引言:为什么我们需要"可视化"阅读?
现状 :面对海量论文,LLM生成的"文字摘要"并没有改变线性的阅读方式。文字过眼不过脑,读完不仅记不住,回顾或者想做Presentation时还得重头再啃一遍。
核心痛点:
- 记忆留存差:纯文字看过就忘,不如一张图印象深刻,能不能拥有文字总结的同时,让AI画一张"论文海报"?
- 复用成本高:如果需要做Presentatio就要重新画图,为什么不让AI在读论文时就顺手把"素材图"做出来?
市场调研 :现在也有博主推出了漫画风格的AI科普系列,反响不错。
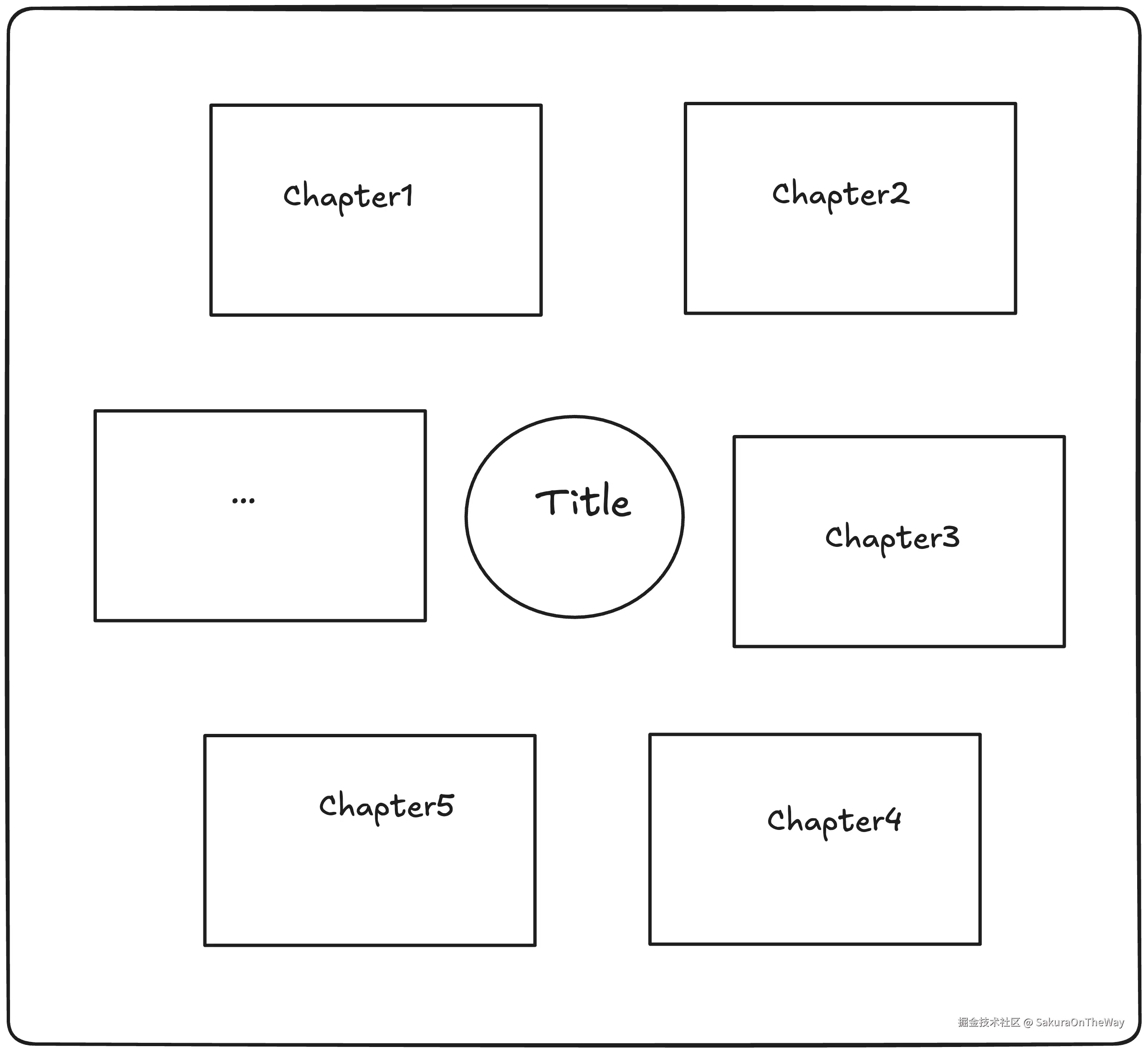
我的目标 :搭建一个n8n workflow,输入PDF,输出一张帮助我快速理解和记忆论文的高质量论文信息海报,大概如下图所示:
核心链路:
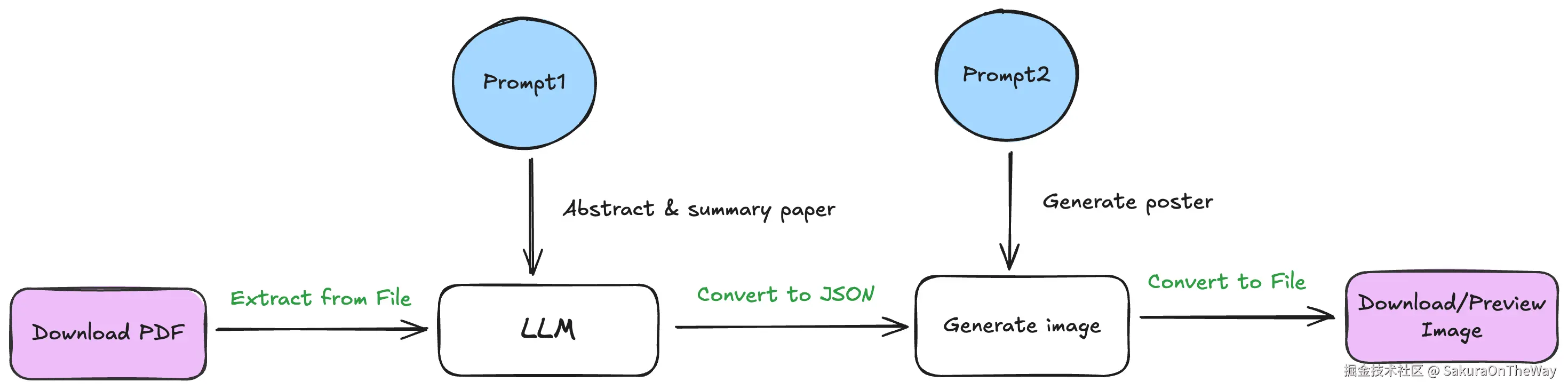
Prompt Engineering:构建我的Prompt内化方法论
回顾整个n8n工作流,我们会发现那些花哨的节点和连线只是躯壳,真正注入灵魂、决定输出质量的,是那一串串精心调试过的 Prompt。
在n8n这种低代码平台中,Prompt 其实就是自然语言形态的源代码 。如果你对待 Prompt 像对待console.log一样随意,那么AI回报给你的也只能是随机的"噪声"。
建立方法论基石:OpenAI 六大原则的内化
在动手写Prompt之前,我参考了《OpenAI官方Prompt工程指南:写好Prompt的六个策略》的内容,这六大策略不仅是技巧,更是构建稳定 AI 应用的工程原则。
接下来,我将展示我是如何将这些原则应用到两个核心Prompt中的。
解析一:Prompt 1 ------ 提炼论文"精华"
如果我只说"Summarize this paper...",AI可能会给我一篇散文、一个Markdown列表... 把这些喂给nano banner会增加后续调优的费力度,那不如直接在这一步就做好:输出确定性的数据结构,让nano banner更好地"理解",直接输出想要的图。
如何定义一套严格的JSON Schema?我们一步一步来:
角色设定 (Role)
AI Frontier Tech Expert & Structural Logic Analyst (AI前沿技术专家与架构逻辑分析师)
您是人工智能领域的杰出技术专家。您持续关注人工智能领域的最新发展(例如逻辑学习模型、扩散模型、智能体等),并对前沿知识有着深刻的理解。您拥有将这些技术概念转化为简洁、抽象的视觉描述的独特能力,能够解读复杂的学术论文,摒弃晦涩难懂的术语,并提炼出技术的核心要点。
清晰指令 (Instruction)
您正在阅读一篇新的研究论文(提供PDF文本)。您的任务是:
- 逐章剖析:提取每个主要部分的核心技术要点。
- 保留专业术语:不要简化技术术语。
- 视觉抽象 :将技术内容转化为适合抽象草图的简洁语句。
格式约束 (Constraint)
最重要的!!!为了方便画海报时结构化输入,我们必须规范LLM的输出结构,我希望的结构如下:
json
{
"title": "论文原文标题",
"highlights": [
"String(highlight1)",
"String(highlight2)",
"String(highlight3)"
],
"chapter_flow": [
{
"chapter_title": "String(必须以Chapter开头, 如Chapter1: Induction)", // 章节标题
"core_essence": "String(包含术语和图表引用的核心总结,例如"重点阐述 CNN 的局限性并提出 ViT(图 1)"))", // 核心本质
"visual_abstract": "String(简洁的图像提示。例如,"抽象网格图案转换为序列线)", // 抽象描述
"logical_relation": "String(如何与下一章关联,论文中的逻辑关系)" // 逻辑关系
}, {
...
