PPT第一章:
C/S结构:使用局域网。客户端响应速度快,但可维护性差。
B/S结构:适用于广域网环境。应用程序及数据库系统都安装在服务器上,客户端只需安装一个浏览器软件。处理功能都运行在服务器端。维护方便,但服务器负担重。
两层架构:用户------表示逻辑层------数据库层
三层架构:用户------表示逻辑层------商务逻辑层------数据库层
N层架构:用户------表示逻辑层------商务逻辑层------服务层------数据库层
.NET FRAMEWORK主要包括CLR(Common Language Runtime,公共语言运行时),还有.NET FRAMEWORK类库。
PPT第二章 ASP.NET基础:
静态页面:纯HTML格式的网页通常被称为静态页面。以.htm、.html、.shtml、.xml等常见形式为后缀。
动态页面:以.asp、.aspx、.jsp、.php、.perl、.cgi等形式为后缀,语言使用HTML+ASP(ASP.NET) 或 HTML+PHP 或 HTML+JSP 等。
两者区别:
1).更新和维护
静态网页内容一经发布到网站服务器上,无论是否有用户访问,这些网页内容都是保存在网站服务器上的。如果要修改网页的内容,就必须修改其源文件,然后重新上传到服务器上。静态网页没有数据库的支持,当网站信息量很大的时候网页的制作和维护都很困难。
动态网页可以根据不同的用户请求,时间或者环境的需求动态的生成不同的网页内容,并且动态网页一般以数据库技术为基础,可以大大降低网站维护的工作量。
**2)**交互性
静态网页由于很多内容都是固定的,在功能方面有很大的限制,所以交互性较差。
动态网页则可以实现更多的功能,如用户的登录、注册、查询等。
**3)**响应速度
静态网页内容相对固定,容易被搜索引擎检索,且不需要连接数据库,因此响应速度较快。
动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器才返回一个完整的网页,其中涉及到数据的连接访问和查询等一系列过程,所以响应速度相对较慢。
.html文件:.html文件由HTML元素构成,HTML元素可以使用HTML语言或者XHTML语言,后者相比前者语法更加严格。HTML语言称为超文本标记语言,利用标记标识信息,一个标记称为一个元素,每个标记都用一对<>括起。HTML语言是解释型语言,不需要经过编译。
一个有效的HTML文档通常包括三大部分:版本信息,说明性HTML标题(HEAD),文档主体。
<head> </head>是所有头部元素的容器,包含文档信息
<titile>我的个人主页</titile>:定义文档标题,是<head>中必须包含的元素。
<meta>是空元素,空元素不需要像<titile>我的个人主页</titile>那样包裹中间的文本,也不需要</titile>那样的闭合。
<meta charset="UTF-8">:告诉浏览器网页用什么语言编码写成。
<meta content=...>:content属性不能单独使用,必须配合name或者http-equiv一起出现,它是meta标签里的值。
<meta name="description" content="这是一个网页">:name是content的搭档,用来定义元数据的类型。它告诉浏览器,我现在要描述网页的哪个方面。
name="description"是网页的简介,name="keywords"是网页的关键词,content此时应等于"关键词1,关键词2,关键词3"。
http-equiv:也是content的搭档,直接给浏览器发令,告浏览器如何处理页面。
3s后自动跳转:<meta http-equiv="refresh" content="3;url=https://www.baidu.com">。
文档主体(body):文档主体是html文档的主要部分,包含实际的文档内容。在<body></body>之间的内容将显示在浏览器窗口的用户区内。
HTML表单:HTML表单包含了表单内部控件和相应的布局信息。HTML表单是在Web页中的<form>和</form>标记之间定义的控件组,用于让用户输入数据并提交。例如:
html
<form method="post" action ="page.html">
输入您的用户名:
<input type="text" name="username">
<input type="submit" name="ok" value="提交" >
</form>其中action告诉浏览器把数据发给哪个服务器地址(URL),method设定发送方式。如果没有<form>包装控件,那么浏览器不知道讲数据发往何处。
Web表单:Web表单中则包含了表单内部控件、相应的布局信息及数据提交后的数据处理代码。在HTML文档中,控件可以独立存在,也可以有多个表单,但在ASP.NET中,只能有一个Web表单,且所有控件都必须位于表单之中。
html
<form runat="server">
......
</form>加上runat="server"会让ASP.NET在生成HTML时自动填好action和method。并且ASP.NET会将数据都提交回当前页面自己,由服务器端的C#代码来判断刚才到底是谁点了什么。
注:没带runat="server"的是静态元素,直接发给浏览器,带了runat="server"的是服务器控件,服务器会处理它,把它翻译成HTML。
在.aspx中,虽然我们写的是web表单,但是最终还是由web表单生成html表单。html表单是浏览器唯一能理解的数据提交方式。
ASP开发模式:ASP.NET Web Forms,ASP.NET MVC,ASP.NET Core。
.aspx网页文件格式:一般包含三个独立的部分,页面指令,代码脚本块,页面内容。
页面指令:核心元素是@指令(最常见的是@Page,该指令用于定义ASP.NET页分析器和编译器使用的页特定属性,只能包含在.aspx文件中;还有@Import指令,该指令可将命名控件显式导入到ASP.NET应用程序文件中,导入的命名控件可以是.NET Framework类库或用户定义的命名空间的一部分,该指令语法形式如<%@ Import Namespace="value"%>),不显示给用户看,而是给ASP.NET编译器看。一般写的时候写为<%@ ... %>,%是服务器端界定符,表示其中的内容不是普通的html文字,而是服务器需要执行的代码或指令。@则是指令标记。虽然指令可以位于.aspx文件中的任何位置,但是通常情况下将指令放在文件的开头。每个指令都可以包含一个或者多个属性,它们与相应的值成对出现。
html
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm1.aspx.cs" Inherits="WebApplication1.WebForm1" %>Language="C#"指定了语言,CodeBehind告诉服务器逻辑代码在哪个文件中。
代码脚本块:这部分包含具体的程序代码,根据运行位置不同,分为两类。
一类是服务器端脚本<script runat=server>,在服务器端运行,通常是C#代码。
另一类是客户端脚本<script type="text/javascript">,处理不需要请求服务器就能完成的动作,就是普通的HTML<script>标签。
页面内容:这是用户在浏览器中真正能看到的部分,也就是<html><body>标签力的内容,它由静态网页元素和服务器空间组成。如果页面包含允许用户交互并提交的控件,则该页面必须包含一个form元素。form元素必须包含runat属性,其属性值设置为server。
注:服务器代码可以选择代码隐藏或者代码内嵌,代码隐藏就是将代码单独放在.aspx.cs文件中,它们通过@Page指令中的CodeBehind属性连接在一起。代码内嵌就是将代码放在上面提到过的<script runat="server"> ... </script>标签中,它会直接把C#代码放在.aspx文件中。
举个例子:
html
<%-- 页面指令放在第一行 --%>
<%@ Page Language="C#" %>
<%-- 版本信息 --%>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<script runat="server">
<%-- 代码脚本块 --%>
</script>
<html xmlns="http://www.w3.org/1999/xhtml" >
<%-- 页面内容 --%>
<%-- head --%>
<head runat="server">
<title>无标题页</title>
</head>
<%-- 文档主体 --%>
<body>
<form id="form1" runat="server">
<div>
</div>
</form>
</body>
</html>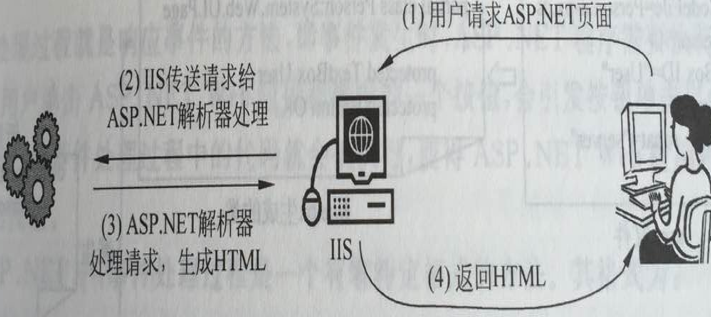
ASP.NET编译过程
单文件模型:aspx文件------生成C#新类------生成页面
代码隐藏页模型的页面运行机制:aspx文件------由从aspx生成的类和aspx.cs文件------组合生成一个新的类------生成页面
ppt第三章 C#基础:
C#本身无类库,而是直接使用.NET框架所提供的类库。C#不推荐使用指针,若要使用指针,必须使用关键字unsafe将代码声明为非安全的。C#采用垃圾回收机制,能够在合适时机回收不再使用的内存资源。
隐式using指令:编译器根据项目类型自动把最常用的命名空间引用了。
全局using指令:只需在一个文件写一次global using MyNamespace,项目力所有其他.cs文件都对自动包含这个命名空间,不用再重复写了。
Console.Writeline(string s);
string s=Console.Readline();
访问修饰符:
internal:允许同一程序集(.dll或者.exe)中的应用程序可以访问。
public:任何程序集都可以访问。
protected:允许跨越程序集,但仅限于继承关系。
protected internal:允许同一程序集中的应用程序可以访问、所属类或派生类中能被访问。
readonly:只读变量,初始化后不能修改。和const的区别在于readonly是访问修饰符,而const只是变量修饰符。
整数类型:
sbyte,有符号八位整数 byte,无符号八位整数
