分布式消息队列kafka【四】------ 消费者进阶提升
文章目录
- [分布式消息队列kafka【四】------ 消费者进阶提升](#分布式消息队列kafka【四】—— 消费者进阶提升)
kafka消费者与消费者组的概念详解
kafka之消费者与消费者组
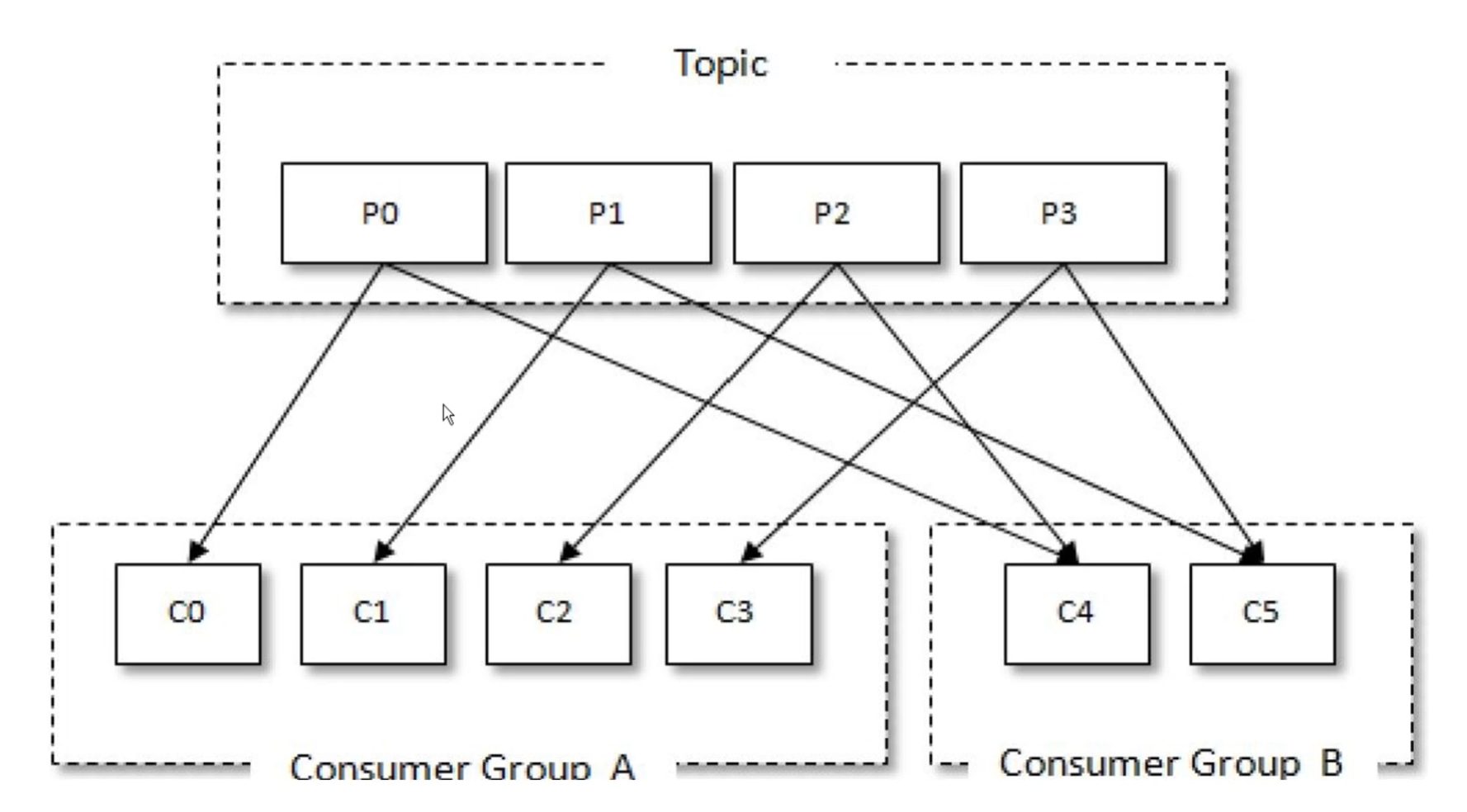
一个消费者只能属于一个消费者组,但是一个消费者组里面可以包含多个消费者,所以消费者组和消费者是一对多的关系。
消费者组里面的每一个消费者都可以分配一个或者多个分区,每一个消费者只能消费所分到的分区的消息,即每一个分区只能被一个消费者组中的一个消费者消费。
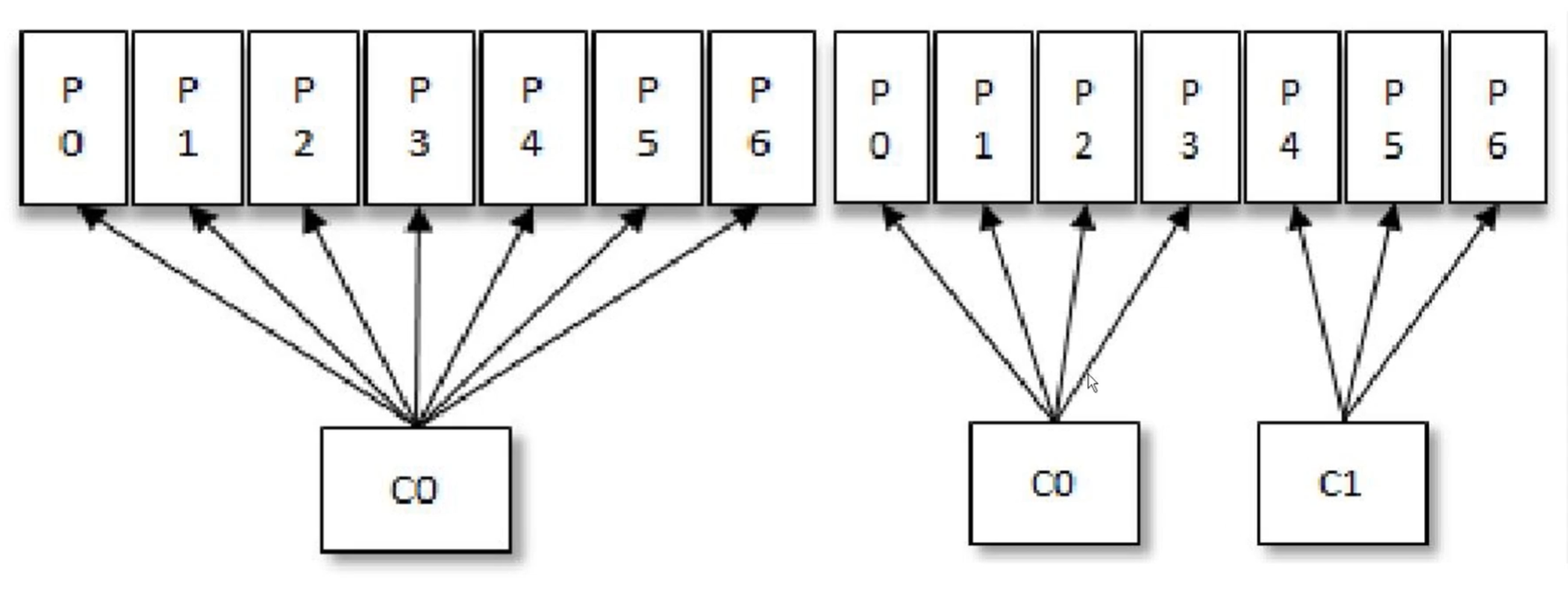
当同一消费者组内新加一个消费者时,原来的消费者可以把部分分区交给新加的消费者,彼此之间时互不干扰的。相当于工作中新来的一个员工接手老员工的部分任务。
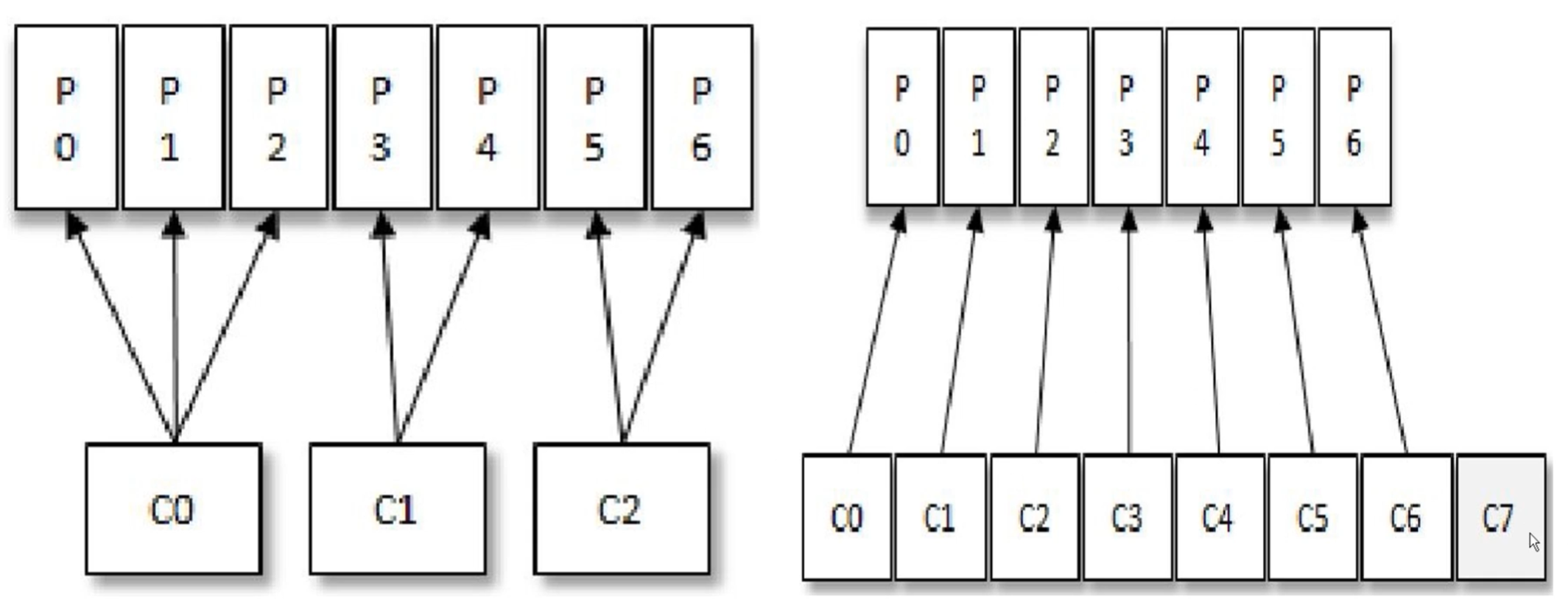
如图左边,如果消费者组里面再新加一个消费者时,分区的消费又会作一次重新分配,这是没有任何问题的。
如图右边,如果后续新增更多的消费者,只有7个分区,但是此时有8个消费者,会导致最后的C7不能消费消息了,因为每一个分区只能被一个消费者组中的一个消费者消费。相当于工作中的白拿工资不干活。
传统消息中间件投递模式
- 消息中间件投递模式:
- 点对点(P2P,Point-to-Point)模式
- 点对点模式是基于队列的,消息生产者发送消息到队列,消息消费者从队列中接收消息
- 发布/订阅(Pub/Sub)模式
- 发布/订阅模式定义了如何向一个内容节点发布和订阅消息,这个内容节点称为主题(Topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者从主题中订阅消息。相当于广播模式
- 点对点(P2P,Point-to-Point)模式
kafka的消息中间件模型
- kafka同时支持以上两种消息投递模式,而这正是得益于消费者与消费者组模型的契合
- 消费者都隶属于同一个消费者组,所有的消息都会被均衡交给每一个消费者处理,因为同一个消费者组内同一个分区时不允许有多个消费者消费消息的。即在同一个消费者组内每一条消息只能被一个消费者处理。相当于点对点模型
- 消费者都隶属于不同的消费者组,不同的消费者组,里面的消费者是可以订阅同一个主题并且消费同一个分区的,即投递一个消息被多个消费者消费。相当于发布/订阅模式
kafka消费者点对点模型与发布订阅模型实现
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_MODULE = "topic-module";
}生产者
java
package com.bfxy.kafka.api.consumer.module;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Producer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "module-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_MODULE, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}点对点模型消费者1
java
package com.bfxy.kafka.api.consumer.module;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class P2PConsumer1 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "module-group-id-1");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_MODULE));
System.out.println("module consumer1 started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}点对点模型消费者2
java
package com.bfxy.kafka.api.consumer.module;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class P2PConsumer2 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// GROUP_ID_CONFIG:消费者组配置
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "module-group-id-1");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_MODULE));
System.out.println("module consumer2 started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}发布订阅模型消费者1
java
package com.bfxy.kafka.api.consumer.module;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class SubConsumer1 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "module-group-id-1");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_MODULE));
