与mongo和mysql不同,redis多用于存储中间层,目前我多用于查重去重,我们需要安装一个库:
python
pip install redis之前的aioredis合并到redis中了
同步操作
建立连接
python
import redis # 同步操作都这样导包
client_syn = redis.Redis(host="127.0.0.1", port=6379, decode_responses=True)同步操作
python
# 给Redis中键为"count"的字符串类型键值对设置值为10(覆盖原有值,无过期时间)
client_syn.set("count", 10)
# 获取Redis中键为"count"的字符串类型值(返回bytes类型,若设置decode_responses=True则返回字符串)
client_syn.get("count")
# 向Redis中名为"duplicate"的集合(Set)添加元素"md5_1",集合自动去重
client_syn.sadd("duplicate", "md5_1")
# 判断"md5_1"是否是Redis中"duplicate"集合的成员,返回True/False
client_syn.sismember("duplicate", "md5_1")去重操作一般用后两个,实现代码如下:
python
# 模拟待处理的一批数据(含重复值)
data_list = ["md5_1", "md5_2", "md5_1", "md5_3"] # 这里其实会将某些一定不能相同的数据加密成md5用于去重操作
for data in data_list:
# 1. 先判断当前数据是否已存在于去重集合中
# (存在则跳过,实现去重)
if client_syn.sismember("duplicate", data):
print(f"数据{data}已存在,跳过处理")
continue
# 2. 数据不存在,执行业务处理(比如存储、爬虫等)
print(f"处理新数据:{data}")
# 3. 将处理后的新数据加入去重集合
# (Sadd会自动忽略重复元素,即使重复执行也不会存入重复值)
client_syn.sadd("duplicate", data)异步操作
建立连接
第一种是普通连接,适合低并发的操作:
python
from redis import asyncio as aioredis
client_aio = await aioredis.from_url(
"redis://localhost:6379/0", # Redis 地址:主机+端口+数据库编号(0-15)
decode_responses=True, # 自动把 Redis 返回的 bytes 转字符串(无需手动 decode)
password=None, # 无密码设为 None,有密码则填字符串(如 "123456")
encoding="utf-8" # 字符编码,固定 utf-8 即可
)第二种是建立连接池,适合高并发:
python
# 先创建连接池(控制最大连接数,避免连接耗尽)
pool = aioredis.ConnectionPool.from_url(
"redis://localhost:6379/0",
max_connections=100, # 连接池最大连接数(根据服务器性能调整)
decode_responses=True # 统一开启字符串自动解码
)
# 基于连接池创建 Redis 实例
redis_pool = aioredis.Redis(connection_pool=pool)基本操作
基础K-V操作(key value)
python
await client_aio.set("name", "张三", ex=60)
# 新增:仅当 key=age 不存在时设置值=20(setnx = set if not exists,避免覆盖)
await client_aio.setnx("age", 20)
# 查询:获取单个 key 的值
name = await client_aio.get("name")
age = await client_aio.get("age")
print(f"【单个查询】name={name}, age={age}") # 输出:name=张三, age=20
# 删除:删除指定 key
await client_aio.delete("age")
print(f"【删除后查询】age={await client_aio.get('age')}") # 输出:age=None
# 批量设置:一次设置多个 key-value
await client_aio.mset({"k1": "v1", "k2": "v2", "k3": "v3"})
# 批量获取:一次获取多个 key 的值(返回列表,顺序与入参一致)
batch_data = await client_aio.mget(["k1", "k2", "k3"])
print(f"【批量查询】{batch_data}") # 输出:['v1', 'v2', 'v3']集合基础操作
python
