在计算机视觉项目中,高质量的标注数据是模型训练成功的关键。然而,手动标注不仅耗时费力,还容易出错。幸运的是,随着 AI 技术的发展,自动标注工具 正在大幅降低这一门槛。

本文将手把手带你使用 X-AnyLabeling ------ 一款开源、强大且支持多种自动标注模型的图像标注工具,涵盖从环境搭建、模型配置、自动标注到格式导出的完整流程,真正做到"保姆级"教学!
B站同步视频:X-AnyLabeling 自动数据标注保姆级教程:从安装到格式转换全流程 | 支持YOLO数据格式一键导出
一、什么是 X-AnyLabeling?
X-AnyLabeling 是基于 AnyLabeling 的增强版,由社区开发者 CVHub520 维护。它集成了 YOLOv5/v8、SAM(Segment Anything Model)、Grounding DINO、RT-DETR 等主流目标检测与分割模型,支持一键自动标注,并兼容 LabelMe、YOLO、COCO、VOC 等多种标注格式。
✅ 支持 Windows / Linux / macOS
✅ 图形化界面,操作简单
✅ 自动标注 + 手动修正无缝衔接
✅ 多语言(含中文)支持
二、安装 X-AnyLabeling
方法一:直接下载可执行文件(推荐新手)
-
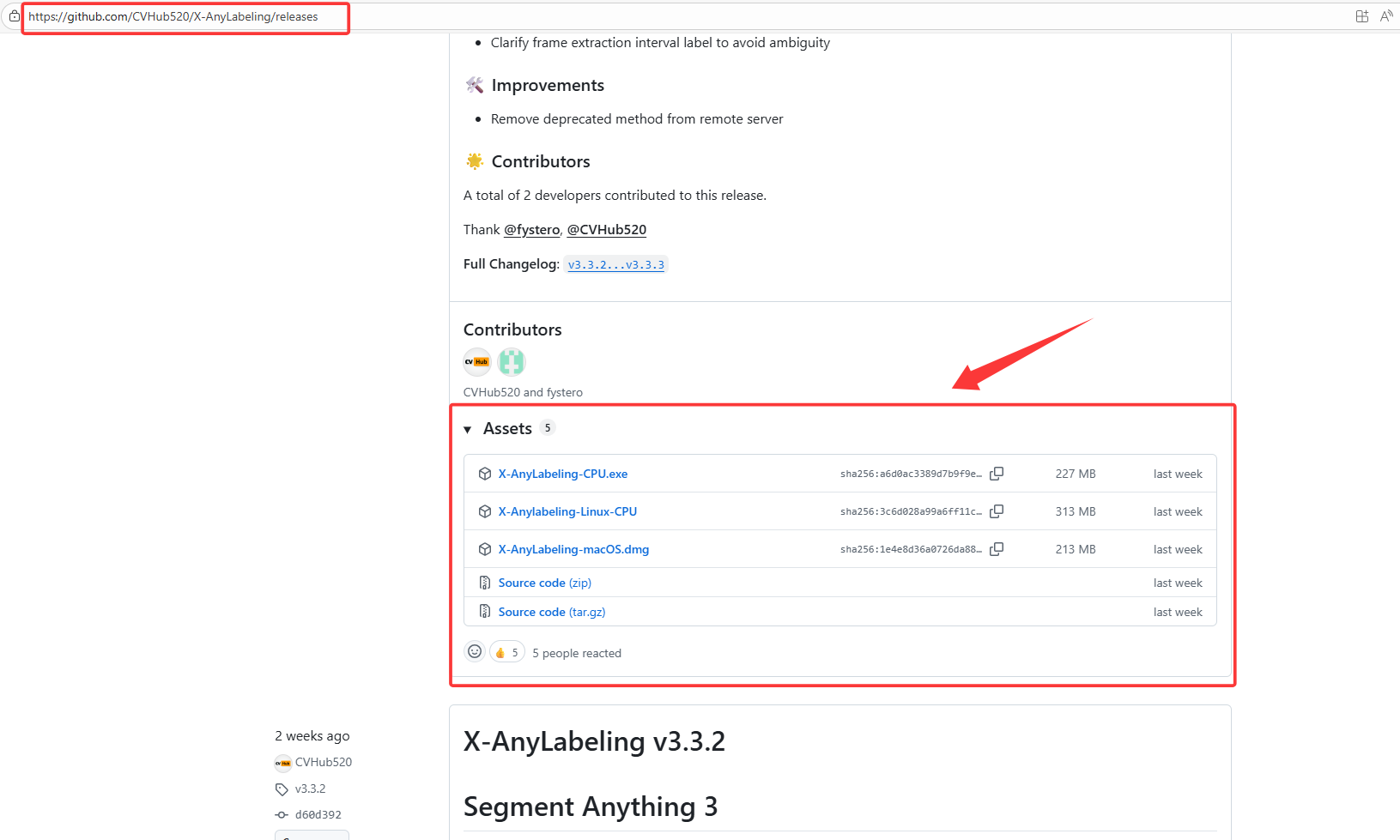
打开 GitHub Release 页面:
-
根据你的操作系统下载最新版本:
- Windows:
X-AnyLabeling-x.x.x-win64.zip - macOS:
X-AnyLabeling-x.x.x-mac.dmg - Linux:
X-AnyLabeling-x.x.x-linux.AppImage
- Windows:
-
解压(Windows/Linux)或安装(macOS),双击运行即可,无需配置 Python 环境!
