📌 个人主页: 孙同学_
🔧 文章专栏: Liunx
💡 关注我,分享经验,助你少走弯路!

文章目录
-
- 1.线程互斥
-
- [1.1 进程线程间的互斥相关背景概念](#1.1 进程线程间的互斥相关背景概念)
- [1.2 互斥量mutex](#1.2 互斥量mutex)
- [1.3 互斥量实现原理探究](#1.3 互斥量实现原理探究)
- [1.4 互斥量的封装](#1.4 互斥量的封装)
- [2. 线程同步](#2. 线程同步)
-
- [2.1 条件变量](#2.1 条件变量)
- [2.2 同步概念与竞态条件](#2.2 同步概念与竞态条件)
- [2.3 条件变量函数](#2.3 条件变量函数)
- [2.4 POSIX信号量](#2.4 POSIX信号量)
- [3. 线程池](#3. 线程池)
-
- [3.1 日志概念](#3.1 日志概念)
- [3.2 线程池的设计](#3.2 线程池的设计)
- [3.3 线程安全的单例模式](#3.3 线程安全的单例模式)
-
- [3.3.1 什么是单例模式](#3.3.1 什么是单例模式)
- [3.3.2 单例模式的特点](#3.3.2 单例模式的特点)
- [3.3.3 饿汉实现方式和懒汉实现方式](#3.3.3 饿汉实现方式和懒汉实现方式)
前言
线程是共享地址空间的,所以线程会共享大部分资源。线程在访问这些公共资源的时候,极有可能会造成数据不一致问题。比如两个线程都往显示器文件里面做写入,两个线程同时写,就会造成数据不一致问题。为了解决数据的不一致问题,我们就要了解线程的同步与互斥。
1.线程互斥
1.1 进程线程间的互斥相关背景概念
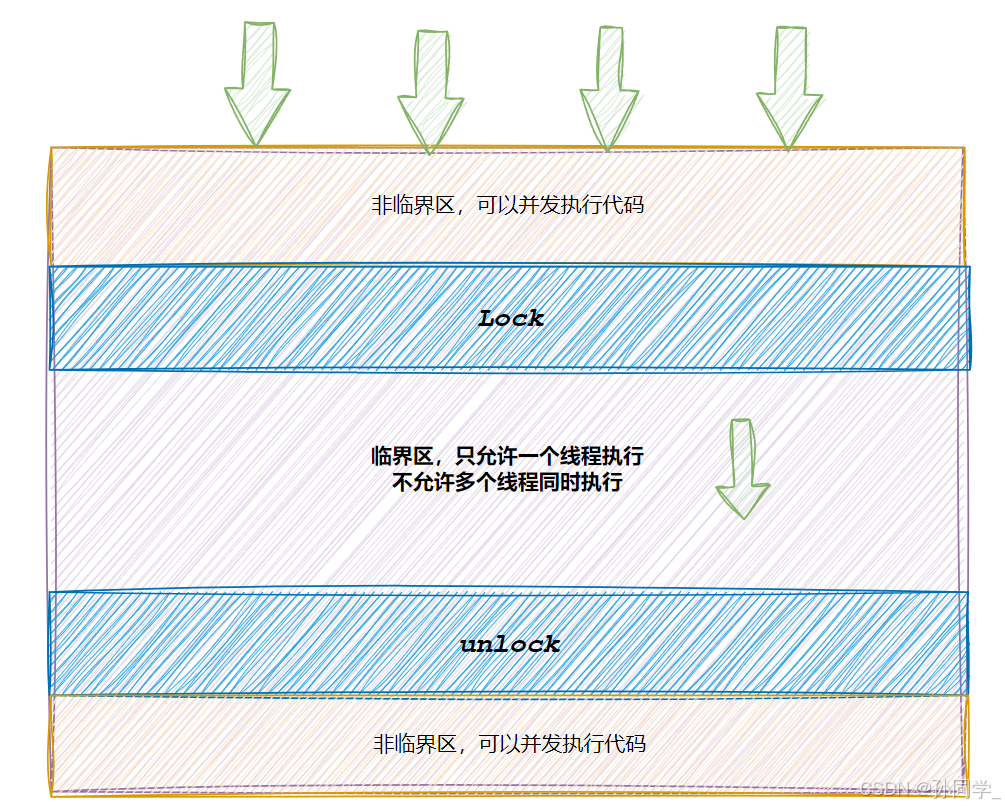
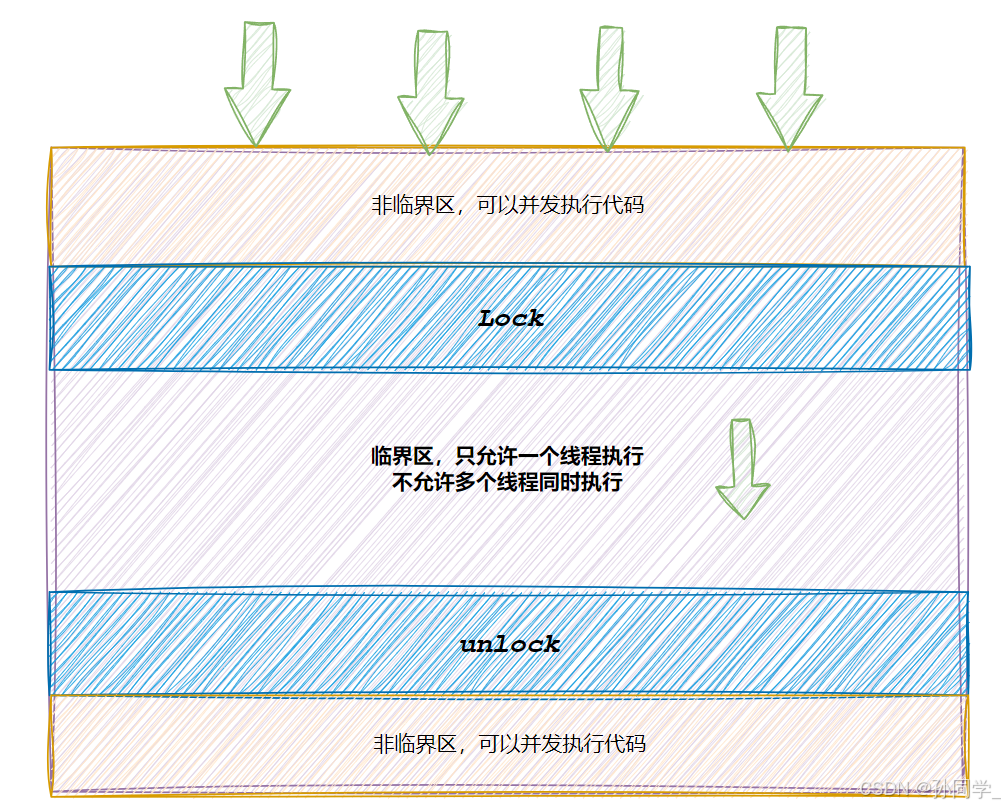
- 临界资源: 多线程执行流共享的资源就叫做临界资源
- 临界区: 每个线程内部,访问临界资源的代码,就叫做临界区
- 互斥: 任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
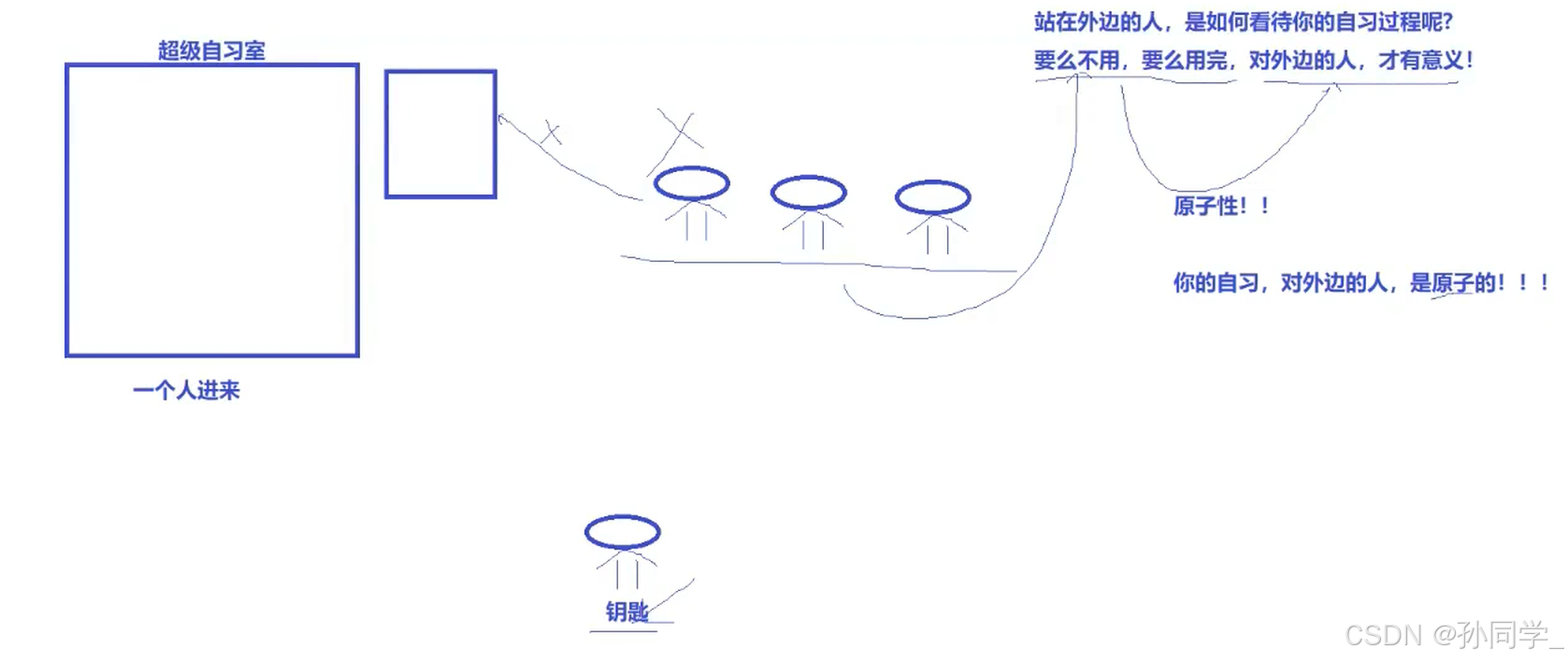
- 原子性: 不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成
1.2 互斥量mutex
- 大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。
- 但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。
