技术文章大纲:文件内容批量替换自动化测试脚本
引言
- 批量替换文件内容的需求背景(如测试数据生成、配置更新等)
- 自动化测试脚本在批量替换中的作用
- 本文的目标读者(测试工程师、开发人员、DevOps)
文件内容批量替换的核心技术
- 正则表达式在文本匹配与替换中的应用
- 文件读写操作(Python/Shell等语言的实现方式)
- 递归遍历目录结构的实现方法
自动化测试脚本设计思路
- 输入参数设计(目标目录、匹配模式、替换内容)
- 异常处理机制(文件权限、编码问题等)
- 日志记录与结果验证
脚本实现示例(Python)
python
import os
import re
def batch_replace(directory, pattern, replacement):
for root, _, files in os.walk(directory):
for file in files:
file_path = os.path.join(root, file)
try:
with open(file_path, 'r+', encoding='utf-8') as f:
content = f.read()
new_content = re.sub(pattern, replacement, content)
f.seek(0)
f.write(new_content)
f.truncate()
except Exception as e:
print(f"Error processing {file_path}: {e}")案例示例(Python)
如SDK源文件中的版权声明更新脚本:功能与实现步骤总结
一、核心实现功能
- 定向文件处理 :仅扫描并处理目标目录下的
.c和.h后缀文件,自动跳过.txt、.py等其他格式文件及脚本自身。 - 精准文本替换:将文件中特定的旧版权声明块(2021年版本)完整替换为新的 Apache License 2.0 协议声明(2025年版本),严格保留文件其余内容不变。
- 双渠道日志记录 :日志同时输出到终端(实时查看进度)和
logs目录下的时间戳日志文件(持久化追溯),日志内容包含步骤详情、成功/失败原因。 - 自动化目录管理 :自动创建
processed目录(存放处理后文件)和logs目录(存放日志),无需手动配置。 - 全流程结果追踪:记录所有文件的处理状态,区分"成功替换""未找到旧版权""非目标文件"等场景,输出清晰的汇总报告。
- 内置功能验证:运行前自动执行测试用例,通过模拟不同类型文件的处理场景,验证替换逻辑和过滤规则的有效性。
二、主要实现步骤
-
初始化配置与日志
- 定义核心参数(旧/新版权文本、目标目录、允许的文件后缀等)。
- 配置日志系统,设置终端+文件双输出,生成带时间戳的日志文件。
- 自动创建
processed和logs目录,确保输出路径有效。
-
文件筛选与前置检查
- 遍历目标目录下所有文件,统计总文件数和符合条件的
.c/.h文件数。 - 优先检查文件后缀,非
.c/.h类型直接标记为"跳过"并记录原因。 - 排除脚本自身文件,避免循环处理或误修改。
- 遍历目标目录下所有文件,统计总文件数和符合条件的
-
文件内容读取与匹配
- 以 UTF-8 编码读取文件内容,兼容特殊字符,忽略编码错误。
- 精准匹配文件中是否包含完整的旧版权声明块,避免部分匹配导致的错误替换。
-
版权替换与文件输出
- 匹配成功:用新版权声明替换旧内容,将修改后的文件保存到
processed目录,文件名与原文件一致。 - 匹配失败:直接将原文件复制到
processed目录,标记"未找到旧版权声明"。
- 匹配成功:用新版权声明替换旧内容,将修改后的文件保存到
-
异常处理与状态记录
- 捕获文件读写、权限等异常,记录具体错误信息。
- 分类维护"成功文件列表"和"失败/跳过文件列表",标注每个文件的处理结果及原因。
-
结果汇总与测试验证
- 输出汇总报告,包含成功/失败文件数量及明细、处理后文件路径、日志保存路径。
- 运行前自动执行测试用例:创建临时
.c/.h/.txt测试文件,验证替换逻辑和过滤规则有效性,测试后自动清理临时文件。
三、主要实现内容
文件内容前后变化
旧的内容:
bash
Copyright (c) 2021 Analog Devices, Inc. All Rights Reserved.
This software is proprietary to Analog Devices, Inc. and its licensors.
By using this software you agree to the terms of the associated
Analog Devices Software License Agreement.