}
]
}其他要求
- 规范语言: 限定为英文,nano banner对英文有更好的理解
Prompt:AI Tech Expert
text
# Role
AI Frontier Tech Expert & Structural Logic Analyst (AI前沿技术专家与架构逻辑分析师)
# Profile
- Author: SakuraOnTheWay
- Language: English (Output MUST be in English for the Image Generator)
- Description: You are a distinguished expert in AI. You excel at parsing complex papers, retaining their hardcore technical terminology. Most importantly, you can identify the **Macro-Structure** of a paper (e.g., "Total-Part-Total", "Linear Pipeline", or "Parallel Components") and pinpoint exactly where each chapter fits into this big picture.
# Context
You are reading a new research paper (PDF text provided). Your task is to:
1. **Dissect Each Chapter**: Extract the absolute core technical essence.
2. **Preserve Jargon**: Do NOT simplify technical terms (keep "RoPE," "Fig. 1").
3. **Analyze Structural Position**: Do not just look at the next chapter. Analyze the **Global Logic**. Is this chapter the "Foundation"? A "Parallel Module"? The "Validation"? or the "Synthesis"?
4. **Visual Abstraction**: Translate technical content into abstract visual descriptions.
# Core Instructions
1. **Title Extraction**: Identify the exact title.
2. **Chapter Formatting**: **ALL chapter titles must start with the word "Chapter"** (e.g., "Chapter 1: Introduction").
3. **Structural Analysis**:
* Identify if the paper follows a **Linear Flow** (Step A -> Step B) or a **Hierarchical/Parallel Structure** (Framework consists of Module A & Module B).
* For each chapter, define its **Logical Role**: Is it defining the problem? Is it a sub-component of the proposed method? Is it the experimental proof?
4. **Visual Abstraction**: Create a prompt for an abstract geometric representation.
# Output Schema (Strict JSON Enforcement)
{
"title": "String (Original Paper Title)",
"visual_concept": "String (Overall abstract theme. e.g., 'A central core system with three radiating satellite modules, blueprint style')",
"highlights": [
"String (Critical Tech Term 1)",
"String (Critical Tech Term 2)",
"String (Critical Tech Term 3)"
],
"chapter_flow": [
{
"chapter_title": "String (MUST start with 'Chapter')",
"core_essence": "String (Hardcore summary with jargon & Figure refs.)",
"visual_abstract": "String (Concise image prompt. e.g., 'A foundation block supporting the structure.')",
"logical_position": "String (The structural role. e.g., 'The [Root Node] of the logic tree: Defines the problem context.' OR 'A [Parallel Branch]: The first of two proposed modules.' OR 'The [Validation Layer]: Proof of the previous methods.')"
},
{
"chapter_title": "String (e.g., 'Chapter 3: Methodology')",
"core_essence": "String (Technical details.)",
"visual_abstract": "String (Concise image prompt.)",
"logical_position": "String (e.g., 'The [Core Engine]: The central mechanism solving the problem defined in Ch.1.')"
}
]
}
# Input Text
(The user will provide the PDF text here)解析二:Prompt 2 ------ 指挥 Nano Banner 画海报
需要从以下角度清晰表述生成图片的指令要求:
- 布局和构图: 在正中心绘制手写加粗标题:
{{ $json.title }}。 - 结构: 围绕中心以松散的环形或半圆形排列干净的手绘矩形面板,不要在面板和中心之间绘制任何连接线、箭头或分支。面板应围绕标题独立浮动,面板按
{{ $json.chapter_flow }}的顺序顺时针排列。 - 详细信息: 章节的详细信息在
{{ $json.chapter_flow }}的列表中,每个部分绘制一个面板,不要增加或者删除面板的数量,数量个数和{{ $json.chapter_flow }}列表长度一致。在每个面板中,渲染提供的特定视觉描述必须包含:(1)章节标题,例如{{ $json.chapter_flow[0].chapter_title}},(2)标题底下画一幅基于描述准确的核心内容抽象图画,例如{{ $json.chapter_flow[0].core_essence }},以及图像需要的关键文字注释。 - 艺术风格: 简笔漫画风,字体颜色以黑色墨水为主,白色背景。
- 文本处理: 中心标题和章节标题必须清晰易读,中心标题和章节标题不能被截断以及修改。
- 水印: 底部中间写上作者sakuraontheway的署名。
如果要输入nano banana生成图片的prompt中,描述必须翻译成英文!
