目录
[1. 效果演示](#1. 效果演示)
[2. 关键点数据获取与训练](#2. 关键点数据获取与训练)
[2.1 获取多种关键点检测结果](#2.1 获取多种关键点检测结果)
[2.2 关键点JSON文件保存](#2.2 关键点JSON文件保存)
[2.3 将JSON转NPZ](#2.3 将JSON转NPZ)
[3. 开集分类训练](#3. 开集分类训练)
[4. 目标跟踪算法ByteTrack的改进](#4. 目标跟踪算法ByteTrack的改进)
[5. 推理全流程](#5. 推理全流程)
[6. 总结](#6. 总结)
前言
以"摔倒检测"为例,实现一个能够商用的行为识别全流程。
行为识别数据集(可以用作负样本):
基于关键点的行为识别(2) - 动作识别/行为识别/视频分类数据集![]() https://blog.csdn.net/qq_40387714/article/details/155934735
https://blog.csdn.net/qq_40387714/article/details/155934735
算法设计、数据处理逻辑参考:
基于关键点的行为识别(3)- 问题分析与算法设计![]() https://blog.csdn.net/qq_40387714/article/details/155959221
https://blog.csdn.net/qq_40387714/article/details/155959221
1. 效果演示
本文关键点检测模型 选择Ultralytics的yolov8s-pose预训练模型。目标跟踪算法 选择改进的ByteTrack(我自己引入了关键点信息)。行为识别算法 选择前文中的PosePointNet。
下图中,黄色 表示追踪算法暂未确定的轨迹,绿色 表示确定的非摔倒轨迹,红色表示摔倒的轨迹。行为识别模型使用约100个视频片段即可训练得到一个差强人意的效果。
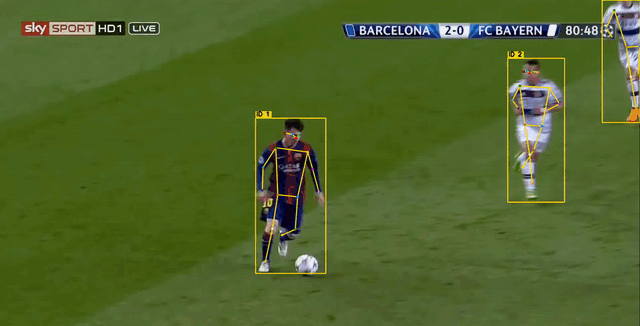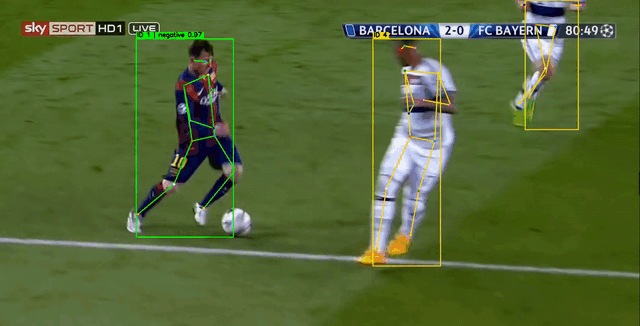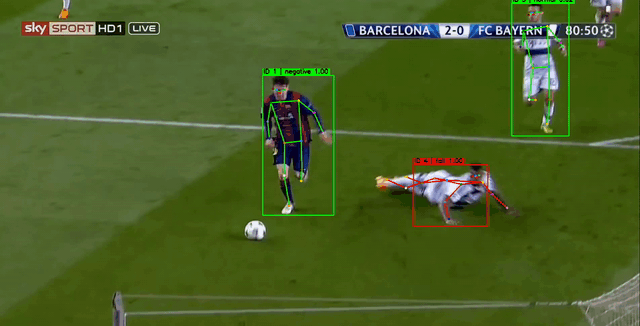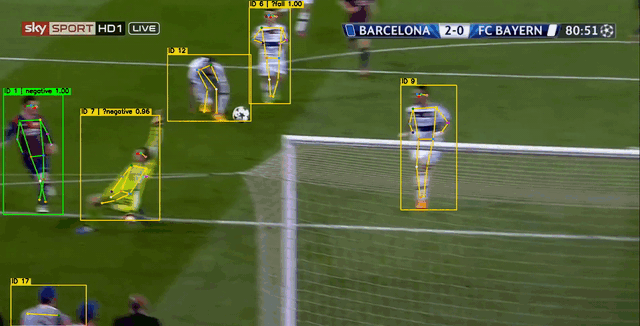


2. 关键点数据获取与训练
(1) 手动截取视频动作片段(动作发生前后1秒钟即可)。
(2)用多种关键点检测模型预测出json文件(比如yolov8s/m/l/x,分辨率设置640、800)。
(3)将JSON转成二进制文件方便读取(比如NPZ文件,里面涉及输入数据预处理)。
2.1 获取多种关键点检测结果
在PoseC3D的论文中,做了以下实验:低质量关键点训练,高质量关键点测试;高质量关键点训练,低质量关键点测试。以此,来说明算法的鲁棒性。
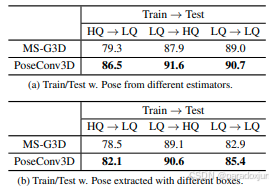
**这样做是完全没必要的:**关键点是对视频数据的转换,二者并非等价关系。低质量关键点数据必定存在一个视频,能够使得高质量检测器也预测为(或近似预测为)该低质量(也许是模糊、遮挡等种种因素导致)。反之,也成立。
**更合理的做法:**直接把不同分辨率的关键点数据混合一起训练。高质量的关键点可以提供高置信度的动作序列,低质量的关键点可以扩大输入误差。二者结合可以拓展数据分布,降低对姿态估计选型的敏感性。
特别地,对于低质量关键点,如果一个高质量关键点序列可以预测为某一类动作,那么当低质量关键点近似接近这个高质量的序列时,低质量关键点大概率也是这个类别。
