目录
[1. UCF101](#1. UCF101)
[2. HMDB51](#2. HMDB51)
[3. NTU-RGB+D 60/120](#3. NTU-RGB+D 60/120)
[4. kinetics 400](#4. kinetics 400)
前言
本文选用的数据集,主要用于本人提出的基于骨骼关键点的行为识别算法测试,也是行为识别/动作识别/视频分类论文中常用的数据集。
包括:UCF101、HUMDB51、NTU-RGB+D 60/120、Kinetics 400、UAVHuman。
大部分数据集都可以在MMACTION2的教程中找到:
https://mmaction2.readthedocs.io/zh-cn/latest/![]() https://mmaction2.readthedocs.io/zh-cn/latest/
https://mmaction2.readthedocs.io/zh-cn/latest/
由于开源数据集只给了关键点数据,我还需要置信度以及检测框信息,所以这些数据集我都自己用yolo-pose和FasterRCNN+HRNet重新预测并获取了数据:关键点及其置信度、检测框及其置信度,用于更好设计基于yolo-pose关键点的行为识别算法。
1. UCF101
视频分类数据集中的"ImageNet",只含有RGB视频,关键点需要自己用姿态估计算法去预测获取。视频分辨率较低(320P)。
视频总数:13,320,类别数:101,含有3种划分,需要3-折交叉验证。
数据集详细介绍:
https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar![]() https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar 如下图可视化所示(yolov8x-pose在640分辨率下预测),对开放数据集,也就是真实世界数据集,基于关键点预测时会存在以下问题:
https://www.crcv.ucf.edu/datasets/human-actions/ucf101/UCF101.rar 如下图可视化所示(yolov8x-pose在640分辨率下预测),对开放数据集,也就是真实世界数据集,基于关键点预测时会存在以下问题:
**1.人数不确定。**开放数据集并不一定是1~2个人,可能十几个人都有,甚至可能只有检测框(例如梳头时候,只有头发和手,导致一个关键点都没有)。
**2.存在无关人员。**打排球的场景,座位上存在大量的无关人员预测,他们对预测类别无效。
**3.人物尺度变化大。**远近视角不确定导致人物占视频画面比例相差较大。
**4.同一个人的误检。**由于视角多样,一个人也可能有多重预测(IOU无法过滤)。
**5.难以跟踪。**引入跟踪算法会存在巨大不确定性。
**6.部分类别不适合基于COCO关键点去做。**例如涉及到手势、手部动作、手持物品等行为。

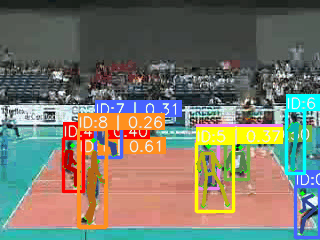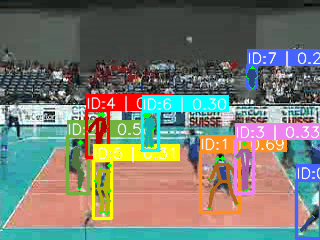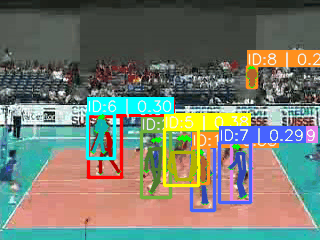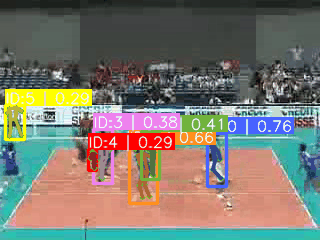
