
论文链接:https://arxiv.org/pdf/2512.08765
项目链接:https://github.com/ali-vilab/Wan-Move

亮点直击
Wan-Move,一个用于图像到视频生成中运动控制的框架。与需要运动编码的现有方法不同,它通过编辑条件特征注入运动引导,无需添加新模块,从而易于大规模微调基础模型。
引入了MoveBench,一个全面且精心策划的基准来评估运动控制。一个混合了人工和SAM的标注流程确保了标注质量。
在MoveBench和公共数据集上进行的大量实验表明,Wan-Move支持多样化的运动控制任务,并通过大规模训练提供商业级结果。
总结速览
解决的问题
现有视频生成模型在运动控制方面存在控制粒度粗糙、可扩展性有限的问题,导致生成效果难以满足实际应用需求。
提出的方案
提出了Wan-Move框架,通过直接编辑原始条件特征来注入细粒度运动控制。其核心是:1)用密集点轨迹表示物体运动;2)将轨迹投影至隐空间并沿轨迹传播首帧特征,生成对齐的时空运动特征图;3)将该特征图作为运动条件,无缝集成至现有图像到视频基础模型(如Wan-I2V-14B)。
应用的技术
-
基于密集点轨迹的细粒度运动表示
-
隐空间特征投影与传播技术
-
无需修改架构的即插即用式运动条件注入方法
-
用于基准评估的混合标注流程(人工+SAM)
达到的效果
-
实现精确、高质量的运动控制,支持多样化控制任务
-
生成5秒480p视频,运动控制质量媲美商业级产品(如Kling 1.5 Pro Motion Brush)
-
无需额外运动编码器,大幅提升框架可扩展性,支持大规模基础模型微调
-
构建MoveBench评估基准,提供高质量、长时长、大数据的运动标注测试集
架构方法
视频扩散模型在正向过程中向干净数据添加高斯噪声,并学习反向过程以去噪和生成视频。为了降低计算成本,去噪网络通常在从预训练VAE获得的潜在视频表示上操作。给定输入视频,编码器压缩时间和空间维度,压缩比分别为(时间)和(空间),同时将通道维度扩展到,得到。解码器然后从潜在表示重建视频。
本文工作专注于运动可控的图像到视频(I2V)生成,其中模型需要根据输入的第一帧图像和运动轨迹生成运动连贯的视频。虽然第一帧将通过VAE编码成条件特征,但运动轨迹(可以以不同格式表示)仍保留在像素空间中。因此,关键挑战在于如何有效地将运动轨迹编码成条件特征并将其注入生成模型。为了避免与额外运动编码器和融合模块相关的信号退化和训练困难,本文旨在开发一个无需架构修改即可利用现有I2V模型的运动控制框架。
潜在轨迹引导
为了实现以第一帧为条件的视频生成,流行的I2V模型采用的一种有效方法是将潜在噪声和第一帧条件特征沿通道维度拼接起来。
通过使用预训练VAE编码器编码第一帧以及零填充的后续帧获得:
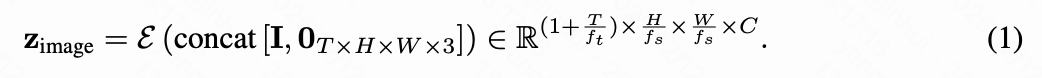
对于运动引导表示,本文遵循先前研究,采用点轨迹,因为它们提供细粒度控制并捕获局部和全局运动。形式上,长度为的点轨迹可以表示为,其中指定了像素空间中第帧的轨迹位置。现有方法通常采用辅助模块来编码轨迹并将其集成到骨干网络中。然而,这种方法可能会在运动编码过程中降低运动信号。此外,训练额外的模块增加了大规模微调基础模型的复杂性。这引出了一个关键问题:能否在没有辅助模块的情况下注入像素空间运动引导?
