环境
系统:CentOS-7
CPU : E5-2680V4 14核28线程
内存:DDR4 2133 32G * 2
显卡:Tesla V100-32G【PG503】 (水冷)
驱动: 535
CUDA: 12.2
ComfyUI version: 0.4.0
ComfyUI frontend version: 1.34.8系统软件信息
系统信息
OS
linux
Python Version
3.12.12 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 20:16:04) [GCC 11.2.0]
Embedded Python
false
Pytorch Version
2.9.1+cu128
Arguments
main.py --listen --port 8188 --cuda-malloc --lowvram
RAM Total
62.68 GB
RAM Free
60.25 GB启动
bash
python main.py --listen --port 8188 --cuda-malloc --lowvram使用模版
Flux Schnell完整版文生图
下载模文件并按提示的要求放入目录中
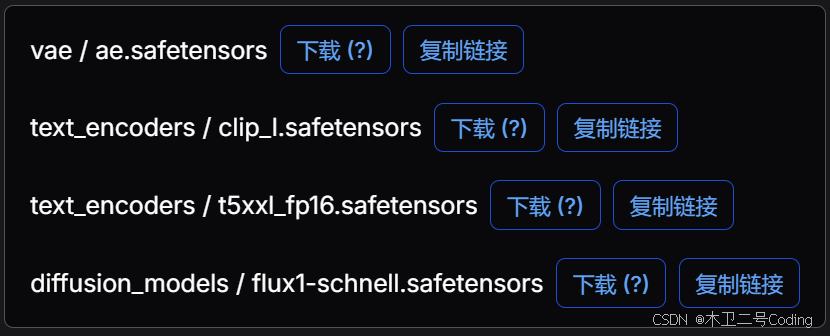
可以使用迅雷单独下载文件
bash
https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/resolve/main/split_files/vae/ae.safetensors
https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors
https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors
https://huggingface.co/Comfy-Org/flux1-schnell/resolve/main/flux1-schnell.safetensors如果没有Manager情况下可以重启ComfyUI
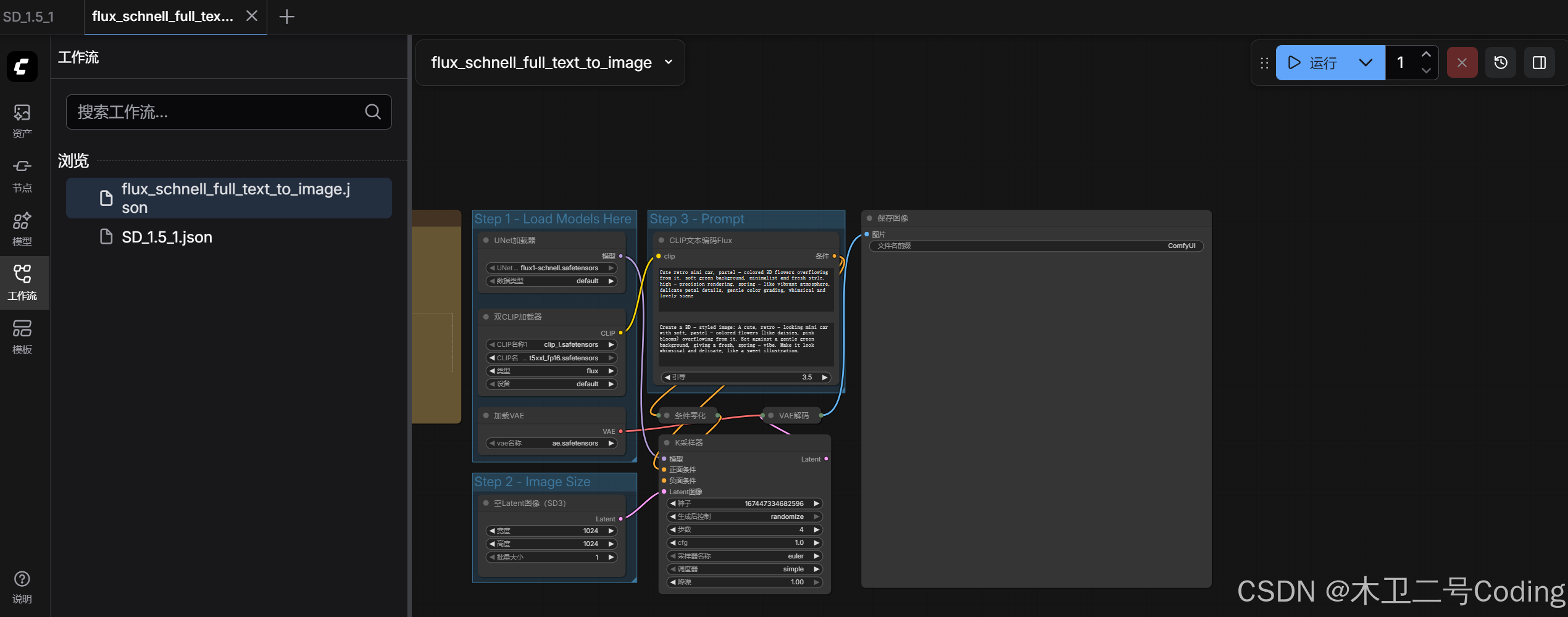
运行结果