short,有符号十六位整数 ushort,无符号十六位整数
int uint
long ulong
object类型:object类型是System.Object类的别名。object类型是所有类型的基类,object类型的变量可以引用任何类型的数据。当我们把值类型赋值给object时,会发生装箱,系统会在堆上分配一块新内存,将栈上的值复制到堆上的这块新内存中,object变量存储的是堆上这块内存的地址。当把object还原回值类型时,系统检查object指向的堆内存中是否真的包含对应值类型的数据,如果匹配,就把堆上的值复制回栈上的变量。
string类型:是System.String类型的别名,实质是一种字符数组。使用ToString()可以转换为string类型,使用Parse()或者Convert类的相应方法可以转换为其他类型。
面向对象编程的优点:程序可维护性好;对象可以多次使用,可重用性好。
base:用于从派生类中访问基类成员,常用于在子类构造函数中初始化基类------base(a),可以用base直接指代基类,或者调用基类中已经被重写的成员。
可空类型:C#中,引用类型天生就是null,但值类型绝对不能是null。我们在值类型后可以加上?,这样int? b=null; 就可以正确运行了。T?本质上是System.Nullable<T>结构的语法糖,上面的代码等价于System.Nullable<int> b = 10; 。Nullable<T>提供两个核心属性,bool HasValue()和T Value()。前一个用于判断是否有值,后一个用于获取具体的值。
和可空类型相关的两个运算符:空条件运算符?.和空合并运算符??。?.用于安全访问,虽然主要用于引用类型,但也常用于可空类型。当使用?.访问成员时,如果实例本身为null,就立刻停止直接返回null。空合并运算符??的含义是如果左边为null,就用右边的值,否则用左边的值。
set和get访问器:在类内声明属性如public int Age{ get; set; }时,可以以这样的方式声明get和set访问器,访问器不能被显式调用,当我们试图对Age赋值时,隐式调用set,当我们试图对Age取值时,隐式调用get。
完整属性:我们需要在get,set里写额外的逻辑。
自动属性:如public string Name { get; set; }。这是C#的语法糖,如果不需要额外的逻辑,C#可以自动生成一个私有字段
只读属性:代码如下,对于外部来说,使用Id属性就像使用一个字段一样。属性的取值和赋值逻辑由get和set的逻辑决定。
cs
private int _id; // 显式声明的私有字段
public int Id
{
get { return _id; }
// 没有 set
}计算属性:没有对应的存储字段,值依赖实时计算,代码如下:
cs
public class Rectangle
{
public double Width { get; set; }
public double Height { get; set; }
// 【计算属性】Area
// 它不存数据,它是算出来的
public double Area
{
get
{
return Width * Height;
}
}
// 使用 Lambda 表达式简写计算属性(更常见)
public double Perimeter => (Width + Height) * 2;
}字段:本质上就是类内变量。属性本质上就是包含get和set方法的代码块,对外提供访问数据的接口,可以在赋值或读取时加入逻辑控制。前者一般定义为private,后者一般定义为public。
多态:使用virtual和override可以实现真正的多态。在子类中使用new关键字修饰方法会隐藏父类中的同名方法。
抽象类和接口:抽象类abstract class不是完整的,但可以有普通方法和字段。接口interface只能有方法声明,但不能有方法定义,也不能有字段。两者都不能直接实例化,都只能使用继承自它们的子类。abstract修饰方法时,父类不能实现该方法,子类必须自己实现该方法。但virtual修饰方法时父类可以自己实现该方法,子类可以选择使用父类的版本或者是自己的版本。如果一个类包含任何一个抽象方法(abstract method),那么这个类必须被定义为抽象类。
sealed关键字:sealed用于修饰类,表明该类不能被继承,sealed修饰方法,表明在子类中该方法不能被重写,只能使用当前版本的方法。
static class:静态类只有静态成员,静态类不能被实例化。
partial class:分部类允许将同一个类的代码拆分在多个不同文件中,编译器在编译时会把这些碎片自动拼在一起。
泛型类:如class Name<T>{}; 其实就是模板,但换了一种语法。
ppt第四章:ASP.NET编程概念详解。
我们在visual studio写的代码(.aspx和.cs后台代码)是服务器端代码,浏览器是看不懂这些代码的。运行流程为:浏览器发起请求------服务器运行你的代码------服务器将运行结果翻译成标准的HTML------发送给浏览器。
回发机制:用户输入网址,服务器生成页面给用户后。当你在页面上点击按钮(提交信息)时,表单数据会被发送给同一个页面(也就是服务器上的自己),服务器接收到数据之后,重新运行这个页面的代码,处理你的逻辑。处理完后,服务器再次生成新的HTML发回给浏览器。
HTTP(Hyper Text Transfer Protocol,超文本传输协议):特点有
1.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2.灵活:HTTP允许传输任意类型的数据对象。正在传输的数据由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后马上断开连接。采用这种方式可以节省服务器的资源。
4.无状态:web服务器在生成html并完成发送后,会马上断开连接,并销毁服务器内存中的这个网页对象实例。当你在网页中点击按钮时,服务器会重新创建一个全新的页面对象,它根本不知道上一个对象中存了什么数据,这就是无状态。因此,ASP.NET会把所有状态打包成加密字符串(即视图状态),并藏在HTML中,以让无状态的HTTP协议看上去能够记忆状态。
HTTP方法特性:HttpGet和HttpPost特性规定了该方法只接待哪种类型的HTTP请求。我们常常写两个名字一摸一样的方法,但是处理不同的逻辑,这两个标签就是用来区分它们的。HttpGet用来告诉服务器只有当浏览器发送GET请求时,才运行这个方法。HttpPost告诉服务器只有当浏览器提交数据(Post请求)时,才运行这个方法。
public class AccountController : Controller
{
// 场景1:用户仅仅是输入网址想看登录页面
// 浏览器发起的是 GET 请求 -> 只有贴了 [HttpGet] 的方法会响应
[HttpGet]
public ActionResult Login()
{
return View(); // 返回包含空表单的 HTML
}
// 场景2:用户填好了用户名密码,点击了"登录"按钮
// 浏览器发起的是 POST 请求 -> 只有贴了 [HttpPost] 的方法会响应
[HttpPost]
public ActionResult Login(string username, string password)
{
// 这里写验证逻辑,查数据库等
if (CheckUser(username, password))
{
return RedirectToAction("Index");
}
return View();
}
}依赖注入(DI):依赖注入就是不要在类中用new创建对象,而是留个接口,让系统把对象传过来。示例如下:
cs
// 【接口】 定义合同:只要是工具,必须能干活
public interface ITool
{
string Work();
}
// 【实现】 具体的工具:这是一把锤子
public class Hammer : ITool
{
public string Work() => "🔨 锤子咣咣砸!";
}builder.Service负责告诉容器,当有人要某个接口时,该给他创建什么具体的类,以及这个类的寿命有多长。常用的有三种方法,分别是AddTransient,AddScoped,AddSingleton。
AddTransient是每次找容器要的时候,都给你用new创建一个全新的对象。
AddScoped是在一个HTTP请求的处理过程中(从浏览器请求到服务器返回),不管你在这个请求中用了多少次这个服务,拿到的都是同一个对象。请求结束,对象销毁。
AddSingleton:整个应用程序启动后,只创建一个对象。以后所有人,所有请求来拿,都是同一个。
cs
// ============== Program.cs (启动文件) ==============
var builder = WebApplication.CreateBuilder(args);
// 【Step A: 注册】 (AddTransient / AddScoped / AddSingleton)
// 告诉容器:如果有人要 "ITool",就给他一个新的 "Hammer"
builder.Services.AddTransient<ITool, Hammer>();
builder.Services.AddControllers();
var app = builder.Build();
app.MapControllers();
app.Run();此时,类接受的是接口。并且该服务类通过构造函数注入。
cs
// ============== WorkerController.cs (使用者) ==============
[Route("/")]
public class WorkerController : ControllerBase
{
private readonly ITool _tool;
// 【Step B: 构造函数注入】
// 并没有写 new Hammer(),而是直接要在构造函数里"我们要一个工具"
public WorkerController(ITool tool)
{
_tool = tool; // 容器会自动把 Hammer 传进来
}
[HttpGet]
public string DoJob()
{
return _tool.Work(); // 输出:"🔨 锤子咣咣砸!"
