前言
主要针对 mmaction / mmpose / pyskl 环境配置困难、代码调用冗余和部署不便等问题 ,对其中基于关键点(skeleton-based)的行为识别/动作识别(action recognition)方法,以最简代码和库,实现对 ST-GCN / ST-GCN++ / AAGCN / CTR-GCN 等GCN-based模型的训练。
项目已开源:https://github.com/paradoxjun/pyskl_gcn/tree/main![]() https://github.com/paradoxjun/pyskl_gcn/tree/main
https://github.com/paradoxjun/pyskl_gcn/tree/main
百度网盘:
该项目使用的最基本库有(requirements.txt中):
TypeScript
matplotlib==3.7.5
numpy==1.24.3
scikit-learn==1.3.2
thop==0.1.1.post2209072238
torchaudio==0.13.1+cu116
tqdm==4.66.4如果不做可视化,就只需要torch、numpy和tqdm,主要是为了兼容YOLO环境 ,解决复杂配置问题,并为后续结合yolo-pose的行为识别算法做准备。
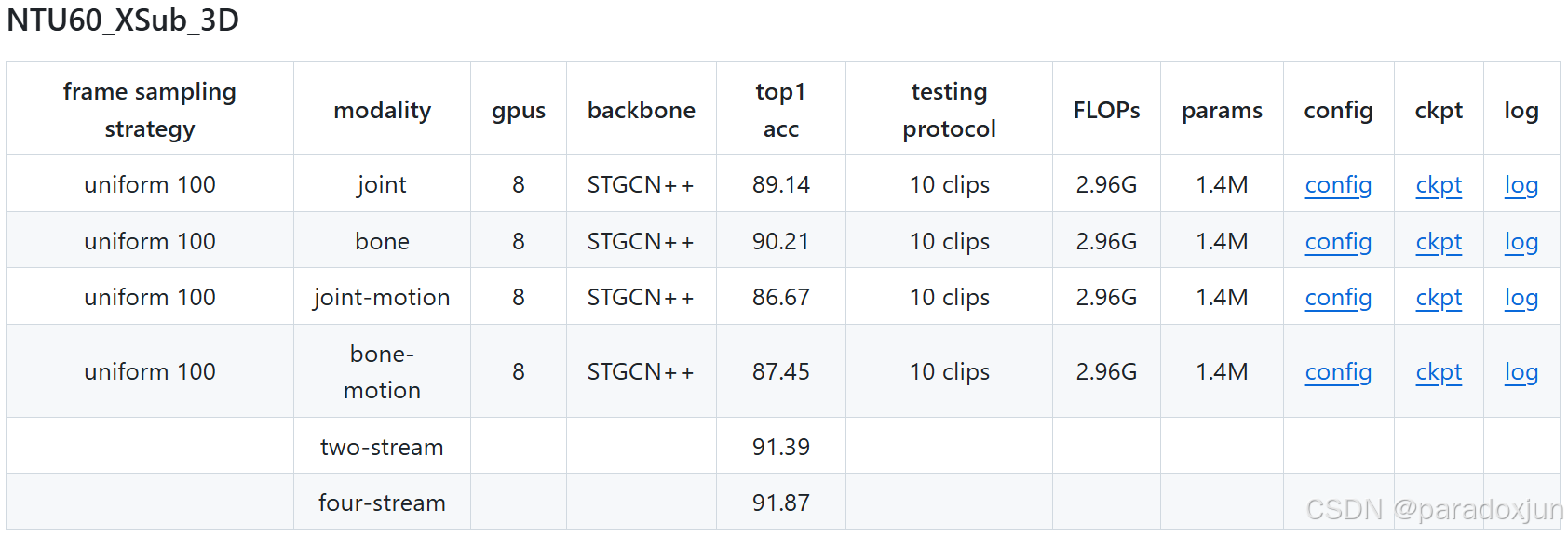
