你有没有想过, 大模型世界里只有数字, 它是怎么知道 "狼" 和 "狗" 差异明显, "狗" 和 "犬" 意思相近的呢?
今天我们不谈复杂的句子理解, 只聚焦语言最基础的单元: 单个词.
我是印刻君, 一位探索 AI 的前端程序员, 关注我, 让 AI 知识有温度, 技术落地有深度.
计算机不认识文字, 只认识数字. 所以, 第一步是把文字变成数字. 最直接的方法, 就是给每个词 (Token) 分配一个唯一编号, 这就是 Token ID.
严格来说, Token 是介于二者之间的 "子词", 但这不影响核心逻辑.
相关细节, 可以阅读我的另一篇文章: Token 到底怎么"变"的? 大模型分词的核心逻辑
以中文轻量级模型 BAAI/bge-small-zh 为例:
| Token | Token ID |
|---|---|
| 犬 | 4305 |
| ... | ... |
| 狗 | 4318 |
| ... | ... |
| 狼 | 4331 |
单看编号, "狼" 和 "狗" 相差 13, "狗" 和 "犬" 也相差 13 ------ 从数字上看二者关系完全对等. 但我们都知道, "狼" 很凶猛, "狗" 很忠诚, "犬" 则是 "狗" 的同义词.
这暴露了 Token ID 的本质缺陷: Token ID 只是一个代号, 它本身不包含任何语义信息.
就像图书馆的图片编号, 你能靠它知道一本书的位置, 却不能靠它知道书的内容.
大模型想理解语言, 必须找到一种让数字承载意义的方法, 而这个方法就是 ------ 词向量.
一、什么是词向量?
简单来说, 词向量是一串多维度的数字序列 (向量), 每个维度对应语义的一个抽象特征, 合起来就是词语在语义空间中的 "坐标".
关于向量, 可以阅读我的另一篇文章: 不再费脑,写给爱好者的 AI 向量 (Vector) 入门课
它不再是单个数字, 而是一长串数字. 比如, 在 BAAI/bge-small-zh 中, "狗" 被表示为 512 维的向量, 前几个维度的数值如下:
python
[
0.039581298828125,
-0.004741668701171875,
0.0285797119140625,
-0.03558349609375,
-0.03662109375,
# ... 省略剩余 507 个维度
]这个高维语义空间有两个神奇的特性:
- 语义相近, 坐标相近: 狼" 和 "狗" 的距离较远, "狗" 和 "犬" 的距离极近;
- 向量运算模拟语义关系 : 最经典的例子就是:
vector('国王') - vector('男人') + vector('女人') ≈ vector('女王'), 完全符合人类的语义认知.
这是怎么实现的呢? 这些 "坐标" 不是人类手动设计的, 而是计算机从海量文本中 "自学" 而来的 ------ 核心方法就是玩一场超大规模的 "完形填空游戏".
二、学习的秘密: 分布假说与神经网络
计算机能学会词向量, 核心支撑有两个:一是语言学的 "分布假说", 二是作为 "学习工具" 的神经网络.
2.1 分布假说: 词的含义由上下文决定
这是词向量技术的思想源头, 语言学家早在几十年前就提出: 一个词的含义, 由它周围经常出现的词决定.
比如 "狼" 常出现在 "草原"、"群居"、"凶猛" 旁边, "狗" 常出现在 "宠物"、"忠诚"、"汪汪" 旁边, 这些上下文差异, 最终会体现在词向量的坐标上.
2.2 神经网络: 学习语义的 "数字大脑"
要让计算机理解分布假说, 需要一个能处理复杂规律的 "大脑"------ 神经网络. 它的基本单元是神经元, 可以理解为一个微小的信息处理站

- x1, x2, x3 是 "输入", 接收来自其他神经元的信号;
- w1, w2, w3 是每条输入的 "权重 (重要性系数)", 比如 w3 大, 说明这个神经元更关注 x3 的信号;
- 中间的圆圈是神经元本身
这个神经元只做两件事:
- 加权求和: 把每个输入乘以对应的权重, 然后加起来. 即 x1w1 + x2w2 + x3w3.;
- 激活: 对加权求和做非线性转换.
这里的非线性是关键 ------ 如果没有激活函数, 无论多少层神经网络, 都等价于简单的线性计算(输出 = a * 输入 + b), 永远学不会语言的复杂规律.
【语言是非线性的】
比如 "单身狗" 这个词, 如果按照线性的理解, 它应该是 "单身" + "狗", 也就是没有伴侣的狗. 但它的真实意思是指"单身的人", 这种语义的 "化学反应", 只有非线性系统才能捕捉.
常见的两种激活函数, 一个是 Sigmoid, 一个是 ReLU.
当大量神经元通过权重连接成网络, 就像一张巨大的 "信息交通网":
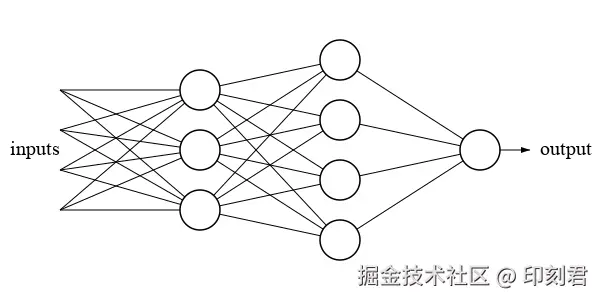
- 神经元是 "路口", 负责信息的中转和计算;
- 权重是 "道路", 权重高是 "高速公路", 信息传递快; 权重低是 "乡间小道", 信息传递慢.
训练模型的过程, 本质就是调整这张 "交通网" 的道路宽窄 (权重), 让信息流动符合语言规律 ------ 而权重就是模型的 "知识", 所有学到的语义规则, 最终都以数字形式存储在权重矩阵里.
三、训练之旅:从混沌到有序的 "猜词游戏"
有了 "大脑" 和 "学习原理", 接下来就是核心的训练过程 ------ 让模型玩亿万次 "完形填空", 从完全无知的 "文盲" 变成懂语义的 "语言大师". 整个过程分为四个阶段:
3.1 随机初始化
训练开始前, 神经网络的所有权重、词向量表中每个词的坐标, 都是随机赋值的. 此时在多维的语义空间里, 词语的位置完全混乱: "好" 可能离 "石头" 很近, 离 "棒" 很远, 没有任何语义规律.
之所以选择随机初始化, 是为了打破 "对称性"------ 如果所有参数初始值相同, 后续调整时所有参数会同步变化, 模型永远学不会不同词语的特征差异.
3.2 疯狂做题(前向传播)
模型开始处理海量文本, 但不会一次性读完, 而是用 "滑动窗口" 技巧: 想象模型拿着一个固定长度的框,沿着句子逐格滑动, 每次只聚焦局部上下文, 生成一道 "完形填空" 题
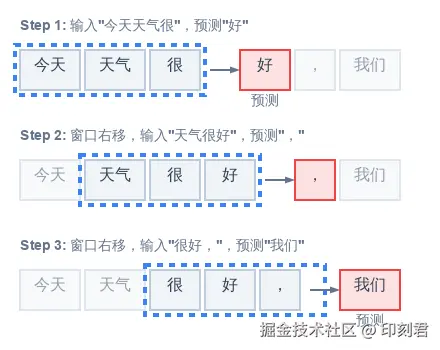
比如句子 "今天天气很好, 我们去公园", 滑动窗口会生成 "今天天气真___"、"天气真___, 我们" 等题目. 模型将上下文词语的随机向量输入神经网络 (前向传播), 最终输出对空缺词的 "猜测"------ 此时的猜测完全是随机的, 正确率极低.
3.3 评分裁判 (Softmax)
模型不会只给出一个答案,而是给词表中所有词打 "原始分数". 这时需要 Softmax 函数充当 "裁判",把分数转换成概率
P(yi)=∑j=1Kezjezi
它的核心作用有两个:
- 放大差距 : 通过指数函数 ex, 让分数高的词, 转换的概率也高, 放大了高分词的优势 (赢家通吃);
- 归一化: 所有词的概率加起来等于 1
3.4 纠错反馈 (反向传播与梯度下降)
这是训练最关键的一步: 我们告诉模型 "正确答案是'好'", 模型的预测与正确答案的差距就是 "损失值".
接下来, 反向传播算法会从输出层往输入层回溯, 计算每个权重对这次错误的 "责任" (梯度); 然后用梯度下降算法微调权重:
新权重=旧权重−学习率∗梯度
于是, 算法会严厉地告诉模型: "猜错了!所有指向错误答案 '石头' 的连接都弱一点, 所有指向正确答案 '好' 的连接都强一点. "
四、涌现的奇迹: 语义规律自发生成
经过亿万次 "刷题-纠错", 奇迹发生了: 原本混乱的语义空间, 被塑造成符合人类认知的样子:
计算机脑中那张原本随机的 "词向量地图", 被慢慢塑造成了我们所期望的样子:
- 近义词(好 / 棒 / 优秀)因为常出现在相似上下文, 坐标逐渐靠近;
- 语义关系(国王 - 男人 + 女人≈女王)自然而然形成
这就是人工智能领域的 "涌现"------ 没有人为设计任何语义规则, 仅仅通过简单的局部反馈 (猜词、纠错), 宏观上就自发形成了高度有序的语义结构
五、黑盒与炼丹: 无法解读的维度
尽管词向量能精准表达语义, 但我们盯着 "狗" 的向量 [0.039581298828125, -0.004741668701171875, ...] 时,却无法给每个维度下定义.
第一维是 "宠物" 吗? 第二维是 "忠诚" 吗? 可以说 "是", 也可以说都不是 ------ 每个维度都是多个抽象特征的混合体.
这是因为神经网络为了最小化预测错误, 会自动找到最高效的坐标系, 这个坐标系适合模型计算, 却完全不符合人类的理解习惯. 这也是深度学习被称为 "黑盒"、调参被戏称为 "炼丹" 的核心原因.
六、总结: 从 "教规则" 到 "找规律" 的范式革命
词向量的诞生, 代表了人工智能理解语言的核心思想转变:
- 过去, 我们试图把人类知识翻译成规则教给计算机.
- 现在, 我们设计简单的游戏规则 (猜词)和反馈机制(反向传播), 让计算机从海量数据中自己发现语义规律.
那些最初毫无意义的随机数字, 在亿万次训练的 "锻造" 下, 最终变成了承载人类语言意义的精密 "坐标", 而这就是词向量.
回到文章开头的问题, 大模型如何分辨 "狼" 与 "狗". AI 没有被灌输任何关于 "狼" "狗" "犬" 的具体规则, 是靠数据驱动的方式, 在高维空间里为这些词语找到了符合人类认知的坐标.
即便这些坐标的每一个维度都无法被人类精准定义. 但这恰恰是其强大之处.
AI 没有被人类的认知边界束缚,而是找到了最适合自身理解语言的方式.
我是印刻君, 一位探索 AI 的前端程序员, 关注我, 让 AI 知识有温度, 技术落地有深度.
补充说明: 现代 LLM(如 GPT)的训练过程比这更复杂, 词向量层是与整个模型一起端到端训练的. 但将词向量理解为猜词任务的"副产品", 但将词向量理解为猜词任务的"副产品", 仍然是理解其本质的有效方式.
附录: 查看 "狼" "狗" "犬" 的词向量
如果你想直观看到一个词在模型中的 "数字形态", 可以运行以下 Python 代码, 打印 BAAI/bge-small-zh 模型中 "狼" "狗" "犬" 的 Token ID 和词向量:
python
from transformers import AutoTokenizer, AutoModel
model_name = "BAAI/bge-small-zh"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
model.eval()
target_text = "狼"
inputs = tokenizer(
target_text,
return_tensors="pt",
add_special_tokens=False
)
token_ids = inputs["input_ids"][0]
tokens = tokenizer.convert_ids_to_tokens(token_ids)
embedding_layer = model.get_input_embeddings()
token_embeddings = embedding_layer(token_ids)
print("="*50)
print(f"查询文本: {target_text}")
print("="*50)
for idx, (token, token_id) in enumerate(zip(tokens, token_ids)):
print(f"\n【Token {idx+1}】")
print(f"字符/Token: {token}")
print(f"Token ID: {token_id.item()}")
print(f"词向量(前10维): {token_embeddings[idx][:10].tolist()}")
print(f"词向量维度: {token_embeddings[idx].shape[0]}")