**神奇的是:**基于关键点的检测,每帧只选取一个人,也可以把UCF101的准确率做到80%+。
**可以合理猜测:**决定一个动作类别的可能只有某一帧的某一个动作。
2. HMDB51
比UCF101小,含有RGB视频,也有对应的关键点数据集JHMDB(但是是个子集,只有21类)。原始视频数据集需要自己去获取关键点,视频分辨率低(320P)。
视频总数:6,849,类别数:51,含有3种划分,需要3-折交叉验证。
数据集详细介绍与下载地址:
https://serre.lab.brown.edu/hmdb51.html![]() https://serre.lab.brown.edu/hmdb51.html 如下图可视化所示(Faster-RCNN+HRNet在mmaction/PoseC3D默认配置下预测):
https://serre.lab.brown.edu/hmdb51.html 如下图可视化所示(Faster-RCNN+HRNet在mmaction/PoseC3D默认配置下预测):


上图只显示了选取的前3个人(论文中通常只会选取1~2个人,这里便于可视化,显示了3个人)。可以发现:
1.第1张梳头动作。即使动作简单也会存在大量误检。
选取两个人时候,可能会有一个重复。但这反而会提高准确率!不能用直觉去理解。关键点只是对图片的建模,相当于提取出一组17*3*2的特征向量,假如所有梳头都会出现"两个人"的手臂完全一样,这样本身也是一种显著的特征,利用分类。
2.第2张投篮动作。但是在选取两个人的条件下,最左边**真正执行动作的人,可能选择不到。**这就导致,这个类区分正确与否,并不在于算法的设计,而是数据本身存在噪声。
3. NTU-RGB+D 60/120
实验室数据集,数据较为简单,也是论文中用的最多最卷的数据集。
**关键点数据(可直接下载):**官方提供了25个3D关键点的标注、深度信息和RGB信息关键点(对3D点的投影,试了分类比3D关键点低8%,但是和3D点一起输入可以提高1~2%准确率,不过论文中没有这样的做法)。
**RGB视频(需要用教育身份去申请):**1080P高清视频,关键点需要自己用姿态估计算法去预测获取。
NTU60视频总数:56,880个,存在302个问题3D关键点文件,所以有效样本数为56,578个。其中CS划分train/val: 40091/16487;CV划分train/val: 37646/18932。
NTU120视频总数:114,480,存在535个问题3D关键点文件,所以有效样本数为113,945个。其中CS划分train/val: 63026/50919;CSET划分train/val: 54468/59477。
数据集介绍和下载地址:
需要RGB视频的需要在下面用教育身份申请,不算很难通过:

通过后,下面这样就可以下载了:

这个数据集个人感觉是存在一些问题的,CS的划分的训练数据是比CV多的,但训练出来的准确率,CS要比CV低5%,因为后者是用视角去划分的,所以网络学习到的是同一个动作不同视角的相似特征,而泛化性并没有那么高。
3D关键点可视化参考前文训练ST-GCN的可视化代码:
基于关键点的行为识别(1)- 搭建ST-GCN(图卷积方法)的新训练框架![]() https://blog.csdn.net/qq_40387714/article/details/155860538
