文章目录
摘要
本周主要阅读了风格迁移方面的三篇论文,内容涉及场景文字编辑、文本驱动风格迁移以及内容与风格组合的图像生成方法。三篇论文分别从文字编辑、文本驱动风格迁移和内容-风格组合三个角度推进了风格迁移领域的发展,在保持内容结构的同时,实现了更精准、多样和高质量的风格化图像生成。
Abstract
This week, I mainly read three papers on style transfer, covering scene text editing, text-driven style transfer, and image generation methods combining content and style. The three papers advance the field of style transfer from the perspectives of text editing, text-driven style transfer, and content-style combination, achieving more precise, diverse, and high-quality stylized image generation while preserving content structure.
1.1 场景文字编辑
论文是来自哈工大的Zhengyao Fang等人,论文题目是Recognition-Synergistic Scene Text Editing。
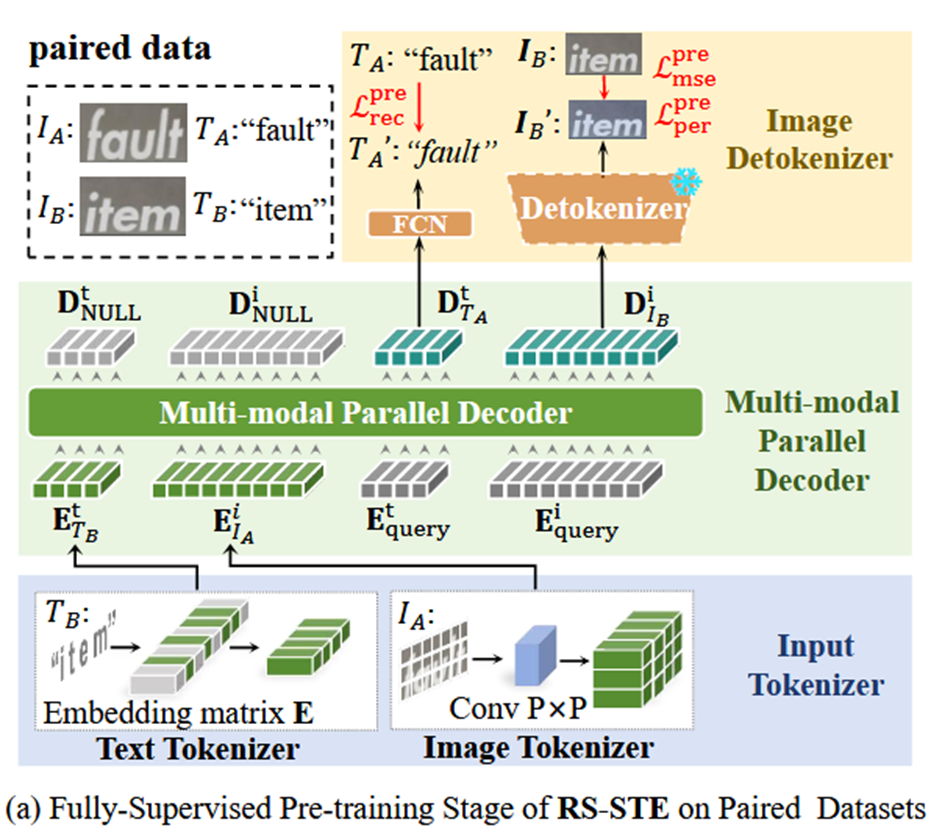
RS-STE,提出一种新的架构,在一个框架内统一进行文本内容识别和内容编辑。
Input Tokenizer:输入编码器,编码目标文本 𝑇 𝐵 𝑇_𝐵 TB和参考图像 𝐼 A 𝐼_A IA,对图片采用类似ViT的编码,通过大小为P的卷积核进行卷积,图片就会变成 𝐻 𝑃 × 𝑊 𝑃 \frac{𝐻}{𝑃}×\frac{𝑊}{𝑃} PH×PW个patch,然后通过Embedding层 ( 𝑁 × 𝐶 ) (𝑁×𝐶) (N×C)编码。
Multi-modal Parallel Decoder:多模态并行解码器,一个标准的Transformer解码器, 𝐿 + 𝑁 𝐿+𝑁 L+N个输出丢弃,后𝐿个输出 𝐷 𝑇 𝐴 𝑡 𝐷_{𝑇_𝐴}^𝑡 DTAt用于文本识别,后𝑁个输出 𝐷 𝐼 𝐵 𝑖 𝐷_{𝐼_𝐵}^𝑖 DIBi用于图像生成。
