
文章目录
- Abstract
- Introduction
- [Related Work](#Related Work)
- Methods
-
- [Atrous Convolution for Dense Feature Extraction](#Atrous Convolution for Dense Feature Extraction)
- [Going Deeper with Atrous Convolution](#Going Deeper with Atrous Convolution)
-
- [Multi-grid Method](#Multi-grid Method)
- [Atrous Spatial Pyramid Pooling](#Atrous Spatial Pyramid Pooling)
- [Experimental Evaluation](#Experimental Evaluation)
- Conclusion
Abstract
在这项工作中,我们重新审视了空洞卷积这一强大的工具,它能够明确地调整滤波器的视野范围,并控制深度卷积神经网络计算出的特征响应的分辨率,主要用于语义图像分割的应用中。为了处理在多个尺度上分割物体的问题,我们设计了采用空洞卷积进行级联或并行的模块,通过采用多种空洞率来捕捉多尺度的上下文。此外,我们提议对之前提出的空洞空间金字塔池化模块进行扩展,该模块能够探测不同尺度的卷积特征,同时包含图像级别的特征以编码全局上下文,并进一步提升性能。我们还详细阐述了实现细节,并分享了我们在训练系统方面的经验。所提出的"DeepLabv3"系统在不进行密集 CRF 后处理的情况下,明显优于我们之前的 DeepLab 版本,并在 PASCAL VOC 2012 语义图像分割基准测试中达到了与其他先进模型相当的性能。
Introduction