https://blog.csdn.net/qq_40387714/article/details/155860538
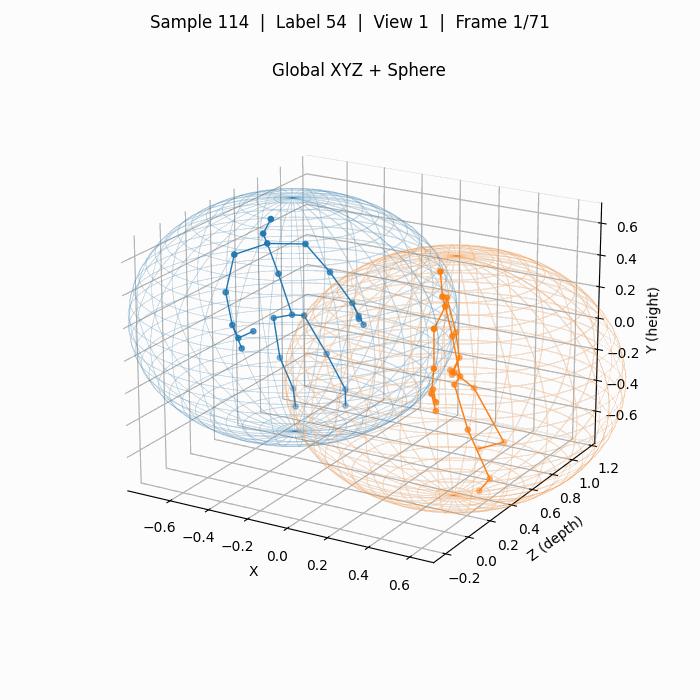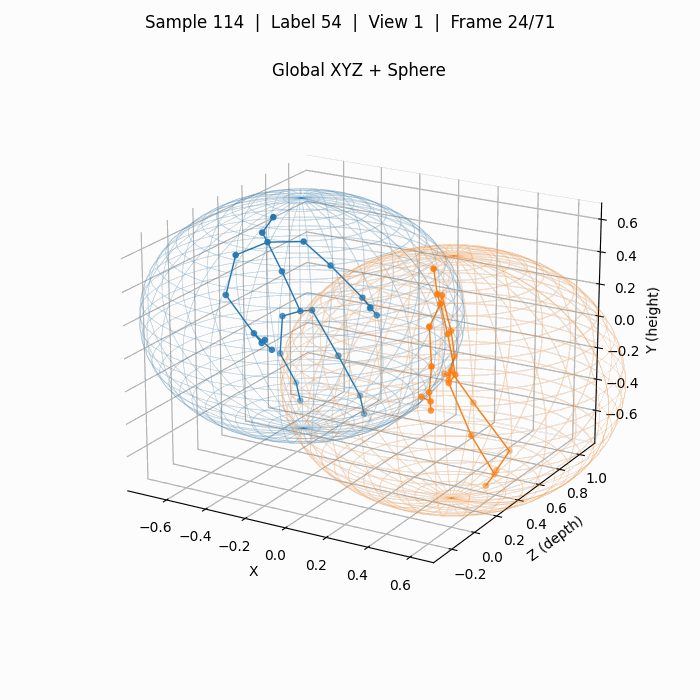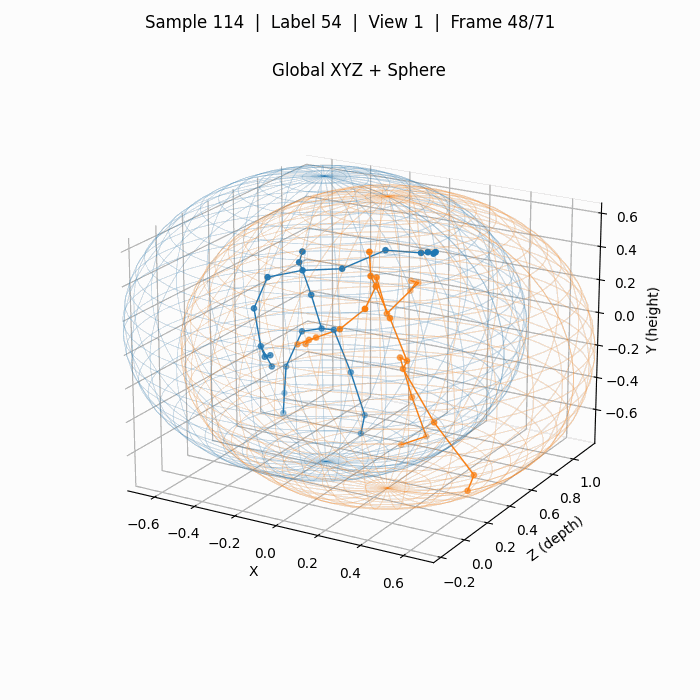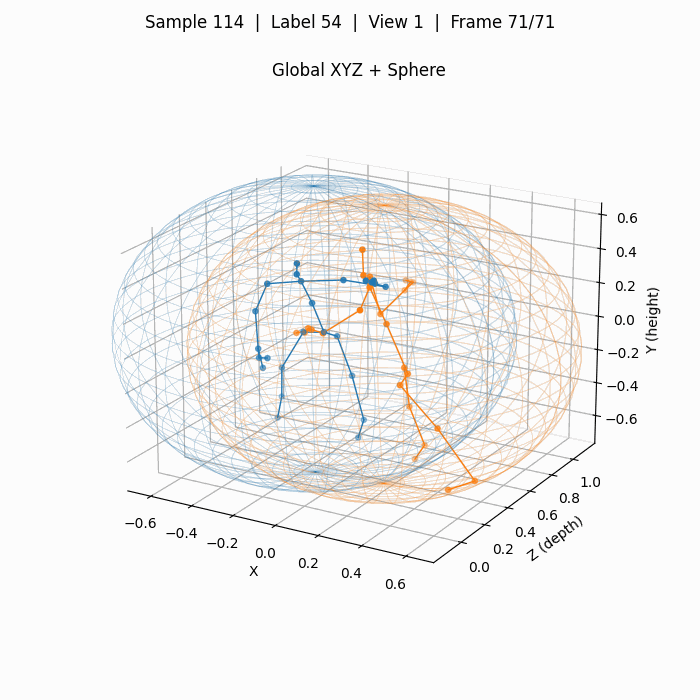
对应上图3D关键点的拥抱,下图为使用YOLOv8x-pose预测得到的2D关键点(COCO-pose定义的17个点),其质量远高于3D关键点。
原始的检测结果/mmation中的仅基于检测框的目标追踪会产生ID Switch (开始框为黄色,结束变为蓝色)。

我们对检测框内进行了一次关键点提取(本质就是特征提取)。下图中,我在跟踪算法中引入关键点信息,通过关键点距离即可很简单地区分出两个跟踪ID (优化后,左边始终为蓝色,当然我们还可以引入更复杂的方式,比如加一个线性层编码之类的,来做更多优化)。

我自己的网络使用2D关键点预测,在CS划分上,单流Joint准确率约为92%,通过分析分类错误的原因,大致只有两种:
**1. 非肢体类 / 物品相关动作无法区分:**比如手写签名、敲击键盘、手指翻书、持枪、持棒球棒等动作,因为涉及到手指的动作,或者和物品外观特征信息相关,仅依靠COCO-pose的17个点,是无法区分出这些动作的。
**2.遮挡问题:**相比于用传感器获取的3D关键点,2D图像的检测,更容易受遮挡影响,一旦遮挡就是乱猜。
(因为是实验室数据集,几乎不含额外噪声,所以yolov8s-pose的检测准确率都可以有90%,和v8x、FasterRCNN+HRNet的92%差距很小。)
如下图,预测错误的(玩手机和敲键盘),我们是不能通过站立和坐着来区分的(站着坐着都能做这个两个动作,两个动作的核心区别在手指上的动作差异):


个人认为:
该数据集上,3D关键点的预测误差主要来自于传感器获取的关键点的不稳定性。
基于2D-pose的动作准确率超过90%以后,再提升意义就不大了,更多的是过拟合。比如上述"玩手机"和"敲键盘",现实中,这些动作是五花八门的,不可能做得这么"标准"让你去检测,我们更多会引入手部patch的图像信息来做区分。
所以,基于关键点的行为识别在真实场景中,应用也是相对受限的,"摔倒"检测可能是最适合的一个应用。
NTU120引入了更多和肢体动作不相关的行为,所以使用2D关键点的效果也会变差很多,比如自测在NTU120-CS划分上,单流Joint仅有82%的准确率。
4. kinetics 400
**目前,基于关键点的行为识别里用到的最大数据集了,共400类,共有25W+的数据。**其中训练集有23W+数据,验证集理论上有400*50=2W条,即每个类别50条测试数据,但由于部分视频链接丢失,实际可用的只有1.9W+条。
随机采样2W条视频,计算平均尺寸,发现将yolo-pose推理尺寸设置为736最合适。
使用该数据集获取预测COCO-pose关键点,v8x八卡需要推理2周,FasterRCNN+HRNet需要推理40天。可以说,极大消耗算力了,也说明实时应用根本用不了FasterRCNN+HRNet,太慢了!!!
