分布式消息队列kafka【三】------ 生产者进阶提升
文章目录
- [分布式消息队列kafka【三】------ 生产者进阶提升](#分布式消息队列kafka【三】—— 生产者进阶提升)
kafka生产者发送消息源码分析
-
发送消息:ProducerRecord
javapublic class ProducerRecord<K, V> { private final String topic; private final Integer partition; private final Headers headers; private final K key; private final V value; private final Long timestamp; } -
属性详解
- topic:消息发送的主题
- partition:分区,可以指定,不指定kafka内部会计算
- headers:自定义的一些属性
- key:消息选择分区的时候会用这个key作计算
- value:具体消息体内容
- timestamp:这条消息发送到kafka的时间
-
必要的参数配置项:
- bootstrap.servers:连接kafka集群的地址,ip+port组成,多个用英文逗号,隔开
- 注意:并不是需要配置集群所有的broker地址,生产者会从给定的broker地址找到集群其他的broker地址。但是在实际工作中不建议只写集群中某个或者某几个,建议全写。因为假设这几个节点宕机,生产者就找不到kafka集群了
- key.serializer和value.serializer:因为Kafka Broker在接收消息的时候,必须要以二进制的方式接收,所以必须要对key以及value做序列化
- client.id:这个属性的目的是标记kafka生产者的ID,不设置默认kafka会生成一个非空的字符串
- bootstrap.servers:连接kafka集群的地址,ip+port组成,多个用英文逗号,隔开
-
简化配置Key:ProducerConfig类,例如:ProducerConfig.BOOTSTRAP_SERVERS_CONFIG
-
KafkaProducer是线程安全的,可以在多线程中共享同一个KafkaProducer实例对象,也可以将KafkaProducer池化封装供其他线程或者线程池调用
-
KafkaConsumer不是线程安全的
-
消息内容ProducerRecord的构造方法:
javapublic ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) { if (topic == null) { throw new IllegalArgumentException("Topic cannot be null."); } else if (timestamp != null && timestamp < 0L) { throw new IllegalArgumentException(String.format("Invalid timestamp: %d. Timestamp should always be non-negative or null.", timestamp)); } else if (partition != null && partition < 0) { throw new IllegalArgumentException(String.format("Invalid partition: %d. Partition number should always be non-negative or null.", partition)); } else { this.topic = topic; this.partition = partition; this.key = key; this.value = value; this.timestamp = timestamp; this.headers = new RecordHeaders(headers); } } public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) { this(topic, partition, timestamp, key, value, (Iterable)null); } public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) { this(topic, partition, (Long)null, key, value, headers); } public ProducerRecord(String topic, Integer partition, K key, V value) { this(topic, partition, (Long)null, key, value, (Iterable)null); } public ProducerRecord(String topic, K key, V value) { this(topic, (Integer)null, (Long)null, key, value, (Iterable)null); } public ProducerRecord(String topic, V value) { this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null); } -
KafkaProducer发送消息的方法:
javapublic void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException { this.throwIfNoTransactionManager(); TransactionalRequestResult result = this.transactionManager.sendOffsetsToTransaction(offsets, consumerGroupId); this.sender.wakeup(); result.await(); } public Future<RecordMetadata> send(ProducerRecord<K, V> record) { return this.send(record, (Callback)null); } public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); return this.doSend(interceptedRecord, callback); } -
