循环神经网络(Recurrent Neural Network, RNN)是一类专门针对序列数据(文本、语音、时间序列等)设计的深度学习模型,其核心创新在于引入隐藏状态(Hidden State) ,使它能够"记忆"序列历史信息并传递到当前决策,从而天然捕捉数据中的时序依赖关系,这是传统神经网络(MLP)和卷积神经网络(CNN)无法高效实现的核心功能。
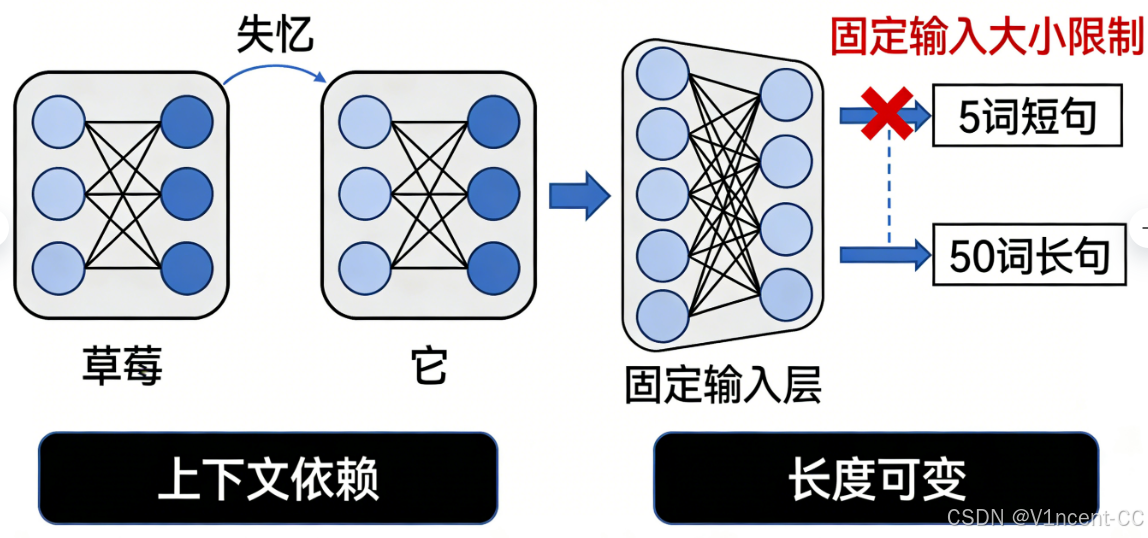
一、传统神经网络的缺陷:面对序列数据的"失忆"与"僵硬"
序列数据是指元素之间存在时间/顺序关联的数据,我们周围的数据,有很大一部分不是独立的、孤立的点,而是有顺序、有依赖关系的序列,如:文本、语音、时间序列(股价走势)。
序列的本质特点是:
- 上下文依赖(Context Dependency): 例如这句话:"我喜欢吃草莓,因为它很甜。"作为人类,你可以立刻理解句子中的"它"指代是前面提到的"草莓"。
- 长度可变(Variable Length): 句子的长度通常是不固定的,一句话可以是 5 个词,也可以是 50 个词。
面对序列的这两个特点,传统的神经网络都无法很好的处理:
- 无法捕捉上下文(健忘): 传统神经网络每次输入都只处理一个独立的点,它们会"失忆",无法将上一步处理的信息传递到下一步。例如,在处理"它"这个词时,它会忘记前一个词是"草莓"。
- 结构僵硬(固定输入): 传统神经网络(MLP)和卷积神经网络(CNN)要求输入层和输出层必须是固定大小的向量。这意味着你无法用同一个固定输入的网络来处理 5 个词和 50 个词的句子。
二、循环神经网络是如何处理序列的:记忆与共享
循环神经网络正是为了解决传统模型难以应对的序列数据两大挑战(可变长度与上下文依赖)而诞生的,它通过结构创新实现了 "记忆"和"参数共享" 这两大关键能力。
2.1 核心机制:时间轴上的循环与展开
从结构图上,循环神经网络(RNN)看起来非常简单:它只有一个神经层,但该层的输出会循环输入回自身,这个循环结构是其"记忆"的来源。
循环神经网络中的每个神经元都有一个"隐藏状态",充当序列中的记忆点,该隐藏状态是当前输入和先前隐藏状态的函数,使网络能够保留序列中先前输入的信息。通俗的说:当网络读完第一个词后会记住了它的信息,在读第二个词时会带着第一个词的记忆来理解,并生成新的记忆,这个过程不断重复,确保每个元素的处理都建立了完整的上下文。
假设任务是分析句子:"我喜欢吃草莓,因为它很甜。",循环神经网络(RNN)则会逐字逐句地处理句子,并在处理过程中保留先前单词的信息:
| 步骤 | 当前输入 | 上一步记忆 | 产生的输出和新记忆 |
|---|---|---|---|
| t=1 | 我 | 初始空记忆 | 记住主语"我"。 |
| ... | ... | ... | ... |
| t=5 | 草莓 | 记住"我喜欢吃" | 记忆状态现在包含"主体喜欢吃某种水果"。 |
| t=6 | , | 记住所有信息直到"草莓" | 记忆保持。 |
| t=7 | 因为 | 记住所有信息直到"草莓" | 记忆保持。 |
| t=8 | 它 | 记忆包含"草莓"这个词的信息 | 输出知道"它"大概率指代前面的名词"草莓"。 |
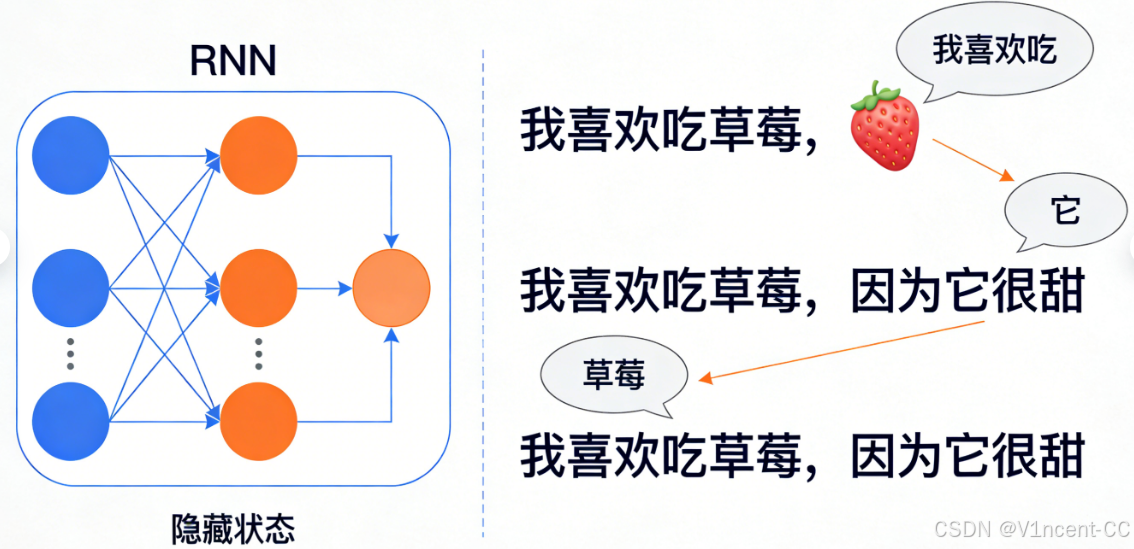
传统的前馈网络在处理"它"时,会忘记"草莓"的存在,但 RNN 的记忆让它能够成功捕获这种长距离依赖关系。
2.2 参数共享:处理可变长度序列
RNN 能够处理任意长度的序列,关键在于它在所有时间步上共享同一套权重参数,
- 同一套规则: 无论序列有多长(5个词还是50个词),处理每个词时使用的数学函数(即权重 WWW)都是同一套。
- 高效性: 这种共享机制使得 RNN 不会因为序列变长而增加模型参数量,保证了模型学习到的规则在序列的任何位置都有效,从而解决了传统网络必须固定输入长度的局限。
三、梯度消失问题
循环神经网络(RNN)虽然强大,但也存在一个严重的技术瓶颈:长距离依赖的梯度消失/爆炸问题。当序列过长时(如超过 20 个元素),历史信息在传递过程中会逐渐衰减(梯度消失)或无限放大(梯度爆炸),导致模型无法学习长距离关联。
3.1 梯度消失:信息传递的"连乘惩罚"
模型的学习是通过随时间反向传播(BPTT),将误差信号(梯度)从序列末尾向序列开头回传,在回传过程中,梯度信号需要经过多次与小于 1 的权重和激活函数导数相乘,如果连乘的因子(权重和导数)小于 1,乘积会呈指数级衰减,误差信号(梯度)在回传到序列早期的权重时,已经衰减到趋近于零。这使得模型**"忘记"了早期的关键信息**,无法将距离过远的信息点联系起来。
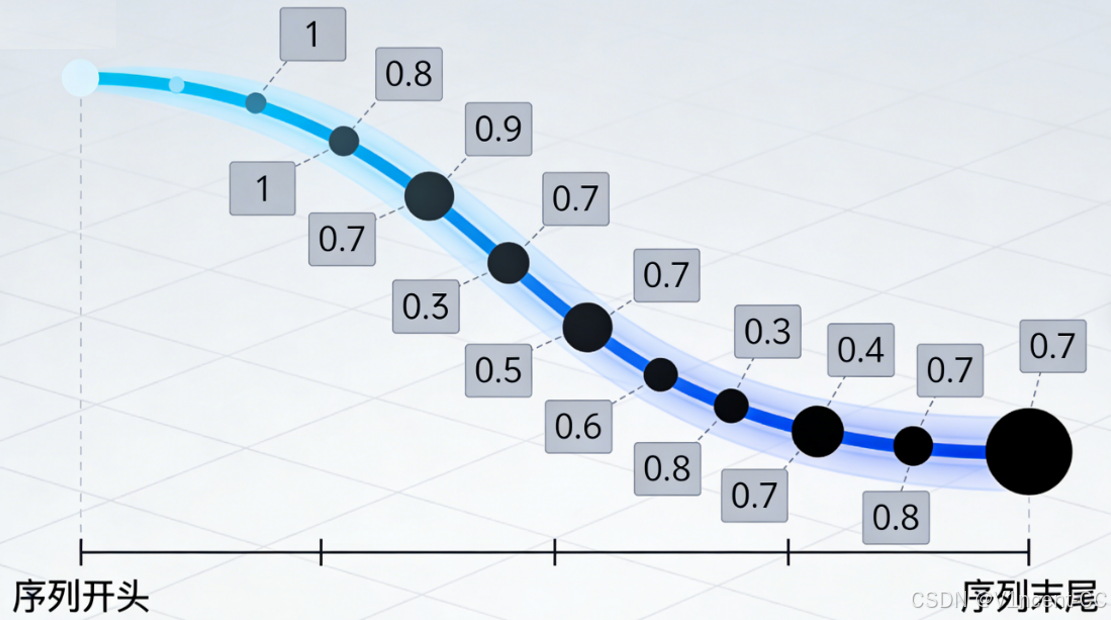
我们可以将神经网络想象成一个徒步旅行者,试图找到到达目的地的最佳路径,他通过观察坡度(即梯度)的变化来调整其路径(即权重)。
- 陡峭坡度 (大梯度): 意味着有很多东西需要学习,徒步者会对路径进行较大的调整。
- 平缓坡度 (小梯度): 意味着没有太多东西需要学习,调整微小。
- 极度平坦 (梯度消失): 在 RNN 的长序列中,坡度(梯度)经过多次连乘后,在序列的起点(早期权重) 变得极度平坦。徒步者(误差信号)陷入困境,它无法察觉到坡度的变化,因此无法对早期的路径(权重)进行有意义的调整。
3.2 解决方案:门控机制 (LSTM 和 GRU)
为解决这一致命问题,研究者提出了门控机制,通过**"选择性记忆"和"选择性遗忘"**来保留关键历史信息。这催生了更高级的 RNN 类型:
- 长短期记忆网络 (LSTM)
- 门控循环单元 (GRU)
它们引入了特殊的 "门"(Gate) 来控制信息流,门控机制决定了每一步应该传递多少信息到下一个隐藏状态,以及应该阻止或遗忘多少不重要信息。这使得模型能够选择性地保留重要信息,从而根本上缓解了梯度消失问题,使得 RNN 能够处理长达数百甚至上千个时间步的序列。
这种架构已被证明非常有效,使 RNN 能够成功应用于自然语言处理 (NLP) 中的复杂任务,包括机器翻译、情感分析、文本摘要和语言生成。
四、总结
循环神经网络(RNN)的本质是 "带记忆的神经网络",通过隐藏状态存储序列历史信息,当前输出不仅依赖当前输入,还依赖历史记忆,你可以把 RNN 想象成一个拥有短期记忆的"思考者"。