使用yolov8x-pose我总共获取了239,102条训练集关键点数据 (一帧关键点结果都没有的数据丢弃了),获取了19,877条验证集数据 (没有结果的视频都填0占位)。理论上验证集的数据量用2W,但是很多论文中,并没有这样做,所以准确率含有一定水分。
数据集下载地址(最好留有1T硬盘,压缩包+解压缩,还要存关键点数据):
https://github.com/chi0tzp/KineticX-Downloader![]() https://github.com/chi0tzp/KineticX-Downloader
https://github.com/chi0tzp/KineticX-Downloader
由于该数据集太大了,很难一次性加载,需要使用缓存和预加载来读取。在数据生成上,训练集可以每个类生成一个npz数据:
5.UAVHuman
无人机视角下的行为识别,论文里说用FasterRCNN+HRNet获取了关键点,且还用人工进行了矫正。不过看数据就是一坨。该数据就用官方给的关键点训练测试了,自己用yolov8x-pose跑出来的结果也是一坨,但能用更好的数据预处理,可以比官方数据准确率好一点点(1%左右)。
视频总数:22,476,类别数:155,含有2种划分。CS1,train/val: 16,723 / 6,307;CS2, train/val: 16,431 / 6,599。含有部分空数据丢弃了。
该数据集低调且不卷,适合水论文,轻轻松松跑到SOTA。
数据集介绍和下载页面:
https://github.com/sutdcv/UAV-Human![]() https://github.com/sutdcv/UAV-Human