本文中,将对kinetic获取的3D关键点(25 keypoints)进行ST-GCN / ST-GCN++的复现。训练框架对 ST-GCN++ 在 NTU-RGB+D60 上3D关键点的复现结果:
CS划分下 joint 准确率达到 90.22%,bone 准确率达 90.33%。2-stream准确率达 91.64%,相比ST-GCN++论文中的准确率分别提高 0.9%,0.2%,0.2%。
实际上,该结果已经接近或超过近两年(23、24年)顶会中轻量化的SOTA方法(参数量1.5MB以下)。
(本文重点调参了joint的训练,如果调整数据增强等参数设置,bone应该会更高一些。)
如下图,在NTU60的cs划分上,本文训练框架直接训练的结果要比mmaction中的训练日志高了1.1%。 mmaction上的ST-GCN++训练结果:
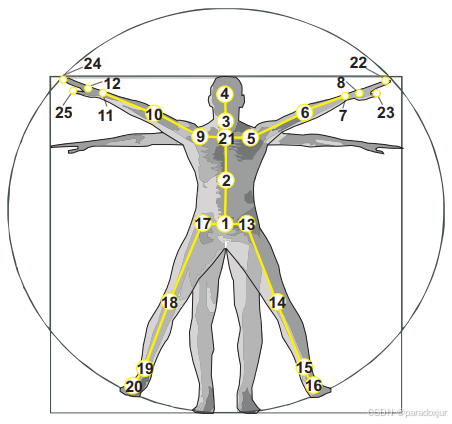
NTU中的25个点如下图所示,2D关键点的训练和3D点一致,只需修改dataset中读取数据维度和数据增强方法即可(3D点有25个x y z,2D点以COCO-17为例有x y conf,所以本质上就是点数不同)。
个人认为 :在实际项目中,目前(截止25年)所有开源的skeleton-based的行为识别方法 ,虽然在各种开源数据集上表现越来越好,但在实际应用中 ,会存在一系列的问题,导致根本落不了地。在下一章中,我会用自己改进的方法解决,并结合YOLO-pose预测的关键点,实现真正的多人在线行为识别。
