从三个疑问谈谈我们的核心理念
AI能写代码早已不是新鲜话题,但当它被引入真实的日常开发流程时,工程层面的问题才真正开始暴露:
- 为什么在多数团队里,AI 写代码仍然时好时坏?
- 为什么同样一句指令,有时像资深工程师,有时却像实习生?
- 为什么生成速度上来了,代码却越来越难维护?
这些困惑并不意外------它们几乎是当前 AI Coding 的"常态体验"。 但是在我们的中后台系统中,AI Coding 却能持续稳定地高质量输出,同时我们还落地了相关的一套工程体系,效果非常直接:
原来一个页面前端编码需要半天,现在只需要一句话 → 5~10分钟就自动生成、可直接运行。
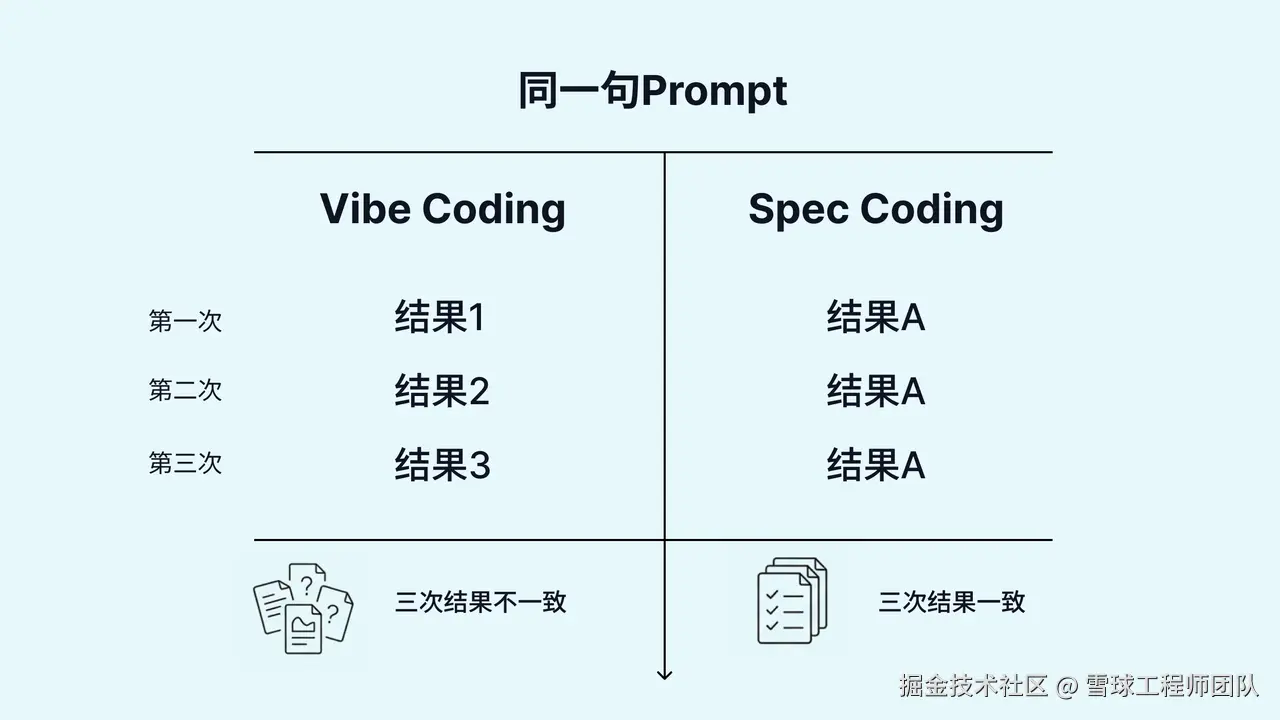
不仅速度快,质量还稳得惊人------同一个需求,不同人生成的代码结构完全一致,像是资深工程师写出来的。
这意味着:
- 研发从大量重复编码中解放出来,把精力投入到复杂问题、架构设计与体验打磨上;
- 新人入职即可交付,无需先花时间熟悉庞大的框架细节;
- 团队整体交付速度成倍提升,质量更可控。
目前雪球内部近60% 的中后台新页面由 AI Coding 自动生成。
那么问题来了:
为什么同样使用 AI,差距会如此之大?