https://github.com/sutdcv/UAV-Human
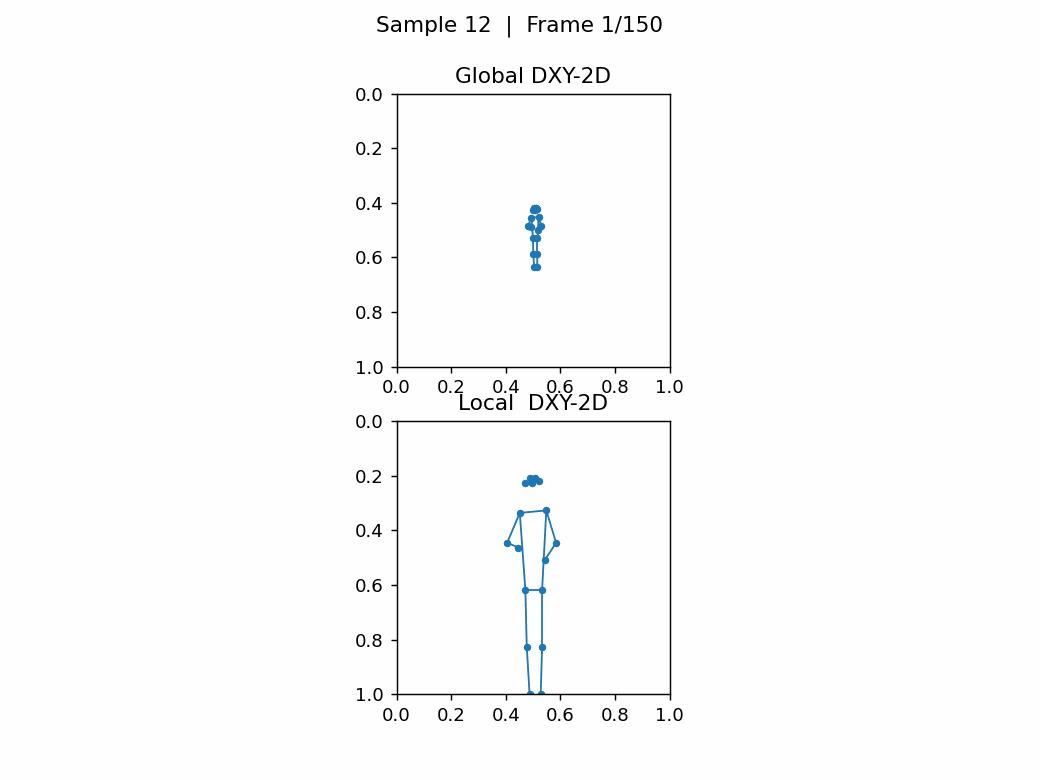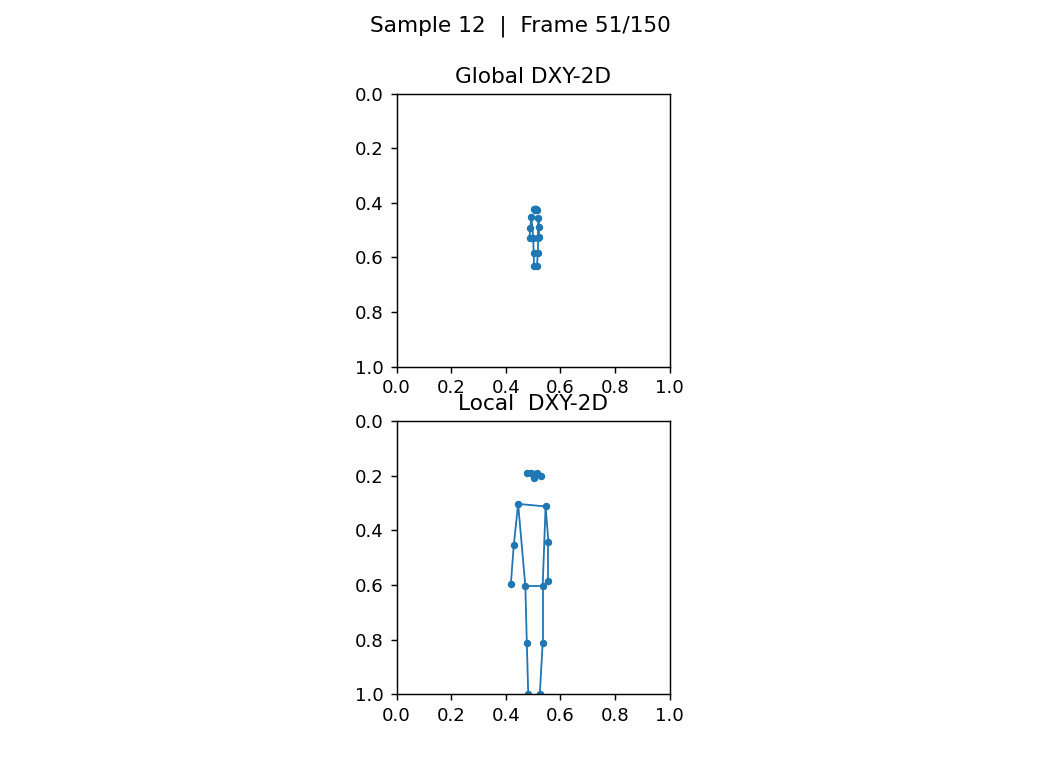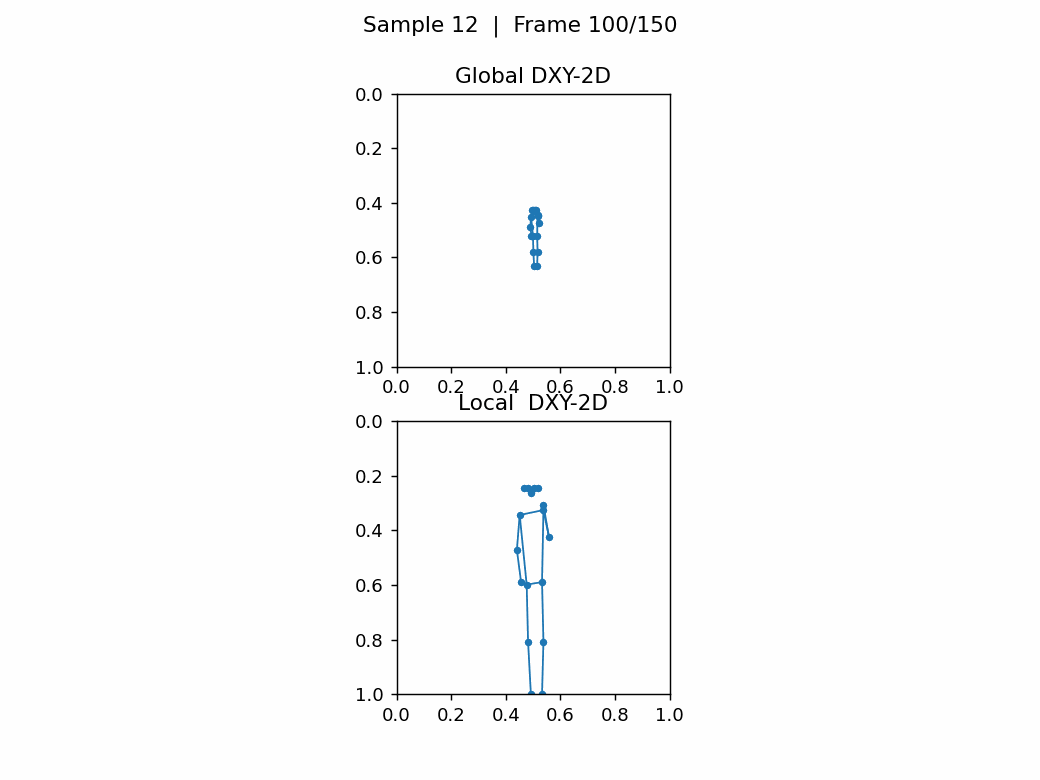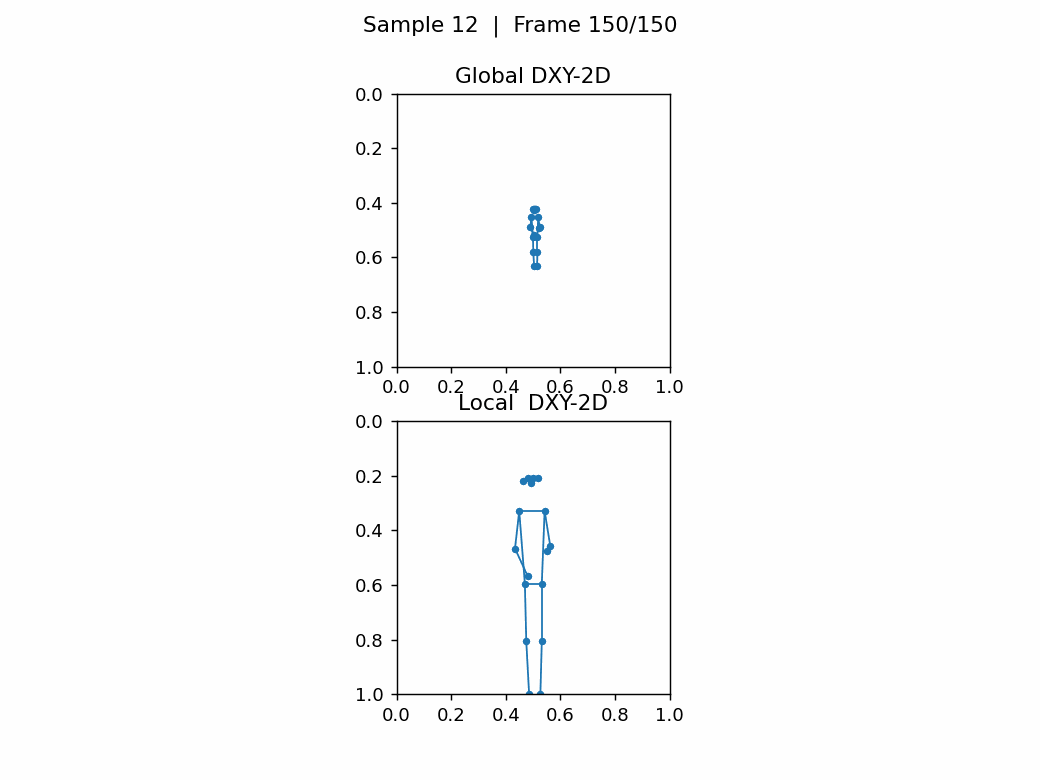
如下图,无人机视角下,任务尺寸,相差巨大,关键点密集很难看出动作。