昆明天气数据预处理
- 前言
- 一、预处理目标与数据概况
- 二、预处理环境配置
- 三、数据加载与初步探索
- 四、核心预处理步骤
-
- [1. 重复值处理](#1. 重复值处理)
- [2. 日期处理](#2. 日期处理)
- [3. 天气类型简化](#3. 天气类型简化)
- [4. 风力等级标准化](#4. 风力等级标准化)
- [5. 温度数据处理](#5. 温度数据处理)
- 五、完整流程整合与执行
- 六、完整代码
前言
在数据分析和机器学习项目中,数据预处理是决定模型效果的关键步骤之一。本文将以昆明天气数据为例,详细介绍天气数据的预处理全过程,包括数据加载、清洗、特征工程等关键环节,并提供完整可复用的Python代码实现。
一、预处理目标与数据概况
昆明作为著名的"春城",其天气数据具有重要的分析价值。数据预处理的目标是:
- 解决数据质量问题(缺失值、重复值、格式错误等)
- 提取有价值的特征(日期特征、季节特征等)
- 简化冗余信息(天气类型、风力等级标准化)
- 为后续的数据分析和建模提供高质量数据集
本次处理的数据包含以下主要字段:
- 城市与区域信息(city, district_name)
- 日期(date)
- 昼夜天气类型(type_day, type_night)
- 昼夜风向风力(direction_day, wind_force_day等)
- 温度信息(max_temperature, min_temperature)
二、预处理环境配置
首先需要配置Python环境,确保中文正常显示并设置合适的Pandas显示选项。
python
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from pathlib import Path
def setup_environment():
"""配置绘图和Pandas环境"""
# 设置中文正常显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 设置Pandas全局选项
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 50)
pd.set_option('display.expand_frame_repr', False)三、数据加载与初步探索
在进行任何处理前,需要先加载数据并对其进行初步探索,了解数据的基本情况。该代码模块是昆明天气数据预处理的前置核心环节,一方面通过异常捕获机制安全加载CSV格式原始数据,避免文件缺失、格式错误等加载问题;另一方面对数据进行结构化探索,输出数据维度、类型、离散特征(天气类型、风力等级等)的唯一值及数量,为后续清洗和特征工程提供数据基础画像。
python
def load_data(file_path):
"""加载数据并进行初步验证"""
try:
df = pd.read_csv(file_path)
print(f"成功加载数据,共 {df.shape[0]} 行,{df.shape[1]} 列")
return df
except FileNotFoundError:
raise FileNotFoundError(f"数据文件不存在: {file_path}")
except Exception as e:
raise Exception(f"加载数据出错: {str(e)}")
def inspect_data(df):
"""检查数据基本信息"""
print("\n=== 数据基本信息 ===")
df.info()