# ========== 新增元素(自动去重) ==========
# 向集合 unique_users 添加 3 个元素(其中 user1 重复,自动过滤)
await client_aio.sadd("unique_users", "user1", "user2", "user1")
# ========== 查询操作 ==========
# 1. 获取集合所有元素(返回集合类型,天然去重)
all_users = await client_aio.smembers("unique_users")
# 2. 判断元素是否在集合中(返回 True/False,去重核心判断)
is_user1_exist = await client_aio.sismember("unique_users", "user1")
is_user3_exist = await client_aio.sismember("unique_users", "user3")
# 3. 获取集合元素数量
user_count = await client_aio.scard("unique_users")
print(f"【集合所有元素】{all_users}") # 输出:{'user1', 'user2'}
print(f"【user1 是否存在】{is_user1_exist}") # 输出:True
print(f"【user3 是否存在】{is_user3_exist}") # 输出:False
print(f"【集合元素数量】{user_count}") # 输出:2
# ========== 删除元素 ==========
# 从集合中删除指定元素 user2
await client_aio.srem("unique_users", "user2")
print(f"【删除后元素】{await client_aio.smembers('unique_users')}") # 输出:{'user1'}去重可配合sadd和sismember:
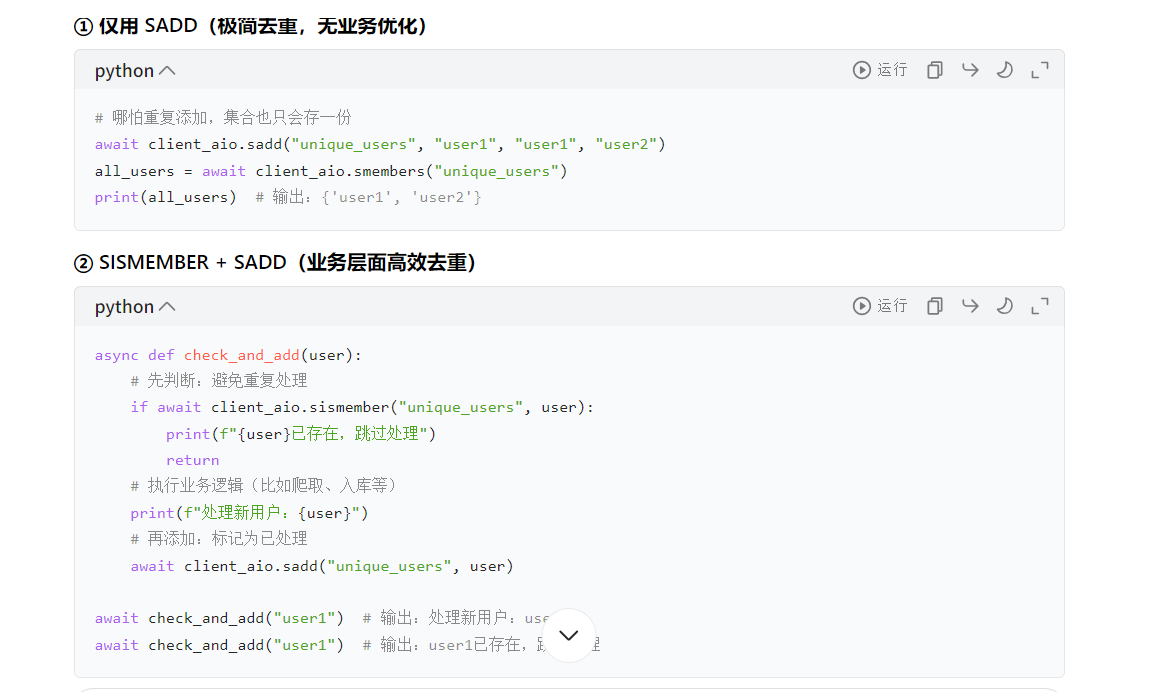
关闭连接
和pymongo一样,redis不论同步异步都不需要手动关闭连接
常用组合(异步)
python
import asyncio
from redis import asyncio as aioredis
async def get_redis_client():
"""创建Redis异步连接(生产级连接池配置)"""
# 自定义连接池(高并发/生产场景首选)
pool = aioredis.ConnectionPool.from_url(
"redis://localhost:6379/0",
max_connections=50, # 按需调整,默认足够日常使用
decode_responses=True # 自动转字符串,省手动解码
)
return aioredis.Redis(connection_pool=pool)
async def redis_common_operations():
# 1. 获取连接
redis = await get_redis_client()
# ========== 【最常用】String(KV键值) ==========
await redis.set("name", "张三", ex=30) # 设置值+30秒过期
print("String查询:", await redis.get("name")) # 获取值
# ========== 【最常用】Set(去重核心) ==========
await redis.sadd("unique_ids", "id1", "id2", "id1") # 自动去重
print("Set所有元素:", await redis.smembers("unique_ids")) # 查所有
print("元素是否存在:", await redis.sismember("unique_ids", "id1")) # 去重判断
# ========== 【常用】Hash(存储对象) ==========
await redis.hset("user:1001", mapping={"name": "李四", "age": 25}) # 存对象
print("Hash查询:", await redis.hgetall("user:1001")) # 查整个对象
# ========== 【常用】Pipeline(批量原子操作) ==========
pipe = redis.pipeline()
pipe.set("a", 1).incr("a").set("b", 2)
print("管道执行结果:", await pipe.execute())
# 关闭连接(可选,程序退出自动释放)
await redis.close()
# 运行测试
if __name__ == "__main__":
asyncio.run(redis_common_operations())小结
redis主要作用是去重,所以会建立连接,然后hash加密作为值,通过sadd和sismember配合去重即可,后面随用随查,如有什么问题及时提出,加油加油