System.out.println("module consumer1 started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}发布订阅模型消费者2
java
package com.bfxy.kafka.api.consumer.module;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class SubConsumer2 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "module-group-id-2");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_MODULE));
System.out.println("module consumer1 started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka消费者核心使用-概念说明
kafka之消费者必要参数方法
-
bootstrap.servers:用来指定连接kafka集群所需的broker地址清单
- 集群节点要写全,与生产者的bootstrap.servers同理
-
key.deserializer和value.deserializer:反序列化参数
- 因为kafka在发送和接收消息都是以二进制的形式传输的,所以必须要序列化和反序列化
-
group.id:消费者所属消费者组
-
subscribe()方法:消息主题订阅,支持集合/标准正则表达式
-
assign()方法:只订阅主题的某个或者某些分区
kafka之消费者参数auto.offset.reset
有三个取值:
- latest (默认)
- earliest
- none
三者均有共同定义:
- 对于同一个消费者组,若已有提交的offset,即该消费者组已有消费者完成消息消费,则从提交的offset开始接着消费
- 意思就是,只要这个消费者组消费过了,不管
auto.offset.reset指定成什么值,效果都一样,每次启动都是已有的最新的offset开始接着往后消费
- 意思就是,只要这个消费者组消费过了,不管
不同的点为:
-
latest(默认):对于同一个消费者组,若没有提交过offset,则只消费消费者连接topic后新产生的数据
- 就是说如果这个topic有历史消息,现在新启动了一个消费者组,且
auto.offset.reset=latest,此时已存在的历史消息无法消费到,那保持消费者组运行,如果此时topic有新消息进来了,这时新消息才会被消费到。而一旦有消费,则必然会提交offset - 这时候如果该消费者组意外下线了,topic仍然有消息进来,接着该消费者组在后面恢复上线了,它仍然可以从下线时的offset处开始接着消费,此时走的就是共同定义
- 就是说如果这个topic有历史消息,现在新启动了一个消费者组,且
-
earliest:对于同一个消费者组,若没有提交过offset,则从头开始消费
- 就是说如果这个topic有历史消息存在,现在新启动了一个消费者组,且
auto.offset.reset=earliest,那将会从头开始消费,也就是从这个topic历史消息第一条开始消费,这就是与latest不同之处。 - 一旦该消费者组消费过topic后,此时就有
该消费者组的offset了,这种情况下即使指定了auto.offset.reset=earliest,再重新启动该消费者组,效果是与latest一样的,也就是此时走的是共同的定义
- 就是说如果这个topic有历史消息存在,现在新启动了一个消费者组,且
-
none:对于同一个消费者组,若没有提交过offset,会抛异常
- 一般生产环境基本用不到该参数
可以通过properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");配置测试
kafka之消费者提交偏移量
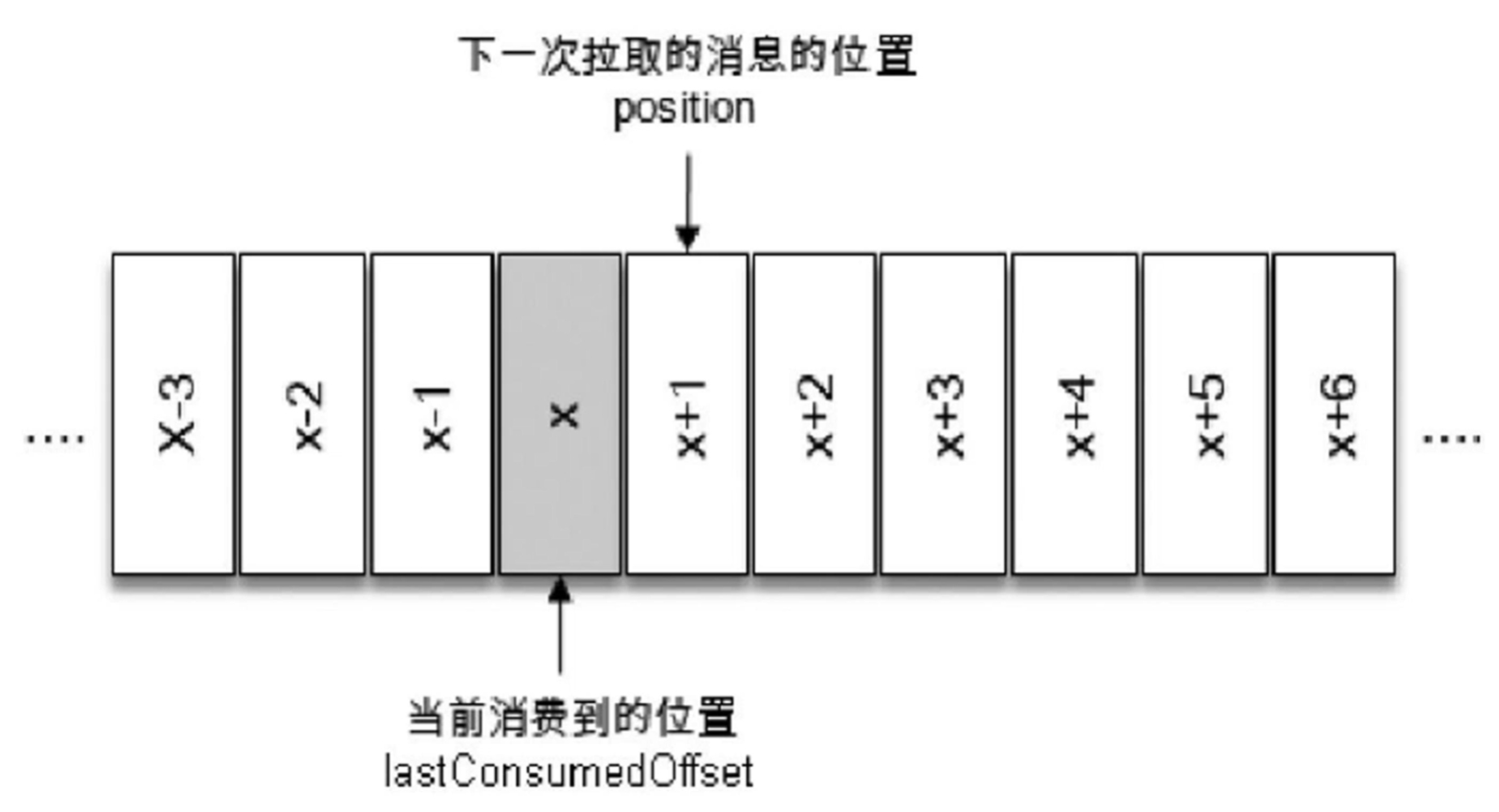
对于kafka而言,在分区里每条消息都有一个offset记录,用来表示消息在分区中的具体位置。对于消费者而言,也存在offset的概念,用来表示消费者消费到某个分区所在的位置,如图:lastConsumedOffset。消费者每次在作pull拉取消息时,都是从lastConsumedOffset+1的位置拉取消息。返回的都是还没有消费过的offset的数据集,当然,这些消息肯定是已经存入kafka的分区中的,对应在kafka的分区中会有一个offset记录。
要做到消费者每次在作pull拉取消息时,都是从lastConsumedOffset+1的位置拉取消息,就必须记录上一次提交的offset偏移量:lastConsumedOffset,提交方式分为以下自动提交和手动提交两种
kafka之消费者自动提交
- 自动提交:enable.auto.commit,默认值为true
- 提交周期间隔:auto.commit.interval.ms,默认值为5秒
kafka之消费者手动提交(实际工作中使用)
-
手动提交是在工作中常用的,因为手动提交我们人为是知道消息是否处理成功还是失败,处理失败可以重新消费或者做一些兜底的策略
-
手动提交:enable.auto.commit配置为false
- 需要注意的是:如果设置enable.auto.commit配置为false,但是后续没有手动提交,这样kafka就会认为这些消息没有消费成功,每次重启消费者都会重复消费这些消息