- 多个线程并发的操作共享变量,会带来一些问题。
cpp
// 操作共享变量会有问题的售票系统代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 1000;
void *route(void *arg)
{
char *id = (char *)arg;
while (1)
{
if (ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
}
else
{
break;
}
}
}
int main()
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, "thread 1");
pthread_create(&t2, NULL, route, "thread 2");
pthread_create(&t3, NULL, route, "thread 3");
pthread_create(&t4, NULL, route, "thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
return 0;
}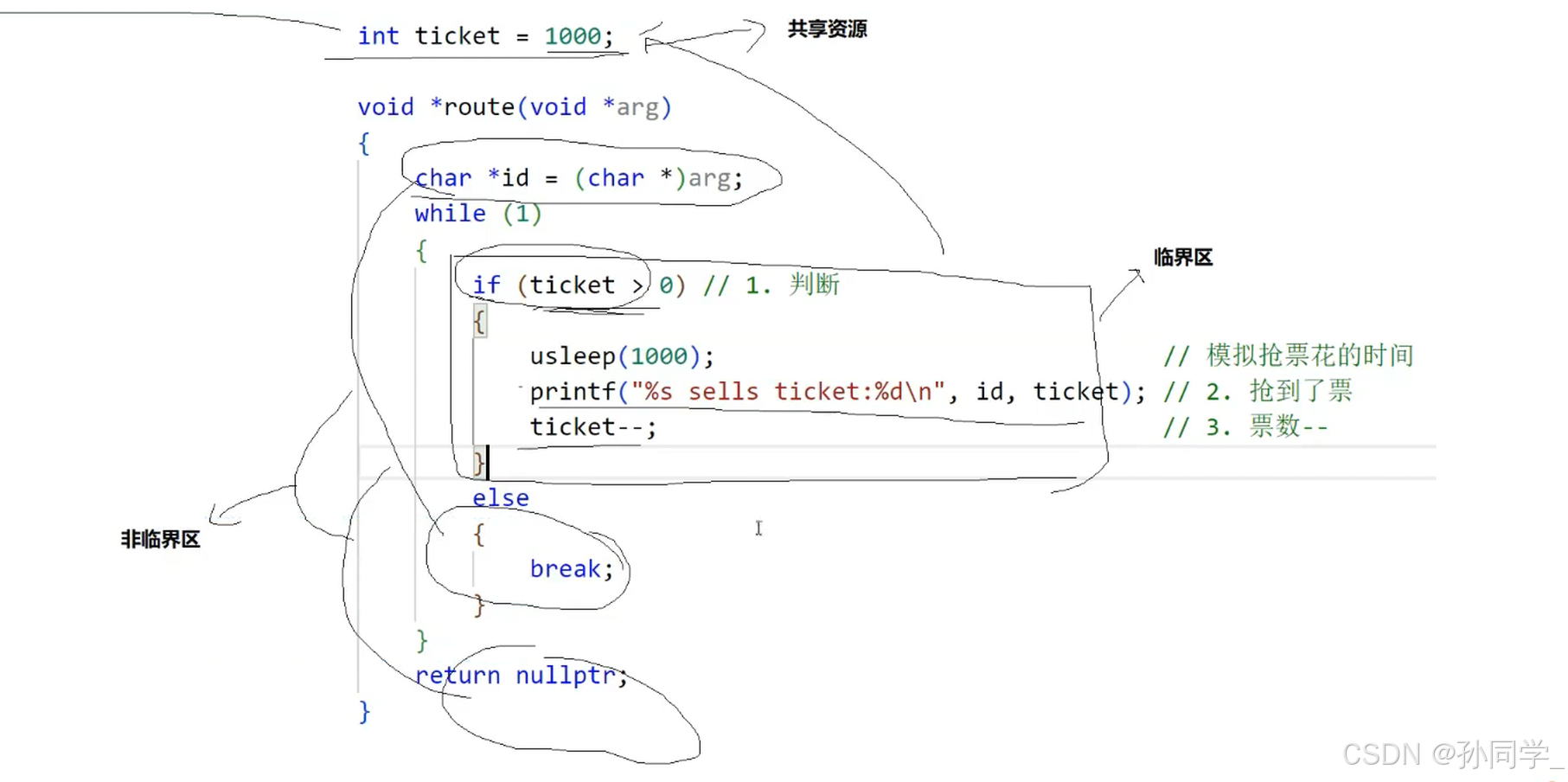
为什么会减到负数?
ticket--:对于ticket--操作不是原子的,只有cup能对ticket做减减操作
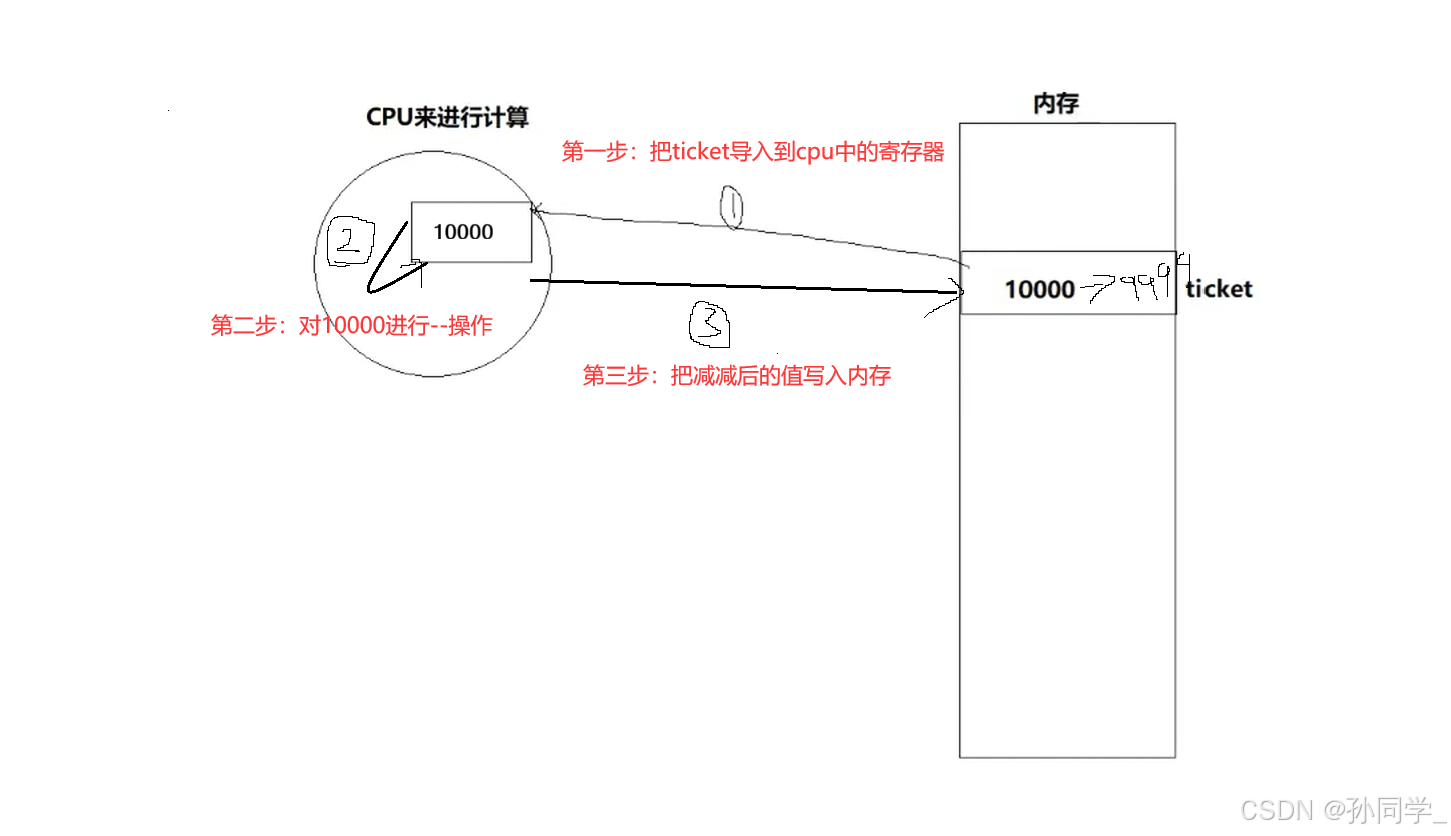
可能有人会说,ticket--不是一条语句吗?答案是ticket--是c语言,C语言是要变成汇编语言的,汇编语言就会把c语言的ticket--操作转化为上面的三步。
cpu为什么要对ticket做计算,为什么又要写回内存,本质是cpu正在执行一个进程或者线程的代码
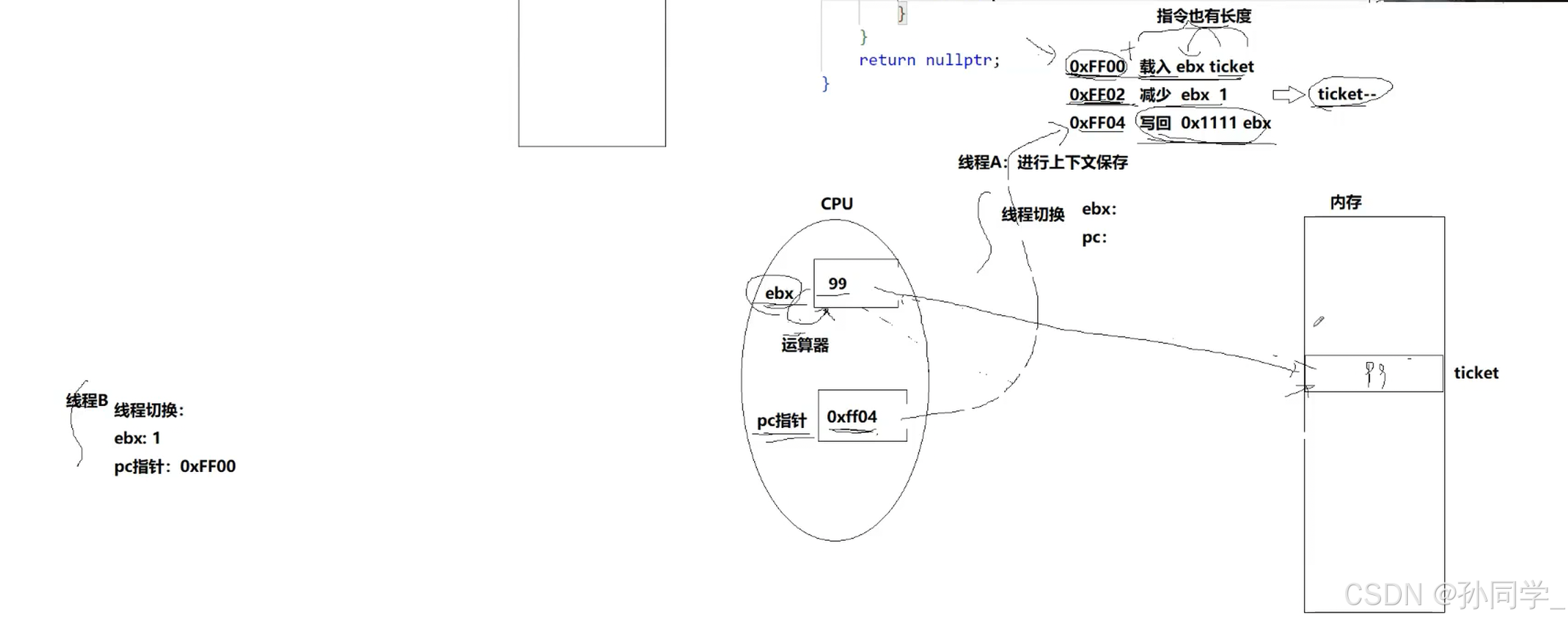
一个整数并不是原子的,在c语言ticket--操作时,c语言会被转化成三条汇编,三条汇编之间任意一个位置都有可能发生线程中断切换,然后换入下一个线程,又因为线程之间资源是共享的,所以ticket--并不是原子的。
上面的并不是ticket减到负数的主要原因,ticket减到负数的原因是
·
上面的对ticket做判断也是一种计算,这种是 逻辑运算,所以判断行为也由cpu完成。本来ticket已经等于1了,但是由于多个线程同时在内部串行式的对ticket做减减,所以ticket减到了负数。
上面的所有都是告诉我们一件事,一个全局的资源没有加保护,可能会在多线程指执行的时候出现并发问题。
抢票问题的前提是我们要在多线程中制造更多的并发和更多的切换。
切换的时间点是什么?