直观地说,I2V生成旨在动画化第一帧,而运动轨迹指定了每个后续帧中物体的位置。鉴于VAE模型的平移等变性,相应轨迹位置的隐空间特征应与第一帧中的特征非常相似。受此启发,本文提出通过空间映射直接将轨迹编码到隐空间,从而消除对额外运动编码器的需求,如如下公式所示:
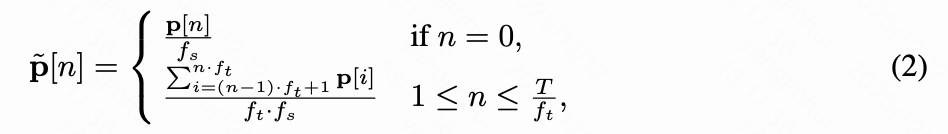
第一帧的潜在轨迹位置通过空间映射获得,而后续帧的潜在轨迹位置则在每个连续的帧上取平均。这确定性地将像素空间轨迹转换为隐空间。为了注入获得的潜在轨迹,本文提取第一帧在初始轨迹点处的隐空间特征,并根据将其复制到后续帧中,利用隐空间特征的平移等变性,如下图2(a)所示。
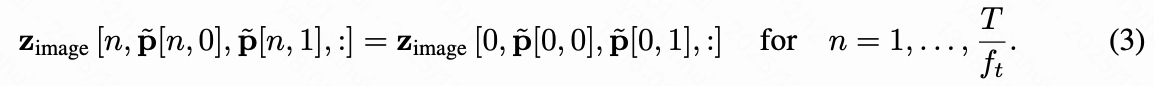
其中,表示时间索引、高度和宽度处的特征向量。此操作通过更新有效地将运动引导注入条件特征,消除了对显式运动条件特征和注入模块的需求。Wan-Move生成框架的概述如下图2(b)所示。当多个可见点轨迹在给定的时空位置重合时,本文随机选择一个轨迹对应的第一帧特征。
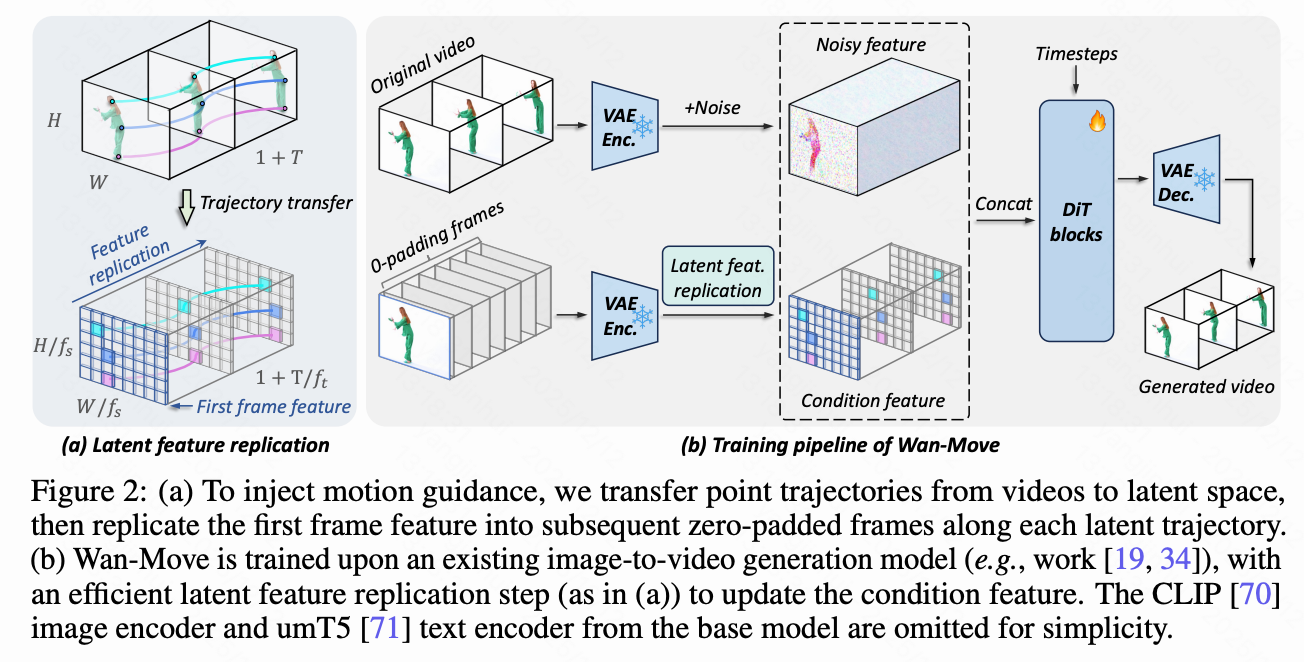
训练和推理
训练数据 本文整理了一个高质量的训练数据集,该数据集经过严格的两阶段过滤,以确保视觉质量和运动一致性。首先,手动标注了1,000个样本的视觉质量,并使用它们训练了一个专家评分模型进行初步质量评估。为了进一步提高时间连贯性,本文引入了运动质量过滤阶段。具体来说,对于每个视频,本文从第一帧中提取SigLIP特征,并计算剩余帧的平均SigLIP特征。这些特征之间的余弦相似度作为本文的稳定性度量。根据对10,000个样本的经验分析,本文建立了一个阈值,只保留内容与初始帧保持一致的视频。这个两阶段流程最终产生了200万个高质量的720p视频数据集,具有强大的视觉质量和运动连贯性。
