一、概论
通义千问VL模型支持对视频内容进行理解,文件形式包括图像列表(视频帧)或视频文件。
视频抽帧说明
通义千问VL 模型通过从视频中提取帧序列进行内容分析,抽帧的频率决定了模型分析的精细度,不同 SDK 抽帧频率不同:
-
使用
DashScope SDK:可通过
fps参数来控制抽帧间隔(每隔 fps1秒抽取一帧),该参数范围为(0.1, 10)且默认值为2.0。建议为高速运动场景设置较高fps,为静态或长视频设置较低fps。
- 使用
OpenAI兼容SDK:采用固定频率抽帧(每0.5秒1帧),不支持自定义。
简单解释以上的内容:
通义千问 VL 模型能 "看懂" 视频内容,你可以给它传视频文件,也可以传由视频画面(帧)组成的图片列表;不过模型并不是逐帧看完整个视频,而是抽取部分画面来分析,抽帧的密集程度(频率)会影响分析的细致度,不同使用方式的抽帧规则不一样:
公式:
-
用 DashScope SDK 时:能自己调抽帧间隔(靠 fps 参数)------ 比如 fps 设 2,就是每 二分之一 秒抽 1 帧;参数能设 0.1 到 10 之间(默认 2.0)。如果视频里画面动得快(比如球赛、车流),就把 fps 设高一点(抽帧更密,看得更细);如果是静态画面多的视频(比如讲座、慢镜头)或很长的视频,就把 fps 设低一点(抽帧疏一点,省资源)。
-
用 OpenAI 兼容 SDK 时:抽帧频率是固定的 ------ 每 0.5 秒抽 1 帧,没法自己调整。
二、代码实现
我们新增出一个接口出来,专门来处理 视频 类型的数据
第一步:新增视频请求实体类 VideoRequest
java
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import gzj.spring.ai.Request.VideoRequest;
import gzj.spring.ai.Service.VideoService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/multimodal/video")
@RequiredArgsConstructor
@CrossOrigin // 跨域支持(生产环境建议限定域名)
public class VideoController {
private final VideoService videoService;
@RequestMapping("/simple")
public String simpleVideoCall(@RequestBody VideoRequest request) throws ApiException, NoApiKeyException, UploadFileException {
return videoService.simpleVideoCall(request);
}
}第二步:新增视频服务接口 VideoService
java
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import gzj.spring.ai.Request.VideoRequest;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
public interface VideoService {
/**
* 视频理解-普通调用(非流式)
* @param request 视频请求参数
* @return 视频理解结果文本
*/
String simpleVideoCall(VideoRequest request) throws ApiException, NoApiKeyException, UploadFileException;
/**
* 视频理解-流式调用(SSE推送)
* @param request 视频请求参数
* @return SseEmitter 用于前端接收流式结果
*/
SseEmitter streamVideoCall(VideoRequest request);
}第三步:新增视频服务实现类 VideoServiceImpl
java
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import gzj.spring.ai.Request.VideoRequest;
import gzj.spring.ai.Service.VideoService;
import io.reactivex.Flowable;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import java.util.*;
import static com.alibaba.cloud.ai.graph.utils.TryConsumer.log;
@Service