对于语义分割任务20, 63, 14, 97, 7,我们在应用深度卷积神经网络(DCNNs)50时考虑了两个挑战。第一个挑战是连续的池化操作或卷积步幅所导致的特征分辨率降低 ,这使得 DCNNs 能够学习越来越抽象的特征表示。然而,这种对局部图像变换的不变性可能会妨碍密集预测任务,因为在这些任务中需要详细的空间信息。为了克服这个问题,我们提倡使用空洞卷积36, 26, 74, 66,它已被证明对语义图像分割10, 90, 11是有效的。空洞卷积,也称为扩张卷积,使我们能够重新利用 ImageNet 72 预训练的网络来提取更密集的特征图,方法是去除最后几层的下采样操作,并对相应的滤波器核进行上采样,相当于在滤波器权重之间插入空洞(法语中称为"trous")。通过空洞卷积,我们能够控制在 DCNN 中计算特征响应的分辨率,而无需学习额外的参数。
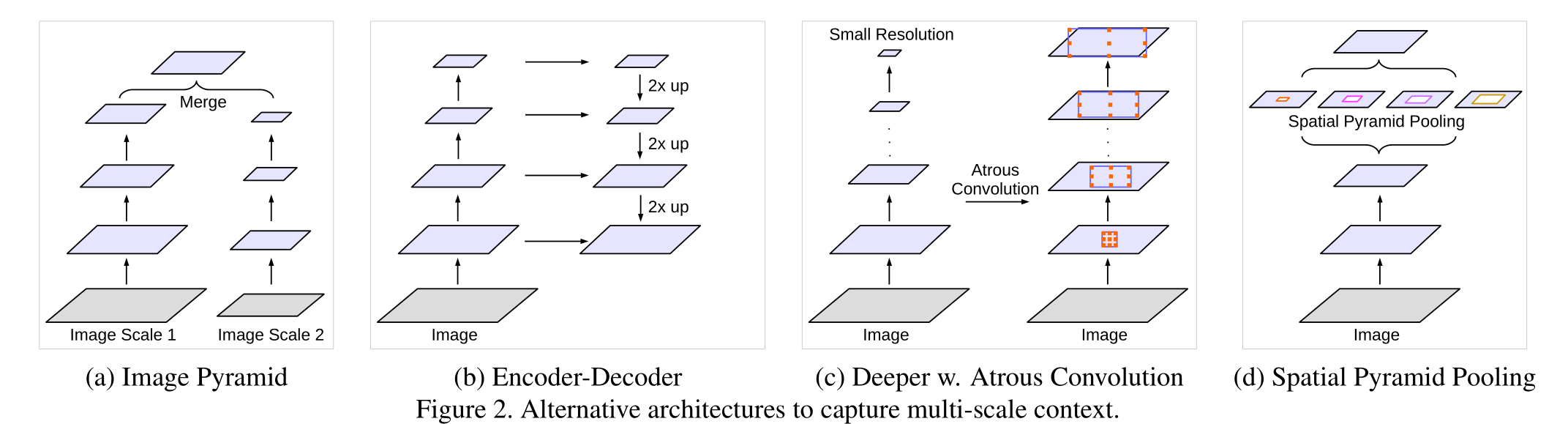
另一个难题源于存在多种尺度的物体。已有多种方法来解决这一问题,在本研究中,我们主要考虑了以下四个类别,如图 2 所示。首先,将深度卷积神经网络应用于图像金字塔,为每个尺度输入提取特征22, 19, 69, 55, 12, 11,其中不同尺度的物体在不同的特征图中变得突出。其次,编码器-解码器结构3, 71, 25, 54, 70, 68, 39利用编码器部分的多尺度特征,并从解码器部分恢复空间分辨率。第三,在原始网络之上添加额外的模块以捕捉长距离信息。特别地,DenseCRF 45用于编码像素级别的成对相似性10, 96, 55, 73,而59, 90则在级联中开发了几层额外的卷积层,以逐步捕捉长距离上下文。第四,空间金字塔池化11, 95使用滤波器或池化操作以不同速率和多个有效视场对输入特征图进行处理,从而捕获不同尺度的物体。
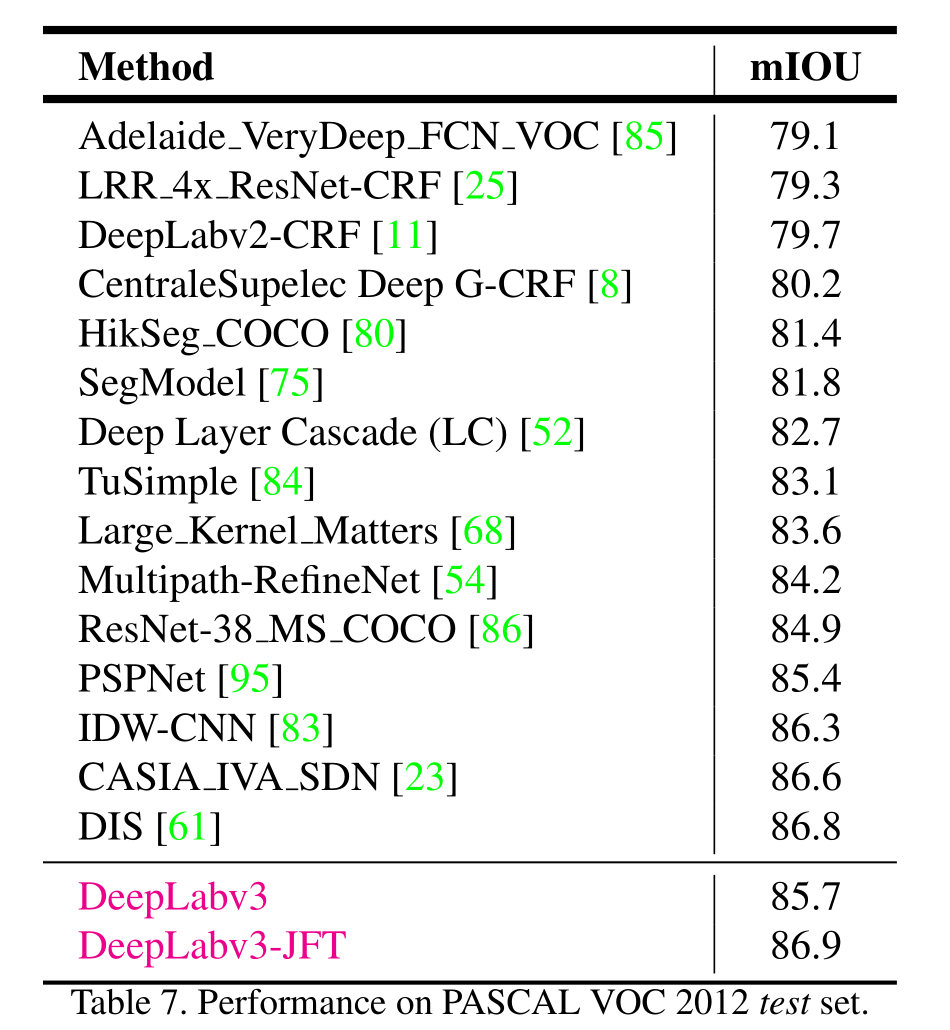
在这项工作中,我们重新探讨了使用空洞卷积的方法,这种方法使我们能够有效地扩大滤波器的视野范围,从而能够融合多尺度的上下文信息。我们将其应用于两级模块和空间金字塔池化框架中。特别地,我们提出的模块包含具有不同步长的空洞卷积以及批次归一化层,我们发现这些对于训练来说也是至关重要的。我们尝试将模块以串联或并联的方式排列(具体采用的是 Atrous 空间金字塔池化(ASPP)方法11)。