pandas是Python数据科学方向必备工具,更新活跃,官网放出2025年即将迎来v3.0.0大版本更新! 下面参考Release notes,看看v3.0.0将带来哪些变化!
**温馨提示:**是否要升级到 pandas 3.0 是一个需要仔细权衡的决定。这个版本引入了一些激动人心的性能改进,但也包含了一些破坏性变更,可能会影响现有代码的正常运行。
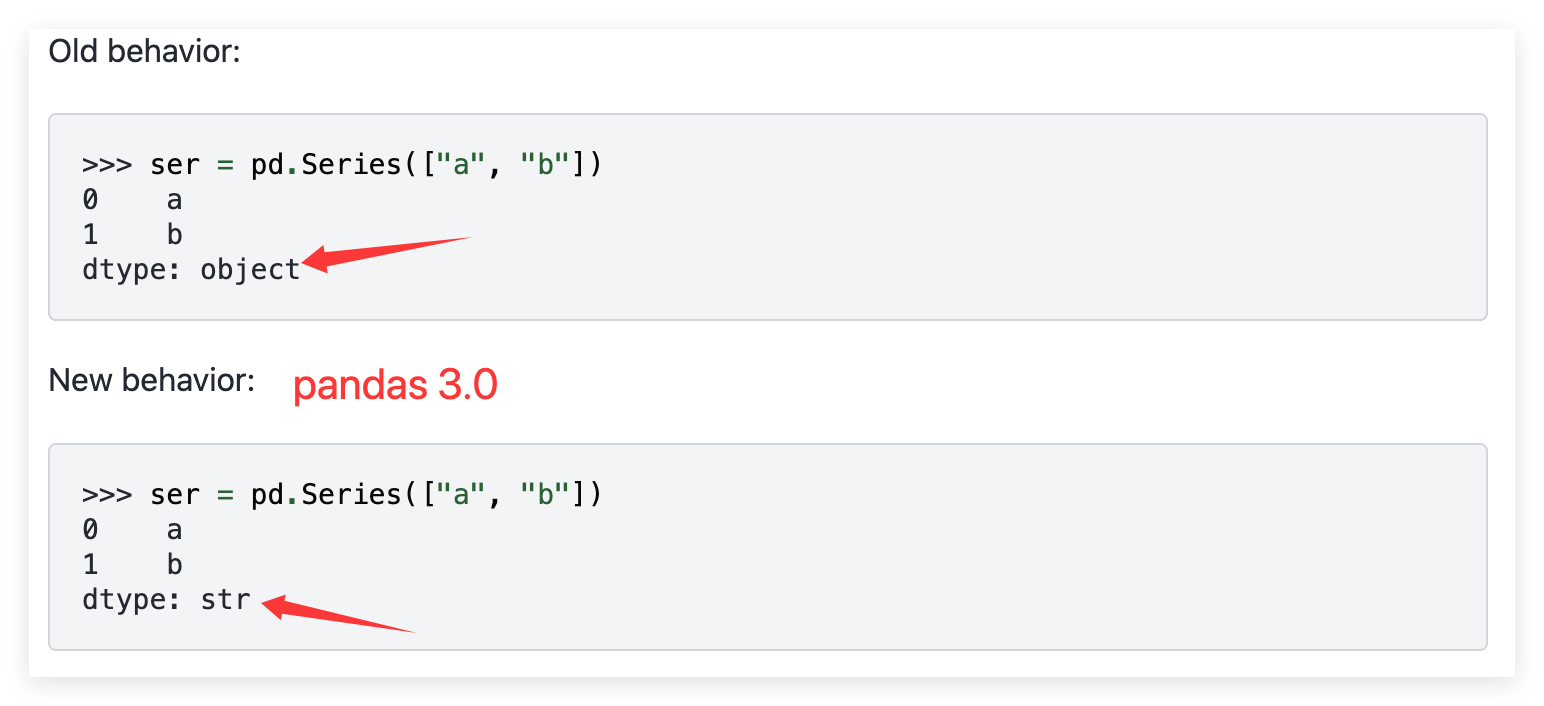
使用更高效的专用字符串数据类型
- 在 pandas 3.0 之前,字符串列默认是
object类型(不专一,效率低)。 - 从 pandas 3.0 开始,字符串列默认是专用的
str类型(更专一,底层优先用 PyArrow 提升效率)
引入"copy-on-write"机制
核心变更要点:
- 任何索引操作(例如,通过任何方式对 DataFrame 或 Series 进行子集选择,包括将 DataFrame 的列作为 Series 访问)或任何返回新 DataFrame 或 Series 的方法,其结果在用户 API 层面都将始终表现得像一个独立的副本。