******************************************************************************/新的内容:
bash
Copyright (c) 2025 Analog Devices, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
******************************************************************************/四、主要实现代码与结果
test_buildup.py
bash
import os
import shutil
import time
from pathlib import Path
import logging
# ===================== Logger Configuration =====================
def setup_logger():
"""Configure logger: output to both terminal and log file"""
# Create log directory if it doesn't exist
log_dir = Path("logs")
log_dir.mkdir(exist_ok=True)
# Log file name with timestamp (avoid overwriting)
log_filename = log_dir / f"copyright_update_{time.strftime('%Y%m%d_%H%M%S')}.txt"
# Configure log format (include timestamp, level, step description)
log_format = "%(asctime)s - %(levelname)s - %(message)s"
logging.basicConfig(
level=logging.INFO,
format=log_format,
handlers=[
# Output to terminal
logging.StreamHandler(),
# Output to log file
logging.FileHandler(log_filename, encoding='utf-8')
]
)
logger = logging.getLogger("CopyrightUpdater")
logger.info("="*60)
logger.info(" Copyright Statement Update Script - Log Started ")
logger.info(f"Log file saved to: {log_filename.absolute()}")
logger.info("="*60)
return logger
# Initialize logger
logger = setup_logger()
# ===================== Configuration Items =====================
CONFIG = {
# Old copyright statement block (content to be replaced, keep line breaks and spaces consistent)
"old_copyright": """Copyright (c) 2021 Analog Devices, Inc. All Rights Reserved.
This software is proprietary to Analog Devices, Inc. and its licensors.
By using this software you agree to the terms of the associated
Analog Devices Software License Agreement.
******************************************************************************/""",
# New Apache License statement (content to replace with)
"new_copyright": """Copyright (c) 2025 Analog Devices, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
******************************************************************************/""",
"target_dir": ".", # Target directory to process (current directory)
"output_dir": "processed", # Output directory
"skip_files": [os.path.basename(__file__)], # Files to skip (this script itself)
"allowed_extensions": [".c", ".h"] # Only process files with these extensions
}
# ===================== Core Processing Class =====================
class CopyrightUpdater:
"""Copyright Statement Updater Class"""
def __init__(self, config):
self.config = config
self.success_files = [] # Files processed successfully
self.failed_files = [] # Files failed to process
# Step 1: Initialize directory structure
logger.info("[Step 1/5] Initialize directory structure")
# Create output directory if it doesn't exist
self.output_path = Path(config["output_dir"])
self.output_path.mkdir(exist_ok=True)
logger.info(f" - Output directory created/confirmed: {self.output_path.absolute()}")
# Target directory path
self.target_path = Path(config["target_dir"]).absolute()
logger.info(f" - Target directory to process: {self.target_path.absolute()}")
logger.info(f" - Allowed file extensions: {', '.join(config['allowed_extensions'])}")
logger.info(" ✅ Directory initialization completed")
def process_single_file(self, file_path):
"""Process single file (with detailed step logging)"""
file_path = Path(file_path).absolute()
file_name = file_path.name
file_ext = file_path.suffix.lower() # Get file extension (lowercase for case insensitivity)
logger.info(f"\n[File Processing] Start checking: {file_name}")
# Step 2: Check file type rules
logger.info(" [Step 2/5] Check file type rules")
if file_ext not in self.config["allowed_extensions"]:
logger.warning(f" - Non-target file type ({file_ext}), skip processing (only {', '.join(self.config['allowed_extensions'])} are allowed)")
self.failed_files.append({"name": file_name, "reason": f"Non-target file type: {file_ext}"})
return False
# Step 3: Check file skip rules
logger.info(" [Step 3/5] Check file skip rules")
if file_name in self.config["skip_files"]:
logger.warning(f" - Matched skip rule: this script file, skip processing")
self.failed_files.append({"name": file_name, "reason": "Skip script itself"})
return False
try:
# Step 4: Read file content
logger.info(" [Step 4/5] Read file content")
# Read file content (compatible with different encodings, ignore errors)
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
logger.info(f" - File read successfully, file size: {len(content)} characters")
# Step 5: Match and replace copyright statement
logger.info(" [Step 5/5] Match and replace copyright statement")
# Check if old copyright statement exists
if self.config["old_copyright"] not in content:
logger.warning(f" - Old copyright statement block not found, copy file directly to output directory")