KafkaProducer消息发送重试机制
- retries参数设置
- 可重试异常&不可重试异常
- 可重试异常:比如网络抖动导致请求未发送成功
- 不可重试异常:磁盘满了、消息体过大导致kafka报异常
kafka生产者发送消息最佳实战
ps:对于一个新的主题,kafka默认是可以在没有主题的情况下创建的。但是,自动创建主题的特性,在生产环境中一定是禁用的。
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_NORMAL = "topic-normal";
}生产者
java
package com.bfxy.kafka.api.producer;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.errors.LeaderNotAvailableException;
import org.apache.kafka.common.errors.NetworkException;
import org.apache.kafka.common.errors.RecordTooLargeException;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.Future;
public class NormalProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "normal-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// kafka消息的重试机制:RETRIES_CONFIG参数默认是0
// 作用是如果发送失败,判断是否属于可重试异常,如果可以重试,则放入队列等待再次轮询,如果不可以重试则抛出异常,由业务方catch处理
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 可重试异常
// org.apache.kafka.common.errors.NetworkException:比如网络产生一些异常抖动没有收到请求或者响应,或者消息没发出去
// org.apache.kafka.common.errors.LeaderNotAvailableException:比如当前一刹那kafka集群没有leader,可能正在选举的过程中
// 不可重试异常
// org.apache.kafka.common.errors.RecordTooLargeException:消息体过大
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
User user = new User("001", "xiao xiao");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_NORMAL, JSON.toJSONString(user));
/**
* 一条消息必须通过key去计算出来实际的partition,按照partition去存储的
* 新创建消息:ProducerRecord(
* topic=topic_normal,
* partition=null,
* headers=RecordHeaders(headers = [], isReadOnly = false),
* key=null,
* value={"id":"001","name":"xiao xiao"},
* timestamp=null)
* 可以看到新创建出来的消息的key和partition是空的,所以必定是在下面发送消息的send()方法中计算得到的partition,可以通过查看源码发现它是通过一些算法计算出来的
*/
System.out.println("新创建消息:" + record);
// 一个参数的send方法本质上也是异步的,因为这个方法返回的是一个java.util.concurrent.Future对象
// 下面这种调用一个参数send()方法后直接调用get()方法,可以认为这是同步阻塞的
// Future<RecordMetadata> future = producer.send(record);
// RecordMetadata recordMetadata = future.get();
// System.out.println(String.format("分区:%s,偏移量:%s,时间戳:%s", recordMetadata.partition(), recordMetadata.offset(), recordMetadata.timestamp()));
// 带有两个参数send()方法是完全异步的,在回调Callback()方法中得到发送消息的结果
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (null != e) {
e.printStackTrace();
}
System.out.println(String.format("分区:%s,偏移量:%s,时间戳:%s", recordMetadata.partition(), recordMetadata.offset(), recordMetadata.timestamp()));
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者
java
package com.bfxy.kafka.api.producer;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class NormalConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "normal-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_NORMAL));
System.out.println("normal consumer started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka生产者重要参数讲解
-
acks:指定发送消息后,Broker端至少有多少个副本接收到该消息;用于kafka在可靠性和吞吐量之间的折中选择。默认为acks=1
- acks=1:生产者发送消息之后只需要leader副本成功写入消息之后就能够收到来自服务端的成功响应