💡 注意:首次启动会自动下载默认模型(如 YOLOv8n),请确保网络畅通。
方法二:从源码安装(适合开发者)
1.1 miniconda
bash
# 创建虚拟环境(推荐)
# CPU Environment [Windows/Linux/macOS]
conda create --name x-anylabeling-cpu python=3.10 -y
conda activate x-anylabeling-cpu
# CUDA 11.x Environment [Windows/Linux]
conda create --name x-anylabeling-cu11 python=3.11 -y
conda activate x-anylabeling-cu11
# CUDA 12.x Environment [Windows/Linux]
conda create --name x-anylabeling-cu12 python=3.12 -y
conda activate x-anylabeling-cu12🌟 如果你不知道你的电脑cuda版本,可以打开终端,输入
nvcc -V。
🌟【图像算法 - 01】保姆级深度学习环境搭建入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)

1.2 Venv(和miniconda 二选一)
bash
# CPU [Windows/Linux/macOS]
python3.10 -m venv venv-cpu
source venv-cpu/bin/activate # Linux/macOS
# venv-cpu\Scripts\activate # Windows
# CUDA 12.x [Windows/Linux]
python3.12 -m venv venv-cu12
source venv-cu12/bin/activate # Linux
# venv-cu12\Scripts\activate # Windows
# CUDA 11.x [Windows/Linux]
python3.11 -m venv venv-cu11
source venv-cu11/bin/activate # Linux
# venv-cu11\Scripts\activate # Windows1.3 Pip Installation
bash
# CPU [Windows/Linux/macOS]
pip install x-anylabeling-cvhub[cpu]