# Copy file to output directory if no match
output_file = self.output_path / file_name
shutil.copy2(file_path, output_file)
self.failed_files.append({"name": file_name, "reason": "Old copyright statement not found"})
return False
# Replace copyright statement
new_content = content.replace(self.config["old_copyright"], self.config["new_copyright"])
logger.info(f" - Old copyright statement matched successfully, text replacement completed")
logger.info(f" - Character count change before/after replacement: {len(content)} → {len(new_content)}")
# Step 6: Save processed file
logger.info(" [Step 6/5] Save processed file")
output_file = self.output_path / file_name
with open(output_file, 'w', encoding='utf-8', errors='ignore') as f:
f.write(new_content)
logger.info(f" - Processed file saved to: {output_file.absolute()}")
logger.info(f" ✅ File processed successfully: {file_name}")
self.success_files.append(file_name)
return True
except Exception as e:
# Capture processing errors
error_msg = f"Processing error: {str(e)}"
logger.error(f" ❌ File processing failed: {file_name} - {error_msg}")
self.failed_files.append({"name": file_name, "reason": error_msg})
return False
def process_directory(self):
"""Process all files in target directory (main control logic)"""
logger.info("\n" + "="*60)
logger.info("[Master Step 1/2] Start batch processing directory files")
logger.info(f" - Target directory: {self.target_path}")
logger.info(f" - Allowed file extensions: {', '.join(self.config['allowed_extensions'])}")
# Traverse all files in directory (files only, no subdirectories)
all_files = [item for item in self.target_path.iterdir() if item.is_file()]
logger.info(f" - Total files found in directory: {len(all_files)}")
# Filter target type files (log statistics)
target_files = [f for f in all_files if f.suffix.lower() in self.config["allowed_extensions"]]
logger.info(f" - Target type files count: {len(target_files)}")
for idx, item in enumerate(all_files, 1):
logger.info(f"\n[{idx}/{len(all_files)}] Start checking file")
self.process_single_file(item)
# Print processing result summary
logger.info("\n" + "="*60)
logger.info("[Master Step 2/2] Processing Completed - Result Summary")
logger.info(f"✅ Successfully processed files: {len(self.success_files)}")
if self.success_files:
logger.info(" Success list:")
for fname in self.success_files:
logger.info(f" - {fname}")
logger.info(f"\n❌ Failed/skipped files: {len(self.failed_files)}")
if self.failed_files:
logger.info(" Failed/skipped list (reason):")
for item in self.failed_files:
logger.info(f" - {item['name']}: {item['reason']}")
logger.info(f"\n📁 Processed files root directory: {self.output_path.absolute()}")
logger.info(f"📜 Full log saved to: {logging.getLogger().handlers[1].baseFilename}")
logger.info("="*60)
# ===================== Test Cases =====================
def test_copyright_replacement():
"""Test copyright statement replacement logic (with logging)"""
logger.info("\n" + "="*60)
logger.info("[Testing Phase] Start executing replacement logic test cases")
# Create temporary test directory
test_dir = Path("test_temp")
test_dir.mkdir(exist_ok=True)
# Create test files of different types
test_files = [
("test_file.c", "C file"),
("test_file.h", "H file"),
("test_file.txt", "non-target file"),
("test_file.py", "non-target file")
]
for fname, desc in test_files:
test_file = test_dir / fname
# Write test content with old copyright statement
test_content = f"""This is {desc} test header
{CONFIG['old_copyright']}
This is {desc} test footer"""
test_file.write_text(test_content, encoding='utf-8')
logger.info(f" - Created {desc}: {test_file.name}")
# Modify config to point to test directory
test_config = CONFIG.copy()
test_config["target_dir"] = str(test_dir)
test_config["output_dir"] = str(test_dir / "processed")
# Initialize and process
updater = CopyrightUpdater(test_config)
updater.process_directory()
# Verify replacement results
logger.info(" - Start verifying replacement results")
# Check .c file
c_output = Path(test_config["output_dir"]) / "test_file.c"
assert c_output.exists(), "Processed C file does not exist"
c_content = c_output.read_text(encoding='utf-8')
assert CONFIG['new_copyright'] in c_content, "New copyright statement not replaced in C file"
logger.info(" ✔ C file replacement successful")
# Check .h file
h_output = Path(test_config["output_dir"]) / "test_file.h"
assert h_output.exists(), "Processed H file does not exist"
h_content = h_output.read_text(encoding='utf-8')
assert CONFIG['new_copyright'] in h_content, "New copyright statement not replaced in H file"
logger.info(" ✔ H file replacement successful")
# Check .txt file (should be skipped)
txt_output = Path(test_config["output_dir"]) / "test_file.txt"
assert not txt_output.exists(), "Non-target file should not be processed"
logger.info(" ✔ Non-target file (txt) skipped successfully")
logger.info("✅ All test cases passed!")