我们探讨了在应用具有极高步长的 3×3 脚步卷积时的一个重要实际问题,由于图像边界效应,这种卷积方式无法捕捉到长距离信息,实际上会退化为 1×1 卷积,并提出将图像级特征纳入 ASPP 模块中。此外,我们详细阐述了实现细节,并分享了训练所提出模型的经验,包括一种简单但有效的用于处理罕见且精细标注对象的自举方法。最终,我们提出的模型"DeepLabv3"在我们的先前工作10, 11的基础上有所改进,在 PASCAL VOC 2012 测试集上达到了 85.7% 的性能,且无需进行 DenseCRF 后处理。
Related Work
已有研究表明,全局特征或上下文交互33, 76, 43, 48, 27, 89对于正确对像素进行语义分割具有积极作用。在本研究中,我们讨论了四种全卷积网络(FCN)类型74, 60(见图 2 以供说明),它们利用上下文信息进行语义分割30, 15, 62, 9, 96, 55, 65, 73, 87。
**图像金字塔:通常采用具有共享权重的相同模型来处理多尺度输入。小尺度输入的特征响应编码了长距离的上下文信息,而大尺度输入则保留了小物体的细节。**典型的例子包括法雷伯等人22,他们通过拉普拉斯金字塔对输入图像进行转换,将每个尺度的输入传递给深度卷积神经网络,并合并所有尺度的特征图。19, 69按从粗到细的顺序依次应用多尺度输入,而55, 12, 11则直接对多个尺度的输入进行缩放并融合所有尺度的特征。这类模型的主要缺点是,由于有限的 GPU 内存,它对于更大的/更深的深度卷积神经网络(例如32, 91, 86等网络)的扩展性较差,因此通常在推理阶段应用。
**编码器-解码器:该模型由两部分组成:(a)编码器,其中特征图的空间维度逐渐降低,从而使得更长距离的信息更容易在更深的编码器输出中被捕捉;(b)解码器,其中对象细节和空间维度逐渐恢复。**例如,60, 64使用反卷积92来学习低分辨率特征响应的上采样。SegNet3利用编码器的池化索引并学习额外的卷积层来填充特征响应,而U-Net71将来自编码器特征的跳过连接添加到相应的解码器激活中,以及25使用拉普拉斯金字塔重建网络。