论文:Large Language Models are Zero-Shot Reasoners
摘要
预训练大型语言模型(LLMs)广泛应用于自然语言处理(NLP)诸多子领域,且被公认为结合任务专属样例的优秀少样本学习器 。值得关注的是,思维链(CoT)提示技术 ------一种通过分步答案样例激发模型复杂多步推理能力的前沿方法------在算术推理与符号推理这两类高难度系统2任务中取得了最先进(SOTA)性能,而这类任务的性能提升并不遵循大语言模型的标准缩放定律。
尽管思维链的成功常被归因于大语言模型的少样本学习能力,但本文研究表明:仅需在每个答案前添加一句"让我们一步步思考"(Let's think step by step),大语言模型就能成为出色的零样本推理器。
实验结果显示,本文提出的**零样本思维链(Zero-shot-CoT)**方法,仅使用这一单一提示模板,就在多类推理基准任务上显著超越大语言模型的零样本基线性能,涵盖算术推理(MultiArith、GSM8K、AQUA-RAT、SVAMP)、符号推理(最后字母拼接、硬币翻转)以及其他逻辑推理任务(日期理解、乱序物体追踪)。该方法无需任何人工构建的少样本样例,例如:基于大尺度指令微调模型 text-davinci-002,MultiArith 任务准确率从 17.7% 提升至 78.7%,GSM8K 任务准确率从 10.4% 提升至 40.7%;基于 5400 亿参数的 PaLM 这一现成大模型,也实现了相近幅度的性能提升。
这种单一提示模板在高度多样化推理任务 中的普适性,揭示了大语言模型中尚未被充分挖掘与研究的基础零样本能力,表明通过简单的提示设计,就有可能激发模型具备高层级、多任务的通用认知能力。
本文期望这项研究不仅能为高难度推理基准任务提供性能强劲的极简零样本基线,更能强调一个核心观点:在构建微调数据集或设计少样本样例之前,应当优先对大语言模型内部蕴藏的海量零样本知识进行审慎的探索与分析。
核心信息浓缩(学术摘要核心要素提炼)
- 研究背景
- 大模型是优秀的少样本学习器,思维链提示通过少样本分步样例,在算术/符号推理等系统2任务上取得SOTA,但被认为依赖少样本能力。
- 核心创新
- 提出Zero-shot-CoT :无需任何少样本样例,仅添加固定短句 Let's think step by step 即可激活大模型的零样本推理能力。
- 实验结论
- 单一提示模板跨算术、符号、逻辑推理任务有效,在 text-davinci-002 和 PaLM-540B 上均实现大幅性能跃升;
- 证明大模型预训练阶段已习得通用推理逻辑,简单提示即可解锁。
- 研究价值
- 提供了极简、高性能的零样本推理基线;
- 揭示大模型零样本能力的潜力,为提示工程和模型能力挖掘提供新方向。
1 引言
扩大语言模型的规模,是近年来自然语言处理(NLP)领域变革的核心驱动力Vaswani 等人, 2017; Devlin 等人, 2019; Raffel 等人, 2020; Brown 等人, 2020; Thoppilan 等人, 2022; Rae 等人, 2021; Chowdhery 等人, 2022。大型语言模型(LLMs)的成功通常被归功于上下文少样本学习 或零样本学习 能力:只需向模型输入少量任务样例(少样本场景)或描述任务的指令(零样本场景),即可使其完成各类任务。这种通过输入信息引导语言模型完成任务的方法被称为提示技术(prompting)Liu 等人, 2021b,而人工设计提示词Schick \& Schütze, 2021; Reynolds \& McDonell, 2021或自动生成提示词Gao 等人, 2021; Shin 等人, 2020,已成为当前NLP领域的研究热点。
尽管大型语言模型在依赖直觉的单步系统1任务 Stanovich \& West, 2000中,结合任务专属的少样本或零样本提示能取得优异性能Liu 等人, 2021b,但即便是参数规模达到千亿级的模型,在需要慢速多步推理 的系统2任务上仍表现不佳Rae 等人, 2021。为解决这一缺陷,Wei 等人2022与 Wang 等人2022提出了思维链提示技术(CoT):该方法向模型输入分步推理的样例,而非传统的问答配对样例(见图1-a)。此类思维链示范能够引导模型生成推理路径,将复杂推理任务拆解为多个更简单的子步骤。值得注意的是,结合思维链提示后,模型的推理性能更贴合缩放定律,且会随模型规模的扩大而显著跃升。例如,当与5400亿参数的PaLM模型Chowdhery 等人, 2022结合时,思维链提示在多个推理基准任务上的性能远超标准少样本提示,以GSM8K任务为例,准确率从17.9%提升至58.1%。
尽管思维链提示Wei 等人, 2022以及众多其他任务专属提示技术Gao 等人, 2021; Schick \& Schütze, 2021; Liu 等人, 2021b的成功,常被归因于大型语言模型的少样本学习能力Brown 等人, 2020,但本文研究表明:仅需在回答每个问题前添加一句简单的提示语"Let's think step by step"(让我们一步步思考),即可使大型语言模型成为出色的零样本推理器(见图1)。尽管方法十分简洁,但我们提出的**零样本思维链(Zero-shot-CoT)**技术,能够以零样本方式生成合理的推理路径,并在标准零样本方法失效的问题上推导出正确答案。