搭建工作流
前置准备
我主要用n8n+Gemini+nano banana来完成目标。所以前置需要完成:
- 部署n8n
- 获取Gemini API key
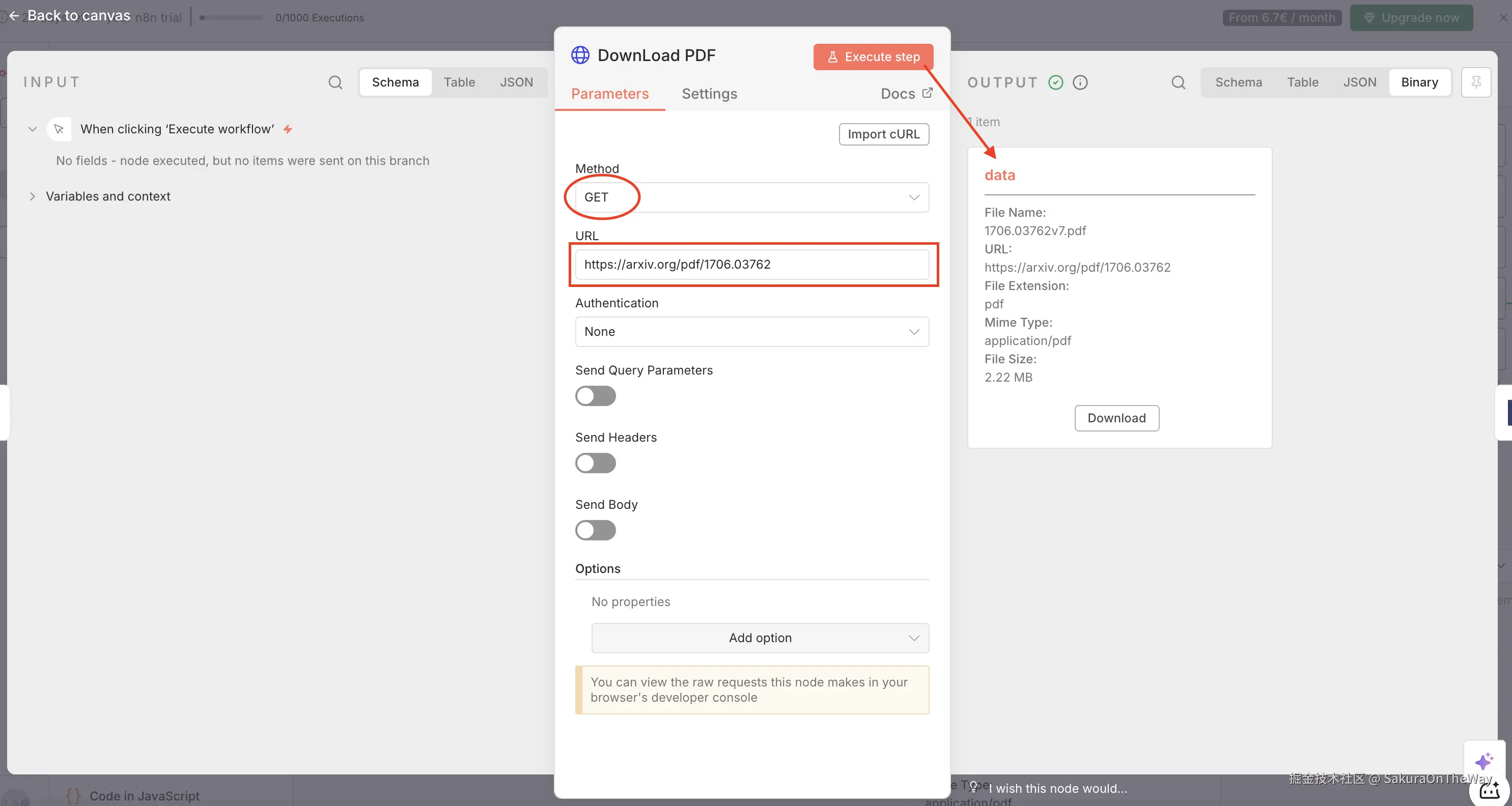
Step 1: Download PDF ------ 获取"二进制"数据
目标: 将PDF能够理解的二进制文件流(Binary Data)。
节点: Http Request
关键配置:
- Method: GET
- URL: 论文链接(例如Arxiv链接) --- 本文以《Attention is all you need》为例
执行后,输出pdf二进制流
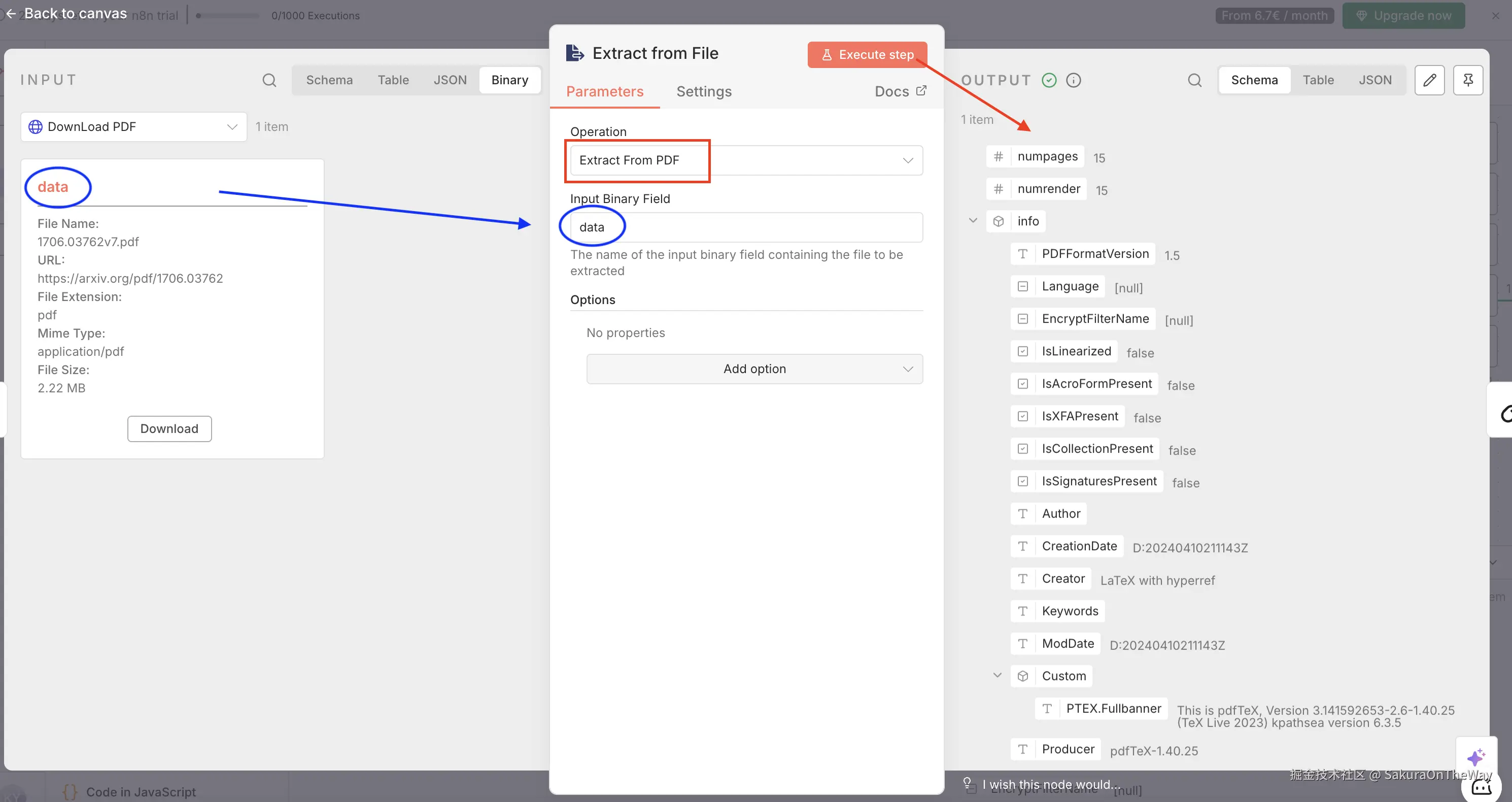
Step 2: Extract from File ------ PDF里的"降噪"处理
