前言:
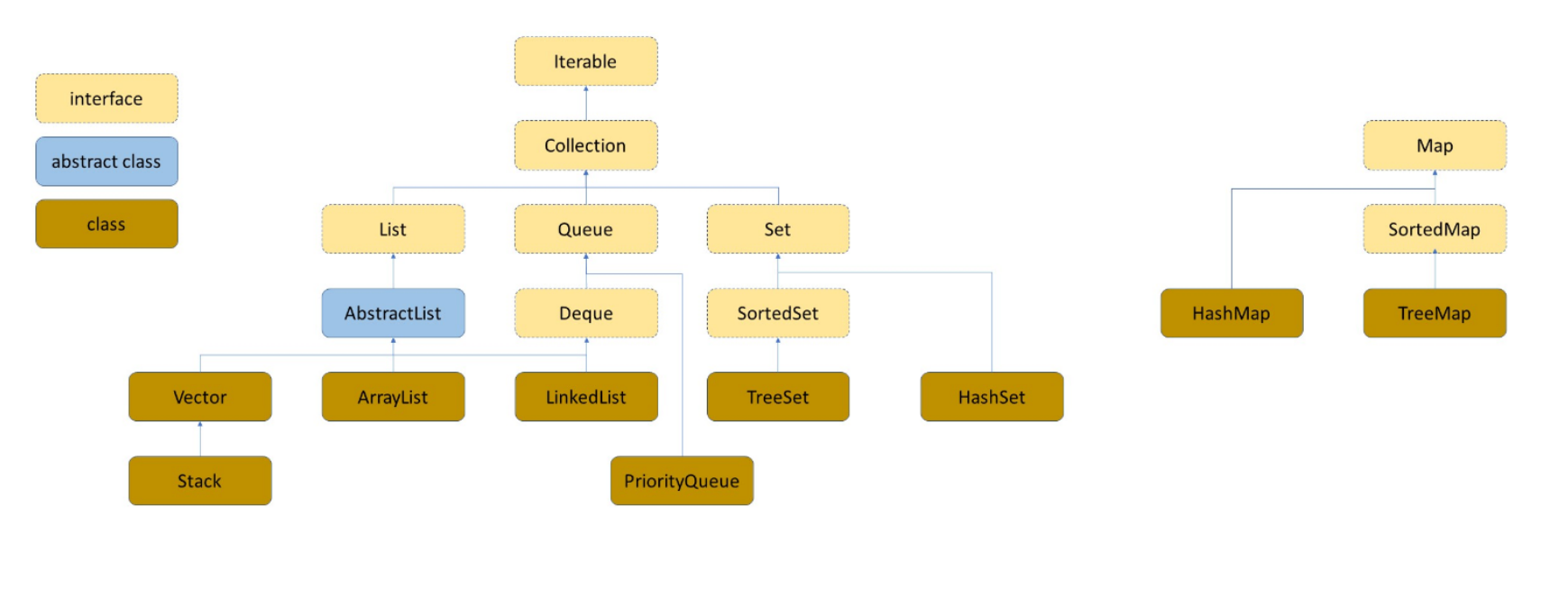
(本章默认大家认识TreeMap和TreeSet,如果不认识可以先去了解二叉搜索树,这两个类的底层就是二叉搜索树。 HashMap和HashSet的底层是哈希表(Hash),下面会讲)
(其实Tree...的底层具体说应该是红黑树,红黑树是特殊的二叉搜索树,新手认为底层是二叉就行)
Map和Set是两个接口,它们两个互不相关。
继承了Map 接口的两个重要类是HashMap 、TreeMap;
继承了Set 接口的两个重要类是HashSet 、TreeSet;
一.Map的说明
Map是一个没有继承Collection的接口,它是以**<K,V>结构的键值对**来存储数据的,并且K是唯一的,不能重复出现。
1.1常用方法
|--------------------------------------------|--------------------------------|
| 方法 | 解释 |
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value |
| V remove(Object key) | 删除 key 对应的映射关系 |
| Set<K> keySet() | 返回所有 key 的不重复集合 |
| Collection<V> values() | 返回所有 value 的可重复集合 |
| Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
注意:
- Map是一个接口,不能直接实例化对象,但要进行实例化对象只能实例化实现了Map接口的类TreeMap或HashMap
- Map中存放键值对的key是唯一的,value是可重复的
- 在TreeMap中插入键值对时,key不能为空,否则就会抛出NullPointerException异常,(且key要能够进行比较)但value可以为空。但是HashMap的key和value都能为空。