Image Detokenizer:图像解码器, 𝐷 𝐼 𝐵 𝑖 𝐷_{𝐼_𝐵}^𝑖 DIBi送入解码器,重建最终的编辑图像。
循环自监督训练
改进训练方式,第一次图像文本编辑,给定一个参考图像 𝐼 𝐴 𝐼_𝐴 IA和目标文本 𝑇 𝐵 𝑇_𝐵 TB,RS-STE生成编辑图像 𝐼 𝐵 ′ 𝐼_𝐵^′ IB′和检测的文本𝑇_𝐴\^′ 。
然后采用RS-STE进行二次编辑,得到编辑图像 𝐼 𝐴 ′ 𝐼_𝐴^′ IA′和识别文本 𝑇 𝐵 ′ 𝑇_𝐵^′ TB′,这个 𝐼 𝐴 ′ 𝐼_𝐴^′ IA′应该是初始参考图像的再现。
1.2 风格迁移
论文是来自西湖大学的Mingkun Lei等人,论文题目是StyleStudio: Text-Driven Style Transfer with Selective Control of Style Elements
改进一: 𝐴 𝑑 𝑎 𝐼 𝑁 ( 𝑥 , 𝑦 ) = σ ( 𝑦 ) ( 𝑥 − μ ( 𝑥 ) ) σ ( 𝑥 ) + μ ( 𝑦 ) 𝐴𝑑𝑎𝐼𝑁(𝑥,𝑦)=\frac{\sigma(𝑦)(𝑥−\mu(𝑥))}{\sigma(𝑥) +\mu(𝑦)} AdaIN(x,y)=σ(x)+μ(y)σ(y)(x−μ(x))对x进行实例归一化,对y计算标准差和均值,然后进行仿射变换,可以将风格融入内容图片。通过Unet的注意力层得到文本和风格图像的两个独立的特征图。
然后将两个特征图经过AdaIN合并
f a f ^ = λ 𝑠 𝑡 𝑦 𝑙 𝑒 ( 𝑓 𝑡 𝑒 𝑥 𝑡 − μ 𝑡 𝑒 𝑥 𝑡 ) σ 𝑡 𝑒 𝑥 𝑡 + β 𝑠 𝑡 𝑦 𝑙 𝑒 \hat{f_{af}}=\frac{\lambda_{𝑠𝑡𝑦𝑙𝑒} (𝑓_{𝑡𝑒𝑥𝑡}−\mu_{𝑡𝑒𝑥𝑡})}{\sigma_{𝑡𝑒𝑥𝑡} }+\beta_{𝑠𝑡𝑦𝑙𝑒} faf^=σtextλstyle(ftext−μtext)+βstyle
把风格特征融合到文本特征里
改进二:布局和教师模型,在初始时间步替换所有Unet层的注意力图,早期的注意力图是为了决定整体的构图、布局,后期的注意力图是为了细化细节,后期不替换注意力图可以保留风格细节。教师模型:原始的文本到图像扩散模型(如 SDXL 或 Stable Diffusion),未经过任何风格适配器(adapter)修改。它不接收风格图像输入,只使用原始文本提示进行标准图像生成。
