上篇文章中说到 :我们用 JVM 的 Native Memory Tracking(NMT)成功定位到内存泄漏发生在"堆外",但问题来了------ "知道是堆外泄漏,可具体是谁干的?代码里有几十个模块,总不能挨个排查吧?"
上篇文章:《你的 Java 应用"吃光"了内存?别慌,NMT 帮你揪出真凶!》
别急。今天,下面我将完全站在"黑盒排查者"角度,一步步还原整个诊断过程。
假装对业务一无所知,凭内存地址里的内容,反推出是哪个业务模块在"偷偷吃内存"。
一、🕵️♂️ 场景还原:模拟堆外内存泄漏现场
我们来写一个很简单类,模拟业务系统的堆外内存泄漏,每2秒分配10M内存,共分配500M,并且在分配的内存中全部填充我们的测试数据:
"Hello, Direct Memory!",看能不能通过内存分析工具定位到这段代码。
java
package org.example;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class App {
public void nativeTest() throws InterruptedException {
Thread.sleep(60000);
List<ByteBuffer> byteBufferList = new ArrayList<>();
// 共分配500M堆外内存
for (int i=0;i<50;i++){
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024 * 1024 * 10);
// 填充内存中的内容,用于标记业务模块,填充内容为 "Hello, Direct Memory!"(循环)
String pattern = "Hello, Direct Memory!";
byte[] patternBytes = pattern.getBytes(StandardCharsets.US_ASCII);
int total = byteBuffer.capacity();
int len = patternBytes.length;
for (int j = 0; j < total; j++) {
byteBuffer.put(j, patternBytes[j % len]); // 直接写到指定位置
}
byteBufferList.add(byteBuffer);
Thread.sleep(1000);
}
}
public static void main(String[] args) throws InterruptedException, IOException {
App app = new App();
app.nativeTest();
Thread.sleep(Long.MAX_VALUE);
}
}启动脚本:
shell
nohup java -Xmx1g -Xmn512m -Xms512m -XX:NativeMemoryTracking=detail -jar java-demo-1.0-SNAPSHOT.jar > app.log 2>&1 &二、💡 破局关键:内存里到底藏着什么?