模型训练 基于训练数据集,本文使用CoTracker来跟踪密集32x32点网格的轨迹。对于每个训练迭代,本文从混合分布中采样个轨迹:以5%的概率不使用轨迹();以95%的概率,从1到200中均匀采样。值得注意的是,本文保留了5%的概率来放弃运动条件,这有效地保留了模型原始的图像到视频生成能力。对于选定的轨迹,本文提取第一帧特征并将其复制到后续的零填充帧中,如上文公式(3)所述。由于CoTracker区分可见和被遮挡的点轨迹,本文只沿着可见轨迹进行特征复制。在训练期间,模型参数从I2V模型初始化,并进行微调以预测向量场,该向量场将样本从噪声分布传输到数据分布:
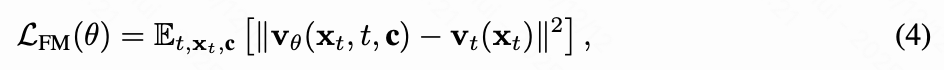
其中,表示生成条件的联合。
Wan-Move的推理 推理过程与原始I2V模型非常相似,只是增加了一个隐空间特征复制操作。具体来说,Wan-Move的生成过程依赖于三个输入条件:(1)文本提示,(2)作为第一帧的输入图像,以及(3)用于运动控制的稀疏或密集点轨迹。预训练的umT5和CLIP模型分别用于编码文本提示和第一帧的全局上下文。生成的图像嵌入和文本嵌入随后通过解耦的交叉注意力注入到DiT骨干网络中。此外,VAE用于提取第一帧条件特征,该特征将通过隐空间特征复制注入。应用无分类器引导以增强与条件信息的对齐。形式上,设无条件向量场,以及条件向量场。引导向量场是条件和无条件输出的加权组合,其中引导尺度为:
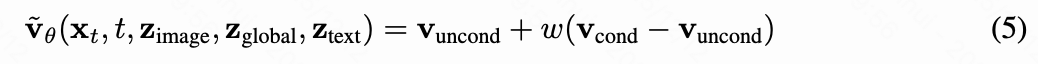
MoveBench
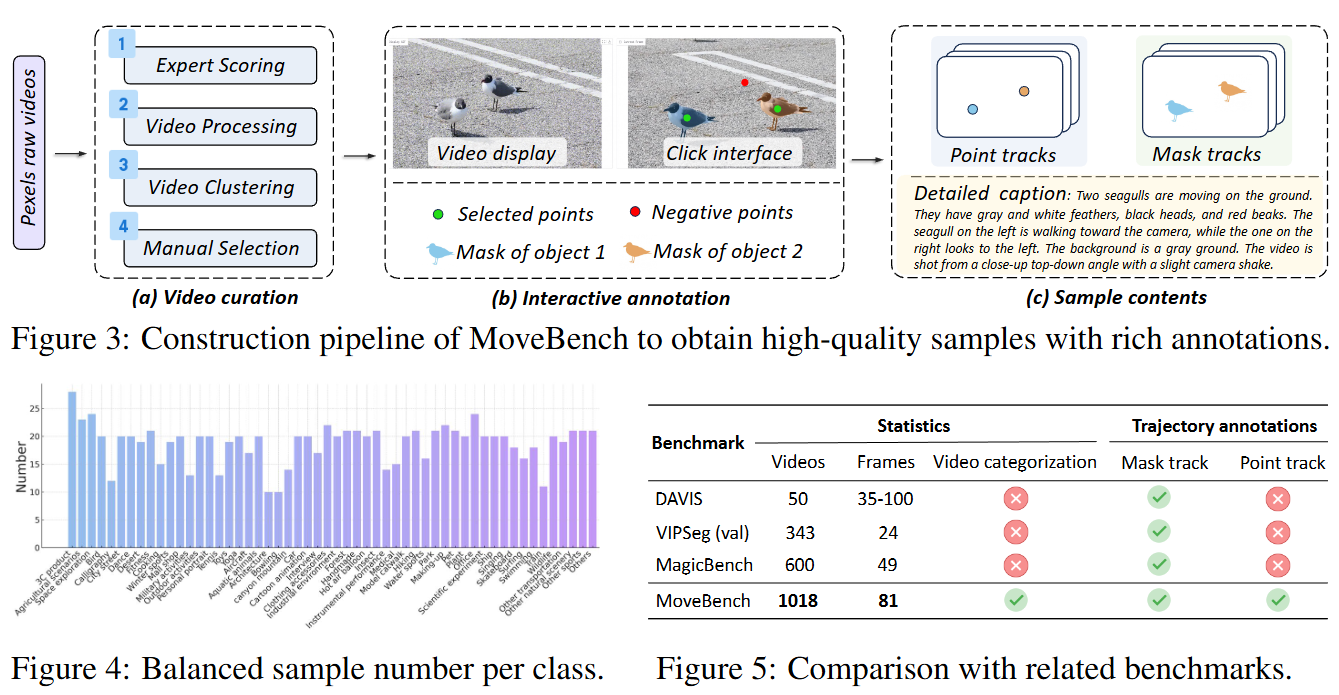
