本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。
Training(模型训练)本质是AI世界的'科学烹饪实验'------以数据为食材原料,用超参数作配方比例,借验证集做品控质检,将'玄学炼丹'的试错过程,淬炼成'可复现的精密工程'。今天用最通俗的话,带你拆解模型训练(Training)全过程。
一、概念解读
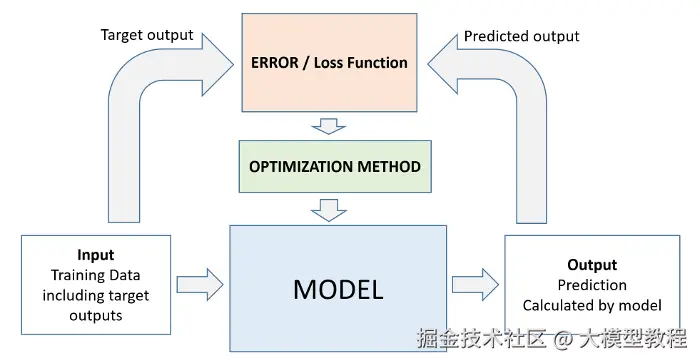
Training(模型训练)到底是个啥? 模型训练是用数据喂AI,通过算法调参数,让它从'瞎猜'到'精准预测'的过程。
模型训练中的专业术语如下:
- 数据(Data):模型的课本+练习题,用于学习。类似学生通过刷题(训练数据)掌握知识点,通过模拟考(验证集)检验水平。
- 参数(Weights):模型的大脑神经元连接强度,训练中不断调整。类似学生解题时调整解题思路(参数),使答案更接近标准答案(真实标签)。
- 损失函数(Loss):衡量模型答案与真实答案的差距。类似学生答错题扣分(Loss升高),答对加分(Loss下降)。
- 优化器(Optimizer):调整参数的学习方法,如梯度下降=查漏补缺。类似学生根据错题本(梯度)调整学习策略(参数),优先补薄弱科目(高Loss方向)。
- 正则化(Regularization):防止AI死记硬背的记忆抑制器。类似学生做题时强制理解原理(L1/L2正则化),而非机械背诵。
模型训练的本质是通过参数(解题思路)不断试错、用损失函数(扣分机制)量化差距、靠优化器(错题本复盘法)迭代策略、借正则化(防机械背诵规则)强化泛化,最终在验证集(模拟考)中交出高分答卷的过程。
为什么需要Training(模型训练)? 模型像一张白纸(随机初始化参数),无法完成任何任务,Training让模型逐步学会从输入到输出的正确映射, 让模型从'文盲'变成'学霸'。
- 人类学习:通过「课本+练习题+考试」掌握知识。
- 模型训练:通过「数据+优化算法+验证集」调整参数,使模型输出接近真实答案。
模型训练中的常见问题与解决方案如下:
- Loss不下降:模型学不会,像学生听天书。大概率是数据质量差、模型架构错误、学习率过大。这时候需要清洗数据、换模型、调小学习率。
- 过拟合:训练集满分,测试集翻车,像学生只背题库。大概率是数据量不足、模型复杂度过高。这时候需要增加数据、简化模型、加正则化。
- 训练速度慢:模型学得慢,像学生走神。大概率是Batch Size过大、硬件算力不足。这时候需要减小Batch Size、换GPU、分布式训练。
- 梯度爆炸/消失:模型学崩了,像学生疯癫/昏迷。大概率是网络层数过深、激活函数选择不当。这时候需要加梯度裁剪、换激活函数(如ReLU→LeakyReLU)、残差连接。

二、技术实现
Training(模型训练)如何进行技术实现?模型训练按'数据预处理→架构搭建→参数调优→迭代验证'四步走。
- 数据预处理 → "喂数据" (模型的"九年义务教育"阶段,先清洗、标注、划分数据集)
- 架构搭建 → "搭脑回路" (选择Transformer模型架构,初始化参数)
- 参数调优 → "刷题+改错" (损失函数扣分→优化器改参数→正则化防死记,模型的"高三冲刺"模式)
- 迭代验证 → "周考+月考" (验证集监控过拟合,测试集"毕业考"定生死,模型的"高考质检局")

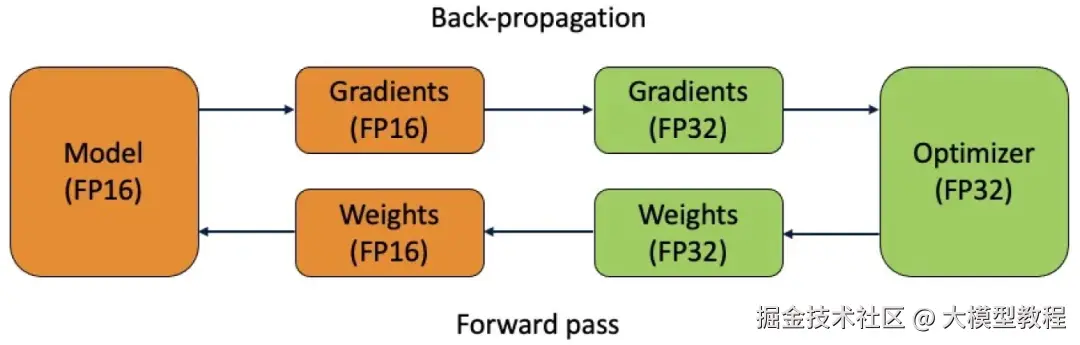
PyTorch如何实现Training(模型训练)?PyTorch通过定义模型结构(继承nn.Module并实现前向传播),配置损失函数(如MSELoss)与优化器(如Adam),在训练循环中反向传播更新参数(通过loss.backward()和optimizer.step()),同时利用DataLoader实现数据批量加载与预处理,最终通过迭代优化使模型拟合数据。
ini
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import math
# 参数配置
input_dim = 10 # 输入特征维度
output_dim = 1 # 输出维度(回归任务)
seq_length = 5 # 序列长度
batch_size = 32
num_epochs = 50 # 增加训练轮次
learning_rate = 0.001
d_model = 64 # 模型维度
nhead = 4 # 注意力头数
dim_feedforward = 256 # 前馈网络维度
