视频链接:bilibi
本系列将会介绍Transformer基础知识和Large Language Model前沿内容,今天记录的内容来自于MIT Song Han老师课程内容。
文章目录
-
- [1. Transformer basics](#1. Transformer basics)
-
- [1.1 Pre-Transformer Era](#1.1 Pre-Transformer Era)
- [1.2 Transformer(重点)](#1.2 Transformer(重点))
-
- [1.2.1 Tokenize words (word -> tokens)](#1.2.1 Tokenize words (word -> tokens))
- [1.2.2 Word Representation](#1.2.2 Word Representation)
- [1.2.3 Multi-Head Attention (MHA)](#1.2.3 Multi-Head Attention (MHA))
- [1.2.4 Feed-Forward Network (FFN)](#1.2.4 Feed-Forward Network (FFN))
- [1.2.5 LayerNorm & Residual connection](#1.2.5 LayerNorm & Residual connection)
- [1.2.6 Position Encoding (PE)](#1.2.6 Position Encoding (PE))
- [2. Transformer Design Variants](#2. Transformer Design Variants)
- 3.
- 4.
 |
 |
 |
 |
1. Transformer basics
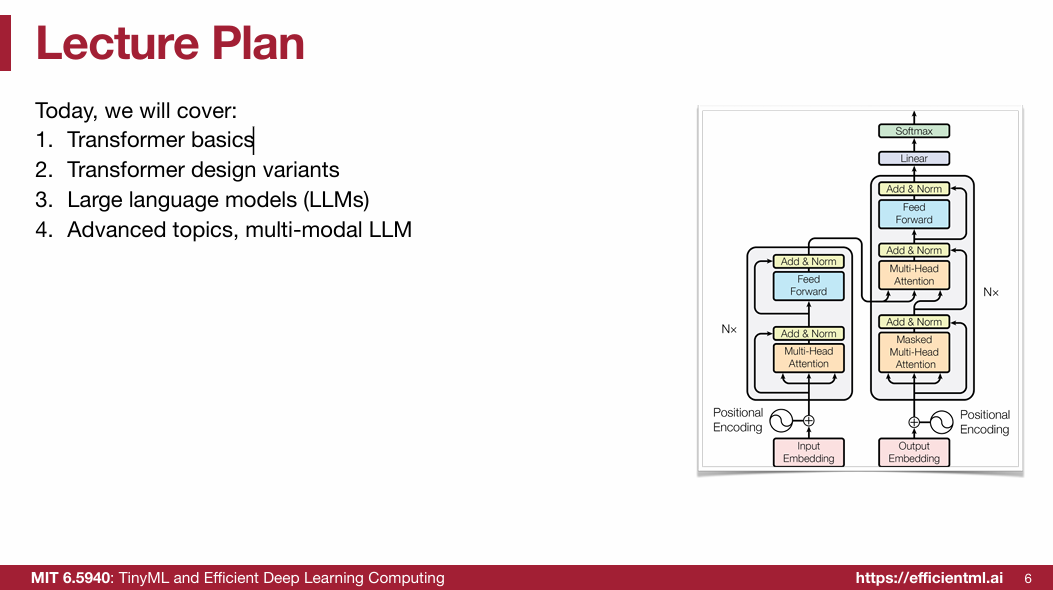
1.1 Pre-Transformer Era
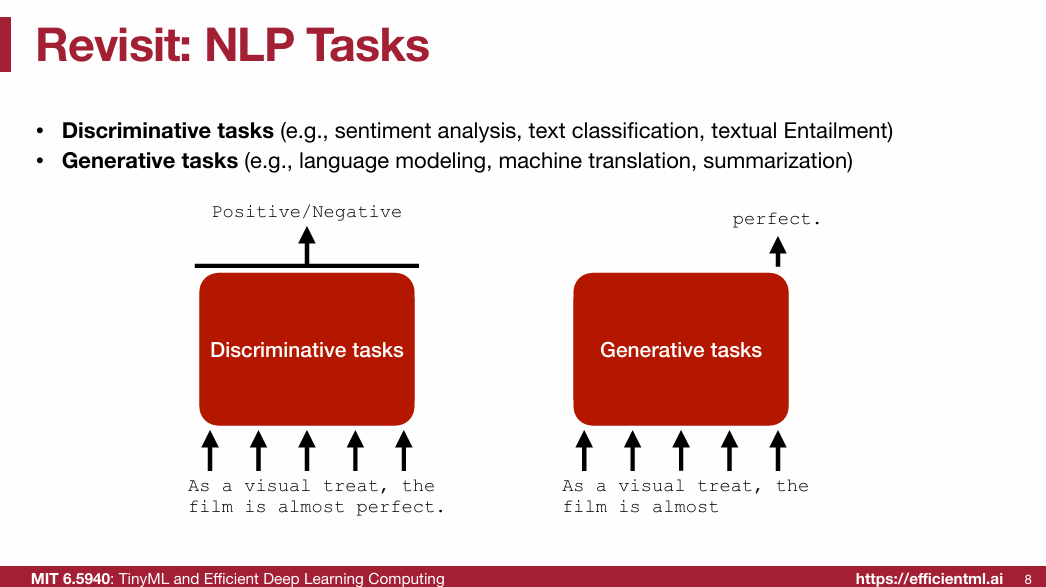
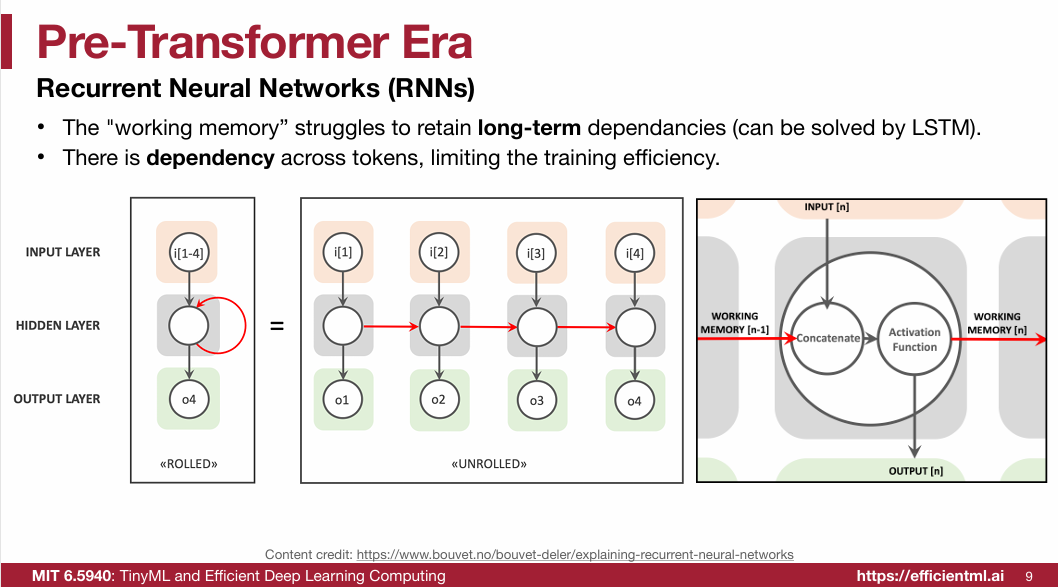