- Map中可以通过keySet()获取全部key,存储到Set中来进行访问(因为键不能重复)
- 也可以将Map中的value全部分离出来,存储到Collection的任何一个子集合中。
- 特别强调注意区别TreeMap和HashMap
1.2Map方法演示
代码下面有运行后的图片
java
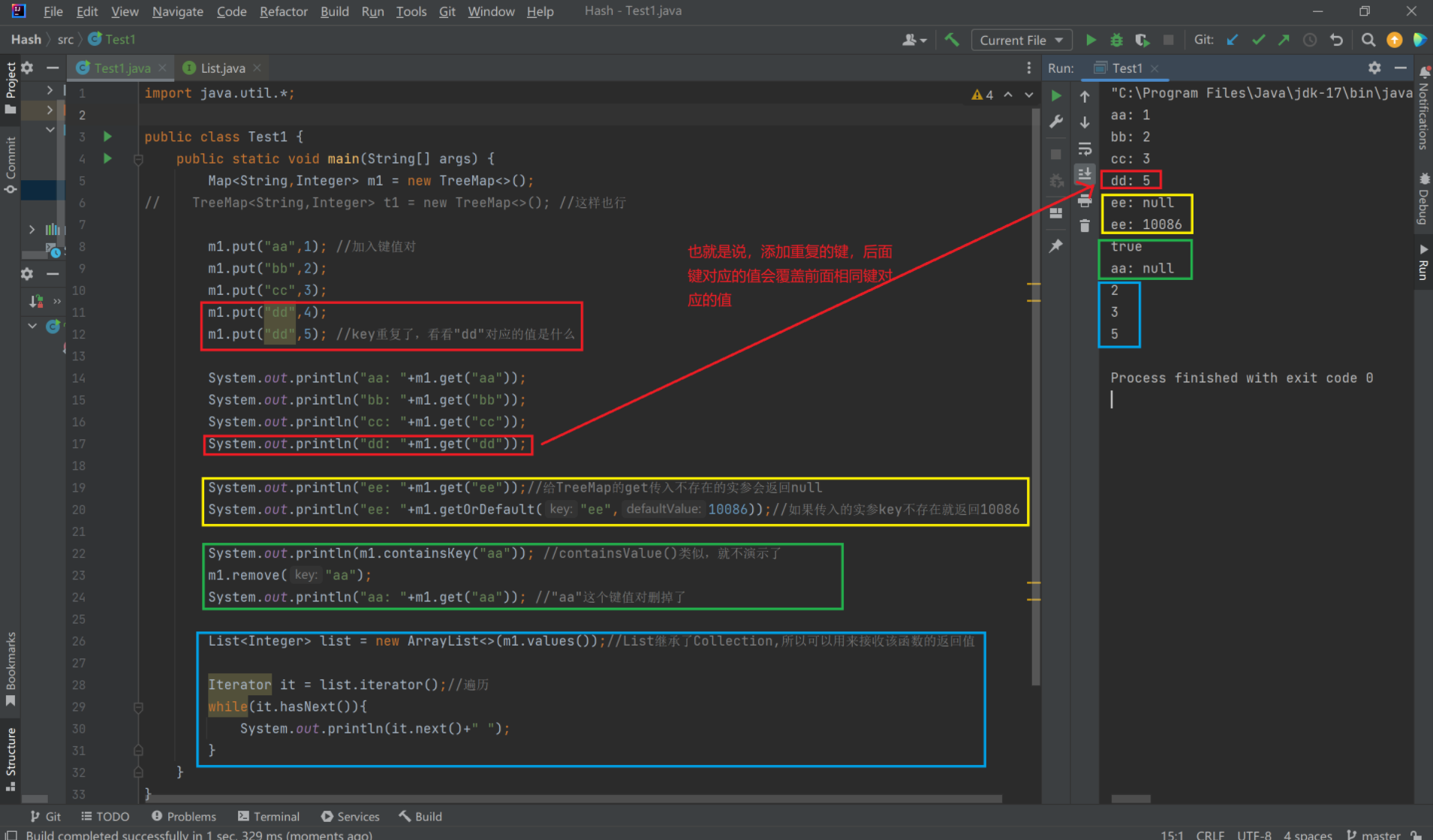
public static void main(String[] args) {
Map<String,Integer> m1 = new TreeMap<>();
// TreeMap<String,Integer> t1 = new TreeMap<>(); //这样也行
m1.put("aa",1); //加入键值对
m1.put("bb",2);
m1.put("cc",3);
m1.put("dd",4);
m1.put("dd",5); //key重复了,看看"dd"对应的值是什么
System.out.println("aa: "+m1.get("aa"));
System.out.println("bb: "+m1.get("bb"));
System.out.println("cc: "+m1.get("cc"));
System.out.println("dd: "+m1.get("dd"));
System.out.println("ee: "+m1.get("ee"));//给TreeMap的get传入不存在的实参会返回null
System.out.println("ee: "+m1.getOrDefault("ee",10086));//如果传入的实参key不存在就返回10086
System.out.println(m1.containsKey("aa")); //containsValue()类似,就不演示了
m1.remove("aa");
System.out.println("aa: "+m1.get("aa")); //"aa"这个键值对删掉了
