参考论文:https://arxiv.org/pdf/2512.05905
参考github: https://github.com/zai-org/SCAIL
主要贡献
(1) 我们提出了一种可扩展的 3D 姿态表示方法,该方法融合了 2D 骨架和 SMPL 的优势,可作为鲁棒的运动驱动信号。(2) 我们通过上下文推理注入驱动姿态控制,实现了有效的时空运动建模,在复杂的多人场景中取得了优异的成果。(3) 我们构建了一个高质量、多样化训练数据的收集流程,并建立了一个全面的 Studio-Bench 用于系统评估。(4) 我们的 SCAIL 框架在现有基线方法的基础上实现了最先进的性能,并将角色图像动画推向了生产级应用。
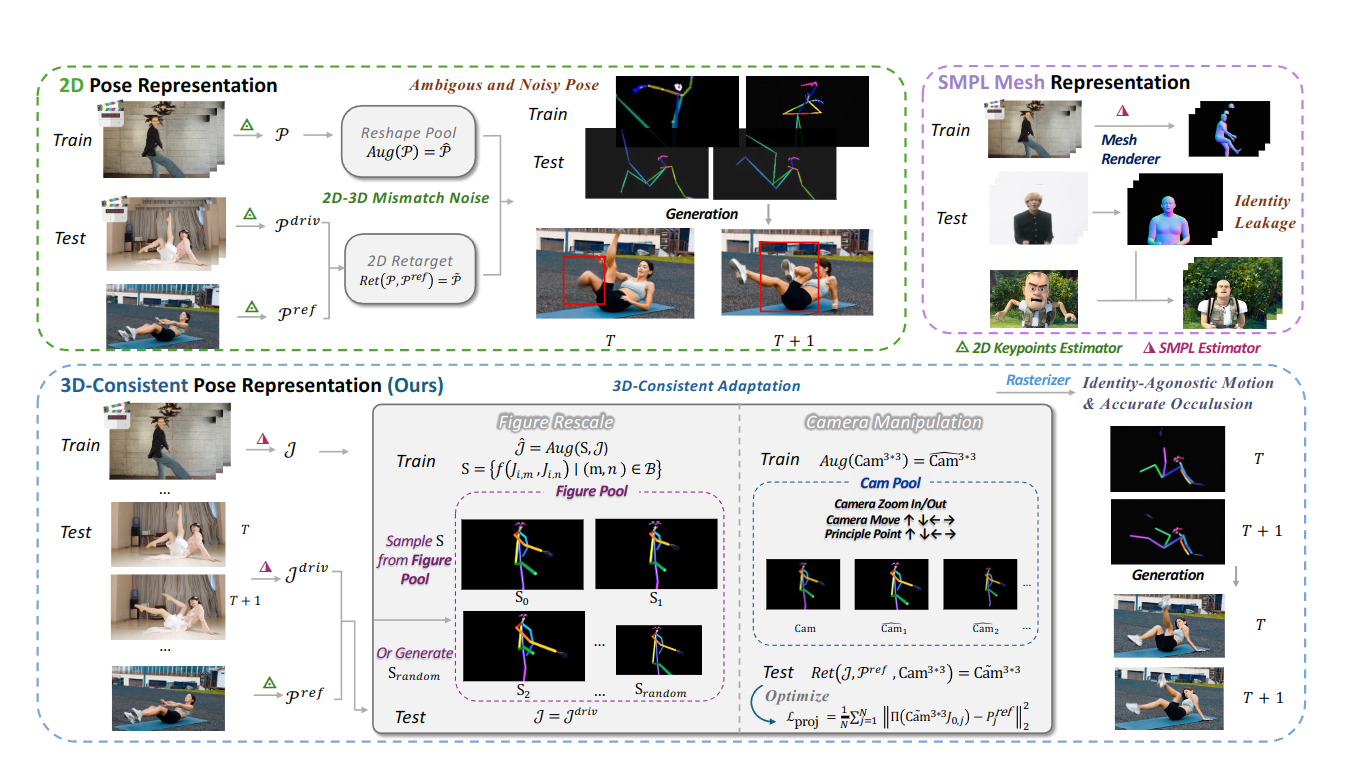
三维一致姿态调节
问题
二维关键点无法编码三维遮挡,使得模型难以从不完整或模糊的姿态信号中生成逼真的运动视频。另一个挑战来自参考图像和驱动姿态之间的差异,二者通常在体型或身份上有所不同。之前的研究30, 38通过在训练中缩放二维骨架或在测试中采用启发式重定向来缓解这种差异,但二维衍生的自适应方法本身就存在形变问题。
理想状态
参考姿态表示应该能够感知深度和遮挡,保持与身份无关,并具备扩展到多人场景的潜力。
解决问题
为了保留 2D 投影中丢失的遮挡和深度线索,我们将 3D 骨骼渲染为圆柱形片段,以提供运动驱动信号。
示意图
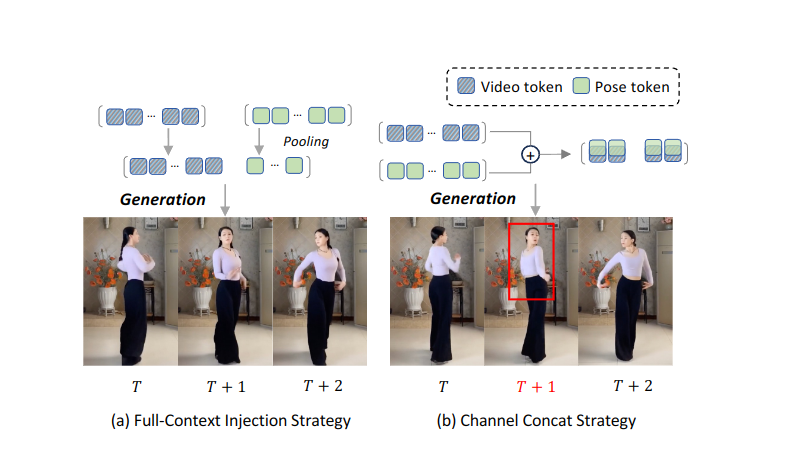
全上下文驾驶姿态注入
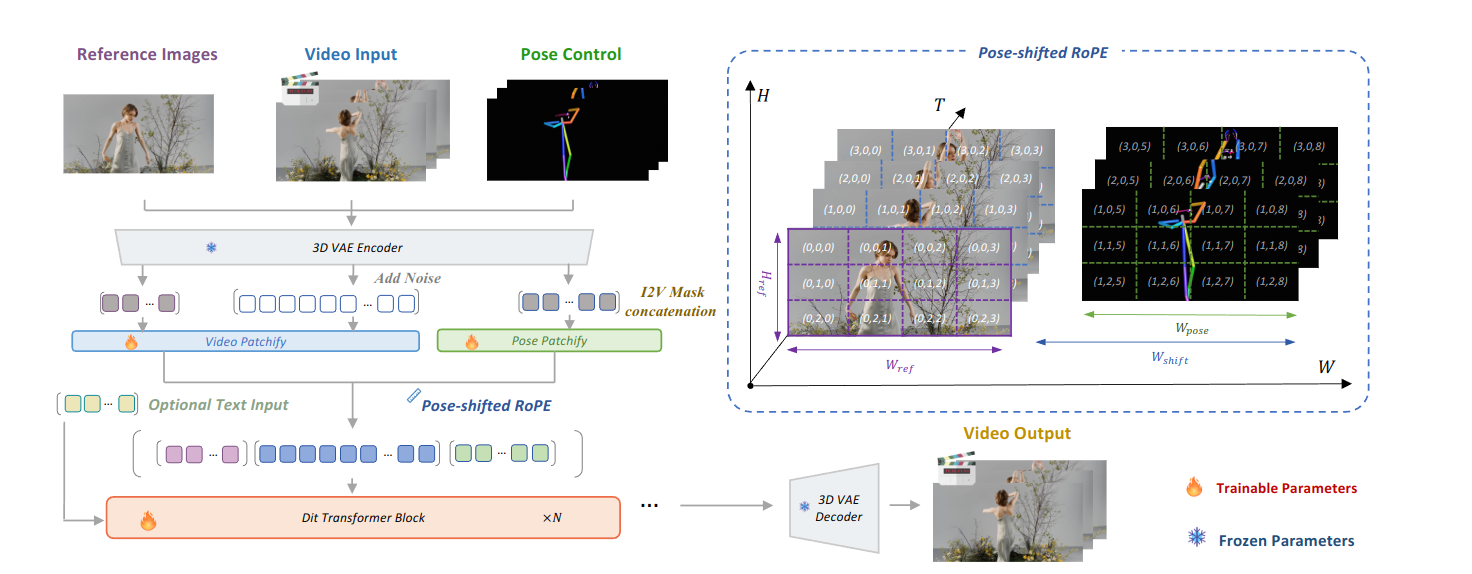
用于姿态上下文的移位 RoPE
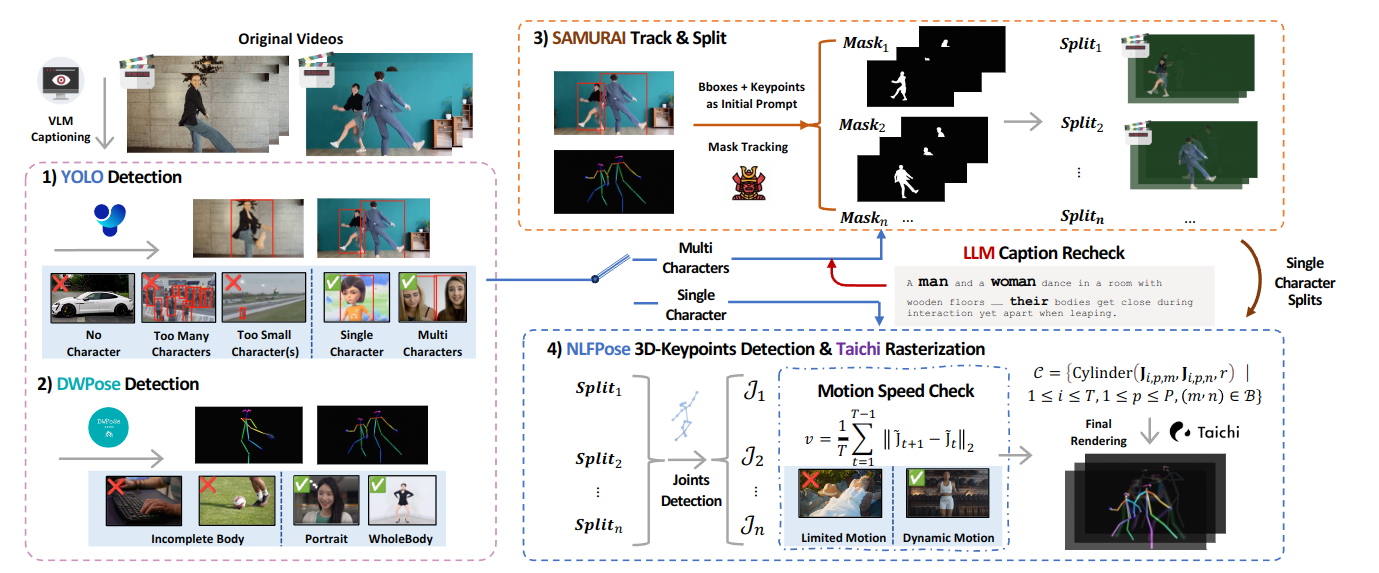
数据过滤pipeline
网络结构
实验细节
我们训练了模型的两个版本(1.3B 和 14B)。1.3B 模型基于 Wan2.1-1.3B-Fun-Inp 骨干网络,在我们的预训练数据集上进行微调,训练步数为 6000 步,批大小为 96,学习率为 1e-5,使用 32 个 NVIDIA H100 GPU,耗时约两天。对于更大的 14B 模型,我们分两个阶段基于 Wan2.1-I2V-14B 骨干网络进行微调:在预训练阶段,我们以 96 的批大小训练 8000 步,学习率为 1e-5。初始学习率为 1e-5;收敛后,我们以相同的批大小和较低的学习率(4e-6)进行 400 步的额外微调。14B 模型的训练在 128 个 NVIDIA H100 GPU 上进行,历时四天以上,并启用了序列并行。所有模型均使用 AdamW 21 进行优化。在推理过程中,我们将无分类器引导 (CFG) 的尺度 10 设置为 4,从而在姿态跟踪和视频保真度之间取得良好的平衡。