-
提交方式:
-
commitSync:同步提交,必须等待offset提交完毕,再去消费下一批数据。
-
commitAsync:异步提交,发送完提交offset请求后,就开始消费下一批数据了。
-
-
同步提交和异步提交都还分整体提交&分区提交两种方式
- 整体提交:需要把这个主题下的所有消息全部拉取并消费完成后才能提交
- 存在的问题:实际工作中可能这个主题下一次性拉取几千条消息,每条消息处理都比较耗时,此时,更适合局部提交,有分区提交和单条消息记录提交两种
- 分区提交:针对每一个partition做一次提交动作
- 存在的问题:也会出现单个分区一次性拉取消息量太大,处理耗时的问题
- 单条消息记录提交:实际工作中都是在一个partition内部,每一条消息记录进行一一提交
- 整体提交:需要把这个主题下的所有消息全部拉取并消费完成后才能提交
-
实际工作中使用的方式:异步提交+单条消息记录提交
kafka消费者核心使用-subscribe与assign详解
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_CORE = "topic-core";
}生产者
java
package com.bfxy.kafka.api.consumer.core;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CoreProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "core-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_CORE, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者
java
package com.bfxy.kafka.api.consumer.core;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
import java.util.regex.Pattern;
public class CoreConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "core-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
// 对于consumer消息的订阅subscribe()方法:可以订阅一个或者多个topic
// consumer.subscribe(Collections.singletonList(Const.TOPIC_CORE));
// consumer消息的订阅subscribe()方法,也支持匹配正则表达式订阅
// consumer.subscribe(Pattern.compile("topic-.*"));
// consumer.assign()方法:可以指定订阅某个主题下的某一个或者多个partition
// consumer.assign(Arrays.asList(new TopicPartition(Const.TOPIC_CORE, 0), new TopicPartition(Const.TOPIC_CORE, 2)));
// 如何拉取主题下的所有partition
List<TopicPartition> topicPartitionList = new ArrayList<>();
List<PartitionInfo> partitionInfoList = consumer.partitionsFor(Const.TOPIC_CORE);
for (PartitionInfo partitionInfo : partitionInfoList) {
System.out.println("主题:" + partitionInfo.topic() + ",分区:" + partitionInfo.partition());
TopicPartition topicPartition = new TopicPartition(partitionInfo.topic(), partitionInfo.partition());
topicPartitionList.add(topicPartition);
}
consumer.assign(topicPartitionList);
System.out.println("core consumer started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka消费者核心使用-手工提交方式详解
topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_COMMIT = "topic-commit";
}生产者
java
package com.bfxy.kafka.api.consumer.commit;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CommitProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "commit-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_COMMIT, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者
java