}
}FromServices特性:如果你有一个很大的服务,但在WorkController的10个方法中,只有一个方法用到了它。如果使用构造函数注入的话,每次创建Controller都要初始化这个大服务,即使很少用到它。因此,我们可以使用FromServices只在具体方法中临时申请该服务。
cs
public class ReportController : Controller
{
// 注意:构造函数里没有 IBigService
// 只在这个方法里临时请求注入
public IActionResult Download([FromServices] IBigService bigService)
{
bigService.Run();
return Ok();
}
}如果你的服务自身参数也包含另一个服务,同样通过构造函数注入。我们只需要在builder.Services中add对应的服务,容器会自动完成组装。
如果服务参数是具体的值,需要使用lambda表达式来手动告诉容器如何创建。
cs
public class Hammer : ITool
{
private string _name;
public Hammer(string name)
{
_name = name;
}
}
// ============== Program.cs ==============
// 这里的写法变了:
// 我们不只是给个类名,而是给了一个"小函数"告诉容器怎么 new
builder.Services.AddTransient<ITool>(provider =>
{
// 在这里,你可以手动传参
return new Hammer("雷神");
});DI的好处在于页面或控制器不需要直到具体的类是谁,只需要知道接口。修改具体实现代码时,不需要改动页面代码。你不需要手动用new创建对象,也不需要手动销毁,容器会帮你管理内存。如果一个类的构造函数中注入了太多东西,说明它管得太宽了,违反了单一职责原则。
C#中数据结构的实现:
| 集合类型 | 添加元素 | 删除并返回 | 获取但不删除 | 数量属性 |
|---|---|---|---|---|
| List<T> | Add(item) |
Remove(item) / RemoveAt(index) |
list[index] |
Count |
| Dictionary<K,V> | Add(key, value) |
Remove(key) |
dict[key] |
Count |
| HashSet<T> | Add(item) |
Remove(item) |
(无索引,只能判断存在) | Count |
| Queue<T> (队列) | Enqueue(item) |
Dequeue() |
Peek() |
Count |
| Stack<T> (栈) | Push(item) |
Pop() |
Peek() |
Count |
所有集合清空都使用Clear(),包含判断都使用Contains(item),计数都使用Count属性(Array使用Length)。
注意:1.Queue使用Enqueue()和Dequeue()方法,Stack使用Push()和Pop()方法,它们都是用Peek()来查看队首/栈顶元素。
2.Dictionary的Add需要两个参数(Key和Value)。
LINQ:提供统一的查询语法、支持筛选/排序/投影、延迟执行、简化代码。
方法语法和查询语法:
| 特性 | 查询语法 (Query Syntax) | 方法语法 (Method Syntax) |
|---|---|---|
| 外形 | 类似 SQL 语句 | 标准的 C# 方法调用 |
| 核心组件 | 关键字 (from, where, select) |
Lambda 表达式 (n => n > 10) |
| 可读性 | 在处理 多表连接 (Join) 或 分组 (Group) 时,非常清晰易读 | 在处理 简单筛选 或 链式调用 时,非常简洁 |
| 完整性 | 不完整 (有些功能没有对应的关键字) | 完整 (包含了 LINQ 的所有功能) |
| 本质 | 它是语法糖,最终转换为方法语法 | 它是编译器真正认识的代码 |
方法语法:
cs
IEnumerable<int> firstAndLastFive = numbers.Take(5).Concat(numbers.TakeLast(5));在C#中,只要实现了IEnumerable<T>接口,那么就可以被视作序列处理。序列可以使用LINQ查询。
常用操作符:
Where:作用是筛选出符合条件的元素,例如:
cs
// 找出所有及格(分数大于60)的学生
var pass = students.Where(s => s.Score >= 60);Select:作用是只拿出想要的部分,例如:
cs
// 1. 只想要学生的名字 (变成 List<string>)
var names = students.Select(s => s.Name);
// 2. 想要名字和分数 (变成一个新的匿名对象)
var infos = students.Select(s => new { s.Name, s.Score });OrderBy:从小到大排序,OrderByDescending,从大到小排序。例如:
cs
// 按分数从高到低排
var ranking = students.OrderByDescending(s => s.Score);GroupBy:归类,把一堆数据切分成好几堆。例如:
cs
// 按班级分组
var groups = students.GroupBy(s => s.ClassId);
foreach(var group in groups)
{
Console.WriteLine($"班级ID: {group.Key}"); // 组的钥匙
foreach(var s in group) { ... } // 组里的学生
}GroupBy最终得到的序列可以说是一个由链表实现的哈希表结构。
cs
var result = students
.GroupBy(s => s.ClassId) // 1. 先分成几个袋子
.Select(g => new // 2. 针对每个"袋子(g)"进行统计
{
BanJi = g.Key, // 拿标签(几班)
RenShu = g.Count(), // 数袋子里有几个元素
PingJunFen = g.Average(s => s.Score) // 算袋子里分数的平均值
});上面代码中Select处理的单位是组,也就是Key相同的元素组成的链表。然后筛选出链表的Key,链表的Count,以及链表中元素的平均值作为匿名类型元素的成员,组成新的序列。
注:var infos = students.Select(s => new { s.Name, s.Score });中序列元素如果不提供名字的话,就沿用之前的名字Name和Score。
Join:连接,把两个集合按某个共同属性拼在一起,例如:
cs
// students.Join(目标集合, 自己的外键, 对方的主键, 结果生成器)
var result = students.Join(
classes, // 1. 跟谁连?(班级表)
s => s.ClassId, // 2. 我用什么连?(我的ClassId)
c => c.Id, // 3. 对方用什么连?(它的Id)
(s, c) => new { s.Name, c.ClassName } // 4. 连好后你要啥?(学生名+班级名)
);注:在LINQ中操作序列时,想要得到序列中元素数量不能直接使用Count属性,应该使用Count方法!
注:C#中new {}表示创建匿名类型,即编译器生成的临时类(只读)。此时不能用new ()。
注:C#中{}没有构造的功能,大括号是初始化器,只负责设置属性。比如这几行代码:
.Select(g => new // 2. 针对每个"袋子(g)"进行统计
{
BanJi = g.Key, // 拿标签(几班)
RenShu = g.Count(), // 数袋子里有几个元素
PingJunFen = g.Average(s => s.Score) // 算袋子里分数的平均值
});
这里的new后面省略了(),实际上应该是new () { BanJi=...... },()负责构造,大括号只是相当于语法糖的东西,功能为赋值。
聚合函数:
| 函数 | 含义 | 示例代码 | 备注 |
|---|---|---|---|
| Count | 数人头 | students.Count() students.Count(s => s.Score > 60) |
括号里可以加条件,一边过滤一边数 |
| Sum | 求和 | students.Sum(s => s.Score) |
必须告诉它把哪个属性加起来 |
| Average | 平均值 | students.Average(s => s.Score) |
算出所有学生的平均分 |
| Max | 最大值 | students.Max(s => s.Score) |
最高的那个分数是多少 |
| Min | 最小值 | students.Min(s => s.Score) |
最低的那个分数是多少 |
EF Core:EF Core是由微软推出的轻量级,跨平台的ORM(Object-Relational Mapper)框架。Object是C#代码中的类,Relational指数据库中的表。Mapper负责将这两者对应起来。没有EF Core之前,需要手写SQL语句,有了EF Core之后,只需要操纵C#对象,EF Core自动帮你生成SQL并执行。
持久化:将数据保存下来,使其在程序重启后依然存在。
实体类(Entity Classes):实体类是EF Core中最基础的单元。它们只是普通的C#类,用于定义数据的结构。这里类对应数据库的表,属性对应表中的列,类的实例对应表中的一行数据。值得注意的是,EF Core依靠约定。例如,名为Id的属性会自动被识别为数据库的主键。
DbSet<T>属性:DbSet<T>是DbContext类中的属性,它表示数据库中某个特定表的所有行(实体)的集合。我们通过DbSet执行增删查改的操作。DbSet也是一个IQueryable,意味着可以用LINQ来写查询语句,EF Core会把这些C#代码翻译成SQL语句。
注:IQueryable继承自IEnumerable,如果数据已经在内存里了,使用IEnumerable,如果数据还在数据库里,一定保持IQueryable状态直到过滤完成。
DbContext类:负责协调实体对象和数据库之间的交互。主要职责包括:
-
数据库连接:配置连接字符串,决定连哪个数据库(SQL Server, SQLite, MySQL 等)。
-
配置模型 :通过
OnModelCreating方法,你可以通过代码详细配置表与表之间的关系(Fluent API)。 -
变更追踪 (Change Tracking) :这是它最神奇的地方。它是"有记忆"的。当你从
DbSet取出一个对象并修改了属性,DbContext会默默记下"这个对象变了"。-
保存数据 :当你调用