最近,RefineNet54以及70, 68, 39在多个语义分割基准测试中展示了基于编码器-解码器结构的模型的有效性。这种类型的模型也在对象检测56, 77的背景下进行了探索。
上下文模块:此模型包含一系列层级排列的额外模块,用于对长距离上下文进行编码。一种有效的方法是将密集条件随机场 45(结合了高效的高维过滤算法 2)与深度卷积神经网络 10, 11相结合。此外,96, 55, 73提议同时训练条件随机场和深度卷积神经网络组件,而59, 90则在深度卷积神经网络的信念图(信念图是最终的深度卷积神经网络特征图,其中包含与预测类别数量相等的输出通道)之上添加几个额外的卷积层,以捕获上下文信息。最近,41提出学习一种通用且稀疏的高维卷积(双边卷积),而82, 8则将高斯条件随机场与深度卷积神经网络相结合用于语义分割。
空间金字塔池化:该模型采用空间金字塔池化技术28, 49来捕捉不同范围内的上下文信息。在 ParseNet 58中,利用图像级别的特征来获取全局上下文信息。DeepLabv2 11提出了空洞空间金字塔池化(ASPP),其中具有不同步率的并行空洞卷积层能够捕捉多尺度信息。最近,Pyramid Scene Parsing Net(PSP)95在多个网格尺度上进行空间池化,并在多个语义分割基准测试中表现出卓越的性能。还有其他基于 LSTM 的方法,如 Image Scale 1 Image Scale 2 合并 Image 2x 上采样 2x 上采样 2x 上采样 图像 小分辨率 空洞卷积 图像 空间金字塔池化 35,用于聚合全局上下文53, 6, 88。空间金字塔池化还应用于对象检测31。
**在本研究中,我们主要将空洞卷积36, 26, 74, 66, 10, 90, 11作为上下文模块和空间金字塔池化工具进行深入探讨。**我们提出的框架具有通用性,可应用于任何网络。具体而言,我们在 ResNet 32 的原始最后一层块上复制多个副本,并将它们依次排列,同时还重新审视了包含多个空洞卷积的 ASPP 模块11。需要注意的是,我们直接将这些级联模块应用于特征图,而非信念图。