package com.bfxy.kafka.api.consumer.commit;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class CommitConsumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "commit-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
// properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
// 使用手动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(Const.TOPIC_COMMIT));
System.out.println("commit consumer started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
// 实际工作中都是在一个partition内部,每一条消息记录进行一一提交
// 实际提交的offset肯定是比实际的消息的offset大1,因为实际提交的offset是下次要拉取的消息的offset
// 单条消息记录提交:同步方式
// consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(commitOffset)));
// 单条消息记录提交:异步方式
consumer.commitAsync(Collections.singletonMap(partition, new OffsetAndMetadata(commitOffset)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if (null != e) {
System.out.println("异步提交报错...");
}
System.out.println("异步提交成功:" + map);
}
});
}
/*// 一个partition做一次提交动作
long latestOffsetInPartition = partitionRecordList.get(partitionRecordList.size() - 1).offset();
long commitLatestOffsetInPartition = latestOffsetInPartition + 1;
// 分区提交:同步方式
// consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(commitLatestOffsetInPartition)));
// 分区提交:异步方式
consumer.commitAsync(Collections.singletonMap(partition, new OffsetAndMetadata(commitLatestOffsetInPartition)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if (null != e) {
System.out.println("异步提交报错...");
}
System.out.println("异步提交成功:" + map);
}
});*/
}
/*// 整体提交:同步方式
// consumer.commitSync();
// 整体提交:异步方式
// consumer.commitAsync();
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if (null != e) {
System.out.println("异步提交报错...");
}
System.out.println("异步提交成功:" + map);
}
});*/
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka消费者核心使用-消费者再均衡应用
kafka之消费者再均衡
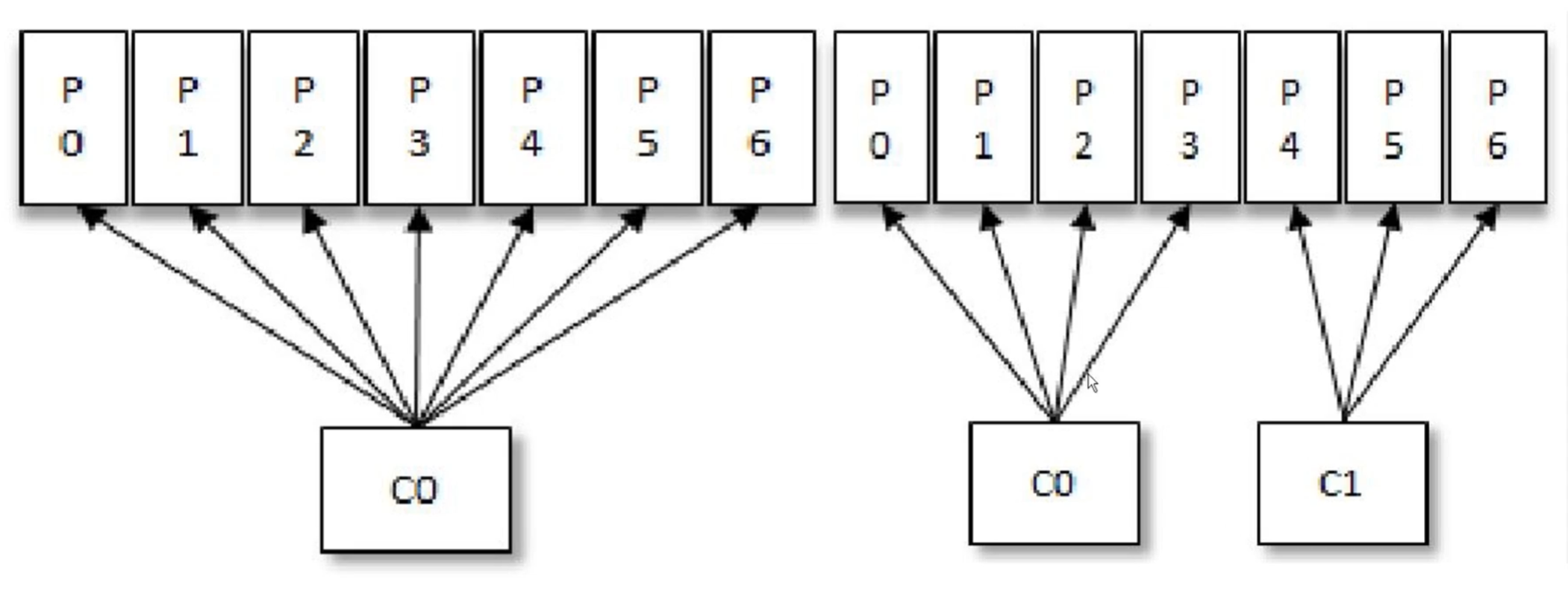
如图,假设存在一个消费者组只有一个消费者C0,此时有7个partition,这样这个消费者C0就需要消费7个partition。后续,新增了一个同组的消费者C1,这样C0就把其中3个partition交给了C1。这个过程就是消费者再均衡。
适用于实际业务中的应用场景:比如针对一些partition去执行一些定时任务,比如原先单个consumer需要执行5个定时任务,新加了一个consumer后,两个consumer一个执行3个定时任务,另一个执行2个定时任务,对任务进行平均分配,相当于降压和扩容、负载均衡的作用。
消息实体
java
package com.bfxy.kafka.api.model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User /*implements Serializable*/ { // 不需要实现Serializable接口,因为kafka对VALUE已经做了序列化
private String id;
private String name;
}topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_REBALANCE = "topic-rebalance";
}生产者
java
