通过Dify智能体,结合MCP工具能力,可以很轻松的构建基于数据库的查询问答,对用户输出的问题,通过Dify的Agent节点,自动调用合适的工具来获取数据并回答问题。下面以一个具体的数据例子来介绍如何完成。
创建示例数据库
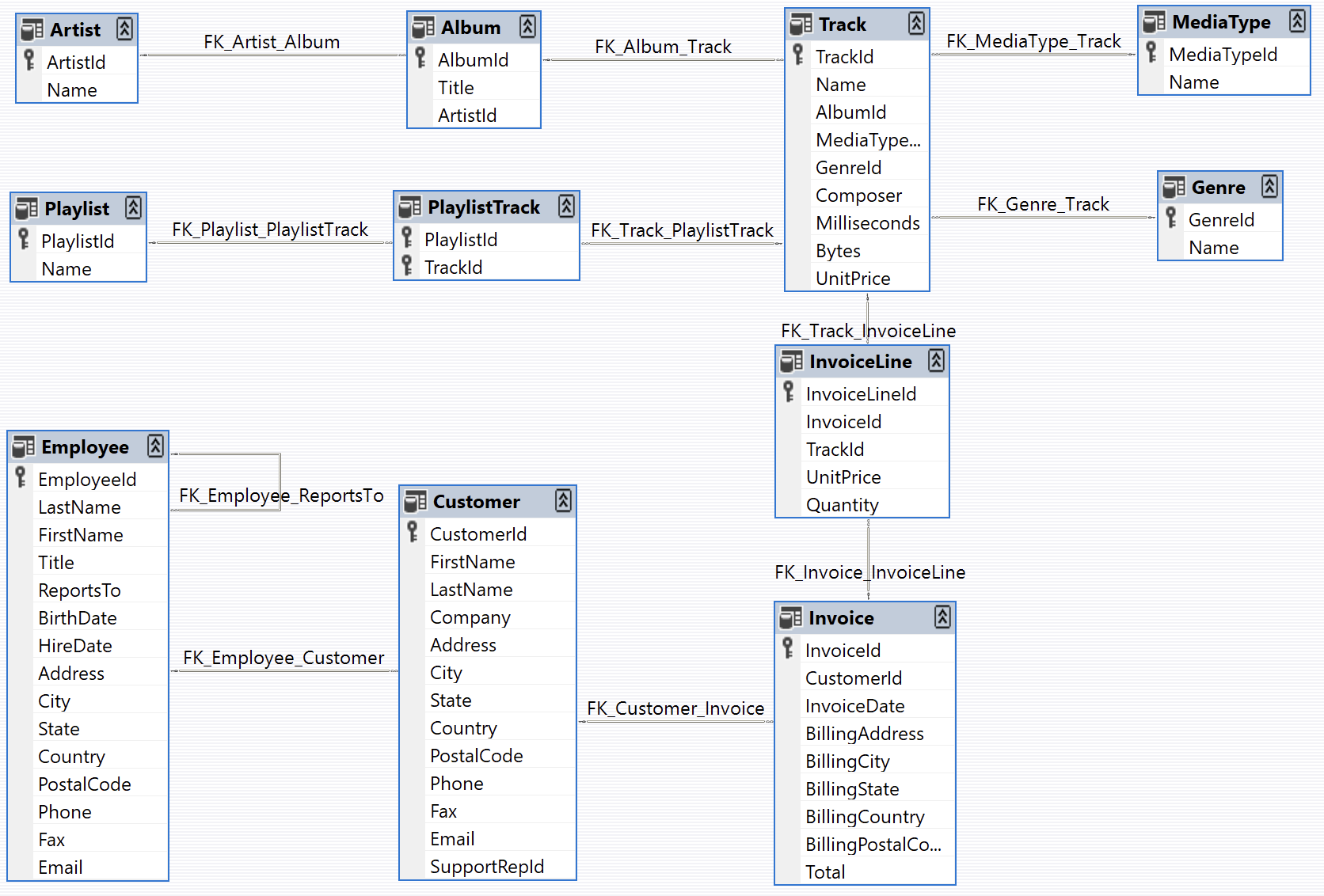
首先准备一些示例数据,这里以一个数字音乐商店的数据为例,可以在Github仓库GitHub - lerocha/chinook-database: Sample database for SQL Server, Oracle, MySQL, PostgreSQL, SQLite, DB2上下载相应的数据库创建脚本,创建数据库。这个数据库有以下的数据表,其结构如下图。
以Postgresql数据库为例,首先通过docker启动postgres服务。
bash
docker run -d \
--name postgres \
-e POSTGRES_PASSWORD=abc123 \
-p 5432:5432 \
-v /home/abc/docker/volumes/postgres:/var/lib/postgresql \
postgres:latest将Github仓库下载的sql脚本通过docker cp拷贝到容器中,然后连接到数据库。
bash
docker exec -it postgres psql -U postgres运行sql脚本创建数据库
bash
\i /Chinook_PostgreSql.sql创建完成后,可以通过命令\dt查看导入的数据表, \d tablename查看具体某个表的结构。
通过以下命令导出所有的表结构数据。
bash
docker exec -it postgres pg_dump -U postgres -d chinook -s -f /datatables.sql然后将其保存到宿主机
bash
docker cp postgres:/datatables.sql ./保存好的sql文件后续可以在智能体工作流中传入给大模型,帮助大模型理解数据库的结构,从而按照用户的提问生成相应的SQL查询语句。
除了用sql格式来描述数据库结构,也可以采用M-Schema规范来描述数据库结构,这是一种用于自然语言转SQL(NL2SQL) 任务的、半结构化的数据库模式表示规范。它由阿里巴巴的团队提出,是其 XiYan-SQL 框架的核心组成部分,旨在解决大模型在理解复杂、专业的数据库结构时面临的挑战,具体介绍可以参见https://github.com/XGenerationLab/XiYan-DBDescGen.git