对于所提出的模块,我们通过实验发现使用批量归一化38进行训练非常重要。为了进一步捕捉全局上下文,我们提议将 ASPP 与图像级特征相结合,类似于 58, 95 的方法。
空洞卷积:基于空洞卷积的模型在语义分割领域得到了广泛研究。例如,85针对改变空洞率以捕捉长距离信息的效果进行了实验,84在 ResNet 的最后两个块中采用了混合空洞率,而18进一步提出了学习可变形卷积,该卷积通过学习偏移来对输入特征进行采样,从而扩展了空洞卷积。为了进一步提高分割模型的准确性,83利用图像描述,40利用视频运动,44整合深度信息。此外,空洞卷积已被应用于物体检测,如66、17、37。
Methods
Atrous Convolution for Dense Feature Extraction
深度卷积神经网络(DCNNs)50以全卷积的方式应用74, 60,已被证明在语义分割任务中效果显著。然而,在这些网络的连续层中,对最大池化和步长的重复组合会显著降低最终特征图的空间分辨率,最近的 DCNNs 中通常在每个方向上会降低 32 倍47, 78, 32。反卷积层(或转置卷积)92, 60, 64, 3, 71, 68已被用于恢复空间分辨率。相反,我们主张使用"空洞卷积",这种卷积最初是为"空洞算法"方案中的无采样小波变换的高效计算而开发的36,并在 DCNN 环境中之前由26, 74, 66使用过。
考虑二维信号,对于输出信号 y 上的每个位置 i 以及滤波器 w,会对输入特征图 x 进行空洞卷积操作:
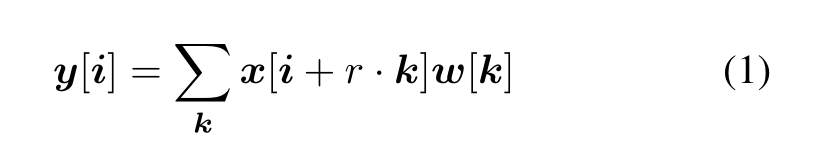
其中,步长率 r 对应于我们对输入信号采样的频率,这等同于将输入信号 x 与通过在每个空间维度上每隔 r - 1 个连续滤波器值之间插入 r - 1 个零而生成的上采样滤波器进行卷积操作(因此,这种卷积方式被称为"空洞卷积",其中法语单词 trous 在英语中意为"孔洞")。标准卷积是当步长率 r = 1 时的特殊情况,而空洞卷积允许我们通过改变步长值来自适应地调整滤波器的视野范围。请参见图 1 以获取示例说明。
