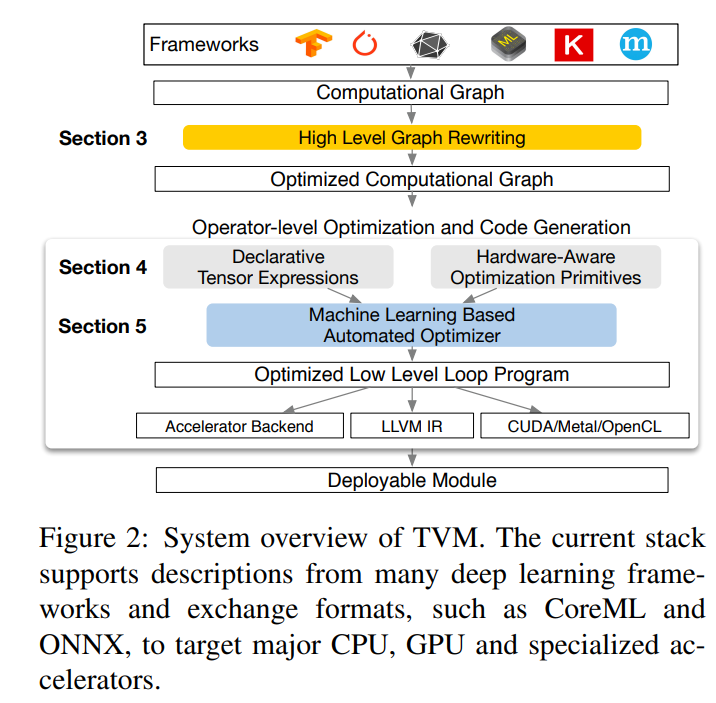
TVM can process graph-level and operator-level optimization.
graph-level optimization
As for the graph-level optimization, it can do operator fusion, constant folding, static memory pre-allocation, and data transformate pass.
operator fusion
Now I want emphasis operator fusion, It split the operator into 4 type:
- injective (one on one map, e.g., add)
- reduction
- complex out fusable(can fuse element-wise op to output)
- opaque(can't be fused, e.g., sort)
TVM will fuse as much as possible.
These optimization methods are very common.
Operator-level Optimization
TVM seperate schedule and compute. So it can detribute different devices. There are 3 schedule primitives in TVM, Special Memory Scope, Tensorizaiton, Latency Hiding.
- Special Memory Scope, to utilize maxmium the shaped memory in GPU.

- Tensorization, spliting a bigger data into micro-data to fully utiize the vectorization.

- Latency Hiding. Overlaping the computation and transition. On CPU, it is achieving by using multi-threading or hardward prefetching. GPU relys on repid context switching of many wraps of threads.
Automating Optimization
How to find the optimal parameter is very important. It proposed a ML-based cost model, which is a gradient tree boosting model based on XGboost, to predict these prameters by giving the loop pragram in the kernel, which include the memory access count, and the resue ratio of each memory buffer, as well as one-hot encoding of loop annotation such as "vectorize", "unroll" and "parallel". As shown in the following graph, the collected data can be train the model again. So the TVM matainer will updated this model periodicly.
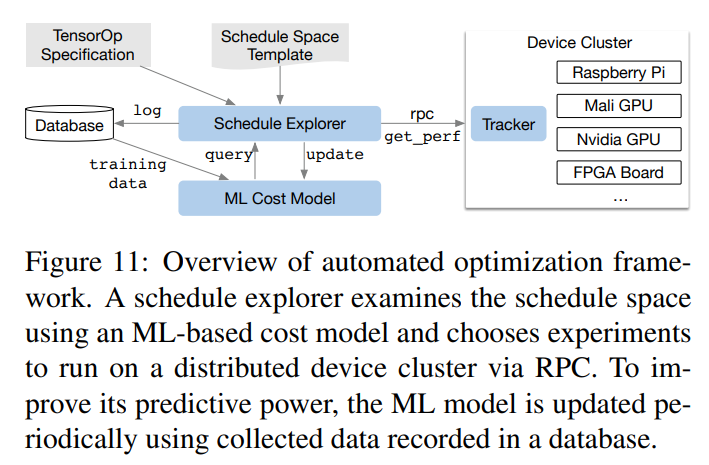
Consequently, TVM lowers the threshold for writing a relavely high-performance kernel. I think there are 2 points deserved us to learn more, which are the schedule primitive and the prediction model.