- 因此,如果您需要修改一个 DataFrame 或 Series 对象,唯一可靠的方式是直接修改这个对象本身。这意味着,以往可能通过操作其派生对象(例如视图)来间接修改原数据的模式将不再有效。
目的:
- 让用户API的行为更加一致和可预测,现在有一条明确的规则:任何子集或返回的Series/DataFrame的行为都如同原始数据的副本,因此永远不会改变原始数据(在pandas 3.0之前,派生对象到底是副本还是视图取决于具体操作,这常常令人困惑)。
- 避免不必要的副本以提高性能,虽然用户层面每个索引操作或方法返回的新DataFrame或Series行为如同副本,但pandas在底层会尽可能使用视图,并仅在需要保证"行为如同副本"时才进行实际复制(这就是底层实现的"写时复制"机制)
注意:
- 这部分行为变化是pandas 3.0中的破坏性变更。建议在升级到pandas 3.0之前,先升级到pandas 2.3版本,以便针对部分变更获取弃用警告。迁移指南详细解释了升级过程
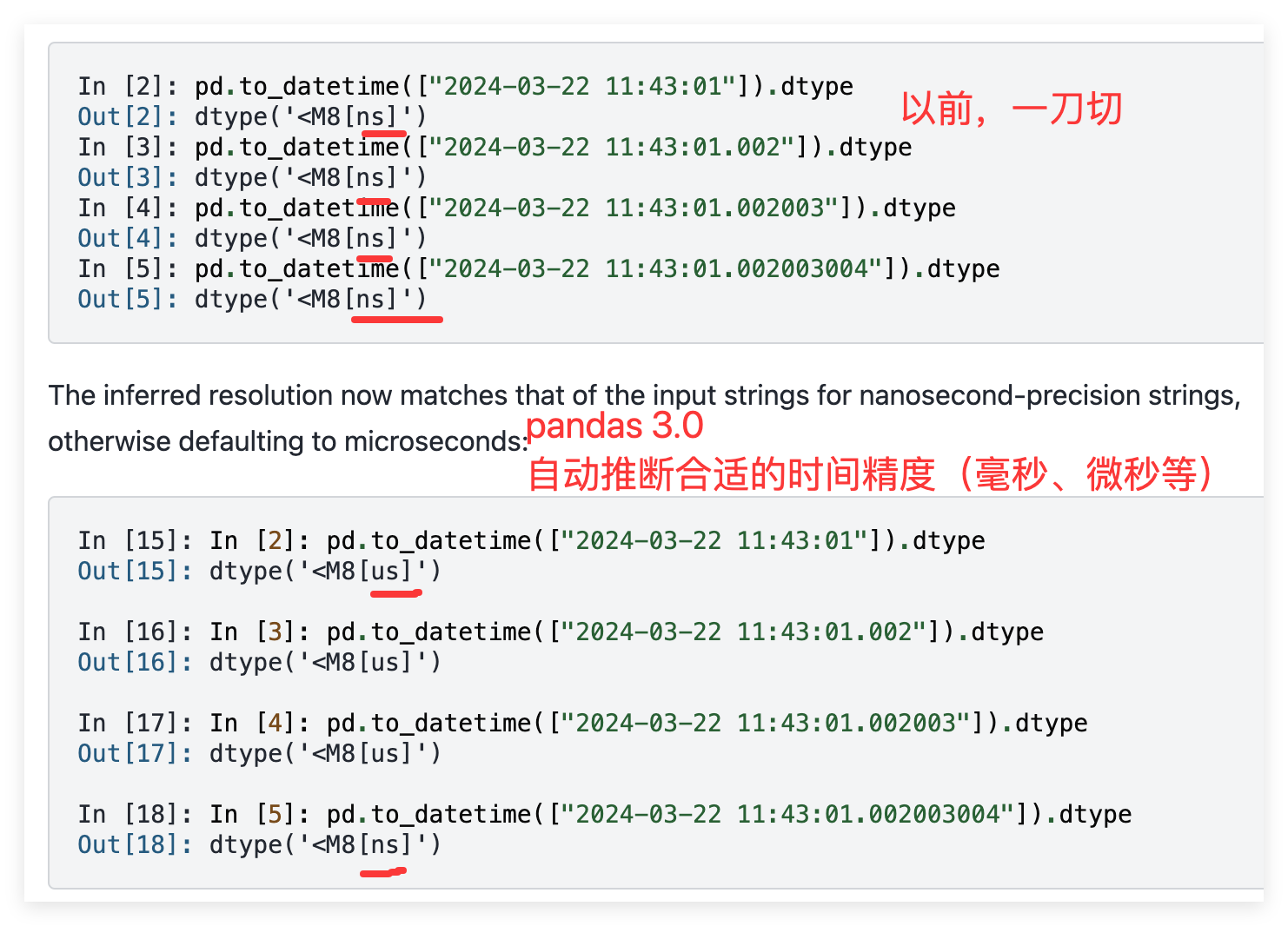
优化时间戳精度
当将字符串序列、datetime对象或np.datetime64对象转换为datetime64数据类型时,现在会自动推断输出数据类型(即datetime64dtype)的适当时间分辨率(也称为单位,如纳秒、微秒、毫秒、秒等)。
同一这一变更影响Series、DataFrame、Index、DatetimeIndex的创建以及to_datetime()函数的行为。
例如,
优化凌乱的缺省值
pandas3.0在默认设置下,缺省值(例如,NA、None、NaN、pd.NA )会被统一视为 NA,这使得缺失值语义更加清晰。
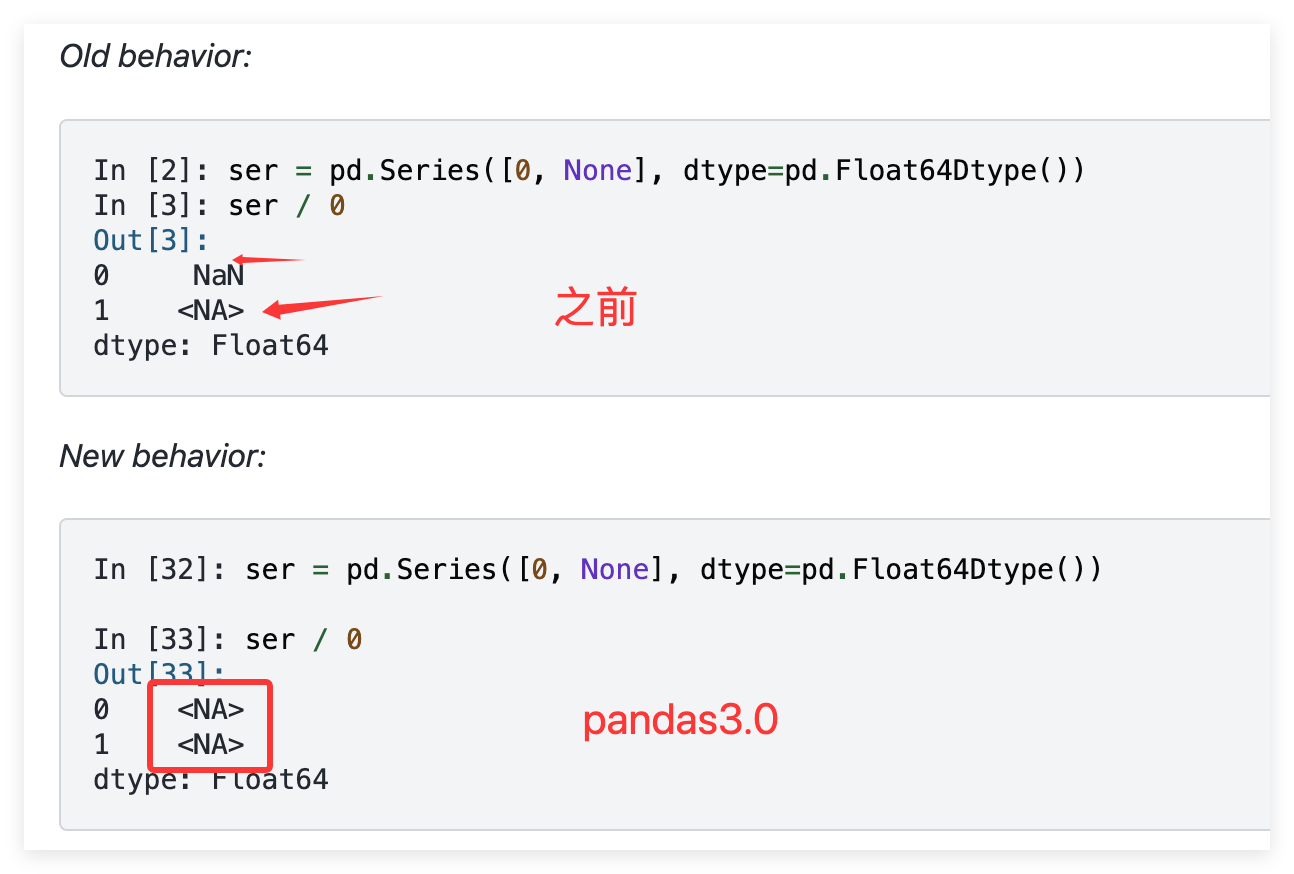
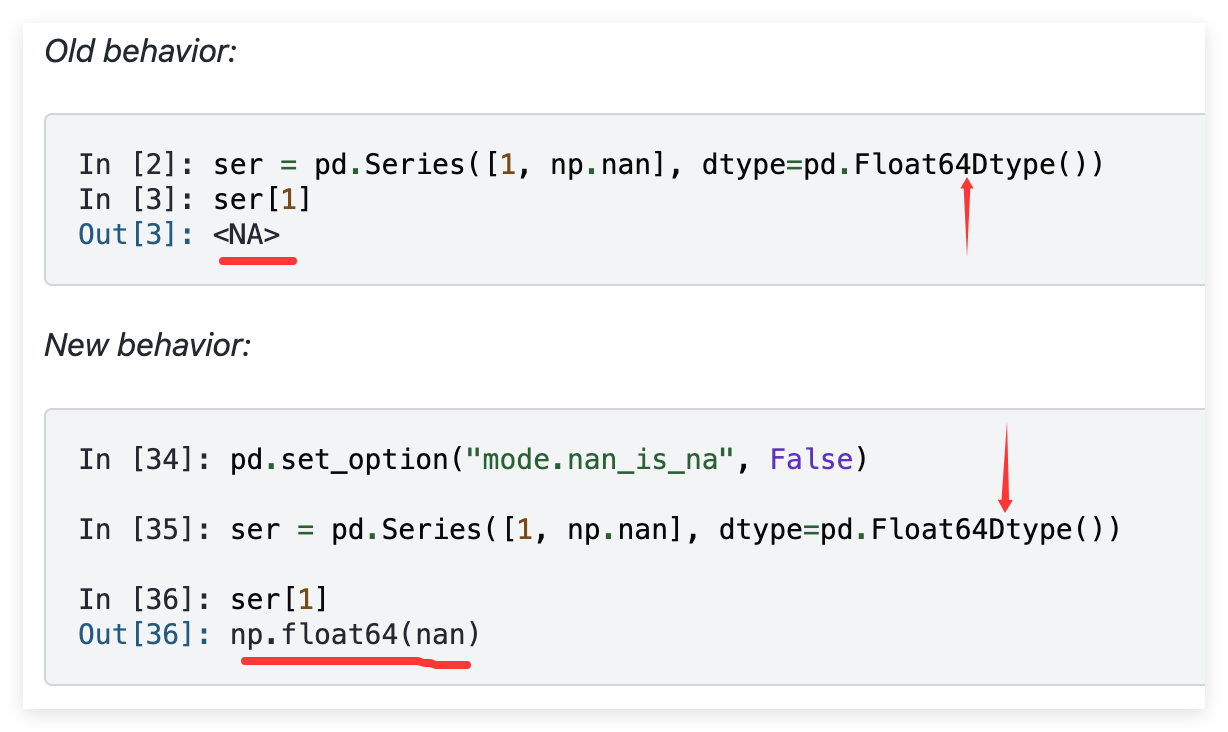
目的:提升缺失值处理在可空数据类型中的一致性和可预测性。
pd.col语法
现在,可以在 DataFrame.assign()和 DataFrame.loc()中使用 pd.col语法来创建可在相应方法中使用的可调用对象。
例如,对于一个名为 df的 DataFrame,需要对a和b列求和:

优化分组操作groupby
在 pandas 的分组操作中,对于 observed=False时的行为得到了改进。此改进修复了多个与未观测组处理相关的错误(例如,函数接收到空数据或全为0的输入)。

此次优化旨在使 observed参数的行为更加一致和符合直觉。
优化后影响一大波groupby相关方法:

优化其它
pandas 3.0除了以上优化,还包含了大量针对API、性能、IO操作和类型系统的增强,请参考官网。
**再次温馨提示:**是否要升级到 pandas 3.0 是一个需要仔细权衡的决定。这个版本引入了一些激动人心的性能改进,但也包含了一些破坏性变更,可能会影响现有代码的正常运行。
更多变化参考pandas官网。