1. 工程结构概览
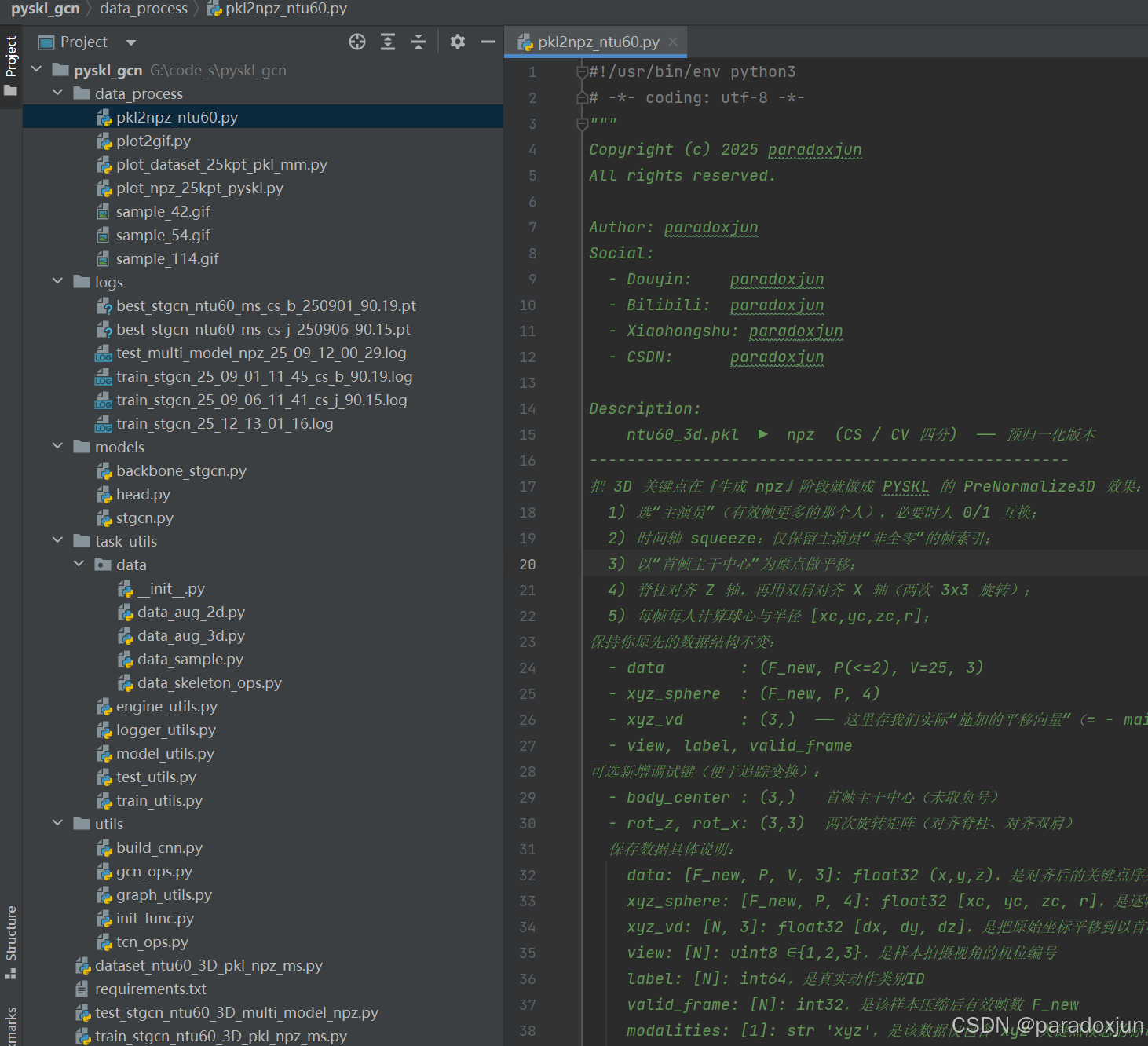
如上图所示:项目主要分为数据处理模块data_process、日志模块logs、模型定义模块models、脚本模块task_utils、模型脚本模块utils,以及dataset、train和test启动代码。
每一个py文件都给出了详细的注释,具体细节参考代码中的注释说明。
2. 数据处理模块data_process
该部分主要实现数据转换数据转换、可视化之类的操作。
其中PKL是将pyskl中的提供的NTU60的pkl文件生成训练用的npz文件。所有官方提供的关键点下载页面:
https://github.com/kennymckormick/pyskl/blob/main/tools/data/README.md![]() https://github.com/kennymckormick/pyskl/blob/main/tools/data/README.md NTU60官方的3D关键点下载链接(".skeleton"格式):
https://github.com/kennymckormick/pyskl/blob/main/tools/data/README.md NTU60官方的3D关键点下载链接(".skeleton"格式):