- 时间片耗尽
- 调用了阻塞式I/O
- 挂起或者休眠的函数
上面的全都是陷入内核
选择新的:从内核态转化为用户态的时候,进行检查
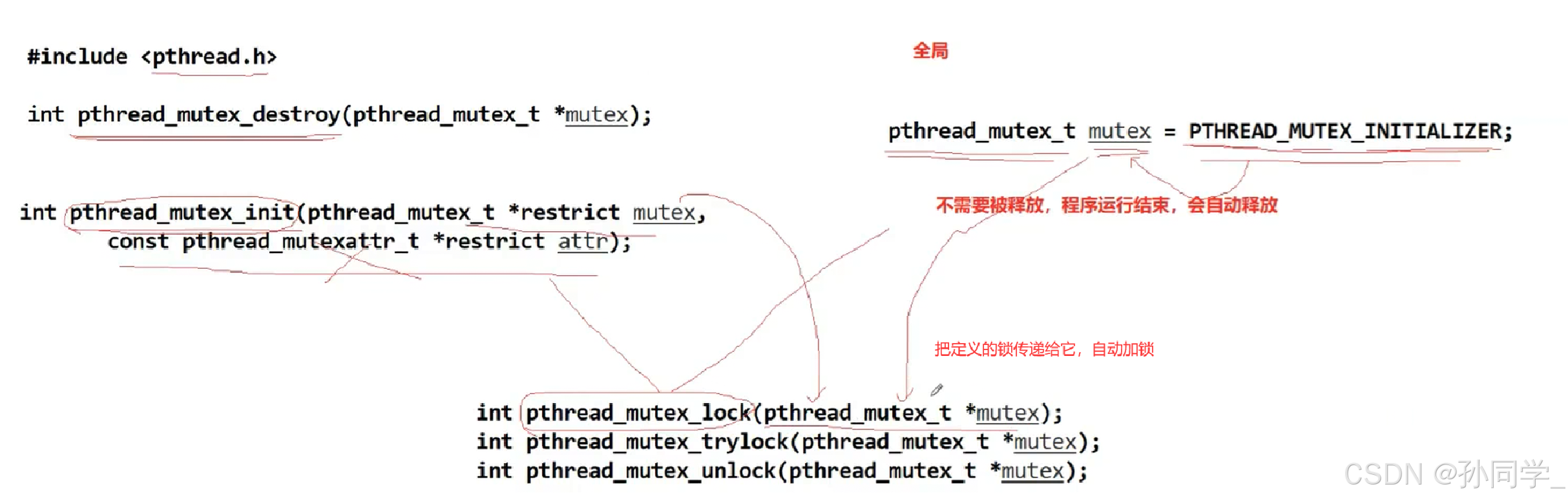
引入锁
pthread_mutex_t:互斥锁/互斥量

使用方式:
1.定义全局的锁 :用pthread_mutex_t mutex= PTHREAD MUTEX INITIALIZER;初始化
不需要释放,程序运行结束,自动释放
2.定义局部的锁:用int pthread_mutex_init初始化,用int pthread_mutex _destroy(pthread mutext *mutex); 来释放。
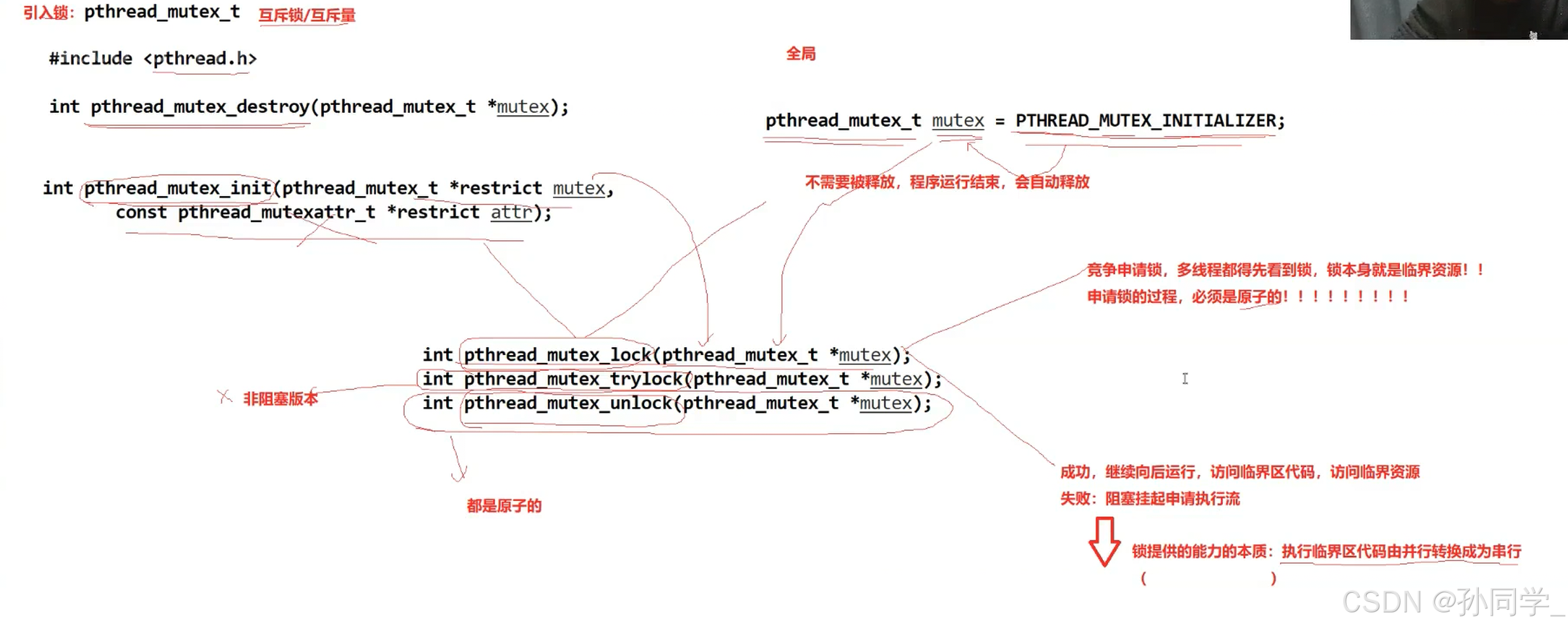
申请锁
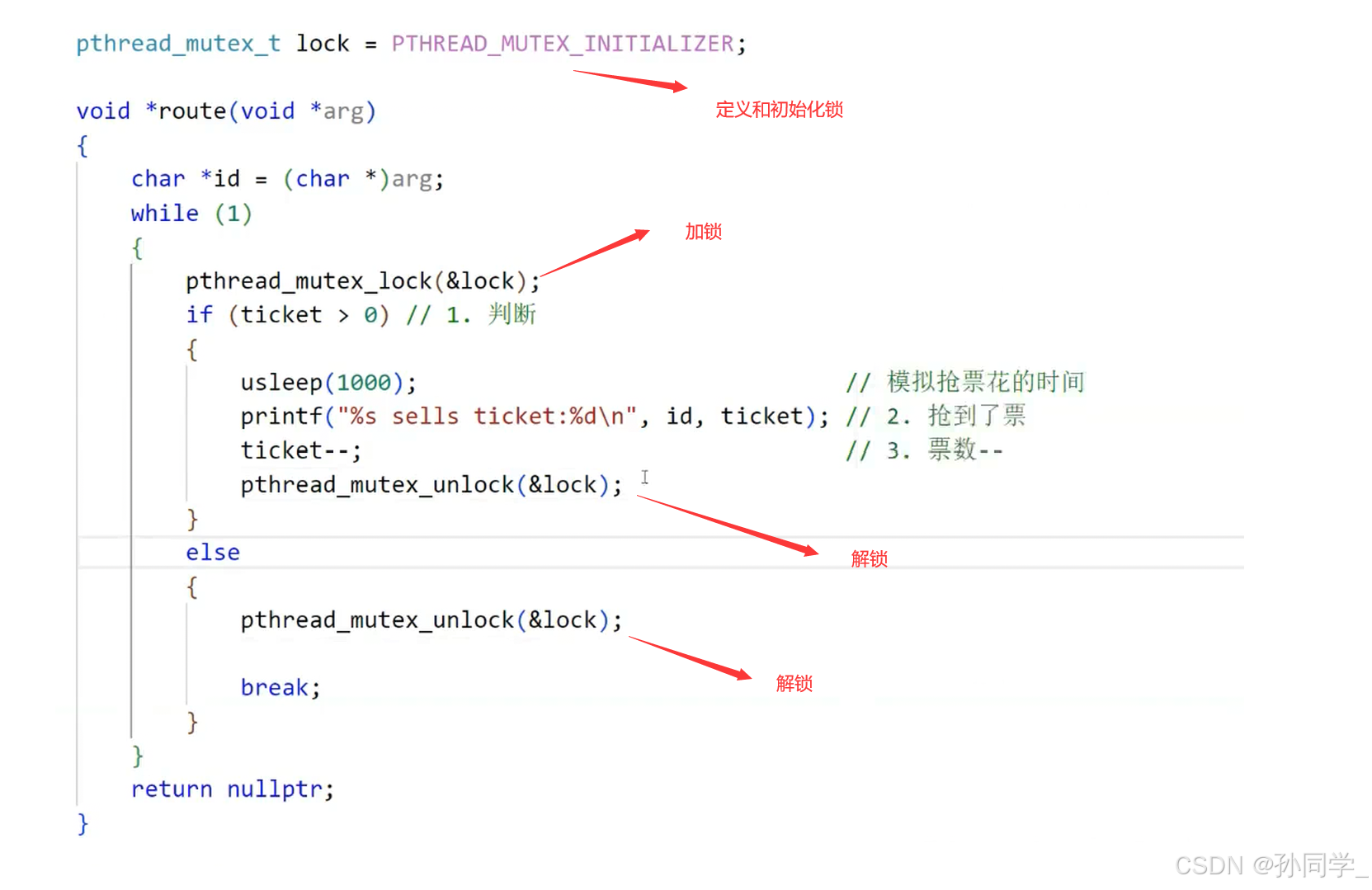
改进上面的售票系统:
cpp
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string>
#include <unistd.h>
#include <pthread.h>
class ThreadData
{
public:
ThreadData(const std::string &n,pthread_mutex_t &lock)
:name(n)
,lockp(&lock)
{}
~ThreadData(){}
std::string name;
pthread_mutex_t *lockp;
};
int ticket = 1000;
//加锁的规则:尽量加锁的范围力度要比较细,尽可能的不要包含太多的非临界区的代码
void* route(void* args)
{
ThreadData *td = static_cast<ThreadData*>(args);
while(1)
{
pthread_mutex_lock(td->lockp); //加锁
if(ticket > 0)
{
usleep(1000);
printf("%s sell ticket:%d\n",td->name.c_str(),ticket);
ticket--;
pthread_mutex_unlock(td->lockp); //解锁
}
else
{
pthread_mutex_unlock(td->lockp); //解锁
break;
}
}
return nullptr;
}
int main()
{
pthread_mutex_t lock;
pthread_mutex_init(&lock,nullptr); //初始化锁
pthread_t t1,t2,t3,t4;
ThreadData *td1 = new ThreadData("thread 1",lock);
pthread_create(&t1,nullptr,route,td1);
ThreadData *td2 = new ThreadData("thread 1",lock);
pthread_create(&t2,nullptr,route,td2);