**很简单的trick:**我们用yolov8s/m/l/x,yolo11/s/m/l/x,分别在640和800的分辨率条件下预测一个视频。这样一个视频就获取了16条关键点数据。
这样做有两个很明显的好处:
极大扩充数据集的数量。
对姿态估计器和推理分辨率的选择不敏感。部署时,用yolov8s还是yolo11s,推理图片分辨率变化,都不需要去重新训练模型了。
UCF101和HMDB51上这样操作,yolov8l-pose的准确率可以和FasterRCNN+HRNet的准确率相当。NTU和K400上,用两种质量的关键点,也可以对低质量关键点提升1%的准确率。即便是同一个姿态估计,用两种分辨率下预测的关键点训练,也要比任意一种单独训练的准确率高。
总而言之,这是一种可解释性很强的数据增强方式,简单相信照着做。
2.2 关键点JSON文件保存
关键点数据获取时,我们应该尽量保留多的推理数据,以防想要什么数据,又得重新检测了,涉及到视频流处理,还有频繁的IO操作,即使用yolo-pose也很耗时。
保存的关键点数据结构如下所示:
TypeScript
{
"video_path": "ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.avi",
"video_height": 240,
"video_width": 320,
"meta": {
"fps": 25.0,
"total_frames": 164,
"duration": 6.56,
"source": "UCF101",
"class_id": 0,
"class_name": "ApplyEyeMakeup"
},
"frame_info": {
"0": {
"total_obj": 1,
"person_box": {
"0": {
"bbox": [0.641968,0.499789,0.715738,0.997828],
"conf": 0.911277,
"rgb": [99,95,113],
"hsv": [119,96,115]
}
},
"person_kpt": {
"0": {
"0": {
"kpt": [0.870883,0.367247],
"conf": 0.977041,
"rgb": [
[211,196,254]
],
"hsv": [
[172,58,254]
]
},
...我使用的数据结构,除了保存检测框和关键点的坐标置信度外,还计算了颜色信息。因为我开始就想将其看做点云来做,一个点的颜色可能没有意义,但是在整个动作序列中是有的。准确率貌似提高了一点,不过最后也没用。一方面是涉及到IO和图像读取,生成JSON文件太慢,还有就是准确率提高不明显,使用的意义不大。具体还需要其他什么特征信息,可以根据自己的场景需求去保存。
2.3 将JSON转NPZ
开源数据集中通常选择2个人,我采用面积排序+IOU sort的方式实现选人。
开源数据集已经引入先验了:这个视频中有人做了某个动作,且通常占视频主体较大。所以直接选取面积最大的两个人,然后用后一帧的检测框去匹配前一帧,尽量让第一个人的动作序列完整。
我在K400上还做了:关键点面积最大、检测框置信度最大、关键点置信度最大等选取方法的测试,发现还是面积最大的效果最好。这里尽量要避开置信度的问题,因为yolo检测结果有个经验特性:检测框能对,但置信度差异会很大。
自己业务需求的任务选取,如"摔倒"、"打架"等,需要引入跟踪,尽量保证单个动作序列的完整性。