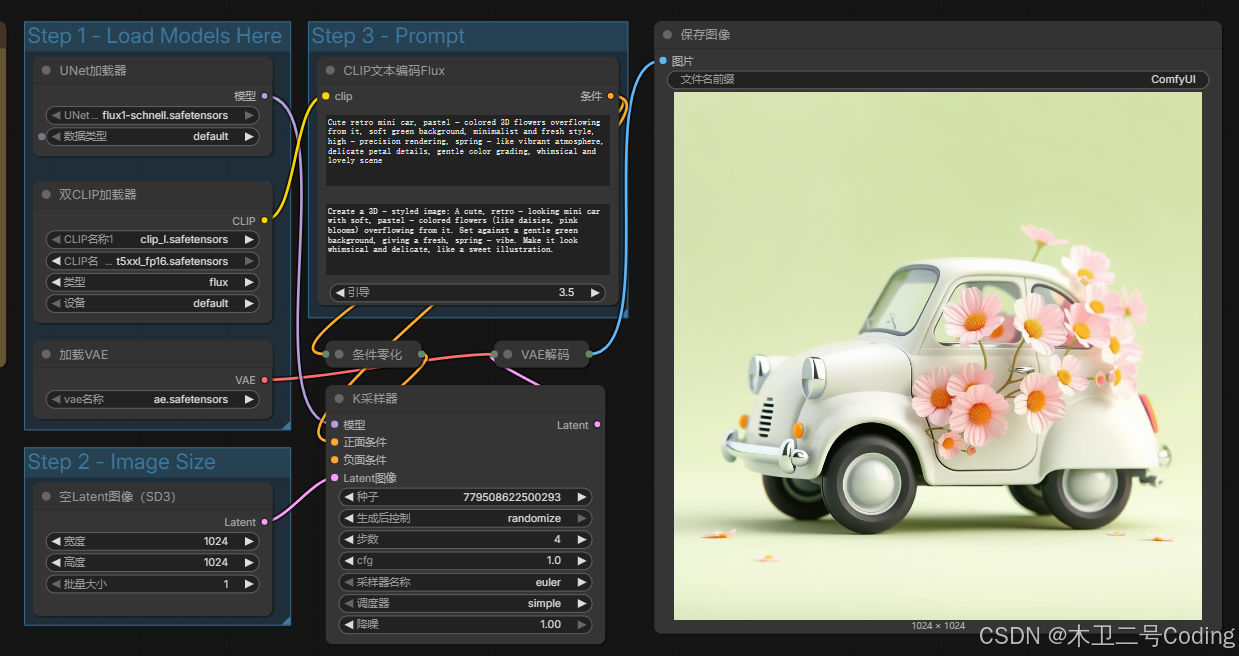
第一次时间长一点
时间
bash
loaded completely; 30782.57 MB usable, 22680.62 MB loaded, full load: True
100%|████████████████████████████████████████████████████████████████████████| 4/4 [00:04<00:00, 1.16s/it]
Requested to load AutoencodingEngine
Unloaded partially: 78.83 MB freed, 22601.80 MB remains loaded, 54.02 MB buffer reserved, lowvram patches: 0
loaded completely; 411.45 MB usable, 319.75 MB loaded, full load: True
Prompt executed in 34.40 seconds
got prompt
loaded completely; 30387.70 MB usable, 22680.62 MB loaded, full load: True
100%|████████████████████████████████████████████████████████████████████████| 4/4 [00:04<00:00, 1.10s/it]
Prompt executed in 6.17 secondsGPU
bash
Mon Dec 15 23:04:28 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla PG503-216 On | 00000000:04:00.0 Off | 0 |
| N/A 34C P0 237W / 250W | 23824MiB / 32768MiB | 100% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+总结
1.GPU 占用2.5G
2.GPU 100%
3.6 秒左右一张1024*1024
4.还是挺好用的