答案,不在模型本身,而在于------有没有建立一套人与 AI 的标准化沟通方式。自然语言本身具有模糊性,而软件开发却高度依赖精确表达,这种张力正是差距产生的根源。
对此,亚马逊云科技首席软件工程师 Claire Liguori 在其关于 Kiro IDE 的实践中指出,开发者要想让 AI 生成符合预期的软件,就必须采用一种更加结构化、精确的沟通方式,也就是我们遵循的核心理念:Spec-driven development(规范驱动开发),通过标准化、可验证的规范,将模糊需求转化为可执行、可追溯的工程过程。
亚马逊 CTO Werner Vogels 也曾更进一步强调,Spec-driven development 不是官僚主义,而是一种工程纪律;Apollo 登月项目的成功,在很大程度上正是建立在这种纪律之上。
那我们具体是如何践行 Spec-driven development 的呢?接下来,我们先从 Spec Coding 与 Vibe Coding 的区别 说起。
一、为什么是 Spec Coding,而不是 Vibe Coding
1、Vibe Coding:看起来很聪明,用起来很心虚
2025年2月,OpenAI 联合创始人、AI 研究者 Andrej Karpathy 首次提出 Vibe Coding(氛围编程),引发了编程的新变革。例如,你给它一句指令:
"做一个有列表和搜索的用户管理页"
它会写代码,写得还挺像回事。
但一旦进入真实工程,就会暴露问题:
- 易出现理解偏差:接口、字段、业务逻辑经常"凭空被 AI 想象出来";
- 风格不统一:每次生成结构都不一样,"像每个工程师风格都完全不同";
- 越复杂越不稳:跨模块、校验逻辑、多状态处理、复杂组件等情况容易崩溃;
- 维护困难:代码不是不能用,但半年后团队没人敢动。
一句话总结:
Vibe Coding = 即兴发挥,爽在当下,痛在维护。
适合 Demo、不严谨的业务评审、原型验证。但无法成为工程体系,难以支撑企业大规模真实项目。
2、Spec Coding:让 AI 按"规格"工作,而不是靠感觉
2025 年下半年亚马逊、OpenAI等头部大厂相继提出 Spec Coding 相关理念,即"规格驱动开发",逐渐被社区和平台采纳 。Spec 的本质是:指令不是"感觉式",而是"结构化、可解析、零歧义"。
举例:
"生成一个标准的用户管理页
数据接口:/user/list(GET)
包含搜索:name(输入框)、status(下拉)
列表字段:name、status、createTime 支持分页、批量删除。"
这是 AI 最擅长处理的输入:固定格式、强结构化、有明确上下文。
好处也极其显著:
- 完全避免幻觉:所有字段、接口、组件都从规范解析;
- 代码质量稳定如同资深工程师:结构统一、抽象一致、可维护;
- 跨项目大规模复用:规范体系 + Agent能力 = 自动生成能力;
- 越做越强:规范体系的积累与完善会持续增强编程能力。
一句话总结:
Spec Coding = 面向工程体系的 AI 生产方式。
它关注的不是"一次写得有多快",而是长期是否稳定、是否可控、是否能规模化落地。
小结:程序员不是被替代,而是完成了一次角色升级
在 AI 时代,更有价值的能力,不再只是"把代码写出来",而是"精准表达意图的沟通"。将目标、约束与成功标准等内容严密通过规范结构化的表达写进规范,代码只是沟通与决策后的一种下游产物。程序员的价值由写代码转为写规范,即程序员负责战略(定义做什么以及为什么),AI负责战术(精确地实现如何做)。
这也是为什么我们中后台系统选择 Spec Coding,而不是 Vibe Coding。那我们是如何在中后台体系落地的呢?
二、AI Coding 的现实挑战与中后台系统的契合点
在经历了从代码补全到智能生成的快速演进后,AI Coding 的能力已经进入"可用但不稳定"的阶段。它能理解自然语言生成结构化代码,显著提升研发效率,却也在工程落地中暴露出一系列问题:
-
理解偏差与幻觉问题:模型可能凭空生成不存在的函数或接口,或因需求描述模糊而误解逻辑,导致输出结果看似正确却无法运行;
-
代码质量与规范不统一:生成代码易出现冗余膨胀、风格不统一、缺乏抽象与复用,短期可用,长期维护成本高;
-
复杂场景难把握:在复杂场景下容易出现逻辑不一致、上下文理解不完整、代码结构混乱等问题,难以稳定生成可直接落地的工程级方案。
可以说,当前的 AI Coding 处理"模板化"的场景更精准,而在涉及复杂业务逻辑时问题会显著增多。当任务描述清晰、结构明确时,AI 能高效生成高质量代码;但面对抽象、依赖上下文理解的业务需求时,往往容易出现偏差或理解错误。
中后台系统相对于C端需求而言,有着更强的"规律性"和"结构化"特征,这与 AI Coding 在规则明确、结构清晰场景中的优势高度契合。中后台场景具备以下天然优势:
- 结构化且规范化:中后台页面以表格、表单、搜索等模块为主,功能模式固定、组件体系规范且完善。能有效约束生成结果,降低"幻觉"风险;
- 规模大且可控:中后台业务页面数量多、相似度高,配合统一模板和规范体系,AI 能在此类场景中实现高效、批量的代码生成与维护,加速需求交付的全流程。
小结:中后台开发场景兼具"高重复性"与"强规范性" ,非常适合通过 Spec Coding 实现 AI Coding 的第一落地场景。它让团队在确保可维护性的同时,快速积累高质量的 AI 生成样本,并逐步向更复杂的业务逻辑延伸。
三、从指令到交付:程序员与AI是如何沟通的?
