存储带宽。
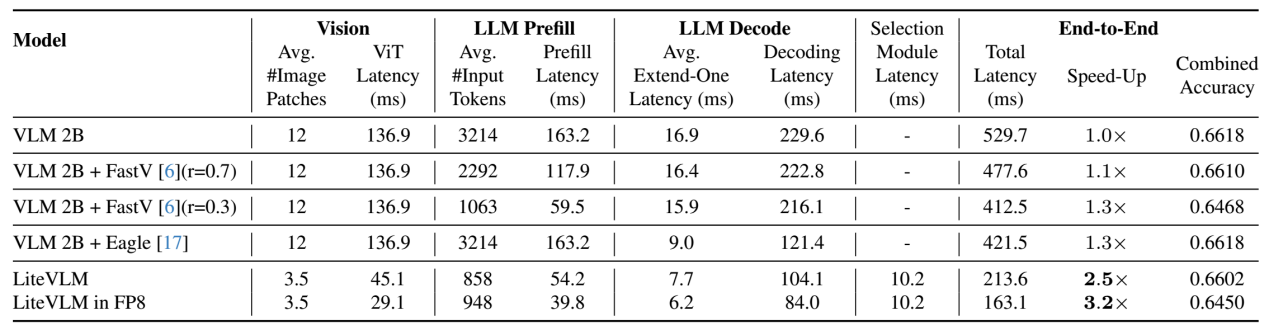
数据来源:英伟达论文《LiteVLM: A Low-Latency Vision-Language Model Inference Pipeline for Resource-Constrained Environments》
如果不计算ViT阶段,那么解码阶段延迟大概占总延迟的58%。换句话说,存储带宽决定了LLM推理运算58%的延迟,因此非常重要。
常见存储带宽
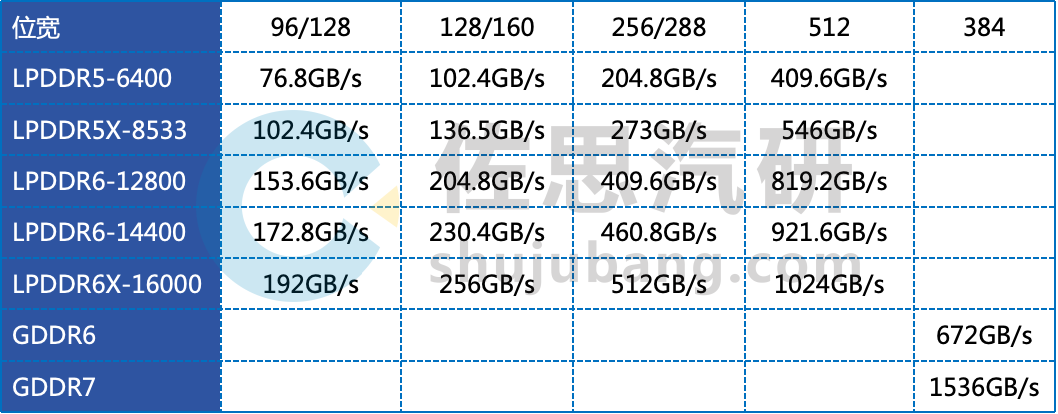
整理:佐思汽研
目前顶级自动驾驶芯片如英伟达的Thor(最低端的z除外,其存储带宽还是204.8GB/s)和高通的SA8397/SA8797都是273GB/s,稍低一级的英伟达Orin和地平线的J6P是204.8GB/s,存储控制器die size面积大,也就是成本高,碍于控制成本,其余大部分自动驾驶芯片都是76.8-102.4GB/s。
高通改走高端路线,对英伟达发起挑战,国内厂家也需要奋起,国人能够接受国产高价车型,不妨把成本控制放一放,更强调性能。
转载自:https://zhuanlan.zhihu.com/p/1925956178896196343,如有侵权,后台私信删除;