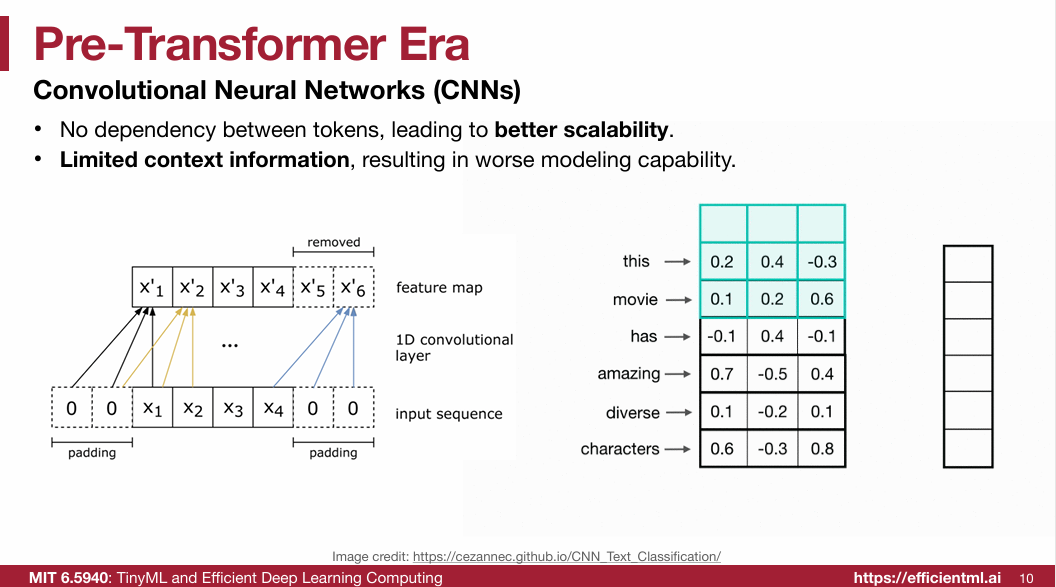
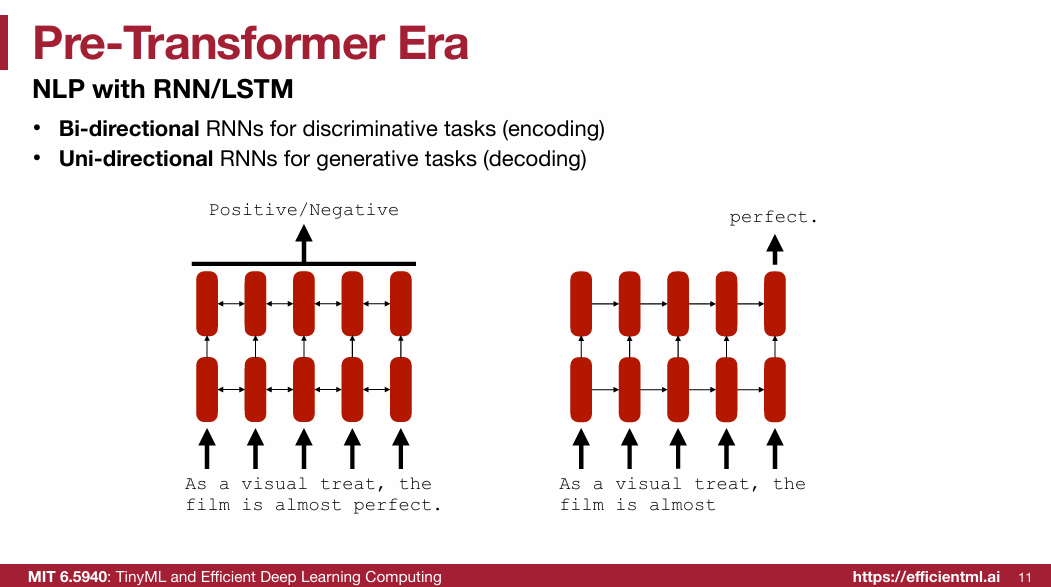
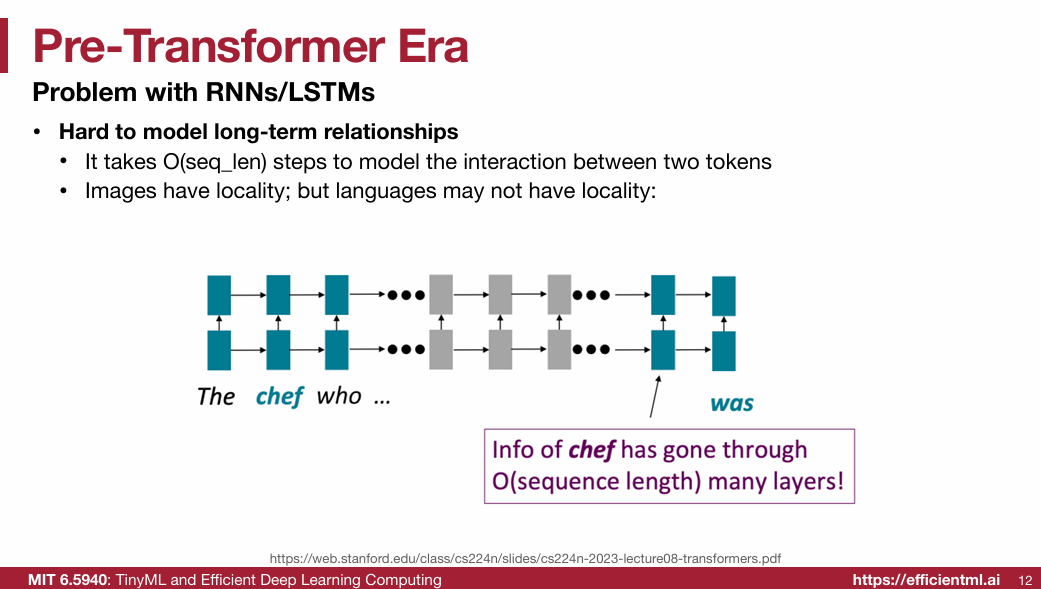
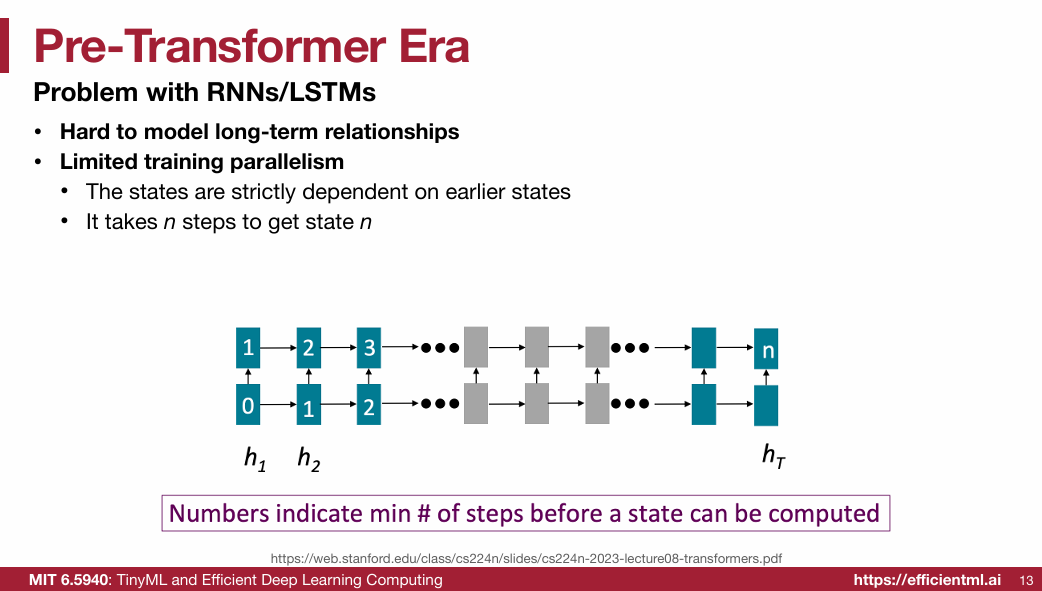
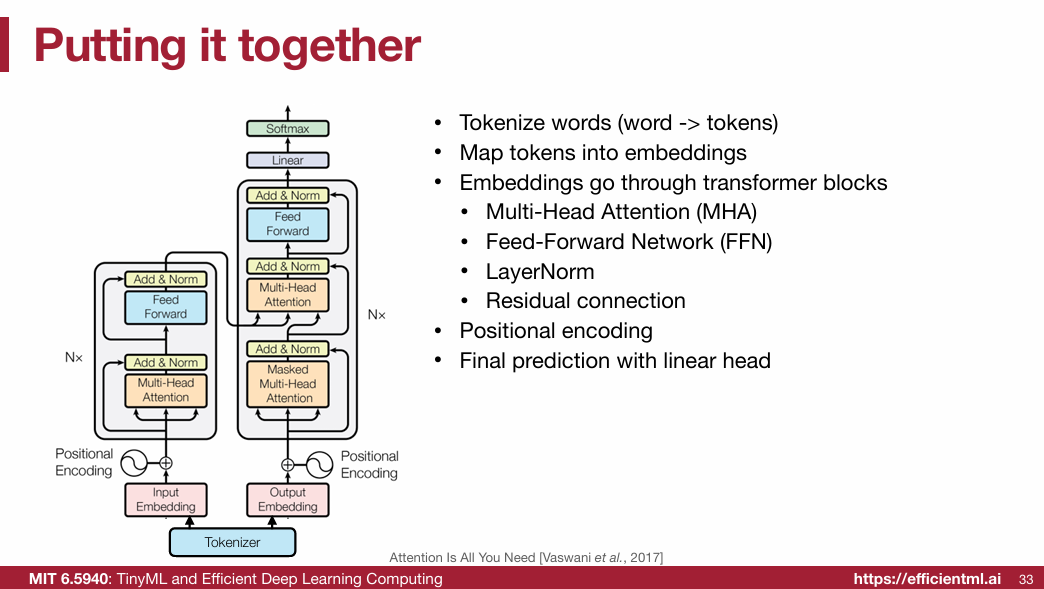
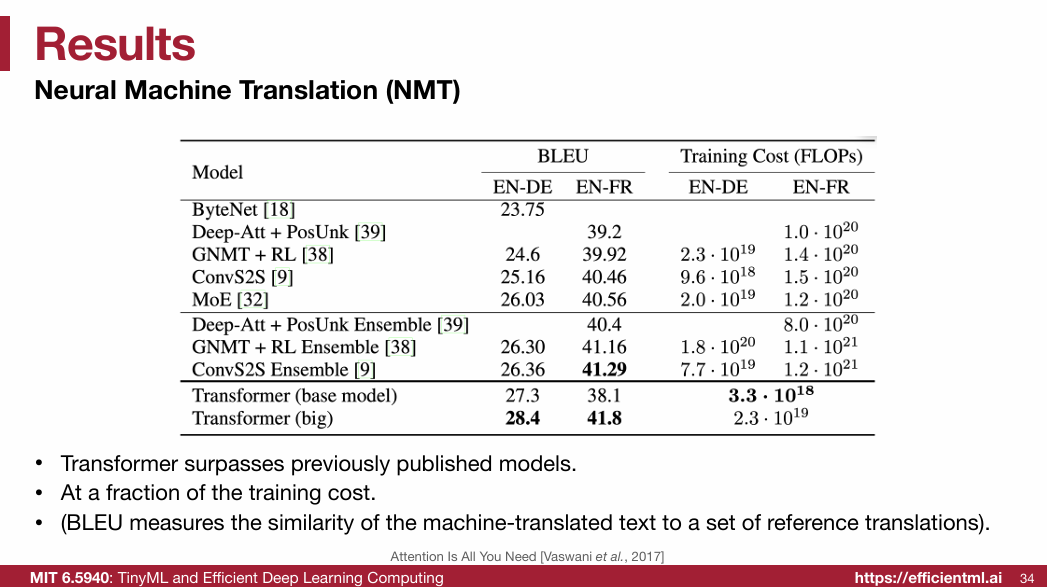
1.2 Transformer(重点)
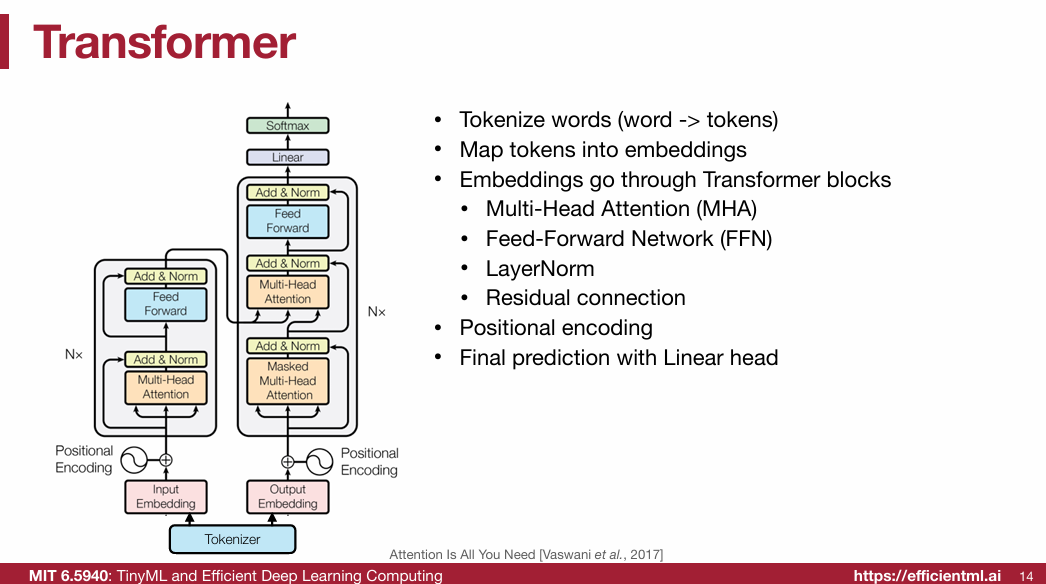
1.2.1 Tokenize words (word -> tokens)
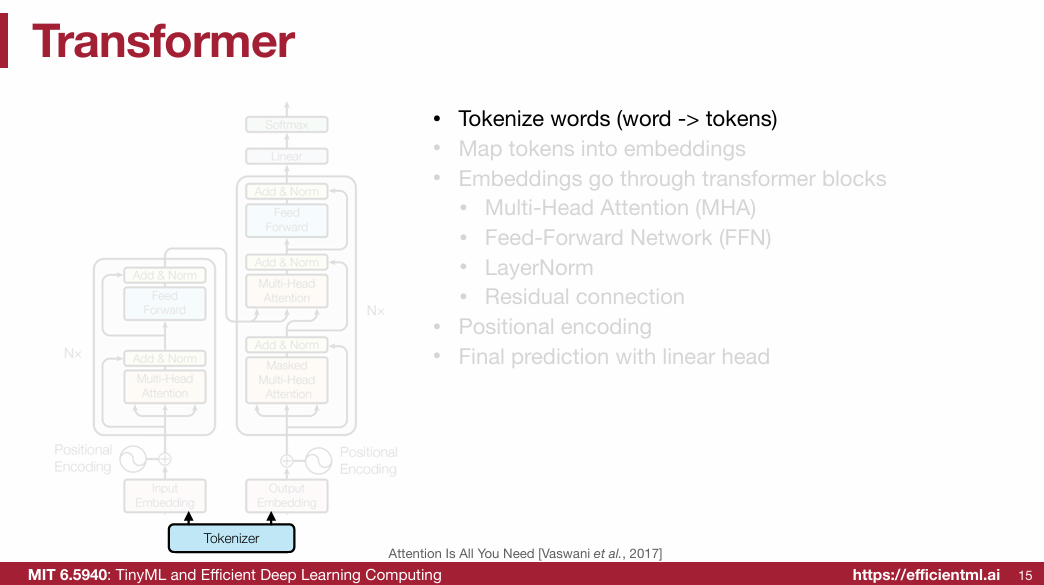

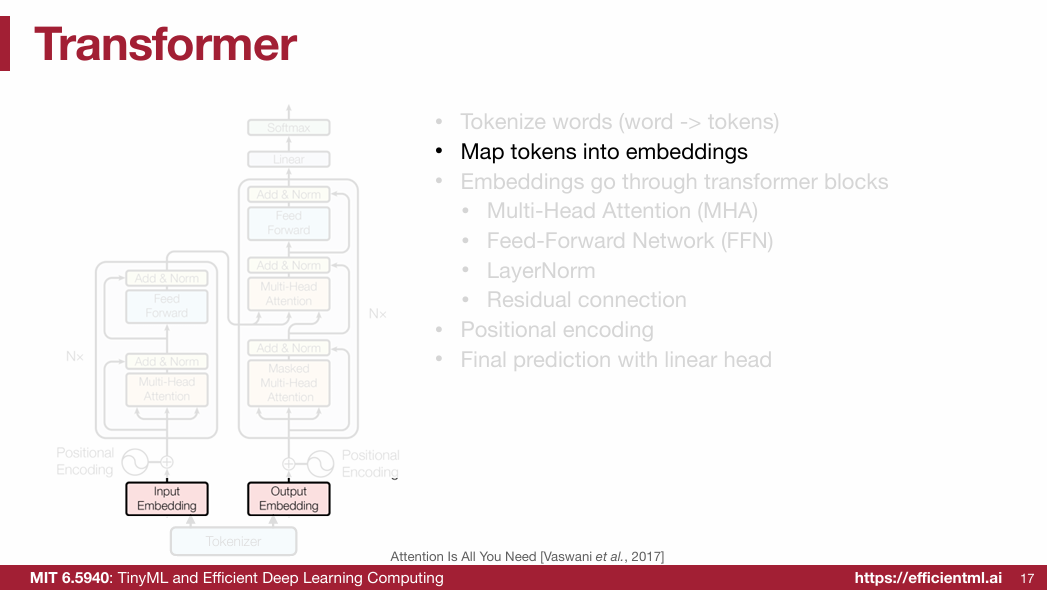
1.2.2 Word Representation


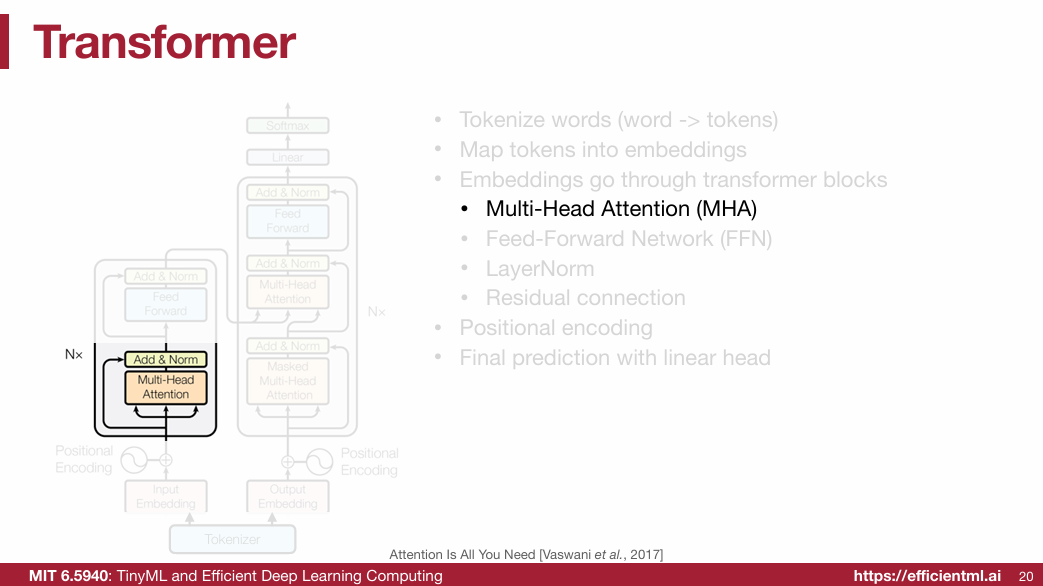
1.2.3 Multi-Head Attention (MHA)


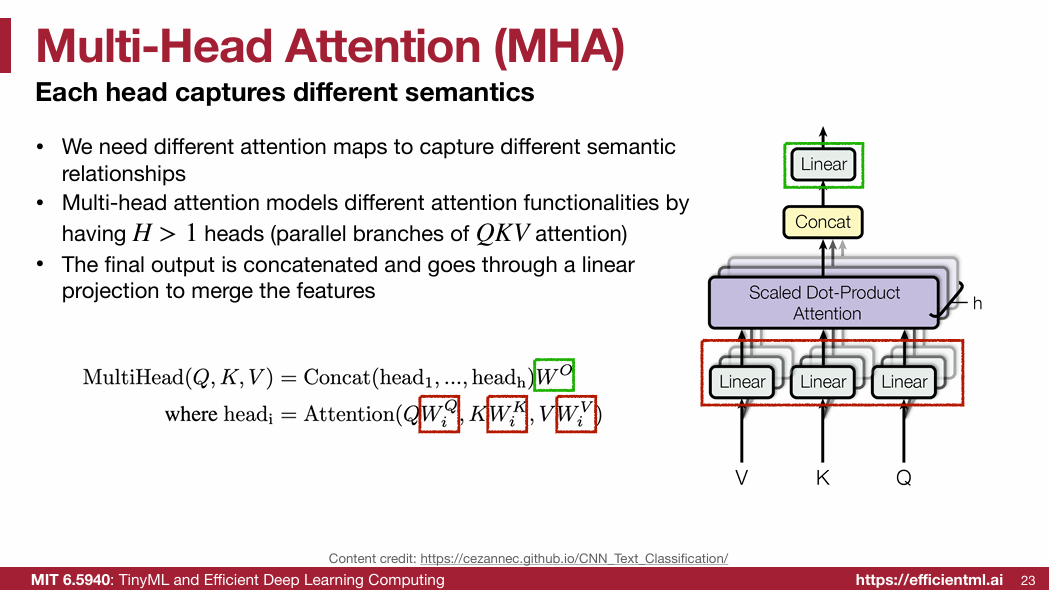
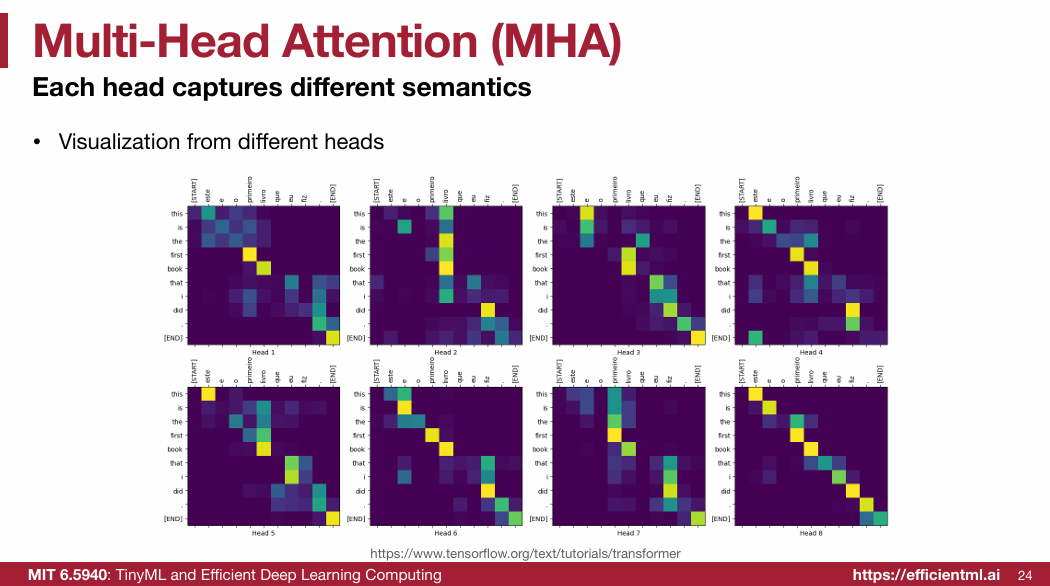
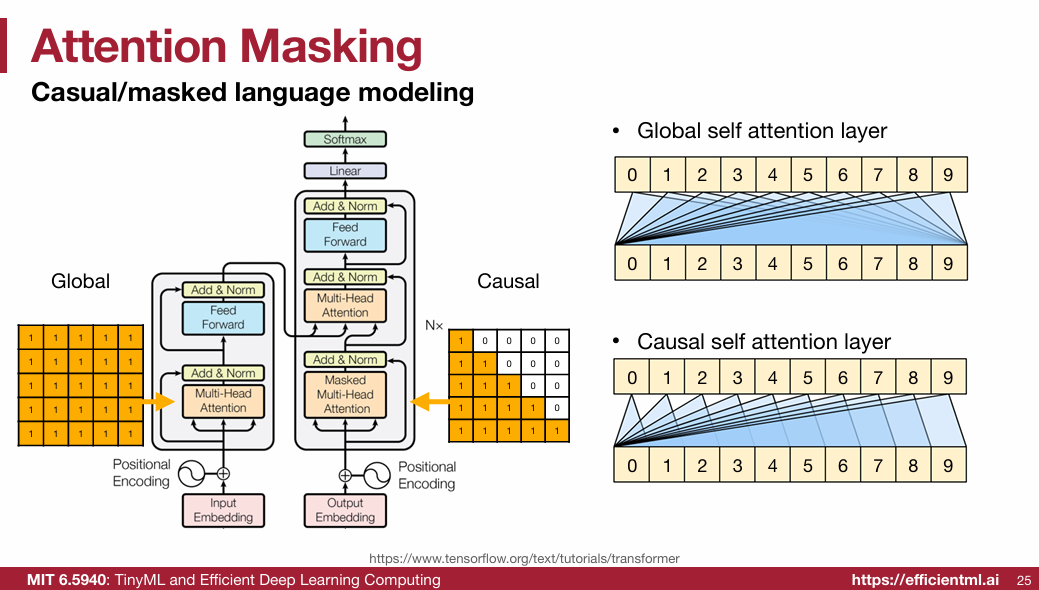
1.2.4 Feed-Forward Network (FFN)
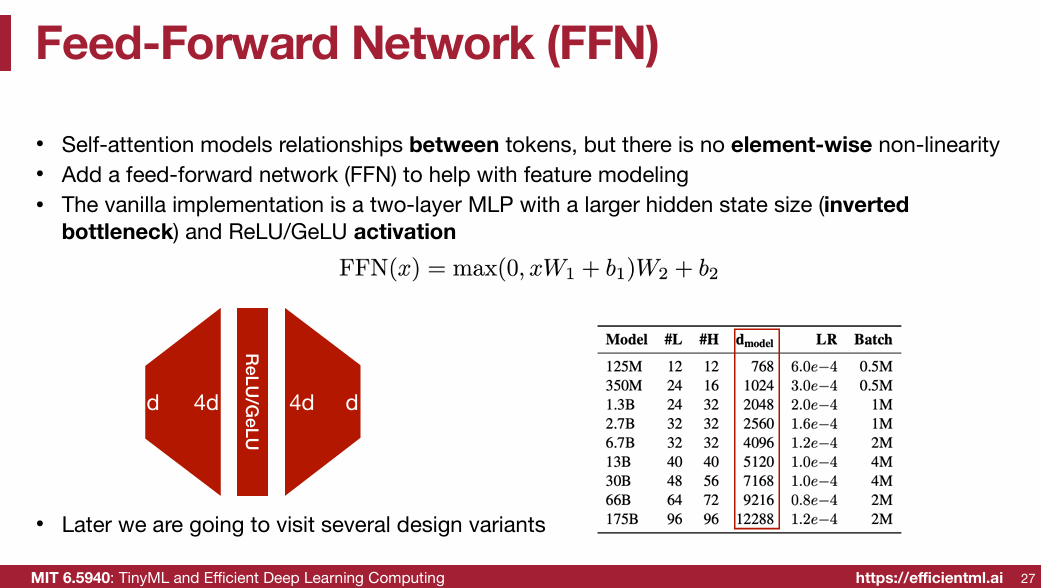