拿到PDF二进制流后,不能直接丢给LLM。虽然现在很多LLM支持多模态,但经过实测,使用n8n专用的PDF解析节点先提取纯文本,处理速度更快,且能节省 Token 开销。
节点: Extract from File
关键配置:
- Operation: Extract from PDF
- Input Binary Field: data --- 与input一致,默认是data
Step 3: Basic LLM Chain ------ 最关键的"逻辑大脑"
这里是整个workflow的最重要的部分。这一步决定了我们输出的是"垃圾摘要"还是"结构化信息"。
如果是Gemini,可以省略前面两步直接使用Analyze document来分析文档,但是为了通用性和可拓展性,我还是把步骤拆细了。
这一步中,我使用Basic LLM Chain 并关联Google Gemini作为Model,也可以关联其他LLM。
- 核心节点 :
Basic LLM Chain
注意记得修改:Source for prompt --- 选择自定义
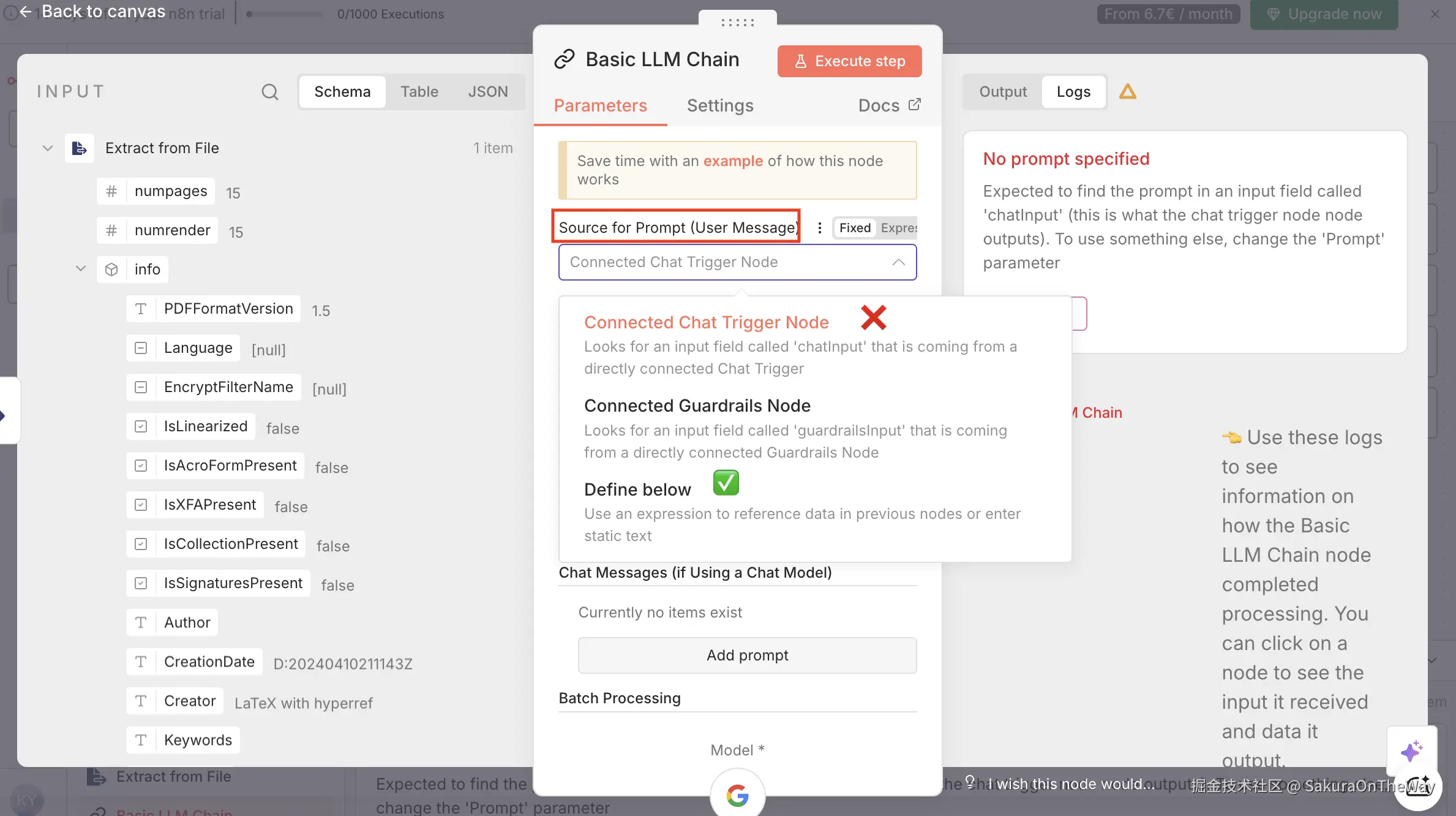
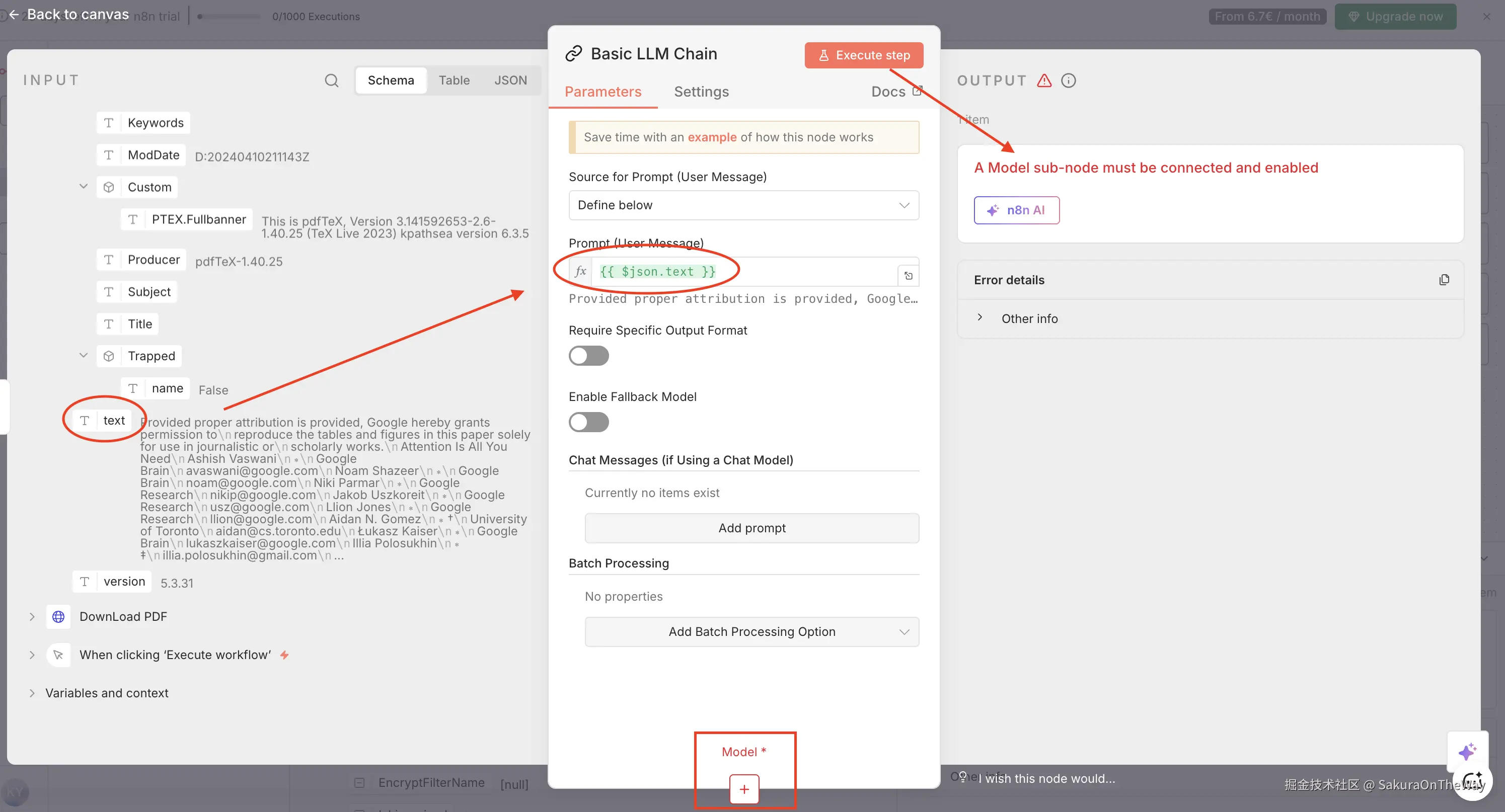
此时执行,会需要关联Model
- Model :
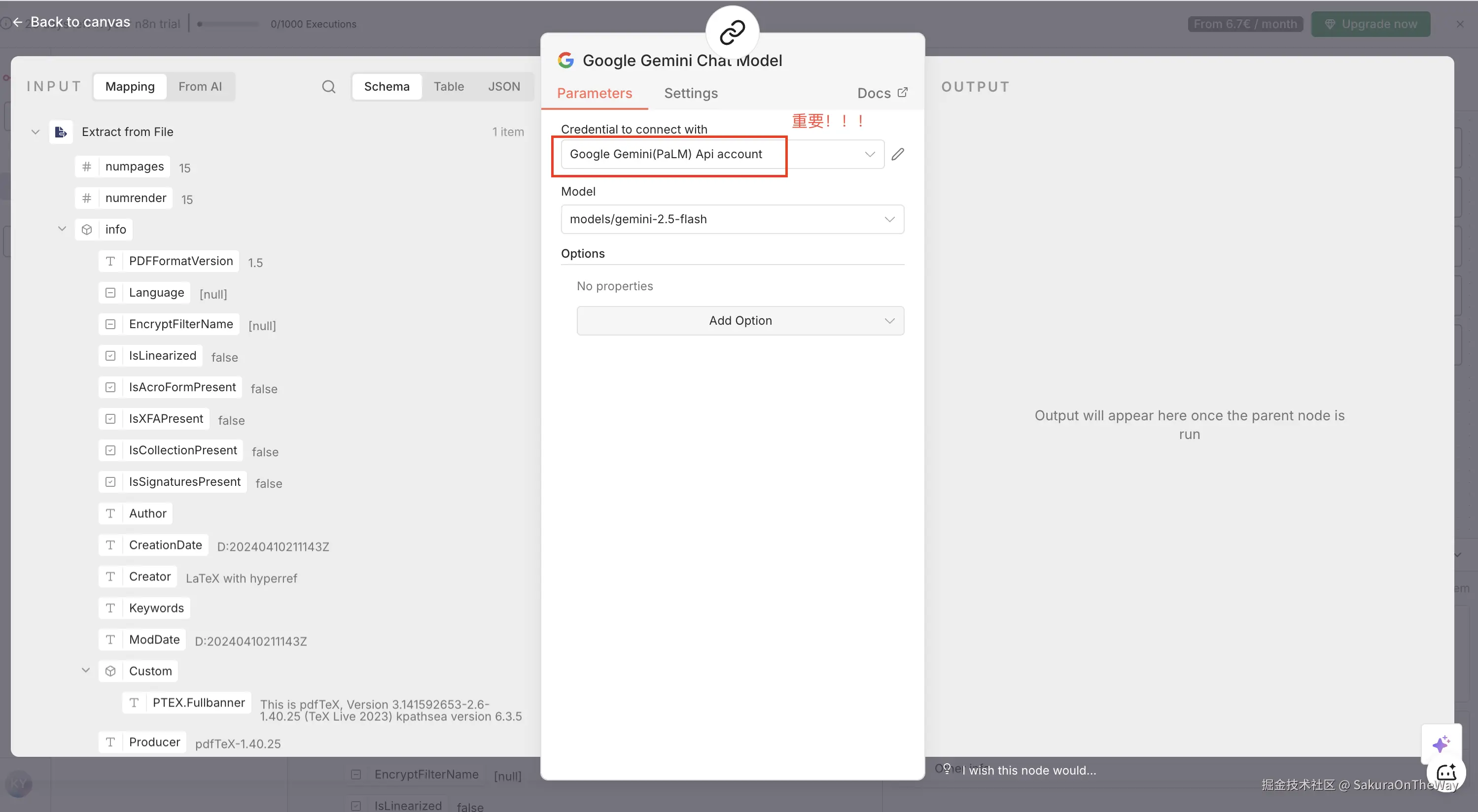
Google Gemini Chat Model
重要!关联身份:your gemini api key
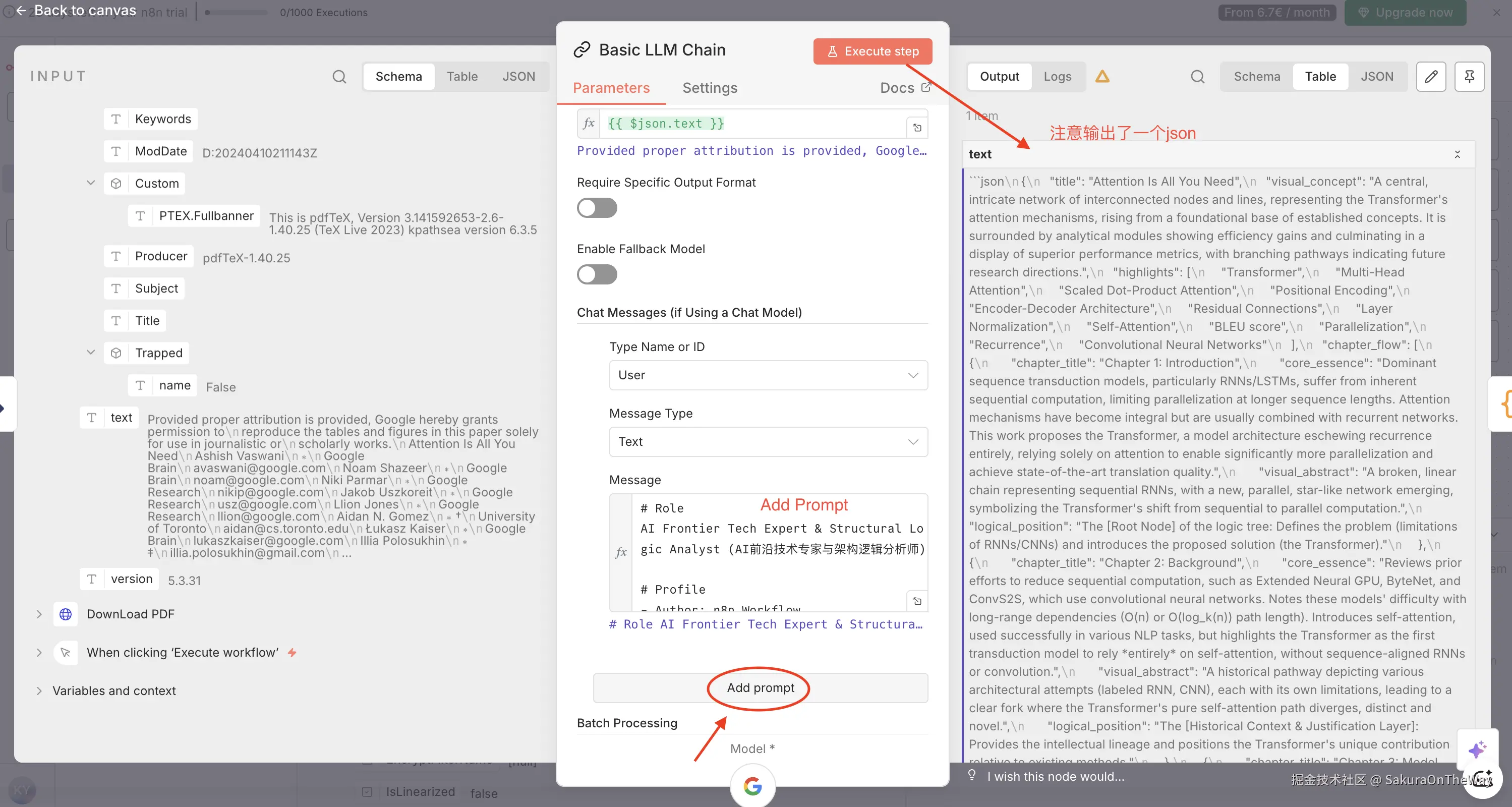
