上一篇我们测试了在"裸金属节点"上的Kafka集群部署,本篇我们将利用Portainer和Docker swarm集群进行Kafka集群的一键部署。
一、Docker 部署
Docker的部署本来是件简单事,但一方面是centos没了,直接yum就不大行了;另一方面,有墙了以后拉镜像这件事就复杂了起来,从一开始的时通时不通,到后来魔法加持下也时通时不通,到现在基本就是各种不通了。
所以,这篇集中解决这两方面问题:
1. Docker-ce安装
使用华为云提供的镜像站点
在容器类标签页里就对应有Debian/Ubantu和CentOS/Fedora上Docker-ce的安装方法:
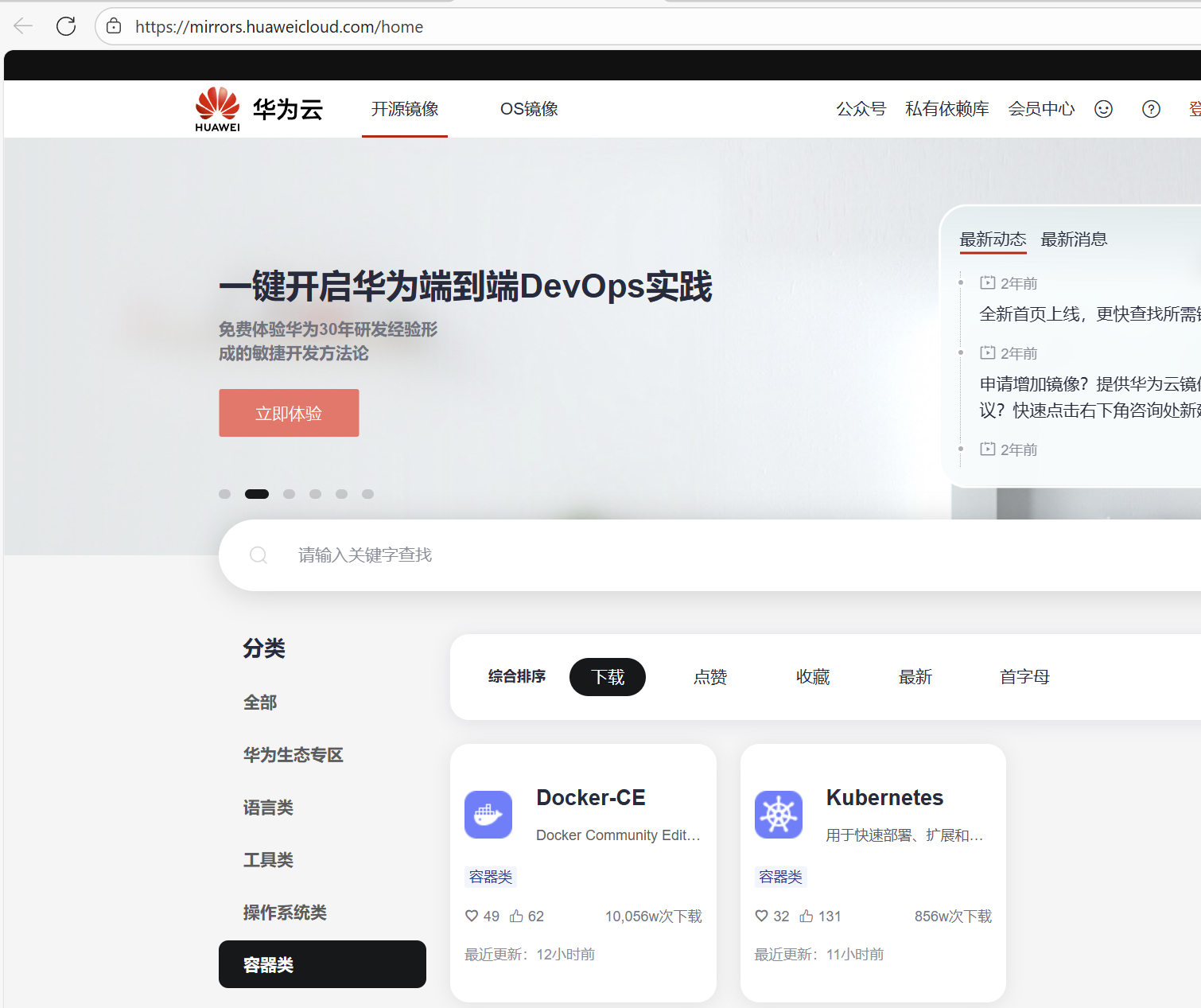
照做就是看,先确保系统自带的docker/podman是被卸载的状态,然后下载repo,更改镜像源,安装......
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo
sudo sed -i 's+download.docker.com+mirrors.huaweicloud.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
yum makecache
yum install docker-ce2. 拉取镜像
在当前情况下,直接使用docker pull是不行的,因为docker.hub.com被挡在外面,直接拉取,多半会得到这么一句:
Error response from daemon: Get "https://registry-1.docker.io/v2/": dial tcp 108.160.163.116:443: i/o timeout当然,这是DNS解析成功的情况下;解析不成功的话,也有可能冒号后面是个别的啥原因------别怀疑,除了没有login(多数情况下不需要),基本一定是撞墙了。这时有简单快速和复杂但托底的两种方法:
(1)指定镜像源
简单来说,啥也不用修改,直接指定从国内镜像源拉取。docker pull命令本身就支持这么干,即在镜像前再加一层"/"指定镜像源:
[root@node4 ~]# docker pull docker.1ms.run/hello-world
Using default tag: latest
latest: Pulling from hello-world
17eec7bbc9d7: Pull complete
Digest: sha256:f7931603f70e13dbd844253370742c4fc4202d290c80442b2e68706d8f33ce26
Status: Downloaded newer image for docker.1ms.run/hello-world:latest
docker.1ms.run/hello-world:latest
[root@node4 ~]# 这样拉取的镜像会在镜像名称前也携带镜像源的名称:
[root@node4 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
clickhouse/clickhouse-server head-alpine b6ed8f160e84 2 weeks ago 718MB
clickhouse/clickhouse-keeper head-alpine 125d5acd6e3b 2 weeks ago 488MB
docker.1ms.run/hello-world latest 1b44b5a3e06a 3 months ago 10.1kB
docker.m.daocloud.io/bitnami/kafka latest 43ac8cf6ca80 4 months ago 454MB如果嫌用起来麻烦,可以使用docker image tag命令赋予别名,这样用起来就方便了。注意tag并不是改名,更像是软链接。
不过,国内镜像源虽然很多,但活跃的却不太好找,一些曾经比较著名的,也不明原因的逐渐不能用了。目前还活跃的,亲测能用的1ms.run,m.daocloud.io,就这两。
(2)代理
使用国内镜像源的方式虽然简单,但也受非官方镜像源不稳定影响,以及镜像库不够全面的原因,用起来总还是略有一些不方便的。所以,如果有魔法加持的话,还是可以尝试一下直接官方的。不过即使魔法加持下,也还是有一些需要注意的事项:DNS解析路径和DOCKER服务路径,配少一个,docker pull时仍然会出错,而且是一些更稀奇古怪的错误:
DNS
由于我们实验时采用windows中的vmware来模拟裸金属服务器,即使外部有局域网代理服务加持,虚拟机操作系统进行域名查询时,默认仍使用vmware NAT网络给定的网关,当使用该网关时,查询墙外域名失败。虽然具体原因不知(可能宿主机系统采用了缓存的ISP 域名服务器进行递归)。但我们可以在虚拟机内部操作系统中显示配置域名到8.8.8.8,8.8.4.4,1.1.1.1,这样,只要代理服务器能帮助我们摸到这些域名服务器,域名查询就是成功的。
