在前两篇文章中,我们了解了List和Set这两种容器。他们都能存储一个个独立的元素。
在了解Set的过程中,我们看过其中一个具体的实现,HashSet。
我们知道HashSet的实现实际借助的是HashMap。
而HashMap则是我们今天要讨论的Map接口的实现之一。
Map在Java中,是用来存储成对的、具有映射关系的键值对的容器。
在实际的开发中,配置项、缓存、统计计数等等都以键值对的形式出现。
都可以放到Map中,满足我们根据Key快速查找Value的使用需求。
一、Map是什么
Map是一种映射关系容器,存储的是键值对(Key-Value)而不是单一元素,它不继承自Collection接口。
在Java的集合体系中,Map和Collection平级,形成两个子体系。
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("nickName", "懒惰蜗牛");
map.put("website", "http://lazysnaistudio.com");
System.out.println(map.get("nickName"));
}每个Key最多映射一个Value,如果重复了就会被覆盖。
Key不允许重复,判断依据是equals方法。
Value没有限制,可以重复。
Map允许为null的Key和Value(具体取决于实现类)。
这是Map源码的第一行注释:

二、Map的核心方法
Map接口定义了一系列跟键值对相关的操作方法。
1. 添加/更新
java
V put(K key, V value);添加或更新键值对。如果key已经存在,就会覆盖旧值并返回旧值,否则返回null。
2. 查询
java
V get(Object key);
boolean containsKey(Object key);
boolean containsValue(Object value);get方法返回key对应的值,如果不存在就返回null。
containsKey()和containsValue()用来判断Map里面是不是存在指定key或value。
3. 删除与清空
java
V remove(Object key);
void clear();remove()删除并返回指定key对应的value。
clear()清空Map里所有数据。
4. 获取集合视图
java
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();keySet是获取所有的key。
values是获取到所有的value。
entrySet是获取到所有的Entry。
我们可以使用这些方法,从不同的角度遍历Map的内容。
三、遍历Map的三种方式
上面我们提到了遍历,接下来看下具体的遍历方式。
1. 遍历keySet + get()
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("nickName", "懒惰蜗牛");