package com.bfxy.kafka.api.consumer.rebalance;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class RebalanceProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "rebalance-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_REBALANCE, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者1
java
package com.bfxy.kafka.api.consumer.rebalance;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class RebalanceConsumer1 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// GROUP_ID_CONFIG:消费者组配置
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "rebalance-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
// 配置消费者在均衡 ConsumerRebalanceListener
consumer.subscribe(Collections.singletonList(Const.TOPIC_REBALANCE), new ConsumerRebalanceListener() {
/**
* partitions回收
* @param partitions
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Revoked Partitions:" + partitions);
}
/**
* partitions重新分配
* @param partitions
*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("Assigned Partitions:" + partitions);
}
});
System.out.println("rebalance consumer1 started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}消费者2
java
package com.bfxy.kafka.api.consumer.rebalance;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
public class RebalanceConsumer2 {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// GROUP_ID_CONFIG:消费者组配置
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "rebalance-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties)) {
// 配置消费者在均衡 ConsumerRebalanceListener
consumer.subscribe(Collections.singletonList(Const.TOPIC_REBALANCE), new ConsumerRebalanceListener() {
/**
* partitions回收
* @param partitions
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("Revoked Partitions:" + partitions);
}
/**
* partitions重新分配
* @param partitions
*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("Assigned Partitions:" + partitions);
}
});
System.out.println("rebalance consumer2 started...");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecordList = records.records(partition);
String topic = partition.topic();
int size = partitionRecordList.size();
System.out.println(String.format("--- 获取topic:%s,分区位置:%s,消息总数:%s ---", topic, partition.partition(), size));
for (ConsumerRecord<String, String> consumerRecord : partitionRecordList) {
String value = consumerRecord.value();
long offset = consumerRecord.offset();
long commitOffset = offset + 1;
System.out.println(String.format("-- 获取实际消息value:%s,消息offset:%s,提交offset:%s ---", value, offset, commitOffset));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}kafka消费者核心使用-多线程模型实现
