基于深度学习的农作物叶片病害智能识别与防治系统
摘要
随着精准农业的发展,农作物病害的快速、准确识别对于保障粮食安全和提高农业经济效益至关重要。本文设计并实现了一套基于 YOLOv8 深度学习模型与现代 Web 技术的农作物叶片病害智能识别系统。该系统采用前后端分离架构,前端基于 Vue 3 和 Element Plus 构建,后端采用 Django 框架,集成了经过微调的 YOLOv8 目标检测算法。实验结果表明,该模型在 PlantVillage 数据集上取得了优异的识别精度,平均精度均值 (mAP) 表现显著。系统不仅实现了病害的实时识别,还结合专家知识库提供了针对性的防治建议,具有较高的实用价值和推广前景。
关键词:深度学习;YOLOv8;图像识别;植物病害;Vue 3;Django
1. 引言
1.1 研究背景
传统的植物病害诊断主要依赖农业专家的现场考察和经验判断,这种方式存在效率低、主观性强、专家资源稀缺等问题。近年来,计算机视觉技术的飞速发展为农业智能化提供了新的解决方案。特别是卷积神经网络 (CNN) 在图像分类和目标检测任务中的突破性表现,使得基于图像的自动化病害诊断成为可能。
1.2 研究意义
开发一套高精度、易使用的病害识别系统,能够帮助缺乏专业知识的普通农户及时发现病害,减少农药滥用,降低生产损失。同时,系统积累的历史数据和病害分布情况,可为农业部门的宏观决策提供数据支持。
1.3 本文工作
本文的主要贡献如下:
- 构建了基于 YOLOv8 的高性能病害识别模型,并在 PlantVillage 数据集上进行了训练与评估。