# CUDA 12.x is the default GPU option [Windows/Linux]
pip install x-anylabeling-cvhub[gpu]
# CUDA 11.x [Windows/Linux]
pip install x-anylabeling-cvhub[gpu-cu11]
1.4 拉取代码
安装xanylabeling
bash
git clone https://github.com/CVHub520/X-AnyLabeling.git
cd X-AnyLabeling
# CPU [Windows/Linux/macOS]
pip install -e .[cpu]
# CUDA 12.x is the default GPU option [Windows/Linux]
pip install -e .[gpu]
# CUDA 11.x [Windows/Linux]
pip install -e .[gpu-cu11]
打开xanylabeling
bash
# 终端直接输入xanylabeling
xanylabeling
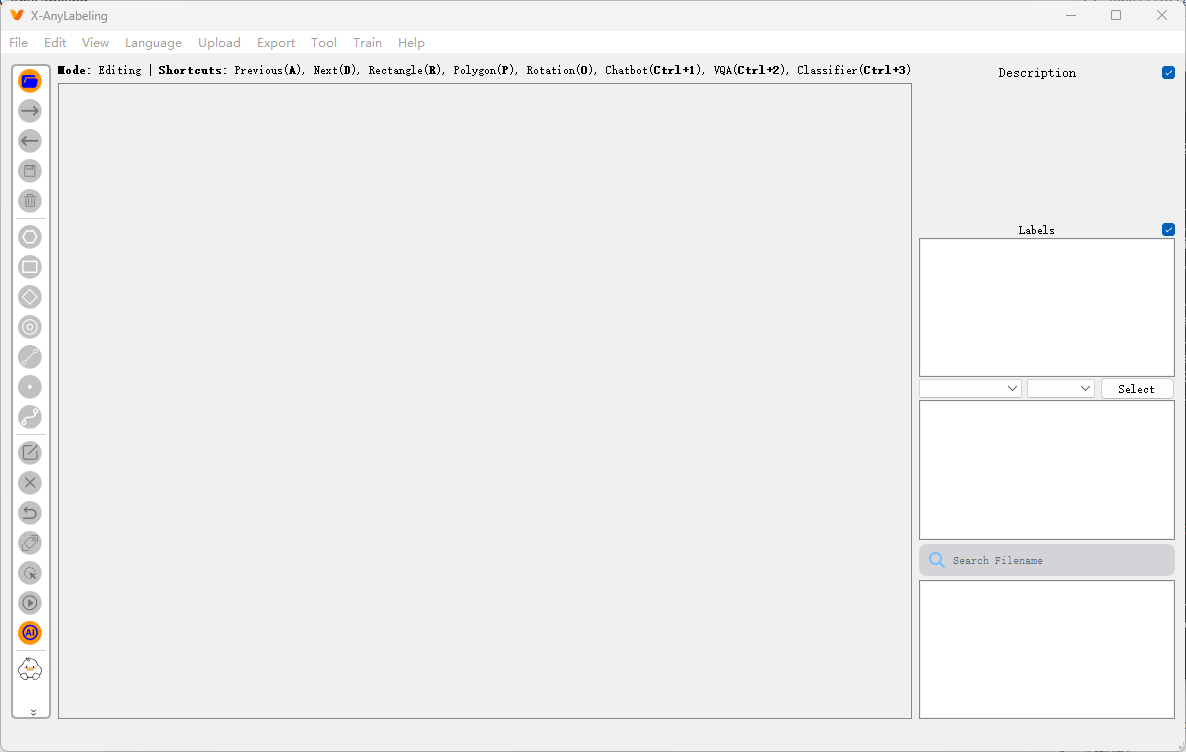
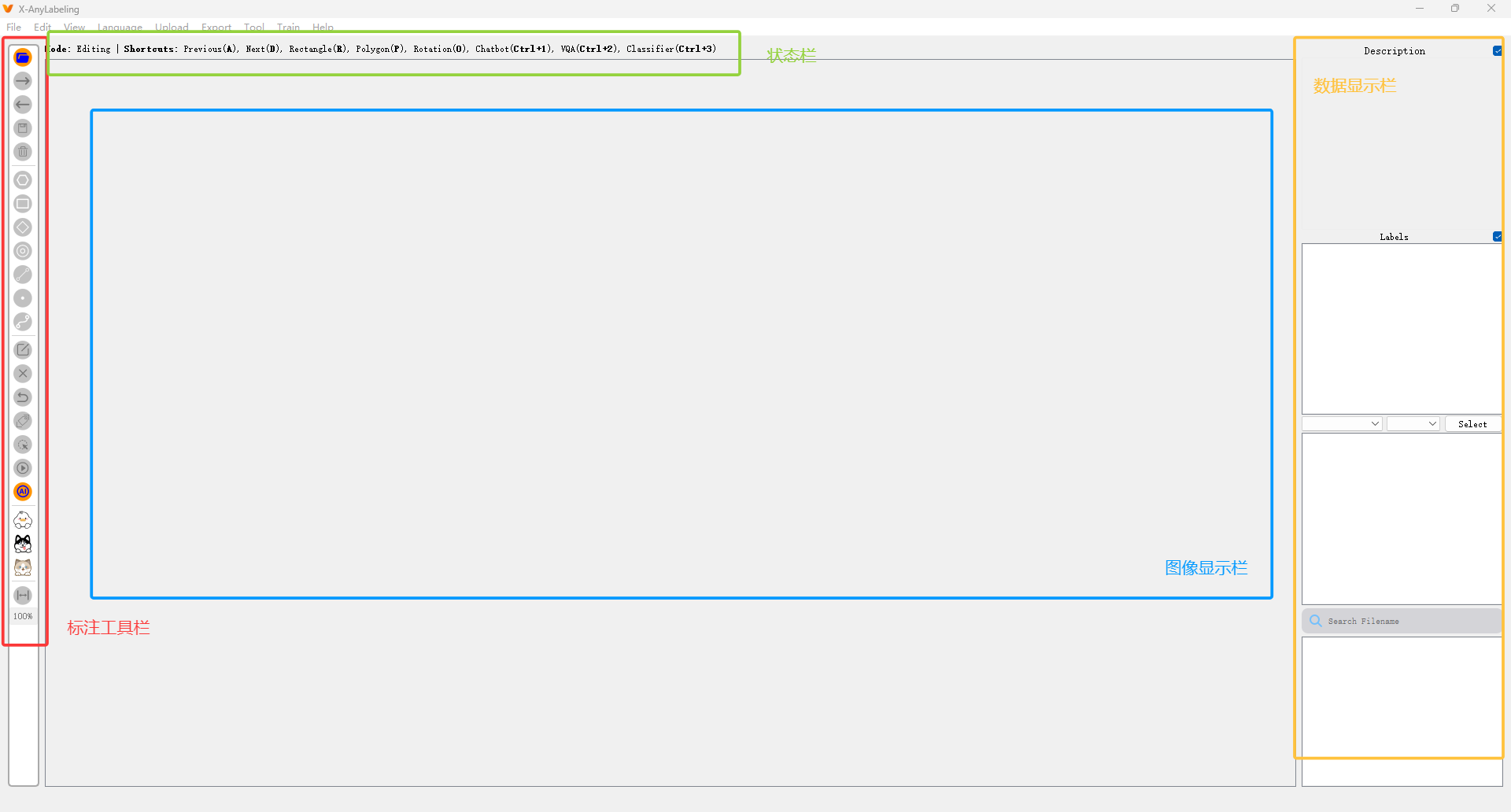
三、首次启动与界面介绍
启动后你会看到如下界面:
- 左侧:标注工具栏 + 模型控制面板
- 中间:图像显示区域
- 右侧:文件浏览器(可加载图像文件夹)
- 顶部菜单:文件、编辑、视图、模型、导出等
🌟 初次使用建议点击右上角 "模型" → "模型设置",确认自动标注模型是否已正确加载。
四、配置自动标注模型

X-AnyLabeling 内置多个预训练模型,以下以 ** SAM 联合标注**为例:
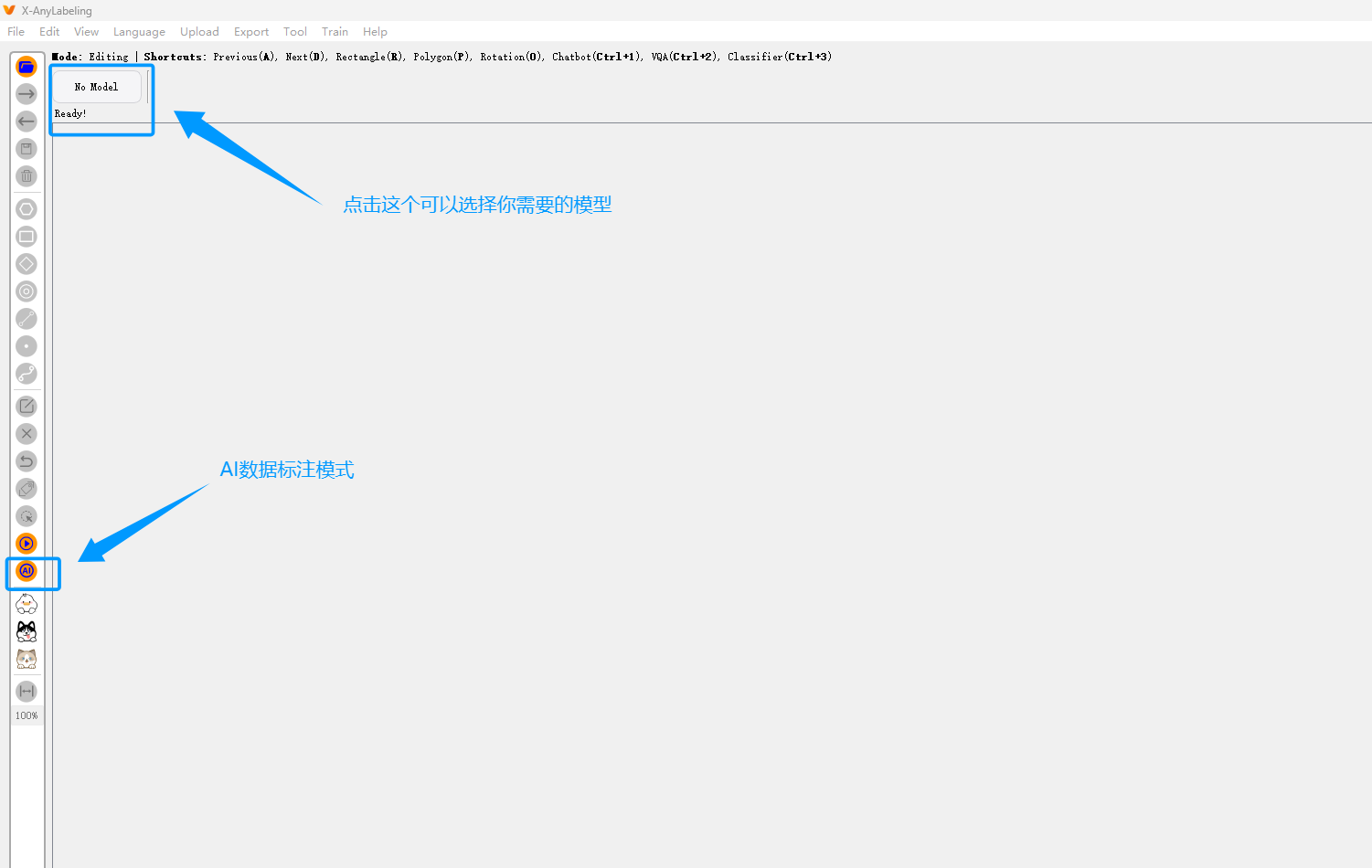
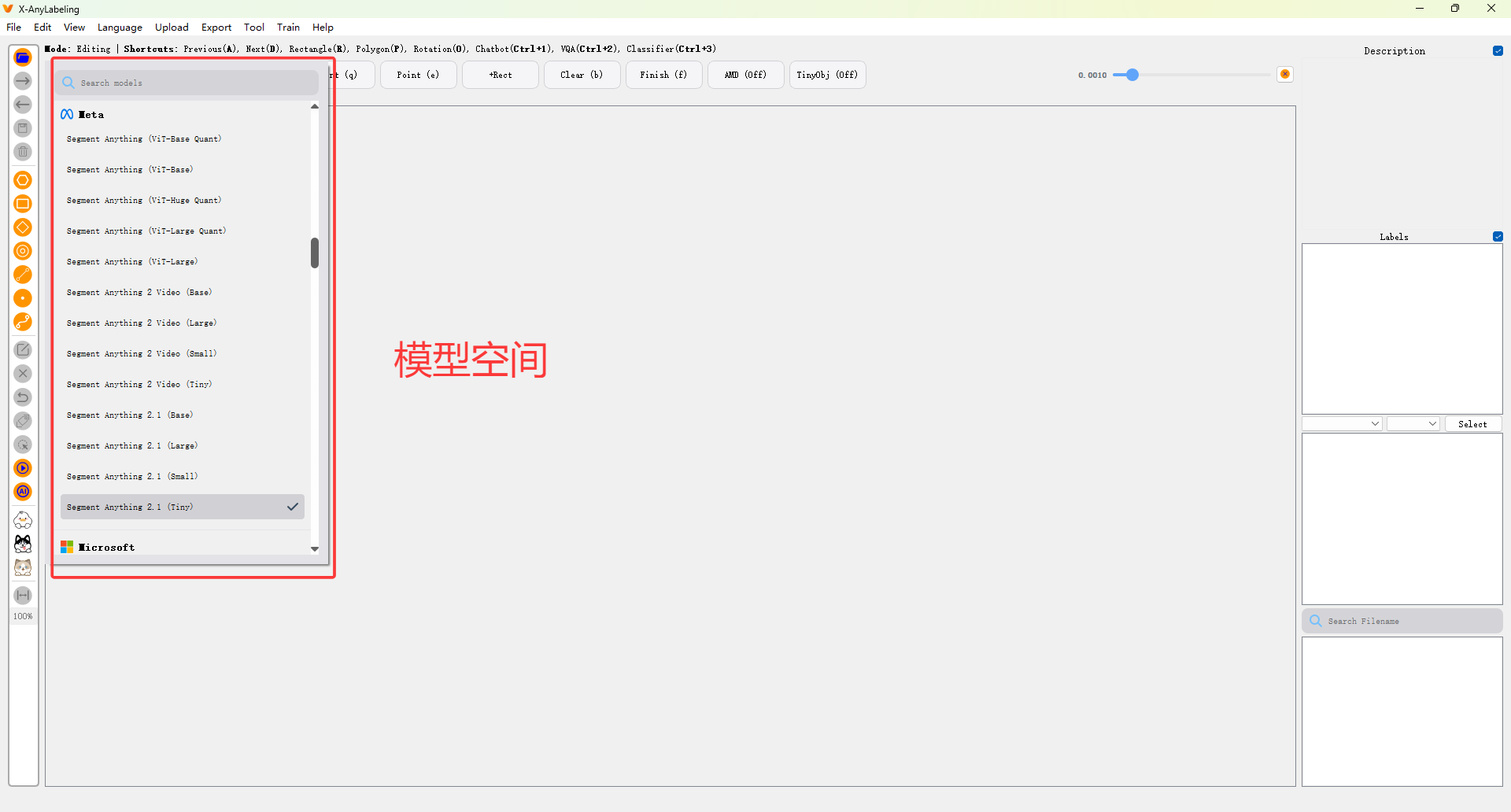
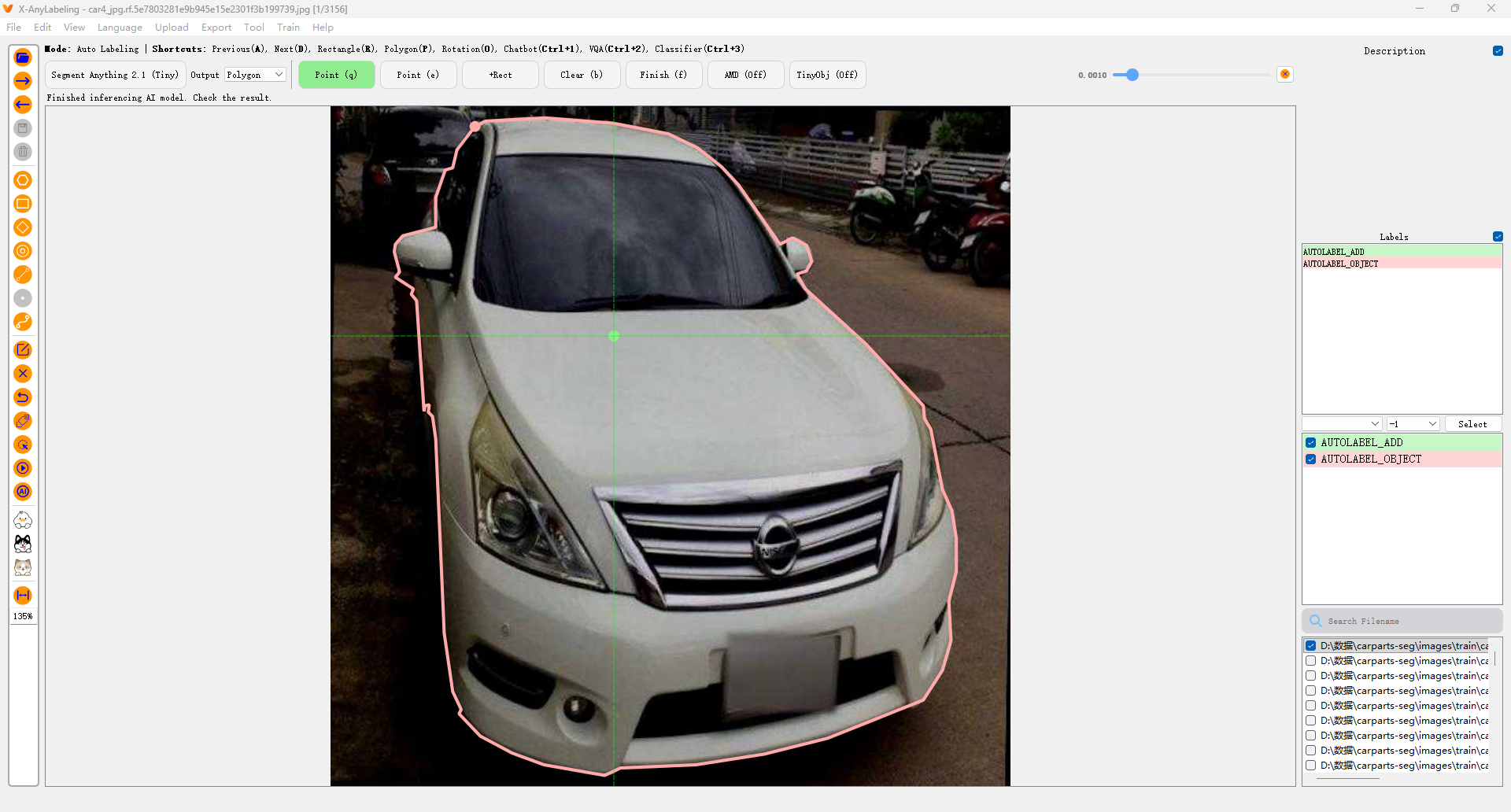
步骤 1:启用自动标注模式
- 点击顶部菜单 "模型" → "选择模型"
- 选择
Grounding-SAM (Text Prompt)等
🔍 推荐组合:
- 任意物体分割 → SAM
- 文本引导检测 → Grounding DINO
步骤 2:加载自定义模型(可选)