List<Integer> list = new ArrayList<>(m1.values());//List继承了Collection,所以可以用来接收该函数的返回值
Iterator it = list.iterator();//遍历
while(it.hasNext()){
System.out.println(it.next()+" ");
}
}实例化TreeMap的运行图片、实例化HashMap运行出来的也一样,大家可以试试。
entrySet()在1.4演示,keySet()在2.2结束后演示!!
1.3Map.Entry<K,V>的说明
Entry是Map中定义的内部接口。Map.Entry<K,V>的用途是存放<key,value>键值对的映射关系(因为key是唯一的,每个键都对应一个值),该接口还定义了键、值和键值对<K,V>的获取,和Key的比较方法。
常用方法:
|---------------------|----------------|
| 方法 | 解释 |
| K getKey() | 返回entry中的key |
| V getValue() | 返回entry中的value |
| V setValue(V value) | 将键值对中的值赋为value |
注意:Map.Entry<K,V>中没有提供设置key的方法。
1.4Map.Entry<K,V>方法演示
java
public static void main(String[] args) {
Map<String,Integer> m1 = new HashMap<>();
m1.put("星期一",1);
m1.put("星期二",2);
m1.put("星期三",3);
m1.put("星期四",4);
m1.put("星期五",5);
Set<Map.Entry<String,Integer>> set = m1.entrySet(); //entrySet返回的是Set类型的键值对集合
//当然不接收返回值直接for(Map.Entry<String,Integer> e : m1.entrySet){}也一样