SaveChanges()时,DbContext会把所有记下来的变更打包成 SQL 事务,一次性提交给数据库。csusing Microsoft.EntityFrameworkCore; // 1. 实体类定义 (货物) public class Student { public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } } // 2. DbContext 类 (仓库管理员) public class SchoolContext : DbContext { // 3. DbSet 属性 (货架) // 告诉 EF Core:数据库里有一张表叫 Students,存的是 Student 类型的数据 public DbSet<Student> Students { get; set; } // 配置数据库连接 protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) { // 这里使用简单的 SQLite 数据库作为示例 optionsBuilder.UseSqlite("Data Source=school.db"); } } // --- 实际使用场景 --- class Program { static void Main() { // 创建上下文实例 (开启会话),using(var context...)会确保在离开大括号后自动销毁context using (var context = new SchoolContext()) { // 确保数据库已创建 context.Database.EnsureCreated(); // 创建一个实体对象 var newStudent = new Student { Name = "Gemini", Age = 1 }; // 通过 DbSet 添加数据 context.Students.Add(newStudent); // 通过 DbContext 保存更改 // 此时 EF Core 会生成: INSERT INTO Students (Name, Age) VALUES ('Gemini', 1); context.SaveChanges(); } } }
-
关系配置
主键:当前表中每行数据的唯一标识,是一个整数值。
外键:用于在另一张表中进行索引,是另一张表中的主键。
导航属性:它是一个对象引用,或者说,它是数据库中一行数据的引用。通过使用导航属性,我们不需要通过外键在SQL中去查找对应的数据(或者说,我们不需要写那样繁琐的代码),我们可以直接通过对象引用来获取该对象的属性,EF Core会自动完成对应的查找工作。
一对多关系:比如一个班级有多个学生,但是一个学生只属于一个班级。我们需要在两头都写上代码:在一的一端(班级),加上一个列表List<Student>,在多的一端(学生)加上一个引用Class和一个外键ClassId。外键的命名规范为"导航属性名+Id"。
注:这里即使不加上属性ClassId,EF Core也会在后台生成一个隐藏的外键。之所以加上这个外键,是为了编程方便。而一的那方之所以不存外键数组是因为SQL的一个格子只能存一个值,不能存数组或列表。
cs
// "一" 的一方:班级
public class Class
{
public Class{
Students=new HashSet<Student>();
}
public int Id { get; set; }
public string ClassName { get; set; }
// 导航属性:一个班级包含"很多"学生
// List<T> 表示这里有很多个
public ICollection<Student> Students { get; set; }
}
// "多" 的一方:学生
public class Student
{
public int Id { get; set; }
public string Name { get; set; }
// 1. 外键 (Foreign Key):数据库里实际存的那一列
// 命名规范:[导航属性名] + Id
public int ClassId { get; set; }
// 2. 导航属性 (Navigation Property):
// 允许你通过 student.MyClass 直接访问班级对象
public Class MyClass { get; set; }
}注:ICollection继承自IEnumerable,不同于IEnumerable只能读,ICollection定义了标准集合应该有的功能,Add,Remove,Clear,Count。
注:List<Student> 是一个 C# 内存中 的容器,它保存了一组 引用 (References)。 在EF Core的帮助下,操作这些引用间接操作了数据库对应的行。EF Core为了性能,绝对不会去填充这个List,它是空的。虽然List为空,但是其实这时候表与表之间的映射关系已经建立。它们之间的匹配关系为Class.Id=Student.ClassId。想要填充List(填充List就是在建立表与表的关系),需要自己手动进行。
cs
var myClass = context.Classes
.Include(c => c.Students) // <--- 下令:填充 List!
.FirstOrDefault(c => c.Id == 1);Include的作用是修改表达式树,告诉SQL生成器之后需要把关联表中符合匹配条件的行防止在List中。它是延迟执行的方法。
FirstOrDefault的作用是查找结果中符合条件的第一条,或者返回默认值。它会按照Include修改后的条件去进行查找并将结果填充到List中。
多对多关系:例如学生和课程之间的关系,学生可以选多门课,一门课也可以被多个学生选。
cs
public class Student
{
public int Id { get; set; }
public string Name { get; set; }
// 我选了很多课
public List<Course> Courses { get; set; }
}
public class Course
{
public int Id { get; set; }
public string Title { get; set; }
// 我有很多学生
public List<Student> Students { get; set; }
}隐含着匹配关系:
对于CourseA元素的Students列表中所有Student元素,你都可以在它的List<Course>中找到某个CourseB的Id,它的Id等于CourseA的Id。
对于StudentA元素的Courses列表中所有Course元素,你都可以在它的List<Student>中找到某个StudentB的Id,它的Id等于StudentA的Id。
一切匹配关系都依赖主键和外键之间的匹配。
EF Core中的查询操作
LINQ to Entities:它是一种技术,允许你使用C#语法(LINQ)来编写查询,然后由EF Core自动将其翻译成数据库能听懂的SQL语句。它是连接面向对象代码(C#)和关系型数据库(SQL)的桥梁。
| 特性 | LINQ to Objects | LINQ to Entities |
|---|---|---|
| 操作对象 | 内存中的集合 (List, Array) |
数据库中的表 (DbSet) |
| 接口 | IEnumerable<T> |
IQueryable<T> |
| 执行逻辑 | 直接运行 C# 代码 (委托 Delegate) | 解析表达式树,翻译成 SQL |
| 能力限制 | 能用所有 C# 方法 | 只能用能翻译成 SQL 的方法 |
延迟执行:在EF Core中,查询分为两个完全割裂的阶段------构建阶段和执行阶段。在构建阶段,当你调用如Where,Select时,会返回IQueryable<T>。此时EF Core只是在内存中修改表达式树,但没有生成SQL,也没有连接数据库。在执行阶段,当我们调用ToList,Count,FirstOrDefault时,返回具体的List<T>,int,bool对象,此时会将表达式树翻译成SQL,发送给数据库,并把返回的数据转换成对象。
延迟执行允许我们在C#逻辑中动态组装SQL,而不用担心性能浪费。
| 类型 | 方法举例 | 返回值 | 行为 |
|---|---|---|---|
| 延迟执行方法 (Deferred) | Where OrderBy Select Skip / Take Include GroupBy Join |
IQueryable<T> |
只修改表达式树。 不查数据库。 |
| 立即执行方法 (Immediate) | 转换类 :ToList, ToArray, ToDictionary 单值类 :First, Single, Find 统计类 :Count, Any, All, Sum 遍历 :foreach |
List, int, bool, Entity |
编译 SQL 并发送。 立马查数据库。 |
延迟加载和立即加载:立即加载就是使用.Include()在查询主数据时就查询关联数据,而延迟加载则是在查询主数据完成后,访问关联数据时才自动完成对关联数据的查询。前者查询完成后,访问速度快,但在关联数据较多时容易耗尽内存,后者内存使用量更小,但在查询次数过多时性能显著下降。
增删查改和SaveChanges方法:新增对象用Add,删除对象用Remove。
SaveChanges():在你调用这个方法之前,所有的Add,Remove等操作,全都是在内存中进行,数据库中一行数据都没变。当你调用context.SaveChanges()时,EF Core会检测变化,根据状态生成对应的SQL语句,然后进行批处理。接着数据库执行SQL,如果执行成功,数据库进行回填。
注:当我们用new创建一个元素时,Id通常默认值为0,大多数数据库的主键被设定为自增,只有数据库有权力知道下一个Id是多少,因此最后需要数据库回填。还有其他的一些东西也需要数据库回填,但不再介绍。
事务处理:数据库事务是指作为单个逻辑工作单元执行的一系列操作。事务必须满足原子性。举个例子,如果事务中包含操作A和操作B,假如操作A执行成功,操作B执行失败,那么将会把操作A撤销,回到完全没有执行过事务的状态。当你调用EF Core时,通常不需要写任何事务代码,EF Core默认帮你完成。当你调用一次SaveChanges()时,EF Core会自动把它生成的所有SQL语句包裹在一个事务中。
有时可能需要显式事务,代码如下:
cs
// 1. 手动开启事务
using var transaction = context.Database.BeginTransaction();
try
{
// --- 第一步:保存订单 ---
context.Orders.Add(newOrder);
context.SaveChanges(); // SQL 已执行,但数据只是"暂存"在数据库,别人还看不见
// --- 第二步:做点别的 (比如再保存日志) ---
// 假设这里可能通过 context2 或者原生 SQL 操作
context.Logs.Add(newLog);
context.SaveChanges();
// --- 第三步:甚至可能有复杂的 C# 逻辑 ---
if (someCondition == false)
throw new Exception("业务检查失败!");
// 4. 只有运行到这里,才算真正成功!