通过以下代码自动生成M-Schema文件。
python
import os
from sqlalchemy import create_engine
database_url = 'postgresql://postgres:abc123@localhost:5532/chinook'
engine = create_engine(database_url)
from schema_engine import SchemaEngine
db_name = 'chinook'
schema_engine = SchemaEngine(engine=engine, db_name=db_name)
mschema = schema_engine.mschema
mschema_str = mschema.to_mschema()
print(mschema_str)
mschema.save(f'./{db_name}.json')创建MCP服务
数据库创建完成后,需要对外提供一个MCP服务,使得大模型可以调用该服务进行数据库的查询。这里采用fastmcp这个库来构建MCP服务,如以下代码。
python
from fastmcp import FastMCP
from sqlalchemy import create_engine, text
database_url = 'postgresql://postgres:roy2000@localhost:5532/chinook'
app = FastMCP("Database Query Server")
def execute_safe_query(sql):
"""执行SQL并返回结果,包含基础安全校验"""
# 1. 安全检查:禁止执行非SELECT语句或包含危险关键词的操作
#sql_upper = sql.replace("\n", "").strip().upper()
sql_upper = sql.strip().upper()
if not sql_upper.startswith('SELECT'):
raise ValueError("Only SELECT queries are allowed for safety.")
if any(keyword in sql_upper for keyword in ['DROP', 'DELETE', 'INSERT', 'UPDATE', ';--']):
raise ValueError("Potentially dangerous operation detected and blocked.")