在搜集数据时,尽量选择单个人且占主体画面的视频,这样可以减少后期处理。
对于打架这种多人场景的,其实只要保证画面中每个人都参与打架了即可。即便只用一个人训练,也可以获取较高准确率。选择两个人进行训练,效果更稳定。
下面是,JSON转到NPZ保存的字典:
python
np.savez_compressed(
out_npz_path,
names=np.array(names, dtype=object),
kp_xy=np.array(xs, dtype=object),
kp_conf=np.array(cs, dtype=object),
bbox=np.array(bs, dtype=object),
bbox_conf=np.array(bcs, dtype=object),
kpt_num=int(kpt_num),
min_frames=int(min_valid_frames),
count=int(kept)
)其实,只需要保存最基本的检测框和关键点,以及他们的置信度就行。其他信息主要用于可视化检查。
3. 开集分类训练
和论文中在数据集上已知类别的训练不同,实际的分类属于开集数据,除了已知类别,所有其他未知类别都是负样本类,这就导致模型会出现大量误检。
**未知类别无限多,需要优化训练方式。**这其实在我前面的文章中已经做过类似的了:
YOLOv8源码修改(1)- DataLoader增加负样本数据读取+平衡训练batch中的正负样本数![]() https://blog.csdn.net/qq_40387714/article/details/138996317分类模型训练框架搭建(1):resnet18/50和mobilenetv2在CIFAR10上测试结果
https://blog.csdn.net/qq_40387714/article/details/138996317分类模型训练框架搭建(1):resnet18/50和mobilenetv2在CIFAR10上测试结果![]() https://blog.csdn.net/qq_40387714/article/details/145281204
https://blog.csdn.net/qq_40387714/article/details/145281204
简单来说就是,采样负样本训练。
我们通常收集的正样本只有几百上千条数据,但负样本可以有几万几十万条。可以做以下的操作:
1.先读取全部数据直接训练,不考虑正负样本比例。这样网络实际上会对任意输入都预测为负样本。这一步是让模型简单看一下全部数据,且让其对于未知数据就预测为负样本。
2.控制正负样本比例训练,正样本固定读取,负样本控制一定比例抽样读取。这一步是为了能让模型有效学习我们需要识别的类别。
3.迭代优化。实际我们会多次采集正样本,每次采集完,重复步骤2,可以让网络见识更多负样本。
以下是一个简单的正负样本数据集划分代码:
python
def split_pos_and_allocate_negs(
pos_keys: Sequence[Tuple[str, Optional[int]]],
neg_keys: Sequence[Tuple[str, Optional[int]]],
split_ratios: Sequence[float] = (0.8, 0.1, 0.1),
negative_ratio: float = 0.0,
seed: int = 0,
) -> Dict[str, List[Tuple[str, Optional[int]]]]:
"""
先对 pos_keys 做稳健切分(最大余数法);再用
val_need = round(len(val_pos)*negative_ratio)
test_need = round(len(test_pos)*negative_ratio)
从 neg_keys 中 两次不放回 抽取 val/test 的负样本,其余留作训练负样本池。
返回 dict:
{
'train_pos': [...],
'val_pos': [...],
'test_pos': [...],
'val_neg': [...],
'test_neg': [...],
'train_neg_pool': [...],
}
"""
rng = random.Random(int(seed))
# 正样本切分(打乱后切)
pos = list(pos_keys)
rng.shuffle(pos)
n_tr, n_va, n_te = compute_split_counts(len(pos), split_ratios)
train_pos = pos[:n_tr]
val_pos = pos[n_tr:n_tr+n_va]
test_pos = pos[n_tr+n_va:n_tr+n_va+n_te]
# 负样本两次不放回
val_need = int(round(len(val_pos) * max(0.0, negative_ratio)))
test_need = int(round(len(test_pos) * max(0.0, negative_ratio)))
neg_pool = list(neg_keys)
rng.shuffle(neg_pool)
val_neg = neg_pool[:min(val_need, len(neg_pool))]
rest = neg_pool[len(val_neg):]
test_neg = rest[:min(test_need, len(rest))]
train_neg_pool = rest[len(test_neg):] # 训练负样本"大池"
return {
"train_pos": train_pos,
"val_pos": val_pos,
"test_pos": test_pos,
"val_neg": val_neg,
"test_neg": test_neg,
"train_neg_pool": train_neg_pool,
}4. 目标跟踪算法ByteTrack的改进
关键点检测可以同时获取关键点框和关键点,多了关键点信息,我们就可以对原本的跟踪算法优化一下。这里使用的是YOLOv8中提供的ByteTrack源码(DeepSORT同理)。
我们在tracker/bytetracker/byte_tracker.py中,简单修改2处:
修改1:
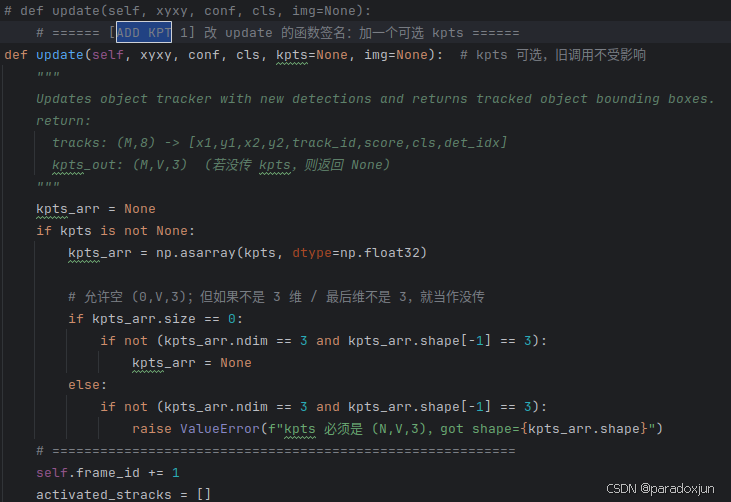
在BYTETracker类的update方法开始处,加入形参kpts,用来传入关键点数据。
修改2:
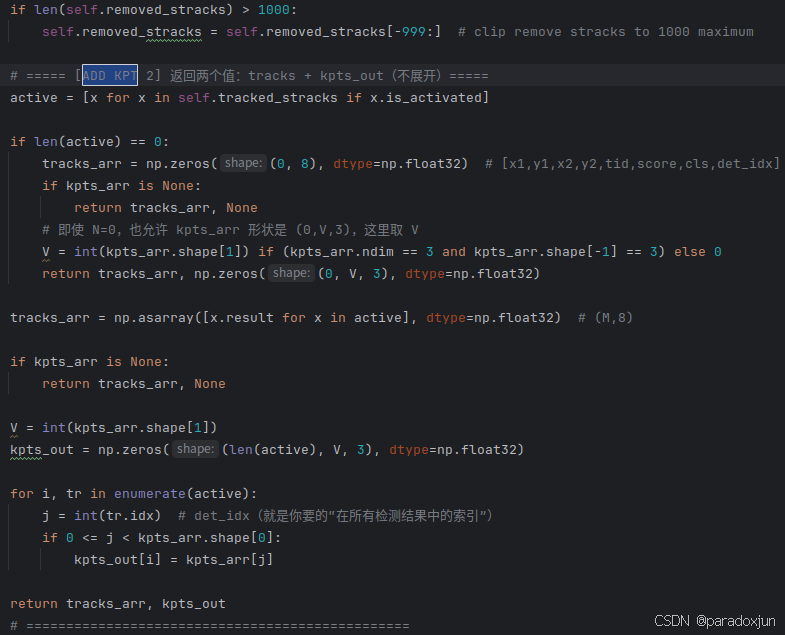
在BYTETracker类的update方法return处,修改返回值,返回原本的信息和关键点信息。
该操作主要是用于后续追踪返回信息,直接将关键点信息和追踪ID绑定。
想要用关键点距离来优化ID Switch问题,只需在下面匹配中引入一定规则即可:
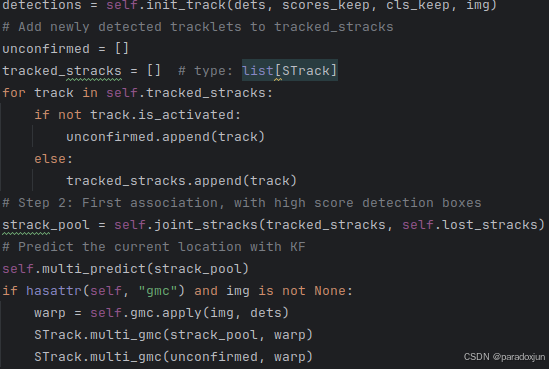
5. 推理全流程
步骤1:使用YOLO-pose获取关键点
python
# 2) YOLO Pose
pose_model = YOLO(model=cfg.YOLO_POSE_WEIGHTS, task="pose")
# ========== YOLO Pose 检测 ==========
res = pose_model.predict(frame, imgsz=640, verbose=False, conf=cfg.DET_CONF)[0]步骤2:使用目标跟踪分配跟踪ID
python
det_boxes = res.boxes.xyxy.cpu().numpy().astype(np.float32) # (N,4)
det_confs = res.boxes.conf.cpu().numpy().astype(np.float32) # (N,)
det_cls = res.boxes.cls.cpu().numpy().astype(np.int32) # (N,)
det_kpts = np.concatenate([k_xy, k_cf[..., None]], axis=-1).astype(np.float32) # (N,V,3), COCO-pose V=17
# ========== ByteTrackWrapper ==========
out_trk = bytetrack.update(det_boxes, det_confs, det_cls, det_kpts)步骤3:使用双端队列构建行为识别模型输入
python
tracks_now: List[Dict] = out_trk.get("tracks", []) or []
pack_ids: List[int] = out_trk.get("pack_ids", []) or []
xg = out_trk.get("xg", None)
xl = out_trk.get("xl", None)
dropped_ids: List[int] = out_trk.get("dropped_ids", []) or []
xg_in = xg[infer_idx].astype(np.float32)
xl_in = xl[infer_idx].astype(np.float32)
logits = sess.run([out_name], {xg_name: xg_in, xl_name: xl_in})[0] # (B,C)
probs = _softmax_np(logits, axis=1) # (B,C)这里我采用了以下逻辑:
为每个ID维护一个双端队列,每当获取一个检测结果(检测框、关键点、置信度),如果队列未满,就把结果压入双端队列,否则先弹出一个最老结果,再压入。
当前ID被检测到,且双端队列中数据长度大于等于队列长度一半,且推理间隔满足步长stride,则将整个队列传入行为识别模型。(我的模型是双输入模型,包含xg和归一化的结果xl。)
当追踪ID被丢弃,则双端队列中的ID也丢弃。
参数设置:
T:32。推理序列最大长度。
STRIDE:1。推理间隔,1为每帧都推理。
追踪算法采用yolov8中ByteTrack的默认参数。
6. 总结
训练和推理框架搭建完成后,整个流程难度仍然在数据采集上。需要保证每个类别数据的尽量不包含不属于该类别的动作。
其余动作的识别,如"站立"、"行走"、"奔跑"、"深蹲"、"坐着"、"趴着"可以一样实现识别。