transaction.Commit(); // 【提交】:让所有改变永久生效
}
catch (Exception)
{
// 5. 如果上面任何一行报错,跳到这里
transaction.Rollback(); // 【回滚】:撤销上面所有的 SaveChanges
// (注:使用 using 块时,如果没有 Commit,退出时会自动 Rollback,但这行写出来更清晰)
}连接字符串:如果说DbContext是仓库管理员,那么连接字符串就是记录仓库位置的纸条,没有它,EF Core根本找不到数据库在哪。
EF Core使用连接字符串主要有两种方式:
A.直接把连接字符串写死在OnConfiguring方法中。
B.把连接字符串放在appsettings.json文件里。
线程和异步编程
线程基础:Thread类,必须手动定义一个方法(委托),然后把它交给线程运行。
cs
void DoWork() { Console.WriteLine("工作线程正在运行..."); }
Thread t = new Thread(DoWork); // 1. 创建
t.Start(); // 2. 启动(此时线程进入 Ready 状态,等待 CPU 调度)线程状态与生命周期:线程的状态有:
Unstarted:new Thread()创立线程之后,Start()之前。
Running:正在被CPU执行,或者准备好被执行。
WaitSleepJoin(阻塞/等待):这是最常见的非运行状态,线程因为某些原因(如Sleep,Join,等待锁释放)暂停,不占用CPU资源。
Stopped:方法执行完毕,线程销毁,不可复活。
关键方法:Thread.Sleep(int ms),让当前线程睡眠指定毫秒数。哪怕设为0,也会触发一次CPU时间片的让出。
t.Join():如果在线程A中调用t.Join(),那么A会暂停,一直等到线程t执行结束,A才会继续往下走。
线程同步:当多个线程同时访问同一个资源时,如果不加控制,数据就会乱套。我们需要锁来保证同一时间只有一个线程能访问关键代码。
A.lock关键字
cs
// 最佳实践:定义一个私有的、只读的引用类型对象作为锁
private readonly object _lockObj = new object();
public void SafeMethod()
{
// 只有一个线程能进入这个花括号
lock (_lockObj)
{
// 临界区:在这里修改共享变量
// ...
}
}B.Monitor,lock实际上是编译器生成的语法糖,他编译后的代码就是Monitor。_lockObj是真正的锁,lockTaken只是记录是否抢到了锁,以应对极端情况下的Bug,防止未获取锁时释放锁。
cs
// lock 的真实面目
bool lockTaken = false;
try
{
Monitor.Enter(_lockObj, ref lockTaken); // 尝试获取锁
// 临界区代码
}
finally
{
if (lockTaken)
{
Monitor.Exit(_lockObj); // 确保无论是否报错,锁一定会被释放!
}
}C.lock和Monitor只能锁住同一个程序(进程)内的线程,如果想要锁住不同的程序,需要用到Mutex,Mutex是操作系统内核级别的对象,比较慢。
cs
// "GlobalMyappMutex" 是系统范围的名字
using var mutex = new Mutex(false, "GlobalMyappMutex");
if (!mutex.WaitOne(TimeSpan.FromSeconds(3)))
{
Console.WriteLine("另一个程序正在运行,我退出了");
return;
}
// 执行程序...
mutex.ReleaseMutex();new Mutex(false,"GlobalMyappMutex"):false表示创建锁时不急着占有锁,另一个参数是锁的名字,操作系统依赖这个名字区分是否为同一把锁。
WaitOne函数接受一个表示时间的参数t,返回布尔值。线程会在这里等待时间t,如果时间t内没有抢到锁就放弃,并返回false。
ReleaseMutex(),当然是释放锁。
任务并行库(TPL)
Task类与Task<TResult>类:Task是对线程的高级抽象。Task代表一个异步操作。当你创建一个Task类时,你并不是创建了一个新线程,你只是创建一个新的任务,并丢进线程池的队列里。Task会被自动分配给线程池中空闲的线程执行。Task完成后,线程不会销毁,而是等待下一个Task。
Task类型没有返回值,Task<TResult>类型有返回值。
cs
Task t = Task.Run(() => {
Console.WriteLine("我干完活了,但我没东西给你。");
});
t.Wait(); // 等待做完
cs
// 泛型 TResult 指定返回值的类型,这里是 int
Task<int> t = Task.Run(() => {
return 1 + 1;
});
// .Result 会阻塞当前线程,直到拿到结果
int result = t.Result;
Console.WriteLine(result); // 输出 2Task.Run()接受一个委托类型,用于启动任务。
Task.Factory.StartNew():Task.Run()是Task.Factory.StartNew()的简化封装版,后者是更加底层的构建起,允许配置非常复杂的参数。后者同样接受委托类型。
任务的取消:涉及到三个point。
1.CancellationTokenSource(指挥官)
2.CancellationToken:这是传递给Task的信物,Task只能看,不能修改他。
3.Task内部代码:必须不断地检查CancellationToken。
cs
// 1. 创建指挥官
var cts = new CancellationTokenSource();
// 获取令牌
var token = cts.Token;
Task t = Task.Run(() =>
{
for (int i = 0; i < 100; i++)
{
// 2. 执行者:每次循环都检查一下令牌
// 如果有人发出了 Cancel 信号,这行代码会抛出 OperationCanceledException 异常,结束任务
token.ThrowIfCancellationRequested();
// 或者温柔的写法:
// if (token.IsCancellationRequested) return;
Console.WriteLine($"工作进度: {i}%");
Thread.Sleep(100);
}
}, token); // 3. 把令牌传进去,让 Task 感知到它关联了这个令牌
// ... 过了 2 秒 ...
Console.WriteLine("不干了,取消!");
cts.Cancel(); // 4. 指挥官:按下停止按钮cts.Cancel只是把令牌上的一个布尔值属性IsCancellationRequested修改为true,所以仅限使用并检查该令牌的Task会被kill。
异步编程
async和await关键字:虽然Task本身的执行是异步的,但是当我们想要通过获取task.Result时,仍然会阻塞在这里。所以我们引入async和await。
async:async关键字告诉编译器,这个方法中有await,需要把该方法编译成一个状态机类,这个状态机负责记录所有变量和执行位置,以便线程被释放后,知道从哪里恢复。
await关键字:await关键字后接一个Task对象。当遇到await task时,会检查task对象是否完成,如果task未完成,await会将当前线程释放回线程池,并设置一个继续点,等到task完成后,运行时会从线程池中找一个线程,回到之前暂停的继续点继续执行await后面的代码。Task完成后,await task最终会返回Task<TResult>对象最后返回的值。
Task的创建有两种语法:一是Task.Run(),二是通过async Task<T>定义方法,这个方法的核心是非阻塞等待。当调用异步方法时,仍然在当前线程上执行该异步方法,就好像只是调用一个普通的方法一样。当在异步方法中遇到await时,方法状态被保存,异步方法返回一个尚未完成的Task给workerTask,Main线程得到控制权并继续执行下一行代码。
cs
using System;
using System.Threading.Tasks;
public class AsyncExample
{
// 标记方法为 async,允许在内部使用 await
public static async Task<int> DoWorkAsync(int delayMs)
{
Console.WriteLine($"\t[Task] 异步任务开始,等待 {delayMs/1000} 秒..."); // [A]
// 遇到 await:
// 1. 如果 Task.Delay 没完成,当前线程被释放回线程池。
// 2. Task.Delay 在后台计时。
await Task.Delay(delayMs); // [B]
Console.WriteLine("\t[Task] 异步任务等待结束,返回结果。"); // [C]
return 99; // 返回的结果会被自动封装在 Task<int> 中
}
// Main 方法也标记为 async Task (现代 C# 入口点)
public static async Task Main()
{
Console.WriteLine($"[{DateTime.Now.Second}s] 主线程开始工作..."); // [1]
// 调用异步方法,但尚未 await,返回一个 Task 对象
Task<int> workerTask = DoWorkAsync(3000); // [2]
// -----------------------------------------------------
// !!! 关键点 !!! -----------------------------------------
// -----------------------------------------------------
// 证明非阻塞:尽管 DoWorkAsync 正在等待 3 秒,主线程会立即执行这一行。
Console.WriteLine($"[{DateTime.Now.Second}s] 主线程继续执行其他任务..."); // [3]
// await 等待结果:
// 遇到 await,主线程暂停执行,直到 workerTask 完成。
int result = await workerTask; // [4]
Console.WriteLine($"[{DateTime.Now.Second}s] 主线程拿到结果:{result}"); // [5]
}
}异步方法和Main函数之间好像全程都只是共用一个线程,从这方面来讲,Main函数就好像在调用一个普通的函数一样。异步方法的价值在于当遇到await task时,如果task未完成,异步方法会返回一个Task,而不是阻塞在这里。接着会执行外层调用异步方法的函数,直到下一个阻塞点。
异步方法的返回值类型:异步方法可以返回Task<T>,Task,void三种类型。返回Task类型时的代码如下:
cs
public async Task SaveLogAsync()
{