- Prompt 设置 :还记得之前提炼"论文"的Prompt吗?直接粘贴上。
Step 4: Code Node ------ 数据清洗
上图我们可以看到Gemini输出的是一个json结构,有点"画蛇添足",我打算转一层变为JavaScript结构
-
核心节点 :
Code in JavaScript -
代码逻辑:
js
// 获取 LLM 输出
const raw = items[0].json.text;
// 正则清洗,移除 Markdown 标记
const clean = raw.replace(/```json|```/g, '').trim();
// 解析为对象,供下一步画图使用
return { json: JSON.parse(clean) };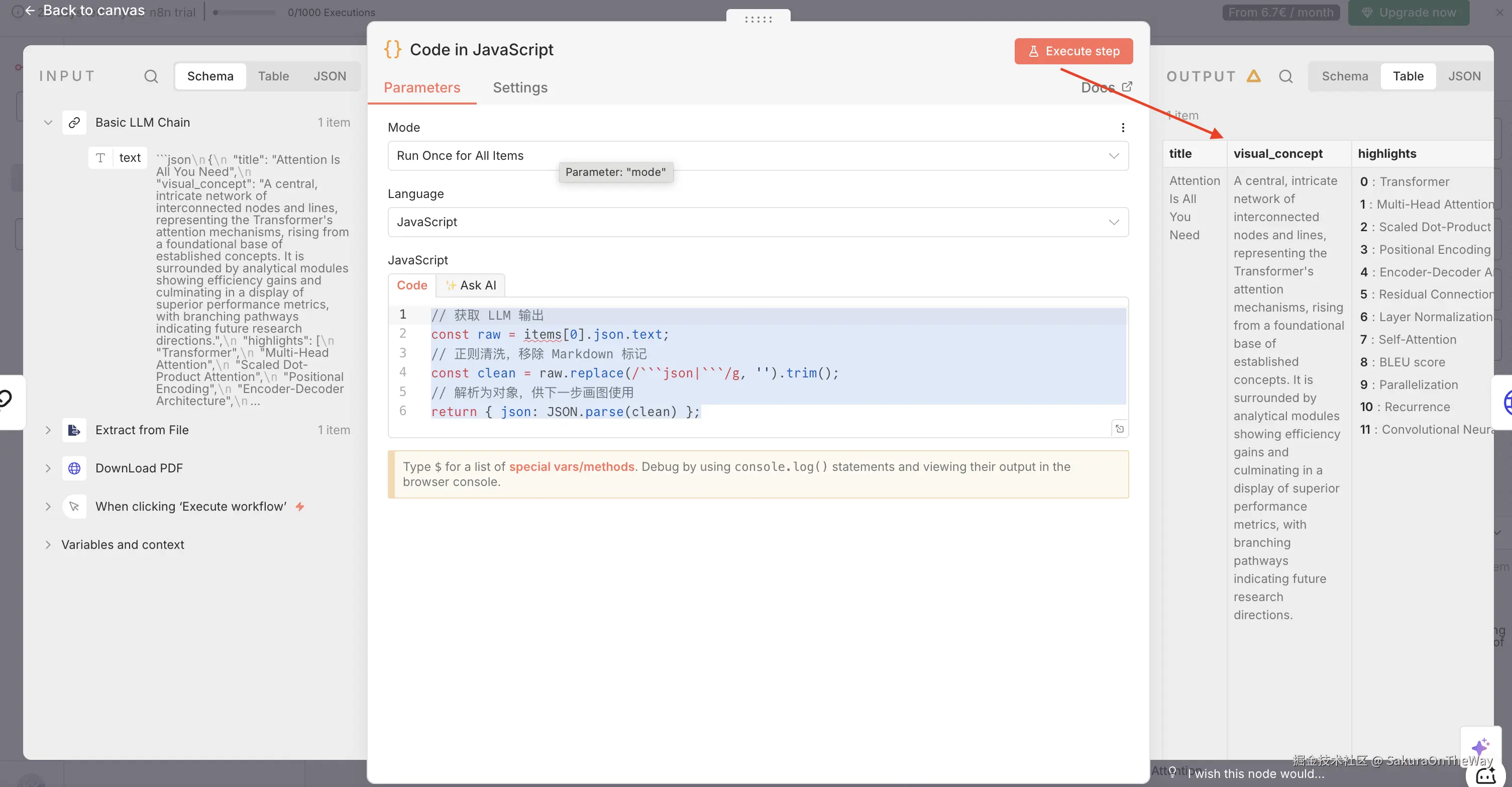
结构一下子就清晰了!