- 设计了基于 Django 和 Vue 3 的全栈 Web 系统,实现了从图像上传、推理分析到结果展示的完整业务流程。
- 建立了结构化的病害知识库,实现了识别结果与防治方案的智能关联。
2. 材料与方法
2.1 数据集
2.1.1 数据来源
本研究使用的数据集源自公开的 PlantVillage 数据库。该数据集包含数万张在受控环境和田间拍摄的健康与病害作物叶片图像,涵盖了苹果、玉米、葡萄、马铃薯等多种常见经济作物。
2.1.2 数据预处理与分布
为提高模型的泛化能力,数据集经过了清洗和整理。类别涵盖如下(部分列举):
- 苹果 (Apple): 黑星病、黑腐病、锈病、健康
- 玉米 (Corn): 灰斑病、锈病、叶斑病、健康
- 葡萄 (Grape): 黑腐病、轮斑病、褐斑病、健康
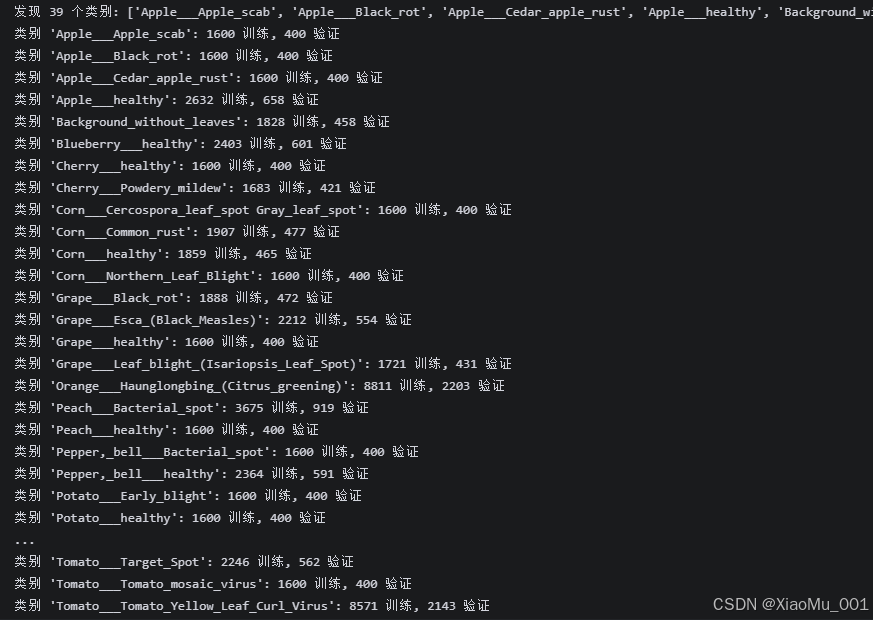
图 1:数据集各类别样本数量分布
在实验中,数据集被随机划分为训练集、验证集和测试集(比例约为 8:1:1),以确保模型评估的客观性。
2.2 深度学习模型构建
本系统采用 YOLOv8 (You Only Look Once version 8) 作为核心识别算法。YOLOv8 是目前最先进的一阶段目标检测模型之一,在保持高推理速度的同时,显著提升了检测精度。
2.2.1 模型架构
YOLOv8 的网络结构在 YOLOv5 的基础上进行了深度优化,主要由以下三部分组成:
-
Backbone (主干网络) : 采用改进的 CSPDarknet 结构。