至关重要的是,与以往大多数依赖任务专属样例(少样本)或模板(零样本)的提示工程不同Liu 等人, 2021b,零样本思维链具备普适性与任务无关性:无需针对不同任务修改提示语,就能在各类推理任务中引导模型生成分步答案,涵盖算术推理(MultiArithRoy \& Roth, 2015、GSM8KCobbe 等人, 2021、AQUA-RATLing 等人, 2017、SVAMPPatel 等人, 2021)、符号推理(最后字母拼接、硬币翻转)、常识推理(CommonSenseQATalmor 等人, 2019、StrategyQAGeva 等人, 2021),以及其他逻辑推理任务(BIG-bench中的日期理解、乱序物体追踪Srivastava 等人, 2022)。
我们在表2中通过实验对比了零样本思维链与其他提示基线的性能。结果显示,尽管零样本思维链的性能略逊于使用人工精心设计的任务专属分步样例的少样本思维链,但相比零样本基线,其性能提升十分显著:例如,基于大尺度指令微调模型text-davinci-002时,MultiArith任务的准确率从17.7%提升至78.7%,GSM8K任务从10.4%提升至40.7%。我们还在5400亿参数的PaLM这一现成大模型上验证了零样本思维链,在MultiArith与GSM8K任务上也观测到了相近幅度的性能提升。
尤为关键的是,借助这一固定的单一提示语,零样本语言模型的性能缩放曲线得到显著优化,可与少样本思维链基线相媲美。我们还发现,少样本思维链不仅需要人工设计多步推理提示词,且当提示样例的题型与目标任务的题型不匹配时,性能会显著下降,这表明其对任务专属提示词的设计高度敏感。相比之下,单一提示语在多样化推理任务中的普适性,揭示了大型语言模型中尚未被挖掘且研究不足的零样本基础能力,例如通用逻辑推理这类更高层次的通用认知能力Chollet, 2019。
尽管大型语言模型领域的蓬勃发展,最初是基于其"优秀少样本学习器"这一核心前提Brown 等人, 2020,但我们希望本研究能够激励更多相关探索,去发掘潜藏在这些模型中的高层级、多任务零样本能力。

图 1:GPT-3 在(a)标准 Few-shot(Brown 等,2020)、(b)Few-shot-CoT(Wei 等,2022)、(c)标准 Zero-shot 以及(d)本文方法(Zero-shot-CoT)下的输入与输出示例。
与 Few-shot-CoT 类似,Zero-shot-CoT 促进多步推理(蓝色文本)并在标准提示失败时得出正确答案。
不同于 Few-shot-CoT 需为每个任务提供逐步推理示例,本文方法无需任何示例,仅使用同一提示"Let's think step by step"即可跨任务(算术、符号、常识及其他逻辑推理任务)实现多步推理。
核心要点拆解(聚焦研究动机与方法创新)
1. 研究背景与痛点
| 类别 | 表现 | 核心问题 |
|---|---|---|
| 系统1任务 | 大模型结合少样本/零样本提示即可取得优异性能 | - |
| 系统2任务 | 千亿级大模型仍表现不佳 | 传统提示无法引导模型完成多步推理 |
| 少样本思维链(Few-shot-CoT) | 大幅提升系统2任务性能 | 依赖人工设计任务专属分步样例,成本高、泛化性弱,且对样例题型匹配度敏感 |
2. 零样本思维链(Zero-shot-CoT)的核心优势
- 极致简洁性 :无需任何人工样例,仅用固定短句 Let's think step by step 即可激活推理能力;
- 任务无关性:单一提示模板适配算术、符号、常识、逻辑等多类推理任务,无需定制化修改;
- 性能跃升显著:在text-davinci-002和PaLM-540B上,相较于零样本基线实现数十个百分点的准确率提升;
- 缩放曲线优化:让零样本模型的性能随规模增长的趋势,接近少样本思维链的水平。
3. 核心学术贡献
- 挑战传统认知:证明大模型的推理能力并非只能通过少样本样例激发,简单指令即可激活零样本推理潜力;
- 提出极简基线:为推理任务提供了无需标注、低成本的零样本基线方案;
- 揭示模型内在能力:证实大模型预训练阶段已习得通用推理逻辑,提示工程是解锁这些能力的关键。
2 研究背景
本文简要回顾构成研究基础的两个核心预备概念:大型语言模型(LLMs)与提示技术的兴起 ,以及面向多步推理的思维链(CoT)提示技术。
大型语言模型与提示技术
语言模型(LM)的目标是对文本的概率分布进行建模。近年来,通过扩大模型参数量 (从数百万量级Merity 等人, 2016,到数亿量级Devlin 等人, 2019,再到数千亿量级Brown 等人, 2020)和扩充训练数据规模 (如网络文本语料库Gao 等人, 2020)带来的性能提升,预训练大型语言模型已能出色完成众多下游自然语言处理任务。
除了经典的"预训练-微调"范式Liu 等人, 2021b外,参数量达到千亿级别的模型还展现出适配少样本学习 的特性Brown 等人, 2020,这种能力依托上下文学习 实现------即通过一段被称为提示词 的文本或模板,强力引导模型生成目标任务的答案,由此开启了"预训练-提示"的全新研究范式Liu 等人, 2021a。
在本研究中,我们将明确包含少量任务样例 的提示词定义为少样本提示词 ,而将仅包含模板、无任务样例 的提示词定义为零样本提示词。
思维链提示技术
多步算术与逻辑推理基准任务,对大型语言模型的缩放定律提出了极大挑战Rae 等人, 2021。作为少样本提示技术的一种具体实现,思维链(CoT)提示技术 Wei 等人, 2022提出了一种简洁的解决方案:将少样本样例中的答案,修改为分步推导的答案 。