print("\n=== 离散特征唯一值统计 ===")
lisan_columns = [
'city', 'district_name', 'type_day', 'type_night',
'direction_day', 'wind_force_day', 'direction_night', 'wind_force_night'
]
for column in lisan_columns:
if column in df.columns:
unique_vals = df[column].unique()
print(f"{column}的唯一值有:{unique_vals},数量:{df[column].nunique()}")
else:
print(f"警告:列 {column} 不存在于数据中")成功加载则输出41206行11列,直观呈现数据规模;失败则精准提示错误原因(文件不存在/格式错误等),快速定位问题。数据基本信息结果显示所有列均为object类型、无缺失值,明确后续需将日期列转datetime、温度列转数值型,且无需处理空值。
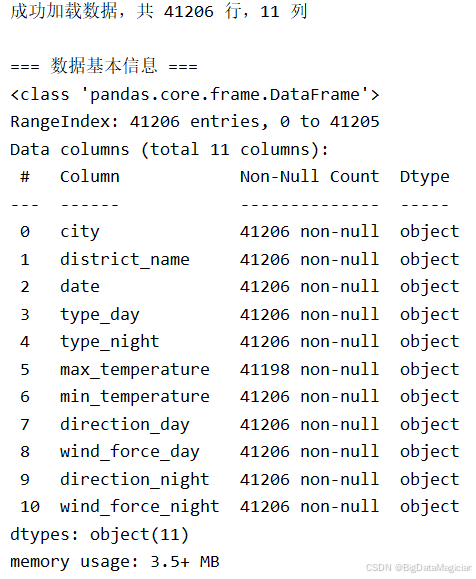
离散特征统计结果显示city仅为"昆明",district_name含多个区县;type_day/night有晴、多云、小雨等十余种取值,wind_force_day/night存在"1-2级、微风、≤3级"等不规范表述,直接支撑后续天气类型简化、风力等级标准化的需求;若缺失目标列,会即时提示异常。

四、核心预处理步骤
1. 重复值处理
该代码实现天气数据的重复值检测与删除,先统计重复记录数,若存在重复则执行删除,通过Pandas原生方法实现轻量化去重,同时打印处理前后的重复值数量,让清洗效果清晰可查。
python
def handle_duplicates(df):
"""处理重复数据"""
duplicate_count = df.duplicated().sum()
print(f"\n重复值数量(处理前):{duplicate_count}")
if duplicate_count > 0:
df = df.drop_duplicates()
print(f"重复值数量(处理后):{df.duplicated().sum()}")
return df根据执行结果显示,处理前重复值数量为3101,明确原始数据存在3101条重复记录,反映采集过程的冗余问题;处理后重复值数量为0,说明所有重复记录已被清理;去重后数据无冗余,避免重复记录干扰后续天气频率统计、温度分析等环节的准确性。

2. 日期处理
对原始数据中的日期信息进行了标准化处理,并基于该字段衍生出多个时间维度的特征。包括年份、月份、具体日期、星期几、所在周序号,以及根据月份划分的四季分类。这些特征有助于刻画天气变化的时间规律,为后续分析提供结构化的时间上下文。
python
def process_dates(df):
"""处理日期相关特征"""
# 日期转换
df['date'] = pd.to_datetime(df['date'], format='%Y年%m月%d日', errors='coerce')
# 检查日期转换错误
invalid_dates = df['date'].isna().sum()
if invalid_dates > 0:
print(f"警告:有 {invalid_dates} 条日期格式不正确")