# 2. 连接数据库并执行查询
with engine.connect() as connection:
try:
result = connection.execute(text(sql))
data = result.mappings().all()
serializable_result = [dict(row) for row in data]
return {"status": "success", "data": serializable_result}
except Exception as e:
return {"status": "error", "message": str(e)}
# 使用装饰器将函数注册为MCP工具
@app.tool()
def query_database(sql_query: str) -> dict:
"""
根据提供的SQL查询语句,从数据库中检索信息。
参数:
sql_query (str): 要执行的SELECT查询语句。
"""
print(f"Sql execute code: {sql_query}")
return execute_safe_query(sql_query)
if __name__ == "__main__":
engine = create_engine(database_url)
# 以标准输入输出(stdio)模式运行服务器,这是最常见的与客户端通信的方式
app.run(transport="sse", host="127.0.0.1", port=8000)运行该Python脚本,即可启动一个MCP服务,提供数据库查询服务。
创建智能体
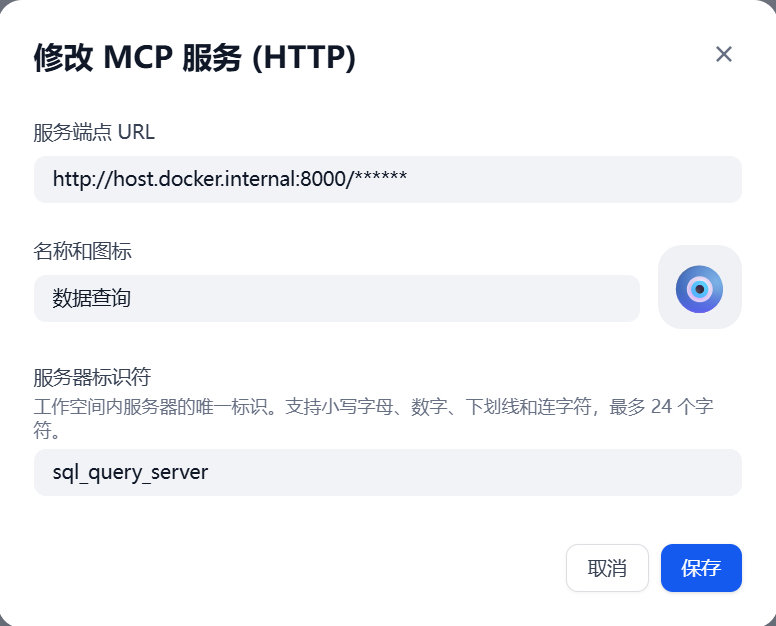
在Dify中,单击"工具"菜单,然后选择"MCP",最后单击"添加一个MCP服务",在设置中填入MCP服务的URL,之前启动的MCP服务的URL是http://127.0.0.1:8000/sse,因为我的Dify是在容器中运行的,所以这里的URL设置为http://host.docker.internal:8000/sse,设置后如下图。
现在可以创建Dify智能体了,在新建一个Chatflow工作流,并按如下方式编排节点。
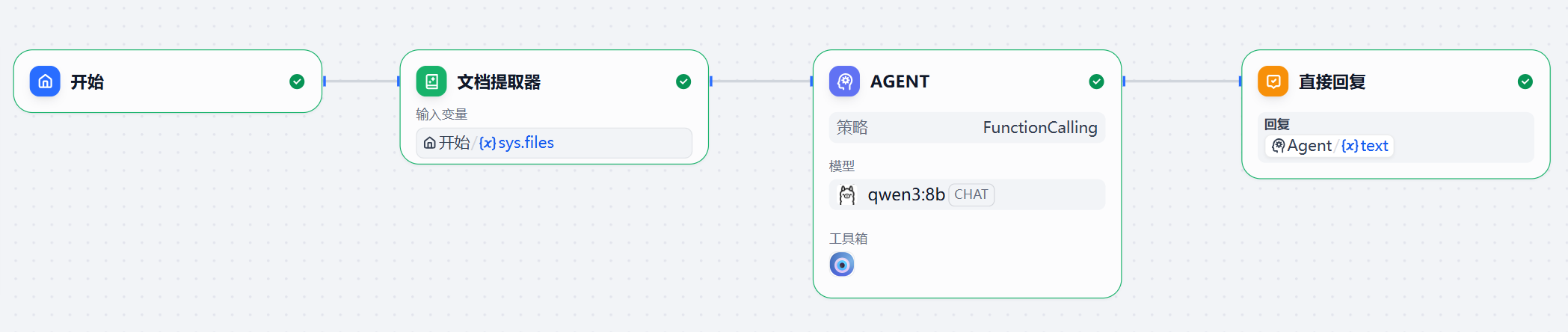
这里面的文档提取器节点用于对上传的数据库sql格式的文件进行解析,以获取文档的内容。Agent节点在工具列表中添加之前配置的MCP服务,并设置指令,如下图。
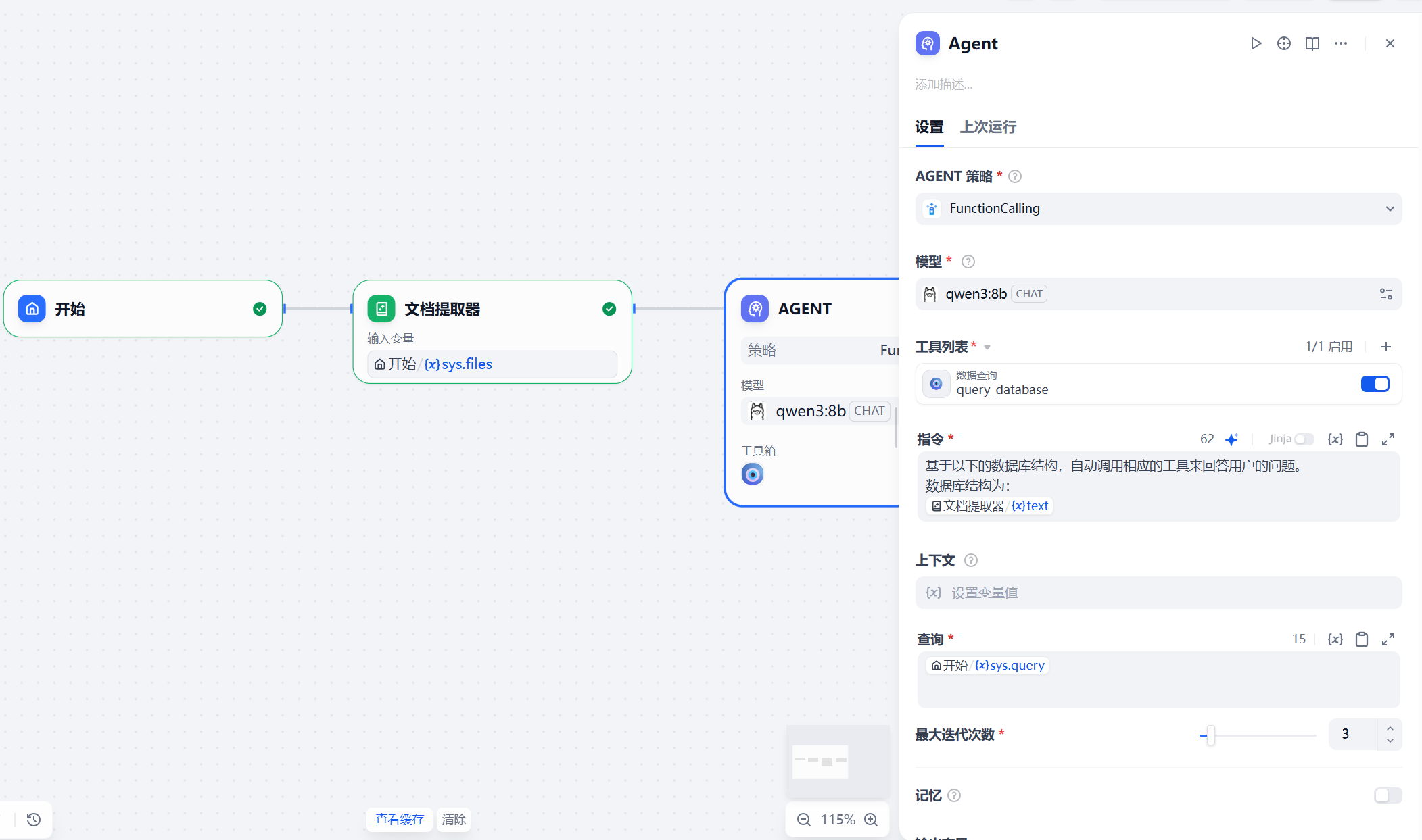
