文章目录
- 说明
- [一 内存布局](#一 内存布局)
-
- [1.1 内存分配示例](#1.1 内存分配示例)
- [1.2 缓冲区溢出](#1.2 缓冲区溢出)
- [二 缓冲区溢出](#二 缓冲区溢出)
-
- [2.1 内存引用错误](#2.1 内存引用错误)
- [2.2 危险的字符串库函数](#2.2 危险的字符串库函数)
- [2.3 echo() 函数栈溢出和详细分析](#2.3 echo() 函数栈溢出和详细分析)
- [2.4 栈溢出攻击(重点)](#2.4 栈溢出攻击(重点))
- [2.5 代码注入攻击(重点)](#2.5 代码注入攻击(重点))
- [2.6 防护措施](#2.6 防护措施)
-
- [2.6.1 避免代码中的溢出漏洞](#2.6.1 避免代码中的溢出漏洞)
- [2.6.2 系统级防护机制](#2.6.2 系统级防护机制)
- [2.6.3 Stack Canary 防护机制](#2.6.3 Stack Canary 防护机制)
- [2.7 返回导向编程攻击(ROP)](#2.7 返回导向编程攻击(ROP))
-
- [2.7.1 gadget实例分析](#2.7.1 gadget实例分析)
- [2.7.2 ROP执行机制](#2.7.2 ROP执行机制)
- [三 联合体(Union)与内存表示](#三 联合体(Union)与内存表示)
-
- [3.1 联合体的内存分配](#3.1 联合体的内存分配)
- [3.2 使用联合体访问数据位模式](#3.2 使用联合体访问数据位模式)
- [3.3 关键区别](#3.3 关键区别)
- [3.4 字节序问题](#3.4 字节序问题)
说明
- 庄老师的课堂,如春风拂面,启迪心智。然学生愚钝,于课上未能尽领其妙,心中常怀惭愧。
- 幸有课件为引,得以于课后静心求索。勤能补拙,笨鸟先飞,一番沉浸钻研,方窥见知识殿堂之幽深与壮美,竟觉趣味盎然。
- 今将此间心得与笔记整理成篇,公之于众,权作抛砖引玉。诚盼诸位学友不吝赐教,一同切磋琢磨,于学海中结伴同行。
- 资料地址:computing-system-security
一 内存布局
- 栈(Stack):运行时栈,大小限制为8MB,存储局部变量等。
- 堆(Heap):动态分配,按需扩展,malloc()、calloc()、new() 调用时分配。
- 数据段(Data):静态分配的数据,包括全局变量、静态变量、字符串常量。
- 文本段 / 共享库(Text / Shared Libraries):存放可执行机器指令,只读区域。
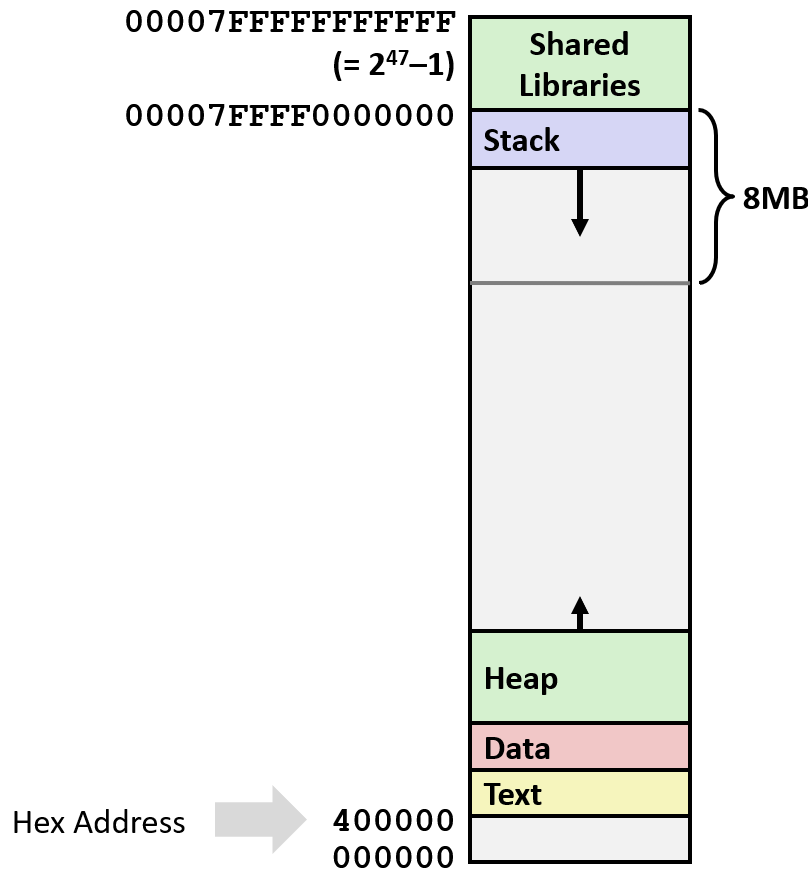
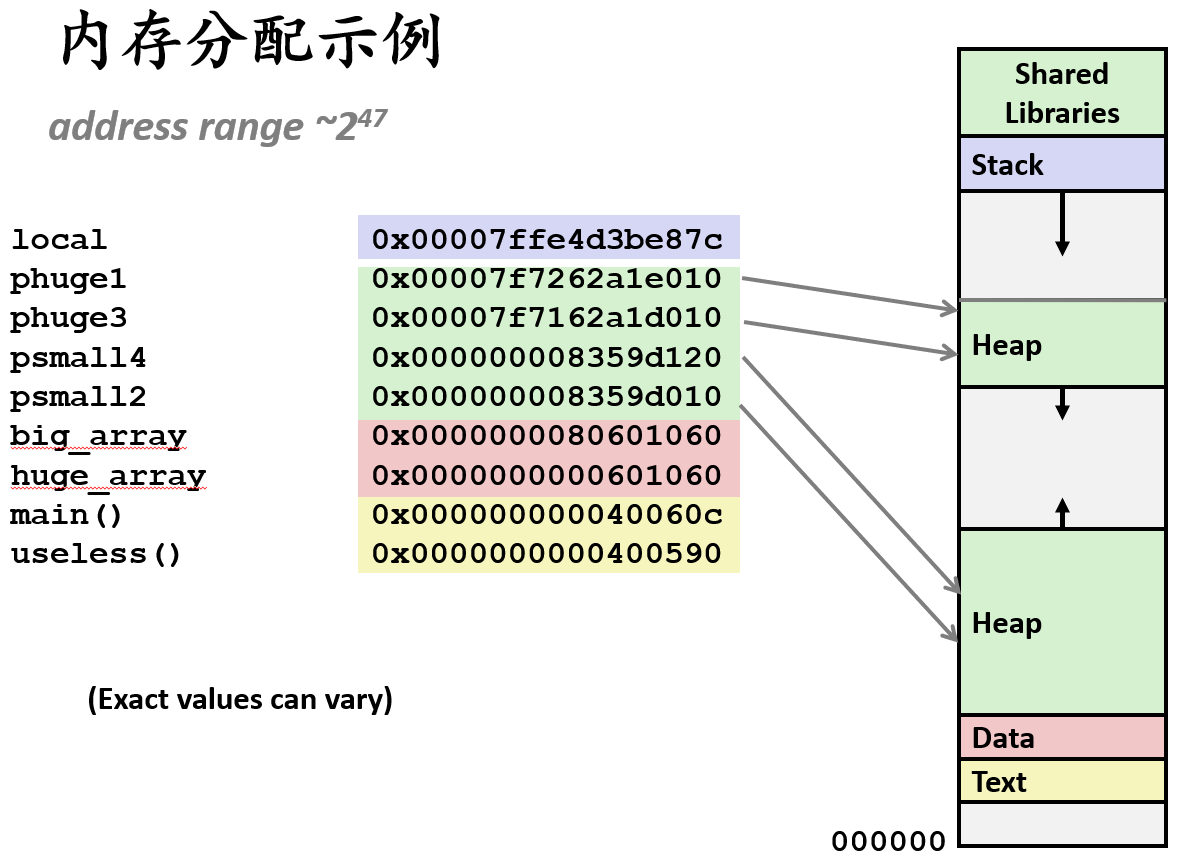
1.1 内存分配示例
c
char big_array[1L<<24]; /* 16 MB */
char huge_array[1L<<31]; /* 2 GB */
int global = 0;
int useless() { return 0; }
int main ()
{
void *phuge1, *psmall2, *phuge3, *psmall4;
int local = 0;
phuge1 = malloc(1L << 28); /* 256 MB */
psmall2 = malloc(1L << 8); /* 256 B */
phuge3 = malloc(1L << 32); /* 4 GB */
psmall4 = malloc(1L << 8); /* 256 B */
/* Some print statements ... */
}- big_array1\<\<24(16MB)→ 数据段
- huge_array1\<\<31(2GB)→ 数据段(地址较低)
- global → 数据段
- phuge1 = malloc(256MB) → 堆
- psmall2 = malloc(256B) → 堆
- phuge3 = malloc(4GB) → 堆
- psmall4 = malloc(256B) → 堆
- main() 和 useless() 函数地址 → 文本段
- 局部变量 local → 栈
1.2 缓冲区溢出
c
int recurse(int x) {
int a[1<<15]; // 4*2^15 = 128 KiB
printf("x = %d. a at %p\n", x, a);
a[0] = (1<<14)-1;
a[a[0]] = x-1;
if (a[a[0]] == 0)
return -1;
return recurse(a[a[0]]) - 1;
}
c
./runaway 67
x = 67. a at 0x7ffd18aba930
x = 66. a at 0x7ffd18a9a920
x = 65. a at 0x7ffd18a7a910
x = 64. a at 0x7ffd18a5a900
. . .
x = 4. a at 0x7ffd182da540
x = 3. a at 0x7ffd182ba530
x = 2. a at 0x7ffd1829a520
Segmentation fault (core dumped) - 递归函数 recurse(int x):每次调用分配 128 KiB 的局部数组 a\[\],导致栈帧深度增加。
- 输出显示栈地址逐次降低
- 最终结果:Segmentation fault(栈溢出)
- 原因:超过8MB栈空间限制
二 缓冲区溢出
2.1 内存引用错误
c
typedef struct {
int a[2];
double d;
} struct_t;
double fun(int i) {
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824; /* Possibly out of bounds */
return s.d;
}- struct_t 包含 int a2 和 double d,fun(i) 中对 s.ai 越界写入
- 不同 i 值的结果:
- i=0,1:正常返回 3.14
- i=2:d 值轻微变化(3.1399998665)
- i=3:d 值显著变化(2.0000006104)
- i=4:段错误
- i=6:栈破坏检测
- i=8:段错误
- 原因:越界写入覆盖了结构体中 double d 的存储位置。

- 当访问超出数组分配内存范围时发生"缓冲区溢出"(Buffer Overflow)。
- 缓冲区溢出的最常见形式:字符串输入未检查长度,特别是栈上的固定字符数组,又称"栈粉碎"(Stack Smashing)。
2.2 危险的字符串库函数
- Unix 函数
gets()的实现
c
/* Get string from stdin */
char *gets(char *dest){
int c = getchar();
char *p = dest;
while (c != EOF && c != '\n') {
*p++ = c;
c = getchar();
}
*p = '\0';
return dest;
}- gets() 函数实现:从标准输入读取字符串直到 EOF 或换行符,无输入长度限制,易导致缓冲区溢出。
- 类似问题函数:
- strcpy, strcat:复制任意长度字符串
- scanf 系列使用 %s 时不指定长度
2.3 echo() 函数栈溢出和详细分析
c
void echo() {
char buf[4]; // 声明一个4字节的缓冲区
gets(buf); // 从用户输入读取字符串到buf
puts(buf); // 打印buf中的内容
}
void call_echo() {
echo(); // 调用echo函数
}char buf[4]:声明了一个只能容纳4个字符的缓冲区(注意:C语言中字符串以\0结尾,所以实际只能存3个字符)。gets(buf):从标准输入读取用户输入,直接存入buf,不检查长度。这是危险的,因为如果输入超过4字节,就会溢出缓冲区。puts(buf):打印buf中的内容。- 实验现象:
- 输入 "01234567890123456789012" → 正常输出
- 输入 "012345678901234567890123" → 段错误
- 原因:长输入覆盖返回地址
echo函数的汇编:
assembly
echo:
subq $0x18, %rsp ; 为局部变量分配24字节栈空间(包括buf[4]和其他)
movq %rsp, %rdi ; 将buf的地址传给gets(%rdi是第一个参数寄存器)
callq gets ; 调用gets函数
movq %rsp, %rdi ; 再次将buf的地址传给puts
callq puts ; 调用puts函数
addq $0x18, %rsp ; 释放栈空间
retq ; 返回调用者subq $0x18, %rsp:在栈上分配24字节空间(0x18是24的十六进制)。其中buf[4]只占4字节,其余空间可能是编译器为了对齐或其他局部变量预留的。movq %rsp, %rdi:将当前栈指针(即buf的地址)传给gets和puts作为参数。callq gets:调用gets函数,将用户输入存入buf。
-
栈溢出分析:栈是程序运行时的一种内存结构,用于存储局部变量、函数参数和返回地址。当
echo函数被调用时,栈的结构如下:+-------------------+
| 返回地址 (call_echo)| <-- 栈顶(%rsp指向这里)
+-------------------+
| 其他数据 |
+-------------------+
| buf[4] | <-- buf的起始地址
+-------------------+
正常情况 :用户输入不超过4字节(如"abc"),buf能容纳,程序正常运行。
溢出情况 :用户输入超过4字节(如"1234567890..."),gets会继续写入,覆盖栈上的其他数据,包括返回地址。
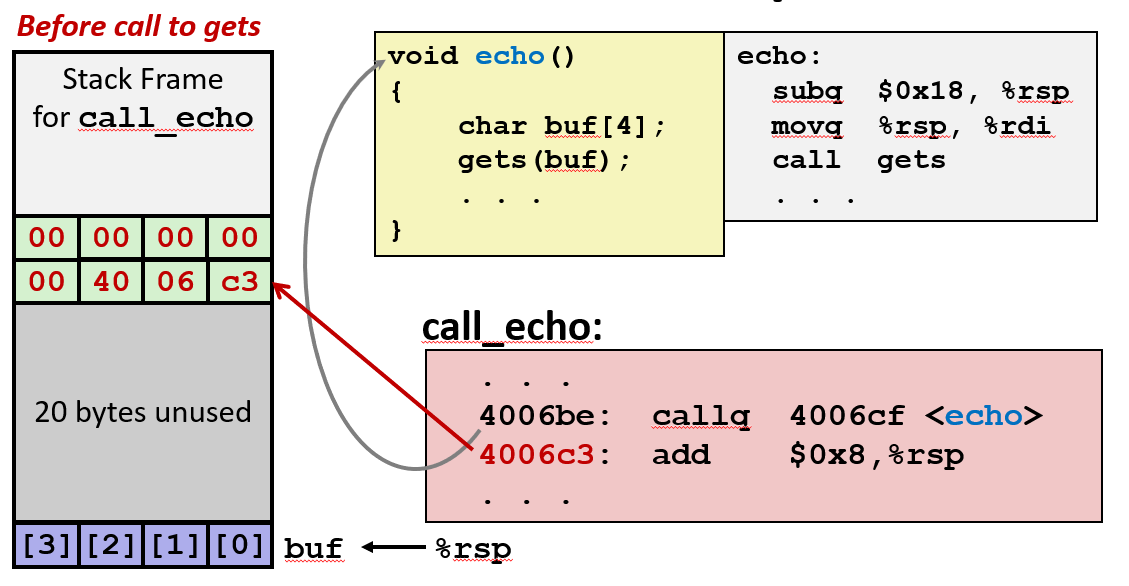
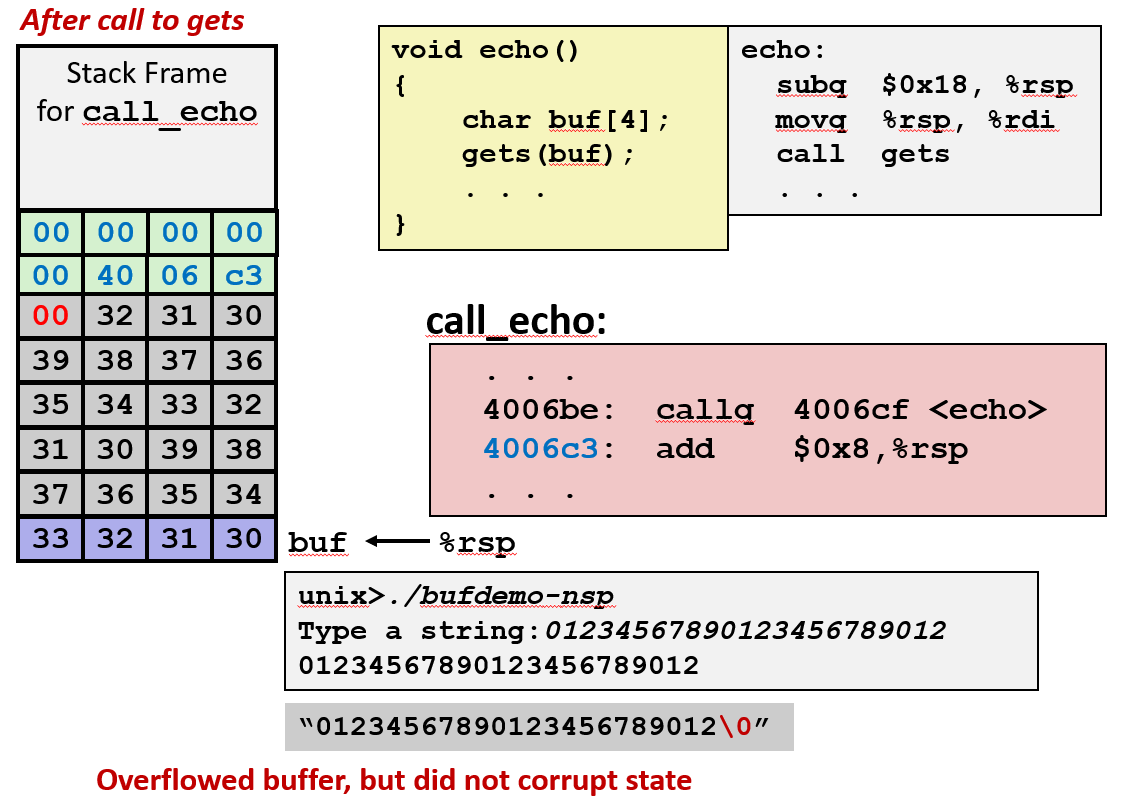
- 栈溢出示例
输入较短(未溢出)
- 输入:"01234567890123456789012"(23字节)
- 结果:缓冲区已溢出,但未破坏状态,
buf被填满,但未覆盖返回地址,程序正常运行。
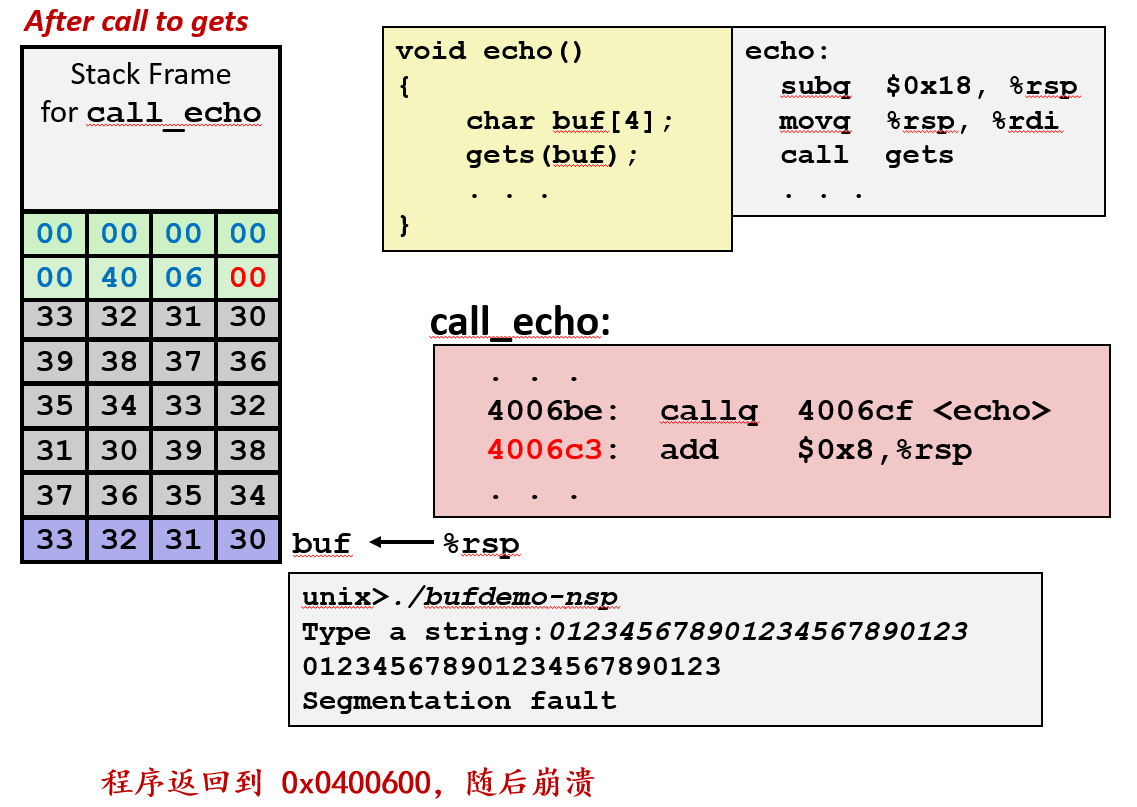
输入较长(溢出)
- 输入:"012345678901234567890123"(24字节)
- 结果:
buf溢出,覆盖了返回地址。返回地址被改为无效值(如0x0400600),导致程序崩溃(Segmentation Fault)。
2.4 栈溢出攻击(重点)
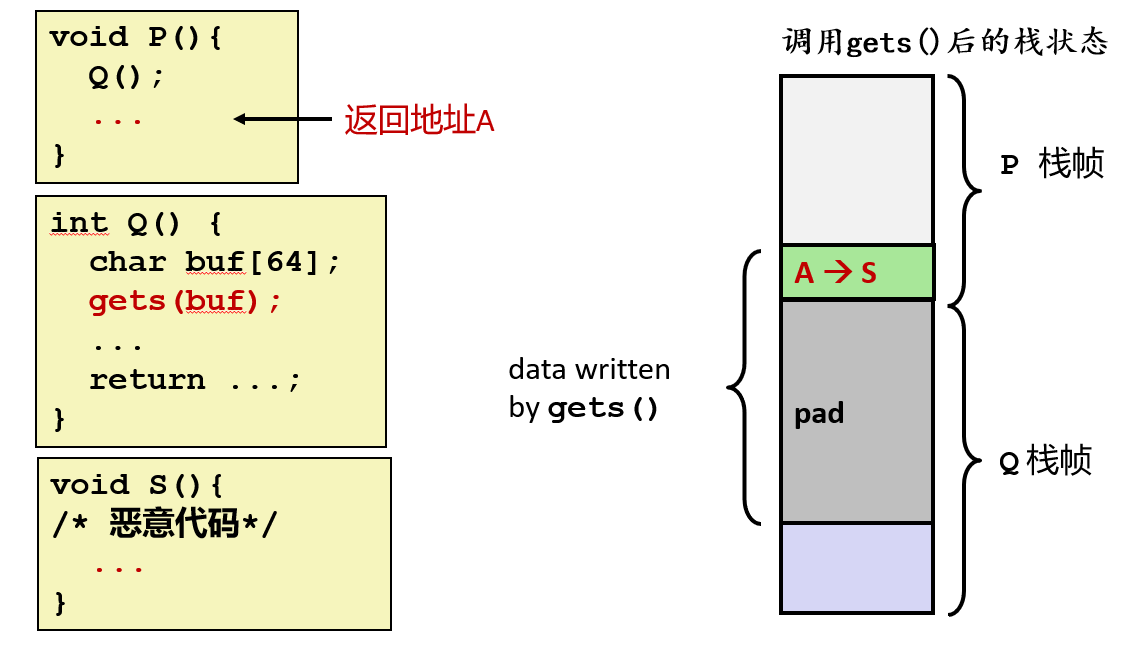
- 将正常的返回地址 A 覆盖为另一段代码 S 的地址。当 Q 执行 ret 指令时,将跳转至其他代码
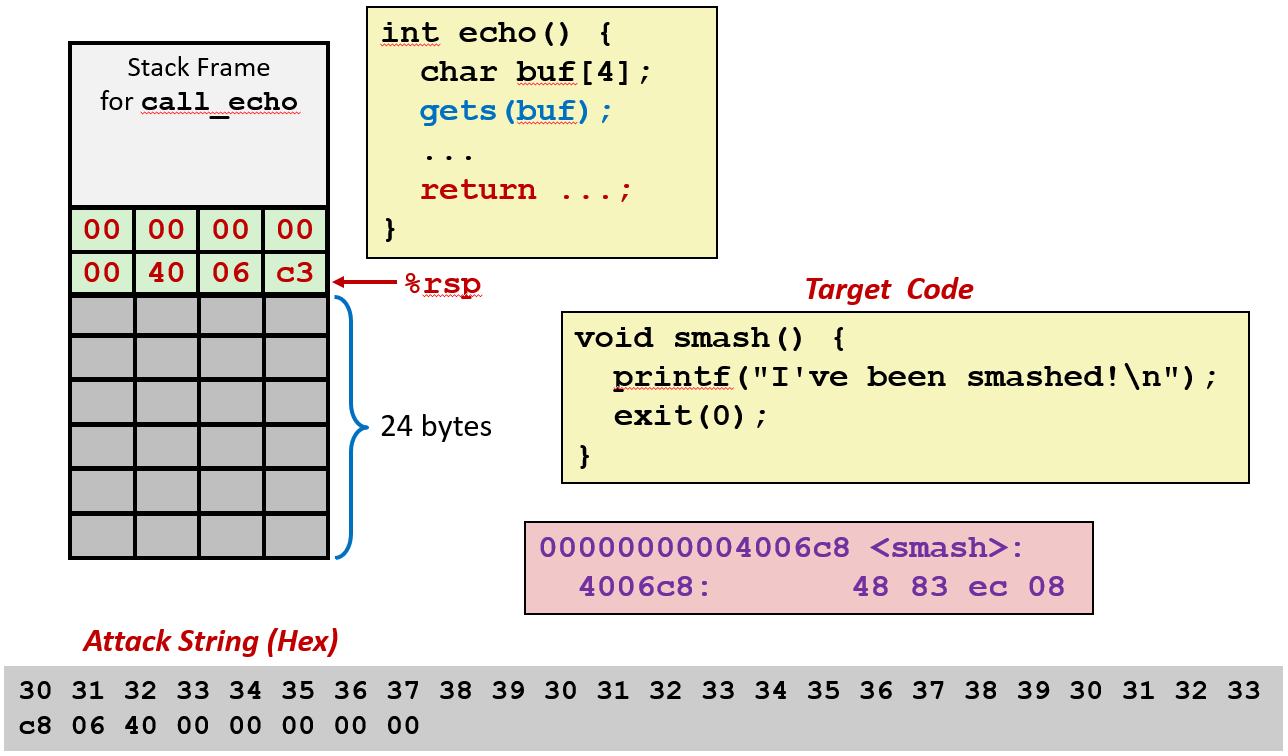
- 攻击模型:函数 Q() 中有 char buf64,gets(buf) 导致溢出。攻击者用目标函数 S 的地址覆盖原返回地址 A。Q 执行 ret 时跳转到 S。
- 目标函数
smash():打印 "I've been smashed!",调用 exit(0) 终止程序,地址为 0x4006c8。 - 攻击字符串组成:前 24 字节填充数据,接着 8 字节为目标地址(0xc8 06 40 00 00 00 00 00),小端序存储(低字节在前)。
2.5 代码注入攻击(重点)
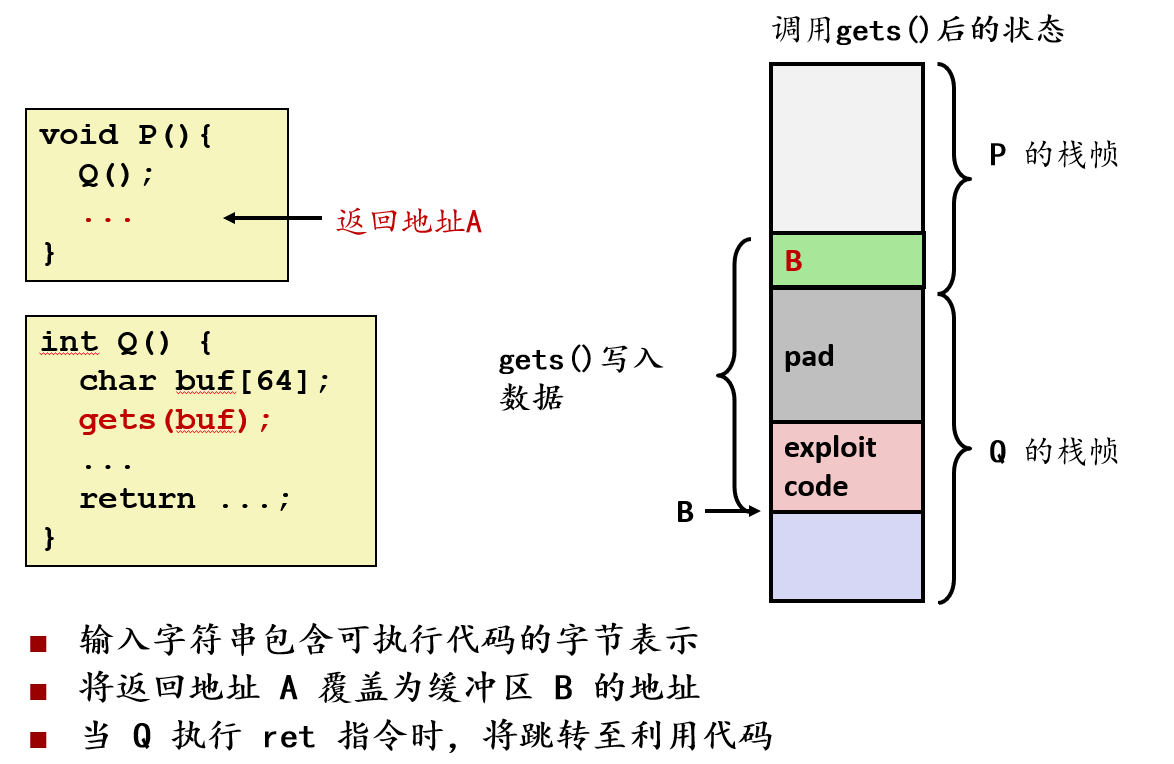
- 攻击机制:输入字符串包含可执行机器码(exploit code),覆盖返回地址指向缓冲区起始位置 B,ret 指令跳转到攻击代码开始执行,攻击代码通常用于打开 shell 或提升权限。
- 执行流程:rip(指令指针)从被覆盖的返回地址加载新值,rsp(栈指针)指向攻击代码所在栈区,CPU 开始执行栈上的恶意代码,直接运行攻击者提供的代码。
2.6 防护措施
2.6.1 避免代码中的溢出漏洞
安全编程实践:使用带长度限制的函数替代危险函数。
- fgets(buf, size, stdin) 替代 gets()
- strncpy 替代 strcpy
- strncat 替代 strcat
- scanf 使用 %ns 形式限定输入长度
- 使用 fgets 读取字符串再解析
2.6.2 系统级防护机制
- 随机化栈偏移:程序启动时在栈上分配随机大小的空间,使栈基地址每次运行都不同,增加预测攻击代码地址的难度
- 非可执行代码段:x86-64 支持显式的"执行"权限位,将栈标记为不可执行,即使跳转到栈上代码也会失败,有效防御代码注入攻击。
2.6.3 Stack Canary 防护机制
- Stack Canary 是编译器为防止栈溢出攻击而引入的一项安全机制。
- 在函数调用时,编译器会自动在局部变量与返回地址之间插入一个特殊的"金丝雀"值(Canary)。这个值在函数开始执行时被写入,在函数返回前再次进行检查。如果 canary 被意外或恶意修改(如发生了栈溢出),程序就会立刻崩溃,防止攻击者劫持控制流。
- 编译选项:-fstack-protector(默认启用)。运行时,正常输入,程序正常运行;溢出输入:检测到栈破坏并报错退出,并输出*** stack smashing detected ***。
- Stack Canary的设置过程:- 分配栈空间后立即设置金丝雀,位于缓冲区和返回地址之间,任何缓冲区溢出都会先覆盖金丝雀,返回前验证确保完整性。
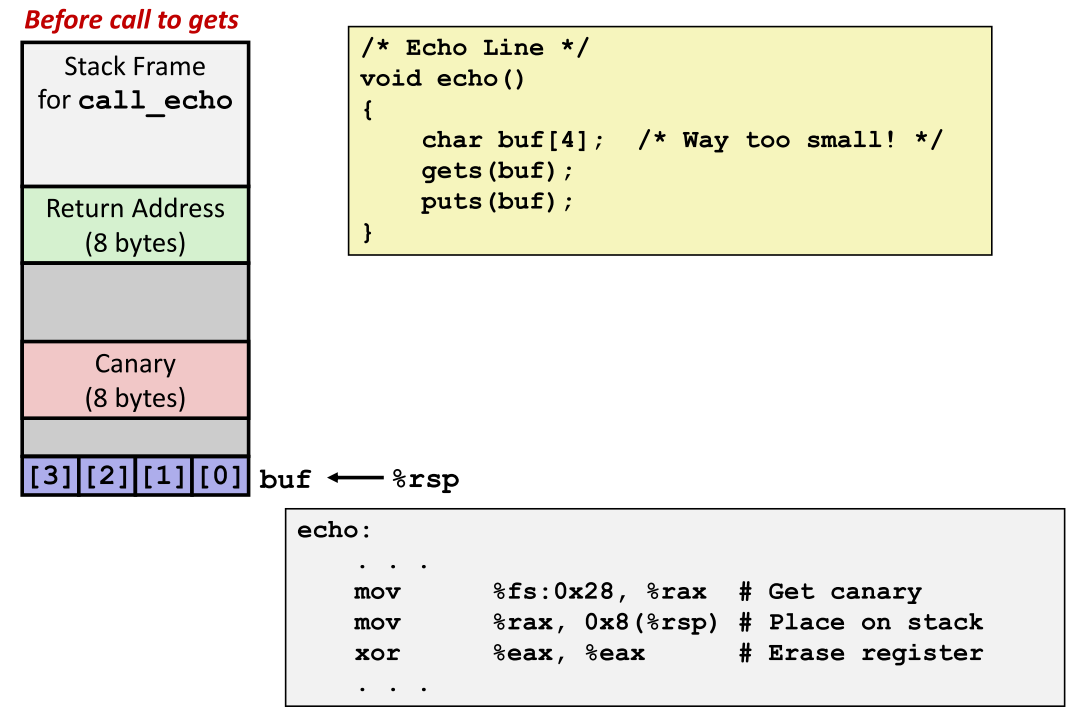
- Stack Canary在栈帧中的布局:调用
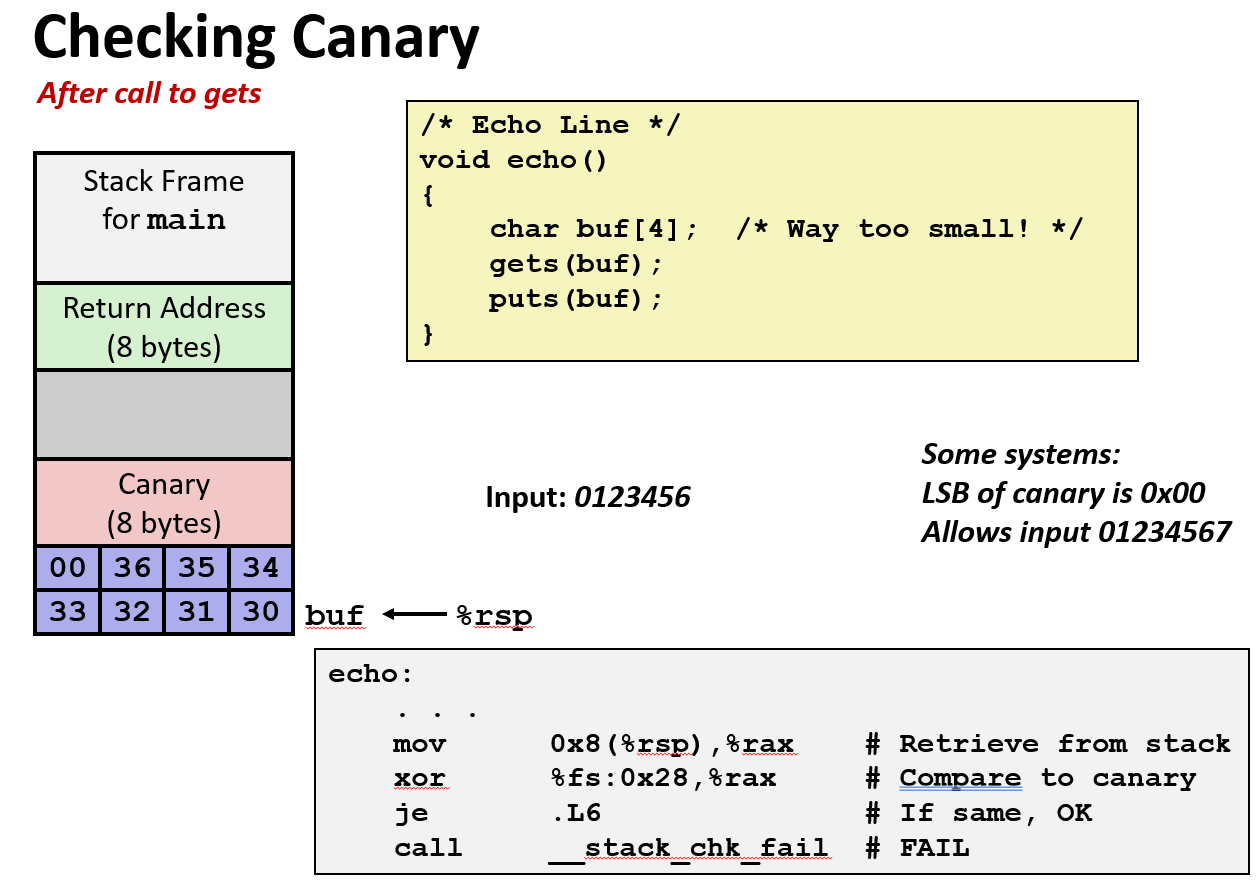
gets后的栈帧结构包含返回地址、保存的 %ebp 和 %ebx、未使用的20字节空间以及8字节的金丝雀值。金丝雀位于局部变量下方,用于检测缓冲区溢出。某些系统中金丝雀最低字节为0x00,允许输入字符串以null结尾。 - Stack Canary的检查过程:函数返回前会从栈中取出金丝雀并与其原始值进行异或比较。若不匹配则跳转至
__stack_chk_fail报告栈溢出错误。示例代码中使用mov 0x8(%rsp),%rax取值并与%fs:0x28处的canary对比。
2.7 返回导向编程攻击(ROP)
攻击挑战与对策
-
栈随机化使缓冲区位置难以预测。
-
栈不可执行标记阻止插入恶意机器码。
-
攻击者转而利用已有 可执行代码片段(gadgets) 构造攻击。
-
ROP基本策略:利用程序或库中已有的代码片段(gadget),每个以
ret(0xc3) 结尾。将多个gadget串联执行,实现任意操作。不受栈金丝雀保护影响,因不破坏金丝雀即可完成控制流劫持。
2.7.1 gadget实例分析
实例一:gadget实例分析:
c
long ab_plus_c
(long a, long b, long c) {
return a*b + c;
}- 对应的汇编代码:
c
00000000004004d0 <ab_plus_c>:
4004d0: 48 0f af fe imul %rsi,%rdi
4004d4: 48 8d 04 17 lea (%rdi,%rdx,1),%rax
4004d8: c3 retq - 地址 0x4004d4 处指令
lea (%rdi,%rdx,1),%rax可作为gadget使用。 - 功能:将
rdi + rdx的结果存入rax。 - gadget地址为
0x4004d4,取自函数尾部。
实例二:setval函数再利用
c
void setval(unsigned *p) {
*p = 3347663060u;
}
c
<setval>:
4004d9: c7 07 d4 48 89 c7 movl $0xc78948d4,(%rdi)
4004df: c3 retq- 原意是向指针写入常量,但中间字节恰好编码为
mov %rax, %rdi。 - gadget地址为 0x4004dc,通过精心布置可改变寄存器状态。
- 展示如何"重解释"合法代码字节实现攻击目的。
2.7.2 ROP执行机制
栈上gadget链构建
- 将一系列gadget地址压入栈,形成调用链。
- 触发方式为执行
ret指令,逐个跳转到各gadget。 - 每个gadget末尾的
ret自动弹出下一地址并跳转。
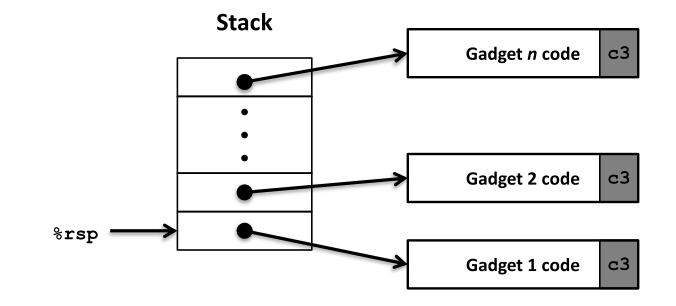
攻击字符串构造
- 构造包含填充数据和 g a d g e t gadget gadget地址的输入字符串。
- 示例攻击串包含两个 g a d g e t gadget gadget地址:0x4004d4 和 0x4004dc。
- 最终实现 r d i ← r d i + r d x rdi ← rdi + rdx rdi←rdi+rdx的复合操作。

echo函数返回后的执行流程
echo执行ret后开始执行第一个gadget。- 第一个gadget执行完后通过
ret跳转到第二个gadget。 - 第二个gadget完成后继续跳转,最终可能导致非法内存访问或进一步攻击。
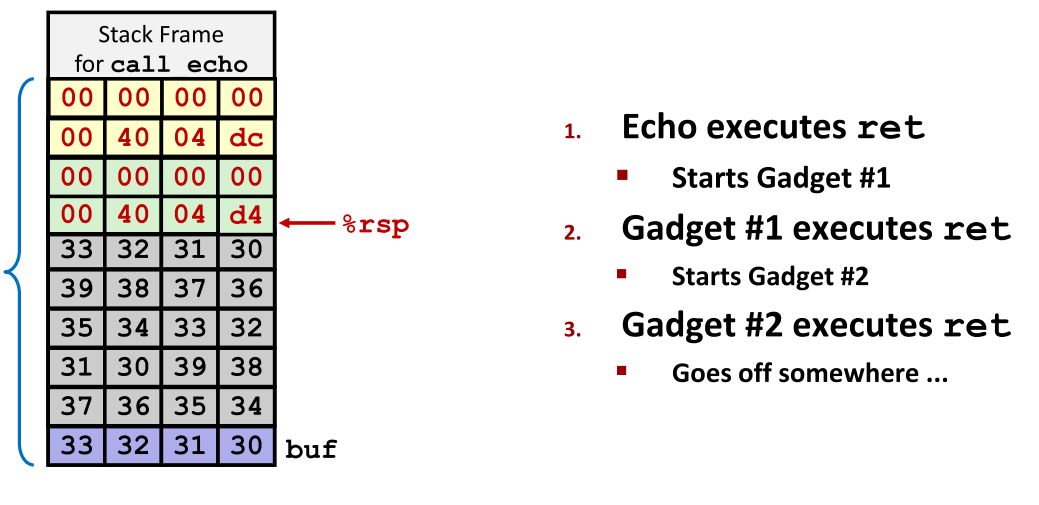
三 联合体(Union)与内存表示
3.1 联合体的内存分配
- 分配大小等于最大成员所需空间。
- 所有成员共享同一块内存区域,任一时刻只能有效使用一个字段。
- 示例:union U1 包含 char、int数组和double,总大小由double决定。
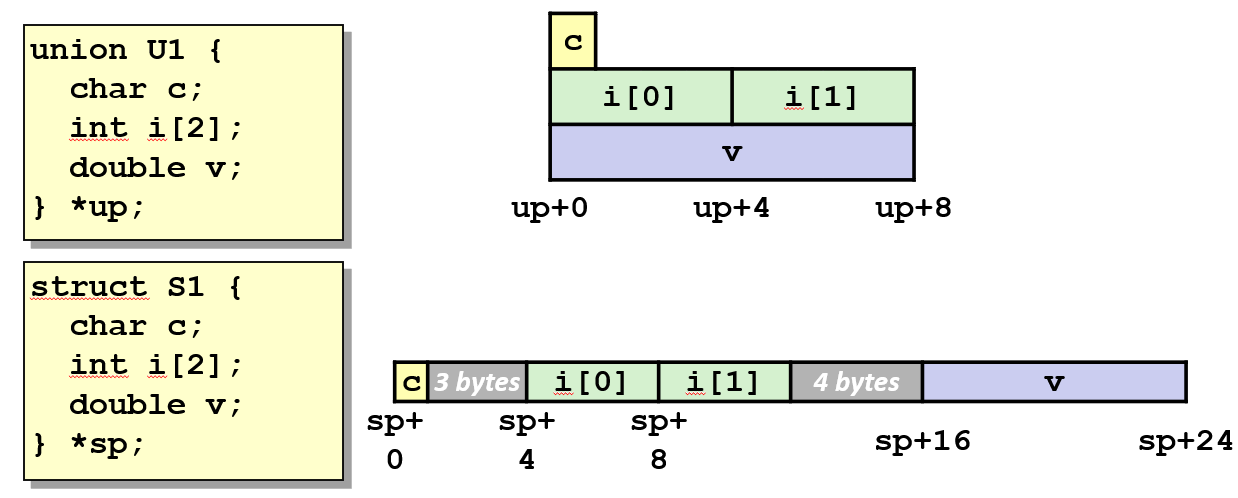
3.2 使用联合体访问数据位模式
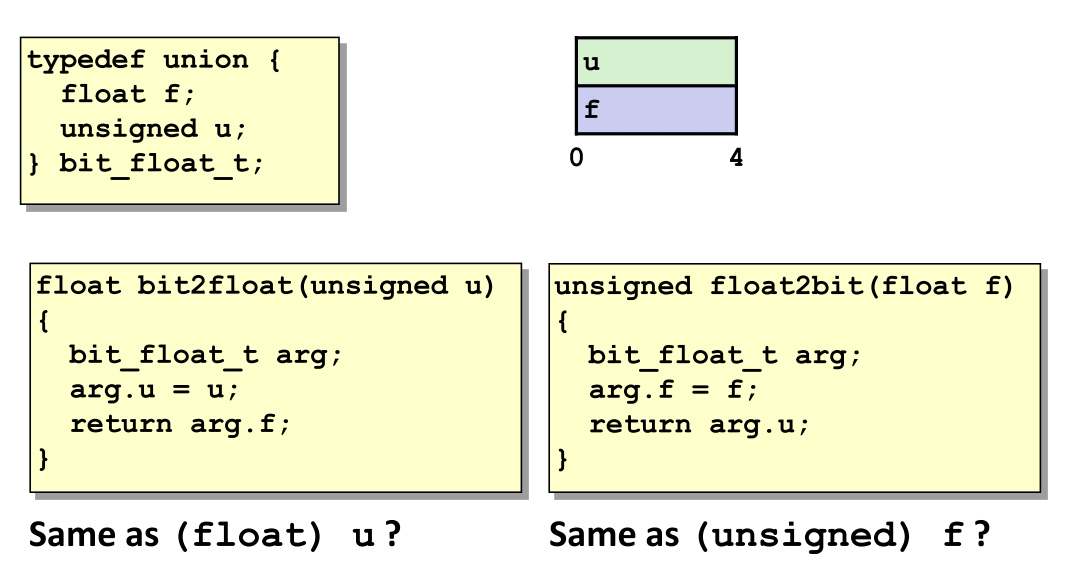
float与unsigned之间的转换
- 定义联合体
bit_float_t实现float与unsigned共享内存。 float2bit: 将浮点数按位模式解释为无符号整数。bit2float: 将无符号整数按IEEE 754格式解释为浮点数。- 与强制类型转换不同,此方法保留原始比特位。
一个联合体 bit_float_t:
c
typedef union {
float f; // 4字节的浮点数
unsigned u; // 4字节的无符号整数
} bit_float_t;- 联合体的特点是:所有成员共享同一块内存空间。这意味着
f和u指向完全相同的4字节内存区域,只是解释方式不同。
位模式访问