- C2f 模块: 引入了 C2f (CSP Bottleneck with 2 convolutions) 模块替代了 YOLOv5 中的 C3 模块。C2f 模块借鉴了 ELAN 的设计思想,通过更多的跳跃连接(Skip Connections)和并行分支,丰富了梯度流,从而在保持轻量化的同时显著增强了特征提取能力。
- SPPF (Spatial Pyramid Pooling - Fast): 在主干网络末端使用 SPPF 模块,通过多尺度池化操作扩大感受野,使模型能够更好地捕捉全局上下文信息。
-
Neck (颈部网络) : 采用 PANet (Path Aggregation Network) 结构。
- 双向特征金字塔: 结合了 FPN (Feature Pyramid Network) 的自顶向下路径和 PANet 的自底向上路径。这种结构能够有效地将高层的语义特征与底层的定位特征进行融合,对于识别不同尺度的病斑(尤其是微小病斑)至关重要。
-
Head (检测头) : 采用 Decoupled Head (解耦头) 结构与 Anchor-Free 策略。
- 解耦设计: 传统的 YOLO 系列通常使用耦合头(Coupled Head),即分类和回归共享卷积层。YOLOv8 将分类任务和边界框回归任务解耦,分别通过两个独立的卷积分支进行处理。这种设计消除了两个任务之间的潜在冲突,提高了模型的收敛速度和检测精度。
- Anchor-Free: 摒弃了基于 Anchor 的设计,直接预测目标的中心点和宽高。这不仅减少了超参数(如 Anchor 尺寸、比例)的调整工作,还提高了模型对不规则形状病斑的泛化能力。
2.2.2 损失函数