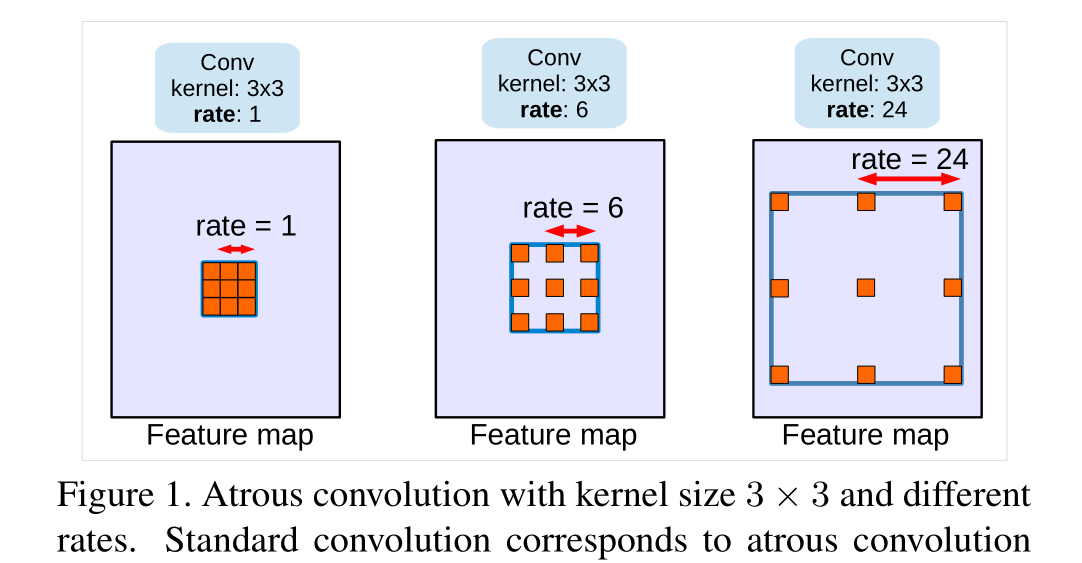
空洞卷积还使我们能够明确地控制在全卷积网络中如何密集地计算特征响应。在此,我们用"输出步幅"来表示输入图像的空间分辨率与最终输出分辨率的比率。对于用于图像分类任务的深度卷积神经网络47, 78, 32,最终的特征响应(在全连接层或全局池化之前)比输入图像尺寸小 32 倍,因此输出步幅 = 32。如果想要在深度卷积神经网络中将计算特征响应的空间密度增加一倍(即输出步幅 = 16),则降低分辨率的最后池化或卷积层的步幅应设置为 1,以避免信号衰减。然后,所有后续的卷积层都替换为具有比率 r = 2 的交错卷积层。这使我们能够在无需学习任何额外参数的情况下提取更密集的特征响应。更多细节请参阅11。
Going Deeper with Atrous Convolution
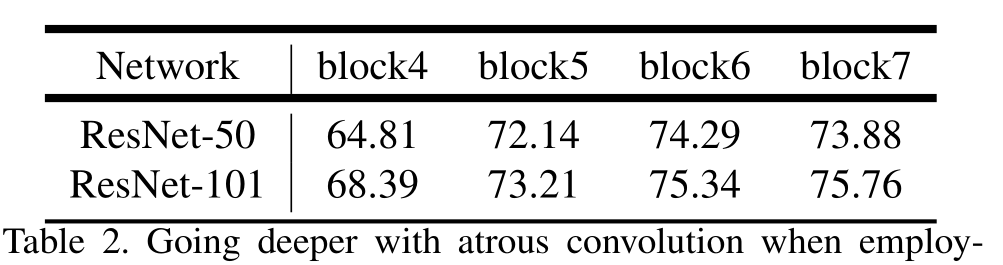
我们首先探讨采用间隔卷积(dilated convolution)并按级联方式设计模块的方法。具体来说,我们复制了最后一个 ResNet 块(在图 3 中标记为 block4),并将其按级联方式排列。这些块中包含三个 3×3 的卷积层,最后一个卷积层除了最后一个块中的那个之外,其步幅为 2,与原始 ResNet 类似。这种模型背后的动机在于引入的步幅使得在更深的块中更容易捕捉到长距离信息。例如,整个图像特征可以被总结在最后一个小分辨率特征图中,如图 3(a)所示。然而,我们发现连续的步幅对于语义分割是有害的(见第 4 节中的表 1),因为细节信息被降采样了,因此我们应用由所需输出步幅值决定的间隔卷积,如图 3(b)所示,其中输出步幅 = 16。
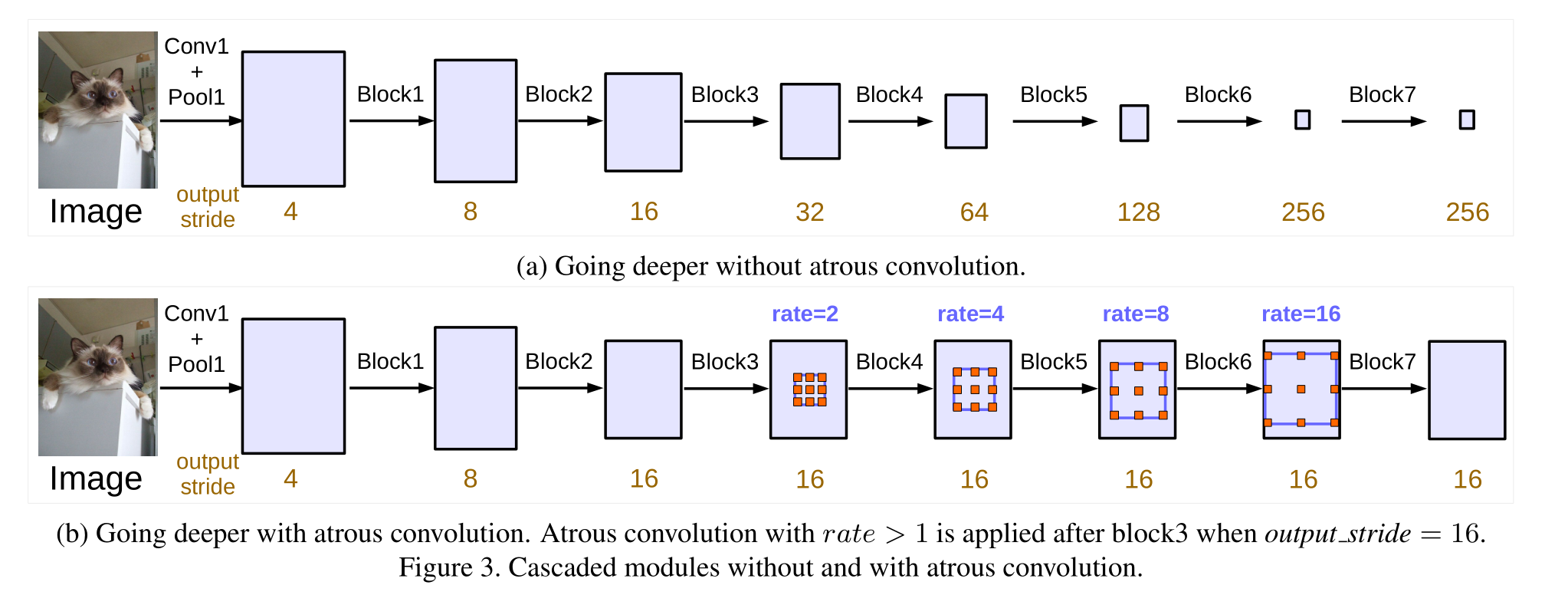
在该模型中,我们对多达第 7 个块的级联 ResNet 块进行了实验(即额外的第 5、第 6 和第 7 块作为第 4 块的复制品),若不应用空洞卷积,则其输出步长为 256 。
Multi-grid Method