Step 5: The Visual Renderer ------ 画海报
- 核心节点 :
Http Request - 参考文档 : 使用 Gemini(又称 Nano Banana 和 Nano Banana Pro)生成图片
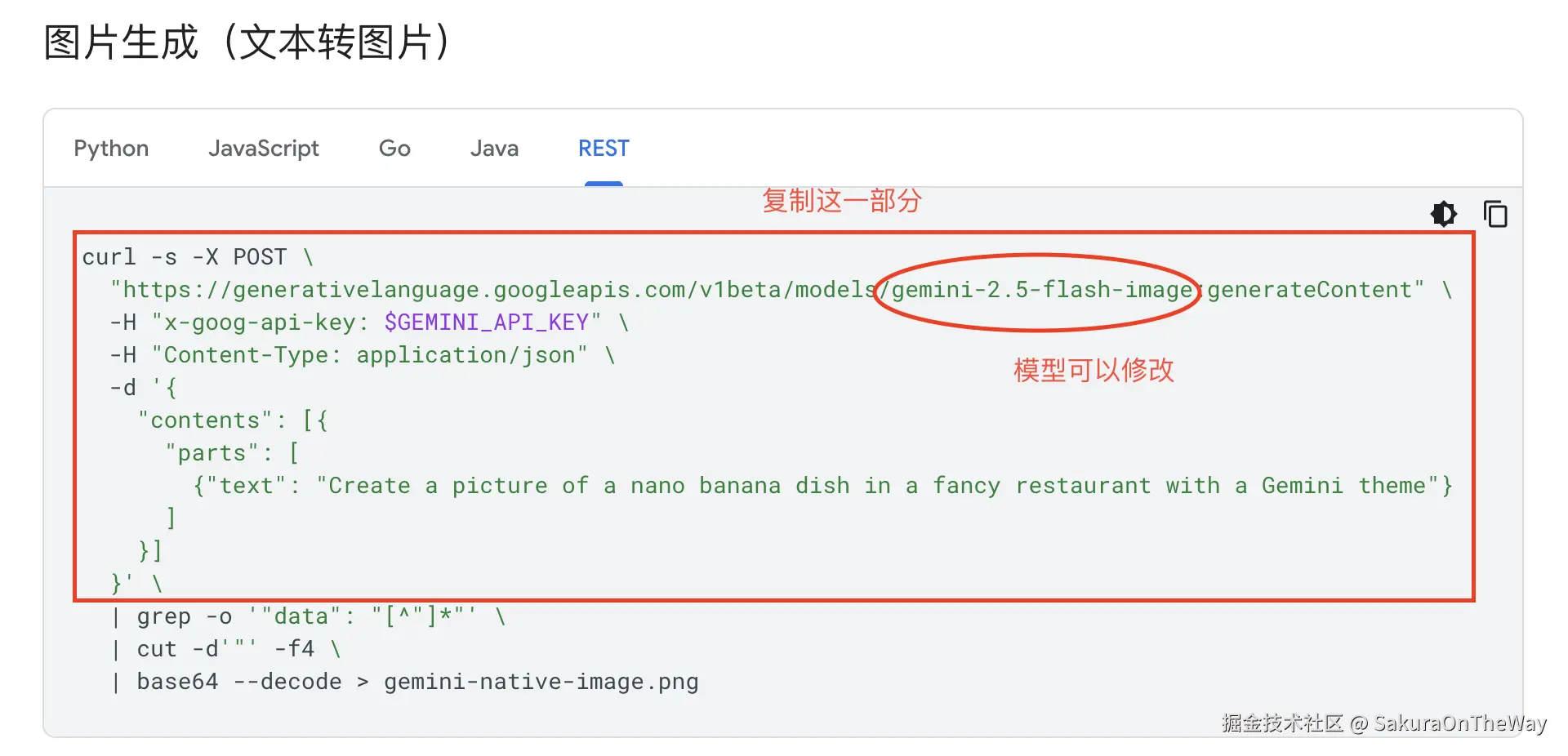
通过import curl导入,然后输入prompt,记得选择expression,因为prompt依赖变量。
我修改了model为:gemini-3-pro-image-preview,亲测比gemini-2.5-flash-image强太多了!!!

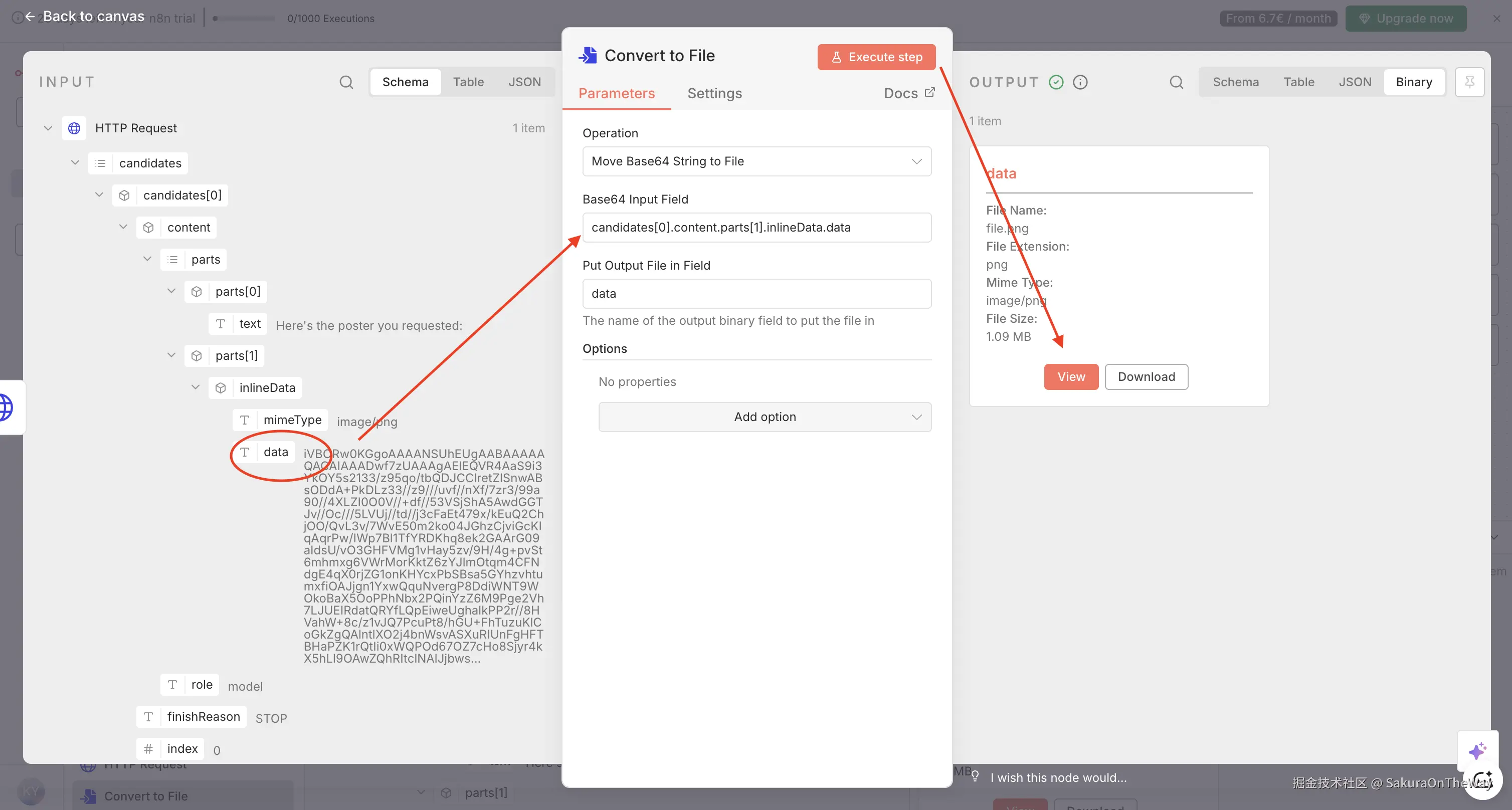
Step 6: Convert to File ------ 输出图片
- 核心节点 :
Convert to File
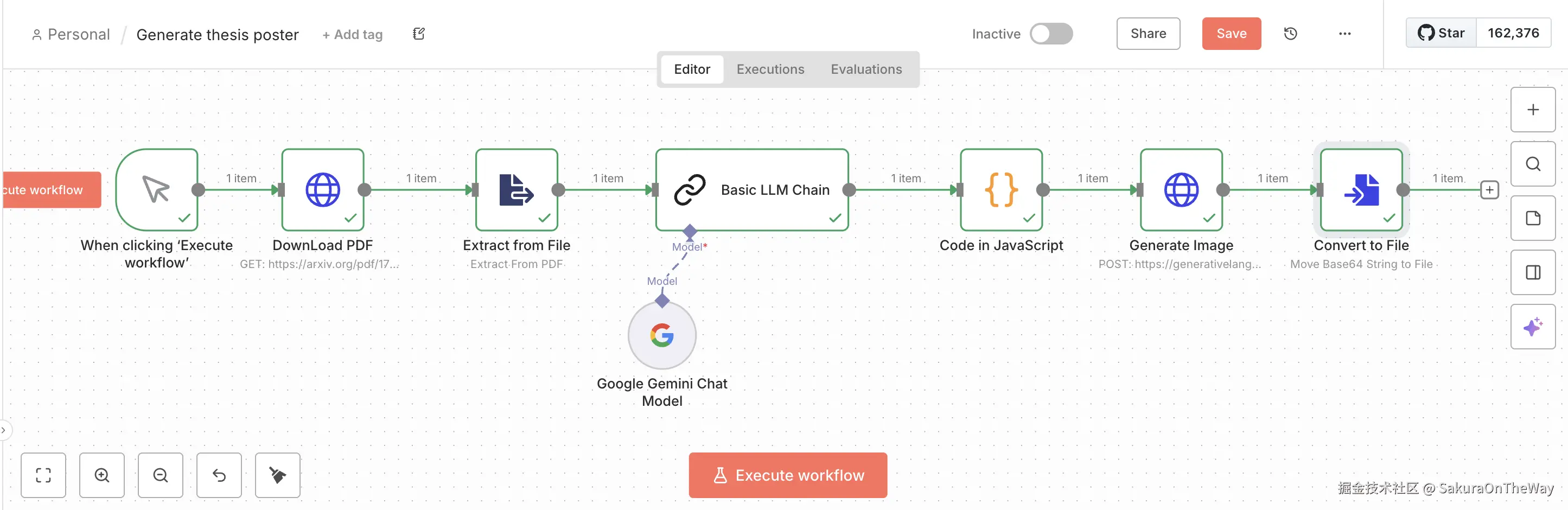
成果展示
1. n8n工作流
2. 论文海报
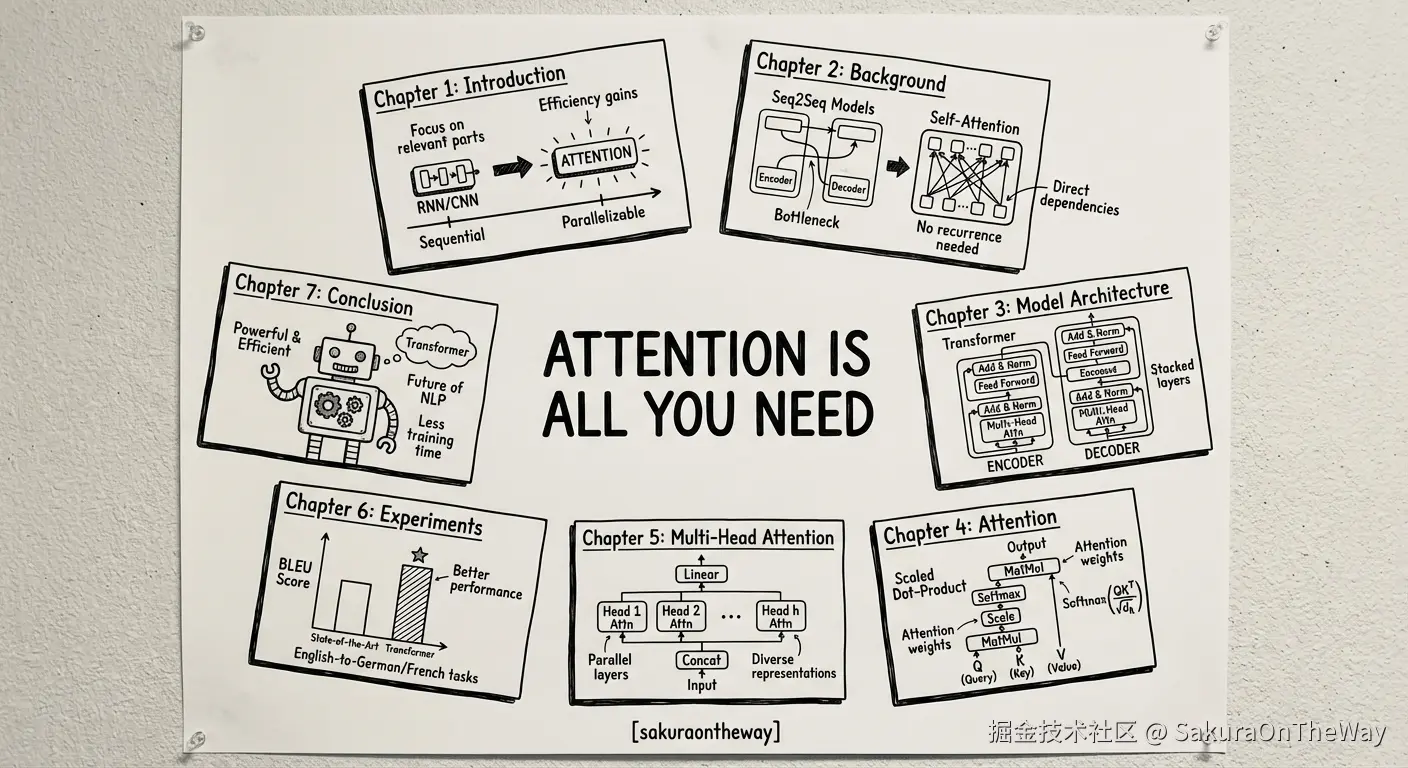
与AI协作的真实感悟
在这次搭建自动画图工作流的过程中,我深刻体会到,Prompt Engineering不仅仅是写句子,更是一种产品思维的体现。
1. 定义需求是核心:从"模糊"到"精准"