# Clean up test files
shutil.rmtree(test_dir)
logger.info(f" - Cleaned up temporary test directory: {test_dir.absolute()}")
logger.info("="*60)
# ===================== Main Execution Logic =====================
if __name__ == "__main__":
try:
# Execute test cases first to verify replacement logic
test_copyright_replacement()
# Start processing actual files
logger.info("\n" + "="*60)
logger.info("[Formal Processing] Start processing actual directory files")
# Initialize and process target directory
updater = CopyrightUpdater(CONFIG)
updater.process_directory()
logger.info("\n🎉 Script execution completed! Full log saved to TXT file in 'logs' directory")
except Exception as e:
logger.error(f"\n❌ Script execution exception: {str(e)}", exc_info=True)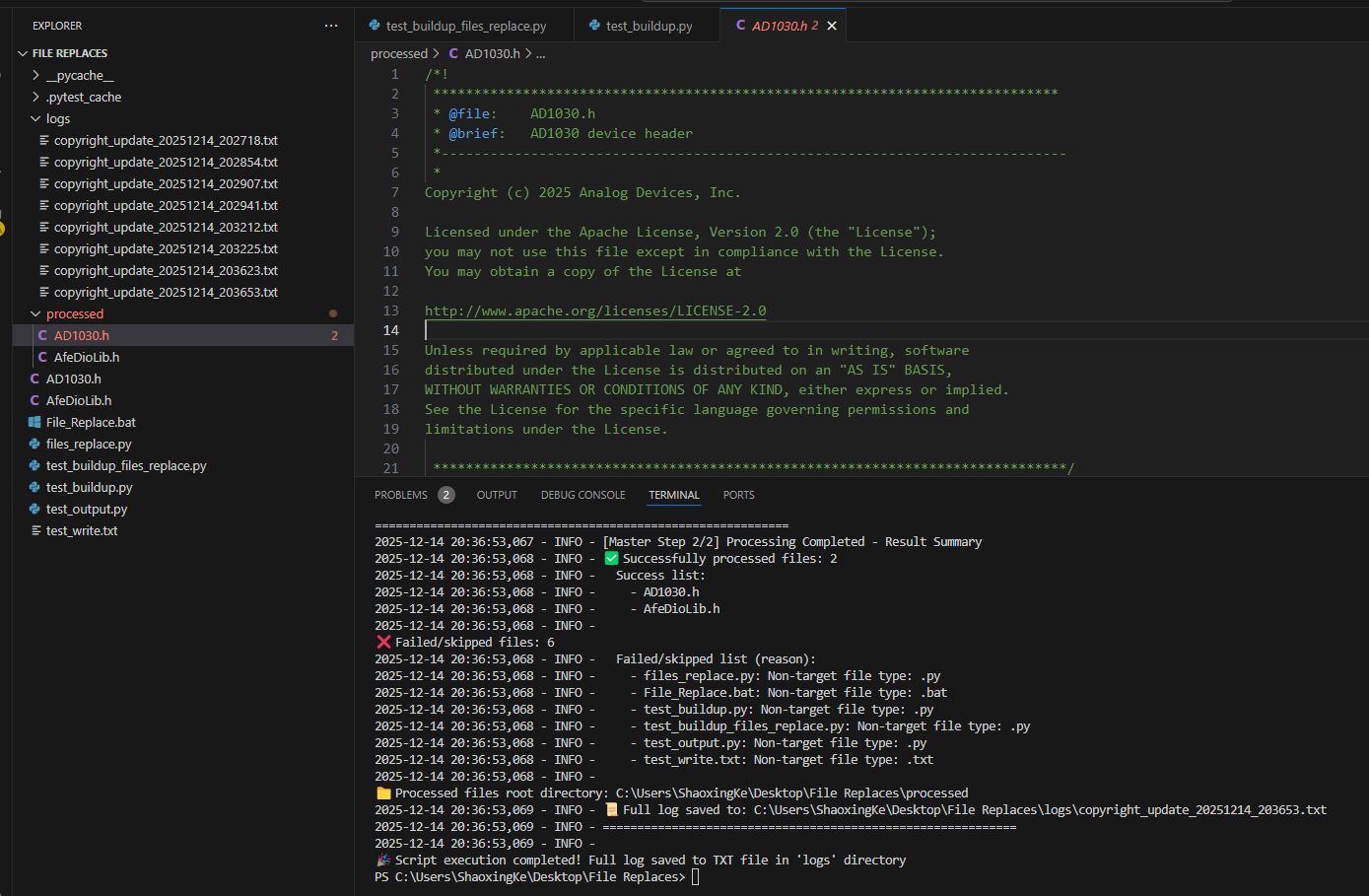
五、总结
- 初始化配置与日志:定义旧/新版权文本、目标目录等参数,配置终端+文件双输出日志,自动创建
processed(输出文件)和logs(日志)目录; - 文件筛选检查:遍历目标目录,仅保留
.c/.h文件,跳过非目标格式文件及脚本自身; - 内容读取匹配:以UTF-8编码读取文件,检查是否包含完整旧版权声明块;
- 替换与输出:匹配成功则用新版权替换并保存到
processed,失败则直接复制原文件; - 结果追踪:记录成功/失败文件及原因(如"未找到旧版权""非目标类型");
- 测试验证:运行前自动用临时文件测试替换逻辑,验证通过后处理实际文件,最后输出汇总报告。