模型训练采用了复合损失函数策略,针对分类和回归任务分别进行了优化:
- 分类损失 (Classification Loss) : 使用 VFL (Varifocal Loss)。VFL 是一种针对密集目标检测设计的损失函数,它通过不对称的加权方式,降低了负样本(背景)的权重,聚焦于难分类的正样本,有效解决了正负样本极端不平衡的问题。
- 回归损失 (Regression Loss) : 结合了 CIoU Loss 和 DFL (Distribution Focal Loss) 。
- CIoU Loss: 在 IoU 的基础上引入了中心点距离和长宽比的惩罚项,使得预测框能够更快地回归到真实框。
- DFL: 针对边界框位置的不确定性,DFL 将边界框的回归问题转化为概率分布预测问题,通过优化边界框的分布,使得模型在边界模糊的病斑检测中表现更佳。
3. 系统设计与实现
3.1 系统架构
系统采用经典的 B/S (Browser/Server) 架构,遵循 MVC (Model-View-Controller) 设计模式,实现了前后端分离开发与部署。
3.1.1 前端设计 (Frontend)
前端基于 Vue 3 框架开发,采用 Composition API 风格,提升了代码的复用性和可维护性。
- 构建工具 : 使用 Vite 作为构建工具,利用其基于 ES Modules 的热更新机制,显著提高了开发效率。
- UI 组件库 : 集成 Element Plus,定制了适应农业场景的主题色(如翡翠绿),实现了响应式布局,确保系统在 PC 端和移动端均有良好的交互体验。