在 Java 中,ByteBuffer.allocateDirect() 分配的堆外内存,本质上是一段匿名的 native 内存。
它存的可能是二进制协议帧、序列化对象,也可能是可读的字符串(比如模块标识、用户 ID、缓存前缀等)。
这些内容,就是藏在内存里的 "业务指纹":
- 如果是可读字符串------恭喜!你很可能直接定位到具体模块;
- 如果是纯二进制------也别慌,它的结构、长度、重复模式甚至魔数(magic number),往往也能暴露身份。
而我们要做的,就是潜入这片"匿名区域",把那些隐藏的指纹打捞出来。
三、实战六步法:从地址找到真相
第1步:确认是"堆外内存"在增长
先用 NMT 看明细,输出如下:
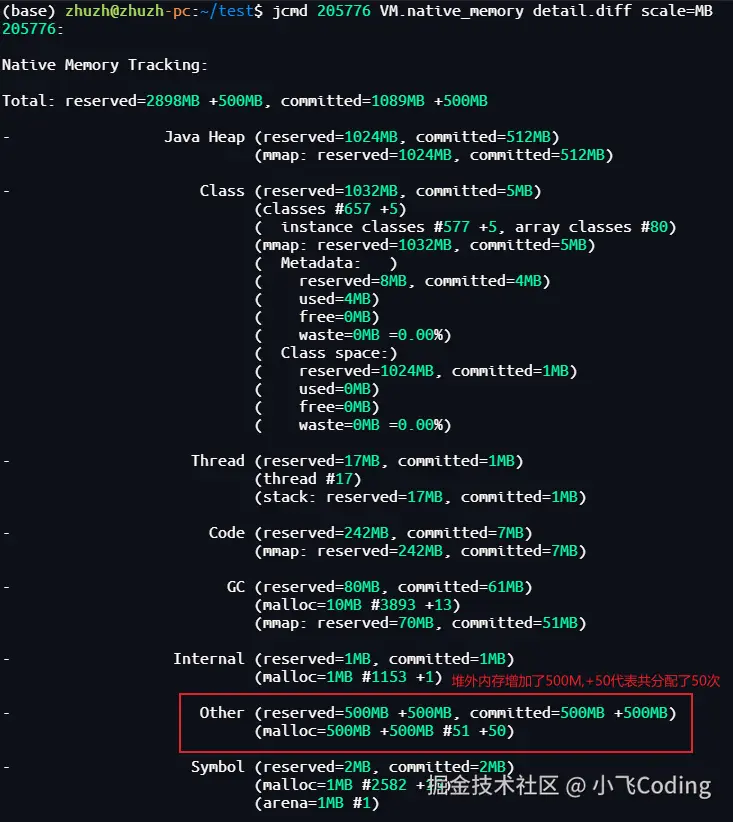
✅→ 明确看到:500MB 新增内存来自 Unsafe_AllocateMemory0,说明是 Java 层直接申请的 native 内存。
但 NMT 不给具体地址,只知道总量。下一步,得找操作系统要线索。
关于NMT的用法,可以参见之前的文章:《你的 Java 应用"吃光"了内存?别慌,NMT 帮你揪出真凶!》
第2步:pmap导出该进程的内存地址信息
通过以下命令导出该进程的内存地址信息:
text
pmap -x 205776 | grep anon🔍 为什么关注
[anon]?因为 Java 的堆外内存(
allocateDirect、JNI、Unsafe)最终都会变成操作系统的匿名映射内存 ,在pmap里就叫[anon]。
pmap数据长这样:
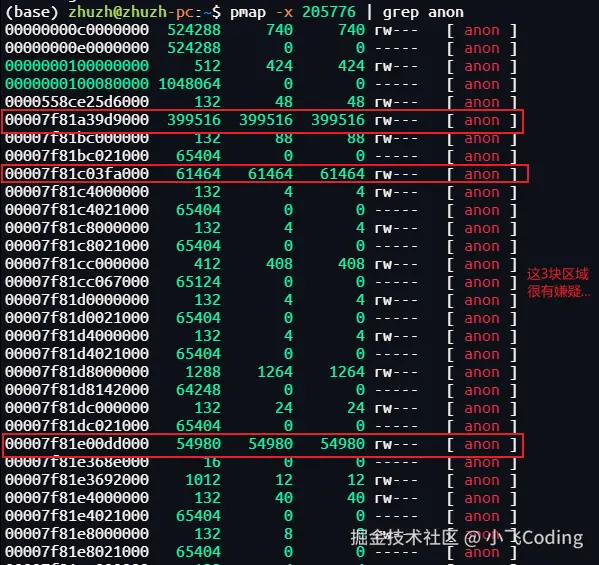
图没有截完,下面还有很多行,只把占内存大的地址空间截下来了。
pmap 输出中各列的含义:
| 列序 | 列名 | 含义 | 单位 |
|---|---|---|---|
| 1 | Address | 内存段的起始虚拟地址 | 十六进制(如 00007f8224696000) |
| 2 | Kbytes | 该内存段的虚拟大小(Virtual Size) | KB |
| 3 | RSS | Resident Set Size:当前实际驻留在物理内存中的页数 | KB |
| 4 | Dirty | 脏页大小:已被修改、尚未写回磁盘的页(对匿名内存即已写入的数据) | KB |
| 5 | Mode | 内存保护权限(r=read, w=write, x=execute, s=shared, p=private) | 字符串(如 rw---) |
| 6 | Mapping | 映射来源: • 文件路径(如 /lib/libc.so.6) • [anon]:匿名映射(堆、栈、mmap(MAP_ANONYMOUS)) • [stack]:主线程栈 • [heap]:传统堆 |
--- |
第3步:用 pmap 找出"可疑区域"
已经通过NMT知道增长了多少内存,又通过pmap拿到了该进程的内存地址数据,如何找到那块内存地址堆外内存增长的恐惧?