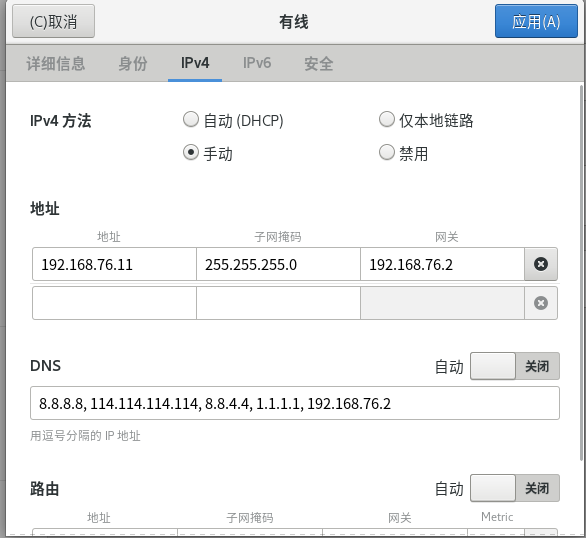
DOCKER服务
仅仅实现名称解析,还不足以成功pull,顶多如我们上面所示的错误那样,能够pull到docker.io的IP地址,但仍然不能拉取镜像。这是因为docker服务所走的通道和操作系统/浏览器所走的通道是不一样的。仅仅在代理工具中配置了"允许局域网连接",以及在虚拟机内部系统配置了网络代理:
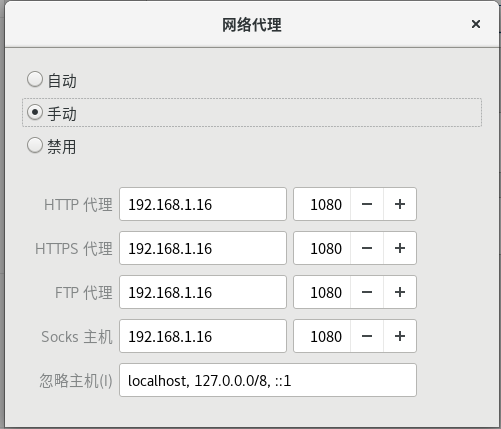
只是打通了虚拟机内部操作系统的代理通道。对于docker而言,必须在/etc/docker下增加daemon.json文件,显式告知docker服务代理服务器的配置:
[root@node1 docker]# cat daemon.json
{
"dns": ["8.8.8.8", "8.8.4.4"],
"mtu": 1400 ,
"proxies": {
"http-proxy": "http://192.168.1.16:1080/",
"https-proxy": "http://192.168.1.16:1080/",
"no-proxy": "localhost,127.0.0.0/8,::1"
}
}
[root@node1 docker]# 编辑完成后 systemctl daemon-reload并重启docker服务,就可以正常从官网拉取镜像了。如果还不行,那可能是你拉取镜像需要登录而已。
二、Portainer 部署
Portainer镜像有很多,我们仅拉取官方的Portainer-ce这个:
[root@node1 docker]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
clickhouse/clickhouse-server head-alpine b6ed8f160e84 2 weeks ago 718MB
clickhouse/clickhouse-keeper head-alpine 125d5acd6e3b 2 weeks ago 488MB
clickhouse latest fd802d7c099d 3 weeks ago 810MB
portainer/portainer-ce latest aa2ac1fdb557 4 weeks ago 186MB
apache/kafka 4.1.1-rc2 97f07998d0d7 4 weeks ago 429MB
ubuntu latest 97bed23a3497 8 weeks ago 78.1MB
hello-world latest 1b44b5a3e06a 3 months ago 10.1kB
docker.m.daocloud.io/bitnami/kafka latest 43ac8cf6ca80 4 months ago 454MB
portainer/portainer latest 5f11582196a4 3 years ago 287MB
clickhouse/clickhouse-client 21.3.20.1 51992fca03b5 3 years ago 519MB
centos centos7 eeb6ee3f44bd 4 years ago 204MB
在官方的介绍页中,详细列举了portainer在各种环境中的各种布置方法,我们选择在linux系统中做dockers standalone部署,参考页面如下:
1. 构建本地卷
执行dockers volume create语句,构建名为portainer_data的本地卷------如果我们不像每次container被删掉的时候连之前在portainer中存储的模板和任务都丢失的话。
docker volume create portainer_data使用docker volume inpect指令可以看到,该卷实际位于/var/lib/docker/volumes文件夹下。是事实上,后面我们也会看到,如果我们在swarm配置文件中使用本地卷来映射容器中的文件夹,其默认对应的文件夹均在宿主机的该路径下:
[root@node1 docker]# docker volume inspect portainer_data
[
{
"CreatedAt": "2025-11-18T08:23:04-05:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/portainer_data/_data",
"Name": "portainer_data",
"Options": null,
"Scope": "local"
}
]2. 启动容器