for(Map.Entry<String,Integer> e : set){
System.out.print("键:"+e.getKey()+" "); //返回e的键
System.out.print("值:"+e.getValue()+" ");
e.setValue(6);//修改e的value
System.out.println("修改后的值:"+e.getValue()+" ");
}
}运行效果: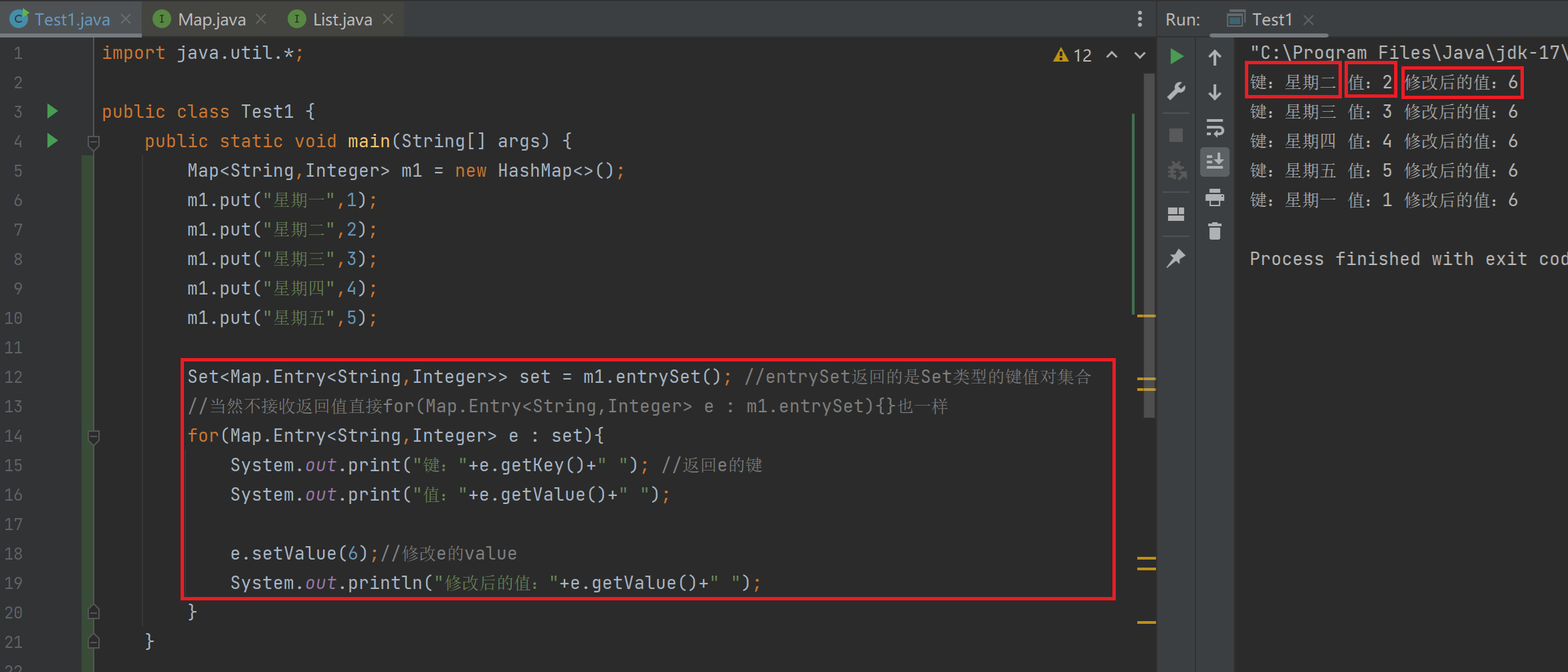
二.Set的说明
Set接口继承了Collection;Set只存储键(key)。
虽然Set与Map没什么关系,但是TreeSet和HashMap的底层是Map,2.1有讲解。
2.1常见方法
|--------------------------------------------|--------------------------------------|
| 方法 | 解释 |
| boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断 o 是否在集合中 |
| Iterator<E> iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object\[\] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回false |
| boolean addAll(Collection<? extendsE> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
TreeMap的底层:
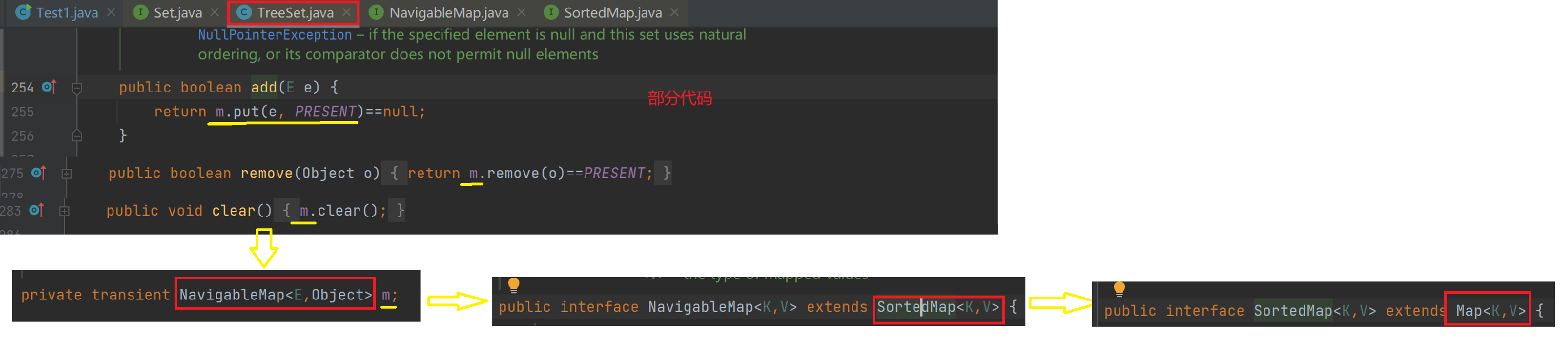
可以看到add()等方法其实是依靠Map存储值的。
那我们继续想,既然TreeSet的底层是Map那我们在只存储key的情况下key对应的值由什么充当的?