# 提取日期特征
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday # 0-6,周一到周日
df['week'] = df['date'].dt.isocalendar().week
# 季节特征
def get_season(month):
if pd.isna(month):
return '未知'
if month in [3, 4, 5]:
return '春季'
elif month in [6, 7, 8]:
return '夏季'
elif month in [9, 10, 11]:
return '秋季'
else:
return '冬季'
df['season'] = df['month'].apply(get_season)
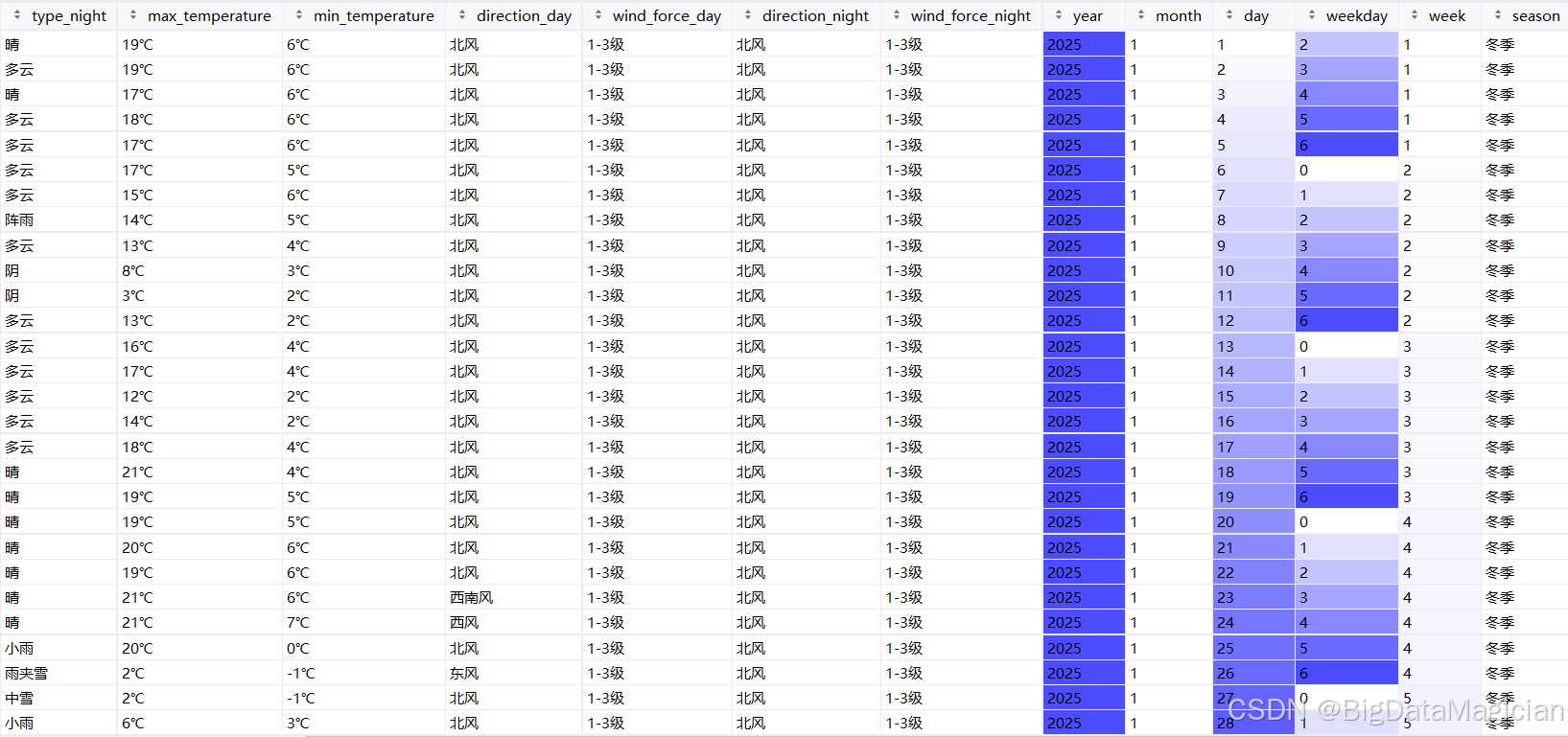
return df处理后部分数据如下图所示,处理后的数据集中新增了多列时间相关字段,每条记录均包含完整的年、月、日信息,并标注了对应的星期、周序号及所属季节。整体格式统一,无明显异常值,能够有效支持按时间维度展开的趋势分析或建模任务。
3. 天气类型简化
原始天气数据里,天气描述会细分到 "小雨""中到大雨" 等具体类型,这类细分表述会增加后续分析的复杂度。因此将这些细分类型归类合并,把各类降雨相关的表述统一归为 "雨天",降雪相关的归为 "雪天",多云、阴天类归为 "阴天",晴、少云类归为 "晴天",雾相关的归为 "雾天",同时对空值标注为 "未知",以此实现天气类型的标准化简化。
python
def simplify_weather_types(df):
"""简化天气类型"""
# 使用集合提高查询效率
rain_set = {'小雨', '阵雨', '雨夹雪', '雷阵雨', '中雨', '大雨',
'小到中雨', '中到大雨', '暴雨', '小雨-中雨',
'大到暴雨', '中雨-大雨', '雷阵雨伴有冰雹'}
snow_set = {'小雪', '中雪', '阵雪', '小到中雪', '中到大雪', '零散阵雪'}
cloud_set = {'多云', '阴', '阴天'}
sunny_set = {'晴', '少云', '局部多云'}
fog_set = {'雾'}
def simple_weather_type(weather_type):
if pd.isna(weather_type):
return '未知'
elif weather_type in rain_set:
return '雨天'
elif weather_type in snow_set:
return '雪天'
elif weather_type in cloud_set:
return '阴天'
elif weather_type in sunny_set:
return '晴天'
elif weather_type in fog_set:
return '雾天'
else:
return '其他'
# 应用简化函数
df['type_day'] = df['type_day'].apply(simple_weather_type)
df['type_night'] = df['type_night'].apply(simple_weather_type)
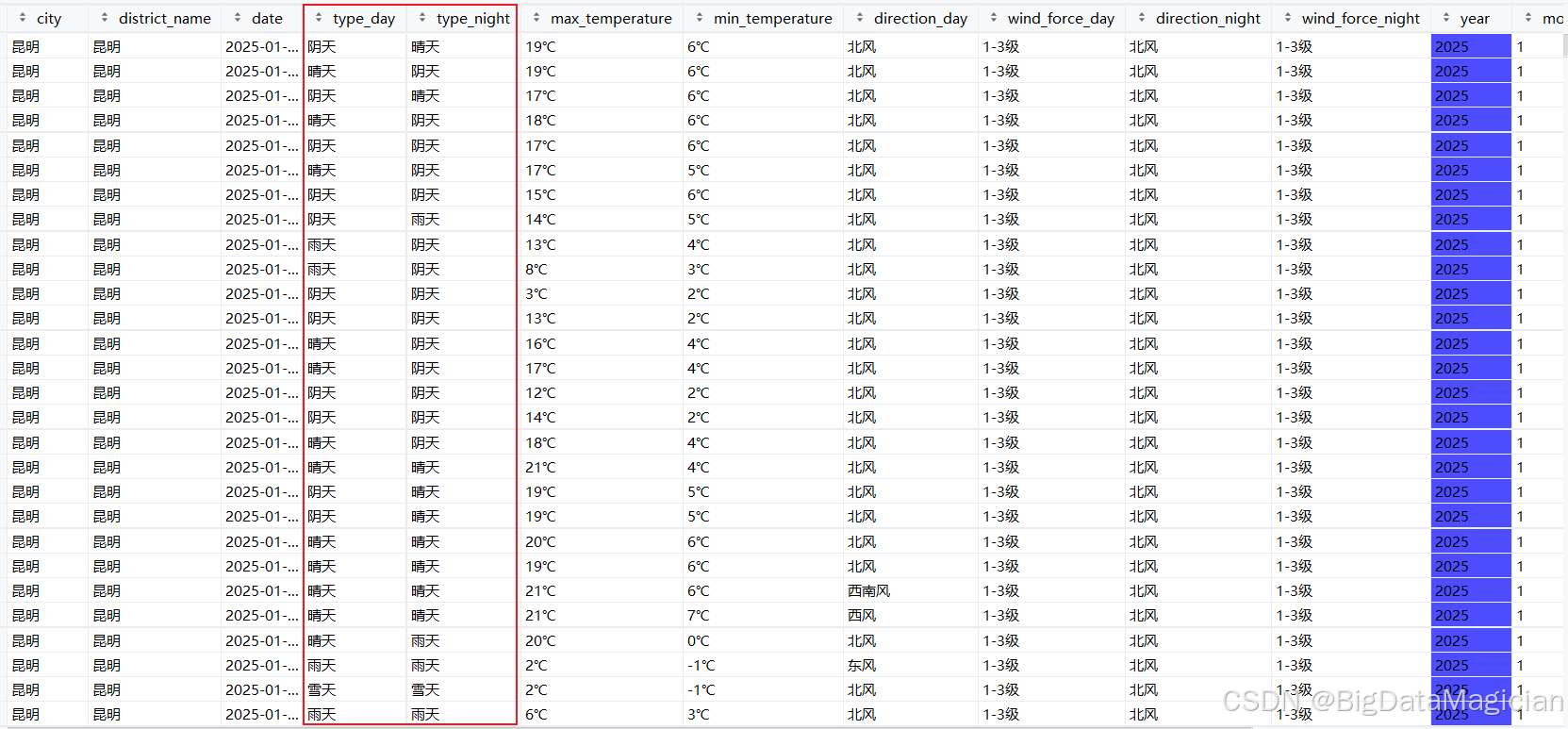
return df处理后部分数据如下图所示,从处理后的数据能看到,原本细分的天气表述(比如 "晴""阴"),现在统一成了 "晴天""雨天" 等大类。简化后的天气类型更简洁规整,既保留了天气的核心属性,又避免了细分类型过多带来的分析冗余,方便后续统计不同天气类别对应的温度变化、出现频率等分析工作。
4. 风力等级标准化
原始数据里,风力的描述方式比较杂乱,像 "1-2 级""微风""≤3 级" 这些不同说法,其实都属于相近的风力范围。把这些零散的表述做了统一归类,将 "1-2 级""微风" 等都合并为 "1-3 级","3""4""3~4 级" 等统一成 "3-4 级",同时保留 "4-5 级""5-6 级" 的分类,对未匹配到的情况标注为 "未知",这样就能让风力等级的表述更规范统一。
python
def simplify_wind_force(df):
"""简化风力等级"""
force_map = {
'1-2级': '1-3级',
'微风': '1-3级',
'微风级': '1-3级',
'≤3级': '1-3级',
'<3级': '1-3级',
'1-3级': '1-3级',
'3': '3-4级',
'4': '3-4级',
'3-4级级': '3-4级',
'3~4级': '3-4级',
'3-4级': '3-4级',
'4-5级': '4-5级',
'5-6级': '5-6级'
}
# 使用map方法进行映射转换
df['wind_force_day'] = df['wind_force_day'].map(force_map).fillna('未知')
df['wind_force_night'] = df['wind_force_night'].map(force_map).fillna('未知')
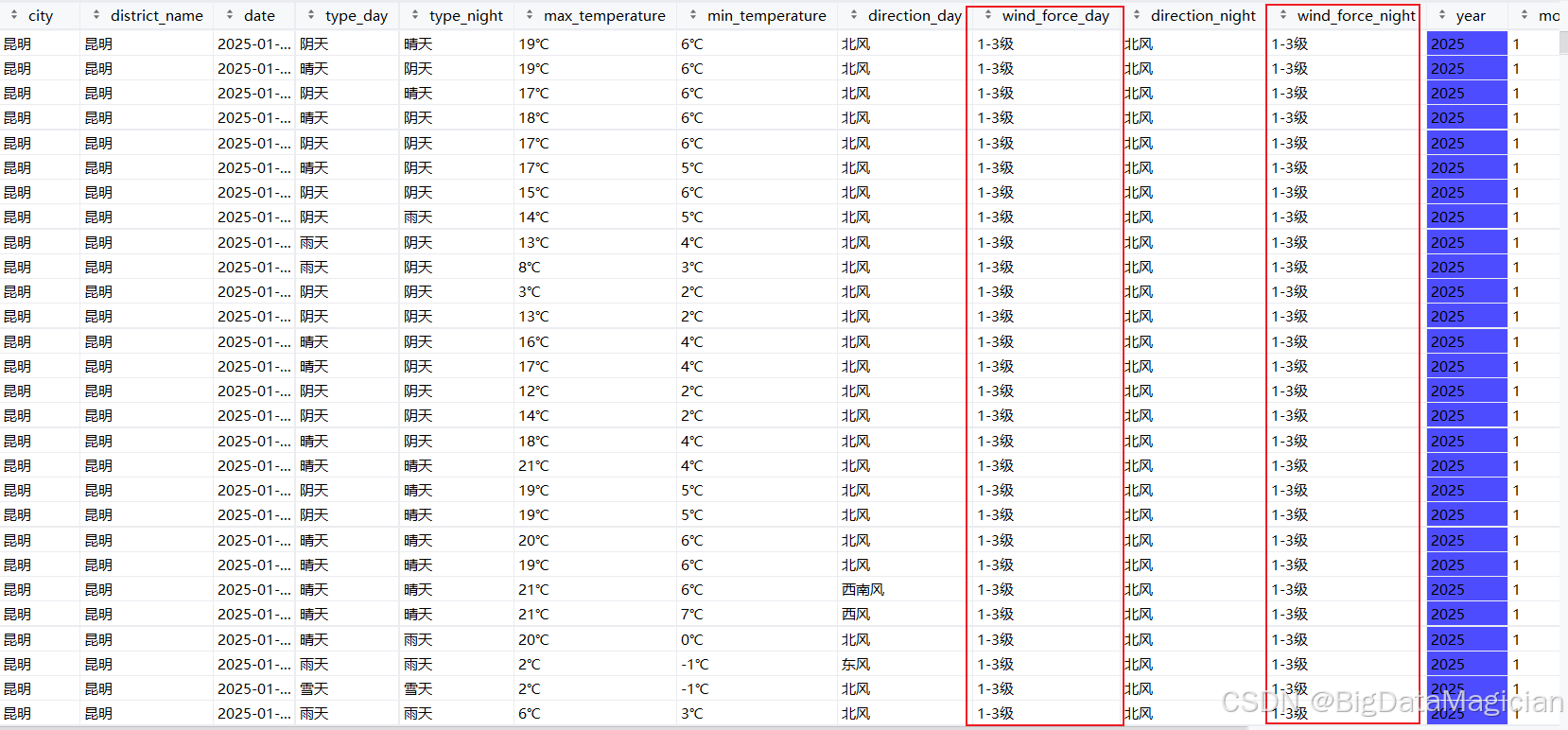
return df处理后部分数据如图所示,从处理后的数据能看到,原本不同表述的风力(比如 "1-2 级""微风"),现在都统一成了 "1-3 级" 这样的标准等级。标准化后的风力等级更规整,既保留了风力的核心区间信息,又避免了表述混乱带来的分析干扰,方便后续统计不同风力等级对应的天气、温度等关联特征。
5. 温度数据处理
温度是天气分析的核心数据,原始数据里温度带 "℃" 单位且可能存在缺失,先按区域、年月分组做前置填充(同区域同月温度有连续性),再去掉 "℃" 单位并转为整数格式,最后计算出日温差。这样既解决了单位和格式问题,也补充了温差这一实用特征。
python
def process_temperatures(df):
"""处理温度数据"""
# 处理缺失值
print("\n缺失值情况(处理前):")
print(df[['max_temperature', 'min_temperature']].isnull().sum())
# 按区域、年、月向前填充缺失值(同区域同月的温度具有连续性)
df['max_temperature'] = df.groupby(['district_name', 'year', 'month'])['max_temperature'].fillna(method='ffill')
df['min_temperature'] = df.groupby(['district_name', 'year', 'month'])['min_temperature'].fillna(method='ffill')
# 处理单位并转换为整数
def clean_unit(temperature):
if pd.isna(temperature):
return np.nan
try:
return int(str(temperature).replace('℃', ''))
except (ValueError, TypeError):
return np.nan
df['max_temperature'] = df['max_temperature'].apply(clean_unit)
df['min_temperature'] = df['min_temperature'].apply(clean_unit)
# 计算温差特征
df['temp_diff'] = df['max_temperature'] - df['min_temperature']
print("缺失值情况(处理后):")
print(df[['max_temperature', 'min_temperature', 'temp_diff']].isnull().sum())
return df处理后数据如下图,从处理后的数据能看到,原本带 "℃" 的温度值(如 "19℃"),现在已转为纯数字格式。统一格式后的温度数据更便于后续计算(比如统计月均温),而温差的隐含信息也被提取出来,能直接用于分析不同天气下的温度波动情况。
五、完整流程整合与执行
为了让零散的预处理步骤形成可落地的完整流程,将环境配置、数据加载、数据检查、各类清洗操作及结果保存整合到主函数中。执行时会先完成绘图和Pandas环境的基础配置,再加载原始昆明天气数据并做初步探查,随后按"去重→日期处理→天气类型简化→风力等级标准化→温度数据清洗"的顺序,依次完成全维度的数据规整,最后将处理后的数据集保存到指定路径,形成一套闭环的预处理流程。这种模块化的整合方式,既保证了预处理步骤的有序性,也让整个过程可复现、可调整,只需运行主函数就能完成从原始数据到可用数据集的全流程转换,且保存后的文件可直接用于后续的天气数据分析或建模工作。
python
def main():
# 环境设置
setup_environment()
# 数据加载
input_path = '../数据采集/data/昆明天气数据.csv'
df = load_data(input_path)
# 数据检查
inspect_data(df)
# 数据清洗流程
df = handle_duplicates(df)
df = process_dates(df)
df = simplify_weather_types(df)
df = simplify_wind_force(df)
df = process_temperatures(df)
# 保存清洗后的数据
output_dir = Path('./data')
output_dir.mkdir(parents=True, exist_ok=True)
output_path = output_dir / '昆明天气数据_清洗后.csv'
df.to_csv(output_path, index=False)
print(f"\n清洗后的数据已保存至:{output_path}")
if __name__ == "__main__":
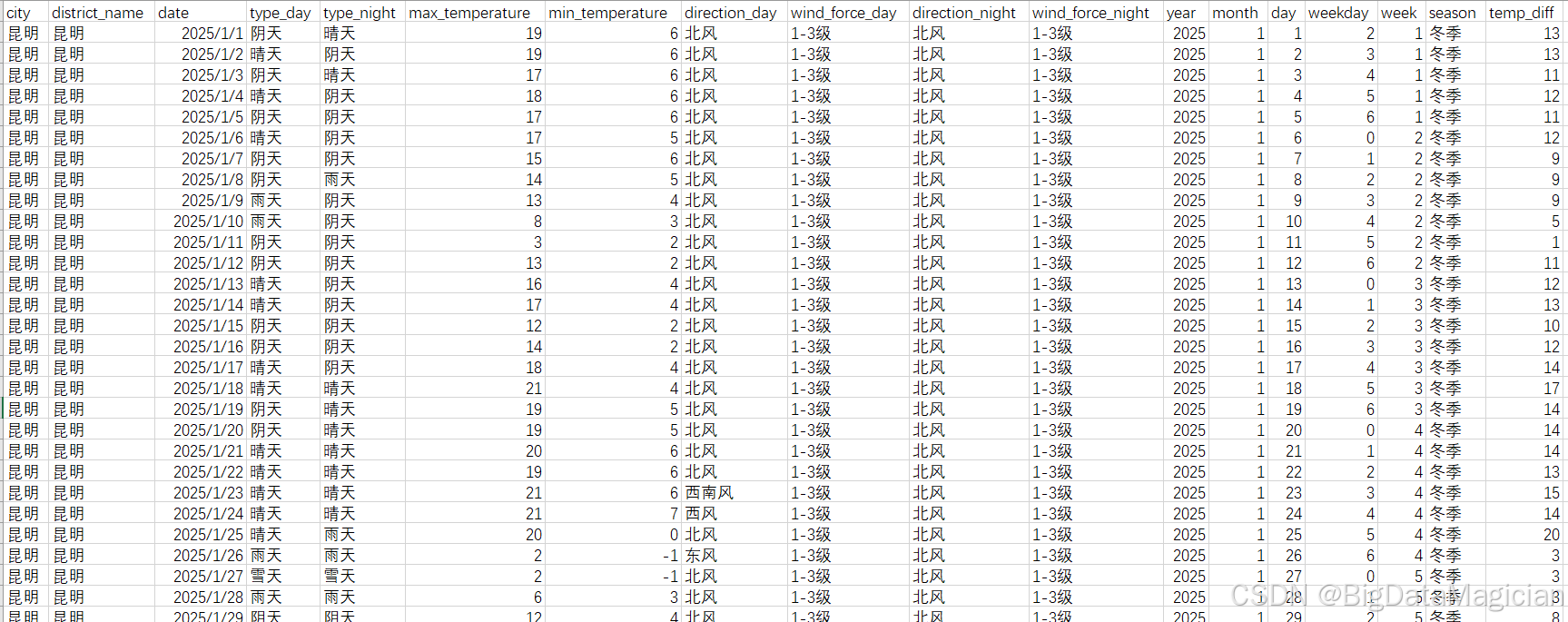
main()预处理后的部分数据如下图所示,处理后的数据集规整性显著提升,天气类型、风力等级完成标准化,温度去除单位转为纯数值;新增年、月、季节、温差等特征。数据保留核心信息且更易分析,可直接用于天气特征统计、时间维度分析等后续工作。
六、完整代码
python
from pathlib import Path
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# ----------------------------
# 配置设置
# ----------------------------
def setup_environment():
"""配置绘图和Pandas环境"""
# 设置中文正常显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 设置Pandas全局选项
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 50)
pd.set_option('display.expand_frame_repr', False)
# ----------------------------
# 数据加载与初步检查
# ----------------------------
def load_data(file_path):
"""加载数据并进行初步验证"""
try:
df = pd.read_csv(file_path)
print(f"成功加载数据,共 {df.shape[0]} 行,{df.shape[1]} 列")
return df
except FileNotFoundError:
raise FileNotFoundError(f"数据文件不存在: {file_path}")
except Exception as e:
raise Exception(f"加载数据出错: {str(e)}")
def inspect_data(df):
"""检查数据基本信息"""
print("\n=== 数据基本信息 ===")
df.info()
print("\n=== 离散特征唯一值统计 ===")
lisan_columns = [
'city', 'district_name', 'type_day', 'type_night',
'direction_day', 'wind_force_day', 'direction_night', 'wind_force_night'
]
for column in lisan_columns:
if column in df.columns:
unique_vals = df[column].unique()
print(f"{column}的唯一值有:{unique_vals},数量:{df[column].nunique()}")
else:
print(f"警告:列 {column} 不存在于数据中")
# ----------------------------
# 数据清洗函数
# ----------------------------
def handle_duplicates(df):
"""处理重复数据"""
duplicate_count = df.duplicated().sum()
print(f"\n重复值数量(处理前):{duplicate_count}")
if duplicate_count > 0:
df = df.drop_duplicates()
print(f"重复值数量(处理后):{df.duplicated().sum()}")
return df
def process_dates(df):
"""处理日期相关特征"""
# 日期转换
df['date'] = pd.to_datetime(df['date'], format='%Y年%m月%d日', errors='coerce')
# 检查日期转换错误
invalid_dates = df['date'].isna().sum()
if invalid_dates > 0:
print(f"警告:有 {invalid_dates} 条日期格式不正确")
# 提取日期特征
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday # 0-6
df['week'] = df['date'].dt.isocalendar().week
# 季节特征
def get_season(month):
if pd.isna(month):
return '未知'
if month in [3, 4, 5]:
return '春季'
elif month in [6, 7, 8]:
return '夏季'
elif month in [9, 10, 11]:
return '秋季'
else:
return '冬季'
df['season'] = df['month'].apply(get_season)
return df
def simplify_weather_types(df):
"""简化天气类型"""
# 使用集合提高查询效率
rain_set = {'小雨', '阵雨', '雨夹雪', '雷阵雨', '中雨', '大雨',
'小到中雨', '中到大雨', '暴雨', '小雨-中雨',
'大到暴雨', '中雨-大雨', '雷阵雨伴有冰雹'}
snow_set = {'小雪', '中雪', '阵雪', '小到中雪', '中到大雪', '零散阵雪'}
cloud_set = {'多云', '阴', '阴天'}
sunny_set = {'晴', '少云', '局部多云'}
fog_set = {'雾'}
def simple_weather_type(weather_type):
if pd.isna(weather_type):
return '未知'
elif weather_type in rain_set:
return '雨天'
elif weather_type in snow_set:
return '雪天'
elif weather_type in cloud_set:
return '阴天'
elif weather_type in sunny_set:
return '晴天'
elif weather_type in fog_set:
return '雾天'
else:
return '其他'
# 使用矢量化操作提高效率
df['type_day'] = df['type_day'].apply(simple_weather_type)
df['type_night'] = df['type_night'].apply(simple_weather_type)
return df
def simplify_wind_force(df):
"""简化风力等级"""
force_map = {
'1-2级': '1-3级',
'微风': '1-3级',
'微风级': '1-3级',
'≤3级': '1-3级',
'<3级': '1-3级',
'1-3级': '1-3级',
'3': '3-4级',
'4': '3-4级',
'3-4级级': '3-4级',
'3~4级': '3-4级',
'3-4级': '3-4级',
'4-5级': '4-5级',
'5-6级': '5-6级'
}
# 使用map方法更高效
df['wind_force_day'] = df['wind_force_day'].map(force_map).fillna('未知')
df['wind_force_night'] = df['wind_force_night'].map(force_map).fillna('未知')
return df
def process_temperatures(df):
"""处理温度数据"""
# 处理缺失值
print("\n缺失值情况(处理前):")
print(df[['max_temperature', 'min_temperature']].isnull().sum())
# 按区域、年、月向前填充缺失值
df['max_temperature'] = df.groupby(['district_name', 'year', 'month'])['max_temperature'].fillna(method='ffill')
df['min_temperature'] = df.groupby(['district_name', 'year', 'month'])['min_temperature'].fillna(method='ffill')
# 处理单位并转换为整数
def clean_unit(temperature):
if pd.isna(temperature):
return np.nan
try:
return int(str(temperature).replace('℃', ''))
except (ValueError, TypeError):
return np.nan
df['max_temperature'] = df['max_temperature'].apply(clean_unit)
df['min_temperature'] = df['min_temperature'].apply(clean_unit)
# 计算温差
df['temp_diff'] = df['max_temperature'] - df['min_temperature']
print("缺失值情况(处理后):")
print(df[['max_temperature', 'min_temperature', 'temp_diff']].isnull().sum())
return df
# ----------------------------
# 主函数
# ----------------------------
def main():
# 环境设置
setup_environment()
# 数据加载
input_path = '../数据采集/data/昆明天气数据.csv'
df = load_data(input_path)
# 数据检查
inspect_data(df)
# 数据清洗流程
df = handle_duplicates(df)
df = process_dates(df)
df = simplify_weather_types(df)
df = simplify_wind_force(df)
df = process_temperatures(df)
# 保存清洗后的数据
output_dir = Path('./data')
output_dir.mkdir(parents=True, exist_ok=True)
output_path = output_dir / '昆明天气数据_清洗后.csv'
df.to_csv(output_path, index=False)
print(f"\n清洗后的数据已保存至:{output_path}")
if __name__ == "__main__":
main()