为了对运动控制方法进行严格、全面的评估,本文引入了一个名为MoveBench的自由许可基准。与现有基准相比,MoveBench提供了更多数据、更大的多样性和可靠的运动标注(如上图5所示)。具体而言,本文设计了一个筛选流程,将视频库分为54个内容类别,每个类别10-25个视频,产生了1000多个案例,以确保广泛的场景覆盖。所有视频片段均保持5秒的时长,以方便评估长距离动态。每个片段都配有针对单个或多个物体的详细运动标注。它们包括精确的点轨迹和稀疏的分割掩码,以适应各种运动控制模型。通过开发一个交互式标注流程,结合人工标注和SAM预测,本文确保了标注质量,兼顾了标注精度和自动化可扩展性。
实验
实验部分对Wan-Move在视频生成中的运动控制能力进行了全面评估,并与多种现有方法进行了比较。
-
实验设置:Wan-Move基于最先进的图像到视频生成模型Wan-I2V-14B实现,并在一个包含200万个高质量视频的数据集上进行微调。评估指标包括FID、FVD、PSNR、SSIM用于衡量视频质量,以及EPE用于评估运动精度。所有评估均在480p分辨率下进行。
-
主要结果 :
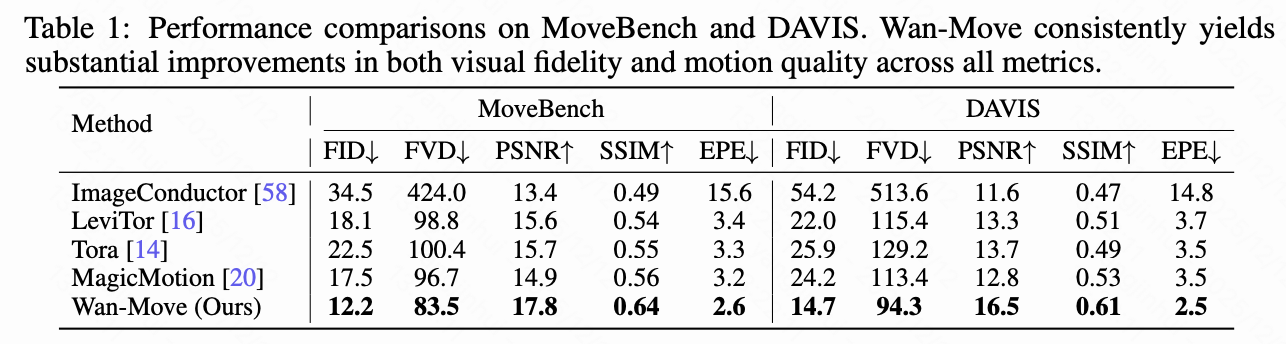
- 单物体运动控制:如下表1所示,Wan-Move在MoveBench和DAVIS数据集上均显著优于ImageConductor、LeviTor、Tora和MagicMotion等方法,在视频质量(最高PSNR和SSIM)和运动控制精度(最低EPE)方面表现最佳。
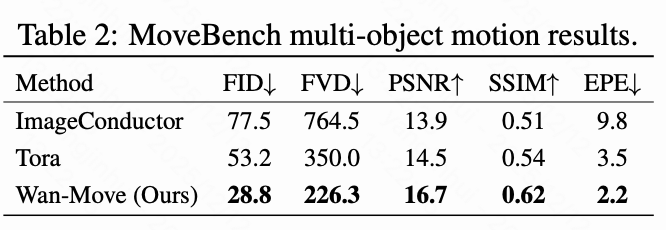
- 多物体运动控制:在MoveBench中包含192个多物体运动场景的挑战性设置下,如下表2所示,Wan-Move相比ImageConductor和Tora实现了更低的FVD和EPE,表明其在复杂场景下对运动约束的精确遵守能力。
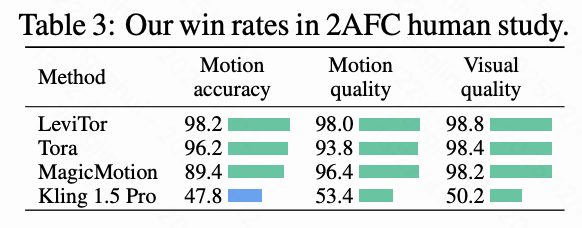
- 人类研究:如下表3所示,在与SOTA方法(Tora、MagicMotion、LeviTor、Kling 1.5 Pro)进行的双向强制选择(2AFC)人类评估中,Wan-Move在运动准确性、运动质量和视觉质量方面均表现出卓越的胜率,尤其是与商业模型Kling 1.5 Pro相比,Wan-Move在运动质量方面具有竞争性优势。
