系统概览图
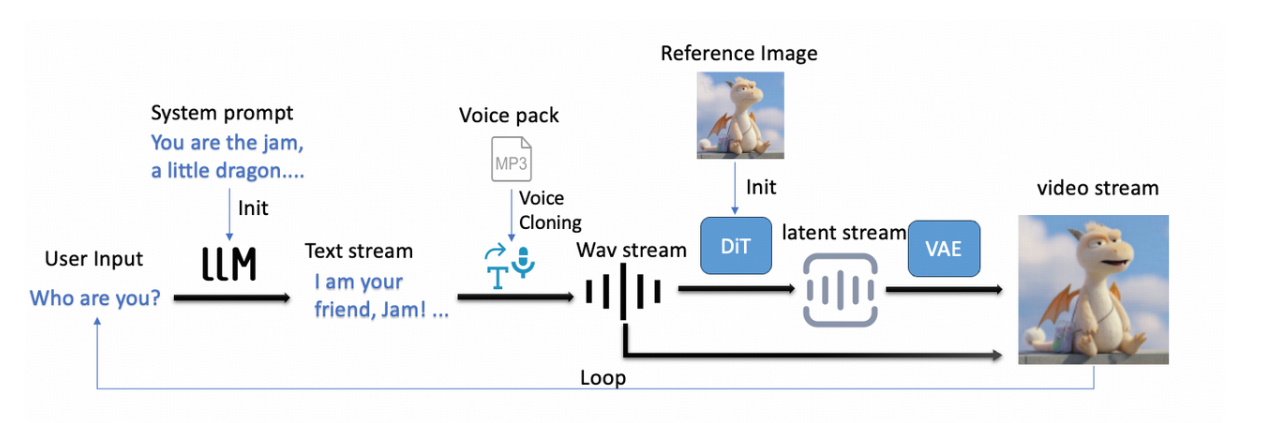
RealVideo 系统工作流程概述
系统工作流程始于角色初始化:用户提供参考图像和参考语音文件用于克隆,系统据此实例化角色。用户还可以设置系统提示,指定模型应扮演的角色。随后,RealVideo 通过文本输入与用户交互。用户消息由 LLM 处理并记录,LLM 随后根据全局上下文生成响应。生成的文本被传递给 TTS 模块合成语音,合成的语音又成为自回归扩散模型的输入。该模型以块(每块约 0.5 秒)的形式输出视频。视频潜在信号随后由 VAE 进行流解码,并与相应的音频一起传输到前端,以实现实时交互。
在当前架构中,通过引入自动语音识别 (ASR) 和语音音频检测 (VAD),可以轻松地将文本输入替换为语音输入。类似地,将 LLM 替换为流式 VLM 即可同时支持视频和语音输入。为了保持模块化,RealVideo 默认使用文本输入;但我们欢迎社区扩展其功能,添加更多输入方式。
模型训练:基于自回归扩散的视频生成
音频驱动视频生成
目前已有多个开源的非实时音频驱动视频生成模型能够生成高质量的结果。经过测试,我们选择 WanS2V 2 作为基础模型进行后续的自回归训练。WanS2V 提供两种生成模式:5 秒语音视频生成和 5 秒视频连续生成。由于自回归训练允许模型生成任意长度的视频而无需显式地进行连续处理,因此我们的训练重点放在第一种模式上。
Autoregressive Training 自回归训练
RealVideo 的训练流程基于 Casuvid 3 和 Self-Forcing 4 框架,并进行了多项改进。训练过程分为两个阶段:
第一阶段:ODE 蒸馏。首先从双向教师模型中采样大量 ODE 轨迹,然后训练一个单向模型来拟合这些轨迹,该单向模型只需显著减少推理步骤(例如 4 步或 2 步)。经过此阶段,单向模型已经能够生成简单的对话场景,但在更复杂的场景中仍会出现轻微的闪烁。