kafka之消费者多线程
- KafkaProducer是线程安全的,但是KafkaConsumer却是线程非安全的
- KafkaConsumer中定义了一个acquire方法用来检测是否只有一个线程在操作,如果有其他线程操作则会抛出ConcurrentModifactionException
- KafkaConsumer在执行所有动作时都会先执行acquire方法检测是否线程安全
提出疑问
KafkaConsumer是线程非安全的,是不是这样就不能多线程消费了呢?答案肯定是否定的,生产者如果产生消息的速率特别快,此时kafka的消息者还是单线程的,就会造成kafka的消息堆积严重。
kafka之消费者多线程模型1
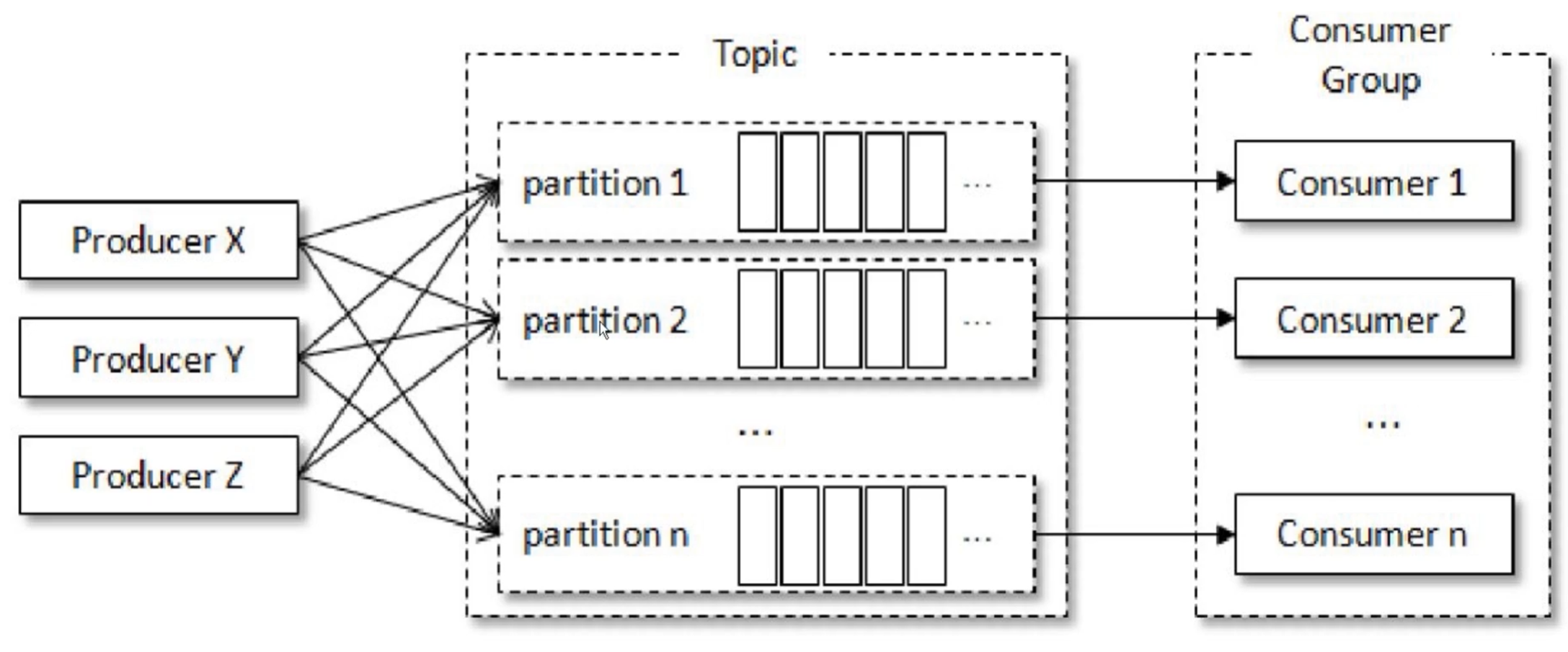
如图,一个consumer对应消费一个partition的消息,这样就可以实现多线程消费了,可以使得消息并行的、及时的处理。
代码实现
消息实体
java
package com.bfxy.kafka.api.model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User /*implements Serializable*/ { // 不需要实现Serializable接口,因为kafka对VALUE已经做了序列化
private String id;
private String name;
}topic常量
java
package com.bfxy.kafka.api.constant;
public interface Const {
String TOPIC_MT1 = "topic-mt1";
}生产者
java
package com.bfxy.kafka.api.consumer.multithread1;
import com.alibaba.fastjson.JSON;
import com.bfxy.kafka.api.constant.Const;
import com.bfxy.kafka.api.model.User;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Mt1Producer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "mt1-producer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(properties)) {
for (int i = 0; i < 10; i++) {
User user = new User("00" + i, "张三");
ProducerRecord<String, String> record = new ProducerRecord<>(Const.TOPIC_MT1, JSON.toJSONString(user));
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}自定义线程任务类
java
package com.bfxy.kafka.api.consumer.multithread1;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicInteger;
public class KafkaConsumerMt1 implements Runnable {
private final KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
private static final AtomicInteger counter = new AtomicInteger(0);
private final String consumerName;
public KafkaConsumerMt1(Properties properties, String topic) {
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(Collections.singletonList(topic));
this.consumerName = "KafkaConsumerMt1-" + counter.getAndIncrement();
System.out.println(this.consumerName + " started ");
}
@Override
public void run() {
try {
while (isRunning) {
// ConsumerRecords包含订阅topic下的所有partition的消息内容
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));
for (TopicPartition partition : consumerRecords.partitions()) {
// 根据具体的TopicPartition获取对应partition下的消息集合
List<ConsumerRecord<String, String>> records = consumerRecords.records(partition);
for (ConsumerRecord<String, String> record : records) {
String message = record.value();
long offset = record.offset();