消融研究
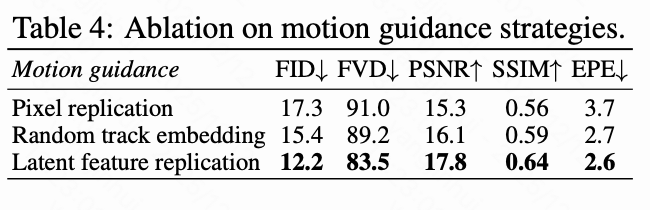
- 轨迹引导策略:如下表4和下图8所示,本文比较了像素复制、随机轨迹嵌入和隐空间特征复制三种策略。结果表明,本文提出的隐空间特征复制方法在视频质量和运动控制精度方面均优于其他方法,这归因于其能够捕获丰富的局部上下文信息。

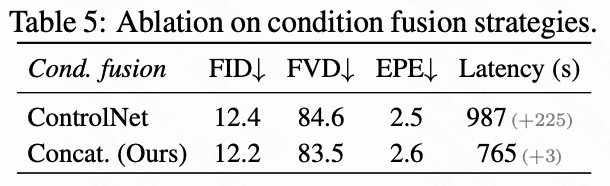
- 条件融合策略:如下表5所示,本文比较了ControlNet和本文的直接拼接方法。结果显示,简单的拼接方法在性能上与ControlNet相当,但显著降低了推理延迟,仅增加了3秒,而ControlNet增加了225秒,突显了本文方法的高效性。
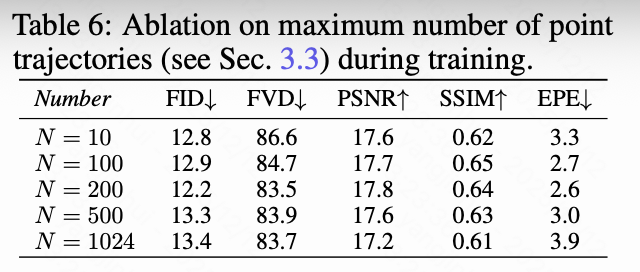
- 训练期间点轨迹数量:如下表6所示,本文研究了训练期间最大点轨迹数量对性能的影响。N=200时达到最佳性能,过多的轨迹反而可能导致EPE上升,这可能是训练和评估时轨迹密度不匹配造成的。
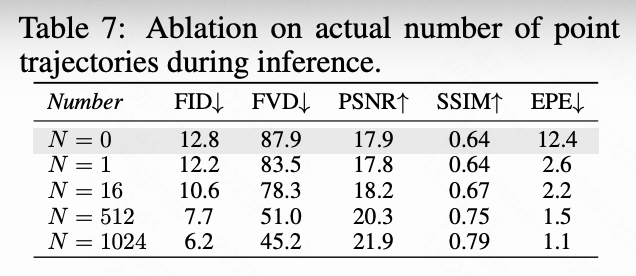
- 推理期间点轨迹数量:如下表7所示,推理时增加点轨迹数量会显著降低EPE,提高运动引导和时间连贯性。即使模型在最多200个轨迹下训练,也能在多达1024个轨迹下表现出强大的泛化能力。此外,无点轨迹的I2V推理(如下图9所示)的PSNR和SSIM与运动控制生成相当,表明模型保留了固有的I2V质量。

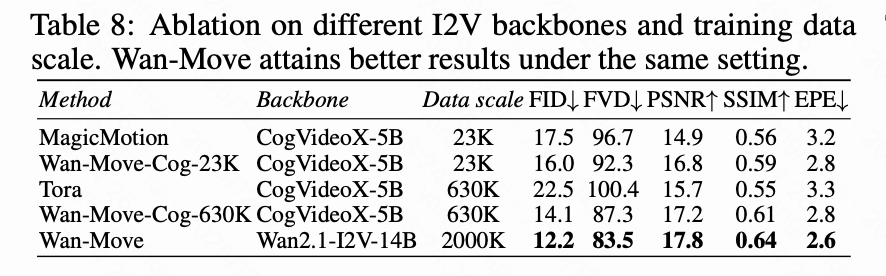
- 骨干网络和数据规模:如下表8所示,在相同骨干网络和数据规模下,Wan-Move即使与MagicMotion和Tora等方法相比,仍能取得更好的结果,这验证了本文方法的优越性。