第二阶段:自强制训练。在常微分方程蒸馏之后,模型将进一步训练以匹配教师模型,方法是最小化"真实分数模型"和"虚假分数模型"概率密度之间的梯度差异,如34所述。真实分数模型和虚假分数模型的选择至关重要;通过实验,我们观察到,对两者都使用双向模型,并从真实模型初始化虚假模型,可以获得最佳结果。
Sliding Window Attention 滑动窗口注意事项
实时生成要求在 1/FPS 秒内生成每一帧,这意味着每帧的推理延迟必须严格控制。因此,稀疏注意力机制对于保持上下文长度在可控范围内至关重要。一种简单有效的方法是滑动窗口注意力机制。当视频长度超过设定的阈值时,旧的键值缓存条目会被截断(同时保留参考图像的键值缓存),从而保持注意力上下文长度不变。然而,滑动窗口注意力机制存在两个主要问题:(i)长期记忆丢失:模型会忘记之前的帧,导致无法完成持续时间较长的动作;(ii)动作重复:反复生成短期动作(尤其是在 T2V 和 I2V 场景中),例如反复挥手。这是因为模型无法在有限的上下文窗口内判断某个动作是否已经完成。
幸运的是,在音频驱动的视频生成中,这种限制通常是可以接受的,原因有二:(i) 音频流严格限制了每一帧的内容;(ii) 人类对话很少涉及冗长或复杂的动作。因此,滑动窗口注意力机制非常适合音频驱动的视频生成,以及具有明确控制流的任务(例如骨架或风格)。虽然并非理想之选,但由于其他注意力机制的训练和部署复杂度更高,我们还是选择了这种方法用于当前版本。我们计划在未来的工作中对其进行改进。
Dynamic Sink RoPE 动态下沉绳
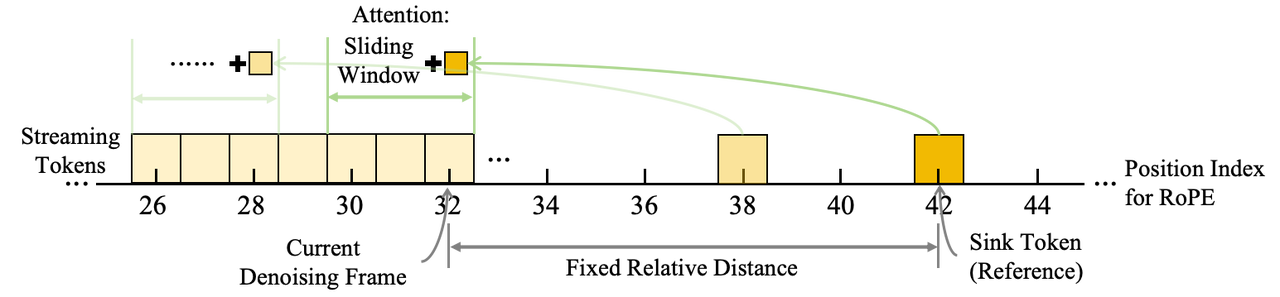
接收器标记(Sink Tokens)的概念最初引入于语言模型5,在滑动窗口注意力机制下,将关键标记保留在键值缓存(KV cache)中可以显著提升长上下文文本生成的性能。在实时流视频生成中,参考图像中的标记是理想的接收器标记,因为它们能够引导模型在整个生成过程中与参考图像保持一致。然而,在长时间的对话过程中,这些接收器标记与当前生成帧之间的相对距离会持续增大。最终,这种距离会超出训练过程中覆盖的位置编码范围,导致训练结果与推理结果之间出现显著的不匹配。这个问题直接表现为"身份漂移":随着生成时间的延长,视频中的角色会逐渐偏离参考图像,导致视觉保真度逐渐下降。