ThreadData *td3 = new ThreadData("thread 1",lock);
pthread_create(&t3,nullptr,route,td3);
ThreadData *td4 = new ThreadData("thread 1",lock);
pthread_create(&t4,nullptr,route,td4);
pthread_join(t1,nullptr);
pthread_join(t2,nullptr);
pthread_join(t3,nullptr);
pthread_join(t4,nullptr);
pthread_mutex_destroy(&lock);
return 0;
}理解锁

加锁之后在临界区内部允许线程切换吗?切了会怎么样?
答案是临界区也是代码,整个代码都是允许随时切换的,因为当前的线程并没有释放锁,当前线程是持有锁被切换的,即便我不存在,其他线程也得等我回来执行完代码,释放锁,其他线程才能展开锁的竞争,进入临界区。
锁的原理:
- 硬件级实现:关闭时钟中断
我们的代码为什么不是原子的?因为我们的代码经过编译形成的汇编指令不是一条的,有大量的代码块,这就存在我们的进程随时都会被切换。那么为什么会被切换呢?时间片到了,操作系统一直在做中断调度,一直做中断,一直检测我的时间片,一旦调度就会存在进程切换,一切换代码不就交叉了,所以锁的实现最简单的硬件级操作就是关闭时钟中断 - 软件级实现:互斥锁
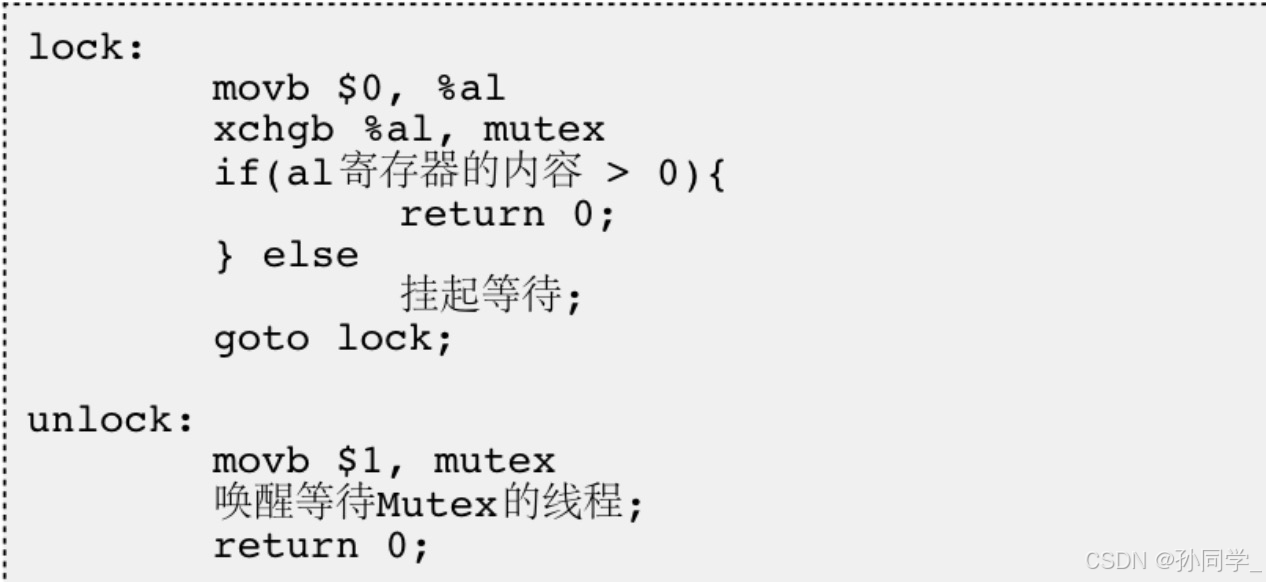
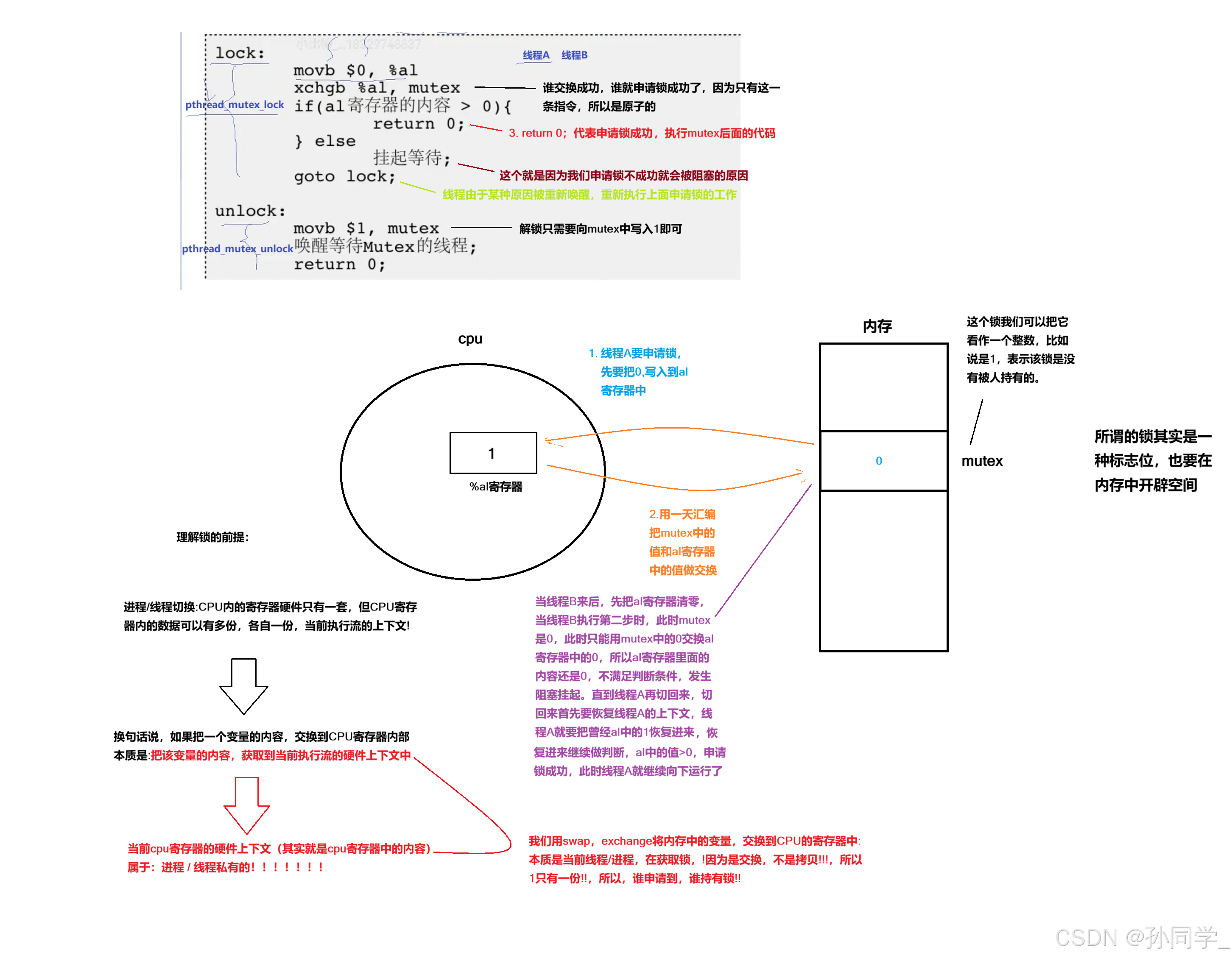
1.3 互斥量实现原理探究
- 经过上面的例子,大家已经意识到单纯的
i++或者++i都不是原子的,有可能会有数据不一致性问题 - 为了实现互斥锁操作,大多数体系结构都提供了
swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。 现在我们把lock和unlock的伪代码改一下。
1.4 互斥量的封装
Mutex.hpp
cpp
#pragma once
#include <iostream>
#include <pthread.h>
namespace MutexModule
{
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_mutex,nullptr);
}
//加锁
void Lock()
{
int n = pthread_mutex_lock(&_mutex);
(void)n;
}
//解锁
void Unlock()
{
int n = pthread_mutex_unlock(&_mutex);
(void)n;
}
~Mutex()
{
pthread_mutex_destroy(&_mutex);
}
private:
pthread_mutex_t _mutex;
};
//锁是成对出现的,我们希望加完锁在程序运行结束后自己解锁怎么办呢?