设置完成后,单击预览,进行测试。
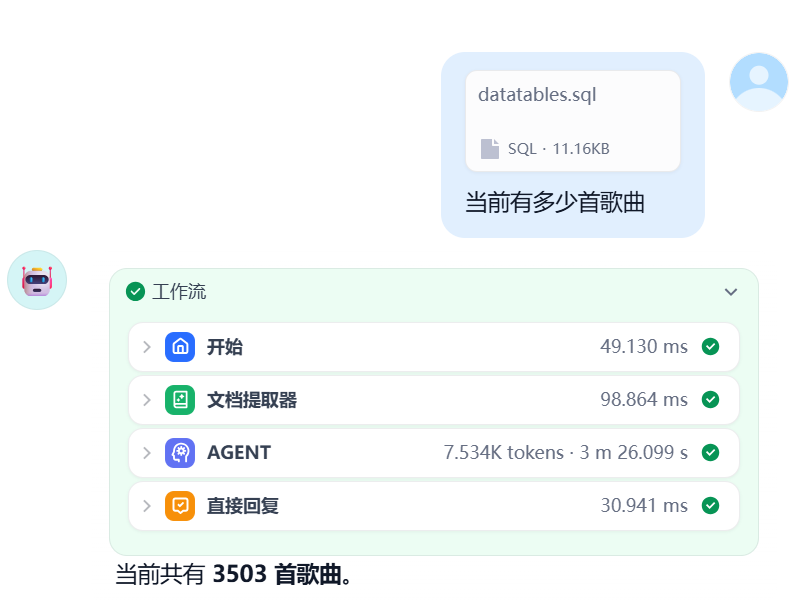
在对话窗口中上传之前创建的数据库格式的sql文件,然后询问"当前有多少首歌曲",Agent节点将基于数据库的格式,自动生成对应的SQL查询语句,然后进行回复。从MCP服务打印出的SQL语句"SELECT COUNT(*) FROM track;"来看,Agent节点的大模型正确的把用户的问题转换为数据库的查询语句,运行结果如下图所示。
现在问一个稍微复杂一点的问题,"按歌曲的风格来统计歌曲数量并进行排序,列出排名前十位的歌曲风格及其歌曲数量", MCP服务打印出的SQL语句是SELECT genre.name, COUNT(track.track_id) as count FROM track JOIN genre ON track.genre_id = genre.genre_id GROUP BY genre.genre_id ORDER BY count DESC LIMIT 10;", 运行结果如下。
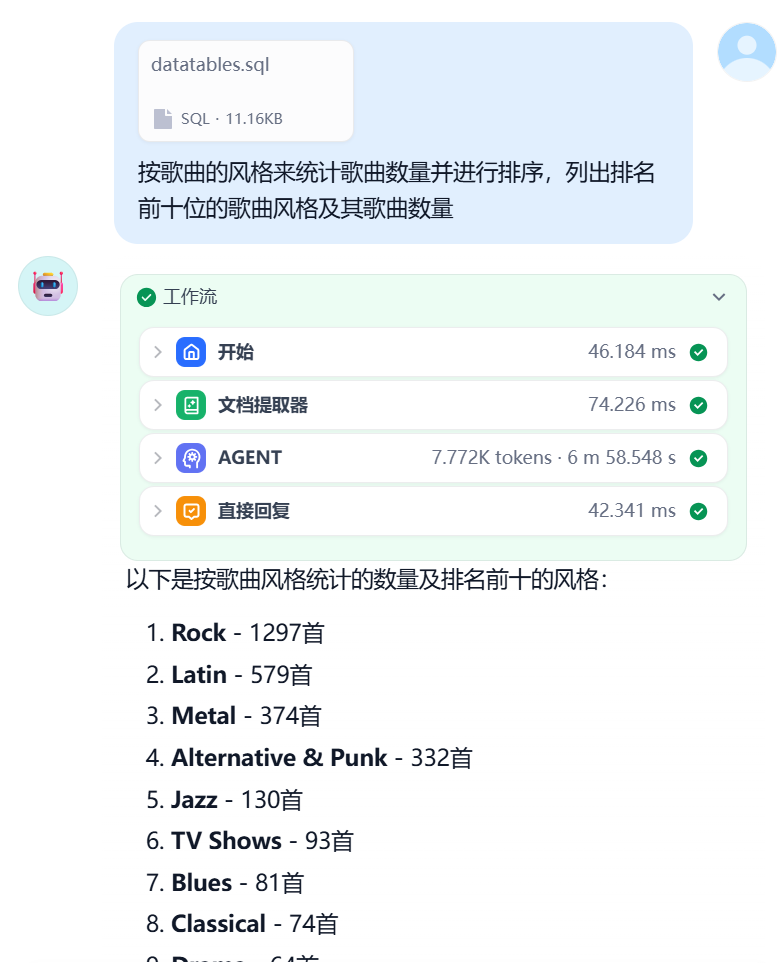
可见工作流可以准确的把用户的问题翻译为SQL语句,并在查询后给出结果。后续将进行功能的进一步丰富和优化。