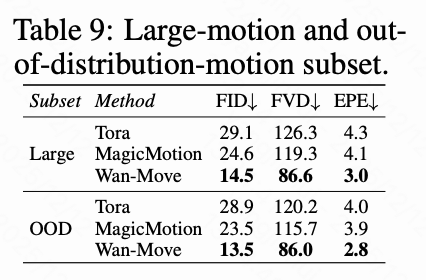
- 大运动和分布外运动场景:如下表9所示,在包含高幅度运动和不常见运动的子集上,Wan-Move持续优于基线模型,性能差距进一步扩大,展示了其强大的泛化能力和鲁棒性。
- 运动控制应用:Wan-Move支持广泛的运动控制应用,如上图1所示,包括单/多物体控制、相机控制、原始级别控制(例如旋转虚拟球体)、运动迁移和3D旋转控制。
总结与讨论
Wan-Move,一个简单且可扩展的框架,用于视频生成中精确的运动控制。它通过点轨迹表示运动,并通过空间映射将其传输到潜在坐标,无需额外的运动编码器。随后,通过隐空间特征复制将轨迹引导注入第一帧条件特征,在不改变架构的情况下实现了有效的运动控制。为了进行严格评估,本文进一步提出了MoveBench,一个全面且精心策划的基准,其特点是内容类别多样且具有混合验证的标注。在MoveBench和公共数据集上进行的大量实验表明,Wan-Move能够生成高质量、长持续时间(5秒,480p)的视频,其运动可控性与Kling 1.5 Pro的Motion Brush等商业工具不相上下。本文相信,这项开源解决方案为大规模运动可控视频生成提供了一条高效途径,并将赋能广泛的创作者。
局限性和更广泛的影响 Wan-Move使用点轨迹来引导运动,当轨迹因遮挡而缺失时,其可靠性可能会降低。尽管本文观察到短期遮挡一旦点重新出现即可恢复,显示出一定程度的泛化能力,但长时间的缺失可能导致控制的丧失(参见附录)。与其他生成模型一样,Wan-Move具有双重用途潜力。它生成逼真、可控视频的能力可以造福创意产业、教育和模拟,但也存在被滥用于生成误导性或有害内容的风险。
参考文献
1 Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance