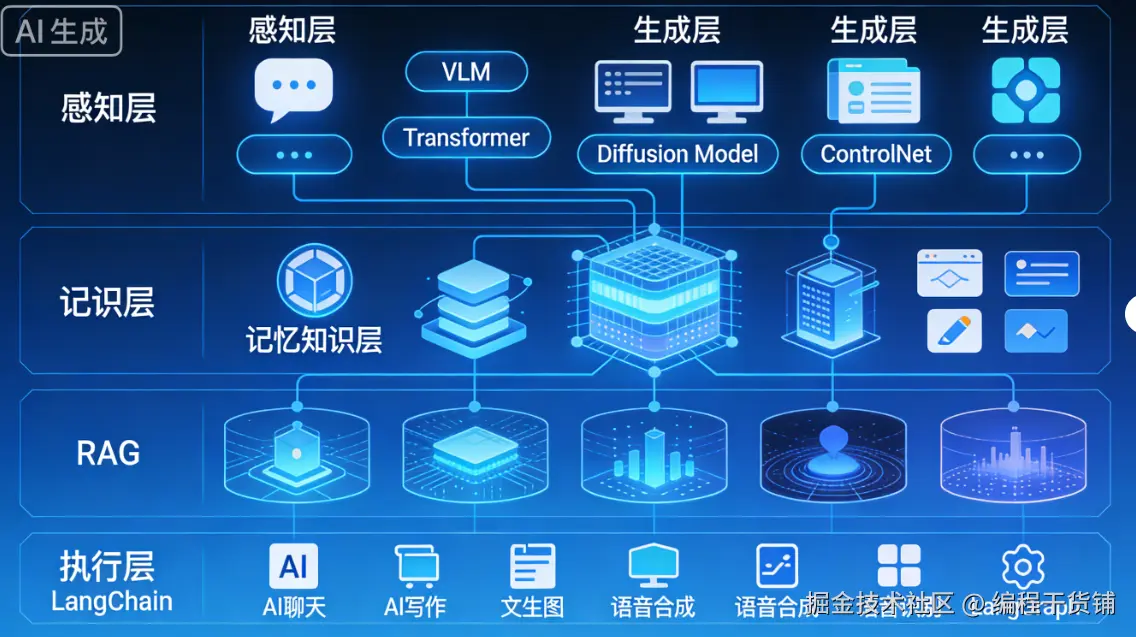
一、从"模型"到"Agent":AI 应用范式的根本变化
早期 AI 应用的核心是模型调用 :
输入 → 模型 → 输出。
但随着生成式 AI 能力爆发,问题开始变得复杂:
- 输入不再只是文本,而是图像、音频、视频、3D
- 输出不再是单一步骤,而是多阶段产物
- 任务不再是一次性生成,而是需要规划、校验、迭代
Multimodal Agent(多模态智能体) 正是在这种背景下出现的。
多模态 Agent ≠ 多模态模型
多模态 Agent = 能调度多模态模型完成复杂任务的系统
它是一种系统级 AI 形态,而不是某一个具体模型。
二、多模态 Agent 的"感知层":理解世界的能力来源
1. Vision-Language Model(VLM)
VLM 是多模态 Agent 的"眼睛和理解器" 。
它的核心能力是:
- 将图像 / 视频编码为语义向量
- 与文本语义空间对齐
- 支持跨模态推理与问答
典型能力包括:
- 图像内容理解(人物、物体、场景)
- 视频事件识别(动作、时序变化)
- 图文联合推理("这张图里的角色在做什么?")
在 Agent 系统中,VLM 通常用于:
- 多模态输入解析(Perceive 阶段)
- 多模态 RAG 的视觉检索
- 内容审核与场景理解
没有 VLM,多模态 Agent 就无法"看懂世界"。
2. Transformer:统一多模态建模的底层范式
Transformer 是几乎所有现代多模态模型的共同基础。
其关键优势在于:
- 自注意力机制,能处理长序列
- Token 化能力,支持不同模态统一建模
- 强大的上下文建模能力
在多模态领域的演化包括:
- 文生图:Diffusion Transformer(DiT)
- 文生视频:时空 Transformer
- 多模态理解:Unified Multimodal Transformer
可以说:
Transformer 解决了"如何把不同模态放在一个模型里思考"的问题。
三、多模态 Agent 的"生成层":内容创造的技术核心
3. Diffusion Model(扩散模型)
扩散模型是当前高质量生成的事实标准。
它的工作机制是:
- 从随机噪声开始
- 在条件(文本 / 图像 / 视频)约束下逐步去噪
- 生成结构稳定、细节丰富的内容
在多模态 Agent 中:
- 图像生成
- 视频生成
- 虚拟人生成
- 图像修复 / 超分
几乎都依赖扩散模型。
Agent 并不"生成内容",
Agent 是"决定什么时候、用什么方式、生成什么内容"。
4. ControlNet:生成可控性的关键组件
扩散模型强,但天然不可控。
ControlNet 的作用是:
- 将"结构约束"引入生成过程
- 控制生成内容的形状、姿态、布局
常见控制方式:
- Canny(边缘)
- Depth(深度)
- Pose(人体姿态)
- Scribble(草图)
在 Agent 场景中,ControlNet 用于:
- 品牌设计中保持布局一致
- 视频生成中保持人物动作一致
- 虚拟人中保持身份稳定
没有 ControlNet,生成结果很难进入商用。
四、三维与空间智能:多模态 Agent 的新边界
5. NeRF(神经辐射场)
NeRF 是 3D 生成的重要理论基础。
核心思想:
- 使用神经网络表示空间中每个点的颜色和密度
- 通过体渲染重建 3D 场景
优势:
- 几何精度高
- 真实感强
不足:
- 计算成本高
- 不适合实时渲染
在多模态 Agent 中,NeRF 更多用于:
- 理解 3D 生成原理
- 作为高精度重建基线
6. 3D Gaussian Splatting
这是 3D 生成工程化的重要突破。
相比 NeRF:
- 使用高斯点表示空间
- 渲染速度极快
- 更适合实时应用
在 Agent 系统中:
- 文生 3D
- 图生 3D
- 电商 3D 资产生成
几乎都优先选择 Gaussian Splatting 路线。
五、典型多模态生成任务范式
7. Text-to-Image(T2I)
T2I 是多模态生成的基础能力。
工程重点不在"能不能生成",而在:
- 风格是否可控
- 是否可复用
- 是否可规模化
因此通常需要:
- Prompt 工程
- ControlNet
- LoRA 风格微调
8. Text-to-Video(T2V)
T2V 的工程难点在于:
- 时间一致性
- 场景连贯性
- 长视频稳定性
Agent 通常采用:
- 脚本 → 分镜 → 片段生成 → 合成
而不是"一次生成一个完整视频"。
9. Text-to-3D(T23D)
T23D 的核心指标不是"好不好看",而是:
- 是否生成标准格式
- 是否可用于真实系统
Agent 会负责:
- 生成路径选择
- 参数控制
- 格式转换与优化
10. Text-to-Speech(TTS)
现代 TTS 已具备:
- 多角色
- 情感控制
- 零样本克隆
在多模态 Agent 中,TTS 是:
- 内容生产的最后一公里
- 视频 / 播客 / 虚拟人的关键组成
六、多模态 Agent 的"记忆与知识层"
11. Retrieval-Augmented Generation(RAG)
RAG 的本质是:
让 Agent 不只依赖参数记忆,而是可检索外部知识。
多模态 RAG 的扩展包括:
- 图像向量
- 视频向量
- 跨模态检索
这使 Agent 能:
- 查历史内容
- 做内容对比
- 做一致性校验
12. 向量数据库(Pinecone / Chroma / Milvus)
向量数据库是多模态 RAG 的基础设施。
作用包括:
- 存储多模态 embedding
- 支持相似度搜索
- 支撑大规模知识库
七、Agent 的"大脑":规划与执行范式
13. Chain of Thought(CoT)
CoT 是 Agent 的基础推理能力:
- 将复杂任务拆解为步骤
- 提升规划质量
14. Inner Monologue
Inner Monologue 是更高级的推理:
- 用于自检
- 用于质量控制
- 用于结果修正
15. Perceive → Plan → Execute
这是多模态 Agent 的标准架构:
- Perceive:理解多模态输入(VLM)
- Plan:生成执行策略(LLM)
- Execute:调度工具(生成 / 检索 / 校验)
八、Agent 的工程化执行层
16. LangChain
LangChain 解决的是:
- 工具如何被 Agent 调用
- 模型如何被统一封装
它是 Agent 的"工具层"。
17. LangGraph
LangGraph 解决的是:
- 多步骤任务如何可靠执行
- 状态如何流转
- 如何处理失败与重试
它是生产级 Agent 的核心。
18. LangSmith
LangSmith 用于:
- 观察 Agent 执行路径
- 调试推理过程
- 提升系统稳定性
九、部署、性能与规模化
19. vLLM
vLLM 解决推理性能问题:
- 高吞吐
- 低延迟
- 高并发
20. FastAPI
FastAPI 用于:
- 服务化模型与 Agent
- 统一接口层
- 支撑前端与外部调用
21. Docker
Docker 保证:
- 环境一致
- 可复制部署
- 云端可扩展
22. Task Queue(任务队列)
任务队列是多模态 Agent 能规模化的前提:
- GPU 调度
- 并发控制
- 长任务管理
十、平台化与商业化能力
23. SaaS 与 Multi-Tenant
当 Agent 成为平台时,必须支持:
- 多用户
- 资源隔离
- 计费与限流
24. Digital Human(虚拟人)
虚拟人是多模态 Agent 的综合应用:
- 图像 + 视频 + TTS + 驱动
- 是系统集成能力的集中体现
25. Content Moderation
内容审核是多模态 Agent 的典型企业场景:
- VLM + RAG + 规则策略
- 实现规模化审核与风险控制
结语:多模态 Agent 是系统工程,不是模型堆叠
真正成熟的多模态 Agent,不是:
- 用了多少模型
- 接了多少 API
而是:
- 能否稳定执行复杂任务
- 能否控制生成质量
- 能否规模化部署
- 能否形成商业闭环
模型决定能力上限,
Agent 架构与工程能力决定落地成败。