bit2float函数
c
float bit2float(unsigned u) {
bit_float_t arg;
arg.u = u;
return arg.f;
}问题:是否等同于 (float)u?
答案:不等于
原因: (float)u 是简单的类型转换,将无符号整数的数值直接解释为浮点数,而 bit2float 是将整数的位模式直接复制到浮点数的内存表示中。例如:如果 u = 0x40490fdb(这是π的浮点数表示)。(float)u 会尝试将整数 0x40490fdb 转换为浮点数,结果是一个很大的数。bit2float(u) 会将位模式 0x40490fdb 解释为浮点数,结果是 π。
float2bit函数
c
unsigned float2bit(float f) {
bit_float_t arg;
arg.f = f;
return arg.u;
}问题:是否等同于 (unsigned)f?
答案:不等于
原因: (unsigned)f 是将浮点数的数值转换为无符号整数,float2bit 是提取浮点数的位模式。
例如:如果 f = 3.14(π),(unsigned)f 会将 3.14 转换为无符号整数,结果是 3。float2bit(f) 会提取 π 的 IEEE 754 位模式,结果是 0x40490fdb
3.3 关键区别
| 操作 | (float)u / (unsigned)f |
bit2float / float2bit |
|---|---|---|
| 转换方式 | 数值转换 | 位模式复制 |
| 结果 | 数值的数学转换 | 相同位模式的重新解释 |
| 用途 | 数值计算 | 位操作、IEEE 754表示 |
3.4 字节序问题
- 多字节数据在内存中按字节存储,顺序影响解析结果。
- 大端存储(Big Endian):最高有效字节位于低地址。例如,一个16位的数0x1234,在大端模式下,0x12是高位字节,会被存储在较低的地址,而0x34作为低位字节,存储在较高的地址。
- 小端存储(Little Endian):最低有效字节位于低地址。例如,一个16位的数0x1234,在小端模式下,0x34会被存储在较低的地址,而0x12存储在较高的地址。
- 双端序(Bi Endian):ARM可配置。
- 典型平台字节序
- Sparc、Internet协议采用大端序。
- Intel x86、ARM Android、iOS采用小端序。
c
union
{
unsigned char c[8];
unsigned short s[4];
unsigned int i[2];
unsigned long l[1];
} dw;