System.out.println("当前消费者:" + consumerName + ",当前分区:" + partition.partition() + ",消息内容:" + message + ",消息的偏移量:" + offset + ",当前线程:" + Thread.currentThread().getName());
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (consumer != null) {
consumer.close();
}
}
}
public boolean isRunning() {
return isRunning;
}
public void setRunning(boolean running) {
isRunning = running;
}
}消费者
java
package com.bfxy.kafka.api.consumer.multithread1;
import com.bfxy.kafka.api.constant.Const;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collection;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Mt1Consumer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.218.21:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "mt1-group");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
String topic = Const.TOPIC_MT1;
// 根据分区数定义的核心线程数,也是这个消费者组内的消费者数
int coreSize = 5;
ExecutorService executorService = Executors.newFixedThreadPool(coreSize);
for (int i = 0; i < coreSize; i++) {
executorService.execute(new KafkaConsumerMt1(properties, topic));
}
}
}kafka消费者核心使用-第二种多线程模型实现思路讲解
kafka之消费者多线程模型2

如图,这个模型是只有一个consumer对象,怎么实现并行消费?这个问题看起来是无解的,根据图示可以理解为一个Thread Handler线程对应一个partition,如果是手动提交,那么任何一个线程消费完成后都需要调用consumer提交偏移量的方法,这样就是多线程在操作一个consumer了就会抛出ConcurrentModifactionException异常。
如何解决上述问题,一般来讲,像种问题可以使用最经典的master、work线程模型去实现,master线程不负责实际的处理任务,只负责处理结果和分配任务,那么master线程就可以理解为是单线程的。work线程是实际的线程池处理任务,master线程把一个个任务分给不同的work线程,work线程处理完成后把结果返回给master线程,由master线程统一提交。具体可见下图
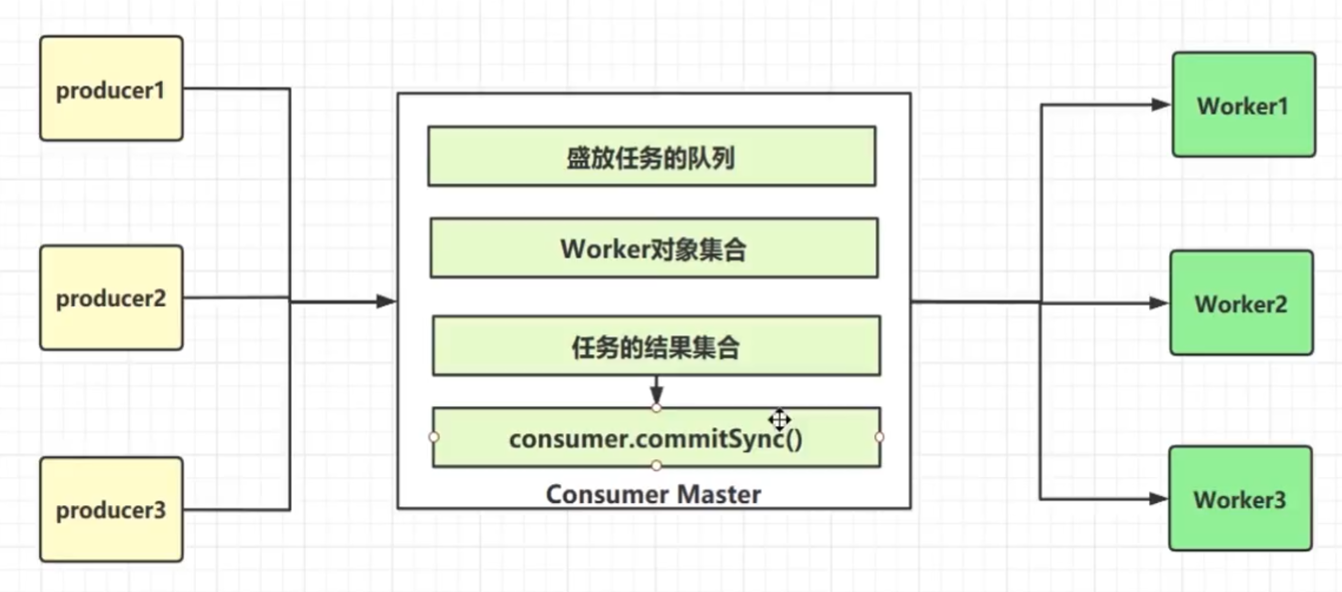
如图,生产者们生产消息由一个consumer消费,这个comsumer就相当于master线程,这个master线程里必然会有盛放任务的队列,一个partition对应一个队列,然后肯定会有worker对象集合,master线程接收到任务到放入队列中,把任务交给实际的worker对象去处理。worker对象只负责处理任务,然后把处理的结果返回给master线程,所以master线程肯定存在一个任务的结果集,最后还是master线程这个单线程执行提交操作,consumer.commitSync()。
kafka消费者核心使用-消费者重要参数讲解
kafka之消费者重要参数
- fetch.min.bytes:一次拉取消息的最小数据量,默认为1B
- fetch.max.bytes:一次拉取消息的最大数据量,默认为50M
- max.partition.fetch.bytes:一次fetch请求,从一个partition中取得的records最大大小。默认为1M
- fetch.max.wait.ms:Fetch请求发给broker后,在broker中可能会被阻塞的时长,默认为500
- max.poll.records:Consumer每次调用poll()时取到的records的最大数,默认为500条
ps:这些参数一般不做修改,如果要修改肯定是根据实际服务器的资源情况、实际的消费速度情况等来作调整
kafka与springboot整合实战
导入maven依赖
xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>生产端
配置文件
properties
server.servlet.context-path=/producer
server.port=8001
## Spring 整合 kafka
spring.kafka.bootstrap-servers=192.168.218.21:9092
## kafka producer 发送消息失败时的一个重试的次数
spring.kafka.producer.retries=0
## 批量发送数据的配置(16KB)
spring.kafka.producer.batch-size=16384
## 设置kafka 生产者内存缓存区的大小(32M)
spring.kafka.producer.buffer-memory=33554432