幸运的是,由于 RoPE 是一种相对位置编码,我们可以通过简单地调整目标标记的位置索引,确保滑动窗口注意力机制下推理和训练之间的严格对齐。类似的观察结果在之前的文献 6 中也有提及。在 WanS2V 架构中,参考图像的时间 RoPE 索引被设置为 30,而 5 秒去噪视频窗口的索引范围为 0-20。这意味着,只要参考图像(目标标记)与当前去噪帧之间的相对距离保持在 10, 30 区间内,配置就能与训练分布保持一致。因此,当当前生成帧的索引超过 20 时,我们会动态更新参考图像的 RoPE 索引,以强制执行以下关系:
下图也展示了这种位置索引关系。实验结果表明,该策略能有效缓解长时间内的角色漂移,显著提升视频生成过程的稳定性和视觉一致性。
受 DMD27的启发,我们在自强制训练阶段引入了基于噪声潜在变量的对抗训练,以提升视觉质量和角色一致性。具体而言,我们利用伪分数模型对噪声潜在变量强大的特征提取能力来构建判别器,如下图所示。
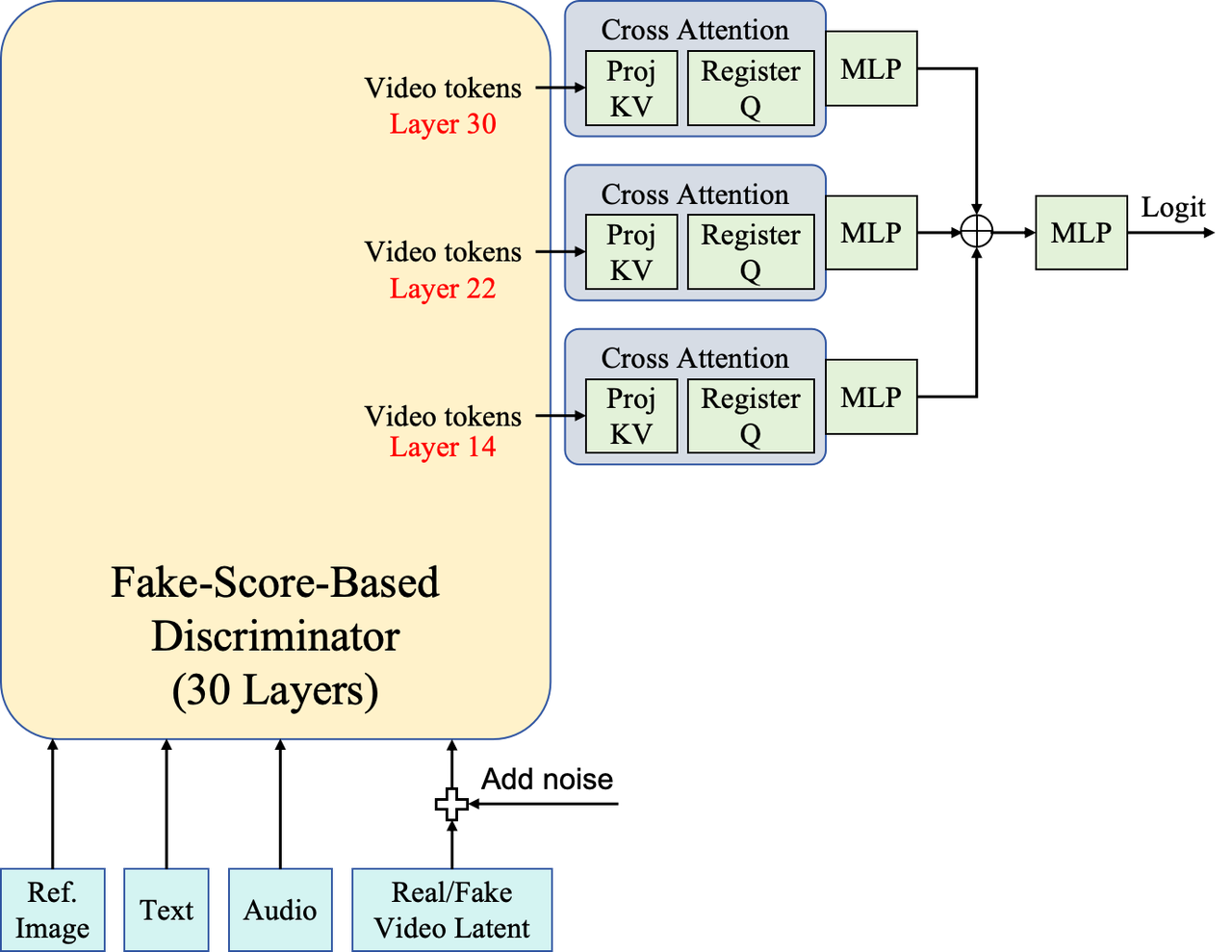
首先,我们采样一个对应于低噪声区域(在本实验中为 0-200)的时间步。基于该时间步采样噪声,并将其添加到真实或生成的视频潜在特征中。这些带噪声的潜在特征,连同条件输入(参考图像、文本提示、音频和时间步),被输入到伪分数模型中。然后,我们从伪分数模型的后续阶段(例如,Transformer 模块 14、22 和 30)提取特征,并将它们传递给轻量级分类头。每个分类头由一个交叉注意力层组成,其中可学习的注册标记作为查询,带噪声的潜在特征作为键和值,之后连接一个多层感知器 (MLP)。三个分类头输出的特征被连接起来,并通过最终的 MLP 进行投影,从而得到分类逻辑值。
我们切断了分类器向模拟模型返回的梯度流,以避免干扰 DMD 损失。此外,由于判别器更新过于频繁可能会使生成器性能下降,我们采取了以下措施:(i)降低判别器的学习率;(ii)当损失低于设定的阈值时停止判别器更新。