https://github.com/shahroudy/NTURGB-D![]() https://github.com/shahroudy/NTURGB-D
https://github.com/shahroudy/NTURGB-D
可视化后,我发现mmaction官方数据处理的并不算好 ,自己从 NTU-RGB+D 下载原始".skeleton"文件处理能有更大的优化空间(比如过滤掉无效人,部分单人动作存在一个无效人干扰;引入滤波平滑部分关键点;还有额外的RGB和深度投影信息)。
而2D关键点我没有使用mmaction提供的点,其用FasterRCNN+HRNet预测的结果处理也不行(比如追踪没有引入关键点信息,NTU上存在ID Switch情况)。
如上图,NTU60转换后生成CS和CV两个划分,如果是NTU120则是CS和CSET划分,120类的代码还需要修改一下。
然后可以用plot_dataset_25kpt_pkl_mm.py 和plot_npz_25kpt_pyskl.py进行可视化,前者是用dataset类可视化(用于查看模型输入数据是否存在问题),后者则是直接读取npz查看数据是否存在问题。
可视化结果如下图,第114个样本(54+60,从0开始计数),标签54,对应类别为A55,即hugging other person(拥抱)。
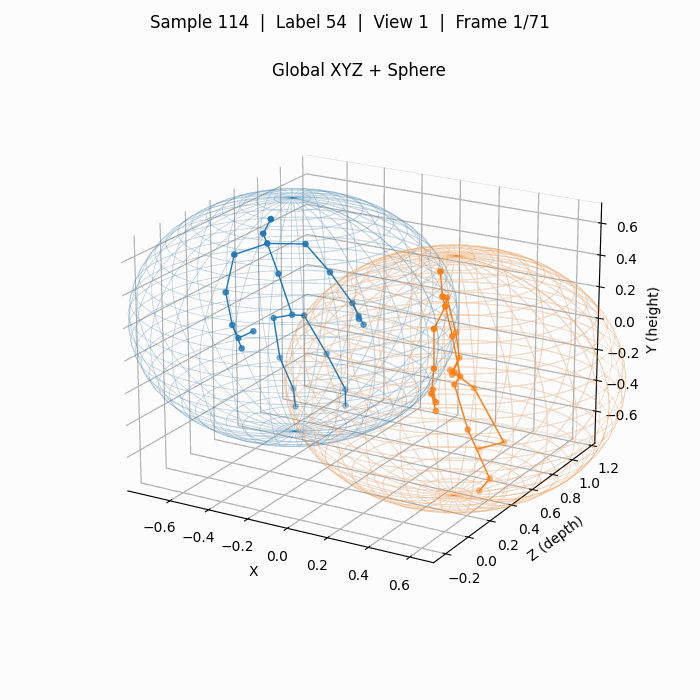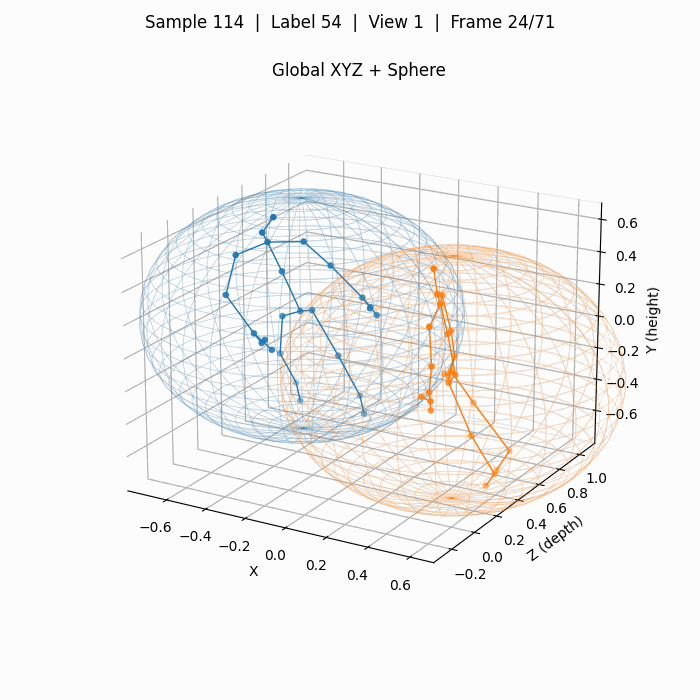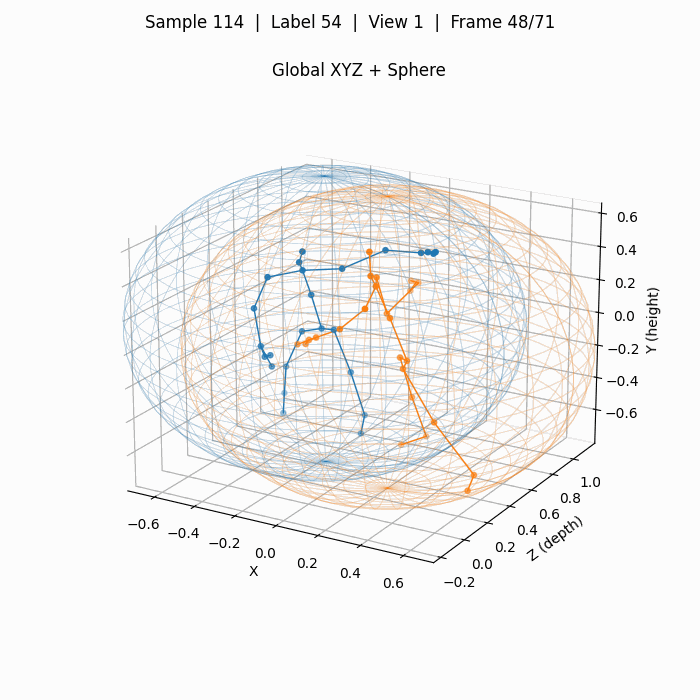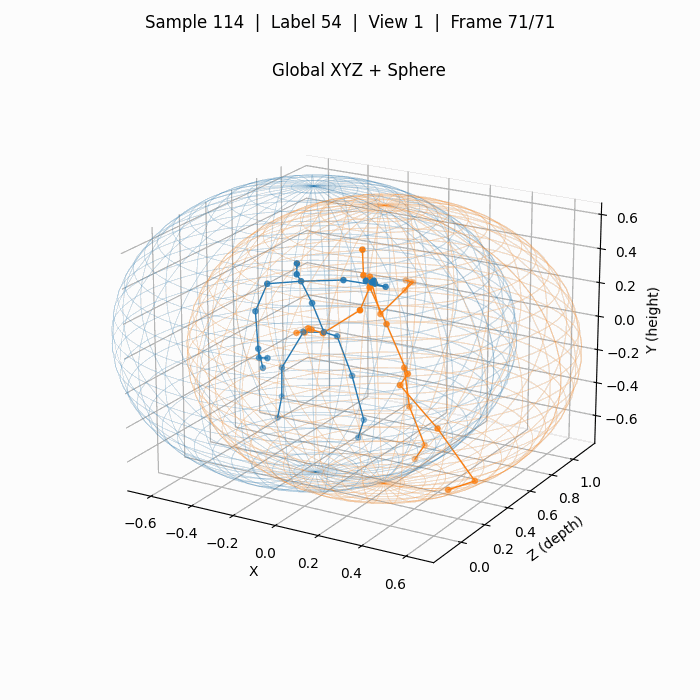
下图为单人动作摔倒,标签42,对应动作A43 falling。
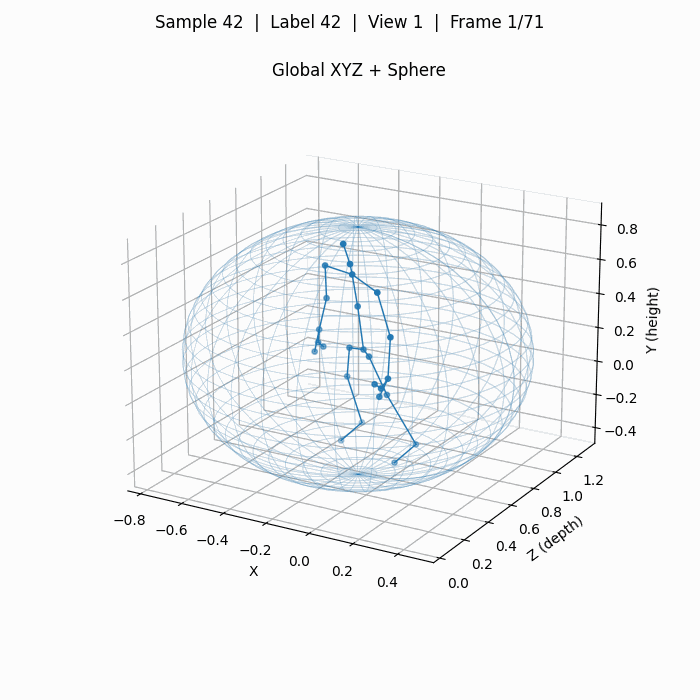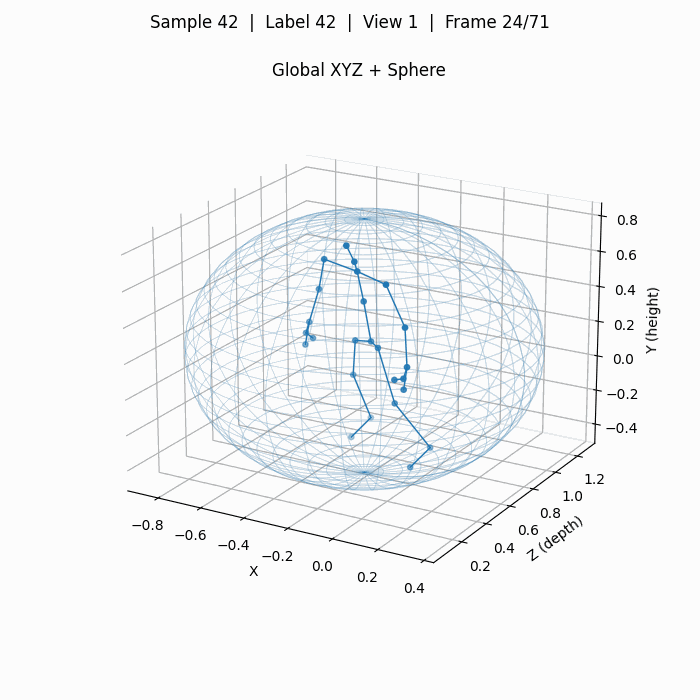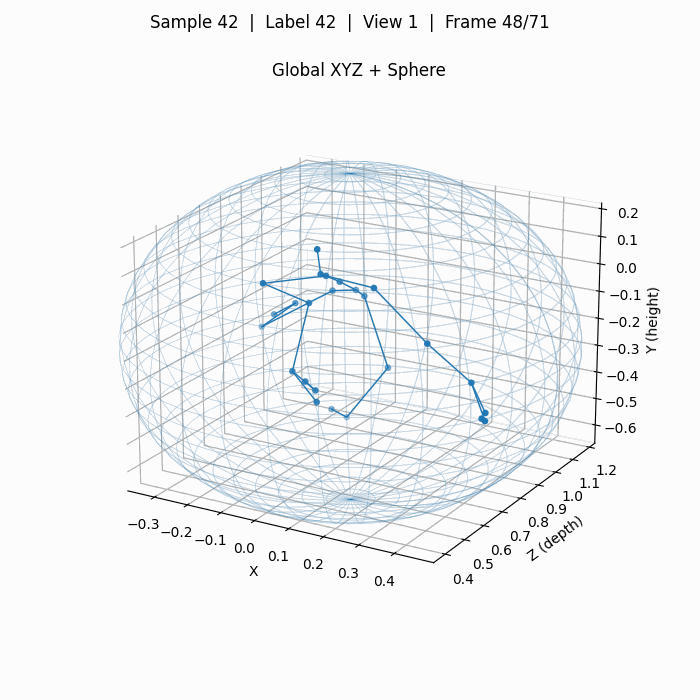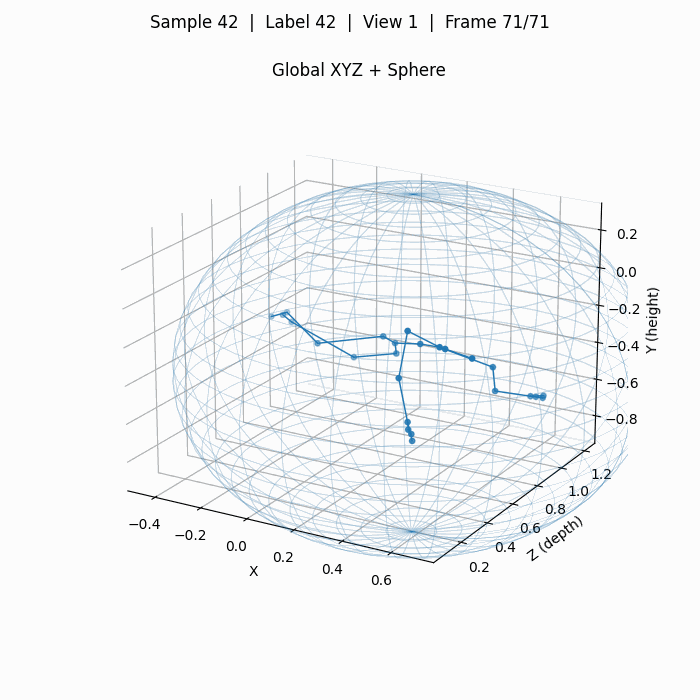
这里面计算并绘制了一个球体spherexc, yc, zc, r,其以25个人体关键点的质心为球心,质心到最远点的距离为半径。
此外,还在一个完整动作序列上,计算了关键点在各个维度上最大最小值得到的video_boxxmin, xmax, ymin, ymax, zmin, zmax,这些数据主要用于数据增强,为我自己的模型进行归一化操作,因为3D关键点是用现实中的"米"为数值单位的,不同于2D点会始终归一化在一个画面中。
3. 日志模块logs
这里就是保存了训练、测试的日志信息。如测试信息(部分,详细见"test_xx.log"文件):
TypeScript
...