借用原始T2I模型在早期去噪阶段产生的 Self-Attention Maps(自注意力图)来"指导"风格化模型的空间布局。
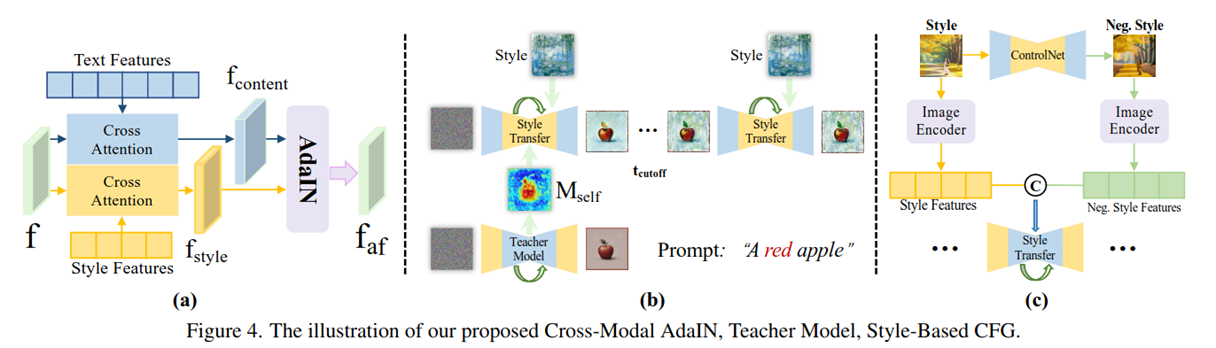
改进三:基于风格的无分类器引导,一张图片有多种风格,多种风格的影响会导致图片出现歧义。
ε ^ θ ( 𝑧 𝑡 , 𝑡 , 𝑦 ) = ( 1 + ω ) ε θ ( 𝑧 𝑡 , 𝑡 , 𝑦 𝑐 𝑜 𝑛 𝑑 ) − ω ⋅ ε ( 𝑧 𝑡 , 𝑡 , 𝑦 𝑛 𝑒 𝑔 ) \hat{\varepsilon}{\theta(𝑧_𝑡,𝑡,𝑦)} =(1+\omega)\varepsilon{\theta(𝑧_𝑡,𝑡,𝑦_{𝑐𝑜𝑛𝑑})} −\omega\cdot \varepsilon(𝑧_𝑡,𝑡,𝑦_{𝑛𝑒𝑔}) ε^θ(zt,t,y)=(1+ω)εθ(zt,t,ycond)−ω⋅ε(zt,t,yneg)
w用于平衡正负条件的权重,负样本可以指定为模糊的/人造的物品.

改进三:基于风格的无分类器引导,通过ControlNet生成一个只有参考图像的结构但是没有风格的图像作为负样本.
ε ^ θ ( 𝑧 𝑡 , 𝑡 , 𝑦 ) = ( 1 + ω ) ⋅ ε θ ( 𝑧 𝑡 , 𝑦 𝑐 𝑜 𝑛 𝑑 𝑡 𝑒 𝑥 𝑡 , 𝑦 𝑐 𝑜 𝑛 𝑑 𝑠 𝑡 𝑦 𝑙 𝑒 ) − ω ⋅ ε θ ( 𝑧 𝑡 , 𝑦 𝑛 𝑒 𝑔 𝑡 𝑒 𝑥 𝑡 , 𝑦 𝑛 𝑒 𝑔 𝑠 𝑡 𝑦 𝑙 𝑒 ) \hat{\varepsilon}{\theta(𝑧_𝑡,𝑡,𝑦)} =(1+\omega)\cdot \varepsilon{\theta} (𝑧_𝑡,𝑦_{𝑐𝑜𝑛𝑑}^{𝑡𝑒𝑥𝑡},𝑦_{𝑐𝑜𝑛𝑑}^{𝑠𝑡𝑦𝑙𝑒})−\omega \cdot \varepsilon_{\theta} (𝑧_𝑡,𝑦_{𝑛𝑒𝑔}^{𝑡𝑒𝑥𝑡},𝑦_{𝑛𝑒𝑔}^{𝑠𝑡𝑦𝑙𝑒}) ε^θ(zt,t,y)=(1+ω)⋅εθ(zt,ycondtext,ycondstyle)−ω⋅εθ(zt,ynegtext,ynegstyle)

1.3 CSGO
论文是来自南京理工大学的Peng Xing等人,论文题目是CSGO: CONTENT-STYLE COMPOSITION IN TEXT-TOIMAGE GENERATION