- 可以确保基本99.9%消息的可靠性投递,但是可能存在这种情况:leader副本写入成功后,follow副本正准备同步消息之前,leader副本宕机,重新选取leader副本,此时选取的leader副本是没有该条消息的,导致这条消息投递失败
- acks=0:生产者发送消息之后不需要等待任何服务端的响应
- 生产端不需要等待任何服务端的响应,可能会出现kafka broker写入异常生产端感知不到,适合不需要可靠性投递的场景
- acks=-1/acks=all:生产者在消息发送后,需要等待ISR中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应
- 适合想要保证安全和可靠性投递的场景
- 但是这个设置也无法保证100%消息的可靠性投递,因为可能ISR中只有leader副本,follow副本都在OSR中,还是相当于acks=1的情况,此时消息还可能会投递失败
- 如果要保证100%消息的可靠性投递,需要配合min.insync.replicas=N使用,代表消息如何才能被认为是写入成功,设置大于1的数,保证至少写入1个或者以上的副本才算写入消息成功。比如现在有1个leader副本和2个follow副本,设置min.insync.replicas=2,但是若此时follow副本就是在OSR中,这样就会导致kafka性能直线下降,所以100%消息的可靠性投递只通过这些中间件很难权衡和保证的,因为中间件是需要对性能和可靠性进行权衡的。一般可以通过同上面RabbitMQ的可靠性投递方案类似通过定时任务把未投递成功的消息再作一次重发,允许消息多发,但是不允许少发。这是保证100%消息的可靠性投递最好的解决方案。
- acks=1:生产者发送消息之后只需要leader副本成功写入消息之后就能够收到来自服务端的成功响应
-
max.request.size:该参数用来限制生产者客户端能发送的消息最大值,默认值:1048576,即1MB
- 一般情况默认值可以满足大多数场景,不建议调整,如果要调整,这个参数还有一些联动的配置项也需要调整
-
retries:重试次数,默认是0
- 作用是如果发送失败,判断是否属于可重试异常,如果可以重试,则放入队列等待再次轮询,如果不可以重试则抛出异常,由业务方catch处理
- 可重试异常
- org.apache.kafka.common.errors.NetworkException:比如网络产生一些异常抖动没有收到请求或者响应,或者消息没发出去
- org.apache.kafka.common.errors.LeaderNotAvailableException:比如当前一刹那kafka集群没有leader,可能正在选举的过程中
- 不可重试异常
- org.apache.kafka.common.errors.RecordTooLargeException:消息体过大
- 可重试异常
- 作用是如果发送失败,判断是否属于可重试异常,如果可以重试,则放入队列等待再次轮询,如果不可以重试则抛出异常,由业务方catch处理
-
retry.backoff.msretries:重试间隔,默认100ms
-
compression.type:这个参数用来指定消息的压缩方式,默认值为"none",可选配置:"gzip"、"snappy"和"lz4"
- 在特定情境下,对于过大的消息体可以设置消息的压缩方式,可以减少网络流量,降低网络IO的成本,提升整体的性能,但是同样压缩也会占用磁盘和CPU
-
connections.max.idle.ms:这个参数用来指定在多久之后关闭限制的连接,默认值是540000(ms),即9分钟
-
linger.ms:这个参数用来指定生产者发送ProducerBatch之前等待更多消息(ProducerRecord)加入ProducerBatch的时间,默认值为0
-
batch.size:累计多少条消息,则一次进行批量发送
-
buffer.memory:缓存提升性能参数,默认为32M
ps:后面这三个参数可以配合使用,实际上就是设置消息的批量发送,提升性能,这三个参数同时配置的话,之间的关系是或,只要满足其中一个就会发送。而且在真正发送消息之前,消息都是存在内存中的。
- receive.buffer.bytes:这个参数用来设置Socket接收消息缓冲区(SO_RECBUF)的大小,默认值为32768(B),即32KB
- send.buffer.bytes:这个参数用来设置Socket发送消息缓冲区(SO_SNDBUF)的大小,默认值为131072(B),即128KB
- request.timeout.ms:这个参数用来配置Producer等待请求响应的最长时间,默认值为30000(ms)
对于这部分常见面试题
- 说一下acks 3个取值的含义,分别适用什么样的应用场景?
- ack=-1/acks=all 是不是一定能够保证100%消息的可靠性投递呢?
kafka生产者和消费者拦截器实现
- 拦截器(interceptor):kafka对应着有生产者和消费者两种拦截器
- 生产者实现接口:
- org.apache.kafka.clients.producer.ProducerInterceptor
- 消费者实现接口:
- org.apache.kafka.clients.consumer.ConsumerInterceptor
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_INTERCEPTOR = "topic-interceptor";
}生产者拦截器
java
package com.bfxy.kafka.api.interceptor;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
public class CustomProducerInterceptor implements ProducerInterceptor<String, String> {
private volatile long success = 0;
private volatile long failure = 0;
/**
* 发送消息之前的切面拦截
* @param producerRecord
* @return
*/
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> producerRecord) {
System.out.println("--------------- 生产者发送消息前置拦截器 ----------------");
String modifyValue = "prefix-" + producerRecord.value();
return new ProducerRecord<>(producerRecord.topic(),
producerRecord.partition(),
producerRecord.timestamp(),
producerRecord.key(),
modifyValue,
producerRecord.headers());
}
/**
* 发送消息之后的切面拦截
* @param recordMetadata
* @param e
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
System.out.println("--------------- 生产者发送消息后置拦截器 ----------------");
if (null == e) {
success ++;
} else {
failure ++;
}
}
@Override
public void close() {
double successRatio = (double) success / (success + failure);
System.out.println(String.format("生产者关闭,发送消息的成功率为:%s %%", successRatio * 100));
}
@Override
public void configure(Map<String, ?> map) {
}
}生产者
java
package com.bfxy.kafka.api.interceptor;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class InterceptorProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "interceptor-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 添加生产者拦截器属性,生产者拦截器可以配置多个
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomProducerInterceptor.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_INTERCEPTOR, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者拦截器
java
package com.bfxy.kafka.api.interceptor;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
public class CustomConsumerInterceptor implements ConsumerInterceptor<String, String> {
/**
* 消费者接收到消息处理之前的拦截器
* @param consumerRecords
* @return
*/
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> consumerRecords) {
System.out.println("--------------- 消费者前置拦截器,接收消息 ----------------");
return consumerRecords;
}
/**
* 消费者接收到消息处理完成后的拦截器
* 如果配置了自动提交AUTO_COMMIT_INTERVAL_MS_CONFIG,没有消息处理完成也会每隔对应的时间执行一次该拦截器
* 手动提交不会则只会在接收到消息处理完成后才会执行该拦截器
* @param map
*/
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> map) {
map.forEach((tp, offset) -> {
System.out.println("消费者处理完成," + "分区:" + tp + ",偏移量:" + offset);
});
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}消费者
java
package com.bfxy.kafka.api.interceptor;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class InterceptorConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "interceptor-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
// 添加消费端拦截器属性
properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_INTERCEPTOR));
System.out.println("interceptor consumer started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka生产者和消费者序列化实现
kafka之序列化反序列化
- 序列化反序列化:生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给kafka,而在对侧,消费者需要用反序列化器(Deserializer)把从kafka中接收到的字节数组转换成对应的对象
- 序列化接口:org.apache.kafka.common.serialization.Serializer
- 反序列化接口:org.apache.kafka.common.serialization.Deserializer
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_SERIAL = "topic-serial";
}自定义序列化类
java
package com.bfxy.kafka.api.serial;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.common.serialization.Serializer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.util.Map;
public class UserSerializer implements Serializer<User> {
@Override
public void configure(Map<String, ?> map, boolean b) {
}
@Override
public byte[] serialize(String s, User user) {
if (null == user) {
return null;
}
byte[] idBytes, nameBytes;
try {
String id = user.getId();
String name = user.getName();
if (null != id) {
idBytes = id.getBytes(StandardCharsets.UTF_8);
} else {
idBytes = new byte[0];
}
if (null != name) {
nameBytes = name.getBytes(StandardCharsets.UTF_8);
} else {
nameBytes = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + idBytes.length + nameBytes.length);
// 4个字节也就是一个int类型长度:这个putInt(int value)方法放idBytes的实际真实长度
buffer.putInt(idBytes.length);
// put(byte[] src)实际放的是idBytes真实的字节数组,也就是内容
buffer.put(idBytes);
// 4个字节也就是一个int类型长度:这个putInt(int value)方法放nameBytes的实际真实长度
buffer.putInt(nameBytes.length);
// put(byte[] src)实际放的是nameBytes真实的字节数组,也就是内容
buffer.put(nameBytes);
return buffer.array();
} catch (Exception e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public void close() {
}
}生产者
java
package com.bfxy.kafka.api.serial;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.interceptor.CustomProducerInterceptor;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class SerializerProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "serial-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 添加序列化value,使用自定义的序列化类
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, UserSerializer.class.getName());
try (KafkaProducer<String, User> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, User> record = new ProducerRecord<>(Const.TOPIC_SERIAL, user);
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}自定义反序列化类
java
package com.bfxy.kafka.api.serial;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Deserializer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.util.Map;
public class UserDeserializer implements Deserializer<User> {
@Override
public void configure(Map<String, ?> map, boolean b) {
}
@Override
public User deserialize(String s, byte[] bytes) {
if (null == bytes) {
return null;
}
if (bytes.length < 8) {
throw new SerializationException("size is wrong, must be data.length >= 8");
}
ByteBuffer buffer = ByteBuffer.wrap(bytes);
// idBytes字节数组的真实长度
int idLen = buffer.getInt();
byte[] idBytes = new byte[idLen];
buffer.get(idBytes);
// nameBytes字节数组的真实长度
int nameLen = buffer.getInt();
byte[] nameBytes = new byte[nameLen];
buffer.get(nameBytes);
String id,name;
try {
id = new String(idBytes, StandardCharsets.UTF_8);
name = new String(nameBytes, StandardCharsets.UTF_8);
} catch (Exception e) {
throw new SerializationException("deserializing error!", e);
}
return new User(id, name);
}
@Override
public void close() {
}
}消费者
java
package com.bfxy.kafka.api.serial;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.interceptor.CustomConsumerInterceptor;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class DeserializerConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 反序列化属性参数配置,使用自定义的序列化类