这一方法在各类高难度推理基准任务上实现了性能的显著提升,尤其是与PaLMChowdhery 等人, 2022这类超大规模语言模型结合时,效果更为突出。
图1的上半部分对比了标准少样本提示 与少样本思维链提示 的差异。值得注意的是,在最初的研究Wei 等人, 2022中,少样本学习被视为解决这类复杂任务的必要前提,甚至未报告零样本基线的性能。为与本文提出的方法区分,我们将Wei 等人2022提出的技术命名为少样本思维链(Few-shot-CoT)。
核心要点拆解(聚焦概念界定与关联)
1. 关键概念定义与区分
| 概念 | 核心特征 | 应用场景 |
|---|---|---|
| 预训练-微调范式 | 需针对下游任务使用标注数据微调模型参数 | 有充足标注数据的任务 |
| 预训练-提示范式 | 无需修改模型参数,通过提示词引导模型完成任务 | 零样本/少样本场景,快速适配多任务 |
| 少样本提示词 | 包含少量任务样例(输入-输出对或输入-思维链-输出对) | 有少量标注样例,需要引导模型学习任务范式 |
| 零样本提示词 | 无任务样例,仅包含任务描述或引导性模板 | 无标注数据,需要模型依赖预训练知识完成任务 |
| 少样本思维链(Few-shot-CoT) | 少样本提示词的特例,样例为输入-分步推理-输出三元组 | 复杂多步推理任务,可提供少量分步样例 |
2. 思维链提示技术的核心定位
- 技术归属 :Few-shot-CoT 本质是少样本提示技术的优化变体,核心改进是将样例的"直接答案"替换为"分步推理路径",从而引导模型模仿多步思考逻辑。
- 原始研究的局限:Wei 等人2022的工作默认"少样本样例是激活推理能力的必要条件",因此未验证零样本场景下的模型性能,这为本文 Zero-shot-CoT 的提出留下了研究空间。
- 性能提升关键 :Few-shot-CoT 与超大规模模型(如 PaLM-540B)结合时性能跃升显著,印证了"推理能力是模型规模的涌现特性"这一核心结论。
3. 技术演进逻辑梳理
传统预训练模型 → 扩大规模 → 千亿级LLMs具备上下文学习能力 → 预训练-提示范式兴起
→ 标准少样本提示在系统2任务失效 → Few-shot-CoT(分步样例)提升推理性能
→ 本文探索:无需样例,仅用指令即可激活零样本推理能力(Zero-shot-CoT)3 零样本思维链(Zero-shot-CoT)
本文提出零样本思维链(Zero-shot-CoT) ------一种基于模板的零样本提示方法,用于激发模型的思维链推理能力。该方法与原始思维链提示Wei 等人, 2022的核心区别的是:无需分步少样本样例 ;与大多数现有模板提示技术Liu 等人, 2021b的区别在于:本质上具备任务无关性 ,可通过单一模板在各类任务中激发多跳推理能力。
本方法的核心思想极为简洁(如图1所示):在提示中添加"Let's think step by step"(让我们一步步思考)或类似表述(见表4),即可引导模型生成分步推理过程。
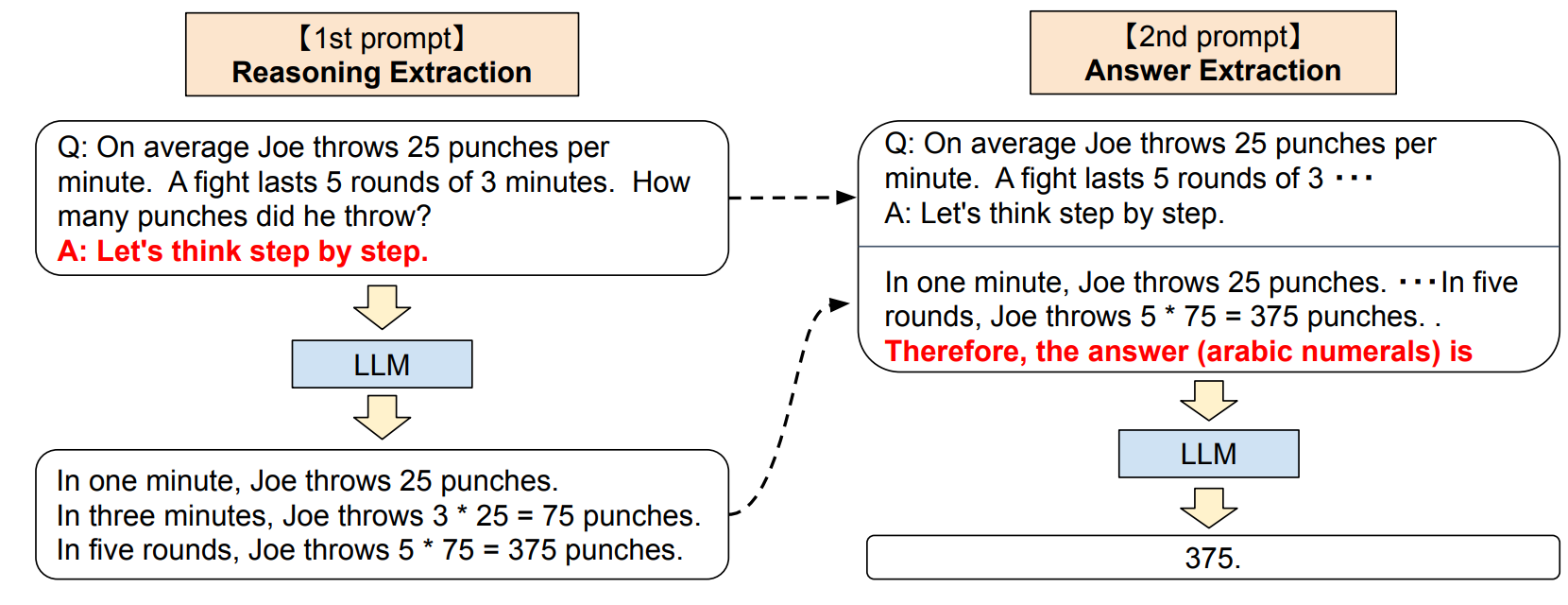
图 2:§3 描述的 Zero-shot-CoT 完整流程:我们首先使用第一个"推理"提示,从语言模型中提取完整的推理路径;随后使用第二个"答案"提示,从推理文本中以正确格式提取最终答案。
3.1 两阶段提示流程
尽管Zero-shot-CoT的概念简洁,但它通过两次提示 分别提取推理过程和最终答案(如图2所示)。相比之下,零样本基线(见图1左下角)仅通过一次提示(如"The answer is")直接提取格式规范的答案;而无论是标准少样本提示还是思维链少样本提示,均通过在人工设计的少样本样例中明确指定答案格式,避免了额外的答案提取提示(见图1左上角和右上角)。
综上,少样本思维链Wei 等人, 2022需要针对每个任务人工精心设计少量带特定答案格式的提示样例,而Zero-shot-CoT虽无需复杂的样例设计,但需分两次向模型输入提示。
-
第一阶段:推理过程提取(1st prompt: reasoning extraction)
第一步,使用简单模板将输入问题( x )转换为提示语( x' ),模板格式为:"Q: X. A: T"。其中:
- 是输入问题( x )的占位符;
- T 是人工设计的触发句 ( t )的占位符,用于引导模型生成解答问题( x )所需的思维链。
例如,若使用"Let's think step by step"作为触发句,则最终提示语( x' )为:"Q: X. A: Let's think step by step."(更多触发句示例见表4)。
将构建好的提示语( x' )输入语言模型,生成后续推理语句( z )。本文为简化实验,全程采用贪心解码策略(其他解码策略同样适用)。
-
第二阶段:答案提取(2nd prompt: answer extraction)
第二步,结合第一阶段生成的推理语句( z )和原始提示语( x' ),从模型中提取最终答案。具体而言,通过拼接三个部分构建提示语:"X′ Z A",其中:
- X′ 是第一阶段的提示语( x' );
- Z 是第一阶段生成的推理语句( z );
- A 是用于提取答案的触发句 (根据答案格式灵活调整)。
该阶段的提示语具有"自增强"特性------提示内容包含模型自身生成的推理语句( z )。
实验中,根据任务的答案格式选用不同的答案触发句:例如,多选题任务使用"Therefore, among A through E, the answer is"(因此,在A到E中,答案是);需要数值答案的数学题使用"Therefore, the answer (arabic numerals) is"(因此,答案(阿拉伯数字)是)。完整的答案触发句列表见附录A.5。
最后,将该阶段的提示语输入语言模型,生成语句( \hat{y} ),并通过解析提取最终答案(解析器细节见第4节"答案清洗(Answer Cleansing)")。
核心要点拆解(聚焦方法设计与流程)
1. Zero-shot-CoT 的核心设计亮点
| 设计维度 | 具体实现 | 核心价值 |
|---|---|---|
| 任务无关性 | 单一推理触发句(如 Let's think step by step)适配所有推理任务 | 无需针对不同任务定制提示,降低工程成本,提升泛化性 |
| 两阶段拆分 | 先提取推理链,再提取答案 | 避免模型直接输出答案时跳过推理步骤,同时通过"推理链+答案触发句"确保答案格式规范 |
| 自增强提示 | 第二阶段提示包含模型自身生成的推理链 ( z ) | 利用模型生成的推理逻辑引导答案输出,确保答案与推理过程的一致性 |
| 轻量化设计 | 无需人工标注少样本样例,仅需设计简单触发句 | 零标注成本,可快速迁移到无数据的新推理任务 |
2. 两阶段提示流程详解(对应通信领域落地适配)
3. 与 Few-shot-CoT 的流程对比
| 流程环节 | Few-shot-CoT | Zero-shot-CoT |
|---|---|---|
| 前置准备 | 人工编写任务专属的〈输入-思维链-输出〉少样本样例 | 设计通用推理触发句和答案触发句(无需样例) |
| 推理引导 | 通过样例示范推理步骤 | 通过触发句直接引导推理步骤生成 |
| 答案提取 | 样例中指定答案格式,模型直接输出符合格式的答案 | 单独设计答案触发句,基于推理链提取答案 |
| 工程成本 | 高(需人工设计样例,且需适配不同任务) | 低(仅需设计两套触发句,全任务复用) |
4. 关键细节补充(适配工程落地)
- 推理触发句的灵活性:除了 Let's think step by step,还可使用"Let's break this down step by step""First, I need to..."等类似表述(见表4),核心是引导模型"分步思考",可根据通信领域任务调整为更贴合专业场景的表述(如"Let's analyze the communication task step by step");
- 答案触发句的适配性:需根据任务输出格式定制(如通信参数提取任务可设计触发句"Therefore, the extracted communication parameters are: "),确保输出格式便于后续解析;
- 解码策略选择:本文用贪心解码保证简洁性,实际落地时可结合采样(如温度T=0.7)生成多个推理链,再通过投票提升答案准确性(参考自一致性策略)。
4 实验
任务与数据集
我们在四类推理任务的12个数据集上验证所提方法的有效性,包括算术推理、常识推理、符号推理及其他逻辑推理任务。各数据集的详细描述见附录A.2。
- 算术推理:选取6个数据集,分别为(1)SingleEq Koncel-Kedziorski 等人, 2015、(2)AddSub Hosseini 等人, 2014、(3)MultiArith Roy \& Roth, 2015、(4)AQUA-RAT Ling 等人, 2017、(5)GSM8K Cobbe 等人, 2021、(6)SVAMP Patel 等人, 2021。前三者来自经典的数学应用题库 Koncel-Kedziorski 等人, 2016,后三者为近年发布的基准数据集。其中,SingleEq和AddSub为简单任务,无需多步计算即可求解;MultiArith、AQUA-RAT、GSM8K和SVAMP为高难度任务,需通过多步推理才能完成。
- 常识推理:采用 CommonsenseQA Talmor 等人, 2019 和 StrategyQA Geva 等人, 2021 两个数据集。CommonsenseQA 的题目语义复杂,通常需要基于先验知识进行推理 Talmor 等人, 2019;StrategyQA 要求模型通过隐含的多跳推理来推导答案 Geva 等人, 2021。
- 符号推理:采用 Last Letter Concatenation(最后字母拼接)和 Coin Flip(硬币翻转)两个任务 Wei 等人, 2022。最后字母拼接任务要求模型拼接每个单词的最后一个字母,实验中每个样本随机选取4个姓名;硬币翻转任务要求模型判断硬币经过多次翻转/不翻转操作后是否仍为正面朝上,实验中每个样本包含4次操作。尽管这些任务对人类而言十分简单,但语言模型在这类任务上的性能随规模扩大的增长曲线通常趋于平缓。
- 其他逻辑推理 :从 BIG-bench 基准 Srivastava 等人, 2022 中选取两个任务,分别为 Date Understanding(日期理解) 和 Tracking Shuffled Objects(乱序物体追踪)。日期理解任务要求模型根据上下文推断具体日期;乱序物体追踪任务测试模型根据物体初始状态和一系列打乱操作,推断物体最终状态的能力,实验中选取包含3个物体的追踪数据集。
模型
实验共采用 17个语言模型 。主实验模型包括 InstructGPT-3 Ouyang 等人, 2022(text-ada/babbage/curie/davinci-001 及 text-davinci-002)、原始 GPT-3 Brown 等人, 2020(ada、babbage、curie、davinci)以及 PaLM Chowdhery 等人, 2022(8B、62B、540B)。此外,为开展模型规模影响研究,还使用了 GPT-2 Radford 等人, 2019、GPT-Neo Black 等人, 2021、GPT-J Wang \& Komatsuzaki, 2021、T0 Sanh 等人, 2022 和 OPT Zhang 等人, 2022。模型参数规模覆盖 0.3B 至 540B,既包含标准模型(如 GPT-3、OPT),也包含指令微调变体(如 InstructGPT-3、T0)。模型详细信息见附录A.3。若无特殊说明,实验默认使用 text-davinci-002。
基线方法
为验证零样本思维链的推理有效性,我们主要将其与标准零样本提示 进行对比。零样本实验中,默认使用与 Zero-shot-CoT 相同格式的答案提取提示,详见附录A.5。为更全面评估大模型的零样本推理能力,我们还与 Wei 等人, 2022 中的少样本提示 和少样本思维链提示 基线进行对比,并使用完全相同的上下文样例。所有方法均采用贪心解码策略:零样本方法的结果具有确定性;少样本方法受上下文样例顺序影响 Lu 等人, 2022,为保证与零样本方法的公平对比,所有实验均使用固定随机种子运行一次。Wei 等人 2022 的研究表明,样例顺序对思维链提示实验结果的影响方差较小。
答案清洗
模型通过答案提取阶段生成文本后(见第3节及图2),我们的方法仅提取首次符合答案格式的文本片段作为最终预测。例如,在算术任务中,若模型输出"probably 375 and 376",则提取首个数字"375"作为预测结果;在多选题任务中,将首次出现的大写字母作为预测答案。详细规则见附录A.6。标准零样本提示方法采用相同的答案清洗策略。对于少样本提示和少样本思维链提示方法,我们遵循 Wang 等人, 2022 的方案:首先从模型输出中提取 "The answer is " 后的文本,再执行相同的清洗规则;若输出中未出现该关键词,则从文本末尾向前检索,将首个符合格式的文本作为预测结果。
4.1 实验结果
零样本思维链 vs 标准零样本提示
表1汇总了 Zero-shot-CoT 与标准零样本提示在各数据集上的准确率。结果显示:
表 1:Zero-shot-CoT 与 Zero-shot 在各任务上的准确率对比。
左侧数值 采用 §3 所述、依答案格式定制的答案提取提示的结果;
右侧数值 为额外实验中使用标准答案提示"The answer is"进行答案提取的结果。
详见附录 A.5 的实验设置。
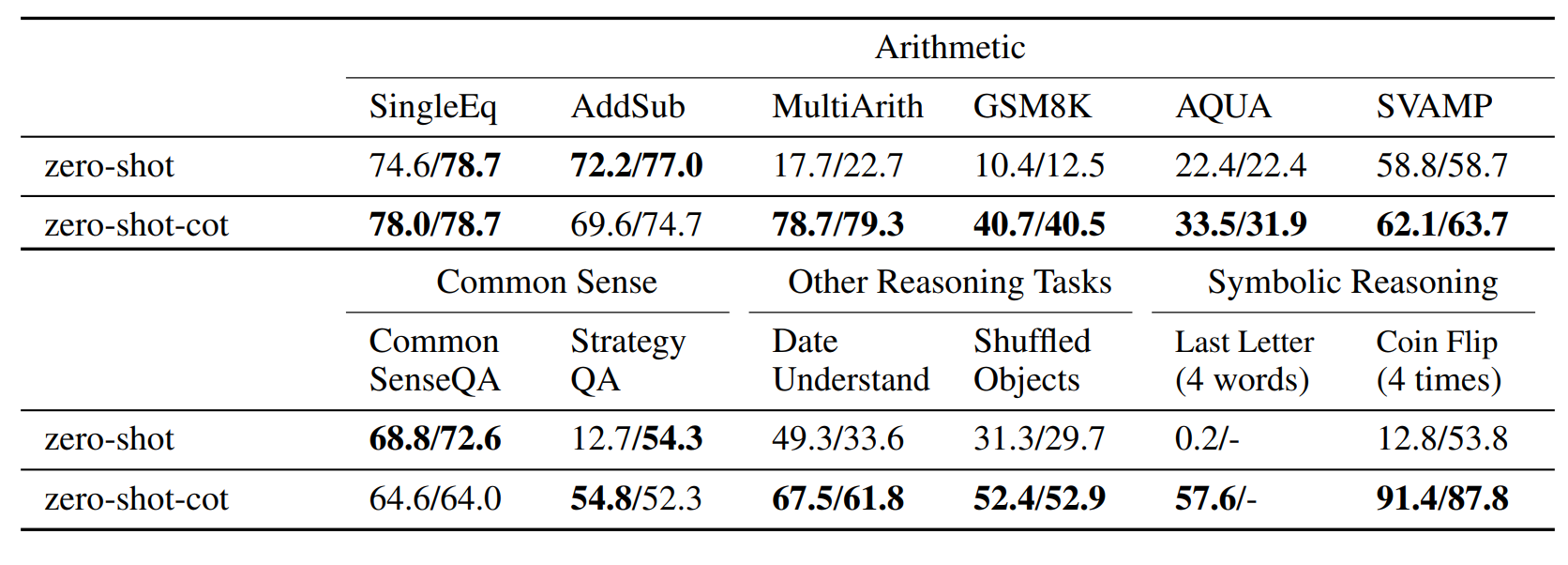
表 2:在 MultiArith 和 GSM8K 上与基线方法的准确率对比。
未指定模型时默认使用 text-davinci-002 。
Few-shot 与 Few-shot-CoT 设置中,我们采用 Wei et al., 2022 描述的相同 8 个示例。
(*1)为验证更换示例的方差,我们将 8 个示例分成两组,报告 4-shot-CoT 的两个结果。
(*2)我们在 Few-shot-CoT 每个示例的答案部分开头插入"Let's think step by step."以测试性能提升。
与 PaLM 的进一步实验结果见附录 D。
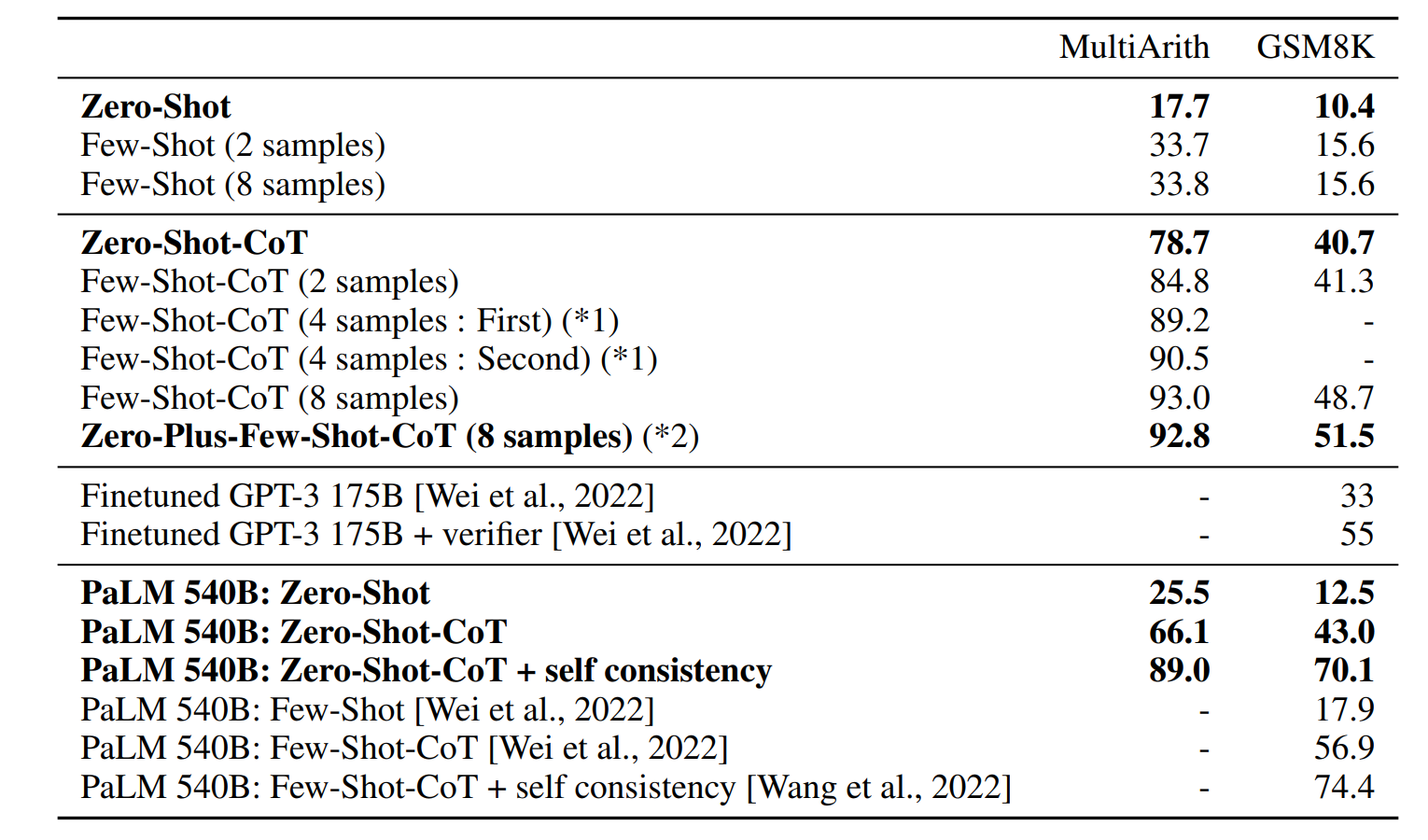
- Zero-shot-CoT 在 6个算术推理任务中的4个 (MultiArith、GSM8K、AQUA-RAT、SVAMP)、全部符号推理任务 及全部其他逻辑推理任务(来自 BIG-bench)上均实现大幅性能超越。例如,MultiArith 任务准确率从 17.7% 提升至 78.7%,GSM8K 任务从 10.4% 提升至 40.7%。
- 在剩余两个算术任务(SingleEq、AddSub)上,Zero-shot-CoT 性能与基线持平------这符合预期,因为这两个任务无需多步推理,思维链的分步引导优势无法体现。
- 在常识推理任务上,Zero-shot-CoT 未实现性能提升。这一现象同样合理:Wei 等人 2022 也指出,少样本思维链提示在 135B 参数的 LaMDA 模型上无法提升常识推理性能,仅在与更大规模的 PaLM-540B 结合时,才能提升 StrategyQA 任务性能,这一规律可能同样适用于本研究。
更重要的是,我们观察到,模型生成的大量思维链本身具有逻辑合理性 ,或仅包含人类可理解的错误(见表3)。这表明即使任务指标未直接体现性能增益,Zero-shot-CoT 确实能引导模型进行更优的常识推理。各数据集的 Zero-shot-CoT 生成样例见附录B。
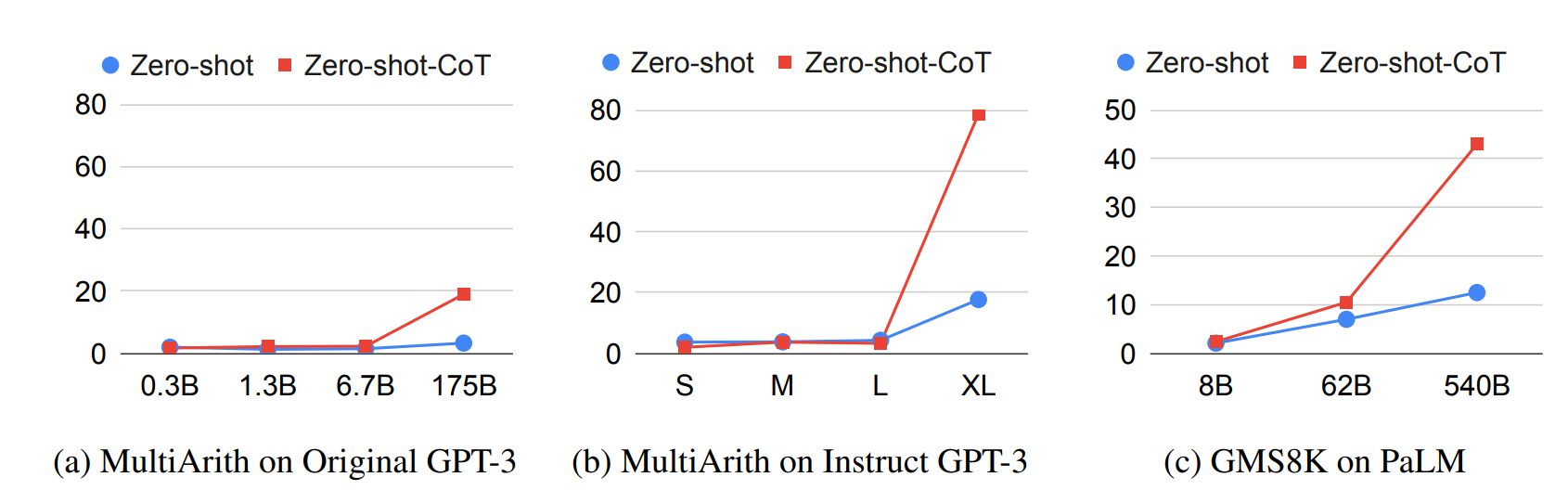
图 3:使用各类模型进行模型规模研究。
S:text-ada-001,M:text-babbage-001,L:text-curie-001,XL:text-davinci-002。 详细设置见附录 A.3 与 E。
Table 3: Examples generated by Zero-Shot-CoT on CommonsenseQA for Error Analysis.

与其他基线方法的对比
表2对比了 Zero-shot-CoT 与各基线方法在两个算术推理基准(MultiArith、GSM8K)上的性能。结果显示:
- 标准提示(第一组)与思维链提示(第二组)的性能差距巨大,说明若不引导模型进行多步推理,这类任务很难被有效解决。
- InstructGPT-3(text-davinci-002)和 PaLM-540B 模型均通过 Zero-shot-CoT 实现显著性能提升(第四组)。尽管 Zero-shot-CoT 性能自然低于少样本思维链提示,但大幅优于每个任务使用8个样例的标准少样本提示。
- 在 GSM8K 任务上,基于 InstructGPT-3(text-davinci-002)的 Zero-shot-CoT 性能,甚至超越了 Wei 等人 2022 报告的微调 GPT-3 模型及 PaLM-540B 标准少样本提示的性能(第三、四组)。PaLM 模型的更多实验结果见附录D。
模型规模对零样本推理的影响
图3对比了不同语言模型在 MultiArith 和 GSM8K 任务上的性能。结果表明:
- 未使用思维链推理时,模型性能随规模扩大基本保持平稳或缓慢增长,即性能曲线趋于平缓。
- 启用思维链推理后,原始 GPT-3、InstructGPT-3 和 PaLM 系列模型的性能均随规模扩大显著跃升。
- 小模型无法通过思维链推理有效提升性能。这一结论与 Wei 等人 2022 的少样本实验结果一致。
附录E展示了更多模型(包括 GPT-2、GPT-Neo、GPT-J、T0、OPT)的扩展实验结果。人工分析生成的思维链质量后发现,大模型的推理逻辑明显更优(各模型生成样例见附录B)。
误差分析
为深入理解 Zero-shot-CoT 的行为特性,我们人工分析了 InstructGPT-3 在 Zero-shot-CoT 提示下随机生成的样本,核心发现如下(示例见附录C):
- 常识推理(CommonsenseQA):即使最终预测错误,Zero-shot-CoT 生成的思维链通常灵活且合理;当模型难以确定唯一答案时,会输出多个候选选项(见表3示例)。
- 算术推理(MultiArith) :Zero-shot-CoT 与少样本思维链提示的错误模式存在显著差异:
- Zero-shot-CoT 的典型错误:在推导出正确答案后,生成多余的推理步骤,导致最终答案被错误修改;或未真正启动推理,仅对输入问题进行改写。
- 少样本思维链提示的典型错误:生成的推理链包含三元运算(如 ((3+2)\times4))时,容易出现计算失误。
- 表 4:在 MultiArith 数据集上,对模板鲁棒性的研究(使用 text-davinci-002)。
(*1)该模板来自 Ahn 等 2022,用于提示语言模型根据高层指令生成逐步动作以控制机器人。
(*2)该模板来自 Reynolds 和 McDonell 2021,但未进行定量评估。
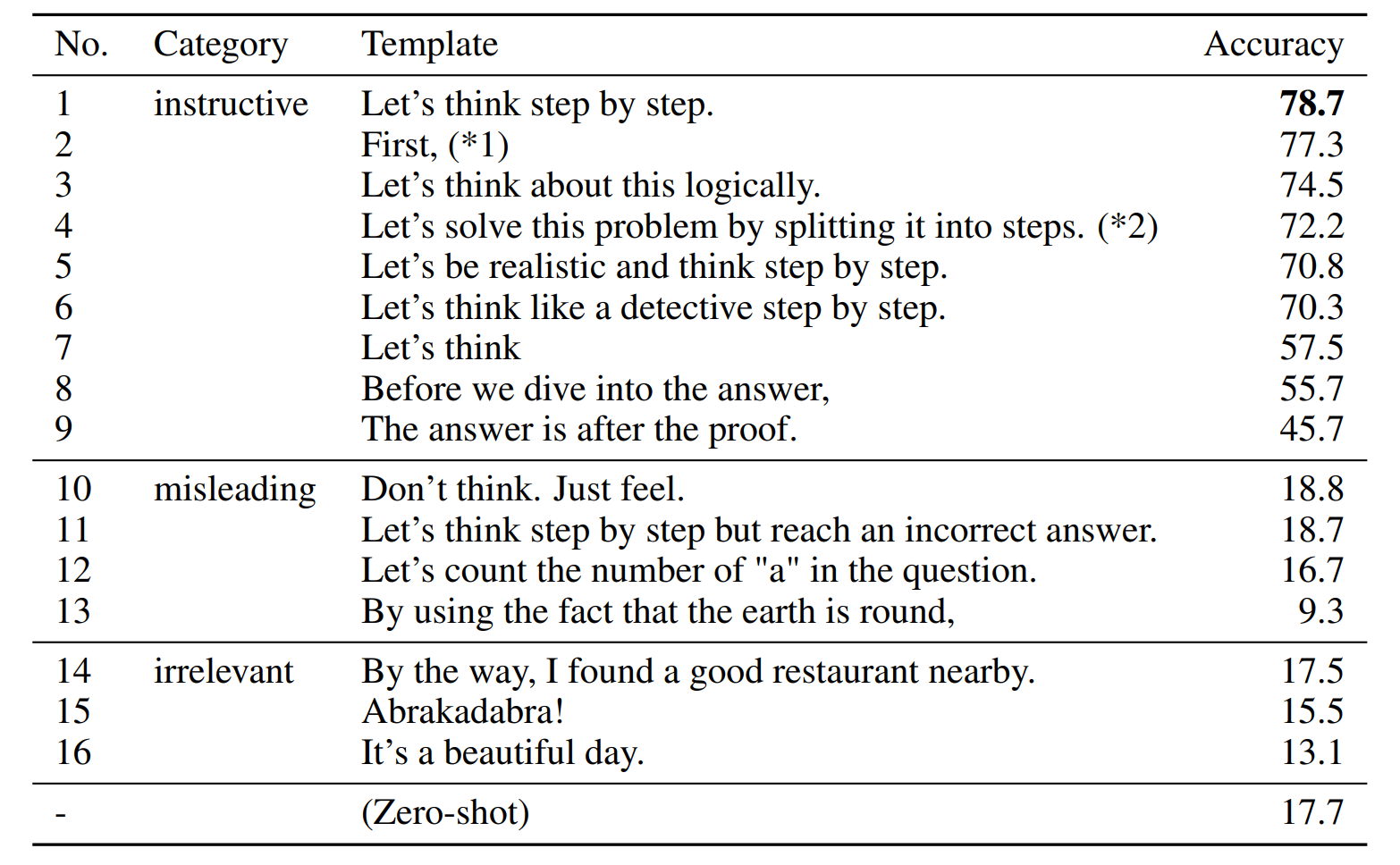
表 5:Few-shot-CoT 对示例的鲁棒性研究。
当示例来自完全不同的任务时,性能普遍下降;但当答案格式匹配时(如 CommonsenseQA → AQUA-RAT,均为多项选择),性能损失较小。 † 本变体使用了 CommonsenseQA 样本。

提示词选择对 Zero-shot-CoT 的影响
我们验证了 Zero-shot-CoT 对输入提示词的鲁棒性。表4汇总了 16种不同模板 在任务上的性能,这些模板分为三类(遵循 Webson & Pavlick 2022 的分类标准):
- 指导性模板:鼓励模型进行推理;
- 误导性模板:抑制推理,或引导模型进行错误推理;
- 无关模板 :与推理无关。
结果表明:指导性模板能显著提升任务性能,其中 "Let's think step by step." 取得最优效果;但不同指导性语句的性能差异明显。有趣的是,不同模板会引导模型生成风格迥异的推理过程(各模板生成样例见附录B)。相比之下,误导性模板和无关模板无法带来性能提升。如何自动构建更优的 Zero-shot-CoT 模板,仍是一个待解的开放性问题。
提示词选择对少样本思维链提示的影响
表5展示了少样本思维链提示在跨数据集样例迁移时的性能:将 CommonsenseQA 的样例分别迁移至 AQUA-RAT 和 MultiArith 任务。两个迁移场景的任务领域均不相同,但前者的答案格式(多选题)与源任务一致,后者的答案格式(数值)与源任务不同。结果表明:
- 当答案格式一致时,跨领域样例迁移(常识→算术)能带来显著的性能增益(相对零样本基线),甚至接近 Zero-shot-CoT 和少样本思维链提示的性能。
- 当答案格式不同时,性能增益大幅下降。
这一结果验证了现有研究结论 Min 等人, 2022:在上下文学习中,语言模型更倾向于利用少样本样例学习答案格式 ,而非理解任务本身。但值得注意的是,两种迁移场景的性能均低于 Zero-shot-CoT,这也印证了少样本思维链提示高度依赖任务专属样例设计的特点。
核心要点拆解(聚焦实验结论与关键洞察)
1. Zero-shot-CoT 的性能边界
| 任务类型 | 性能表现 | 核心原因 |
|---|---|---|
| 多步算术推理(如 GSM8K) | 大幅超越零样本基线,媲美部分微调模型 | 分步推理适配多步计算的逻辑需求,解决了模型"跳步计算"的问题 |
| 单步算术推理(如 SingleEq) | 与基线持平 | 任务无多步推理需求,思维链的引导优势无法体现 |
| 符号/逻辑推理(如硬币翻转、日期理解) | 显著提升 | 符号操作和逻辑推导可被思维链显性化,避免模型"直觉性错误" |
| 常识推理(如 CommonsenseQA) | 无明显增益 | 常识推理依赖海量隐性知识,仅靠分步引导不足以弥补知识缺口,需超大模型+领域知识结合 |
2. 模型规模的关键作用
- 阈值效应 :思维链推理是大模型的涌现能力,仅当模型参数规模达到一定量级(如百亿级)时,才能有效生成逻辑正确的推理链;小模型即使添加思维链提示,也只会生成流畅但无意义的推理文本。
- 缩放曲线优化:Zero-shot-CoT 可将零样本模型的"平缓缩放曲线"转化为"陡峭上升曲线",大幅提升大模型的性价比。
3. 提示词与样例设计的核心洞察
| 方法 | 核心依赖 | 局限性 |
|---|---|---|
| Zero-shot-CoT | 指导性提示词(如 Let's think step by step) | 对提示词表述敏感,误导性/无关提示词会完全失效 |
| 少样本思维链提示 | 任务专属样例 | 跨领域迁移性能差,模型易"学格式不学任务" |
4. 两类方法的错误模式对比
| 方法 | 典型错误 | 优化方向 |
|---|---|---|
| Zero-shot-CoT | 多余推理步骤、未启动推理 | 设计"推理终止触发词",避免模型生成冗余内容;优化提示词引导模型主动拆解问题 |
| 少样本思维链提示 | 复杂运算失误 | 引入外部计算器工具,对推理链中的计算步骤进行验证;优化样例中的运算步骤表述 |
5 讨论与相关工作
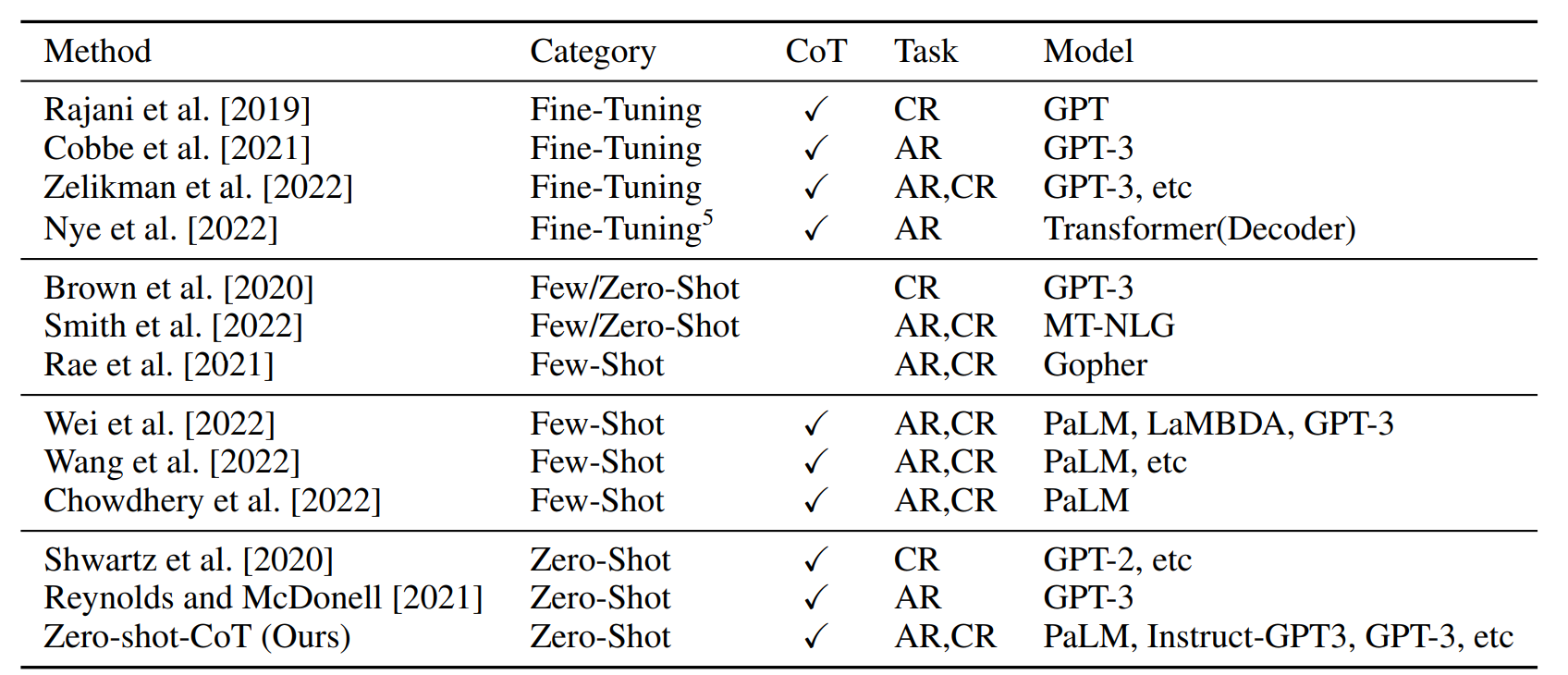
表6 :算术推理/常识推理领域相关研究汇总。其中"类别"列表示训练策略,"CoT"列表示是否输出思维链,"任务"列列出对应论文研究的任务类型(AR=算术推理,CR=常识推理)。
大语言模型的推理能力
多项研究表明,预训练模型通常不擅长推理任务Brown 等人, 2020; Smith 等人, 2022; Rae 等人, 2021,但通过让模型生成分步推理过程,其推理能力可得到显著提升------实现方式包括微调 Rajani 等人, 2019; Cobbe 等人, 2021; Zelikman 等人, 2022; Nye 等人, 2022和少样本提示 Wei 等人, 2022; Wang 等人, 2022; Chowdhery 等人, 2022(相关研究汇总见表6)。
与大多数现有研究不同,本文聚焦零样本提示 ,实验证明:单一固定触发提示词 可大幅提升大语言模型在各类复杂多跳推理任务中的零样本推理性能(见表1),且模型规模越大,提升效果越显著(见图3)。即使最终预测结果错误,模型在不同任务上生成的思维链依然具备合理性与可解释性(见附录B、C)。
与本文研究思路相近的是 Reynolds 和 McDonell 2021 的工作,他们提出提示词"Let's solve this problem by splitting it into steps"(让我们把问题拆分成步骤来解决)可促进模型在简单算术题上的多步推理。但该研究仅将其视为任务专属提示样例 ,未在多样化推理任务上与基线方法开展定量对比。
Shwartz 等人 2020 提出将常识问题分解为一系列信息查询子问题(例如"X的定义是什么"),该方法无需示范样例,但需要针对每个推理任务进行大量人工提示工程。
现有研究Wei 等人, 2022往往只强调少样本学习和任务专属上下文学习(例如未报告零样本基线性能),而本文结果有力证明:大语言模型本身就是出色的零样本推理器。本文提出的方法无需耗时的微调或高成本的样本工程,可适配任意预训练大语言模型,为所有推理任务提供性能强劲的零样本基线。
大语言模型的零样本能力
Radford 等人 2019 研究发现,大语言模型在阅读理解、翻译、摘要等系统1任务 中具备优异的零样本能力。Sanh 等人 2022、Ouyang 等人 2022 指出,通过显式指令微调,可进一步增强大语言模型的零样本能力。
尽管这些研究关注大语言模型的零样本性能,但均聚焦于系统1任务;而本文则针对系统2任务 展开研究------这类任务因性能缩放曲线趋于平缓,被视为大语言模型面临的重大挑战。此外,零样本思维链(Zero-shot-CoT)与指令微调具有正交性:无论是 InstructGPT-3、原生 GPT-3 还是 PaLM 模型,Zero-shot-CoT 均能有效提升其零样本性能(见图3)。
从"狭义(任务专属)提示"到"广义(多任务)提示"
大多数提示方法都是任务专属 的:少样本提示因依赖任务专属上下文样例,天然具备任务特异性Brown 等人, 2020; Wei 等人, 2022;而多数零样本提示也聚焦于逐任务模板工程Liu 等人, 2021b; Reynolds 和 McDonell, 2021。
借鉴 Chollet 2019 基于智能层级模型McGrew, 2005; Johnson \& Bouchard Jr, 2005提出的术语,这些提示方法可被认为是从大语言模型中激发**"狭义泛化能力"或任务专属技能。
相比之下,本文方法是一种多任务提示**,能够激发大语言模型的**"广义泛化能力"**或通用认知能力(例如逻辑推理能力本身,或系统2思维能力)。我们希望本研究不仅能为大语言模型逻辑推理研究提供参考,更能推动学界发掘大语言模型中潜藏的其他通用认知能力。
训练数据集细节
本研究的一个局限性在于:缺乏大语言模型训练数据集的公开细节 ------例如 GPT 系列模型的 001 与 002 版本差异、原生 GPT-3 与 InstructGPT 的训练数据区别Ouyang 等人, 2022,以及 PaLM 模型的训练数据详情Chowdhery 等人, 2022。
但从实验结果来看,在所有主流大模型(InstructGPT-001/002、原生 GPT-3、PaLM)上,Zero-shot-CoT 均能实现从零样本基线到零样本思维链的性能跃升,且在算术与非算术任务上的提升效果具有一致性。这表明模型并非简单地记忆训练数据 ,而是真正学习到了一种与任务无关的、适用于通用问题求解的多步推理能力。
尽管本文大部分实验基于 InstructGPT(因其是性能最优的开源可访问大模型),但核心结果在 PaLM 上得到了复现;同时,InstructGPT 的数据集细节Ouyang 等人, 2022 附录A、B、F也证实,该模型并未针对多步推理任务进行特殊设计。
局限性与社会影响
本研究基于大语言模型的提示方法展开。大语言模型的训练数据来源于互联网多渠道的海量语料(详见"训练数据集细节"),因此会捕捉并放大训练数据中存在的偏见。
提示技术的本质是利用语言模型捕捉到的模式来完成各类任务,因此不可避免地继承了这一缺陷。但需要说明的是,本文方法为探究预训练大语言模型的复杂推理能力提供了更直接的途径------它消除了现有少样本方法中上下文学习带来的干扰因素,有助于更客观地研究大语言模型中的偏见问题。
核心要点拆解(聚焦研究价值与定位)
1. 本文与相关工作的核心差异
| 研究方向 | 核心方法 | 局限性 | 本文优势 |
|---|---|---|---|
| 微调增强推理 | 用标注推理数据微调模型 | 标注成本高、泛化性弱 | 零标注成本,适配任意预训练模型 |
| 少样本CoT | 人工编写任务专属分步样例 | 样例工程成本高、跨任务迁移差 | 无需样例,单一提示词适配全任务 |
| 早期零样本推理提示 | 任务专属模板/分解式提示 | 需逐任务人工设计,通用性差 | 任务无关性,无需定制化改造 |
2. 关键学术贡献的再梳理
- 能力认知突破 :证明大模型的推理能力并非"依赖少样本样例激发",而是预训练阶段就已习得的通用零样本能力,简单提示即可激活;
- 技术范式极简:提出两阶段零样本提示框架,以"单一触发词+两次提示"实现多任务推理,大幅降低工程落地成本;
- 研究视角拓展:将提示技术从"狭义任务专属"推向"广义多任务泛化",为发掘大模型通用认知能力提供新思路;
- 基线价值突出 :为推理任务提供最强零样本基线,避免后续研究重复造轮子,同时为少样本/微调方法提供对照基准。
3. 核心结论的跨领域迁移启示
- 通信领域适配价值:Zero-shot-CoT 的任务无关性,使其可直接迁移至通信意图识别/参数提取任务------无需标注通信领域推理样例,仅用"Let's analyze the communication task step by step"这类专属触发词,即可引导模型分步解析业务问题;
- 小模型落地方向 :尽管 Zero-shot-CoT 依赖大模型规模,但可结合知识蒸馏,将大模型的零样本推理能力迁移至小模型,降低通信场景的部署成本。
4. 局限性的深层解读
| 局限性 | 本质问题 | 潜在解决方案 |
|---|---|---|
| 训练数据集细节不透明 | 无法完全排除模型"记忆效应"的干扰 | 构建公开的推理任务测试集,设计"抗记忆"的全新推理题目 |
| 继承训练数据偏见 | 提示技术无法修正模型内置偏见 | 结合对抗性提示 或外部知识检索,削弱偏见对推理结果的影响 |
| 依赖千亿级大模型 | 小模型无法有效激发推理能力 | 探索"小模型+专用推理模块"的混合架构;利用大模型生成推理数据微调小模型 |
6 结论
我们提出了 Zero-shot-CoT,这是一种单一的零样本提示,能够在各种推理任务中从大型语言模型中引出思维链,而无需像以往工作那样为每个任务手工制作少量示例。我们的简单方法不仅是难以实现的多步骤系统 2 推理任务的最小且最强的零样本基线,这些任务长期以来逃避了 LLM 的缩放定律,而且也鼓励社区进一步发现类似的多任务提示,这些提示能够引发广泛的认知能力,而不是狭窄的任务特定技能。