# 生成虚拟数据(带时序特征)
X = torch.randn(1000, seq_length, input_dim) * torch.arange(1, seq_length+1).view(1, -1, 1)
y = X.mean(dim=(1,2)).unsqueeze(-1) # 目标:带时序权重的均值回归
# 数据标准化
X = (X - X.mean()) / X.std()
y = (y - y.mean()) / y.std()
# 封装为DataLoader
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2)
class TransformerEncoderRegressor(nn.Module):
def __init__(self):
super().__init__()
self.input_proj = nn.Linear(input_dim, d_model)
# Transformer编码器(参考网页7架构)
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=dim_feedforward,
batch_first=True # PyTorch 1.9+特性
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=3)
# 输出层(带特征聚合)
self.output_layer = nn.Sequential(
nn.Linear(d_model * seq_length, 128),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(128, output_dim)
)
# 位置编码(参考网页4实现)
self.pos_encoder = PositionalEncoding(d_model, dropout=0.1)
def forward(self, src):
# 输入投影 [batch, seq, d_model]
src = self.input_proj(src) * math.sqrt(d_model)
# 添加位置编码
src = self.pos_encoder(src)
# 编码处理 [batch, seq, d_model]
memory = self.encoder(src)
# 特征聚合 [batch, seq*d_model]
flattened = memory.view(memory.size(0), -1)
return self.output_layer(flattened)
class PositionalEncoding(nn.Module):
"""网页4位置编码实现(适配batch_first格式)"""
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0)) # [1, max_len, d_model]
def forward(self, x):
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
# 初始化模型
model = TransformerEncoderRegressor()
criterion = nn.MSELoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=1e-4)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5)
# 训练循环(带验证)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
# 梯度裁剪(网页7实践)
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
scheduler.step(avg_loss)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}, LR: {optimizer.param_groups[0]["lr"]:.2e}')
# 测试推理
test_input = torch.randn(3, seq_length, input_dim) # 批量推理测试
model.eval()
with torch.no_grad():
prediction = model(test_input)
print('Test predictions:', prediction.squeeze().tolist())学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。