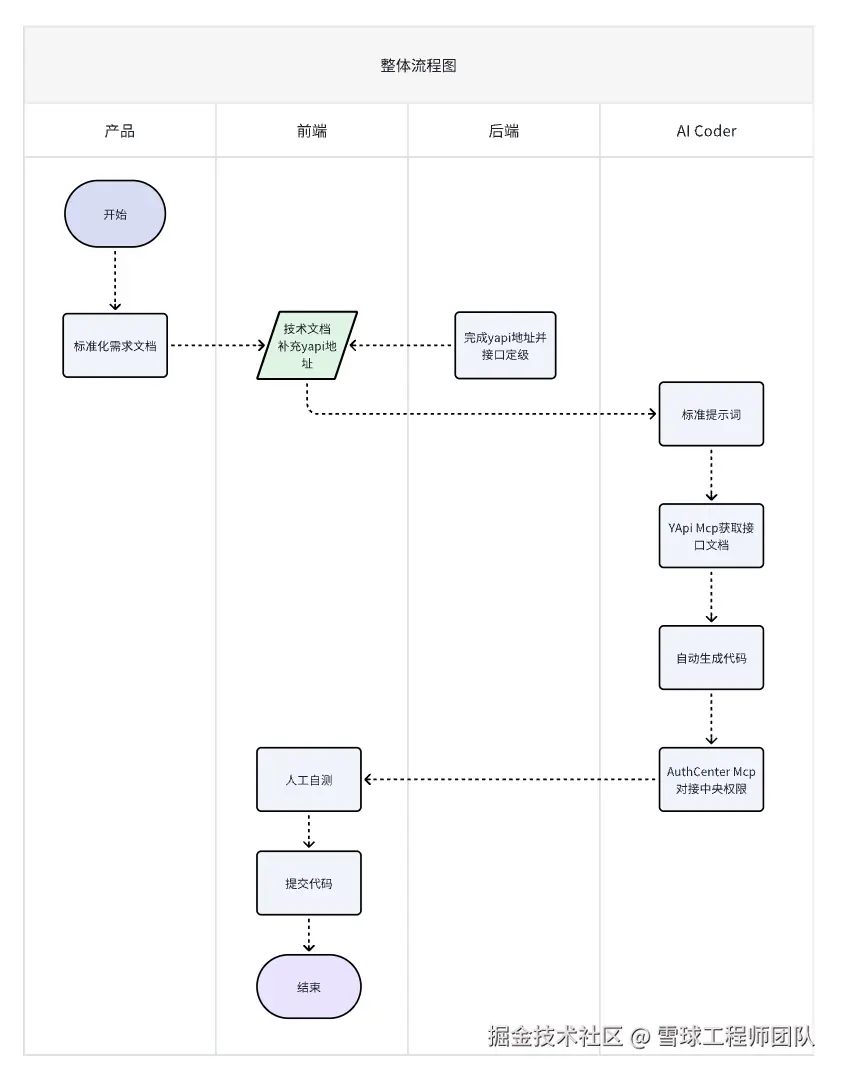
要让人与 AI 之间实现真正高效的沟通,我们没有设计复杂的指令,而是极简的一句话
"帮我根据 需求文档地址 生成页面,并对接具体环境的中央权限系统"
即可触发完整工作流。为此,我们打造了三大 Spec 利器,并以 Cursor 作为承载这一切的工作台,把需求内容、接口信息、代码规范等全部结构化,让 AI 能在一轮沟通中就"听懂"要做什么,从而稳定产出可靠的工程级结果。
Cursor 编辑器:在 Cursor 中,我们用一句自然语言指令即可触发完整工作流:读取需求文档、调用 MCP 获取接口语义、参考UI规范并遵循 rules,生成符合工程标准的页面代码,并最终对接中央权限系统进行权限管理。Cursor 将分散的能力整合为一个连续的开发体验,让"需求→代码→调试"形成闭环,使开发者从编写代码转向指导 AI 生产代码。
三大 Spec 利器:UI 规范确保页面展示与交互统一,MCP 补充项目语义上下文,Rules 体系保障生成质量。
利器一:UI 规范为 AI 编码标准化提供基础
中后台系统的界面虽然以业务为主,但为了保证美观与一致的交互体验,我们在初期就建立了系统化的 UI 规范,并整理成 UI Spec,为后续的 AI Coding 提供了可复用、可生成的基础。

这套规范主要包含两大方面:
- 视觉与交互标准:统一主题、字体、间距、页面模块布局、操作交互等规则,使整个项目保持一致的观感与操作体验;
- 组件化体系:常用模块(搜索框、列表、弹窗表单等)均来自公共组件库,AI 在生成页面时可以直接复用现有标准组件而非重新造轮子。
基于这套体系,AI Coding 不再是"随意绘制界面",而是在约束下生成标准化的 UI。这既能保证所有界面的一致性,也为自动化开发提供坚实基础。
利器二:MCP 是 AI 编码的"信息中枢"
MCP(Model Context Protocol)能连接到外部系统和数据,让模型真正理解项目语境,具备"看得见、听得懂、做得准"的能力,是 AI 编码中重要的"信息中枢"。我们核心 MCP 包含以下两个:
1. YApi MCP
YApi 是一个接口管理与文档平台,前后端等角色可在同一平台查看并对接接口,避免沟通混乱与信息不一致等问题。得益于后端团队长期、规范地维护 YApi 文档,接口信息始终保持准确、完整。
在此基础上,YApi MCP 自动获取接口的请求地址、参数、响应字段等内容,为模型提供权威、最新的 Api Spec,从源头上避免大模型凭猜测生成接口信息。
2. Auth-center MCP
中央权限系统是公司内部所有中后台系统统一管理权限的平台。
Auth-center MCP 通过接口调用的方式快速接入权限系统,包括接口自动定级、资源自动新增、页面接口绑定等权限管理全流程配置,既能提高接入效率,更能避免人工操作失误。
基本的 MCP 配置如下:
json
{
"mcpServers": {
"auth-center-mcp": {
"command": "npx",
"args": [
"-y",
"auth-center-mcp",
"--username=***",
"--password=***"
]
},
"yapi-mcp": {