如果你有自己的训练好的 YOLO 模型(.pt 文件):
- 在"模型设置"中选择
YOLOv8 - 点击"模型路径",选择你的
.pt文件 - 设置类别名称(如
classes.txt)
✅ 支持 YOLOv5/v8/v10、RT-DETR、PP-YOLOE 等格式
五、自动标注实战演示
场景:对一批交通图像进行车辆和行人标注
1. 导入图像
- 点击左侧面板 "打开目录",选择包含图片的文件夹(支持 JPG/PNG 等)
2. 启动自动标注
- 选中一张图片
- 点击右下角 "Auto Labeling" 按钮(或按快捷键
Ctrl+L) - 工具会自动运行模型,生成边界框或分割掩码
3. 手动修正
- 自动标注可能有漏检或误检,可使用:
- 矩形框工具:添加/修改检测框
- 多边形工具:精细调整分割轮廓
- 删除工具:移除错误标注
4. 批量自动标注(高效!)
- 点击顶部菜单 "自动标注" → "批量自动标注"
- 选择输出格式(如 YOLO txt)
- 工具将自动处理整个文件夹,并保存标注结果
⏱️ 实测:100 张 1080p 图像,sam + RTX 4060,约 2 分钟完成!
六、导出标注结果(支持多种格式)
X-AnyLabeling 支持一键导出为以下格式:
| 格式 | 适用场景 | 文件结构 |
|---|---|---|
| YOLO | 目标检测训练(Ultralytics) | .txt 每张图对应一个 |
| COCO | 通用标准(Detectron2, MMDetection) | instances.json |
| Pascal VOC | 传统检测框架 | .xml |
| LabelMe | 多边形分割 | .json |
| Mask | 实例分割掩码图 | .png |

导出步骤:
- 点击顶部菜单 "文件" → "导出标注"
- 选择目标格式(如 YOLO)
- 指定保存路径(建议新建
labels文件夹) - 点击"确定",自动导出
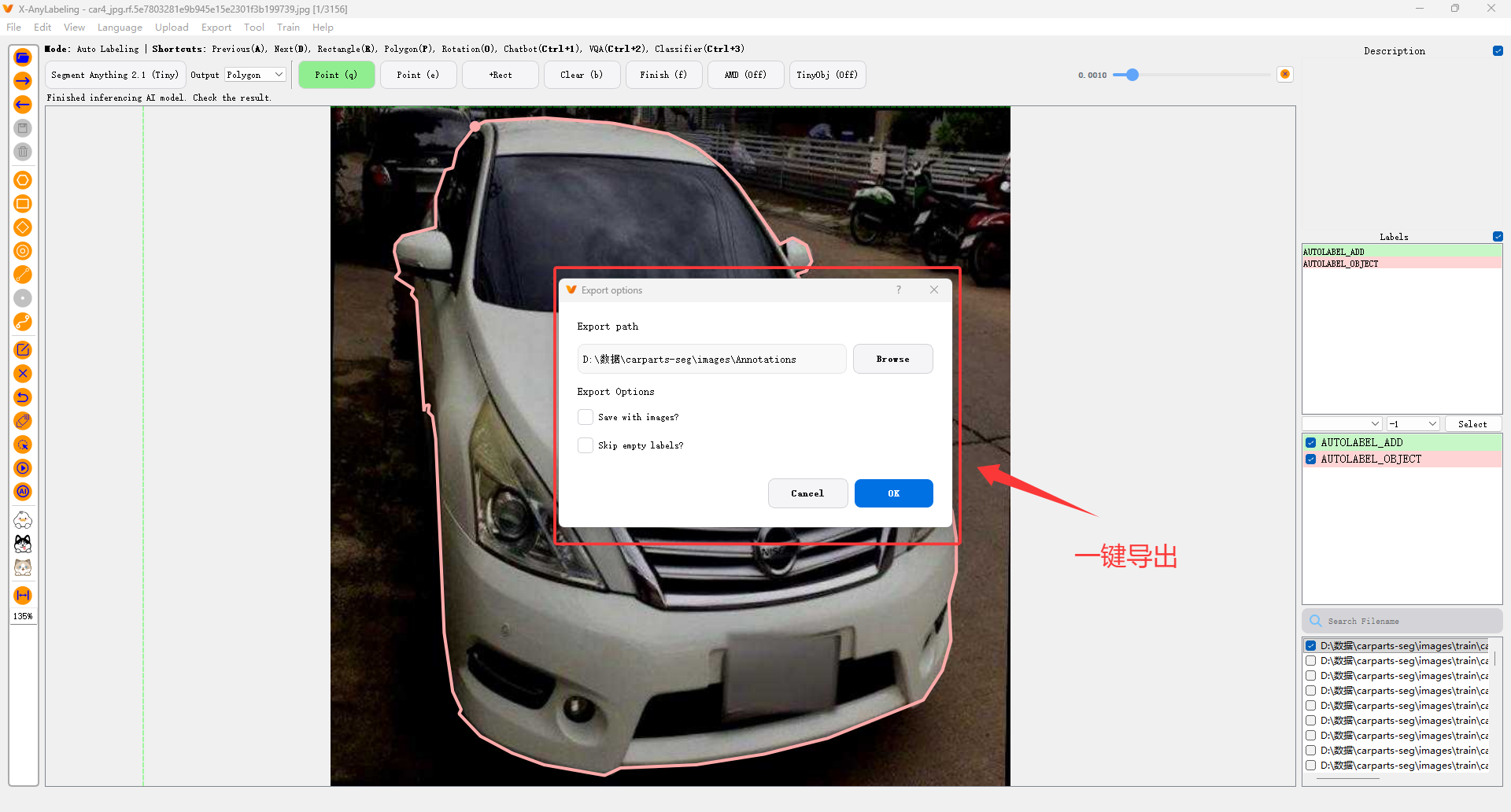
📌 注意:YOLO 格式需要提前在 "标签列表" 中定义类别顺序(与训练时一致)!
七、常见问题与解决方案
Q1:自动标注没有反应?
- 检查模型是否下载成功(查看
models/目录) - 确保图像路径不含中文或特殊字符
- 尝试切换模型(如从 YOLOv8 切换到 RT-DETR)
Q2:导出的 YOLO 标签类别不对?
- 在左侧"标签列表"中手动添加类别,顺序必须与模型输出一致
- 或在模型设置中指定
classes.txt
Q3:如何提升 SAM 分割精度?
- 使用 点提示(Point Prompt):在目标上点击正样本点(绿色),背景点(红色)
- 或结合 文本提示(Text Prompt):输入"car, person"等关键词
八、进阶技巧
- 快捷键大全 :
W/A/S/D:移动画布Ctrl+Z/Y:撤销/重做Space:临时拖动画布Q/E:切换上/下一张图
- 多人协作:导出 LabelMe JSON 后,可上传至 CVAT 或 Label Studio 进行团队审核
- 自定义模型集成 :通过修改
x_anylabeling/configs/下的 YAML 配置文件,接入自己的 ONNX 或 TensorRT 模型
九、结语
X-AnyLabeling 极大地简化了数据标注流程,尤其适合中小团队快速构建高质量数据集。无论是科研实验还是工业落地,它都能帮你节省 70% 以上的标注时间。
🌈 开源地址:https://github.com/CVHub520/X-AnyLabeling
📚 官方文档:见 GitHub README
赶快动手试试吧!如果你觉得这篇教程有帮助,欢迎点赞、收藏,并分享给需要的朋友!