对抗训练能够显著提高感知质量,并减少长期视频生成中的颜色漂移。

System Architecture 系统架构
RealVideo 的架构由三个主要组件构成:
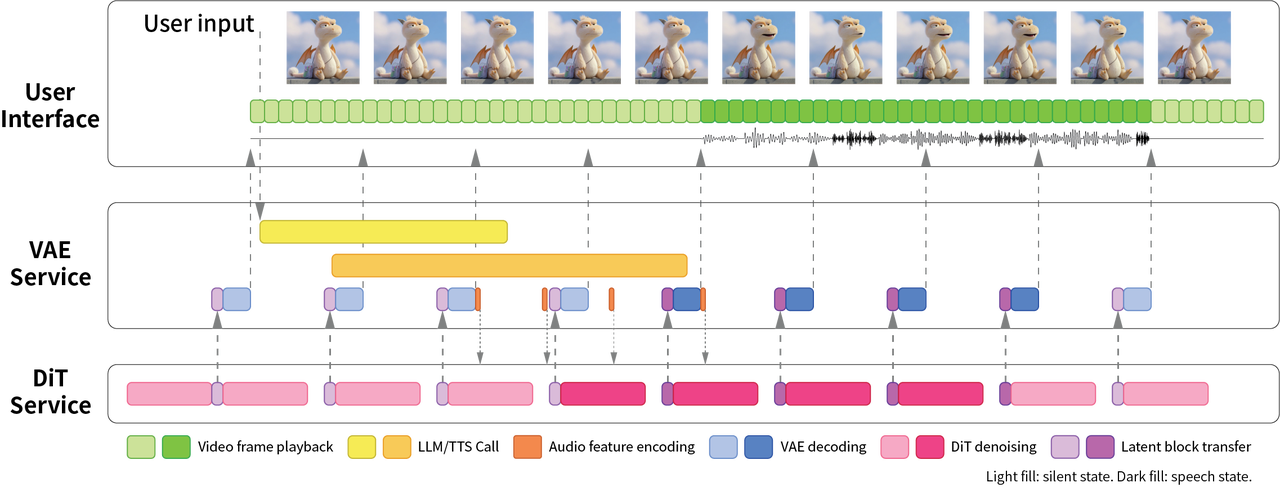
User Interface 用户界面
处理用户交互:将用户输入发送到后端并显示流式音频/视频帧。
VAE Service VAE 服务
VAE 服务负责协调以下任务:
输入处理:接收用户输入并调用 LLM-TTS 管道生成音频响应。
编码和传输:对音频和文本提示进行编码,并将其传输到 DiT 服务。
解码和显示:从 DiT 服务接收生成的视频潜在块,使用 VAE 将其解码为像素空间视频帧,并将其流式传输到用户界面。
DiT Service DiT 服务
DiT 服务托管了一个流式视频生成扩散变换器。它从 VAE 服务接收音频嵌入,并以自回归流式方式生成相应的潜在视频块,然后将这些视频块发送回 VAE 服务。
System Optimizations 系统优化
影响用户体验的两个主要因素是:
实时生成平滑度
系统响应延迟
我们据此实施了几项优化措施。
Real-Time Generation 实时生成
实时性能的主要瓶颈在于 DiT 服务能否在当前数据块的播放时间内完成下一个数据块的去噪和传输。我们实现了几种加速策略:
- 多 GPU 序列并行:我们在推理过程中使用 Ulysses 7 进行序列并行,随着 GPU 数量的增加,速度提升接近线性。在 H100 数据集上,单个 GPU 上单个数据块(4 步,block_size=2)的推理时间为 943 毫秒,而使用 2 个 GPU 时则为 655 毫秒。
- PyTorch 编译:利用 torch.compile(在 PyTorch 2.0 中引入),我们优化了特定模块,将推理速度从 513 毫秒提高到 480 毫秒。
- 内存优化:自回归生成算法需要频繁地对键值缓存进行读写操作,导致内存分配和释放的开销。利用滑动窗口注意力机制中键值缓存的有效大小恒定这一特性,我们预先分配一个与窗口大小对应的固定内存块。通过调整更新和读写策略,我们显著减少了冗余的内存操作和数据复制。