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, UserDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "serial-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, User> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_SERIAL));
System.out.println("serial consumer started...");
while (true) {
ConsumerRecords<String, User> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, User>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, User> consumerRecord : partitionRecordList) {
User user = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", user, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka分区器使用与最佳实践
kafka之分区器
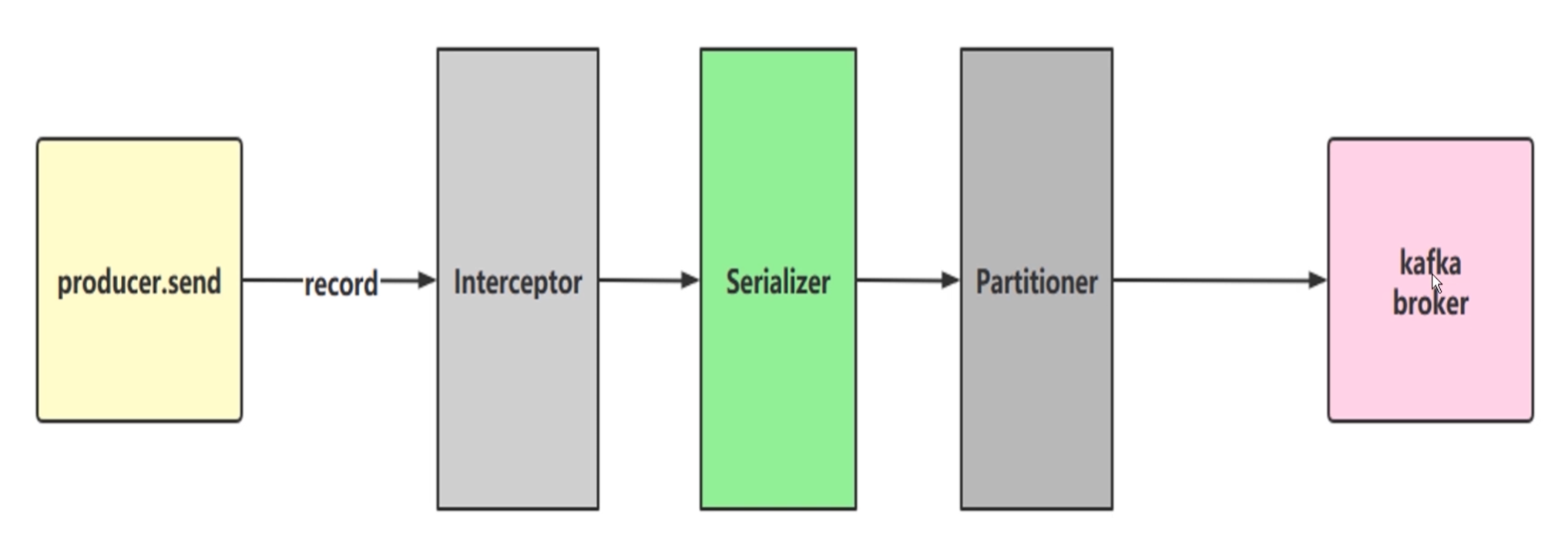
如图,kafka producer发送消息,依次经过生产者拦截器、序列化器、分区器,拿到partition分区的序号后最后再存到kafka broker上。这里的record就是指ProducerRecord,如果没有指定partition分区,就会通过分区器内部算法根据key计算一个分区序号,如果指定了partition分区,就不会走分区器,直接根据指定的partition分区存到kafka broker上。
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_PARTITION = "topic-partition";
}自定义分区器
java
package com.bfxy.kafka.api.partition;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
public class CustomPartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfoList = cluster.partitionsForTopic(topic);
int numOfPartition = partitionInfoList.size();
System.out.println("------ 进入自定义分区器,当前分区个数:" + numOfPartition);
if (null == keyBytes) {
return counter.getAndIncrement() % numOfPartition;
} else {
return Utils.toPositive(Utils.murmur2(keyBytes)) % numOfPartition;
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}生产者
java
package com.bfxy.kafka.api.partition;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.interceptor.CustomProducerInterceptor;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class PartitionProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "partition-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 添加分区器配置,使用自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_PARTITION, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者
java
package com.bfxy.kafka.api.partition;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.interceptor.CustomConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class PartitionConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "partition-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_PARTITION));
System.out.println("partition consumer started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}自定义分区器在实际工作中的应用
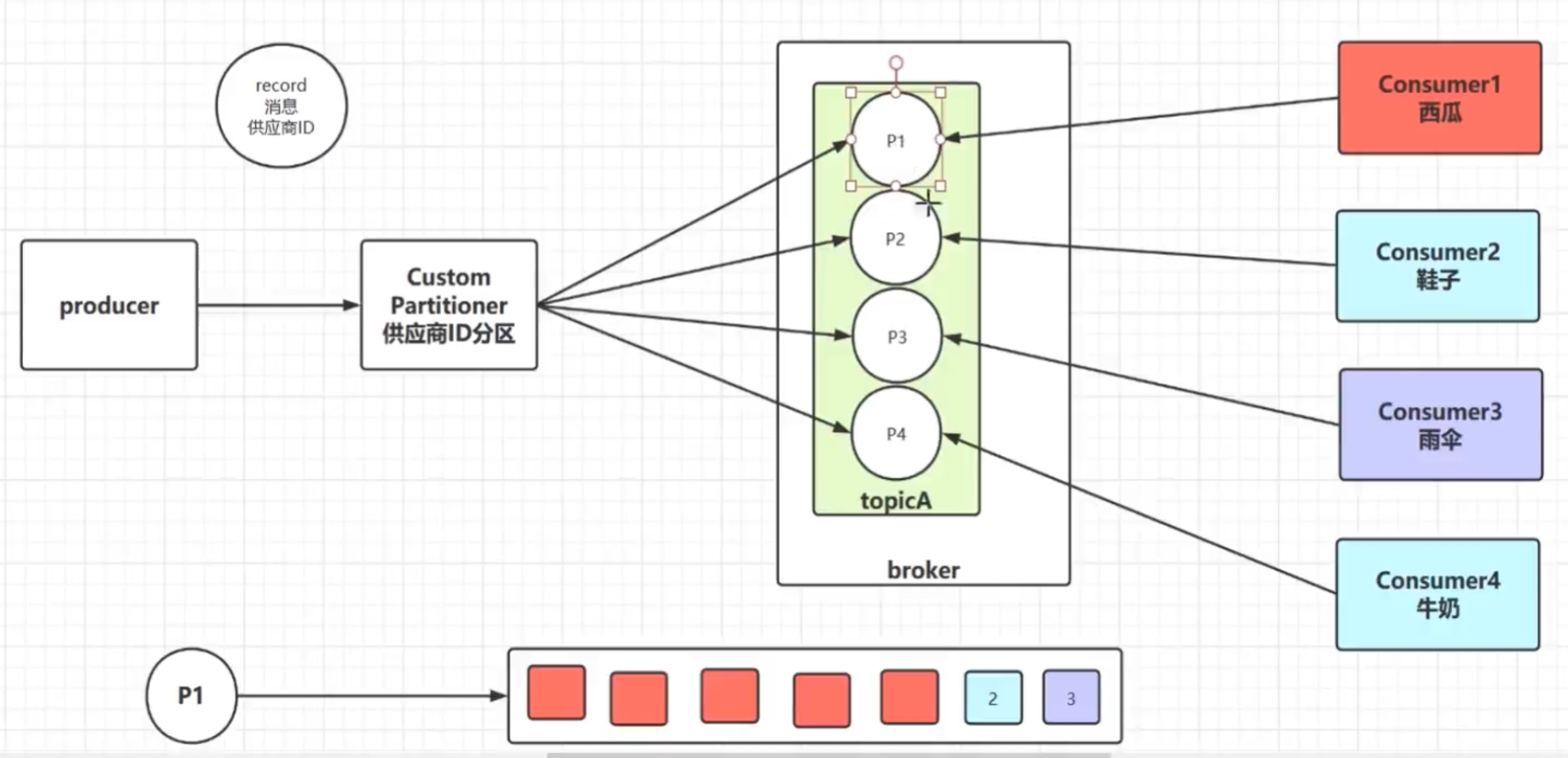
假设现在我们的kafka broker的topicA存在4个partition,此时还存在4个consumer(代表4个供应商)对应从4个partition中消费消息,因为我们的partition和队列一样,先进先出是实现顺序消息的。我们的消息是包含供应商ID的,然后通过自定义分区器Custom Partitioner根据供应商ID作partition的选择,相同的供应商ID会流入同一个partition,可以保证不同供应商ID的消息会相互不冲突,这样每个供应商都能及时的拿到具体的订单,第一时间消费消息。
假设比如partition1中有consumer1、consumer2、consumer3、consumer4的消息,而consumer1这个供应商的消息特别多,consumer2、consumer3、consumer4这几个供应商的消息非常少,此时就存在consumer1这个供应商因为消息过多一直处于消费状态,consumer2、consumer3、consumer4这几个供应商的无法及时消费消息。