await File.WriteAllTextAsync("log.txt", "...");
}
// 调用:我可以 await 它,确保它存完文件我再走
await SaveLogAsync();当返回void类型时,调用者无法使用await,因为await后面应该接task,因此调用者不知道异步方法何时结束,也无法等待异步方法结束。
ConfigureAwait(false):只有主线程(UI)线程有资格更新界面,await默认设定是在UI线程启动,就一定回到UI线程。ConfigureAwait(false)是在告诉编译器一会儿干完活之后,随便找个线程继续执行后面的代码就行,不用非得回到原来的UI线程。语法形式如下:
cs
await DoWorkAsync().ConfigureAwait(false);并发集合:
由于普通集合线程不安全,多线程同时读写容易导致内部结构损坏。因此在使用的时候必须用lock锁住整个集合,即使保证了安全,性能也是问题,所以,我们引入并发集合。
并发集合的特点是线程安全(不需要手写lock),且具有高性能(内部使用细粒度锁或无锁算法),允许多个线程同时读写,效率极高。
ConcurrentDictionary<TKey,TValue>:线程安全的哈希表。接口有GetOrAdd(key,value),AddOrupdate(key,addValue,updateFunc),后者如果没有就添加,有就调用updateFunc,适合做计数器。
BlockingCollection<T>:他不是一个单一的集合,而是一个包装器,默认包裹着ConcurrentQueue。调用Take取数据时,如果集合为空,会自动阻塞,直到有人放入数据被唤醒。放入数据时调用Add方法,我们在创建BlockingCollection时,可以提供一个参数表示容量上限,如果达到上限,Add会阻塞在这里,直到有人取走数据。可以通过使用它实现生产者-消费者模型。
ConcurrentQueue<T>和ConcurrentStack<T>:仍使用Push和Enqueue作为方法名,因为没有容量上限,默认这两个操作总是会成功的。而TryDequeue,TryPeek,TryPop方法有可能失败。
异常处理和调试
System.Exception基类:所有异常类型都必须继承自System.Exception类。它有三个最核心的属性:Message(string),用于描述错误的文字信息,是给人看的。StackTrace,栈堆跟踪,记录异常发生时的方法调用链。InnerException:内部异常,用于追根溯源。假如在方法A中捕获了一个异常 FileNotFoundException,然后包装成DatabaseLoadException 抛出去,新的异常的InnerException就会指向原始的FileNotFoundException。
ArgumentException:通用的参数错误。
InvalidOperationException:对象状态不对,比如在foreach循环遍历List时,试图Add或Remove它的元素。
FileNotFoundException:文件没有找到。
异常处理结构
try-catch-finally块:
cs
FileStream file = null;
try
{
// 1. 尝试执行
string content = File.ReadAllText("config.txt");
int num = int.Parse(content);
}
catch (FileNotFoundException ex) // 2. 精准捕获:文件找不到
{
Console.WriteLine("文件不存在,请检查路径。");
}
catch (FormatException ex) // 3. 精准捕获:格式不对
{
Console.WriteLine("文件内容不是数字。");
}
catch (Exception ex) // 4. 兜底捕获:抓漏网之鱼
{
// 注意:Exception 是所有异常的父类,必须放在最后!
Console.WriteLine($"发生了未知错误: {ex.Message}");
}
finally
{
// 5. 善后工作:不管上面发生了什么,这里一定执行
if (file != null)
{
file.Close();
}
Console.WriteLine("清理完成");
}throw关键字
throw new Exception("你好你好");
或者throw; 如果不想处理异常,只想把它往外抛的话,就写throw; 。throw 异常会把错误发生地点设定为throw 异常这一行,相当于破坏了现场。
自定义异常类:创建一个类继承自Exception,类名以Exception结尾,然后提供几个标准的构造函数。
cs
// 1. 继承 Exception
public class InsufficientFundsException : Exception
{
// 2. 无参构造
public InsufficientFundsException() { }
// 3. 带消息构造 (最常用)
public InsufficientFundsException(string message)
: base(message) { }
// 4. 带内部异常构造 (用于包裹其他异常)
public InsufficientFundsException(string message, Exception inner)
: base(message, inner) { }
}
// 使用
throw new InsufficientFundsException("余额不足,当前余额: 5元");异常处理最佳实践:
1.捕获特定异常,而不是为了省事直接捕获Exception。
2.在finally块中进行资源清理(数据库连接,文件流)。
3.异常信息记录:处理并记录 或者 记录并抛出给上层处理。不要使用空的catch块或者只是打印一个错误发生了来进行处理。
文件与流操作
文件操作:
File类:静态类,不需要new,直接调用方法。例如File.ReadAllText(path),File.WriteAllText(path,content),前者会把整个文件都读成一个巨大的string,后者会创建新文件(如果存在则覆盖,旧的文本会被删除),写入字符串。
FileInfo类:必须先new FileInfo(path)创建对象,创建对象后,这个对象就拥有了文件的所有信息,可以反复查看。
流操作:System.IO.Stream是所有流的父类(抽象类)。核心方法有Read()/Write()读写字节,Seek()调整指针位置,Flush()冲刷缓冲区。
FileStream是Stream最常用的子类,专门用于磁盘文件的字节读写。它只认识byte\[\](字节),不认识字符串。
StreamReader/StreamWriter:直接操作byte\[\]比较困难,所以我们会使用StreamReader/StreamWriter,他们会把byte自动翻译成string。
using语句与资源释放:
cs
// 经典的块状写法
using (var fs = new FileStream(...))
{
// 操作...
} // 到了这里自动调用 Dispose(),关闭文件
// 声明式写法
public void ProcessFile()
{
using var fs = new FileStream("data.bin", ...);
// 操作...
} // 方法结束时,自动 Dispose()序列化:序列化就是把内存里的对象(Object)变成字符串或字节流,更方便存到文件里,或者直接通过网络发送给别人。反序列化就是把文件里的字符串重新变回内存里的C#对象。
JSON序列化(System.Text.Json):JSON序列化更加符合现代标准,速度极快。核心方法都在JsonSerializer静态类中:
JsonSerializer.Serialize(obj):将对象转换为JSON字符串
JsonSerializer.Deserialize<T>(json):将JSON字符串转换为T类型的对象。
XML序列化(System.Text.XML):虽然XML不如JSON流行,但在旧系统集成,配置文件或者银行/政府接口中,它还是占据统治性的低位。XML的规则比JSON严格得多。
委托,事件与lambda表达式
委托(Delegate):委托就是类型安全的函数指针。定义委托必须先定义委托的类型(即定义委托对应的函数签名),然后才能把某个具体方法赋值给委托,接着就可以像调用普通方法一样调用它了。
cs
// 1. 定义委托 (规定:只能指向 "返回 void 且 接收一个 string 参数" 的方法)
public delegate void LogHandler(string message);
public class Program
{
// 一个符合签名的方法
public static void WriteToConsole(string msg)
{
Console.WriteLine($"Console: {msg}");
}
// 另一个符合签名的方法
public static void WriteToFile(string msg)
{
// 假装写文件
Console.WriteLine($"File: {msg}");
}
public static void Main()
{
// 2. 实例化 (把方法装进变量)
LogHandler handler = WriteToConsole;
// 3. 调用 (Invoke)
handler("Hello World"); // 输出: Console: Hello World
// 也可以换绑方法
handler = WriteToFile;
handler("Hello File"); // 输出: File: Hello File
}
}Action<T>和Func<T>:这两个模板是对delegate的封装,前者没有返回值,后者有返回值。Action<T>的模板参数类型就是函数的参数类型,Func<T>的模板参数类型是<参数类型,返回值类型>。
多播委托:一个委托变量可以包含多个方法,当你调用它时,它会按顺序把里面的方法全跑一遍。我们用+=添加方法(订阅),用-=移除方法(取消订阅)。如果委托有返回值,多播调用后只能拿到最后一个方法的返回值,前面的返回值被覆盖。如果链条中的一个方法报错,后面的方法就不会再执行了。
事件:事件相比委托更具封装性和安全性,它是委托的包装器。定义事件需要在委托类型前面加event关键字。事件的本质是多播。
cs
public class Button
{
// 1. 定义事件
// 这里的 Action 是委托类型,Click 是事件名
public event Action Click;
// 2. 触发事件的方法 (通常叫 OnEventName)
// 只有类自己能调用!
public void OnClick()
{
// ?.Invoke 检查是否有人订阅,如果没人订阅(null)就不执行
Click?.Invoke();
}
}
public class Program
{
static void Main()
{
Button btn = new Button();
// 3. 订阅事件 (只能用 +=)
btn.Click += () => Console.WriteLine("按钮被按下了!");
// 4. 取消订阅 (只能用 -=)
// btn.Click -= ...