- 数据交互 : 封装 Axios 拦截器,统一处理请求头(如 JWT Token 注入)和响应错误(如 401 未授权自动跳转登录),增强了系统的健壮性。
- 数据可视化 : 引入 ECharts 图表库,将病害识别历史和统计数据以饼图、柱状图等形式直观展示,帮助用户快速理解数据。
3.1.2 后端设计 (Backend)
后端基于 Django 4.x 全栈框架,结合 Django REST Framework (DRF) 构建 RESTful API。
- API 设计 : 使用 DRF 的
ModelViewSet快速生成符合 REST 规范的 CRUD 接口,并通过Serializer实现复杂数据模型(如嵌套的病害详情)的序列化与反序列化。 - 认证鉴权 : 采用 SimpleJWT 实现基于 Token 的身份认证机制。用户登录后获取 Access Token 和 Refresh Token,实现了无状态的会话管理,提高了系统的扩展性。
- 跨域处理 : 配置
django-cors-headers中间件,解决前后端分离架构下的跨域资源共享 (CORS) 问题。 - AI 模型集成 : 封装 YOLOv8 推理服务,通过 Python SDK 加载训练好的权重文件 (
best.pt)。为提高响应速度,模型在系统启动时预加载至内存,并在接收到图片上传请求时进行实时推理,返回包含类别、置信度及建议的 JSON 数据。
3.2 数据库设计
系统核心数据表设计如下,采用关系型数据库进行存储,保证了数据的一致性和完整性。
3.2.1 用户表 (auth_user)