class LockGuard
{
public:
LockGuard(Mutex &mutex):_mutex(mutex)
{
_mutex.Lock();
}
~LockGuard()
{
_mutex.Unlock();
}
private:
Mutex &_mutex;
};
}TestMutex.cpp
cpp
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string>
#include <unistd.h>
#include <pthread.h>
#include "Mutex.hpp"
using namespace MutexModule;
int ticket = 1000;
class ThreadData
{
public:
ThreadData(const std::string &n, Mutex &lock)
: name(n), lockp(&lock)
{
}
~ThreadData() {}
std::string name;
Mutex *lockp;
};
// 加锁的规则:尽量加锁的范围力度要比较细,尽可能的不要包含太多的非临界区的代码
void *route(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
while(1)
{
LockGuard guard(*td->lockp);//加锁完成,RAII风格的互斥锁的实现
if(ticket > 0)
{
usleep(1000);
printf("%s sells ticket:%d\n",td->name.c_str(),ticket);
ticket--;
}
else
{
break;
}
}
// while (1)
// {
// //pthread_mutex_lock(td->lockp); // 加锁
// td->lockp->Lock();
// if (ticket > 0)
// {
// usleep(1000);
// printf("%s sell ticket:%d\n", td->name.c_str(), ticket);
// ticket--;
// //pthread_mutex_unlock(td->lockp); // 解锁
// td->lockp->Unlock();
// }
// else
// {
// //pthread_mutex_unlock(td->lockp); // 解锁
// td->lockp->Unlock();
// break;
// }
// }
return nullptr;
}
int main()
{
// pthread_mutex_t lock;
// pthread_mutex_init(&lock, nullptr); // 初始化锁
Mutex lock;
pthread_t t1, t2, t3, t4;
ThreadData *td1 = new ThreadData("thread 1", lock);
pthread_create(&t1, nullptr, route, td1);
ThreadData *td2 = new ThreadData("thread 2", lock);
pthread_create(&t2, nullptr, route, td2);
ThreadData *td3 = new ThreadData("thread 3", lock);
pthread_create(&t3, nullptr, route, td3);
ThreadData *td4 = new ThreadData("thread 4", lock);
pthread_create(&t4, nullptr, route, td4);
pthread_join(t1, nullptr);
pthread_join(t2, nullptr);
pthread_join(t3, nullptr);
pthread_join(t4, nullptr);
// pthread_mutex_destroy(&lock);
return 0;
}2. 线程同步
2.1 条件变量
理解条件变量
现在有一批人往盘子里面放苹果,这个盘子只能放一个苹果,这个人的眼睛是被蒙住的,并不知道盘子里面有没有苹果。于此同时还有一批人是在盘子里面拿苹果的,这批人的眼睛也是被蒙住的。这个盘子就是公共资源,当正向盘子里面放苹果的时候,拿苹果的人在盘子中不一定能拿到苹果。盘子是临界资源。我们规定这两个人往盘子里面拿放苹果都必须得加锁。所以拿放苹果的人首先都得先申请钥匙,放苹果的人首先得先申请钥匙,然后打开锁,将苹果放入盘子中,关闭锁。拿苹果的人首先也得申请钥匙,打开锁,在检测盘子里面有没有苹果,有苹果就直接拿,没有苹果就直接退出。如果是纯互斥,双方都不知道盘子里面有没有苹果,都需要高频率的去竞争这把锁。因为放苹果的人不知道盘子中有没有苹果,所以就得申请这把锁,如果有苹果就释放这把锁,就会导致拿苹果的人出现饥饿问题。
由于这两个人都只是看不见,所以为了解决这个问题我们就引入一个新的东西,铃铛。我们得提供一个铃铛,另外我们也得提供一个队列。假设今天放苹果的人申请锁成功,就要检查盘子里面有没有苹果,没有苹果,把苹果放入盘子然后释放锁。它一旦把锁释放了,理论上来说它要继续申请锁,因为它并不知道对方是什么时候拿的苹果,盘子中有没有苹果。所以放苹果的人在放完苹果之后,把铃铛打一下,铃铛一敲此时放苹果的人什么也不干,就在那里等。拿苹果的人首先去申请锁,申请成功去检测盘子里面有没有苹果,没有苹果就继续申请锁。我们规定,如果拿苹果的人,盘子中没有苹果,这个人不能立即进行第二次申请锁,这个人必须去队列里面排队,当听到铃铛响了,醒来再去拿苹果。
我们把上面的铃铛+队列叫做条件变量。
- 当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
- 例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。
2.2 同步概念与竞态条件
高频的申请钥匙,没有做有效的动作,就会导致其他线程得不到钥匙(锁),其他线程就会产生饥饿问题。
纯互斥没有错,但是纯互斥不高效,对其他线程不太公平。
我们就规定,刚申请完锁的线程不能立即申请第二次。
外面的线程必须得排队等,退出的线程必须跑到队列的尾部,进行二次申请。
- 同步: 在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步。
- 竞态条件: 因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解。
2.3 条件变量函数
调用条件变量和调用互斥锁相同,都有两种调用方式
- 全局/静态(static):
pthread_cond_t cond = PTHREAD_COND_INITIALIZER,用全局的定义条件变量也不用去销毁它。 - 定义局部:
初始化int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr)
第一个参数是要定义的条件变量,第二个参数是我们要定义的全局变量的属性(一般我们不用管设为空)
销毁:int pthread_cond_destroy(pthread_cond_t *cond)
当拿苹果的人从盘子中拿苹果,但万一盘子中没苹果呢?检测没有苹果退出,退出之后此线程就不能重新申请锁了,应转而将此线程投入到队列中进行阻塞等待,在哪等呢?在条件变量下等,所以条件变量要为我们提供一个Wait接口。
cpp
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
第一个参数表示的是调用该函数的线程就要在指定的条件变量下进行等待。
第二个参数是一把互斥锁,后面解释
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex,const struct timespec *restrict abstime);
前两个参数和上面的一摸一样,第三个参数为时间参数,可以设置等待时长,比如5秒10秒,它在条件变量下等时,如果等的时间超时了,它会自己醒来。放苹果的人在放完苹果之后要把条件变量进行唤醒,敲这个铃铛,唤醒条件变量来唤醒在该条件变量下等待的线程。拿苹果的人关注的是把自己放在队列里,而放苹果的人关注的是我要唤醒同一个条件变量。
唤醒在条件变量下等待的线程。
cpp
int pthread_cond_broadcast(pthread_cond_t *cond);
唤醒指定条件变量下等待的所有的线程
int pthread_cond_signal(pthread_cond_t *cond);
唤醒在该条件变量下等待的一个线程生产者消费者模型
在现实生活中,工厂(生产者)向超市供货,而超市让用户(消费者)在超市消费,这就是我们显示生活中的生产者消费者模型。
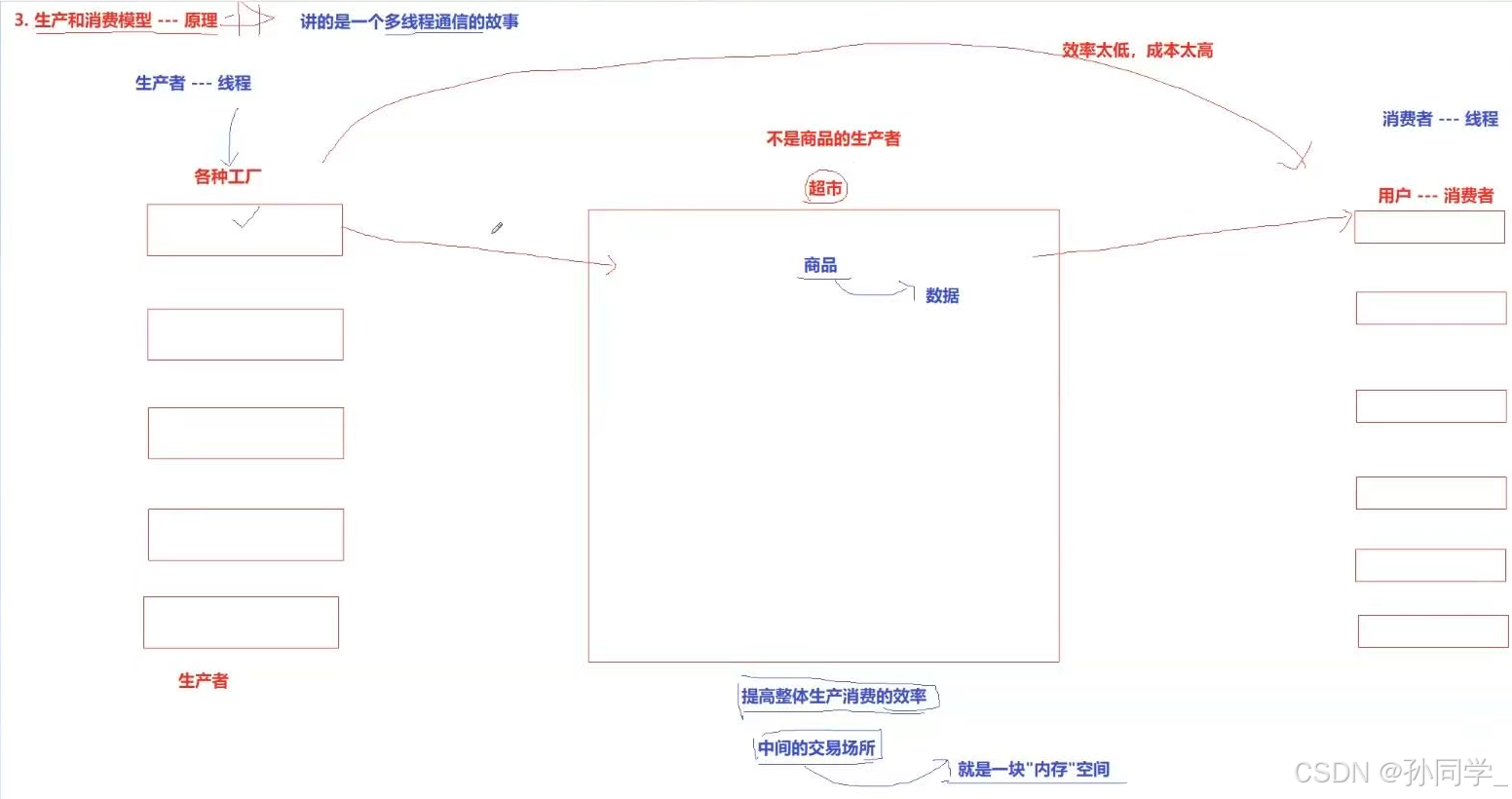
用户为什么不直接从工厂中拿商品?效率太低,成本太高
超市存在的意义:提高整体生产消费的效率
生产者消费者模型讲的是一个多线程通信的故事。
有若干个线程,会生产对应的数据,然后向中间的内存空间里去写数据,另外一个线程再从中间的内存空间去读数据,然后进行数据的处理。这种模式就叫做生产者消费者模型,它的本质是多线程通信安全的问题。
生产者消费者模型:
生产者s,消费者s,一个交易场所(一种临界资源)
- 三种关系。
生产者之间:竞争关系,即互斥关系
消费者和消费者之间:竞争关系,即互斥关系
生产者和消费者之间:互斥关系和同步关系 - 两种角色
生产者角色和消费者角色(线程承担) - 一个交易场所:以特定结构构成的一种"内存"空间
"3,2,1"原则
为什么要有生产者消费者模型??