## kafka消息的序列化配置
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# acks=0 :生产者发送消息之后不需要等待任何服务端的响应。
# acks=1 :生产者发送消息之后只需要leader副本成功写入消息之后就能够收到来自服务端的成功响应。
# acks=-1 :表示分区leader必须等待消息被成功写入到所有的ISR副本(同步副本)中才认为producer请求成功。这种方案提供最高的消息持久性保证,但是理论上吞吐率也是最差的。
## 这个是kafka生产端最重要的选项
spring.kafka.producer.acks=1生产者
java
package com.bfxy.kafka.producer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import javax.annotation.Resource;
@Service
public class KafkaProducerService {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaProducerService.class);
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
public void sendMessage(String topic, Object object) {
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, object);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onSuccess(SendResult<String, Object> result) {
LOGGER.info("发送消息成功: " + result.toString());
}
@Override
public void onFailure(Throwable throwable) {
LOGGER.error("发送消息失败: " + throwable.getMessage());
}
});
}
}测试发送方法
java
package com.bfxy.kafka.producer.test;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import com.bfxy.kafka.producer.KafkaProducerService;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ApplicationTest {
@Autowired
private KafkaProducerService kafkaProducerService;
@Test
public void send() throws InterruptedException {
String topic = "topic02";
for(int i=0; i < 1000; i ++) {
kafkaProducerService.sendMessage(topic, "hello kafka" + i);
Thread.sleep(5);
}
// 线程休眠是为了等待kafka broker返回ack的信息
Thread.sleep(Integer.MAX_VALUE);
}
}消费端
配置文件
properties
server.servlet.context-path=/consumser
server.port=8002
## Spring 整合 kafka
spring.kafka.bootstrap-servers=192.168.218.21:9092
## consumer 消息的签收机制:手动签收
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.listener.ack-mode=manual
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值):在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest:在偏移量无效的情况下,消费者将从起始位置读取分区的记录
# none:在偏移量无效的情况下,会抛异常
spring.kafka.consumer.auto-offset-reset=earliest
## 序列化配置
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费者监听线程数
spring.kafka.listener.concurrency=5消费者
java
package com.bfxy.kafka.consumer;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaConsumerService.class);
@KafkaListener(groupId = "group02", topics = "topic02")
public void onMessage(ConsumerRecord<String, Object> record, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
LOGGER.info("消费端接收消息: {}", record.value());
// 手动签收机制
acknowledgment.acknowledge();
}
}