基于 Django 内置认证系统,扩展用户管理功能。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | Integer | 主键 ID |
| username | Varchar(150) | 用户名 |
| password | Varchar(128) | 加密密码 |
| Varchar(254) | 电子邮箱 | |
| date_joined | DateTime | 注册时间 |
3.2.2 病害知识库表 (api_diseaseinfo)
存储病害的百科信息,用于识别后的关联展示。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | Integer | 主键 ID |
| name | Varchar(100) | 病害英文标识 (模型标签) |
| display_name | Varchar(100) | 中文显示名称 |
| description | TextField | 病害综述 |
| symptoms | TextField | 典型症状 |
| treatment | TextField | 治疗方案 |
| prevention | TextField | 预防措施 |
3.2.3 识别记录表 (api_recognitionrecord)
记录用户的历史识别操作,用于追溯和统计。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | Integer | 主键 ID |
| image | ImageField | 上传的叶片图像 |
| result | Varchar(255) | 识别结果 |
| confidence | Float | 置信度 (0-1) |
| created_at | DateTime | 识别时间 |
4. 实验结果与分析
4.1 训练过程分析
模型在 GPU 服务器上进行了多次迭代训练。训练过程中的各项指标变化如图 2 所示。
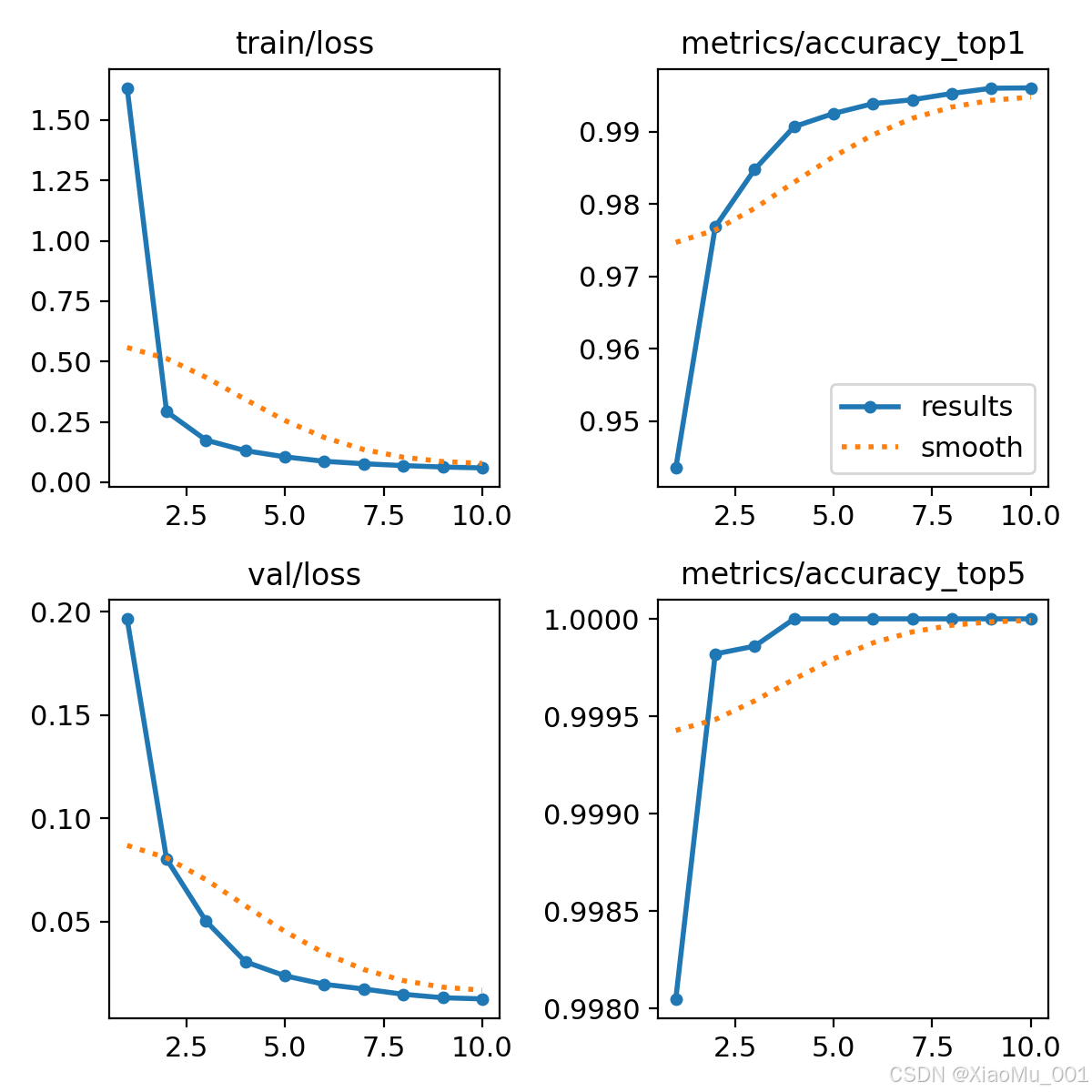
图 2:训练过程中的损失与精度曲线
从图中可以看出:
- 损失收敛: Box Loss 和 Cls Loss 随着 Epoch 的增加呈显著下降趋势,且在后期趋于平稳,表明模型已充分拟合数据。
- 精度提升: Precision (精确率) 和 Recall (召回率) 稳步上升。
- mAP 指标: mAP50 和 mAP50-95 均达到了较高水平,证明模型在不同 IoU 阈值下均表现出鲁棒的检测性能。
4.2 混淆矩阵分析
为了更细致地评估模型对各类病害的区分能力,我们绘制了混淆矩阵。
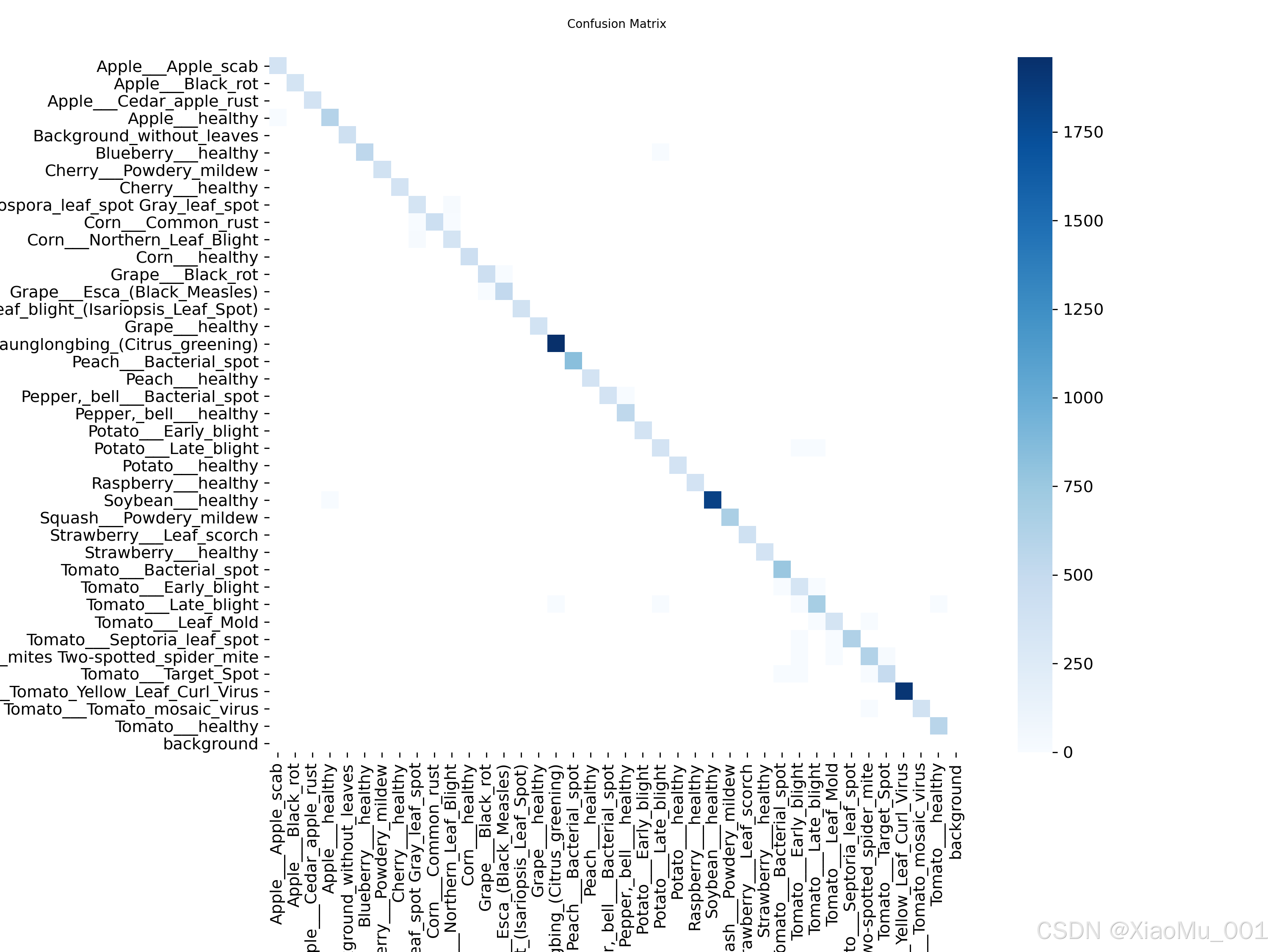
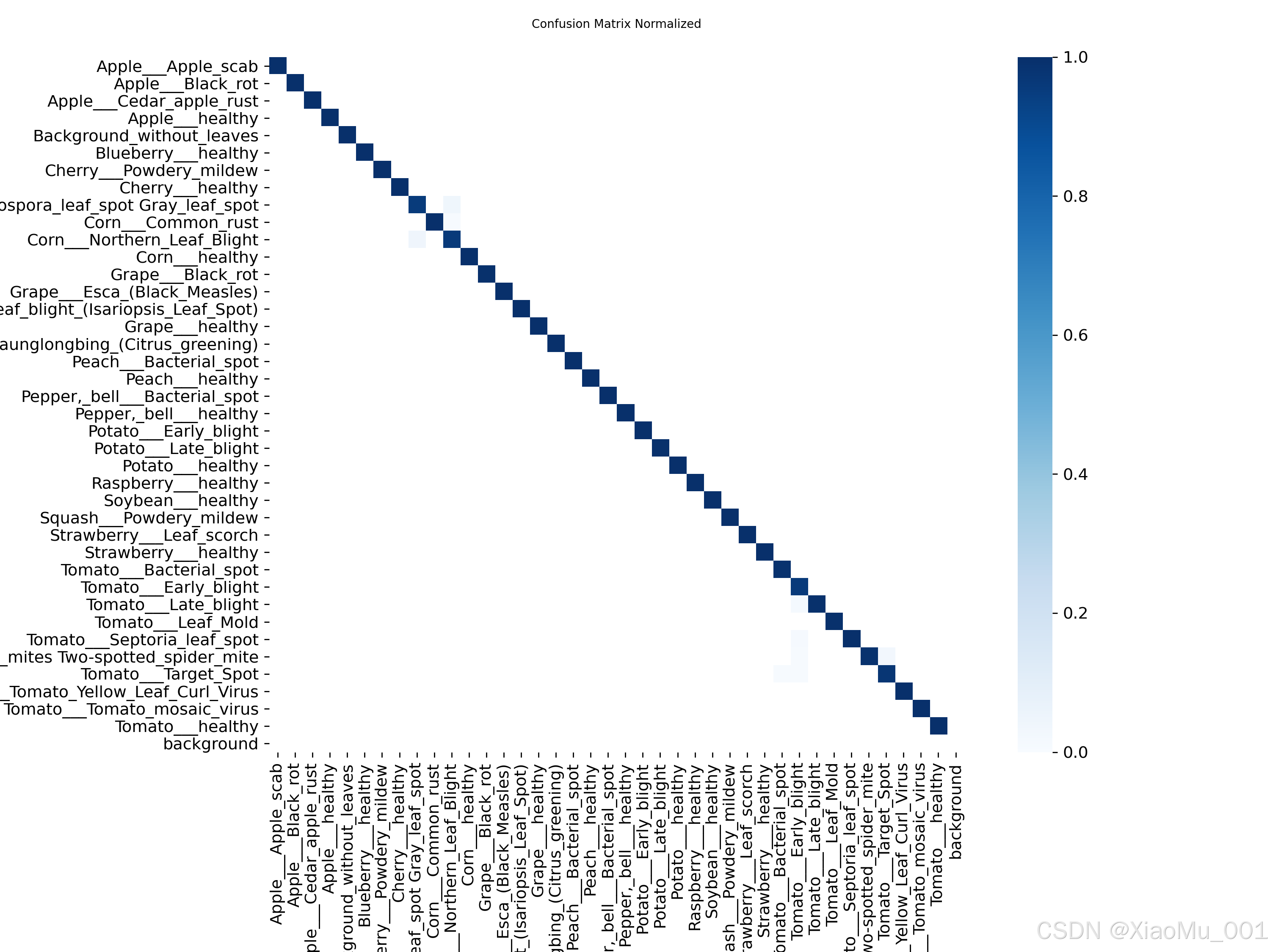
rithm%2Fconfusion_matrix_normalized.png&pos_id=img-nblnBIyv-1765594121479)
图 3:混淆矩阵与归一化混淆矩阵
分析图 3 可知:
- 对角线主导: 绝大多数样本主要集中在对角线上,颜色较深,说明模型在大部分类别上的预测结果与真实标签一致。