"command": "npx",
"args": [
"-y",
"yapi-mcp",
"--yapiHost=***",
"--username=***",
"--password=***"
]
}
}
}通过 MCP 的接入,模型像是装上了"千里眼",不再是一个"闭门造车"的助手,而是能真正读懂上下文的团队成员。
利器三:Rules 让生成代码具备"专业级水准"
大模型虽然强大,但它容易幻觉生成冗余且不易维护的代码,为了控制它的输出质量,我们制定了一系列 Spec 并沉淀到 cursor的 rules 文件中,在编程过程中提供持久的、可复用的上下文,这些 Spec 既是工程的底线,也是 AI 的知识库。
在众多rules文件中,有6个对生成的代码质量至关重要:
markdown
---
description:
globs:
alwaysApply: true
---
## 文件组织
项目开发规范已按功能模块拆分到 `./rules/` 目录中:
- `project-overview.mdc` - 项目概述和核心开发原则
- `requirements-reading.mdc` - 读取需求文档的规范
- `api-development.mdc` - 接口调用规范和数据格式处理规范
- `component-usage.mdc` - 公共组件使用规范
- `forbidden-practices.mdc` - 禁止事项和常见错误预防
- `auth-center.mdc` - 接入中央权限规范
... 其他rules文件-
project-overview.mdc:定义项目的核心开发原则与工程约束,提供标准CRUD的最佳实践,是所有生成任务的总纲; -
requirements-reading.mdc:指导大模型从需求文档中,精准读取页面相关需求内容; -
api-development.mdc:规范接口请求方式,确保接口调用及数据处理相关代码符合团队约定; -
component-usage.mdc:指导大模型遵循设计规范,并正确使用公共组件,在避免重复造轮子的同时,还能在生成阶段对齐UI规范; -
auth-center.mdc:提示大模型根据代码找出页面所有操作按钮及对应接口,组装成特定schema数据,并调用对应mcp,确保权限按需接入中央权限系统; -
forbidden-practices.mdc:列出禁止写法与常见错误,比如直接操作 DOM、跳过 YApi 文档直接开发等。
AI 生成的代码会自动对照这些 rules 进行校验,不符合规范的部分会触发二次修正,最终让 AI 的输出更接近资深开发者的专业级水准。
四、后续展望:我们还想做更多
目前只是 AI Coding 的第一步,我们还将基于规范驱动开发继续探索以下方向:
- 扩大覆盖面:目前主要支持部分中后台项目的常规页面,后续会逐步提升中后台项目使用占比;同时扩展到支持复杂交互页面;更进一步,做到走出中后台项目,支持要求更严格、形式更多变的C端系统;
- 更细粒度的回溯与优化:让 AI 输出过程具备"可回放"、"可解释"、"可优化"的能力;
- 全流程智能化: 从上游提出业务需求(想法),智能生成需求文档,再到自动 coding、测试,最后完成自动提交和部署。