好处:
- 生产过程和消费过程解耦
- 支持忙闲不均(因为有缓存)
- 提高效率
编写基于blockqueue的生产者消费者模型
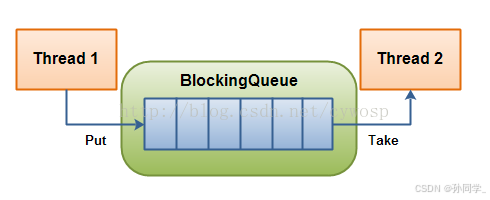
阻塞队列是我们可以让一个或者多个线程向队列里面放数据,另一个线程可以在该队列里面拿数据,这就是一个典型的生产者消费者模型。那么Thread1就代表着生产者,Thread2就代表这消费者,blockingQueue代表着交易场所。
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)
1.单生产,单消费
生产和消费的过程,本来就是互斥加锁,串行的,怎么提高效率?
提高效率:不是体现在入交易场所和出交易场所上,而在于未来获取任务和处理具体的任务,是并发的。
2.多生产,多消费
阻塞队列的代码实现:
cpp
// 阻塞队列的实现
#pragma once
#include <iostream>
#include <string>
#include <queue>
#include <pthread.h>
const int defaultcap = 5; // for test
template <typename T>
class BlockQueue
{
private:
bool IsFull() { return _q.size() >= _cap; }
bool IsEmpty() { return _q.empty(); }
public:
BlockQueue(int cap = defaultcap)
: _cap(cap), _csleep_num(0), _psleep_num(0)
{
pthread_mutex_init(&_mutex,nullptr); // 对锁初始化
pthread_cond_init(&_full_cond, nullptr);
pthread_cond_init(&_empty_cond, nullptr);
}
void Equeue(const T &in)
{
pthread_mutex_lock(&_mutex);
// 生产者调用
while (IsFull())
{
// 应该让生产者等待
// 重点一:pthread_cond_wait调用成功,挂起当前线程之前,要先自动释放锁!!!
// 重点二:当线程被唤醒时,默认就在临界区内唤醒!
// 要从pthread_cond_wait成功返回,需要当前线程,从新申请------mutex锁!
// 重点三:如果我被唤醒了,但是申请锁失败了???我就在锁上阻塞等待!!!
_psleep_num++;
std::cout << "生产者,进入休眠了:_psleep_num" << _psleep_num << std::endl;
// 问题一:pthread_cond_wait是函数吗?有没有可能失败?如果失败pthraad_cond_wait立即返回了,不就往队列中多添加了吗
// 问题二:pthread_cond_wait可能会因为,条件其实不满足,pthread_cond_wait 伪唤醒了
pthread_cond_wait(&_full_cond, &_mutex);
_psleep_num--;
}
// 100%确定:队列有空间
_q.push(in);
// //临时唤醒方案
// //v2
if (_csleep_num > 0) // 说明
{
pthread_cond_signal(&_empty_cond);
std::cout << "唤醒消费者..." << std::endl;
}
pthread_mutex_unlock(&_mutex);
}
T Pop()
{
// 消费者调用
pthread_mutex_lock(&_mutex);
while (IsEmpty())
{
_csleep_num++;
pthread_cond_wait(&_empty_cond, &_mutex);
_csleep_num--;
}
T data = _q.front();
_q.pop();
//
if (_psleep_num > 0)
{
pthread_cond_signal(&_full_cond);
std::cout << "唤醒生产者..." << std::endl;
}
// pthread_cond_signal(&_full_cond); // 放unlock前面可以,因为是在锁上等
pthread_mutex_unlock(&_mutex);
return data;
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_full_cond);
pthread_cond_destroy(&_empty_cond);
}
private:
std::queue<T> _q; // 临界资源
int _cap; // 容量大小
pthread_mutex_t _mutex;
pthread_cond_t _full_cond; // 当生产者生产满了,它要在这里面等
pthread_cond_t _empty_cond; // 消费者将整个队列消费为空时就得等,在这里面等
// 用两个条件变量的原因:因为用一个跳进啊变量的话我们还得区分它是生产者还是消费者,写起来比较麻烦
int _csleep_num; // 消费者休眠的个数
int _psleep_num; // 生产者休眠的个数
};2.4 POSIX信号量
信号和信号量的关系,信号和信号量之间的关系就如同老婆和老婆饼之间的关系,没有关系。
信号量也叫做信号灯,本质是一种计数器,表示临界资源的数量有多少。
多线程使用资源有两种场景:
1.将目标资源整体使用【锁技术或者是二元信号量】
2.将目标资源按照不同的"块",分批使用【信号量】
所有线程要访问公共资源就得先申请信号量,申请信号量就得先看到信号量sem,信号量本身就是计数器,申请信号量就是对信号量--操作,释放信号量就是对信号量进行++操作。信号量本质也是临界资源。
P:--:原子的
V:++:原子的
环形队列
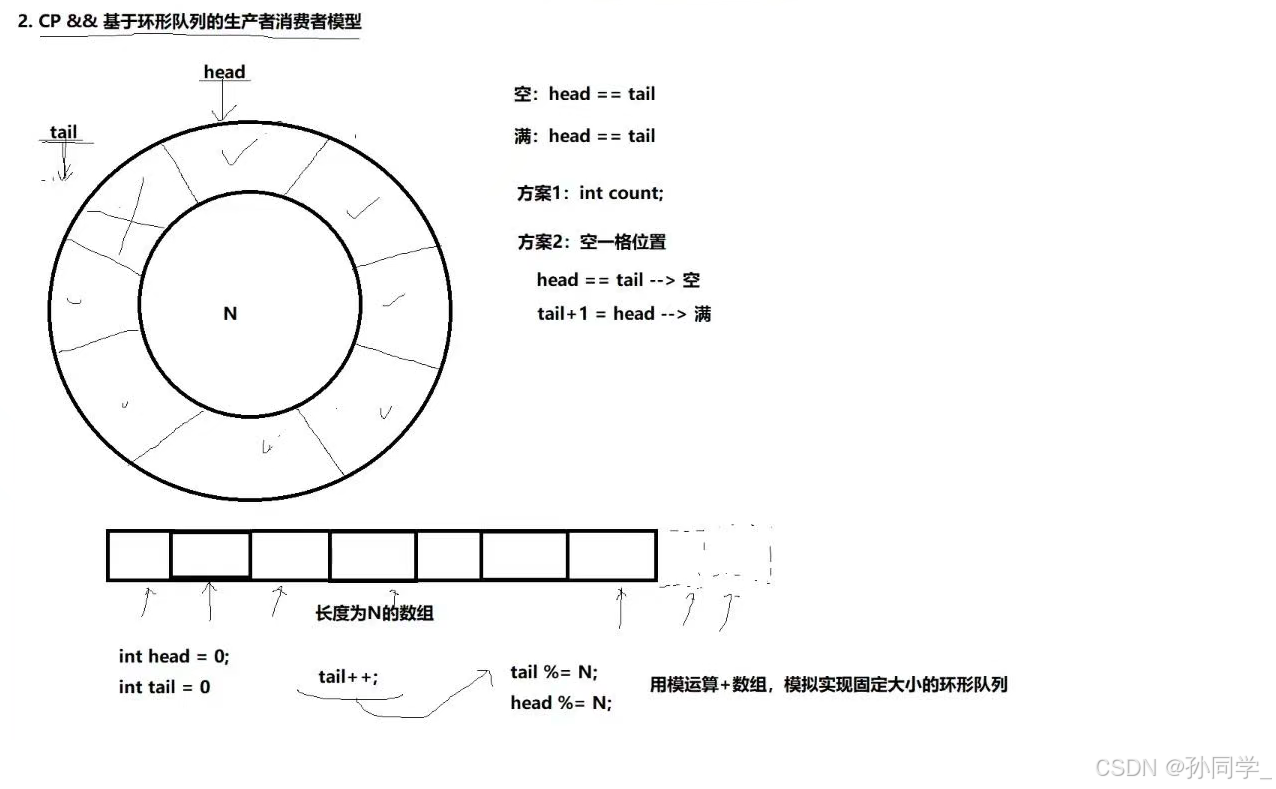
约定一:空,生产者先运行
约定二:满,消费者先运行
约定三:生产者不能把消费者套一个圈以上
约定四:消费者不能超过生产者
思考:
1.只要我们不访问同一个位置,我们就可以同时进行
2.什么时候,我们会在同一个位置?为空或者为满
如果不为空或者不为满,就能同时进行
3.为空:只能让生产者先运行
为满:只能让消费者先进来
结论:
1.在环形队列不为空并且不为满,生产者消费者可以同时进行
2.环形队列,为空或者为满的时候,生产和消费,需要同步互斥
怎么保证者四个约定呢?信号量保证
信号量是用来标记临界资源数据的数量的
生产者关心的资源是:环形队列中空的位置
消费者关心的资源是:环形队列中的有效数据
信号量是原子的,申请成功,继续运行,申请失败,申请的线程会被阻塞
熟悉接口
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。但POSIX可以用于线程间同步。
初始化信号量
cpp
#include <semaphore.h>
int sem init(sem t *sem, int pshared, unsigned int value);
参数:
sem_t:定义一个对象
pshared:0表示线程间共享,非零表示进程间共
value:信号量初始值销毁信号量
cpp
int sem_destroy(sem t *sem);等待信号量
cpp
功能:等待信号量,会将信号量的值减1
int sem_wait(sem t *sem);//P()操作发布信号量
cpp
功能:发布信号量,表示资源使用完毕,可以归还资源了。将信号量值加1。
int sem post(sem t *sem);//V()操作上一节生产者-消费者的例子是基于queue的,其空间可以动态分配,现在基于固定大小的环形队列重写这个程序(POSIX信号量)
基于环形队列的生产消费模型
- 环形队列采用数组模拟,用模运算来模拟环状特性
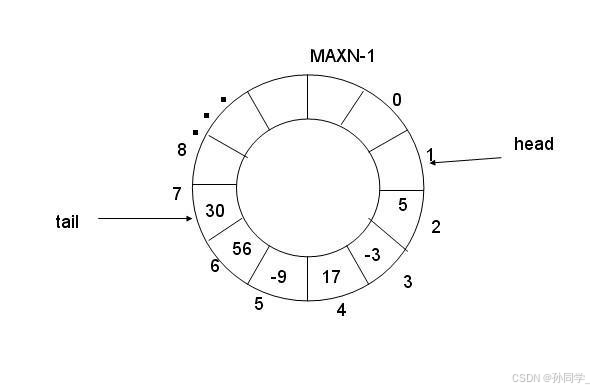
- 环形结构起始状态和结束状态都是一样的,不好判断为空或者为满,所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留⼀个空的位置,作为满的状态。
把加锁放在申请信号量之前还是把加锁放在申请信号量之后?