- 误判分析: 非对角线区域数值极低,表明模型极少发生类别间的混淆,具有极高的分类特异性。
4.3 实际样本测试
在验证集上的随机采样测试结果如图 4 所示。

图 4:验证集样本实际预测效果
可视化结果显示,模型能够准确框定叶片中的病斑区域(如有)或识别整叶状态,并给出高置信度的分类标签,验证了模型的实际应用能力。
5. 系统功能展示
系统界面设计遵循现代 UI/UX 原则,注重用户体验。
5.1 核心功能
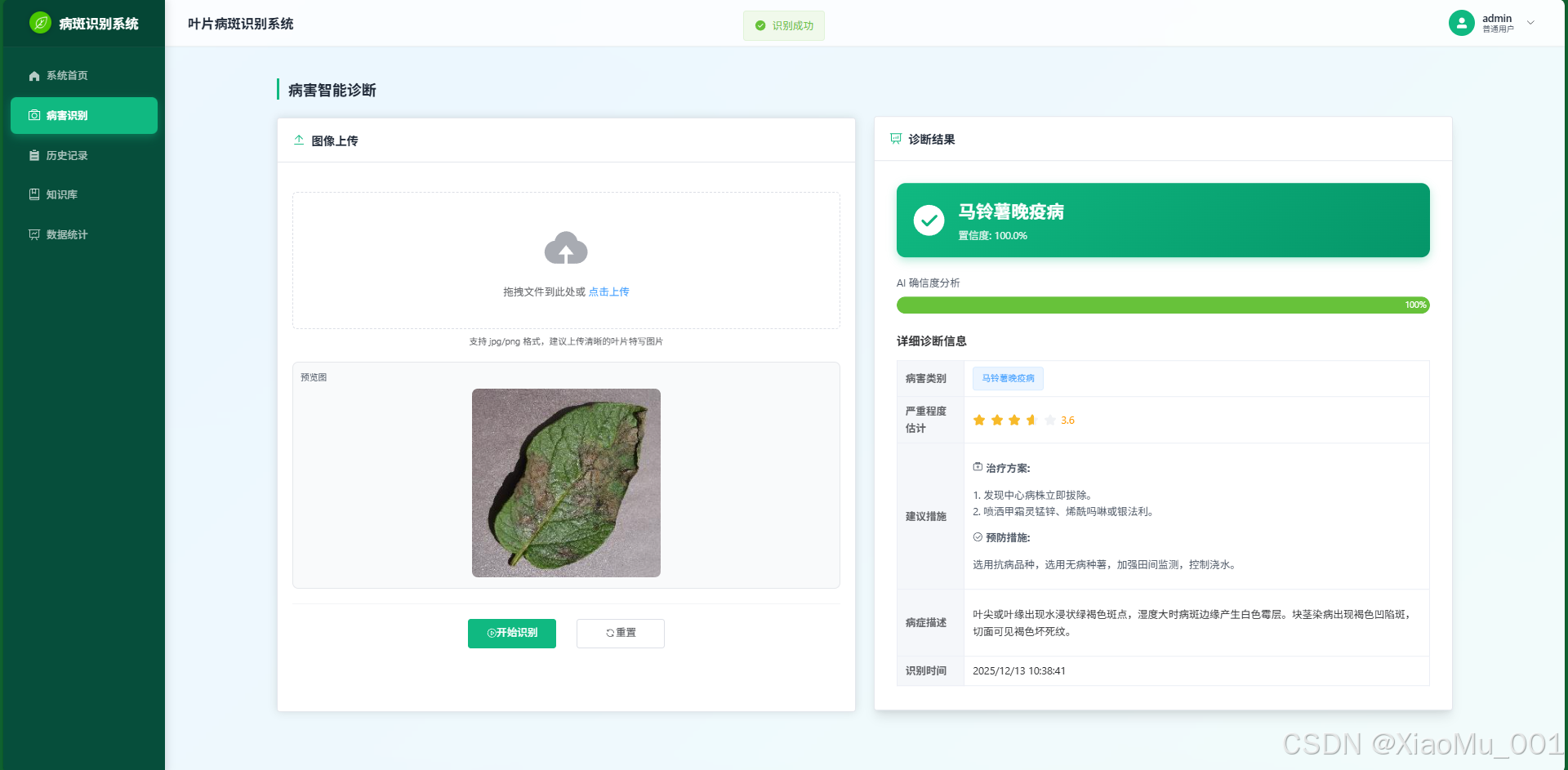
-
病害识别 : 支持拖拽上传,集成扫描动画,提供实时的识别反馈与防治建议。
-
历史追溯 : 自动保存识别记录,支持按时间、结果进行筛选和回溯。
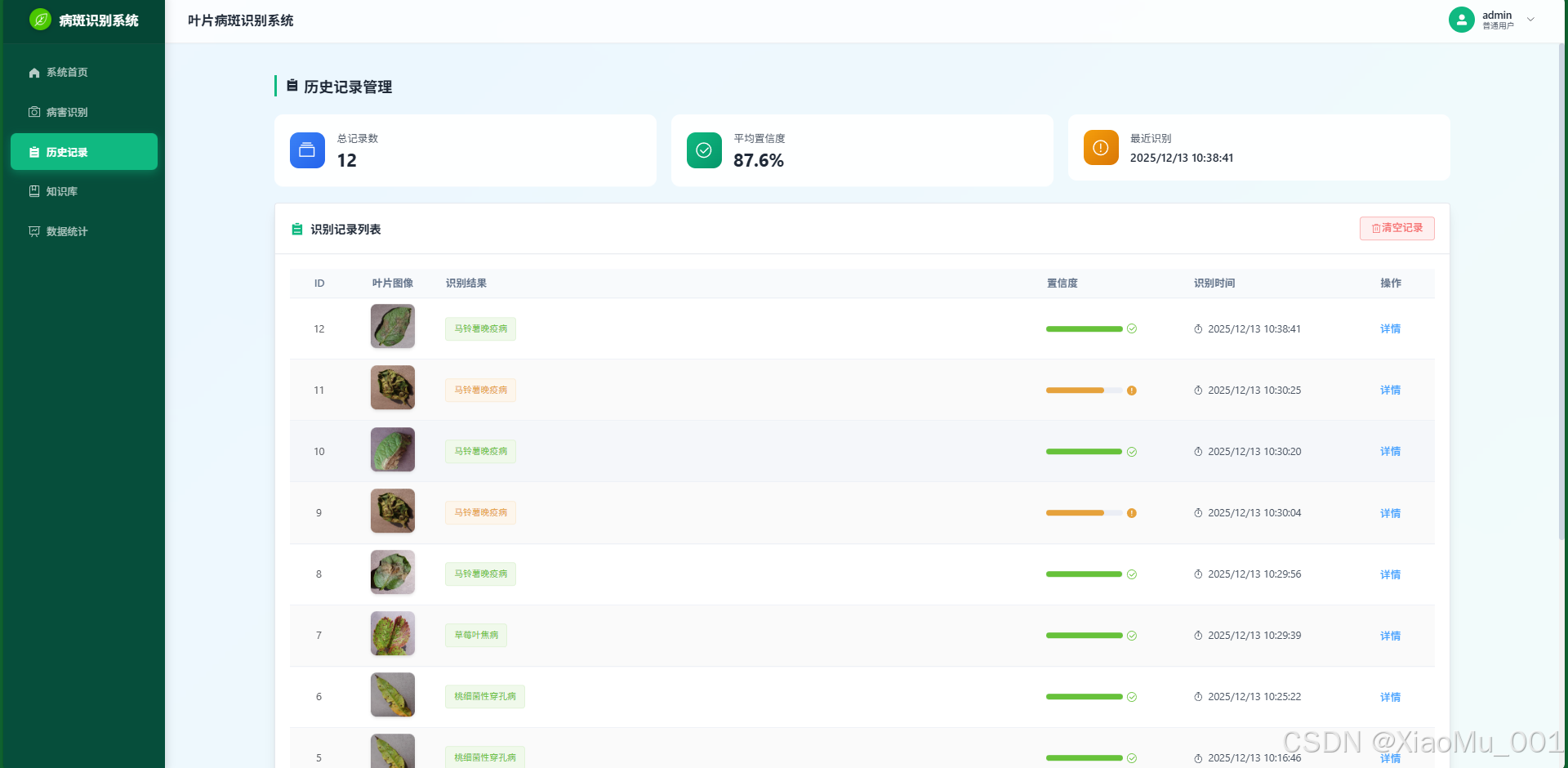
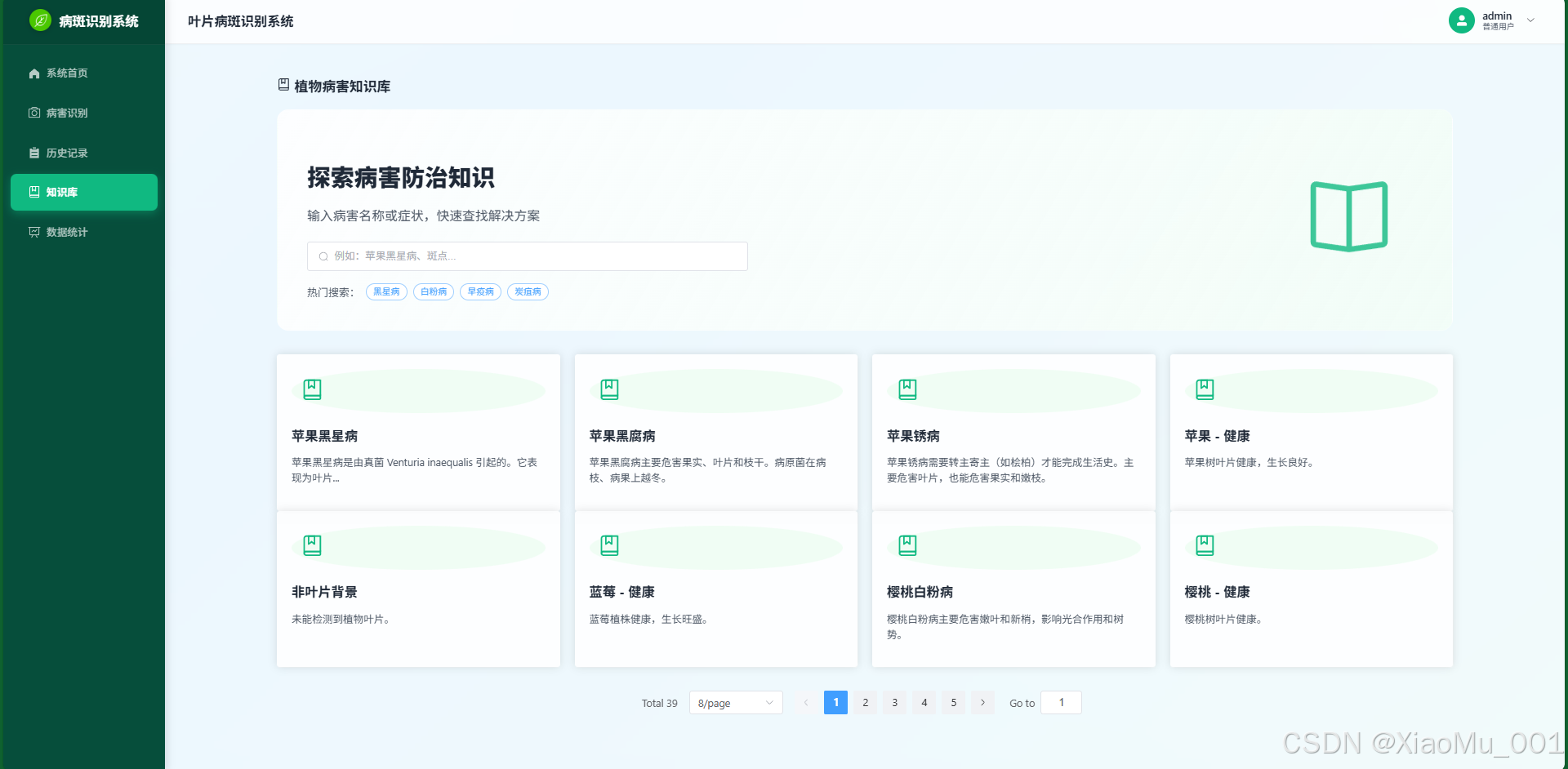
-
知识图谱 : 内置详细的病害百科,支持关键词搜索和热门标签索引。
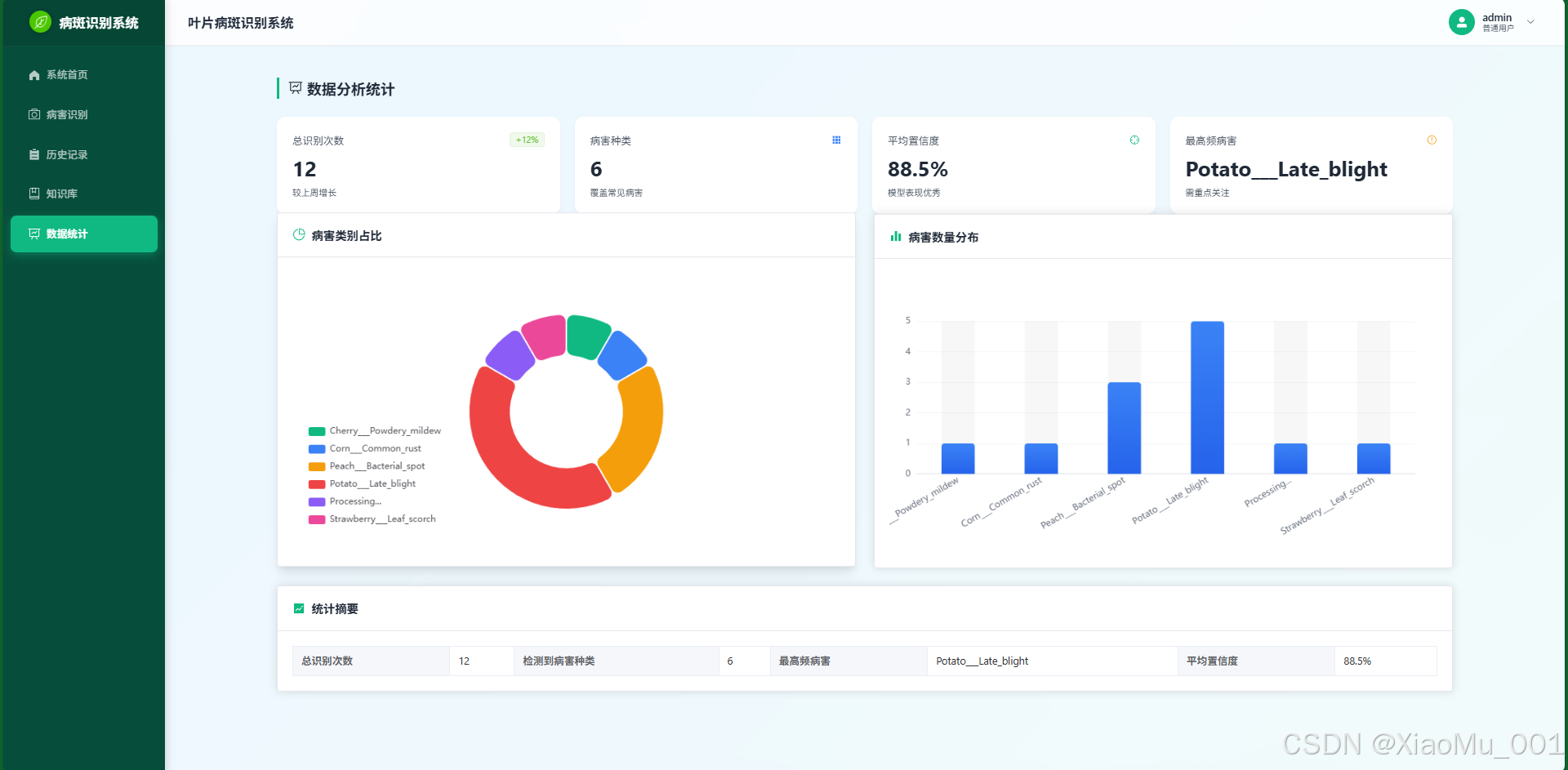
5.2 数据可视化
- 统计分析 : 仪表盘通过图表展示病害发生趋势和类别占比,辅助农业决策。
6. 结论
本文提出并实现了一种基于 YOLOv8 的农作物叶片病害识别系统。通过深度学习算法与 Web 开发技术的深度融合,解决了传统病害诊断中的诸多痛点。实验结果验证了算法的高效性与准确性,系统测试表明了其功能的完备性与易用性。未来工作将集中在扩充数据集以涵盖更多作物种类,以及优化模型在移动端设备的部署性能。