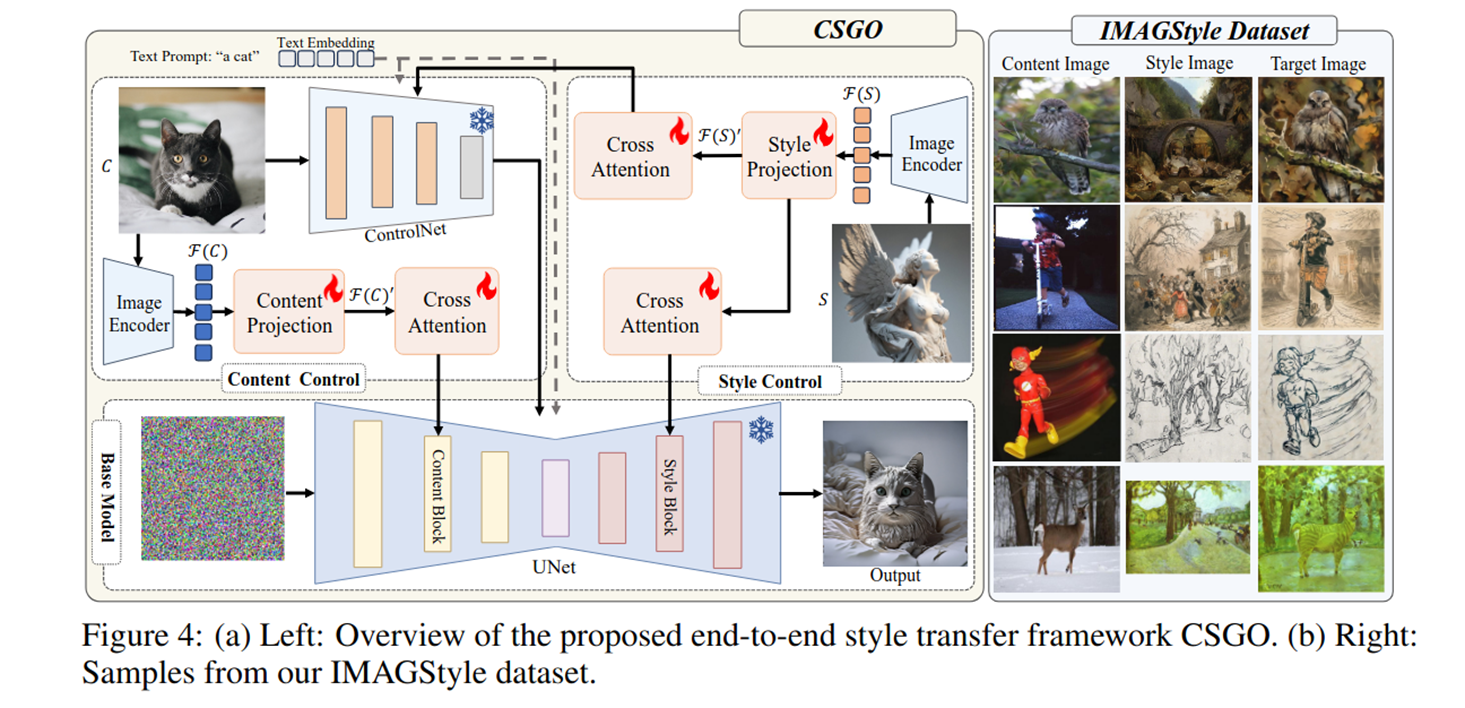
论文合成了一个210k图像的风格迁移数据集。
内容图像(Content Images):
来源:MSRA10K、MSRA-B(显著性检测数据集),共约 11,000 张。主体清晰、语义明确,便于保留内容结构。额外加入 1,000 张 ImageNet-Sketch 草图用于草图风格迁移。每张图用 BLIP 生成文本描述(caption)。
风格图像(Style Images):
来源:WikiArt(5,000 张,涵盖历史绘画、肖像、风景等);Midjourney 生成(5,000 张,覆盖古典、现代、抽象、未来主义等多样风格)。共 10,000 张风格图。
为每张图训练独立 LoRA
对每张内容图 C,单独微调一个 LoRA(仅用该图训练),得到 C L o R A C_{LoRA} CLoRA。
对每张风格图 S,单独微调一个 LoRA,得到 S L o R A S_{LoRA} SLoRA。
B-LoRA(Frenkel et al., 2024)发现,SD 微调后的 LoRA 可隐式解耦为 content LoRA 和 style LoRA。
组合 LoRA 生成候选风格化图像, C c o n t e n t L o R A C_{content_{LoRA}} CcontentLoRA(从 C L o R A C_{LoRA} CLoRA分离出的内容部分)与 S s t y l e L o R A S_{style_{LoRA}} SstyleLoRA(从 S L o R A S_{LoRA} SLoRA分离出的风格部分)。
使用组合后的 LoRA + SDXL 生成 n 张候选图像 T 1 , T 2 , . . . , T n {T_1, T_2, ..., T_n} T1,T2,...,Tn。
提出了一个CSGO模型用于端到端训练风格迁移的图像。
内容图片与风格图片经过ControlNet得到一个带风格痕迹的布局结构图,然后内容图片的特征和布局图片输入到Unet中指导模型的去噪,风格特征在生成过程中又引导模型生成风格照片。
总结
本周主要对一些感兴趣方向的论文进行了阅读,从中获取一些应用方向、创新点的启发,为以后的科研提供方向。