// 模拟用户点击
btn.OnClick();
}
}假设我们不用event关键字,直接用public委托,那么外部代码可以调用btn.Click=null把别人订阅好的事件全部清空,也可以直接调用btn.Click(),尽管用户并没有点击按钮。
加上event关键字后,编译器会禁止外部直接赋值,外部只能调用+=或者-=订阅或取消订阅事件。并且外部不能调用btn.Click(),只有定义事件的类自己才有权触发它。
事件访问器add/remove:事件访问器就像属性get/set一样,默认情况下,编译器会自动帮你生成一个私有的委托变量来存订阅者。如果想要自己控制订阅过程的话,可以显式写出add和remove。
cs
public class CustomEventClass
{
// 私有委托,自己存
private Action _myDelegate;
// 自定义事件
public event Action MyEvent
{
add
{
Console.WriteLine("有人想订阅事件...");
// 可以在这里加锁 (lock) 保证线程安全
if (_myDelegate == null || _myDelegate.GetInvocationList().Length < 3)
{
_myDelegate += value; // 允许订阅
}
else
{
Console.WriteLine("订阅人数已满!");
}
}
remove
{
Console.WriteLine("有人取消订阅...");
_myDelegate -= value;
}
}
public void Trigger()
{
_myDelegate?.Invoke();
}
}事件运行的代码的例子:
cs
using System;
// 1. 发布者:只管"响铃"和"发通知"
public class SchoolBell
{
// 定义事件:Action 代表不带参数的动作
public event Action OnRing;
public void Ring()
{
Console.WriteLine("[发布者] 🔔 叮铃铃......");
// 触发事件:如果有订阅者(不为null),就广播
OnRing?.Invoke();
}
}
// 客户端
class Program
{
static void Main()
{
SchoolBell bell = new SchoolBell();
// 2. 订阅者:用 += 挂载逻辑
// 学生听到铃声 -> 冲向食堂
bell.OnRing += () => Console.WriteLine(" -> 学生:冲向食堂!");
// 老师听到铃声 -> 拖堂
bell.OnRing += () => Console.WriteLine(" -> 老师:再讲两分钟...");
// 3. 触发:铃声一响,上面两个动作自动执行
bell.Ring();
}
}Invoke函数:当你定义了一个委托或事件时,Invoke方法就是让委托或事件开始执行。它和函数调用符()的功能是一样的。
cs
Action<string> sayHello = name => Console.WriteLine("Hello " + name);
// 方式 1:隐式调用 (像调用普通方法一样) ------ 常用
sayHello("Tom");
// 方式 2:显式调用 (使用 Invoke) ------ 本质完全一样
sayHello.Invoke("Tom");Invoke真正的用法应该是?.Invoke(),它会执行空检查。而()在委托是null的时候会直接崩溃。
注:当我们调用事件/委托时,所有订阅函数都接受提供给事件/委托的参数。
lambda表达式:结构是 (输入参数) => { 执行逻辑/返回值 }
简化规则:
cs
// 原始完整版
(int x) => { return x * 10; }
// 1. 去掉类型 (Type Inference)
(x) => { return x * 10; }
// 2. 去掉参数括号 (只有一个参数时)
x => { return x * 10; }
// 3. 去掉花括号和 return (只有一行代码时)
x => x * 10特殊情况:
没有参数必须用空括号()
cs
() => Console.WriteLine("Hello");多个参数,必须用括号
cs
(x, y) => x + y;多行逻辑,必须用{}且手写return。
cs
x => {
int temp = x + 1;
return temp * 2;
};闭包:Lambda表达式捕获并延长外部变量生命周期的机制叫做闭包。Lambda表达式捕获的是变量本身的引用,而不是值捕获。
cs
for (int i = 0; i < 5; i++)
{
int temp = i; // 【关键】:每次循环 temp 都是一个新的变量
actions.Add(() => Console.WriteLine(temp)); // 捕获的是 temp
}
// 输出: 0, 1, 2, 3, 4ASP.NET Core Web API:在传统的应用中,服务器端既负责处理数据,又负责渲染HTML,这意味着前端UI代码和后端业务逻辑高度耦合。ASP.NET Core Web API的作用是将数据层彻底剥离出来,将前端和后端的职责划分开来。
后端仅负责执行业务逻辑,操作数据库,并序列化数据,它不关心数据如何展示。
前端(比如浏览器)负责解析JSON数据并渲染UI控件。
前端和后端可以部署在不同的服务器上,同一套API接口可以同时服务于Web端,App端,无需重复编写业务逻辑。
Web API提供了标准化的HTTP接口,它将C#方法映射为标准的HTTP操作。Web API属于后端的一部分,它是后端暴露给前端的唯一入口。
本质上讲,ASP.NET Core Web API是一个HTTP消息处理器。它监听服务器端口,接收标准的 HTTP 请求(包含 URL、Header、Body),利用路由系统找到对应的 C# 控制器方法(Action),执行逻辑后,将 C# 对象序列化为 JSON 格式,封装进 HTTP 响应中返回给调用者。
ControllerBase基类:ControllerBase是Web API控制器的基础架构提供者,它是一个抽象类。Web API的本质是处理HTTP请求,当控制器被实例化时,会自动注入一些关键属性,比如HttpContext,Request,Response等等。
动作方法:动作方法是控制器类中用于处理传入HTTP请求的执行单元,简单来说,它是C#方法和HTTP网络请求之间的映射终点。当一个具体的URL请求到达服务器时,框架最终会调用这个方法来执行逻辑并生成响应。
动作方法必须满足以下条件才能被框架识别并执行:
-
它必须是定义在 Controller 类中的
public方法。 -
它不能是
static方法。 -
它通常(但不强制)被 HTTP 动词特性 (如
[HttpGet],[HttpPost])所标记。
动作方法的返回类型:动作方法应该返回一个描述了完整HTTP响应的对象。一个HTTP响应应该包括状态码(比如200表示成功,404表示没找到,400表示BadRequest,即传递参数错误)和数据(这是给用户看的,比如查出来的User对象,List列表,或者报错的文字信息等等)。
直接返回具体类型:这种方法无法控制状态码。
IActionResult类型:可以使用OK(),NotFound(),BadRequest()等辅助方法,返回一个被包裹的C#对象。我们可以根据不同逻辑返回不同的HTTP状态码。缺点是丢失了类型信息,方法签名只写了IActionResult,我们不知道内部包裹了什么类型的对象。
ActionResult<T>类型:特点是类型安全,可以通过ActionResult<User>明确告知成功时返回的是User类。既可以成功返回T类型的数据(自动转200),也可以返回ActionResult类型的结果。
cs
[HttpGet("{id}")]
// 明确告诉外界:我要么给你 User,要么给你 HTTP 状态码
public ActionResult<User> GetById(int id)
{
var user = _db.Users.Find(id);
if (user == null)
{
return NotFound(); // 返回 404
}
// 【亮点】不需要写 Ok(user),直接返回对象
return user; // 自动转换为 200 OK + JSON
}HTTP方法特性:HTTP方法特性可以让同一个URL根据不同的HTTP动词,分发给不同的C#方法。
| 特性 (Attribute) | HTTP 动词 | 对应数据库操作 | 含义 (大白话) |
|---|---|---|---|
[HttpGet] |
GET | Read (查) | "给我看看数据" |
[HttpPost] |
POST | Create (增) | "我给你一些新数据,帮我存起来" |
[HttpPut] |
PUT | Update (改) | "把这条数据彻底换成我给你的新的" |
[HttpDelete] |
DELETE | Delete (删) | "把这条数据删掉" |
路由:负责将客户端发来的HTTP请求地址(URL),精确地映射到代码中的某一个控制器的某个一动作方法上。路由分为两种,约定路由和属性路由。
属性路由:在控制器类或动作方法上,直接用Route特性来定义URL长什么样。对于占位符controller,框架会自动把它替换为控制器名字去掉Controller后的部分。例如UsersController会变为users,最终的基础URL就是/api/users。
cs
[ApiController]
[Route("api/[controller]")] // 这里的 [controller] 是个占位符
public class UsersController : ControllerBase
{
// ...