第1张图的类别是A012: take off a coat,第2张图的类别是A152: walk。
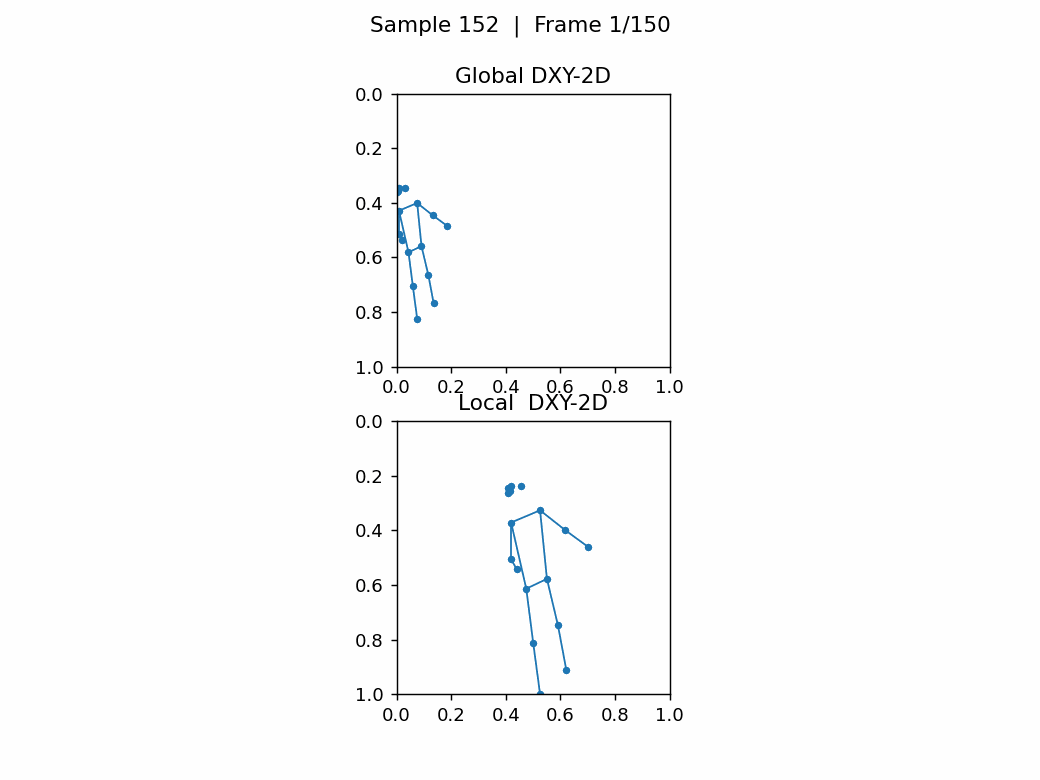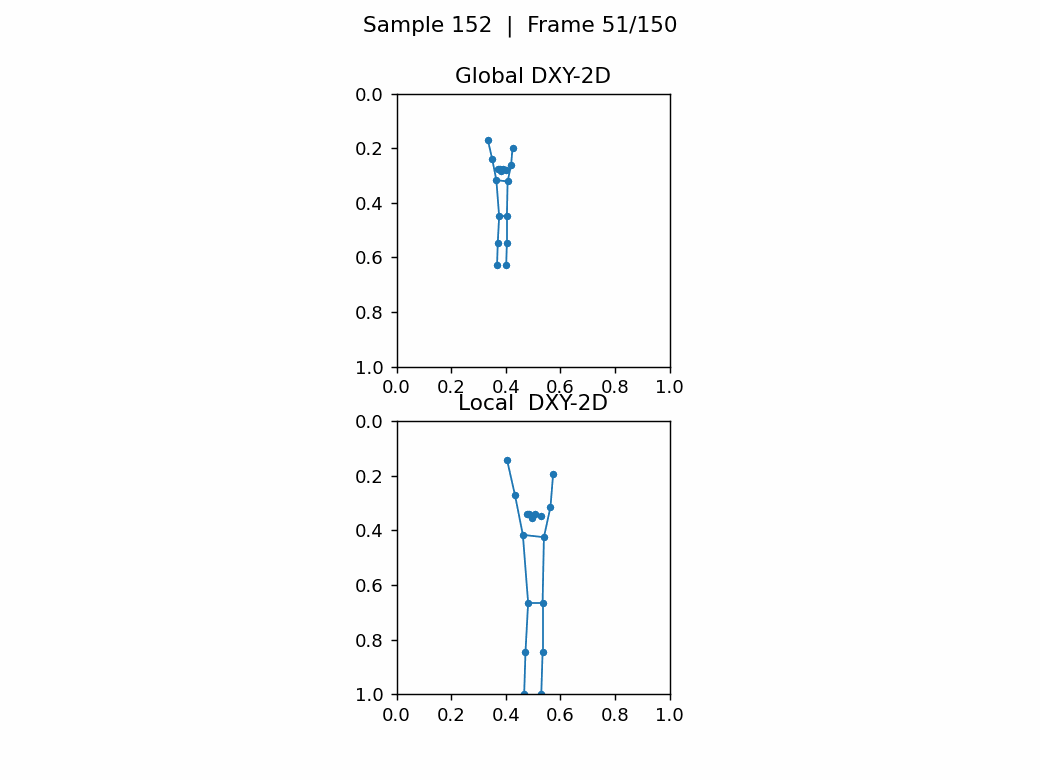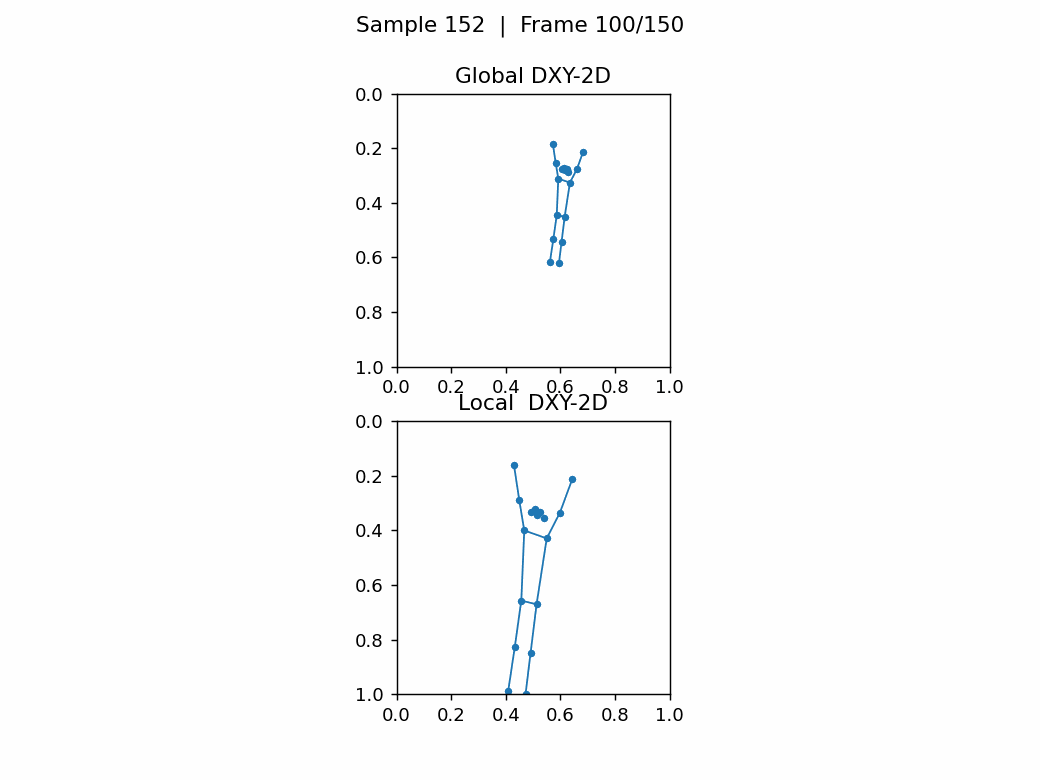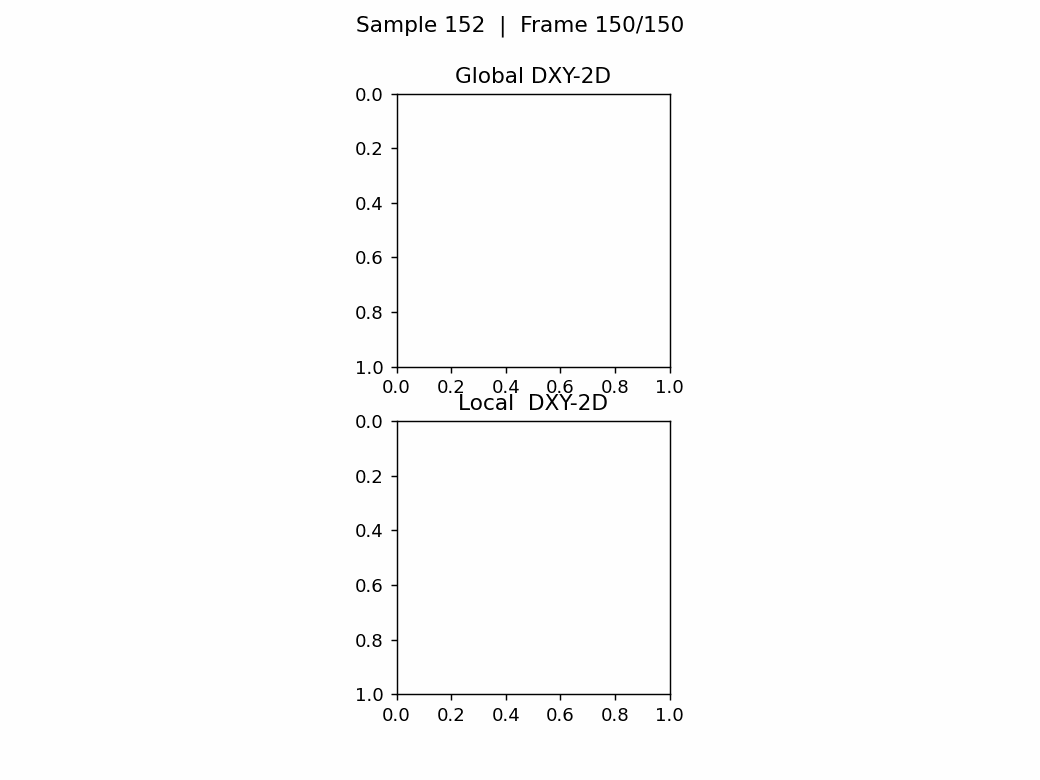
6.总结
这些数据集将用于我后续自己基于关键点的行为识别算法PosePointNet的测试。