实验过程:
首先,拍快照
1、进入opt目录
cd /opt
2、上传 flink 的 tgz 包到服务器
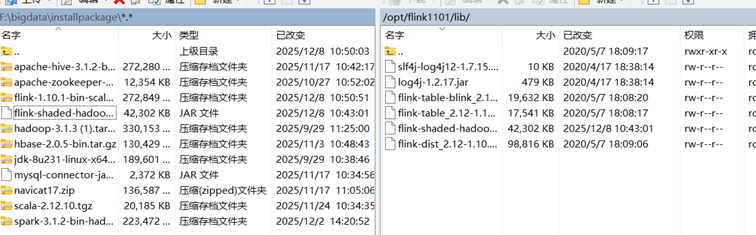
3.解压到当前路径
tar -zxf flink-1.10.1-bin-scala_2.12.tgz
4.改名字
mv flink-1.10.1 flink1101

5.将 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar 放置到 lib 目录下
6.启动 flink
进入到 flink 的 bin 目录
./start-cluster.sh

7.jps 测试 ==> 如果出现 StandaloneSessionClusterEntrypoint 说明成功
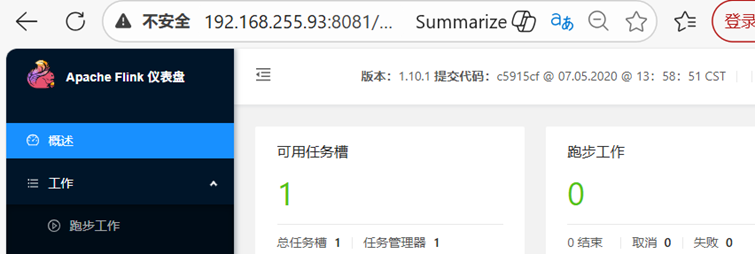
8.测试访问:http:// 服务器 ip 地址:8081
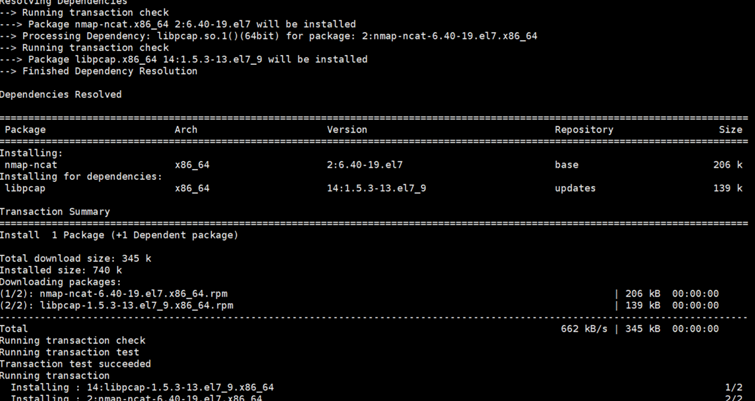
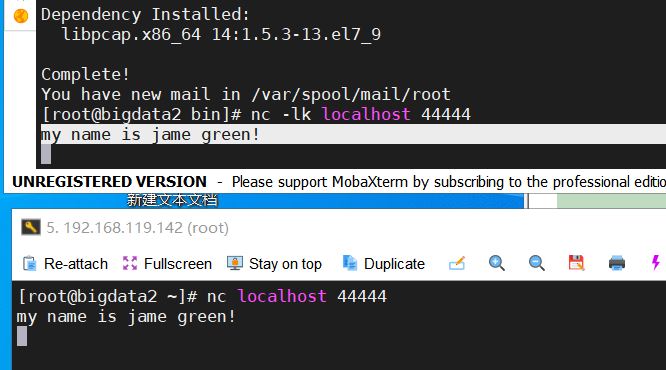
9.安装 nc 工具yum install -y nc

11.重新开一个终端(复制会话)
nc localhost 4444
12. 测试:
在新会话中输入一串内容,原会话中也会出现。
实验结束。