申请信号量本质是对资源的预定机制,先加锁再申请信号量相当于先排队,再买票。先申请信号量再加锁相当于先在网上买了票,再排队进入电影院。很明显是第二种效率更高,所有的线程先把信号量瓜分了,因为申请信号量本身就是原子性申请。然后再串行式的申请锁。
如果先申请锁,申请锁成功的人还得申请信号量,申请锁失败的线程还得先等你把锁释放了。
进一步理解信号量,为什么今天没有判断?因为信号量本身就是描述临界资源的数量的,信号量申请失败就是条件不满足。
信号量本质 :信号量把对临界资源是否存在?就绪?等条件,以原子性的形式,呈现在访问临界资源之前就判断了!!!
未来我们自己在实现信号量的同步和互斥的时候:
如果资源可以拆分 --------- 考虑信号量sem
如果资源是整体的 --------- 就是用互斥锁mutex
信号量的代码实现:
cpp
#include <iostream>
#include <semaphore.h>
#include <pthread.h>
namespace SemModule
{
const int defaultvalue = 1;
class Sem
{
public:
Sem(unsigned int sem_value)
{
sem_init(&_sem, 0 ,sem_value);
}
//P操作
void P()
{
int n = sem_wait(&_sem);//原子的
(void)n;
}
//V操作
void V()
{
int n = sem_post(&_sem);//原子的
(void)n;
}
~Sem()
{
sem_destroy(&_sem);
}
private:
sem_t _sem; //定义信号量
};
}ring_queue.hpp
cpp
#pragma once
#include <iostream>
#include <vector>
#include "Sem.hpp"
#include "Mutex.hpp"
static const int gcap = 5; // for test
using namespace SemModule;
using namespace MutexModule;
template <typename T>
class RingQueue
{
public:
RingQueue(int cap = gcap)
: _cap(cap), _rq(cap), _blank_sem(cap) // 刚开始时信号量的容量有多大,空格子的值就有多大
,
_p_step(0), _data_sem(0), _c_step(0)
{
}
void Equeue(const T &in)
{
// 生产者来执行
// 1. 申请信号量,空位置信号量
_blank_sem.P();
{
LockGuard lockguard(_pmutex);
// 2. 生产
_rq[_p_step] = in;
// 3. 更新下标
++_p_step;
// 4. 维持环形特性
_p_step %= _cap;
}
_data_sem.V();
}
void Pop(T *out)
{
// 消费者来执行
// 1. 申请信号量,数据信号量
_data_sem.P();
{
LockGuard lockguard(_cmutex);
// 2. 消费
*out = _rq[_c_step];
// 3. 更新下标
++_c_step;
// 4. 维持环形特性
_c_step %= _cap;
}
_blank_sem.V();
}
~RingQueue()
{
}
private:
std::vector<T> _rq;
int _cap;
// 生产者
Sem _blank_sem; // 关注的是空的格子的资源
int _p_step;
// 消费者
Sem _data_sem; // 数据
int _c_step;
// 维护多生产多消费 2把锁,一个用来维护生产者之间的关系,一个用来维护消费者之间的关系
Mutex _cmutex;
Mutex _pmutex;
};3. 线程池
3.1 日志概念
- 基本概念
cpp
[可读性很好的时间] [⽇志等级] [进程pid] [打印对应⽇志的⽂件名][⾏号] - 消息内容,⽀持可
变参数
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [16] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [17] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [18] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [20] - hello world
[2024-08-04 12:27:03] [DEBUG] [202938] [main.cc] [21] - hello world
[2024-08-04 12:27:03] [WARNING] [202938] [main.cc] [23] - hello world'
常见的日志等级:
DEBUG :表明这条日志是做测试的
INFO:常规消息
WARING:告警消息
ERROR:表明一条错误消息
FATAL:表明是一条错误消息
日志功能:
1.形成一条完整的日志
2.刷新到目标文件(显示器,指定文件打一日志)
日志的代码实现:
cpp
#ifndef __LOG_HPP__
#define __LOG_HPP__
#include <iostream>
#include <string>
#include <cstdio>
#include <filesystem> //c++17
#include <memory>
#include <sstream>
#include <fstream>
#include <ctime>
#include <unistd.h>
#include "Mutex.hpp"
namespace LogModule
{
using namespace MutexModule;
const std::string gsep = "\r\n";
// 策略模式
// 2. 刷新策略 a:向显示器打印 b:向指定文件写入
// 刷新策略基类
class LogStrategy
{
public:
~LogStrategy() = default;
virtual void SyncLog(const std::string &message) = 0;
};
// 显示器打印日志的策略:子类
class ConsoleLogStrategy : public LogStrategy
{
public:
ConsoleLogStrategy()
{
}
virtual void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::cout << message << gsep;
}
~ConsoleLogStrategy()
{
}
private:
Mutex _mutex;
};
// 文件打印日志的策略:子类
const std::string defaultpath = "./log";
const std::string defaultfile = "my.log";
class FileLogStrategy : public LogStrategy
{
public:
FileLogStrategy(const std::string &path = defaultpath, const std::string &file = defaultfile)
: _path(path), _file(file)
{
LockGuard lockguard(_mutex);
if (std::filesystem::exists(_path))
{ // 如果这个路径存在直接返回
return;
}
try
{
// 如果这个路径不存在
std::filesystem::create_directories(_path);
}
catch (const std::filesystem::filesystem_error &e)
{
std::cerr << e.what() << '\n';
}
}
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::string filename = _path + (_path.back() == '/' ? "" : "/") + _file; //"./log" + "my.log"
std::ofstream out(filename, std::ios::app); // 追加写入的方式打开
if (!out.is_open())
{
return;
}
out << message;
out.close();
}
~FileLogStrategy()
{
}
private:
std::string _path; // 日志文件所在路径
std::string _file; // 日志文件本身
Mutex _mutex;
};
// 形成一条完整的日志&&根据上面的策略,选择不同的刷新方式
// 1.形成日志等级
enum class LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
std::string Level2Str(LogLevel level)
{
switch (level)
{
case LogLevel ::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "INFO";
case LogLevel ::WARNING:
return "WARNING";
case LogLevel ::ERROR:
return "ERROR";
case LogLevel ::FATAL:
return "FATAL";
default:
return "UNKONWN";
}
}
std::string GetTimeStamp()
{
time_t curr = time(nullptr);
struct tm curr_tm;
localtime_r(&curr,&curr_tm);
char timebuffer[128];
snprintf(timebuffer,sizeof(timebuffer),"%4d-%02d-%02d %02d:%02d:%02d",
curr_tm.tm_year + 1900,
curr_tm.tm_mon + 1,
curr_tm.tm_mday,
curr_tm.tm_hour,
curr_tm.tm_min,
curr_tm.tm_sec
);
return timebuffer;
}
// 形成日志 && 2.根据不同的策略模式完成刷新
class Logger
{
public:
Logger()
{
EnableConsoleLogStrategy();
}
void EnableFileLogStrategy()
{
_fflush_strategy = std::make_unique<FileLogStrategy>();
}
void EnableConsoleLogStrategy()
{
_fflush_strategy = std::make_unique<ConsoleLogStrategy>();
}
// 内部类,主要表示的是未来的一条日志
class LogMessage
{
public:
LogMessage(LogLevel &level, std::string &src_name, int line_number, Logger &logger)
: _curr_time(GetTimeStamp()), _level(level), _pid(getpid()), _src_name(src_name), _line_number(line_number), _logger(logger)
{
// 日志的左半部分合并到loginfo中
std::stringstream ss;
ss << "[" << _curr_time << "]"
<< "[" << Level2Str(_level) /*?*/ << "]"
<< "[" << _pid << "]"
<< "[" << _src_name << "]"
<< "[" << _line_number << "]"
<< "-";
_loginfo = ss.str();
}
// LogMessage() << "hello world" << "XXXX" << 3.14 << 1234
template <typename T>
LogMessage &operator<<(const T &info)
{
// 日志的右半部分,可变的
std::stringstream ss;
ss << info;
_loginfo += ss.str();
return *this;
}
~LogMessage()
{
if (_logger._fflush_strategy)
{
_logger._fflush_strategy->SyncLog(_loginfo);
}
}
private:
std::string _curr_time;
LogLevel _level;
pid_t _pid;
std::string _src_name;
int _line_number;
std::string _loginfo; // 合并之后,一条完整的信息
Logger &_logger;
};
// 这里故意写成返回临时对象
LogMessage operator()(LogLevel level, std::string name, int line)
{
return LogMessage(level, name, line, *this);
}
~Logger()
{
}
private:
std::unique_ptr<LogStrategy> _fflush_strategy;
};
// 全局日志对象
Logger logger;
//使用宏,简化用户操作,获取文件名行号
#define LOG(level) logger(level,__FILE__,__LINE__)
#define Enable_Console_Log_Strategy() logger.EnableConsoleLogStrategy()
#define Enable_File_Log_Strategy() logger.EnableFileLogStrategy()
}
#endif3.2 线程池的设计
线程池:
一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
线程池的应用场景:
- 需要大量的线程来完成任务,且完成任务的时间比较短。比如WEB服务器完成网页请求这样的任.务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。但对于长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
- 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程可能使内存到达极限,出现错误.