另一种方法是量化模型,当前代码库已支持该模型。我们欢迎社区成员共同努力开发量化版本。
Response Speed 响应速度
响应速度定义为用户输入完成到视频响应开始之间的延迟。这取决于上游模型(LLM、TTS)和视频生成系统本身的延迟。
TTS 并行策略(实验性策略,最终未采用):为了最大限度地缩短首词时间,我们尝试了一种双路径策略。首先快速生成一个低质量的音频"草稿"(步骤=2),用于模拟视频生成(足以实现唇形同步);同时并行生成一个高质量的音频(步骤=6),用于最终的音频输出。然而,测试表明,这种方法仅节省了几十毫秒,却使 API 调用次数翻了一番;因此,在开源版本中省略了该策略。
块大小配置:一旦第一个音频数据包到达,流水线( 𝐷𝑖𝑇→𝑉𝐴𝐸→𝐹𝑟𝑜𝑛𝑡𝑒𝑛𝑑D i T →V A E →F ro n t e n d )便开始运行。由于生成速率高于播放速率,初始延迟取决于流水线缓冲区长度(2-3 个已生成但尚未显示的视频块)。这种延迟主要源于 DiT、VAE 和前端之间的流水线并行处理,而非 DiT 本身的生成速度。我们选择 2 个延迟帧(0.5 秒播放时长)的块大小,以在响应速度和计算效率之间取得平衡。系统总延迟约为 2 秒。
沉默处理
在交互过程中,虚拟化身通常处于静默状态(零音频输入)。我们观察到,纯零输入会导致虚拟化身完全静止。为了解决这个问题,我们在静默音频帧中注入随机噪声,其方差与训练音频数据的全局背景噪声相匹配。这有效地防止了静态伪影,并保持了逼真的效果。
概括
RealVideo 是一款实时流式对话视频系统,它利用自回归扩散算法将文本交互转换为连续、高保真的视频响应。其双服务架构(VAE 服务 + DiT 服务)结合序列并行推理、键值缓存优化和流水线调度,实现了流畅的 0.5 秒视频块流传输,端到端延迟约为 2 秒。这些建模和工程方面的进步使 RealVideo 成为首批能够实时、逼真且持续生成对话视频的开放实用系统之一。