public class VideoServiceImpl implements VideoService {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
/**
* 构建视频请求参数(封装video + fps)
*/
private Map<String, Object> buildVideoParams(VideoRequest request) {
Map<String, Object> videoParams = new HashMap<>(2);
videoParams.put("video", request.getVideoUrl());
videoParams.put("fps", request.getFps());
log.info("视频抽帧配置:fps={} → 每隔{}秒抽取一帧", request.getFps(), 1/request.getFps());
return videoParams;
}
/**
* 视频理解-普通调用(非流式)
*/
@Override
public String simpleVideoCall(VideoRequest request) throws ApiException, NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
// 1. 构建用户消息(视频参数 + 提问文本)
MultiModalMessage userMessage = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(
buildVideoParams(request), // 视频+fps参数
Collections.singletonMap("text", request.getQuestion()) // 提问文本
)).build();
// 2. 构建API请求参数
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(apiKey)
.model("qwen3-vl-plus") // 仅qwen3-vl-plus支持视频理解
.messages(Arrays.asList(userMessage))
.build();
// 3. 同步调用API
MultiModalConversationResult result = conv.call(param);
// 4. 解析返回结果
List<Map<String, Object>> content = result.getOutput().getChoices().get(0).getMessage().getContent();
if (content != null && !content.isEmpty()) {
return content.get(0).get("text").toString();
}
return "未获取到视频理解结果";
}
/**
* 视频理解-流式调用(SSE推送)
*/
@Override
public SseEmitter streamVideoCall(VideoRequest request) {
// 设置超时时间60秒(视频处理耗时可能更长)
SseEmitter emitter = new SseEmitter(60000L);
new Thread(() -> {
MultiModalConversation conv = new MultiModalConversation();
try {
// 1. 构建用户消息
MultiModalMessage userMessage = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(
buildVideoParams(request),
Collections.singletonMap("text", request.getQuestion())
)).build();
// 2. 构建流式请求参数
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(apiKey)
.model("qwen3-vl-plus")
.messages(Arrays.asList(userMessage))
.incrementalOutput(true) // 增量输出(流式)
.build();
// 3. 流式调用API
Flowable<MultiModalConversationResult> resultFlow = conv.streamCall(param);
resultFlow.blockingForEach(item -> {
try {
List<Map<String, Object>> content = item.getOutput().getChoices().get(0).getMessage().getContent();