docker run -d -p 8000:8000 -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce按照官方给出的方式启动portainer-ce容器,使用docker ps可以观察到容器的启动情况:
[root@node1 docker]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c62d7485a169 portainer/portainer-ce "/portainer" 11 days ago Up 6 days 0.0.0.0:8000->8000/tcp, :::8000->8000/tcp, 0.0.0.0:9443->9443/tcp, :::9443->9443/tcp, 9000/tcp portainer在进程列表中,存在portainer进程:
[root@node1 docker]# ps -aux|grep portainer
root 2410 0.0 1.0 1320092 80708 ? Ssl 11月28 0:04 /portainer
root 23006 0.0 0.0 222016 1088 pts/1 S+ 08:24 0:00 grep --color=auto portainer在端口监听列表中,9443端口被监听:
[root@node1 docker]# netstat -tuanp|grep 9443
tcp 0 0 0.0.0.0:9443 0.0.0.0:* LISTEN 2342/docker-proxy
tcp6 0 0 :::9443 :::* LISTEN 2348/docker-proxy
[root@node1 docker]# 3. WEB登录
此时,在外部(即vmware的外部windows宿主机),或者与容器宿主机ping通的其它终端/服务器上,通过容器宿主机IP地址加9943端口,可以利用浏览器访问portainer的主页了:
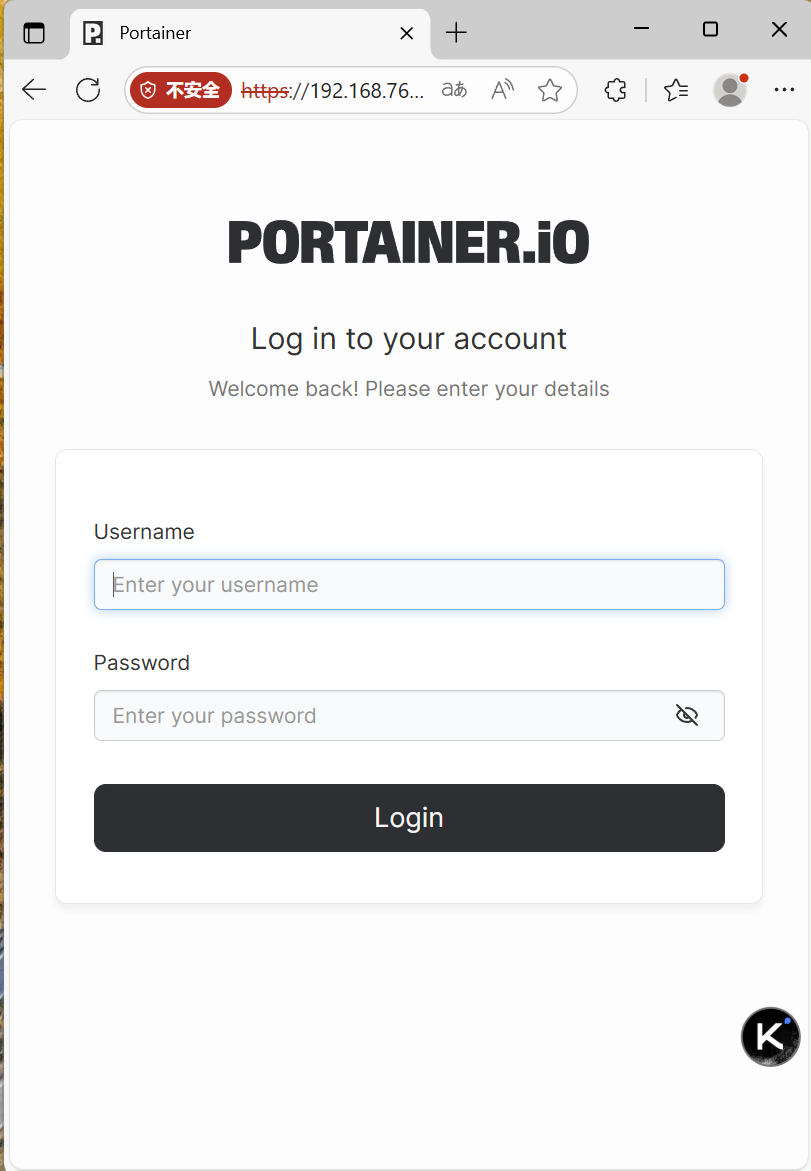
如果是第一次登录,需要为amdin创建登录口令。登录后,页面如下,点击local继续进入管理页面:
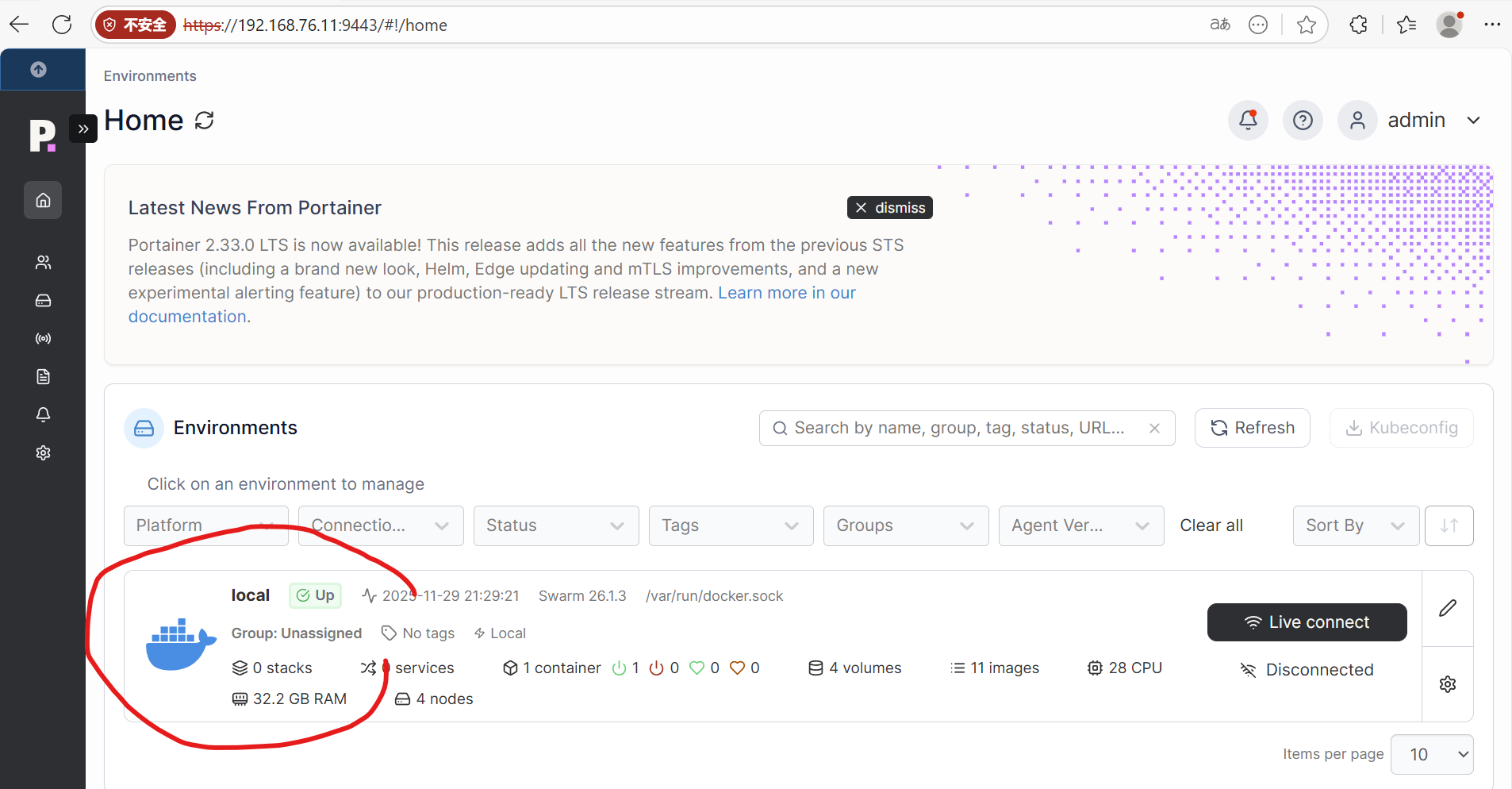
进入后,可以看到一个正在活动的容器,哪个是我们刚启动的container,还有其它volumes、networks和images等等,当然可能没有stack和services------在我们还没创建的情况下:
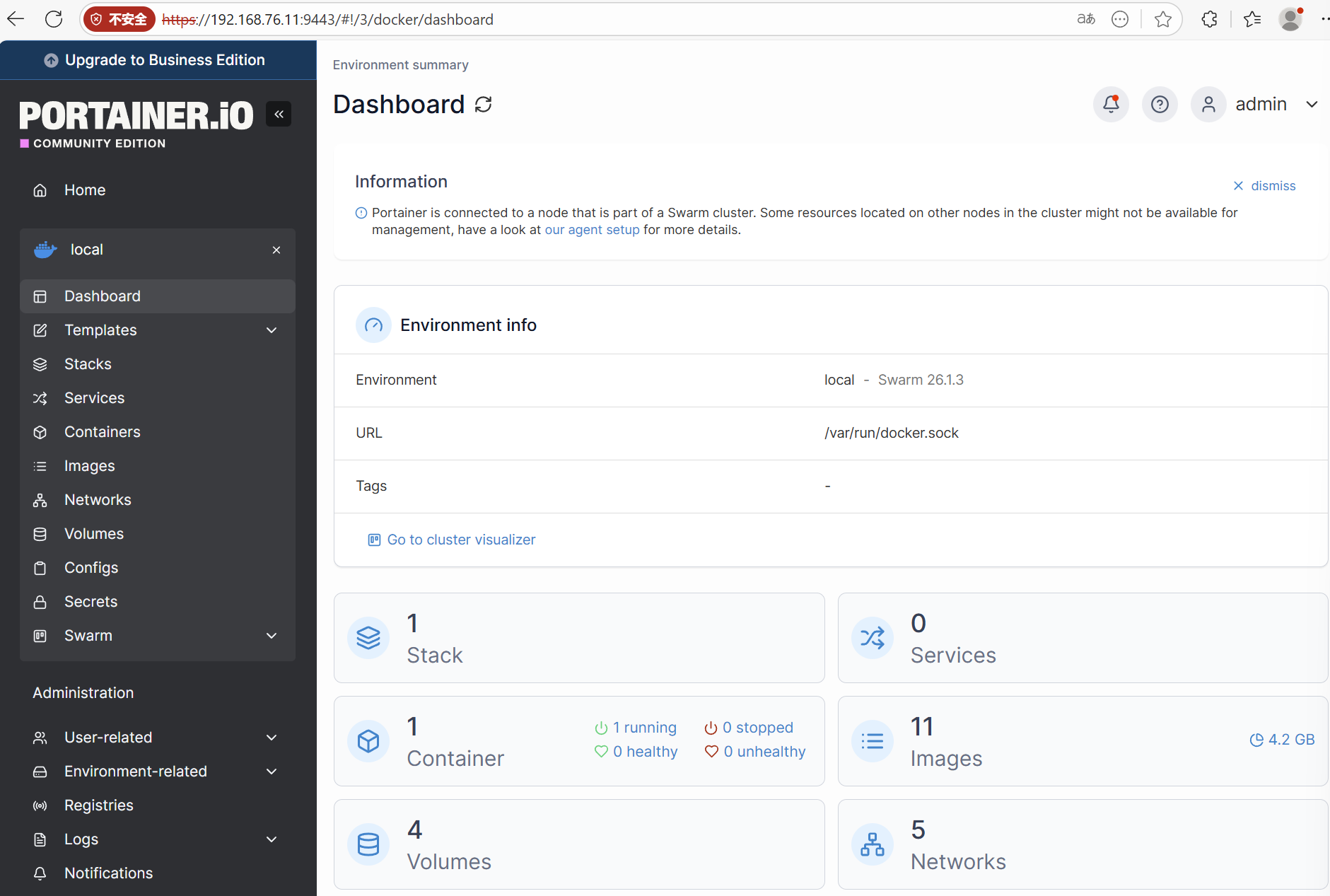
虽然网上常常将portainer视为轻便易用的编排工具,个人感觉不如把它看作是docker-desktop以及docker-swarm-desktop(这个我编的)的类似的管理工具。portainer所能提供的功能在我看来还不至于达到编排及运营管理的程度,其提供的功能依靠docker命令和docker swarm命令大多能够完成,portainer的作用只是让它们更加易用和直观而已,不过这也足够满足我们的需求了。
三、部署Docker Swarm
Dockers swarm的部署方法之前介绍过,并无多大变化,这里简单记录一下过程。唯一不同的,是需要对加入的节点都增加一个label,这个主要是为了后面配置swarm stack的时候,能够按照我们的规划将service指定部署在特定的节点上。
1. init主节点
docker swarm init --advertise-addr 192.168.76.112. 其它节点加入
docker swarm join --token ............ ............ 192.168.76.11:23773. 更改节点标注
在manager节点上,通过docker node update命令给加入swarm的节点增加标签,这样后面编排的时候就可以利用标签来指定service部署的节点(这种方式比之前我们直接指定hostname和IP,并且绕过swarm负载均衡的方式要好很多,可以利用上swarm的负载均衡和管理上的灵活性)。
i=1;while(($i<=6));do docker node update --label-add sn=$i node$i;let "i++";done在manager节点上通过node inspect命令可以查看标签是否赋予成功:
[root@node1 ~]# docker node inspect node6
[
{
"ID": "...... ......",
"Version": {
"Index": 3642
},
"CreatedAt": "2025-11-30T08:36:50.069447087Z",
"UpdatedAt": "2025-11-30T08:38:02.164229642Z",
"Spec": {
"Labels": {
"sn": "6"
},
"Role": "worker",
"Availability": "active"
},
..................
}
]四、再次部署Kafka
1. 下载镜像
嗯......我是从m.daocloud.io下载bitnami/kafka镜像(有图为证),不过在写这篇记录时,已经下不下来了,主要是因为m.daocloud.io似乎是对应映射hub.docker.com库的,而这个库里的bitnami/kafka的tags已经失效了。当然,使用apache官方的镜像也是可以的,只是配置的时候参数的写法略不一样,需要按照官方的指南进行配置。
[root@node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
portainer/portainer-ce latest aa2ac1fdb557 4 weeks ago 186MB
apache/kafka 4.1.1-rc2 97f07998d0d7 4 weeks ago 429MB
ubuntu latest 97bed23a3497 2 months ago 78.1MB
docker.m.daocloud.io/bitnami/kafka latest 43ac8cf6ca80 4 months ago 454MB当然,在国内费心找一找也还是能找到免费源的,比如:

这个源下的latest标签有幸还在:
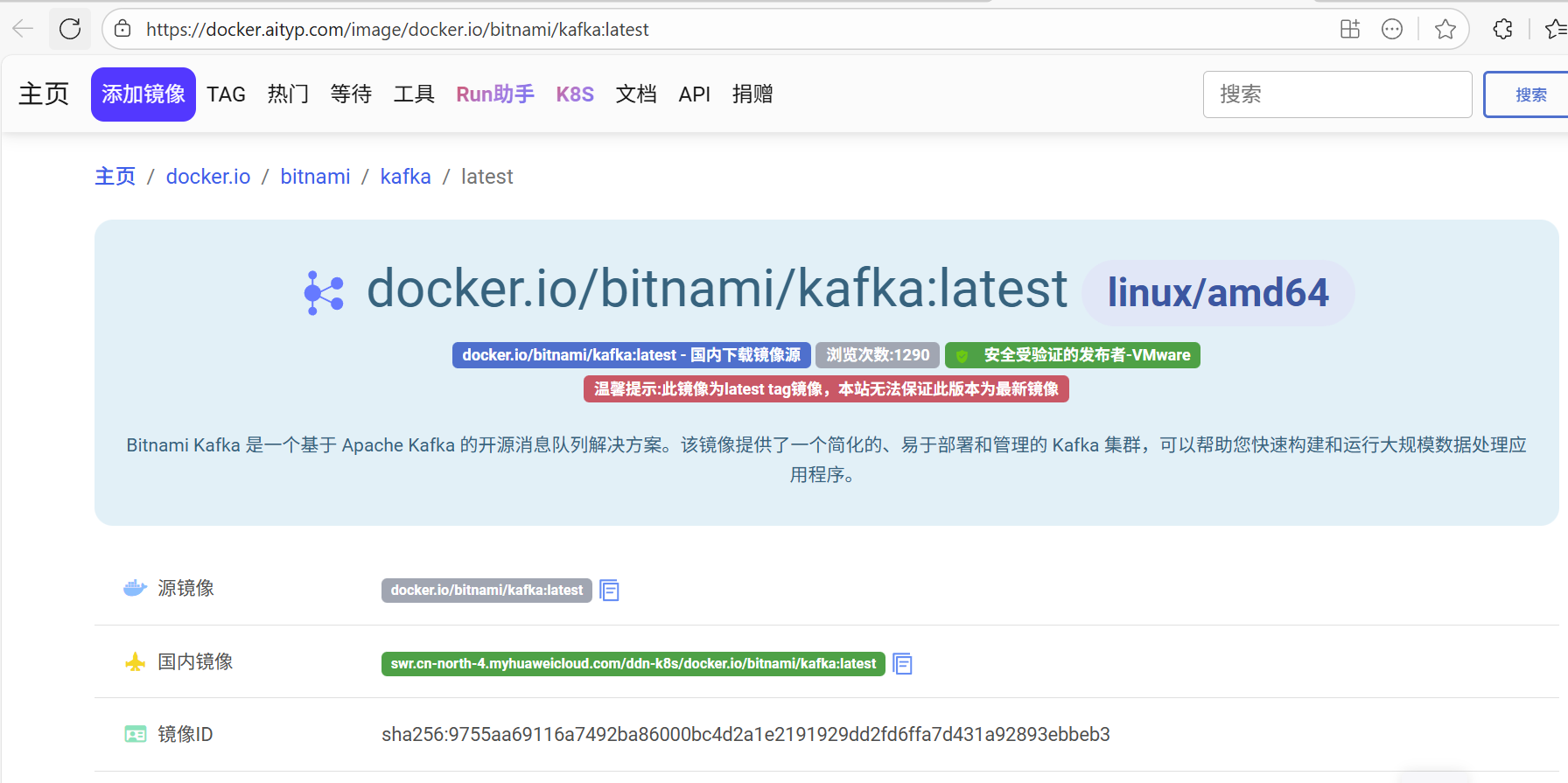
直接指定镜像源的位置swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/下载即可:
[root@node1 ~]# docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka:latest
latest: Pulling from ddn-k8s/docker.io/bitnami/kafka
b7cbeafa8732: Pull complete
Digest: sha256:88de1d95d3e390274465505f7dc439e282f1f7aa5f4c7d5b7a1e115198be2956
Status: Downloaded newer image for swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka:latest
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/bitnami/kafka:latest2. 拷贝及更改配置文件
下面我继续用之前从m.daocloud.io源下载的镜像,应该都一样的。
(1) 拷贝配置文件
如果使用的是官方镜像,则需要在每个节点中配置好service.properties。如此需要首先将镜像加载到容器中......这一步只是为了将官方给的配置模板给拷贝出来。先在宿主机上建一个config文件夹,然后映射到容器内的/opt/bitnami/kafka/config上。需要提一句的是,最好从我们要用的镜像中拷贝配置文件作为母版,因为不同版本或者不同出处的这个文件可能有一点细微的不一样(尤其是clickhouse),如果没对上,可能会给自己留下一个隐形大坑。
[root@node1 ~]# docker run -it --name pig -v /root/config:/opt/bitnami/kafka/config/m docker.m.daocloud.io/bitnami/kafka bash
kafka 13:41:25.27 INFO ==>
kafka 13:41:25.27 INFO ==> Welcome to the Bitnami kafka container
kafka 13:41:25.27 INFO ==> Subscribe to project updates by watching https://github.com/bitnami/containers
kafka 13:41:25.27 INFO ==> Did you know there are enterprise versions of the Bitnami catalog? For enhanced secure software supply chain features, unlimited pulls from Docker, LTS support, or application customization, see Bitnami Premium or Tanzu Application Catalog. See https://www.arrow.com/globalecs/na/vendors/bitnami/ for more information.
kafka 13:41:25.27 INFO ==>
I have no name!@c324847471cc:/$ cd /opt/bitnami/kafka/config/
I have no name!@c324847471cc:/opt/bitnami/kafka/config$ ls
broker.properties connect-distributed.properties connect-log4j2.yaml consumer.properties m tools-log4j2.yaml
connect-console-sink.properties connect-file-sink.properties connect-mirror-maker.properties controller.properties producer.properties trogdor.conf
connect-console-source.properties connect-file-source.properties connect-standalone.properties log4j2.yaml server.properties.original
I have no name!@3496bd6a8a76:/opt/bitnami/kafka/config$ cp server.properties.original m 拷出来后就可以删除这个临时容器(不是镜像),然后按照上篇的配置方法进行配置了。 不过,如果使用的是bitnami的kafka镜像,则可以通过预设的参数将配置传入。这些参数名称基本是对service.properties中的配置名称的大写化、点转下划线并加上"KAFKA_CFG_"前缀。
(2)新建一个Stack
下面依托portainer来部署bitnami/kafka。登录到portainer后,从stacks标签页进入,并点击"
Add Stack"新建一个Stack
然后在Web Editor中配置swarm的yml文件。
由于网络上关于kafka Kraft的部署方式介绍很多,所以我们完全可以利用人工智能直接给出YML文件,比如使用百度AI,提示词如下:

YML文件如下,略微调整一下,调整镜像名称,加上标签约束,基本是可用的
version: '3.8'
services:
kafka1:
image: 'bitnami/kafka:latest'
ports:
- '19091:19091'
environment:
- KAFKA_CFG_NODE_ID=1
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:19091
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka1:9092,EXTERNAL://192.168.76.14:19091
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
- KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3
- KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2
networks:
- kafka
volumes:
- kafka-data1:/bitnami/kafka
deploy:
replicas: 1
placement:
constraints:
- node.labels.sn==4
kafka2:
image: 'bitnami/kafka:latest'
ports:
- '19092:19092'
environment:
- KAFKA_CFG_NODE_ID=2
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:19091
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka2:9092,EXTERNAL://192.168.76.15:19092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
- KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3
- KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2
networks:
- kafka
volumes:
- kafka-data2:/bitnami/kafka
deploy:
replicas: 1
placement:
constraints:
- node.labels.sn==5
kafka3:
image: 'bitnami/kafka:latest'
ports:
- '19093:19093'
environment:
- KAFKA_CFG_NODE_ID=3
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka1:9093,2@kafka2:9093,3@kafka3:9093
- KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:19091
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka3:9092,EXTERNAL://192.168.76.16:19093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR=3
- KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=3
- KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR=2
networks:
- kafka
volumes:
- kafka-data3:/bitnami/kafka
deploy:
replicas: 1
placement:
constraints:
- node.labels.sn==6
volumes:
kafka-data1:
driver: local
kafka-data2:
driver: local
kafka-data3:
driver: local
networks:
kafka:
driver: overlay
attachable: true3. 需要注意的配置
记得关Selinux和防火墙并且重启,一些坑可能仅仅是因为这个原因。
在使用VMware虚拟机当作裸金属服务器方式直接部署Kafka时没有遭遇太多问题,在swarm情况下,大概是因为swarm自有的负载均衡网络,还是接二连三的掉了几个大坑。哪怕是在生产环境中,基于swarm管理的裸金属服务器搭建成功的情况下,为了写这篇文章,在Vmware虚拟机做为swam管理的节点时,同样的配置,居然就启动不了,所以这里把遇到的问题再次记录一下:
(1)监听配置
KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:19091
如上篇所说,在使用裸金属服务器作为swarm的node时,该监听配置使用CONTROLLER://:9093可以正常工作,但是在使用Vmware的虚拟节点作为swarm的node时,该配置却导致kafka的kraft控制节点选举失败,原因是无法正确解释控制节点的hostname kakfa*:
test_kafka1.1.nket1qf3h4f9@node4 | [2025-12-09 15:23:43,781] WARN [RaftManager id=1] Connection to node 2 (kafka2/10.0.1.4:9093) could not be established. Node may not be available. (org.apache.kafka.clients.NetworkClient)
test_kafka1.1.nket1qf3h4f9@node4 | [2025-12-09 15:23:43,785] WARN [RaftManager id=1] Error connecting to node kafka3:9093 (id: 3 rack: null isFenced: false) (org.apache.kafka.clients.NetworkClient)
test_kafka1.1.nket1qf3h4f9@node4 | java.net.UnknownHostException: kafka3
test_kafka1.1.nket1qf3h4f9@node4 | at java.base/java.net.InetAddress$CachedAddresses.get(Unknown Source) ~[?:?]
test_kafka1.1.nket1qf3h4f9@node4 | at java.base/java.net.InetAddress.getAllByName0(Unknown Source) ~[?:?]
test_kafka1.1.nket1qf3h4f9@node4 | at java.base/java.net.InetAddress.getAllByName(Unknown Source) ~[?:?]
test_kafka1.1.nket1qf3h4f9@node4 | at java.base/java.net.InetAddress.getAllByName(Unknown Source) ~[?:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.DefaultHostResolver.resolve(DefaultHostResolver.java:27) ~[kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.ClientUtils.resolve(ClientUtils.java:125) ~[kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState.resolveAddresses(ClusterConnectionStates.java:536) ~[kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState.currentAddress(ClusterConnectionStates.java:511) ~[kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.ClusterConnectionStates.currentAddress(ClusterConnectionStates.java:173) ~[kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:1140) [kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.clients.NetworkClient.ready(NetworkClient.java:368) [kafka-clients-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.server.util.InterBrokerSendThread.sendRequests(InterBrokerSendThread.java:146) [kafka-server-common-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.server.util.InterBrokerSendThread.pollOnce(InterBrokerSendThread.java:109) [kafka-server-common-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.server.util.InterBrokerSendThread.doWork(InterBrokerSendThread.java:137) [kafka-server-common-4.0.0.jar:?]
test_kafka1.1.nket1qf3h4f9@node4 | at org.apache.kafka.server.util.ShutdownableThread.run(ShutdownableThread.java:136) [kafka-server-common-4.0.0.jar:?]如上篇所说,CONTROLLER://:9093的含义应该是CONTROLLER://127.0.0.1:9093。即定义监听本机的9093端口,这种配置用于本机内部服务或者应用通信,但在配置选举集群时,我们也指定了选举时使用hostname:KAFKA_CFG_CONTROLLER_QUORUM_VOTERS = 1@kafka1:9093, 2@kafka2:9093, 3@kafka3:9093,从报错情况看,Kraft也确实是通过hostname在联络其它控制节点进行选举。而选举失败的原因在当时是不明的......
其后将监听配置改为KAFKA_CFG_LISTENERS = PLAINTEXT://0.0.0.0:9092, CONTROLLER://0.0.0.0:9093, EXTERNAL://0.0.0.0:19091 ,即同时监听内外网端口,则能够完成选举。
中间各种尝试过程此处省略,直说最后结论
后续发现,其实真正原因在于防火墙。在vmware虚拟机中,虽然我们已经关闭防火墙,但是并未重启服务(忘了)......,从而导致出现各种奇怪的现象。而配置0.0.0.0的内外网端口同时监听,似乎会提示bitnami/kafka进行相应的防火墙配置(猜测,未深究脚本).后续我们在确认防火墙关闭的情况下,仍然使用CONTROLLER://:9093配置,也没有类似的报错了。
(2)集群ID
KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv
在上述的各种尝试过程中,也遭遇集群ID设置错误。事实上,如果能够保证一把配置成功的化,该配置参数默认是可以不配置的,bitnami/kafka脚本会在启动过程中自行调用kafka api生成。但是如果反复尝试,就有一定机会看到如下报错:
test_kafka1.1.iot9ha9b3tka@node4 | [2025-12-09 15:01:50,053] INFO [MetadataLoader id=1] initializeNewPublishers: the loader is still catching up because we still don't know the high water mark yet. (org.apache.kafka.image.loader.MetadataLoader)
test_kafka1.1.iot9ha9b3tka@node4 | [2025-12-09 15:01:50,059] ERROR [RaftManager id=1] Unexpected error INCONSISTENT_CLUSTER_ID in VOTE response: InboundResponse(correlationId=6079, data=VoteResponseData(errorCode=104, topics=[], nodeEndpoints=[]), source=kafka3:9093 (id: 3 rack: null isFenced: false)) (org.apache.kafka.raft.KafkaRaftClient)
test_kafka1.1.iot9ha9b3tka@node4 | [2025-12-09 15:01:50,059] ERROR [RaftManager id=1] Unexpected error INCONSISTENT_CLUSTER_ID in VOTE response: InboundResponse(correlationId=6080, data=VoteResponseData(errorCode=104, topics=[], nodeEndpoints=[]), source=kafka2:9093 (id: 2 rack: null isFenced: false)) (org.apache.kafka.raft.KafkaRaftClient)
test_kafka1.1.iot9ha9b3tka@node4 | [2025-12-09 15:01:50,080] ERROR [RaftManager id=1] Unexpected error INCONSISTENT_CLUSTER_ID in VOTE response: InboundResponse(correlationId=6081, data=VoteResponseData(errorCode=104, topics=[], nodeEndpoints=[]), source=kafka3:9093 (id: 3 rack: null isFenced: false)) (org.apache.kafka.raft.KafkaRaftClient)其原因是kraft会将集群ID存入本地volume,也就是swarm配置中指向的volumes配置
volumes:
kafka-data1:
driver: local
kafka-data2:
driver: local
kafka-data3:
driver: local这些本地化文件在宿主机的/var/lib/docker/volumes文件夹下(如kafka3的节点):
[root@node6 volumes]# ls
backingFsBlockDev metadata.db test_kafka-data3将这些本地化文件删除即可解决问题,当然使用docker volume rm要正规一些,如果不小心手滑使用rm 删除的话,记得systemctl daemon-reload和systemctl restart docker.service,否则docker仍然会认为自己拥有这些本地化目录,出现对应目录无法访问的错误。
[root@node1 volumes]# docker stack ps test --no-trunc
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
x9vhikmms0crpiq3l79k38hjm test_kafka1.1 bitnami/kafka:latest node4 Ready Rejected 3 seconds ago "failed to populate volume: error evaluating symlinks from mount source "/var/lib/docker/volumes/test_kafka-data1/_data": lstat /var/lib/docker/volumes/test_kafka-data1: no such file or directory"
wb1rca2mccubxwbqot9hg0f9e \_ test_kafka1.1 bitnami/kafka:latest node4 Shutdown Rejected 8 seconds ago "failed to populate volume: error evaluating symlinks from mount source "/var/lib/docker/volumes/test_kafka-data1/_data": lstat /var/lib/docker/volumes/test_kafka-data1: no such file or directory" (3)HOSTNAME
如果使用swarm的overlay网络,让swarm做负载均衡,实际hostname就是service name,完全可以不做配置,亲测无任何影响。
(4)EXTERNAL
external是自定义外部监听的名字,其协议在LISTENER_SECURITY_PROTOCOL_MAP中定义,监听IP与端口则在ADVERTISED_LISTENERS定义。重要的是这个监听IP,必须用宿主机IP,才能够保证在外部集群能够访问到Kafka的broker。
如果尽在集群内使用,是不需要定义这个外监听IP的;但如果是从集群外部访问,则必须定义。如果仅使用一个分区,问题也不大,我尝试过在宿主机增加kafka*的IP映射实现从外部访问到kafka集群。但如果是多个分区,在调用rdkafkalib的API进行生产时,若使用自动选择分区参数,则会随机发生消息生产错误问题:
// 发送消息
std::string message = "Hello, Kafka!";
RdKafka::ErrorCode resp = producer->produce(
topic,
RdKafka::Topic::PARTITION_UA, // 自动选择分区
RdKafka::Producer::RK_MSG_COPY, // 复制消息内容
const_cast<char*>(message.c_str()),
message.size(),
nullptr, // key
0, // timestamp
nullptr // 回调参数
);猜测还是因为swarm的负载均衡原因:虽然外部生产者可以通过额外配置的kafka*名称映射解析到kafka服务容器宿主机IP,并通过该IP访问kafka服务时,又能够被内网解析kafka*到内网容器IP及kafka监听的9092端口,从而连接到kafka集群进行正常生产,该但若是被swarm内部均衡到其它节点上时,就会因为内部无法解析不属于本节点的hostname导致监听外部IP而失败,从而造成随机的生产或成功或失败问题。
以上现象为亲测,原因为纯猜测,未作抓包验证,总之如果想从外部访问,一定要advertise外部集群地址就对了。
4. 启动stack
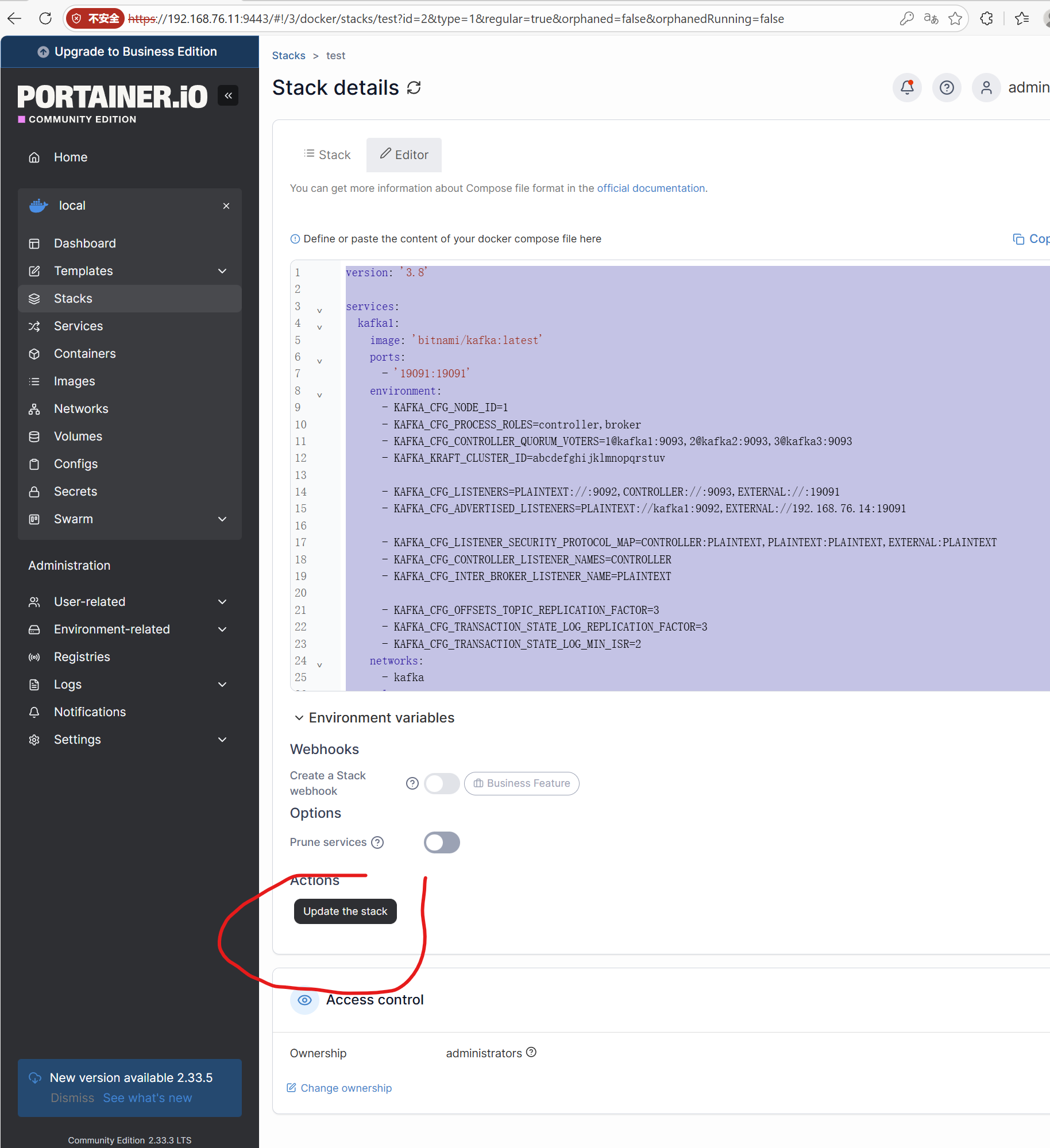
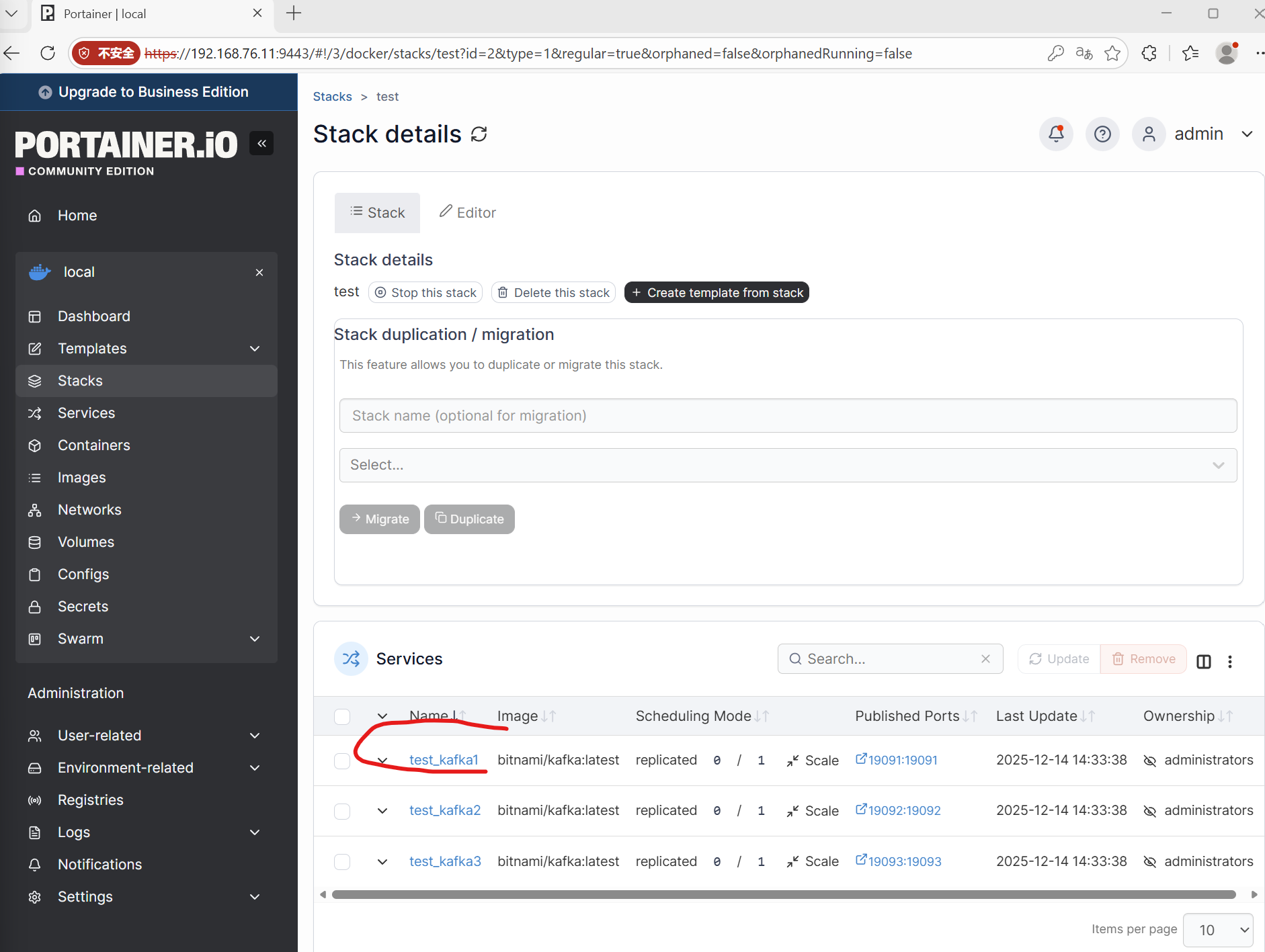
在portiner中update the stack,稍等即可启动集群,或则直接进入stack中点击start stack启动
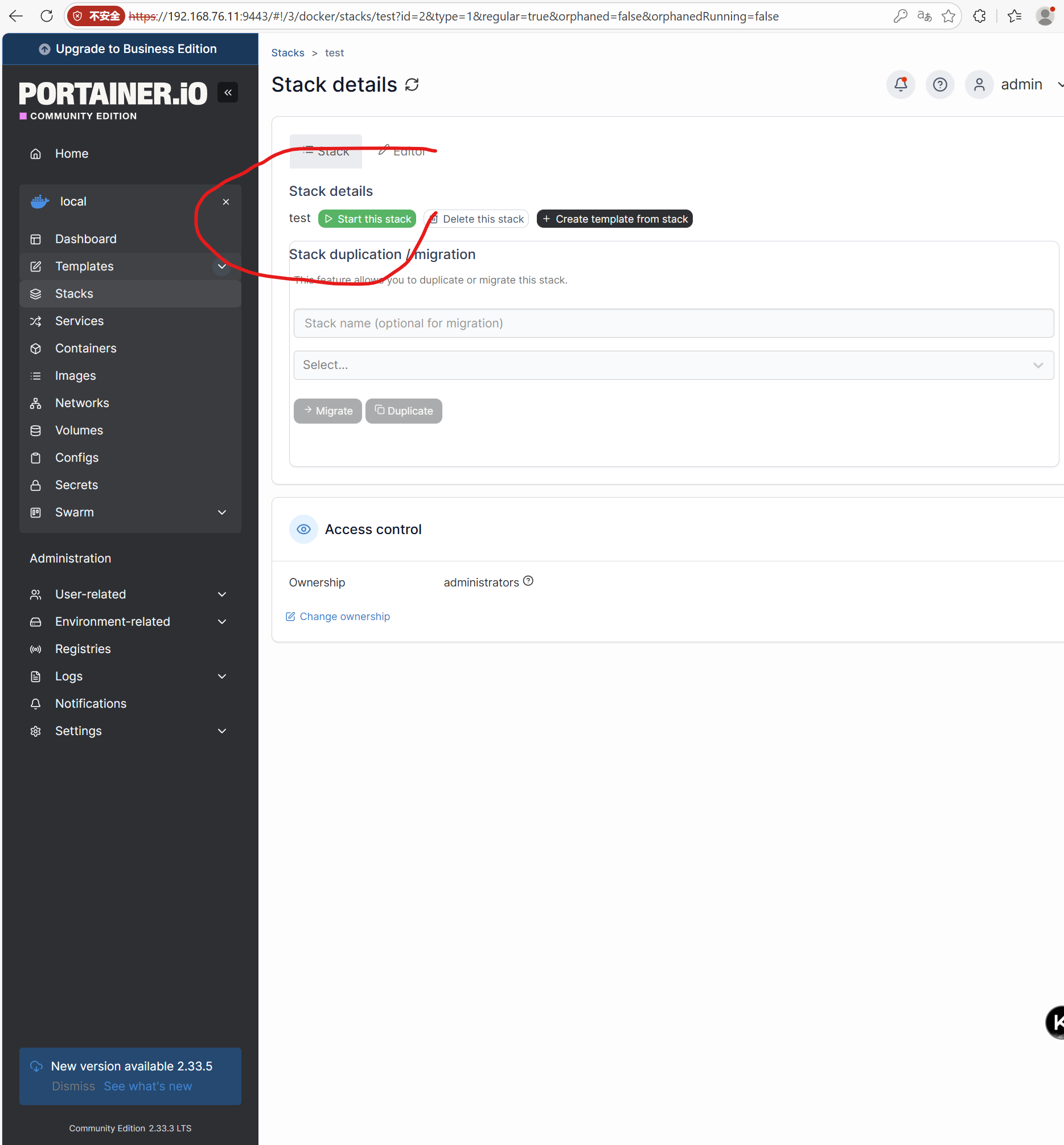
选择任意一个节点的service,点击进入
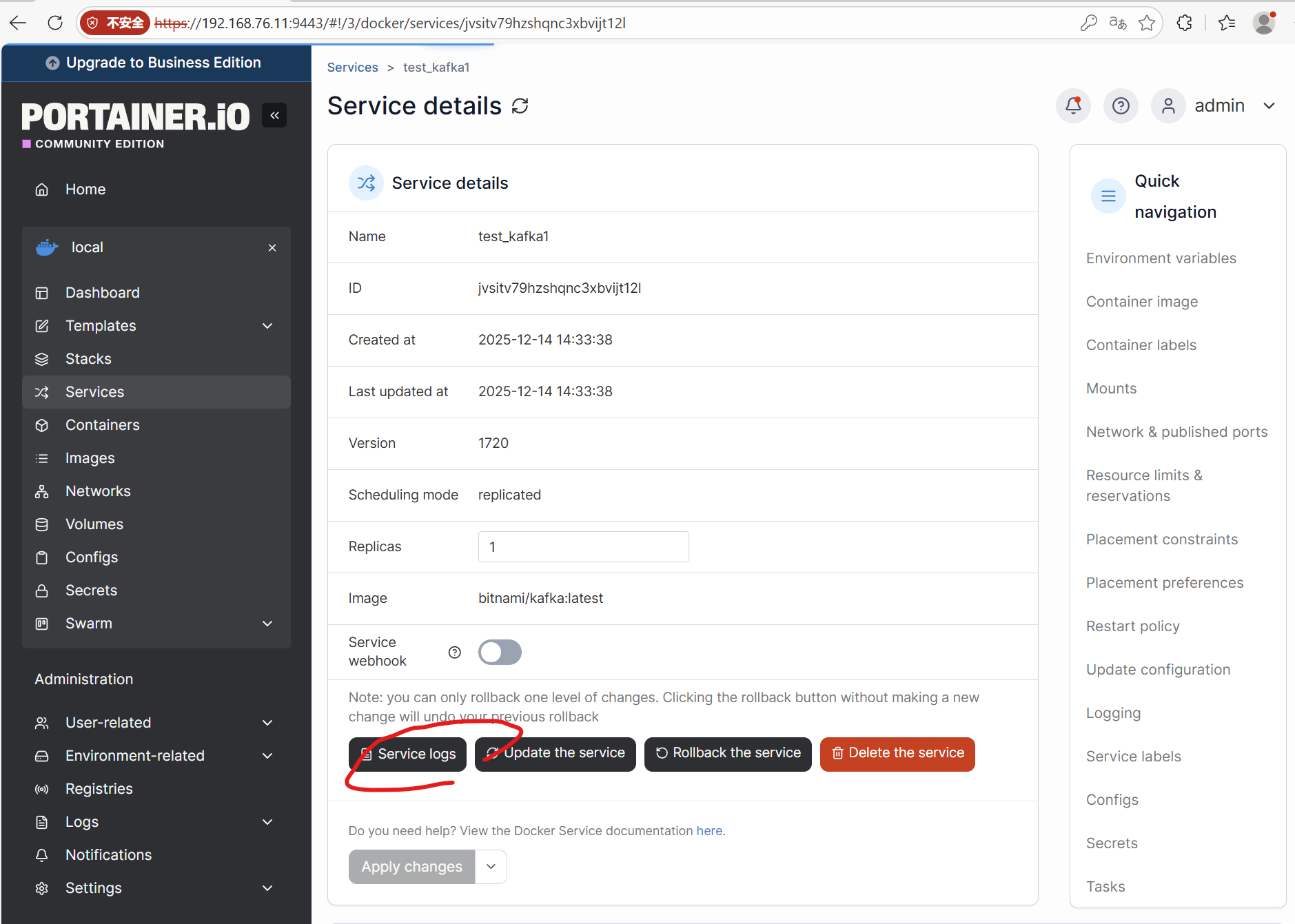
选择service logs可以查看服务启动日志
5. 创建Topic
[root@node4 volumes]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
13b96844647b bitnami/kafka:latest "/opt/bitnami/script..." About a minute ago Up About a minute 9092/tcp test_kafka1.1.ve3l7y3fit2243e2m4pwkgu7b
[root@node4 volumes]# docker exec -it 13b9 bash
I have no name!@kafka1:/$
I have no name!@kafka1:/$ kafka-topics.sh --create --topic pigtest --bootstrap-server kafka1:9092
Created topic pigtest.
I have no name!@kafka1:/$ 6. 启动消费者
[root@node5 volumes]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
368e65edd178 bitnami/kafka:latest "/opt/bitnami/script..." 4 minutes ago Up 4 minutes 9092/tcp test_kafka2.1.ewclb0amy37sb514autxfllhg
[root@node5 volumes]# docker exec -it 368e bash
I have no name!@kafka2:/$ kafka-console-consumer.sh --topic pigtest --bootstrap-server kafka1:90927. 启动生产者
[root@node6 volumes]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3fdd9f0754b6 bitnami/kafka:latest "/opt/bitnami/script..." 5 minutes ago Up 5 minutes 9092/tcp test_kafka3.1.yigesdqhlzcvi6oud4khtjd3u
[root@node6 volumes]# docker exec -it 3fdd bash
I have no name!@kafka3:/$ kafka-console-producer.sh --topic pigtest --bootstrap-server kafka1:9092
>8. 生产消息,在消费者中看到
[root@node6 volumes]# docker exec -it 3fdd bash
I have no name!@kafka3:/$ kafka-console-producer.sh --topic pigtest --bootstrap-server kafka1:9092
>hello,pig.
>
[root@node5 volumes]# docker exec -it 368e bash
I have no name!@kafka2:/$ kafka-console-consumer.sh --topic pigtest --bootstrap-server kafka1:9092
hello,pig.