从 pmap 找出大块 committed anon 段,重点关注 已提交(RSS > 0)且大小接近 500MB 的匿名内存段:
text
00007f81a39d9000 399516 399516 399516 rw--- [ anon ] ← ~390MB
00007f81c03fa000 61464 61464 61464 rw--- [ anon ] ← ~60MB
00007f81e00dd000 54980 54980 54980 rw--- [ anon ] ← ~54MB这三块加起来 ≈ 505MB ,正好匹配 NMT 报告的 +500MB Other。
✅ **结论猜想 **:这三块
[anon]区域极大概率就是那 500MB 堆外内存的实际物理映射。
第4步:用 gdb 把内存"dump"出来
现在,我们要把这几段内存原样拷贝出来,看看里面到底藏了啥。
以第一块为例:使用 gdb 将这几段内存数据dump出来,执行命令及结果如下:
bash
sudo gdb -p 205776 -batch \
-ex "dump memory /tmp/buf_dump1.bin 0x00007f81a39d9000 0x00007f81bc000000" \
-ex "detach" -ex "quit"💡 小技巧:结束地址 = 起始地址 + (Kbytes × 1024) 可用脚本自动计算,避免手算出错。
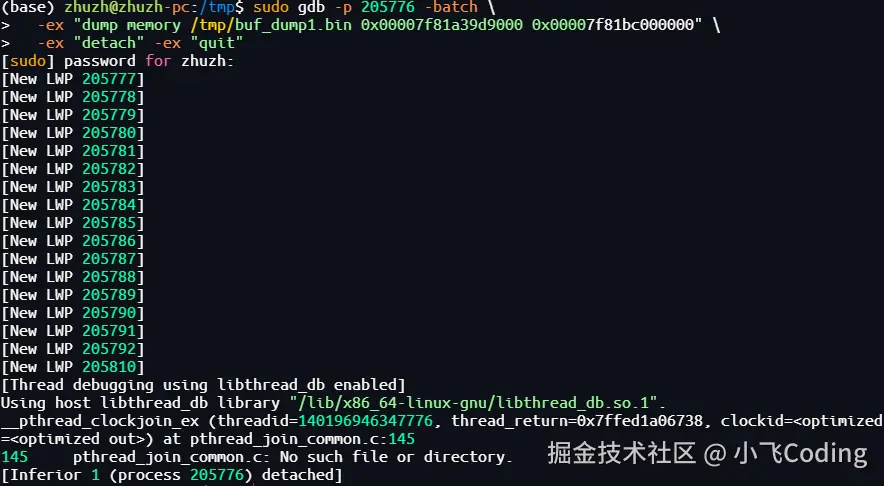
重复操作,把另外两块也 dump 出来,保存为buf_dump2.bin、buf_dump3.bin。
⚠️ 若提示
ptrace: Operation not permitted,请先执行:echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
第5步:用 hexdump 或 strings "窥探"内存内容
根据上一步dump的内存块数据,用 hexdump或strings 工具提取内存中的内容:
提取第1块内存数据:
shell
hexdump -C /tmp/buf_dump1.bin | head -n 20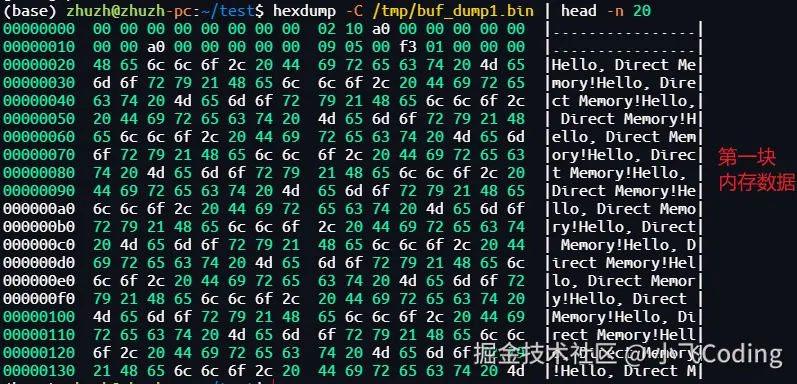
🚨🚨🚨内存中反复出现测试的字符串!"Hello, Direct Memory!",与猜想的一致。
第2块内存数据:
shell
hexdump -C /tmp/buf_dump2.bin | head -n 20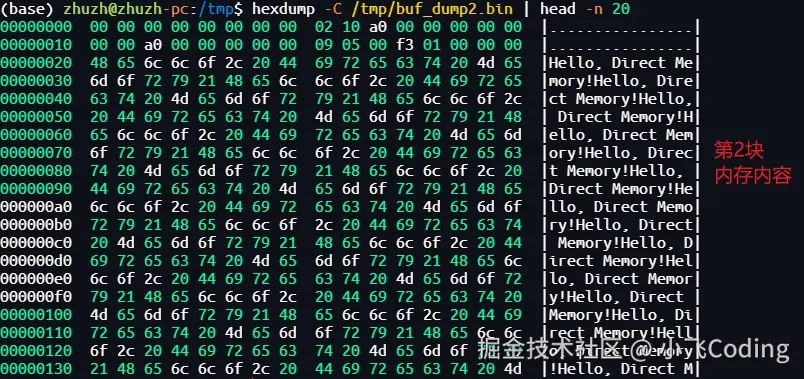
🚨🚨🚨内存中也是反复出现测试的字符串!"Hello, Direct Memory!",与猜想的一致。
第3块内存数据:
shell
hexdump -C /tmp/buf_dump3.bin | head -n 20
🤔🤔🤔🤔 呃......等等?
第3块内存怎么不太一样?开头根本没看到 "Hello, Direct Memory!",难道不是我们的数据?
可500MB的泄漏,现在只找到450MB,还差50MB去哪了?是不是判断错了???
起初我也怀疑自己:难道内存被分散到一堆小块里了?
理论上有可能------毕竟 glibc 的分配策略复杂,但这次测试代码极其干净,几乎没其他干扰,内存理应高度集中。
虽然这个可能性很低,但我还是确认了下,又翻了 pmap 里剩下的小段:4MB、1MB、几百KB......挨个 dump 出来扫了一遍,全都没有目标字符串,这就奇了怪了,到底存哪了。
写到这儿时,已经是周五晚上快8点,想着回家前把文章写完。
此时,孩子打来电话:"爸爸,你几点回来?饭都凉了......"
我只好先收工回家。
那天特别冷,骑着小电驴一路寒风直往领口钻,吹得脑瓜子又麻又清醒。
可脑子就是停不下来:到底漏在哪了?
半路上,突然灵光一闪------
我只看了前20行!
这块内存有54MB,而缺失的正好是约50MB。
会不会......我的测试数据其实就在后面,只是开头被别的东西占了(比如分配器元数据、对齐填充)?
这个念头一冒出来,整条逻辑瞬间闭环:
→ 第3块内存极大概率也是"自己人",只是"藏得深"。
那一刻的感觉,就像之前无数次处理生产疑难故障时一样------
明明知道问题就在这儿,却死活找不到证据,仿佛撞上了"灵异事件"。
但这些年踩过的坑告诉我:世上没有灵异,只有盲点。
那些"诡异"的现象,往往卡在一个你根本不会怀疑的细节上,而且你潜意识认为它是对的,就像我只看了前20行内存,因为知道代码干净,潜意识这20行就能代表全部。
要是放在早几年,我肯定掉头回公司验证,否则整晚睡不着。
但现在嘛,没那么年轻了...... 孩子今天期中考试出成绩,等我半天了。得回家了。
周一 一大早到公司,进行了确认:
shell
(base) zhuzh@zhuzh-pc:~/test$ strings /tmp/buf_dump3.bin | grep -o "Hello, Direct Memory!" | wc -l
2496604
超过 249 万次命中!
说明第 3 块内存绝大部分内容仍然是我们的标记字符串,只是开头恰好被其他数据(比如对齐填充、元信息或分配器头)占用了。
✅ 结论更新:三块 [anon] 内存都属于本次泄漏,总和 ≈ 500MB,完美吻合 NMT 数据。
📊 重新计算归属
| 地址范围 | 大小(KB) | 是否含目标字符串 | 是否属于你的 500MB |
|---|---|---|---|
0x00007f81a39d9000 |
399,516 KB ≈ 390 MB | ✅ 是 | ✅ 是 |
0x00007f81c03fa000 |
61,464 KB ≈ 60 MB | ✅ 是 | ✅ 是 |
0x00007f81e00dd000 |
54,980 KB ≈ 54 MB | ✅ 是 | ✅ 是 |
至此,终于破案了! 🎉🎉🎉
第6步:反推业务模块
现在,你手里握着关键线索:"Hello, Direct Memory!"
-
搜索代码中看是否有包含此字符串的代码。
→ 直接定位到
App.java的nativeTest()方法。 -
如果没有,通过语义推理联系业务开发团队,看是哪个模块导致的。
🧩 总结:堆外内存排查全景图
| 步骤 | 工具/命令 | 目标 | |
|---|---|---|---|
| 1️⃣ 定位泄漏类型 | jcmd VM.native_memory |
确认是堆外(Other) | |
| 2️⃣ 锁定物理区域 | `pmap -x | grep anon` | 找出大块匿名内存 |
| 3️⃣ 导出内存内容 | gdb dump memory |
获取原始数据 | |
| 4️⃣ 提取业务指纹 | strings / hexdump |
发现隐藏字符串 | |
| 5️⃣ 反推责任模块 | 代码搜索 or 团队沟通 | 定位到具体功能 |
整个过程,不需要重启、不需要改代码、甚至不需要懂业务逻辑------只要你敢"扒内存",真相就在字节之间。
❓ 小疑问:pmap中为什么没看到50个10MB的内存段?
你可能会纳闷:
我明明调用了 50 次
ByteBuffer.allocateDirect(10MB), 为什么pmap里看不到 50 个独立的 10MB 区块? 反而只看到几个大块(比如 390MB、60MB)?
答案是:中间隔着一层"内存管家"------glibc 的 malloc。
ByteBuffer.allocateDirect()在底层并不是直接调用mmap向操作系统要内存;- 它实际走的是 glibc 的
malloc(),由 glibc 统一管理 native 内存池; - 当你频繁申请大块内存时,glibc 会合并请求 ,一次性向 OS 申请一个更大的匿名内存区域(即
[anon]段); - 然后再在自己的内存池里切分给你用。
所以:
- ✅ Java 层 :你有 50 个
DirectByteBuffer对象,每个逻辑上占 10MB; - ❌ OS 层(pmap 所见):只看到少数几个大块的匿名映射,并不知道这些块内部被怎么"切分"了。
📌 简单说 : pmap 展示的是 操作系统视角的虚拟内存映射 , 而我们的 50 次分配,只是 Java 应用层的逻辑行为。 两者之间,隔着 glibc 内存分配器这一层抽象。
这也正是堆外内存排查的难点与魅力所在------表象之下,另有乾坤。
❓如果堆外内存里存的是二进制数据呢?
堆外内存里如果存的是二进制数据 (比如图片、序列化对象、网络协议帧、加密字节流等),根本看不到像 "Hello, Direct Memory!" 这样清晰的字符串"指纹"。
那是不是就没招了? 当然不是! 虽然难度提升,但仍有办法"见微知著"。
🔍 1. 别放弃 strings:它比你想象的更强大
即使主体是二进制,很多结构仍会夹杂可读信息:
- 协议头(如
HTTP/1.1、gRPC、Kafka的 magic byte + topic 名) - 类名或包名(Java 序列化、Kryo、Protobuf 可能嵌入类路径)
- 配置标识(如
cache_key:user:12345、job_id=abc-xyz) - 错误日志片段、URL、IP 地址、文件路径等
🔧 2. 用 hexdump + 模式识别找"结构特征"
二进制数据常有固定结构,比如:
- 固定头部(magic number):
CA FE BA BE(Java class)、89 50 4E 47(PNG) - 长度字段 + payload
- 对齐填充(大量
00或特定 padding)
✅ 观察:
- 开头是否有重复魔数?
- 是否每隔 N 字节出现相似模式?
- 是否有大段连续
00(可能是未初始化或对齐区)?
这些模式可反推数据类型(如"这看起来像 Protobuf 编码"或"像是 Netty 的 ByteBuf 池")。
🧩 3. 结合分配行为 + 内存布局缩小范围
即使内容不可读,也可以从内存分配特征入手:
- 大小规律:是否全是 16KB 块?→ 可能是 Netty 的 PooledByteBuf。
- 数量突增 :NMT 显示
Internal或Other在某个时间点陡增 → 结合业务日志看当时在跑什么任务。 - 生命周期:泄漏内存是否长期不释放?→ 排除临时 buffer,聚焦缓存、连接池、静态引用。
🌟 写在最后
堆外内存排查确实有点"硬核",但它不像 GC 日志那样晦涩难解,也不像CPU飙升那样转瞬即逝。只要你有耐心、愿意去扣,就一定能挖出真相。
更重要的是:真正的排障能力,来自事前的模拟与演练。
只有在测试环境亲手制造过问题、完整走通一遍诊断链路, 等到生产故障时(往往比你模拟的更复杂),你才能冷静应对,有自己的主线逻辑,而不是手忙脚乱
地"东猜西试"。
另外,还有个小心得给大家分享下,在处理疑难故障时,很多问题的突破口,都不是硬想出来的,而是在你倾尽全力、近乎放弃时,突然从脑海深处冒出来的。
如果你觉得这篇文章有用,欢迎点赞、收藏、转发,让更多 Java 同伴少走弯路!