map.put("website", "http://lazysnaistudio.com");
for (String key : map.keySet()) {
System.out.println(key + ":" + map.get(key));
}
}2. 遍历entrySet
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("nickName", "懒惰蜗牛");
map.put("website", "http://lazysnaistudio.com");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}3. Lambda表达式遍历
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("nickName", "懒惰蜗牛");
map.put("website", "http://lazysnaistudio.com");
map.forEach((k, v) -> System.out.println(k + ":" + v));
}Lambda表达式是Java8引入的,后面会讲到。
4. 使用迭代器安全删除
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("nickName", "懒惰蜗牛");
map.put("website", "http://lazysnaistudio.com");
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
if (entry.getKey().startsWith("nick")) {
iterator.remove();
}
}
System.out.println(map.size());
}四、Map的常见实现
HashMap、LinkedHashMap、TreeMap、Hashtable、ConcurrentHashMap都是Map的实现。
其中Hashtable已经不推荐使用了。
打开Hashtable源码你会看到,很多的方法都使用了synchronized关键字,这是一个所操作,会影响性能。
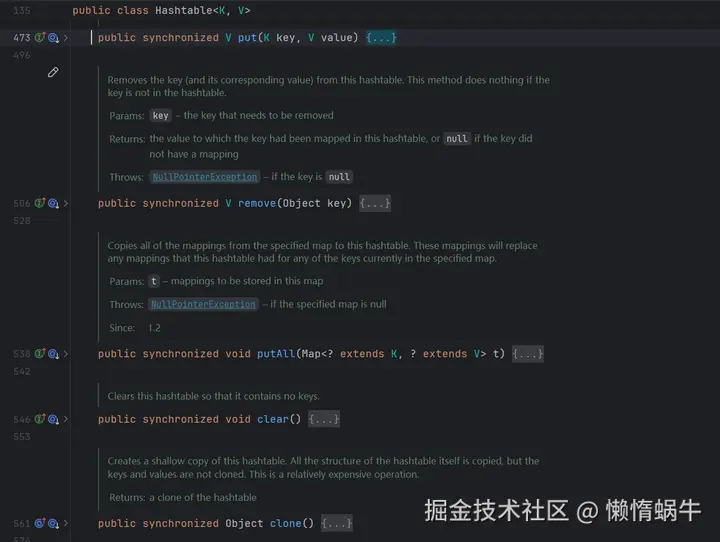
如果需要在多线程环境下使用Map,推荐的是ConcurrentHashMap。
ConcurrentHashMap使用了开销更低的锁机制来解决并发问题。
没有数据竞争的情况下,直接使用HashMap就可以了。
HashMap采用的是数组 + 链表/红黑树的底层结构,线程不安全。
LinkedHashMap在HashMap的基础上加上了双向链表,以此来实现插入、查询的顺序。
TreeMap是一个有序的Map,底层结构是红黑树。
前文讲到的TreeSet就是复用的TreeMap,只是TreeSet忽略了Value的存储。
总结一下:
| 实现类 | 是否有序 | 是否线程安全 | 底层结构 | 特点 |
|---|---|---|---|---|
| HashMap | 否 | 否 | 数组 + 链表/红黑树 | 使用最广泛,允许null键值,查询快 |
| LinkedHashMap | 插入顺序/访问顺序 | 否 | HashMap + 双向链表 | 保留插入/访问顺序,支持构建LRU缓存 |
| TreeMap | 按key排序 | 否 | 红黑树 | 有序,支持Comparator定制key排序 |
| Hashtable | 否 | 是 | 哈希表 | 线程安全,已过时,性能较差 |
| ConcurrentHashMap | 否 | 是 | CAS + 分段锁(JDK8前) → Node + CAS(JDK17) | 高并发性能,不允许null键/值 |
五、HashMap底层实现(JDK17)
1.put的大致流程:
1.1判断table是否为空,若为空则初始化。
table是用来存储Node节点的数组。

1.2调用hash()扰动函数计算key的hash
java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这个函数主要是为了让计算出来的hash值分布得更加均匀。
1.3计算桶索引:(n - 1) & hash
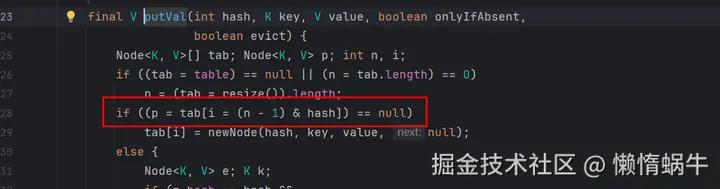
这一步就是计算这个key会存储在table的哪个下标中。
1.4如果table下标这个位置为空就直接插入,否则就要遍历链表/树查找是不是已经有相同key。
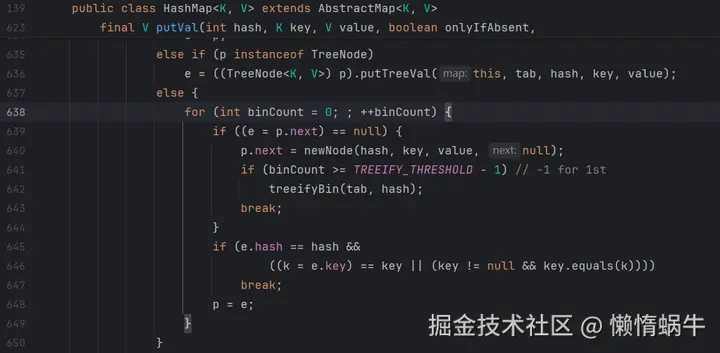
1.5如果key已经存在就覆盖旧值,否则就插入新节点。
1.6树化或者扩容
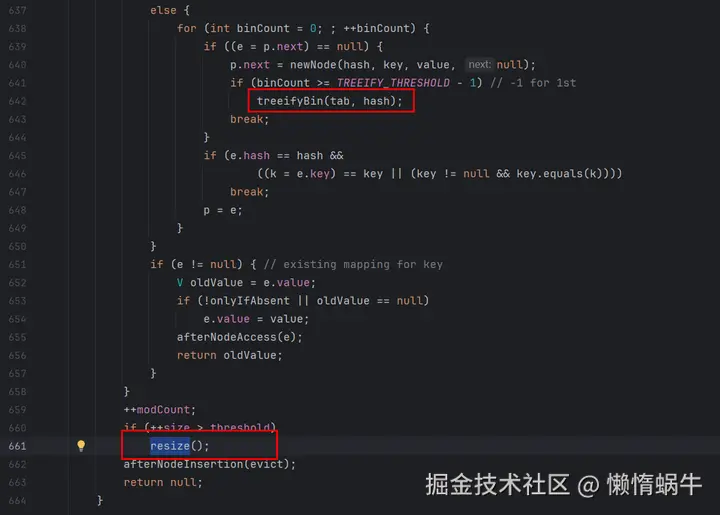
treeifyBin是树化的入口。
resize是扩容方法。
2.冲突解决策略
桶中节点以链表存储,JDK8引入红黑树优化。
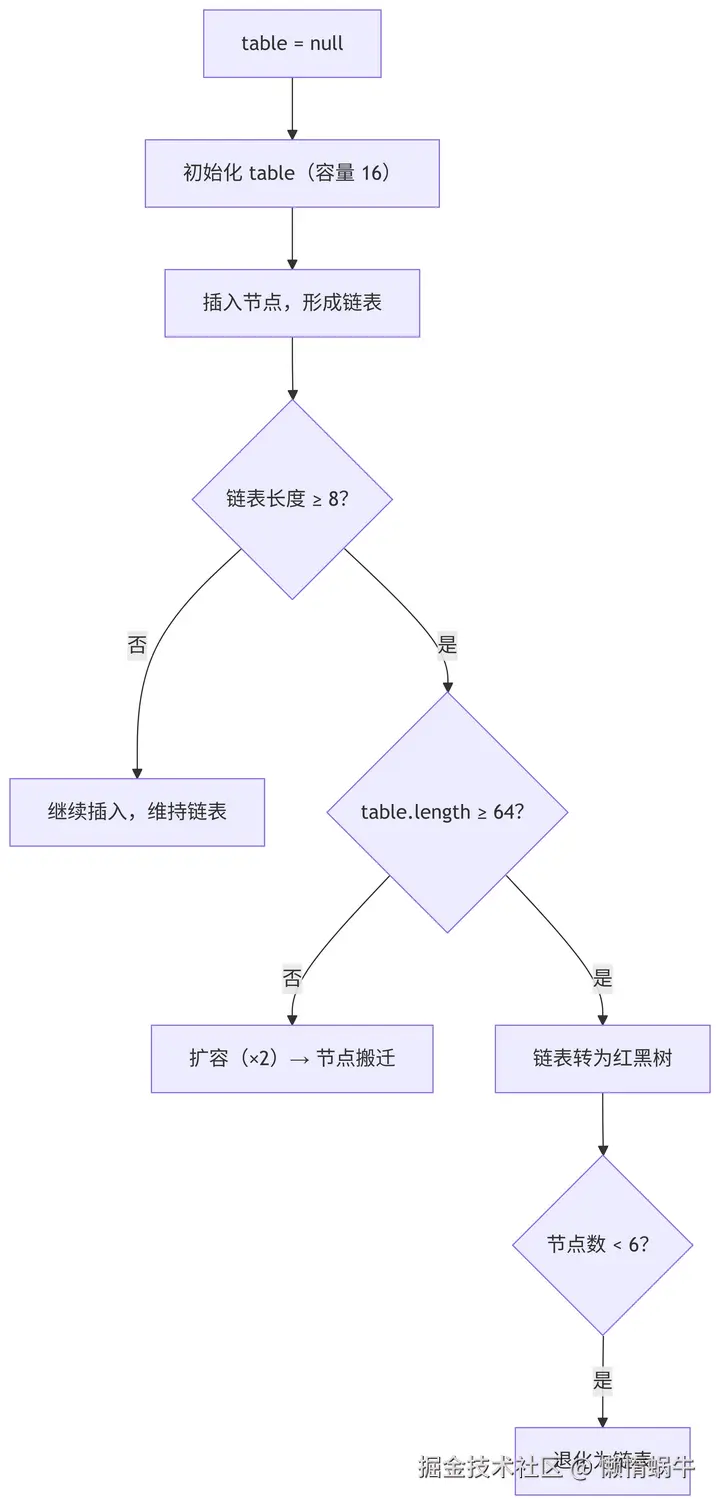
如果链表长度超过TREEIFY_THRESHOLD(8),并且数组容量>64,链表转红黑树(treeifyBin)。
红黑树查找效率为O(log n),链表为O(n)。
3.扩容机制
负载因子默认0.75,初始容量16。
每次扩容为原容量2倍。
迁移元素的时候使用 (oldHash & oldCap) 判断是不是要移动到新桶位或者保留原位。
4.图解
画了一个大致的流程图
总结
Map接口虽然不属于Collection体系,但在Java集合里依然非常重要。
掌握他的核心方法和实现原理,能够帮助我们写出更加健壮、高效、易维护的代码。
特别是理解HashMap、TreeMap、ConcurrentHashMap的适用场景和性能特点。
不管是系统设计还是面试都很重要。
下一篇预告
Day30 | Java集合框架之Collections工具类
如果你觉得这系列文章对你有帮助,欢迎关注专栏,我们一起坚持下去!