if (content != null && !content.isEmpty()) {
String text = content.get(0).get("text").toString();
// 推送流式数据到前端
emitter.send(SseEmitter.event().data(text));
}
} catch (Exception e) {
log.error("视频流式推送失败", e);
handleEmitterError(emitter, "流式推送失败:" + e.getMessage());
}
});
// 流式结束标记
emitter.send(SseEmitter.event().name("complete").data("视频理解流结束"));
emitter.complete();
} catch (ApiException | NoApiKeyException | UploadFileException e) {
log.error("视频流式调用API失败", e);
handleEmitterError(emitter, "API调用失败:" + e.getMessage());
} catch (Exception e) {
log.error("视频流式调用未知异常", e);
handleEmitterError(emitter, "系统异常:" + e.getMessage());
}
}).start();
return emitter;
}
/**
* 工具方法:统一处理SSE发射器异常
*/
private void handleEmitterError(SseEmitter emitter, String errorMsg) {
try {
emitter.send(SseEmitter.event().name("error").data(errorMsg));
emitter.completeWithError(new RuntimeException(errorMsg));
} catch (Exception e) {
log.error("处理发射器异常失败", e);
}
}
}总结
-
以下是本次新增通义千问 VL 视频理解接口相关代码的核心总结:
一、代码新增模块与结构
整体延续原有多模态服务的分层设计,新增 4 个核心模块,保持代码风格统一:
-
请求实体类(VideoRequest) :封装视频理解所需参数,包含
videoUrl(视频链接)、fps(抽帧频率)、question(提问文本);通过@NotNull/@DecimalMin/@DecimalMax做参数校验,限定 fps 范围 0.1~10(默认 2.0),避免无效请求。 -
服务接口(VideoService) :定义两类调用方式 ------
simpleVideoCall(非流式)、streamVideoCall(SSE 流式),与原有多模态接口设计一致。 -
服务实现类(VideoServiceImpl) :
- 复用
MultiModalConversation客户端,仅调整消息内容为video + fps参数 Map; - 模型固定为
qwen3-vl-plus(仅该模型支持视频理解); - 流式调用超时设为 60 秒(适配视频抽帧 / 解析的耗时,比图片的 30 秒更长);
- 复用统一的 SSE 异常处理方法
handleEmitterError,保证错误信息标准化推送。
- 复用
-
控制器(VideoController) :暴露
/api/multimodal/video/simple接口,接收VideoRequest参数,调用服务层完成视频理解请求。
二、代码层面关键注意事项
- 模型限制:代码中硬绑定
qwen3-vl-plus模型,不可替换为其他模型(如 qwen-vl 等不支持视频); - 输入限制:
videoUrl仅支持视频文件的直接 HTTPS 链接(如.mp4 格式),非网页链接(如抖音 / B 站的网页 URL); - 异常兼容:捕获
ApiException/NoApiKeyException等通义千问 SDK 异常,与原有多模态异常处理逻辑一致。
三、核心设计亮点
- 参数规范化 :fps 参数添加清晰注释(
每隔1/fps秒抽取一帧),配合校验注解,降低使用错误率; - 逻辑复用性:沿用原有多模态服务的客户端、异常处理、流式推送逻辑,减少重复代码;
- 适配视频特性:针对视频处理耗时更长的特点,调整流式调用超时时间,兼顾性能与稳定性。
三、效果演示
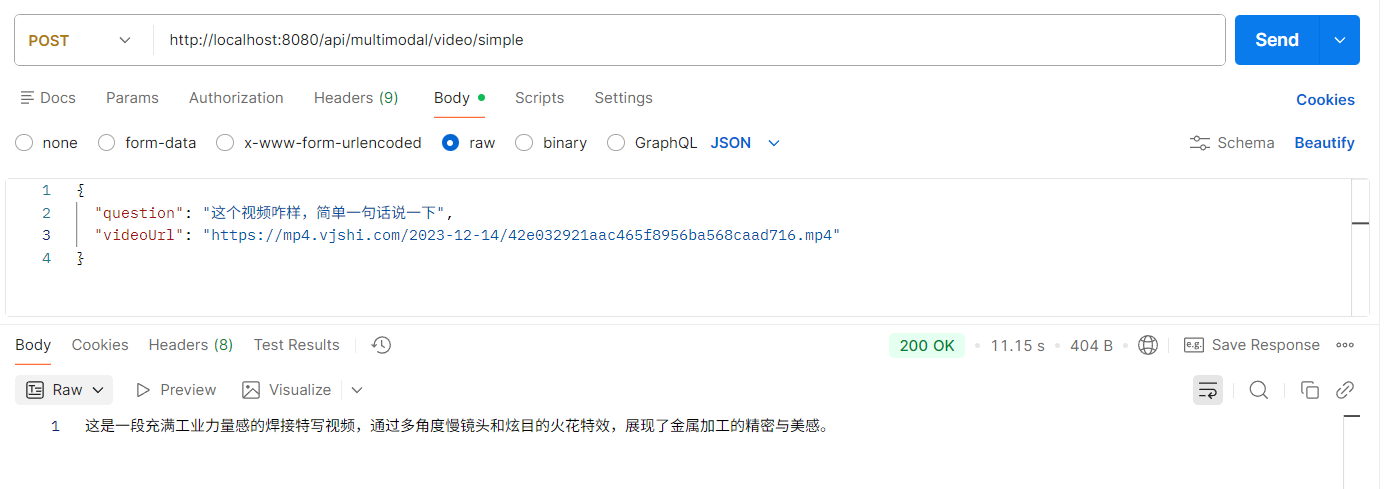
大家注意,视频在线的视频一定要是mp4结尾的,如果是别的格式的视频可能无法解析(加密)
如果觉得这份修改实用、总结清晰,别忘了动动小手点个赞👍,再关注一下呀~ 后续还会分享更多 AI 接口封装、代码优化的干货技巧,一起解锁更多好用的功能,少踩坑多提效!🥰 你的支持就是我更新的最大动力,咱们下次分享再见呀~🌟