==========================================================================================
2025-09-12 00:29:33 | INFO | [NPZ] ntu60_cs_test_xyz_raw.npz
2025-09-12 00:29:33 | INFO | [Load] ema_state_dict | epoch=197 | val_top1=90.15% | val_top5=98.54%
2025-09-12 00:30:15 | INFO | [ joint | 1-clip] Top1=90.15% Top5=98.54% | N=16487 | t=38.1s
2025-09-12 00:35:30 | INFO | [ joint | 10-clip/prob] Top1=90.22% Top5=98.56% | N=16487 | t=311.1s
2025-09-12 00:35:30 | INFO | [Load] ema_state_dict | epoch=103 | val_top1=90.19% | val_top5=98.49%
2025-09-12 00:36:21 | INFO | [ bone | 1-clip] Top1=90.19% Top5=98.49% | N=16487 | t=46.5s
2025-09-12 00:43:34 | INFO | [ bone | 10-clip/prob] Top1=90.33% Top5=98.53% | N=16487 | t=429.4s
2025-09-12 00:43:34 | INFO | [FUSION | 1-clip | logits] Top1=91.48% Top5=98.76%
2025-09-12 00:43:34 | INFO | [FUSION | 10-clip/prob | logits] Top1=91.64% Top5=98.77%
2025-09-12 00:43:34 | INFO | ==========================================================================================
2025-09-12 00:43:34 | INFO | ✅ Done.当前论文中喜欢的做法:
1.用10-clip计算一个视频的预测结果。用大白话讲:就是采样10次,然后对预测分数取平均后看类别。比如30帧采样T=3帧,那么就是{1, 11, 21, 2, 12, 22, ..., 10, 20, 30}这样10个采样序列分别预测后取平均得结果。
**2.多流(2s/4s/6s)预测。**大白话讲就是手工提取了多种特征然后训练网络,对这多种特征的预测结果取平均。比如joint就是点直接作为输入,bone说的好听叫"骨架",实际就是指定了一组点,计算向量得到新的25个点的值,比如手腕1, 1, 手肘2, 2,那么一个手臂骨架就是-1, -1,这里25个点的语义和之前不一样了,但本质上就是根据身体关节的先验划分,在输入网络前做了一组线性变换。还有jm就是计算前一帧和后一帧同一个点的均值,以此来说明是"速度",表示关节运动速度,bm同理就是骨架"速度"。还有kj、kb,和该组点的质心距离来输入。总之,只要大胆想,弄个8s、10s、无限s都没问题。
关于上述做法的个人看法:
除了搞论文以外,毫无意义 。因为skeleton-based action recognition已经卷到头了,为了那0.1%的准确率提升,想破脑袋。在实际应用中(绝大部分)不可能这样去做,甚至这些方法连基本的数据预处理(对齐、旋转等)都做不了(未知情况太多了,会不可控)。
现实检测的是视频流,我们根本不知道动作何时发生,以每秒25帧的视频流,每秒采样5帧为例,上面这样的做法对算力的浪费是灾难性的!!!
**我们真正合理的做法应该是:**直接且只用joint信息,以此尽量降低数据预处理的复杂性,然后每收到一次结果检测一次(针对摔倒、翻越等瞬时动作,进行高频率检测)。因为实际检测还会存在关键点缺失和错误、跟踪丢失和错误、超长持续时间检测等一系列问题。预处理越复杂,那么结果越不可控,甚至会出现,一步错,步步错的情况。
4. 模型定义模块models
该部分主要就是对pyskl中提供的模型定义代码进行了重写:
只需写一个backbone_xx.py文件,直接从pyskl中的算法拷贝,再修改一下导入的方法名。然后,定义一个算法文件(比如stgcn.py),在这之中将backbone和head组合封装。
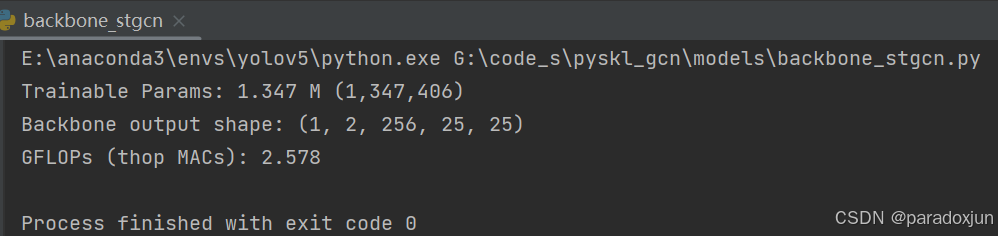
运行backbone_stgcn.py,可以查看主干网络的参数量和计算量:
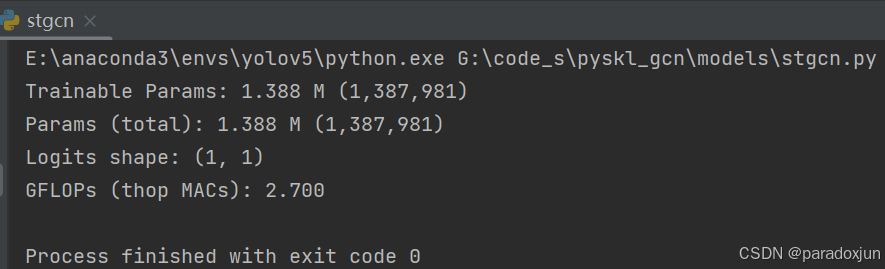
运行stgcn.py,查看除了分类层以外(目前论文通常不计,这里类别数设置为1进行近似查看)的参数量和计算量:
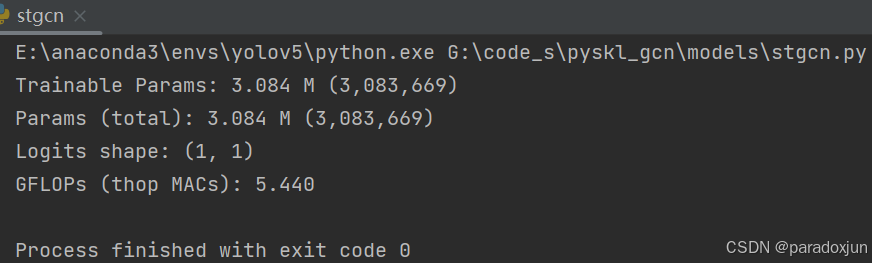
切换ST-GCN和ST-GCN++的设置:

修改成ST-GCN后重新运行,参数量和计算量显著增加:
因为ST-GCN是被ST-GCN++完爆的(其改进的多尺度时序卷积很有用),所以本文主要跑ST-GCN++,而ST-GCN印象中好像只跑过一次joint,88%左右的准确率。
5. 脚本模块task_utils
其中,data主要处理用于dataset中的数据的。
data_aug_2d 和data_aug_3d分别是用于两类不同关键点的数据增强(除了关节互换这一种增强,其余方法和点数无关/点排序,实验发现关节互换没啥卵用,有用的是镜面翻转)。
data_sample是用于采样训练、验证和测试序列的,可以修改优化,不保证是最好实现,但验证了自己的方法可以在UCF101、HMDB51、UAVHuman、NTU60等数据集上达到SOTA。
data_skeleton_ops是生成多种不同流数据的,可以额外增加自己想要的数据流。
剩余文件是训练用的代码文件。
engine_utils定义了一轮的训练方法。
logger_utils定义了一些写日志的方法。
model_utils定义了一些模型定义、加载、保存的方法。
test_utils定义了测试训练好的模型文件的全流程代码。
train_utils定义了训练用的一些工具,比如优化器、学习率变化方法、EMA等。
6. 模型脚本模块utils
这里面主要是针对models模块中调用的一些方法进行了实现,在将pyskl中模型改写时,只需要将相关同名方法改为从其中导入即可。
7.训练文件dataset、train和test
dataset才是整个基于人体关键点的行为识别算法的核心!!!
如果用mmaction,且不去看数据预处理源码,很多细节注意不到(其实看了也没用);不自己去处理真实数据,很多坑想不到。
**需要理解整个关键点序列是如何预处理的:**包括人员选取(多人且无法知道谁真正做了某一类动作,那么选择谁、选择几个人);尺度变化大(无人机视角,相机远近不固定);标准化处理(用batchnorm?最大最小值?尺度放缩?);序列长度T的设定与帧选取(视频解码延迟卡顿、丢帧、没有时间概念、动作持续时间长短);检测问题(动作本身多样不明显,漏检、误检);开放数据问题(已知类别动作确定,但未知动作有无限种,不再是分几个类,而是从已有数据中找出几个类)。
因为目前大多数开源算法应用是不需要考虑落地的,所以在一些demo上表现还行,但实用的话就会崩盘。
不过,我们在NTU-RGB+D上的处理可以做的很简单:人物最多只有2个人,最多300帧,必定居中,不需要考虑动作起始,动作明确,唯一的误差来自于本身关键点的不稳定性。
在train_xxx.py中,设定训练参数:
python
CFG = dict(
TRAIN_NPZ=fr'G:/datasets/cls_video/nturgbd_skeletons_s001_to_s017/pkl_mmaction/npz_raw_xyz_ntu60/ntu60_cs_train_xyz_raw.npz',
VAL_NPZ=fr'G:/datasets/cls_video/nturgbd_skeletons_s001_to_s017/pkl_mmaction/npz_raw_xyz_ntu60/ntu60_cs_test_xyz_raw.npz',
NUM_CLASS=60,
BATCH=16,
GPU_ID=0,
EPOCH=240,
NUM_WORKERS=8,
SEED=42,
AMP=True,
T=64,
STREAMS=('j',), # 多流 ('j','b','jm','bm') → 12 通道
CKPT_PATH="best_stgcn_ntu60_ms_cs_j_base_250906_01.pt",
PRINT_FREQ=0,
PREFETCH=4,
# 优化器:用字典统一管理
OPT=dict(name='SGD', lr=0.1, momentum=0.9, weight_decay=0.0005, nesterov=True),
# OPT=dict(name='Adam', lr=1e-3, betas=(0.9, 0.999), eps=1e-8),
# OPT=dict(name='AdamW', lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=1e-4),
# 学习率:也改成字典
# SCHED=dict(type='step', by='step', min_lr=1e-4, decay=0.95, decay_epoch=2),
SCHED=dict(type='cosine', by='step', min_lr=1e-2, warmup_epochs=3), # SGD
# SCHED=dict(type='cosine', by='step', min_lr=0, warmup_epochs=3), # Adam
# SCHED = dict(type='linear', by='step', min_lr=0.0),
# SCHED = dict(type='exp', by='step', min_lr=0.0), # 自动算 gamma 到终点
# SCHED = dict(type='exp', by='step', min_lr=0.0, gamma=0.98),
PRETRAINED="", # 预训练权重(为空字符串则不加载)