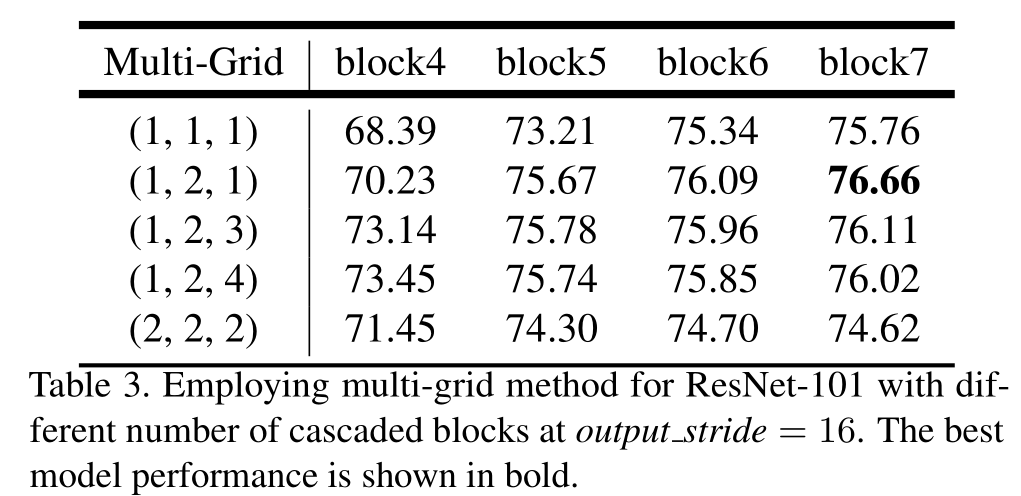
受多网格方法的启发,该方法采用了不同大小网格的层级结构4, 81, 5, 67,并遵循84, 18的相关规定,我们在所提出的模型中在块4到块7之间采用了不同的空洞率。特别地,我们定义 Multi Grid = (r1, r2, r3) 为块4到块7内三个卷积层的单位空洞率。卷积层的最终空洞率等于单位空洞率与相应空洞率的乘积。例如,当输出步长为16 且 Multi Grid = (1, 2, 4) 时,三个卷积层在块4 中的空洞率分别为 = 2 · (1, 2, 4) = (2, 4, 8) 。
Atrous Spatial Pyramid Pooling
我们再次回顾了文献11中提出的"空洞空间金字塔池化"方法,该方法在特征图之上应用了四个具有不同空洞率的并行空洞卷积。ASPP 是受到空间金字塔池化方法(28, 49, 31)成功的启发,该方法表明在不同尺度上重新采样特征对于准确且高效地对任意尺度的区域进行分类是有效的。与11不同的是,我们在 ASPP 中加入了批量归一化。
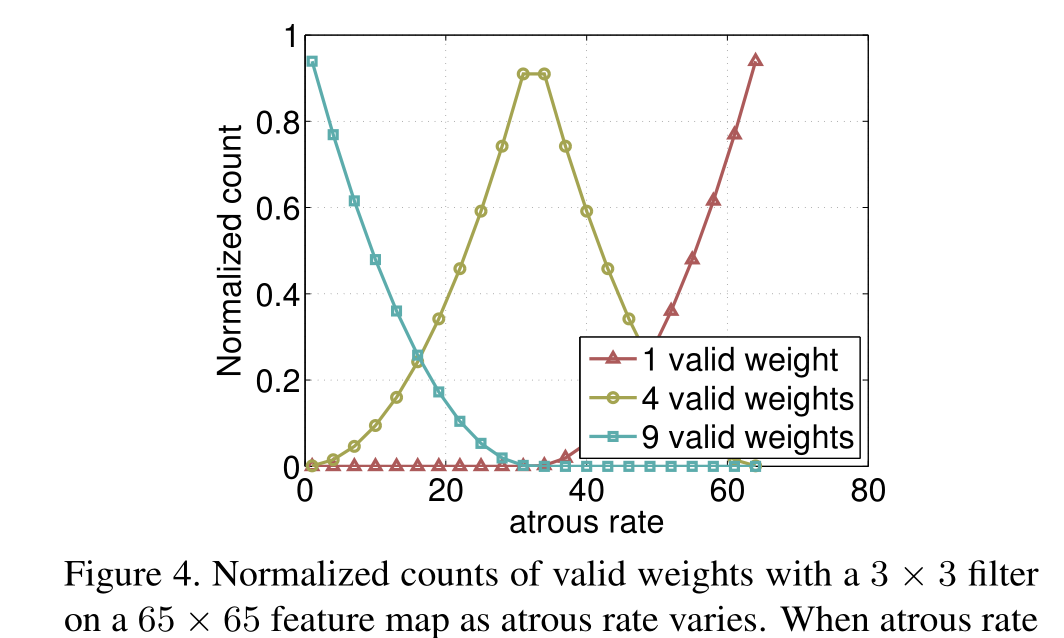
采用不同空洞率的 ASPP 能够有效地捕捉多尺度信息。然而,我们发现,随着采样率的增大,有效滤波器权重的数量(即应用于有效特征区域而非填充零值的权重)会减少 。这一现象在图 4 中得到了体现,当对一个 65×65 的特征图应用 3×3 的滤波器时,采用了不同的空洞率。在极端情况下,当空洞率值接近特征图的大小时,3×3 的滤波器不再能够捕捉整个图像上下文,而是退化为一个简单的 1×1 的滤波器,因为只有中心滤波器的权重是有效的。
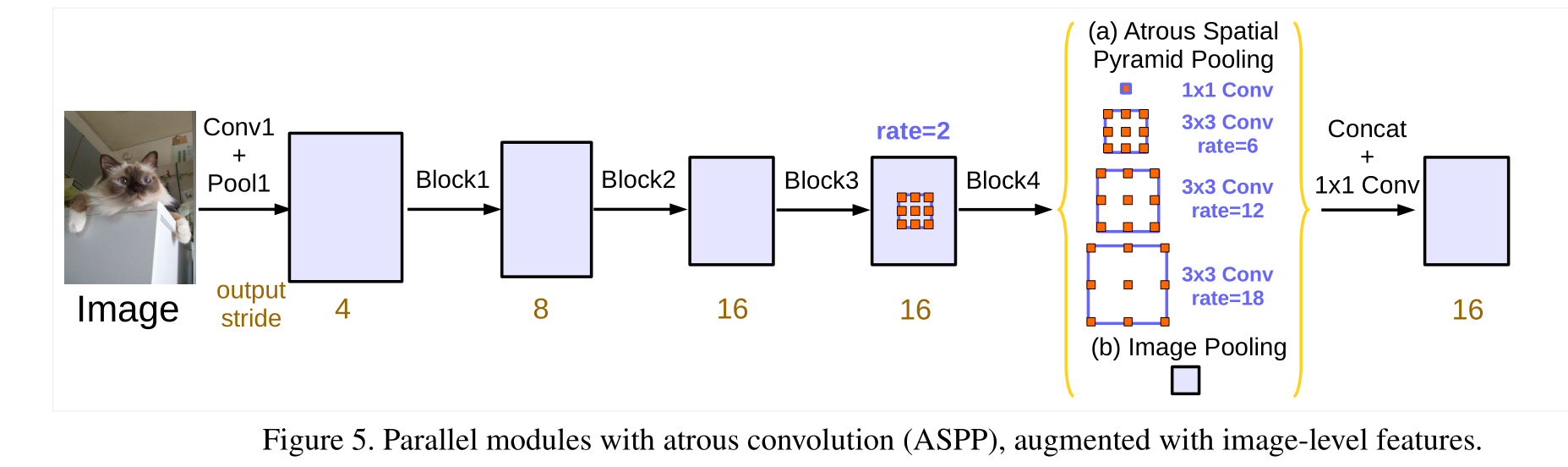
为了克服这一问题并将全局背景信息纳入模型中,我们采用了图像级别的特征,类似于58, 95。具体而言,我们在模型的最后一个特征图上应用全局平均池化,将所得的图像级别特征传递给一个具有 256 个滤波器且带有批量归一化的 1×1 卷积(以及批归一化38),然后将特征进行双线性上采样以达到所需的空间维度。