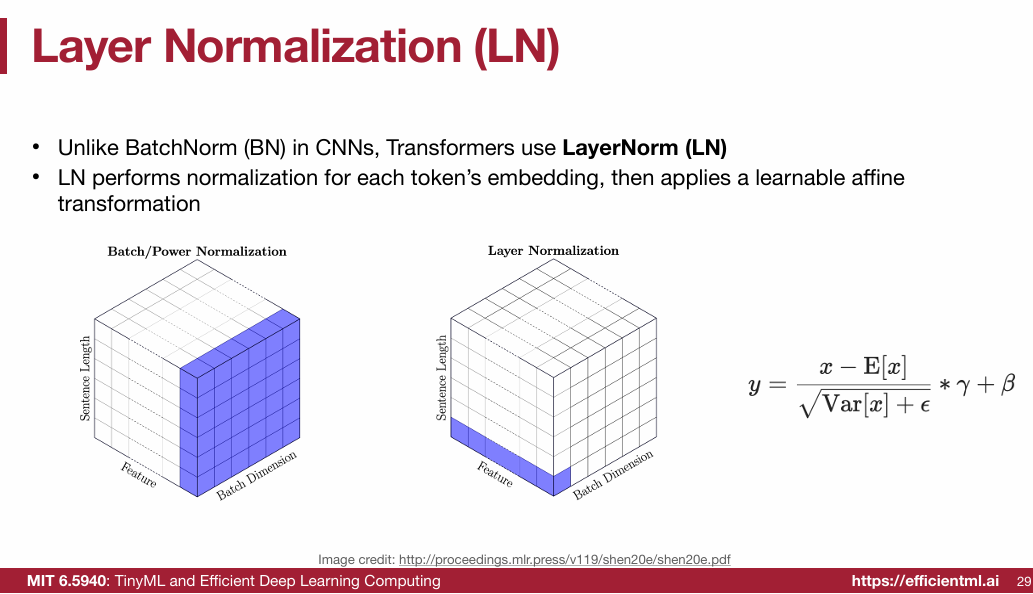
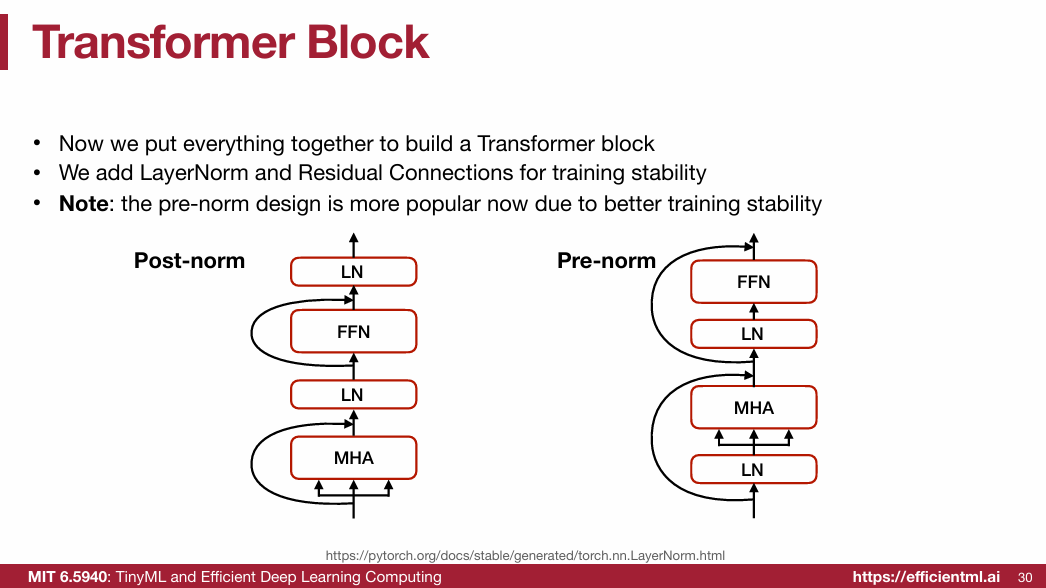
1.2.5 LayerNorm & Residual connection
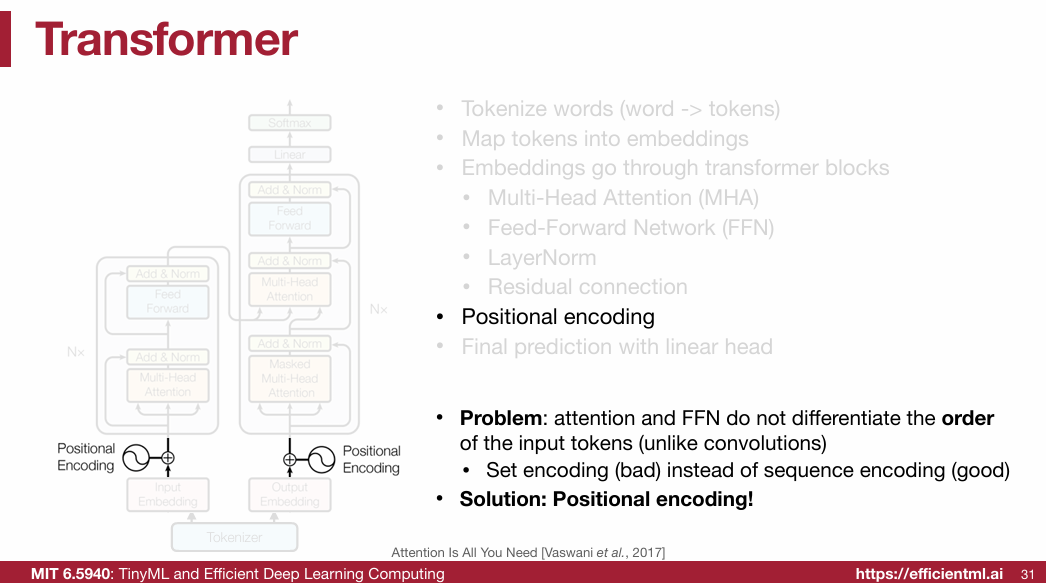
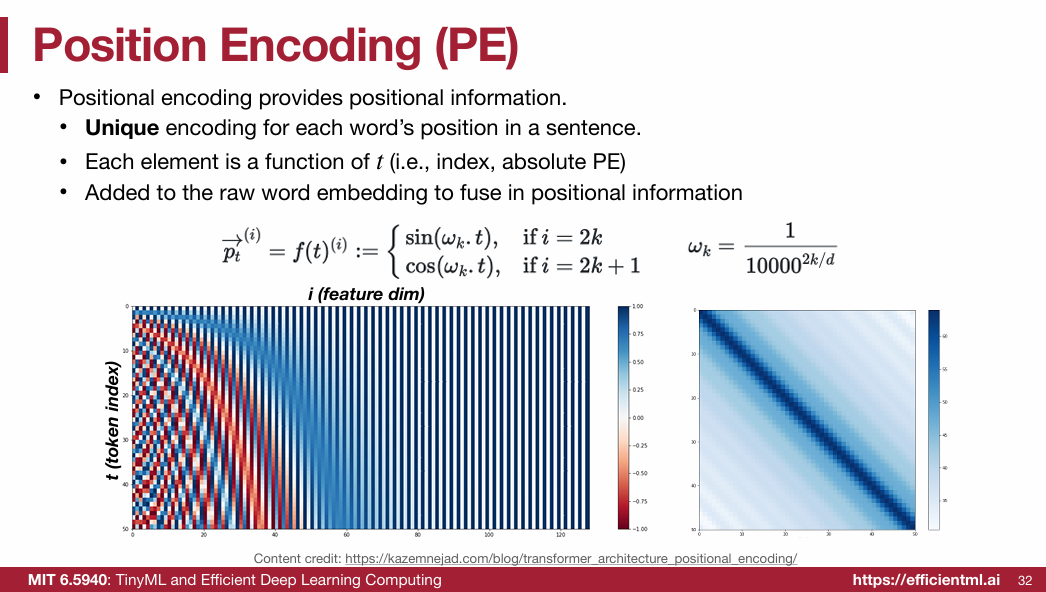
1.2.6 Position Encoding (PE)