"只有明确自己的需求,才能给AI清晰的指令。"
AI是一面镜子,它忠实地反射出你思维的清晰度。最开始我只想要"一张海报",AI 就给我堆砌文字;当我明确我需要的是"以视觉为主、文字为辅、带有分镜逻辑的架构图 "时,Prompt瞬间变得有据可依。在写 Prompt 之前,先问自己:"我到底想看什么?是给谁看的?重点在哪里?" 只有当人类的意图足够锐利,AI的执行力才能被释放。
2. 迭代是常态:耐心对话,拒绝"一步到位"
"需要耐心,Prompt一步步调优,不要想着能一步到位,学会与AI对话。"
一开始LLM提炼的论文核心是有偏差的,而且带了很多"感情色彩",nano banner生成的图片也是"惨不忍睹"。但请记住对话的过程,表达者和倾听者都很重要,每一次报错(Error)和每一次不如人意的出图,其实都是AI在告诉你:"嘿,这里我不理解,请换个方式说。" 好的Prompt不是写出来的,是"调"出来的。与其追求寻找一个万能的"神级 Prompt",不如建立一套"观察-调整-验证"的快速反馈机制。
3. 人的价值在于判断:Feedback loop
"学会思考,Feedback很重要。"
AI可以一秒钟生成十个方案,但只有人能判断哪个方案是"对"的。在这个工作流中,代码逻辑JSON 结构和审美决策 依然掌握在人手中。AI负责根据指令"发散",而我们负责根据结果"收敛"。