最终,我们改进后的 ASPP 包括(a)一个 1×1 卷积和三个具有比率 = (6, 12, 18) 的 3×3 卷积(当输出步幅 = 16 时,所有均具有 256 个滤波器和批量归一化),以及(b)如图 5 所示的图像级别特征。请注意,当输出步幅 = 8 时,比率会翻倍。所有分支产生的特征随后被连接起来,并通过另一个 1×1 卷积(同样具有 256 个滤波器和批量归一化)传递,然后经过最终的 1×1 卷积以生成最终的逻辑值。
Experimental Evaluation
我们对 ImageNet 预训练的 72ResNet 32 进行了调整,使其适用于语义分割任务,方法是应用空洞卷积来提取密集特征。回想一下,输出步幅的定义是输入图像的空间分辨率与最终输出分辨率的比值。例如,当输出步幅为 8 时,原始 ResNet 中的最后两个模块(在我们的表示中为模块 3 和模块 4)分别包含步率分别为 2 和 4 的空洞卷积。
我们对所提出的模型在 PASCAL VOC 2012 语义分割基准测试20上进行了评估,该基准测试包含 20 种前景对象类别和 1 个背景类别。原始数据集包含 1464 张(用于训练)、1449 张(用于验证)和 1456 张(用于测试)像素级别的标注图像,分别用于训练、验证和测试。该数据集通过29提供的额外注释进行了扩充,从而产生了 10582 张(用于训练扩充)训练图像。性能通过在 21 个类别上计算的像素交并比(IOU)的平均值来衡量。

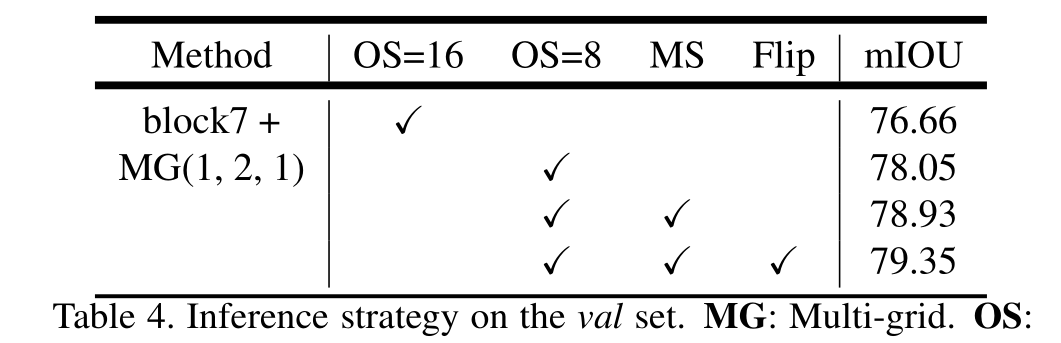
Conclusion
我们提出的模型"DeepLabv3"采用了空洞卷积和上采样滤波器来提取密集特征图,并捕捉长距离上下文信息。具体而言,为了编码多尺度信息,我们提出的级联模块逐渐将间隔率加倍,而我们提出的带有图像级特征的间隔空间金字塔池化模块则以多种采样率和有效的视野范围使用滤波器来探索特征。我们的实验结果表明,所提出的模型明显优于之前的 DeepLab 版本,并在 PASCAL VOC 2012 语义图像分割基准测试中达到了与其他最先进模型相当的性能。