# EMA 设置(默认启用;验证/保存用 EMA),基准decay: BS=16, decay=0.999
# EMA=dict(enabled=True, start_epoch=3, eval_use_ema=True, ref_batch=16, decay=0.999),
EMA=dict(enabled=True, start_epoch=3, eval_use_ema=True, half_life_epoch=0.25),
)BATCH **:**最佳为64,过大过小都会导致准确率降低一些,16或32只会降低一点点。该任务上比较神奇的参数,一般都是设置越大越好,可能点坐标对BN比较敏感。
**EPOCH:**实际上150轮足矣,少部分情况240轮效果比150号,具体和学习率设置也有关系。
**T:**序列长度设置48/64/100/150/300都有,具体看算法,并不是越长越好,NTU上设置64和100也没差,但FGLOPs显著降低,NTU、UAVHuman、K400我都设置了64,UCF101、HMDB51设置了48也能取得SOTA。但现实应用会设置更小,比如16/24/32,因为主要做摔倒等瞬时动作的检测。
**OPT:**多次试验表明优化器选SGD取得的准确率要比Adam高1~5%,但训练过程没那么稳定;Adam超绝快速收敛,比如在K400上训练30轮就收敛了。
**SCHED:**调度学习率变化,主要还是用余弦退火,不过最终值0可能不是最好,也要多试。
**EMA:**经典EMA,能够提升0~3%的准确率,但设置不好训练可能会崩盘。给了两种设置,一种是batchsize=64稳定涨点,另一种是根据轮次的保守涨点。
**NUM_WORKER:**电脑配置不行就改成1或者2。
在test_xxx.py中设置测试参数:
python
CFG = dict(
# 一个或多个 npz 都行;脚本会逐个 npz 生成结果
NPZ_PATH=[
r'G:/datasets/cls_video/nturgbd_skeletons_s001_to_s017/pkl_mmaction/npz_raw_xyz_ntu60/ntu60_cs_test_xyz_raw.npz',
],
# 多模型(多流)列表:name 仅用于日志;streams 用于特征生成;ckpt 为各自权重;w 为模型融合权重
MODELS=[
dict(name='joint', streams=('j',), ckpt='logs/best_stgcn_ntu60_ms_cs_j_250906_90.15.pt', w=1.0),
dict(name='bone', streams=('b',), ckpt='logs/best_stgcn_ntu60_ms_cs_b_250901_90.19.pt', w=1.0),
# dict(name='jm', streams=('jm',), ckpt='ckpt_jm.pt', w=0.5),
# dict(name='bm', streams=('bm',), ckpt='ckpt_bm.pt', w=0.5),
],
NUM_CLASSES=60, # NTU60
GPU_ID=0,
SEED=42,
AMP=True,
# 数据形状
T=64,
# 1-clip 批
BATCH_1CLIP=16,
# N-clip:这里的 batch 指"每步前向多少个视频";实际前向 batch = Bv * Nc
BATCH_NCLIP=8,
NUM_WORKERS=4,
# 多 clip
NUM_CLIPS=2,
CLIP_FUSE='prob', # 把同一模型 Nc 个 clip 的分数怎么融合:'prob' | 'logits'
MODEL_FUSE='logits', # 把不同模型的分数怎么融合: 'prob' | 'logits'
USE_CONTIG_WINDOW=False, # False=相位切片(推荐);True=连续窗口
# 可选:把每个模型与融合后的分数导出,便于复现实验或后处理
SAVE_SCORES_DIR='', # 例如 'scores_out';留空则不保存
)参数设置和训练参数尽量保持一致即可。
MODELS中指定训练好的模型,w为权重,其实可以调权重。3D点的joint和bone准确率有高有低,但在2D点中,结果必定是joint>bone>jm>bm,因为2D点存在无效点,每一次转化都会将一些点置为0(如果这样操作的话),导致信息丢失。
8. 推理代码(暂未实现)
根据test代码就可以修改得到,每次读到一组关键点作为一个batch进行输入。
这里有很多的细节需要修改,例如配合追踪算法中间消失一段时间,那么后续动作是否连接前段时间动作。动作推理关于帧数的推理逻辑,例如每64帧推理一次,还是维护一个双端队列按间隔推理(间隔为1,收集满32帧起,32/33/34/.../64均进行推理,满64帧后每次弹出最老的1帧,并加入最新一帧进行推理;间隔为2,收集满32帧后,32/34/36/.../64进行推理,满64帧后,每次弹出最老的2帧;依次类推...)
9. 总结
本文给出了一个简单的基于关键点的行为识别训练框架,并在NTU-RGB+D60上,训练ST-GCN++,得到的结果要高于论文与开源日志中给出的结果。
对于能落地的基于关键点的行为识别方法将在下一章中给出。解决现实困难,并提供更好的推理方案。