注意:
- Set是继承自Collection的一个接口类
- Set中只储存了key,并且要求key唯一
- TreeSet、HashMap的底层是 使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中
- Set最大功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet 和HashMap,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入顺序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再从新插入
- TreeSet中不能插入null的key,HashSet可以。
- TreeSet和HashMap的区别(会在讲Hash(哈希表)时讲解)
2.2Set方法演示
部分函数演示
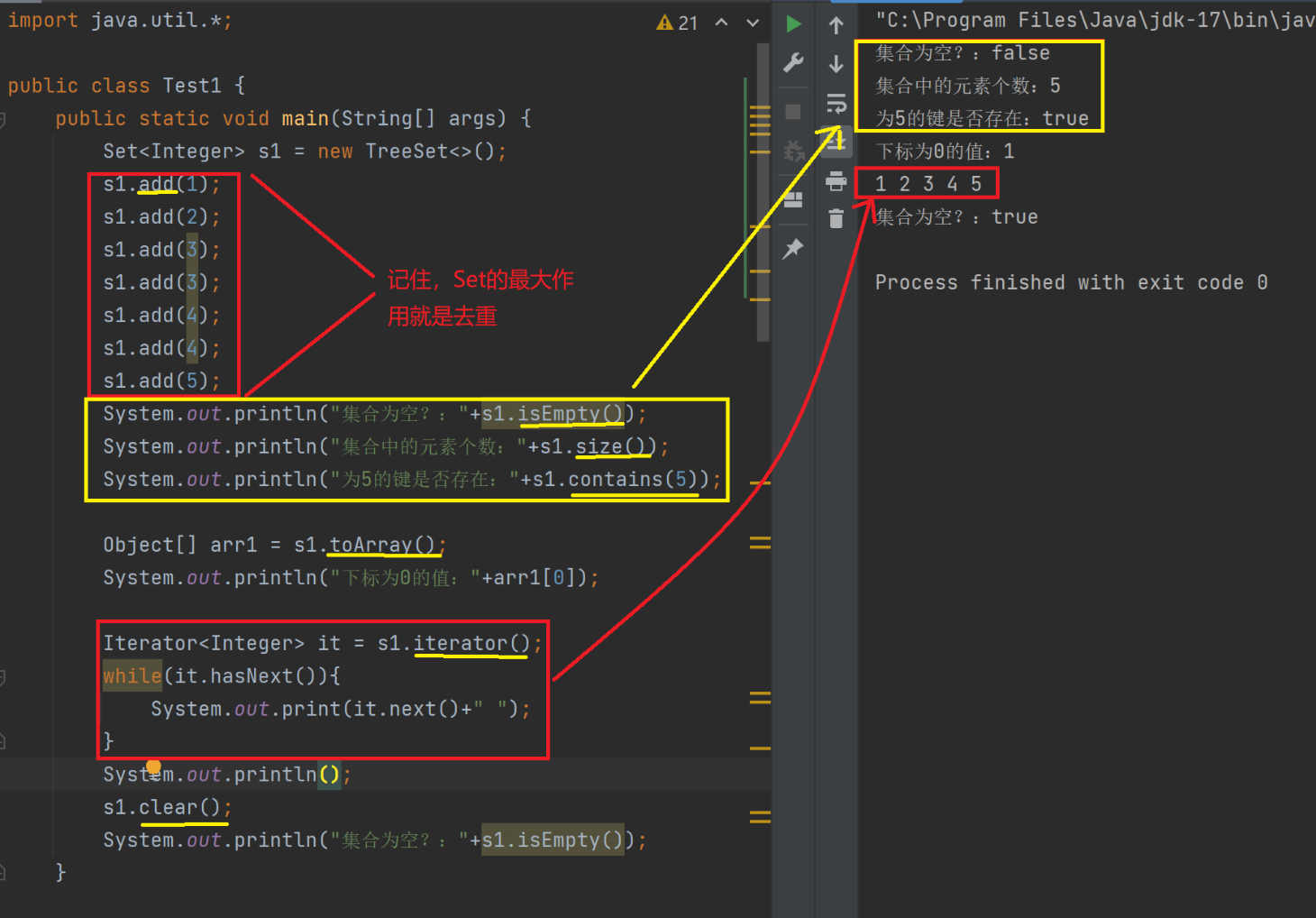
keySet()说明:
和这个函数就是把Map中的key值装换为Set类型而已。
java
public static void main(String[] args) {