}在动作方法上,我们结合HTTP动词特性来拼接剩余路径。最终URL=控制器路由+动作路由。
cs
// 基础路径: /api/users
[HttpGet] // URL: /api/users
public IActionResult GetAll() { ... }
[HttpGet("{id}")] // URL: /api/users/123
public IActionResult GetOne(int id) { ... }
[HttpGet("search")] // URL: /api/users/search
public IActionResult Search() { ... }约定路由:它不是写在Controller里的,而是写在Program.cs的全局配置中。它定义了一个通用的模板,试图套用所有的控制器。
cs
// 在 Program.cs 中配置
app.MapControllerRoute(
name: "default",
pattern: "{controller}/{action}/{id?}");它假设你的URL永远是 控制器名/方法名/ID 的格式,访问/Users/GetAll会自动找UsersController里的GetAll方法。
路由参数:使用花括号定义,是直接嵌在URL路径里的变量。
cs
// 定义: /api/products/{id}
[HttpGet("{id}")]
public IActionResult GetProduct(int id)
{
// 如果 URL 是 /api/products/99
// 这里的 id 就会自动变成 99
return Ok(id);
}查询参数:跟在URL的?后面,不同于路由参数,查询参数的使用不需要在路由模板中定义,只要方法参数里有同名的变量,框架会自动找。
cs
[Route("api/test")]
public class TestController : ControllerBase
{
// 1. 路由参数写法
// URL: GET /api/test/100
[HttpGet("{id}")]
public IActionResult GetByRoute(int id) { ... }
// 2. 查询参数写法 (注意模板里没有 {id})
// URL: GET /api/test?id=100
[HttpGet]
public IActionResult GetByQuery(int id) { ... }
}注:只要在特性中写了"{id}",就强制把这个参数变为了路由参数,该参数必须出现在URL的路径里。路由参数和查询参数冲突。
模型绑定与验证:核心作用是自动化地将HTTP请求中的零散数据(字符串,JSON,URL参数)转换为强类型的C#对象。
HTTP请求中的数据可能藏在URL,Body或者Header里。在写API时,为了明确与安全,我们通常使用特性来显式指定参数数据的来源。
下面是一些参数特性,一个参数特性修饰一个参数。
| 特性 | 英文含义 | 数据来源位置 | 典型场景 |
|---|---|---|---|
[FromRoute] |
From URL Path | URL 路径 (路由模板里的 {}) |
获取唯一资源的 ID (如 /users/5) |
[FromQuery] |
From Query String | URL 问号后面 (?key=val) |
筛选、分页、搜索 (如 ?page=1&search=Tom) |
[FromBody] |
From Request Body | HTTP 请求体 (JSON) | 创建 或修改复杂数据 (如提交用户注册表单) |
cs
// URL: PUT /api/users/5?version=2
// Body: { "name": "Tom", "email": "tom@abc.com" }
[HttpPut("{id}")]
public IActionResult UpdateUser(
[FromRoute] int id, // 1. 从路径拿 ID (5)
[FromQuery] int version, // 2. 从问号后面拿版本号 (2)
[FromBody] UserUpdateDto userDto // 3. 从 Body 里拿 JSON 数据
)
{
// 此时,id=5, version=2, userDto 已经被自动填好了数据
// 你直接用就行了!
}模型状态验证:ModelState.Isvalid是数据经过模型绑定和模型验证后框架生成的报告,告诉你这次接受的数据是合格还是不合格。本质上它是ControllerBase类中的一个属性,类型为布尔值。值为true时说明数据格式正确,且符合验证规则。如果值为false,要么是格式错误,要么违反规则。
自定义验证特性:本质就是,写一个类。这个类必须继承自ValidationAttribute基类,并且重写IsValid方法。
假设我们的要求是,用户注册时用户名不允许叫"admin","root","system"。
cs
using System.ComponentModel.DataAnnotations; // 必须引用这个命名空间
// 1. 继承 ValidationAttribute
public class NoAdminAttribute : ValidationAttribute
{
// 2. 重写 IsValid 方法
// value: 用户填写的那个具体的值 (比如 "admin")
// validationContext: 上下文信息 (比如整个 DTO 对象)
protected override ValidationResult IsValid(object value, ValidationContext validationContext)
{
// 先把 object 转成 string,方便处理
var strValue = value as string;
// 如果是空的,通常由 [Required] 去管,这里放行 (return Success)
if (string.IsNullOrEmpty(strValue))
{
return ValidationResult.Success;
}
// --- 核心业务逻辑 ---
var blackList = new[] { "admin", "root", "system" };
// 检查是否在黑名单里 (忽略大小写)
if (blackList.Contains(strValue.ToLower()))
{
// ❌ 验证失败!
// 返回一个新的 ValidationResult,并附上错误信息
return new ValidationResult("不允许使用该敏感词作为用户名!");
}
// ✅ 验证通过!
return ValidationResult.Success;
}
}现在NoAdmin可以直接被贴在参数上。
老师划的重点,并非真的重点:
1.面向对象三大特性:封装,继承,多态。
封装:把对象的属性和方法结合成一个独立的单位,并隐藏对象内部细节,只暴露有限的接口供外部使用。
继承:子类自动拥有父类的所有属性和方法,子类可以复用父类的代码。
多态:多态通常表现为父类引用指向子类对象。多态可以使同一操作作用于不同对象,产生不同的执行结果。
2.值类型和引用类型的区别:值类型通常存储在栈上,引用类型真实数据通常存储在堆上,栈上只存储指针。在传参时,值类型的参数会重新开辟一块内存空间来存储值,而引用类型只传递内存地址,不会开辟新的内存空间,函数内部仍然是对原本的内存进行操作。
3.接口与抽象类的区别:接口内部不能有数据,只能有方法声明,不能有方法的定义。所有方法都应该由子类实现。抽象类可以有数据,可以有完整的方法定义,抽象类内部由abstract修饰的抽象方法同样只能有声明,不能有定义。
4.异常处理机制:异常处理机制是为了在逻辑发生错误时,不要让程序直接崩溃,而是优雅地处理意外。
省略
5.多线程同步:指协调多个线程对共享资源的访问顺序机制。
省略
6.泛型的类型约束:泛型的类型约束就是虽然泛型T表示任意类型,但我现在强制要求这个任意类型必须满足某些硬性条件。语法形式是public class Myclass<T> where T : 约束条件1,约束条件2, ......
常用的约束如下:
| 约束写法 | 含义 | 作用/解锁的能力 |
|---|---|---|
where T : class |
引用类型约束 | 保证 T 必须是类、接口、数组等。 允许你把 T 赋值为 null。 |
where T : struct |
值类型约束 | 保证 T 必须是 int, float, bool 等结构体。 禁止传入 class。 |
where T : new() |
无参构造函数约束 | 保证 T 可以被 new T() 实例化。 常用于工厂模式。 |
where T : 基类名 |
基类约束 | 保证 T 必须是该类或其子类。 解锁能力:可以直接访问该基类的属性和方法! |
where T : 接口名 |
接口约束 | 保证 T 必须实现了这个接口。 解锁能力 :可以调用接口定义的方法(如 CompareTo)。 |
cs
public class MyClass<T>
{
public void DoSomething(T obj)
{
// ❌ 报错!
// 编译器:T 是什么?它有 Name 属性吗?我不敢保证,所以我报错。
Console.WriteLine(obj.Name);
// ❌ 报错!
// 编译器:T 能不能被 new 出来?万一它是个抽象类怎么办?报错。
T newObj = new T();
}
}
cs
// 定义一个接口
public interface IEntity
{
int Id { get; set; }
}
// 定义泛型仓储,加上三个约束
// 注意顺序:class/struct 先写,接口中间,new() 必须放最后!
public class Repository<T> where T : class, IEntity, new()
{
public void Add(T item)
{
// 1. 因为有 IEntity 约束,所以我可以大胆访问 .Id
Console.WriteLine($"正在添加 ID 为 {item.Id} 的数据");
}
public T CreateNew()
{
// 2. 因为有 new() 约束,所以我可以大胆 new T()
return new T();
}
}易错(我们老师说的易错)
1.String的不可变性:字符串一旦被初始化,就无法改变存储的值。当你在代码中修改一个字符串时,你以为是在修改它,但实际上原地址上存储的字符串会被抛弃,系统会创建一个新的对象,并把指针指向它。现在字符串拥有全新的地址。
这样做的好处有:线程安全,既然字符串的内容根本无法改变,那么多个线程读取同一字符串时也是安全的。(还有其他好处,但是有点复杂)
2.==和Equals的区别:对于值类型,两者表现完全一样,都比较值是否相等。对于引用类型,==默认比较的是引用的内存地址是否相等,Equals同样默认比较内存地址是否相同,但可以在类中重写Equals方法,修改为自己想要的逻辑。
注:String是特殊的引用类型。不论是==还是Equals都比较值。
3.ref和out参数:这两个参数都是按引用传递的实现。ref完全可以当作正常的引用使用,要求调用者必须已经初始化该对象。out则不要求调用者初始化该参数,即使已经初始化,进入方法后也会被清空视为未赋值。在方法内部,要求必须在方法结束之前给out参数一个值,否则编译器报错。
4.using语句的作用:在离开{}后,自动销毁使用using语句声明的变量。using语句本质上是try...finally的语法糖,所以即使发生异常,也能保证资源被释放。
5.Task和Thread的区别:Task类继承自Thread类,Thread类是底层的线程的概念,而Task是它的高层抽象。Thread是重量级的,开销大且功能单一,而Task是轻量级的,支持返回值,和异步等待等特性。