AIGC大语言模型之词元和嵌入向量
AIGC大语言模型之词元和嵌入向量
前言
词元和嵌入向量是人工智能生成内容(AIGC)中使用LLM的两个核心概念。
一、LLM的分词
1、分词器
是在模型处理文本之前, 分词器会将文本分解成词或者子词。这个是根据特定的方法和训练过程进行的。
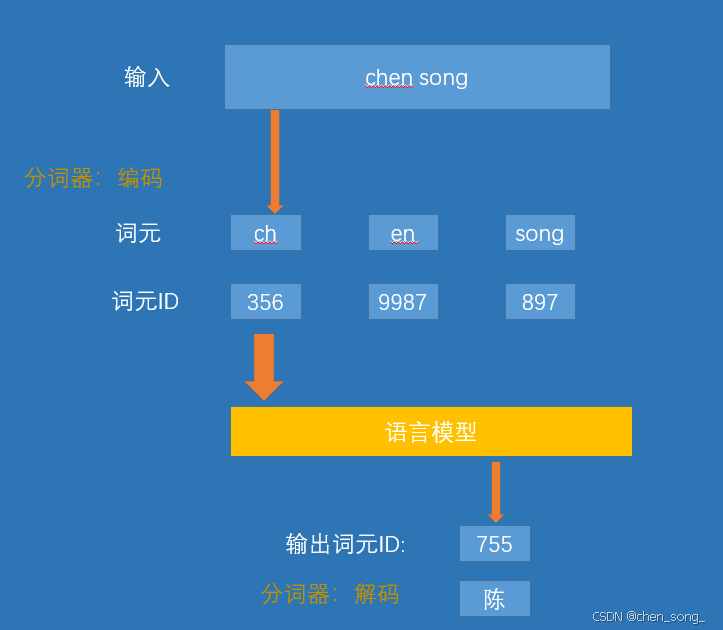
2、分词器如何分解文本
3、开源分词器
| 分词器/库 | 核心思想/算法 | 标志性特点 | 主要使用者 |
|---|---|---|---|
| OpenAI BPE(tiktoken) | Byte-level BPE | 直接在字节流上操作,高效压缩 | GPT-2,GPT-3,GPT-4,GPT-40, GPT-5 |
| SentencePiece | BPE, Unigram | 语言无关,无需预分词,空格视为 | LLaMA, T5,多语言模型 |
| WordPiece | Max-Likelihood | 需要预分词,词中片段用 ## 标记 | BERT 及其家族 |
| Hugging Facetokenizers | BPE, WordPiece,Unigram... | 集大成者,高性能Rust 实现,完整流水线 | Hugging Face 生态所有模型 |
4、词级、子词级、字符级与字节级分词
二、词元嵌入向量
语言是词元的序列,如果我们子啊足够大的词元集上训练一个足够好的模型, 它就会开始捕获训练数据集中出现的复杂模式:
- 如果训练数据包含有大量英语文本, 通过这些模式,模型就能够表示和生成英语。
- 如果训练数据包含事实性信息(例如维基百科),模型就会具有生成一下事实性信息的能力
1、文本嵌入(用于句子和整篇文档)
虽然词元嵌入是LLM运作的关键, 但许多LLM应用需要处理完整的句子,段落甚至文本文档,这催生了一下特殊的语言模型,他们能够生成文本嵌入-- 用单个向量来表示长度超过一个词元的文本片段。
我们可以这样理解文本嵌入模型:它接收一段文本, 最终生成单个向量, 这个向量以某种形式表示该文本并捕获其含义. 生成文本嵌入有多种方法。常见的方法之一是对模型生成的所有词元嵌入的值取平均值,然而,高质量的文本嵌入模型往往是专门为文本嵌入任务训练的
2、这边我们自己预训练文本词
- 准备预训练数据集(清洗、去重、tokenizer)
- Tokenizer设置(词元、分词策略)
- 输出模型
javascipt
# 导入 SentencePiece 库:用于无监督训练子词(BPE/Unigram)模型以及后续编码/解码
import sentencepiece as spm
def train(input_file, vocab_size, model_name, model_type, character_coverage):
"""
重要说明(官方参数文档可查):
https://github.com/google/sentencepiece/blob/master/doc/options.md
参数含义:
- input_file: 原始语料文件路径(每行一句,SentencePiece 会做 Unicode NFKC 规范化)
支持多文件逗号拼接:'a.txt,b.txt'
- vocab_size: 词表大小,如 8000 / 16000 / 32000
- model_name: 模型前缀名,最终会生成 <model_name>.model 和 <model_name>.vocab
- model_type: 模型类型:unigram(默认)/ bpe / char / word
注意:若使用 word,需要你在外部先分好词(预分词)
- character_coverage: 覆盖的字符比例
* 中文/日文等字符集丰富语言建议 0.9995
* 英文等字符集小的语言建议 1.0
"""
# 这里使用"字符串命令"式的调用来指定训练参数
# 固定 4 个特殊符号的 id:<pad>=0, <unk>=1, <bos>=2, <eos>=3
# 这与下游 Transformer 常用配置一致,便于对齐
input_argument = (
'--input=%s '
'--model_prefix=%s '
'--vocab_size=%s '
'--model_type=%s '
'--character_coverage=%s '
'--pad_id=0 --unk_id=1 --bos_id=2 --eos_id=3 '
)
# 将传入参数填充到命令字符串
cmd = input_argument % (input_file, model_name, vocab_size, model_type, character_coverage)
# 开始训练;会在当前工作目录下生成 <model_name>.model / <model_name>.vocab
spm.SentencePieceTrainer.Train(cmd)
# ===== 英文分词器配置 =====
en_input = 'data/data.txt' # 英文语料:一行一句
en_vocab_size = 32000 # 词表大小:翻译任务常见为 16k/32k
en_model_name = 'eng' # 输出前缀:会生成 eng.model / eng.vocab
en_model_type = 'bpe' # 使用 BPE(也可尝试 unigram)
en_character_coverage = 1.0 # 英文字符集小 → 用 1.0
train(en_input, en_vocab_size, en_model_name, en_model_type, en_character_coverage)