Map<String,Integer> m1 = new HashMap<>();
m1.put("星期一",1);
m1.put("星期二",2);
m1.put("星期三",3);
m1.put("星期四",4);
m1.put("星期五",5);
Set<String> ks = m1.keySet();
ks.add("星期六");
}三.哈希表(Hash)的说明
哈希表查找元素的时间复杂是O(1),二叉搜索树则要O(logn)。
3.1哈希表的底层
哈希表的底层是数组与链表的组合。
通过HashMap或HashSet对象插入数据时,要经过hashCode() 处理返回哈希值 ,然后通过哈希函数与哈希值确定传递的值放入哈希表(数组)的什么位置。
首先我们来看一个哈希函数,hash(key)=key%capacity(key代表哈希值,capacity代表数组容量)。图形展示:
java
public void push(K key,V val){
int hashcode = key.hashCode();
int index = hashcode % array.length;
//判断key是否存在,存在则更新val,否则在对应下标进行插入
//若插入的节点超过数组容量的75%(这个百分数是负载因子),发生扩容,扩容的目的是降低冲突率(多个节点存放在同一个下标位置)
}hashCode()是Object类的函数,所有的类都继承与它所以大家都可以用。
接着底层示例:
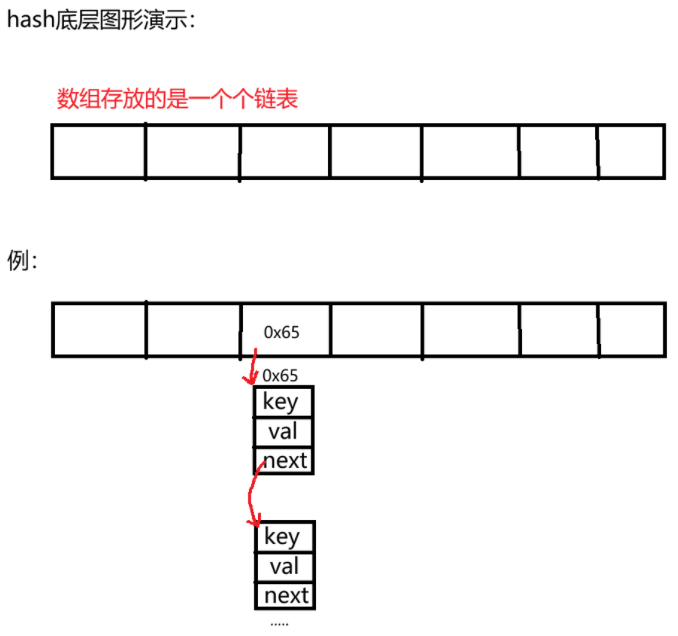
举个例子:插入的key数量大于数组元素的75%(hash默认的负载因子),数组就会自动扩容,扩容后节点存放所在地址会发生什么变化?例:
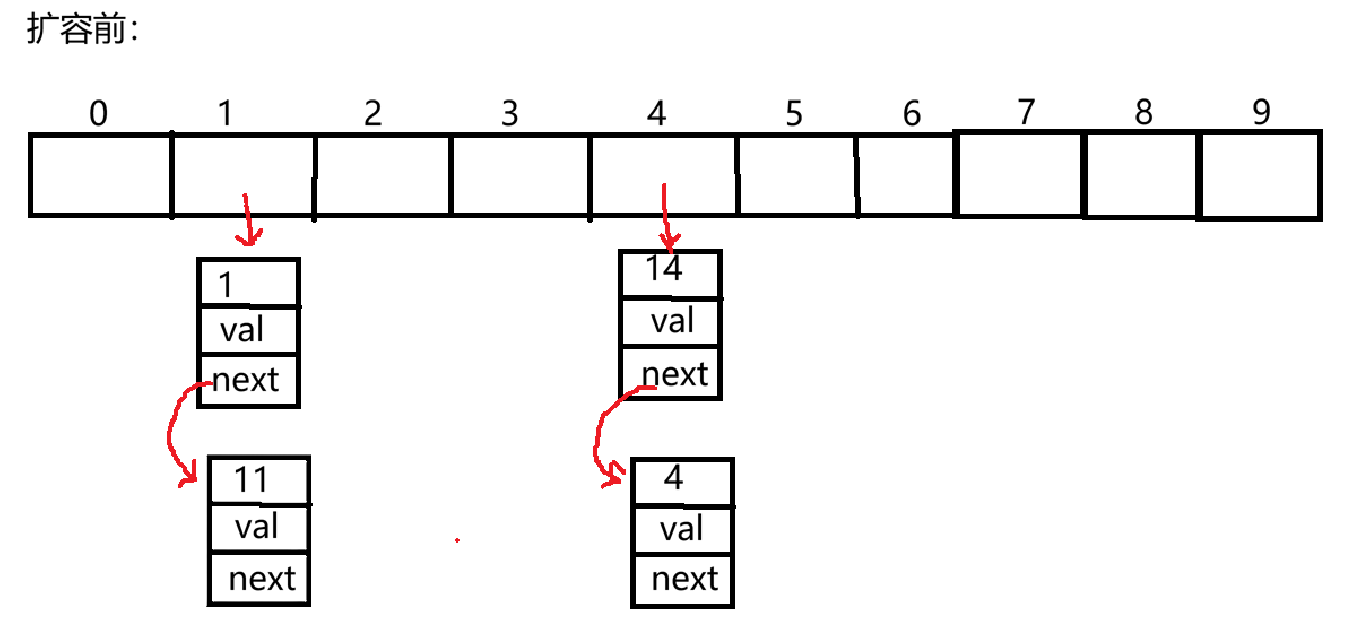
扩容前节点的存放坐标是通过int index = key%array.length(1%10,11%10,14%10),Node cur=arrayindex,后遍历,进行尾插;
扩容(array.length*2)以后则根据哈希函数重新分布节点所在位置,1%20,11%20。
但是哈希表并不一直是数组和链表的组合,当某一链表长度大于8并且数组长度大于64 ,哈希表就会树化。
3.2HashMap和HashSet常用方法
它俩常用的方法也和上面一样。着急拓展的话可以查查文档学习。
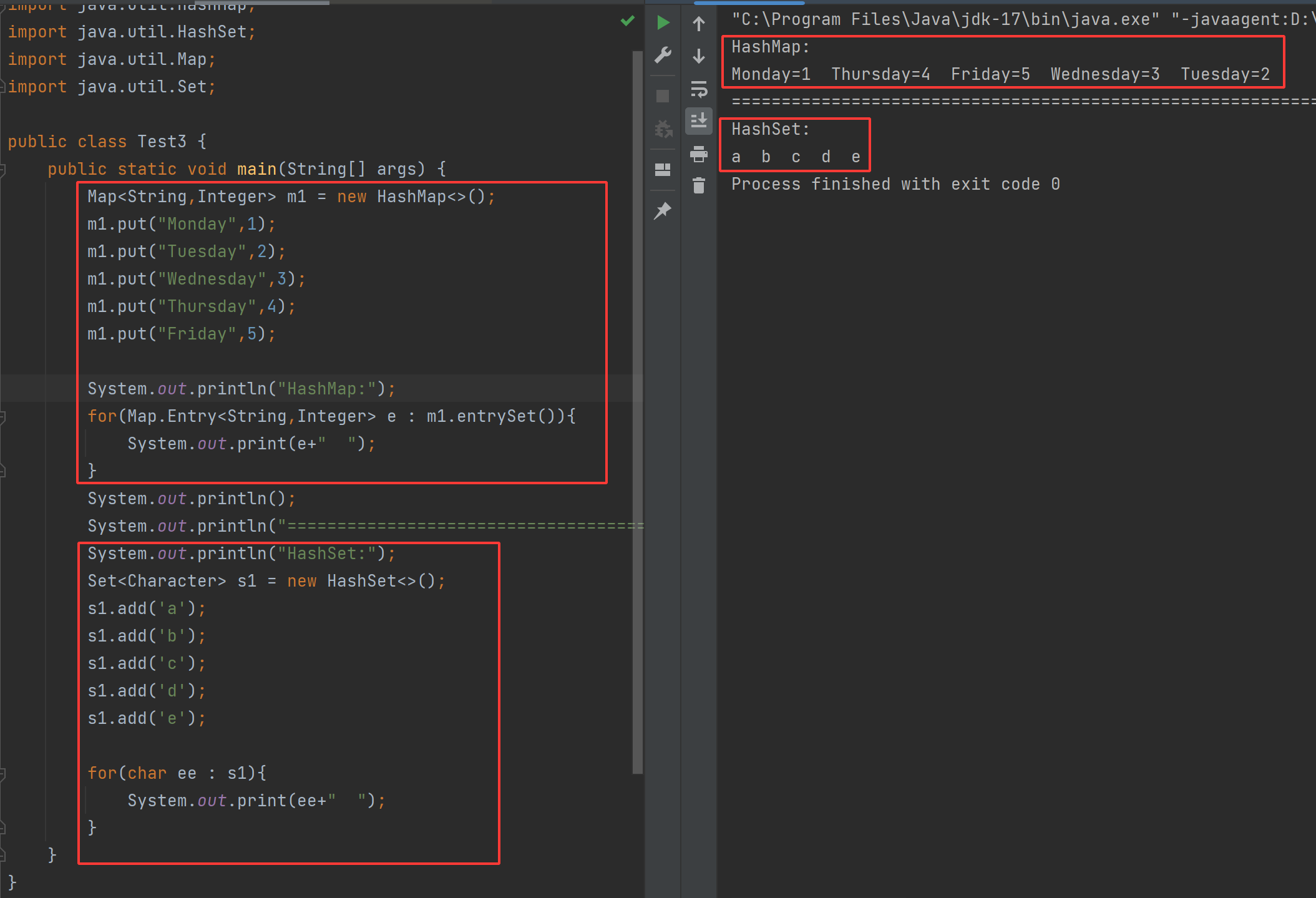
java
public static void main(String[] args) {
Map<String,Integer> m1 = new HashMap<>();
m1.put("Monday",1);
m1.put("Tuesday",2);
m1.put("Wednesday",3);
m1.put("Thursday",4);
m1.put("Friday",5);
System.out.println("HashMap:");
for(Map.Entry<String,Integer> e : m1.entrySet()){
System.out.print(e+" ");
}
System.out.println();
System.out.println("==================================================================");
System.out.println("HashSet:");
Set<Character> s1 = new HashSet<>();
s1.add('a');
s1.add('b');
s1.add('c');
s1.add('d');
s1.add('e');
for(char ee : s1){
System.out.print(ee+" ");
}
}