线程池的种类
a.创建固定数量线程池,循环从任务队列中获取任务对象,获取到任务对象后,执行任务对象中的任务接口
b.浮动线程池,其他同上
此处,我们选择固定线程个数的线程池。
线程池的代码实现:
cpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <queue>
#include "Log.hpp"
#include "Thread.hpp"
#include "Cond.hpp"
#include "Mutex.hpp"
namespace ThreadPoolModule
{
using namespace ThreadModule;
using namespace LogModule;
using namespace CondModule;
using namespace MutexModule;
static const int gnum = 5;
template <typename T>
class ThreadPool
{
private:
void WakeUpAllThread()
{
LockGuard lockguard(_mutex);
if (_sleepernum) // 大于0
_cond.Broadcast();
LOG(LogLevel::INFO) << "唤醒所有的休眠线程";
}
void WakeUpOne()
{
_cond.Signal();
LOG(LogLevel::INFO) << "唤醒一个线程";
}
ThreadPool(int num = gnum) : _num(num), _isrunning(false), _sleepernum(0)
{
for (int i = 0; i < num; i++)
{
_threads.emplace_back(
[this]()
{
HandlerTask();
});
}
}
void Start()
{
if (_isrunning)
return;
_isrunning = true;
for (auto &thread : _threads)
{
thread.Start();
LOG(LogLevel::INFO) << "start new thread success:" << thread.Name();
}
}
// 我们不允许将来有人拿单例做赋值或者是拷贝
ThreadPool(const ThreadPool<T> &) = delete; // 去掉拷贝构造
ThreadPool<T> &operator=(const ThreadPool<T> &) = delete; // 去掉赋值运算符
public:
static ThreadPool<T> *GetInstance() // static方法属于类
{
if (inc == nullptr)
{
LockGuard lockguard(_lock);
LOG(LogLevel::DEBUG) << "获取单例.....";
if (inc == nullptr)
{
LOG(LogLevel::DEBUG) << "首次使用单例,创建之.....";
inc = new ThreadPool<T>();
inc->Start();
}
}
return inc;
}
void Stop()
{
if (!_isrunning)
return;
_isrunning = false;
// 唤醒所有线程
WakeUpAllThread();
}
void Join()
{
for (auto &thread : _threads)
{
thread.Join();
}
}
void HandlerTask()
{
char name[128]; // char name 缓冲区在自己的每一个独立栈上开辟的
pthread_getname_np(pthread_self(), name, sizeof(name));
while (true)
{
T t;
{
LockGuard lockguard(_mutex);
// 1.当线程池被唤醒 a.队列是否为空 b.线程池没有退出
while (_taskq.empty() && _isrunning)
{
_sleepernum++;
_cond.Wait(_mutex);
_sleepernum--;
}
// 2.内部的线程被唤醒
if (!_isrunning && _taskq.empty())
{
LOG(LogLevel::INFO) << name << "退出了,线程池退出 && 任务队列为空";
break;
}
// 一定有任务
t = _taskq.front();
_taskq.pop();
}
t(); // 处理任务,需要在临界区内部处理吗?不需要,从q中获取任务,任务就已经是线程私有的了!!!
}
}
bool Enqueue(const T &in)
{
if (_isrunning)
{
LockGuard lockguard(_mutex);
_taskq.push(in);
if (_threads.size() == _sleepernum == 0)
WakeUpOne();
return true;
}
return false;
}
~ThreadPool()
{
}
private:
std::vector<Thread> _threads;
int _num; // 表示线程池当中线程的个数
std::queue<T> _taskq;
Cond _cond;
Mutex _mutex;
bool _isrunning;
int _sleepernum; // 代表当前有多少线程休眠
// 线程池对象的静态指针
static ThreadPool<T> *inc; // 单例指针
static Mutex _lock;
};
template <typename T>
ThreadPool<T> *ThreadPool<T>::inc = nullptr; // 类内的静态成员在类外初始化
template <typename T>
Mutex ThreadPool<T>::_lock;
}当我们的线程退出 _isrunning == false;
内部线程的状态?
1.等待
2.等待唤醒(从条件变量中唤醒)
3.处理任务
线程池推出的时候,内部的任务应该被完全取完 && _isrunning(false)
上面的这两个条件满足,线程才能退出
反面:队列中还有任务并且_isrunning(true)
3.3 线程安全的单例模式
3.3.1 什么是单例模式
单例模式(Singleton Pattern)是一种创建型设计模式 ,其核心目标是确保一个类在整个应用程序生命周期中仅有一个实例,并提供全局访问点来访问该实例。这种模式常用于管理共享资源(如数据库连接池、配置管理器、日志记录器等),避免重复创建对象导致的资源浪费或状态不一致问题。
3.3.2 单例模式的特点
-
唯一实例:类自身负责创建并维护唯一实例。
-
全局访问:通过静态方法或属性提供全局访问入口。
-
延迟初始化(可选):实例在首次使用时才创建,节省资源。
-
线程安全(需考虑):在多线程环境下需确保实例的唯一性。
3.3.3 饿汉实现方式和懒汉实现方式
洗碗的例子
吃完饭,立刻洗碗,这种就是饿汉方式。因为下一顿吃的时候可以立刻拿着碗就能吃饭。
吃完饭,先把碗放下,然后下一顿饭用到这个碗了再洗碗,这就是懒汉方式。
懒汉方式的最核心的思想是"延时加载",从而能够优化服务器的启动速度。
饿汉方式实现单例模式
cpp
template <typename T>
class Singleton
{
static T data;//静态成语属于类,而不属于对象,当这个类被加载到内存的时候,这个data就被创建出来了
//当访问这个对象的时候,不用创建了,它在加载的时候就已经帮我们创建好了
public:
static T* GetInstance()
{
return &data;
}
};饿汉模式如果对应的这个类体积特别的大,它会导致在形成进程的时候,把二进制文件load到内存时的时间变长
懒汉方式实现单例模式
cpp
template <typename T>
class Singleton
{
static T* inst; //不需要加载进程时就把地址空间构建出来,只需要定义个指针就行,定义指针4个或者8个字节体积很小,所以创建这个
//inst对象时并不会花太多时间,当未来真正需要这个单例的时候,判断一下这个指针,这个指针如果为空,才给我们创建这个对象
public:
static T* GetInstance()
{
if(inst == NULL)
{
inst = new T();
}
return inst;
}
};懒汉就是一种延迟申请
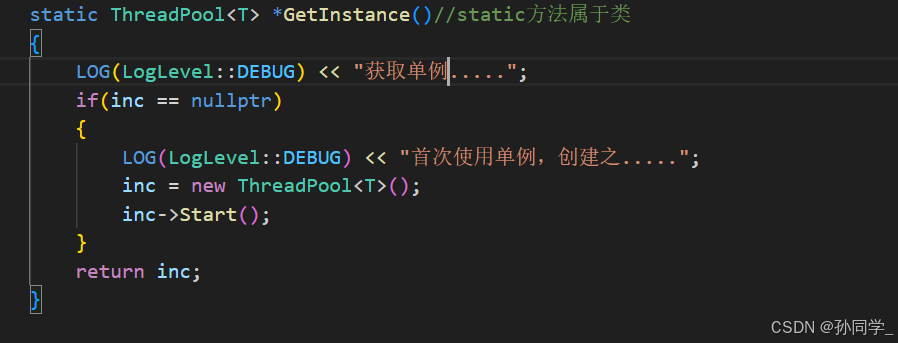
如果今天有多个线程并发式的GetInstance获取单例,每个线程读取inc的时候都认为inc为空。此时就会有多个进程创建单例,存在内存泄漏问题。
所以我们就得加锁,由于创建单例时的对象还不存在,所以锁也就不存在,所以我们就得再创建一把锁,这把锁也应该是static的。
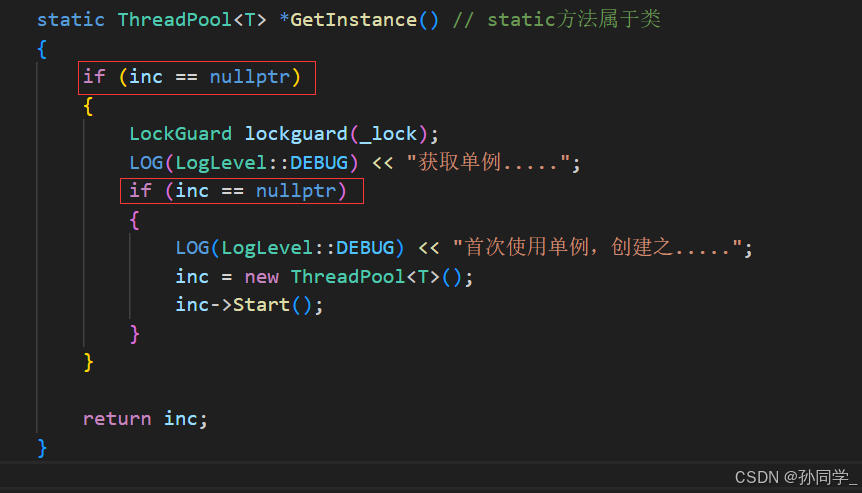
如果有多个线程并发的进来了,如inc不为空,直接返回单例。如果inc为空,说明这个对象还没有创建出来,进来之后首先要加锁,加锁之后只有一个线程创建单例成功。从此往后所有线程再获取单例时,inc==nullptr不满足,直接返回,再也不用加锁了,采用双重判断的方式提高获取单例的效率。
线程安全:讨论的是线程本身的健康或者安全状态
能被重入或者不能被重入:描述的是一个函数的特征

常见的锁概念
在单线程的前提下有没有可能产生死锁呢?
答案是可能的
👍 如果对你有帮助,欢迎:
- 点赞 ⭐️
- 收藏 📌
- 关注 🔔