minio分片上传
前言
为什么要选择将一个大文件拆分成许多小文件来上传?
- 对于许多服务器和应用框架来说,单次HTTP请求的大小有严格的限制。
- 上传一个10GB的大文件可能需要数个小时,单一的http请求连接不稳定,造成上传失败。
- 降低服务器的压力
- 其次分片上传可以实现断点续传、秒上传等功能
分片上传的技术选择
分片上传分为两种,一种是经过后端服务器来上传,另外一种是前端直传。
- 第一种是由后端接受分片文件流,在调用minio的api上传
- 第二种就是有后端生成预签名url返回给前端,前端上传到minio。
一般我们选择后者,第二种利用客户端宽带,减轻了服务器的压力
实现分片上传
流程图
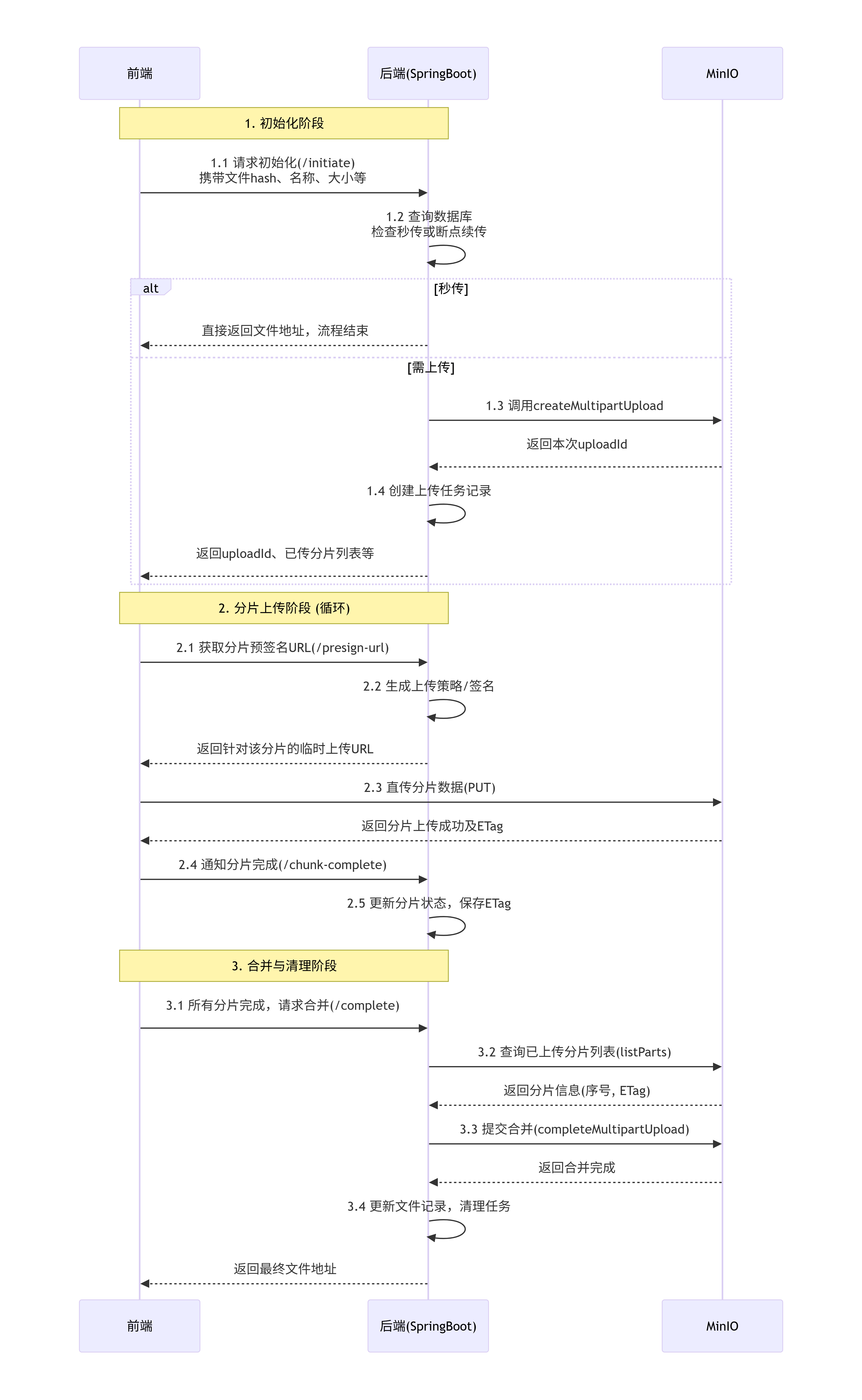
第一步自定义客户端
java
package com.petlife.base.config;
import com.google.common.collect.Multimap;
import io.minio.CreateMultipartUploadResponse;
import io.minio.ListPartsResponse;
import io.minio.MinioClient;
import io.minio.ObjectWriteResponse;
import io.minio.errors.*;
import io.minio.messages.Part;
import java.io.IOException;
import java.security.InvalidKeyException;
import java.security.NoSuchAlgorithmException;
public class BigFileClient extends MinioClient{
public BigFileClient(MinioClient client) {
super(client);
}
/**
* 创建分片上传任务 - 在MinIO服务器上初始化一个分片上传会话
* 获取uploadId - 返回一个唯一的uploadId,用于标识这次分片上传会话
* @param bucket 存储桶名称
* @param region 区域 (null 表示默认区域)
* @param object 对象名称 (文件路径)
* @param headers 额外的请求头
* @param extraQueryParams 额外的查询参数
* @return 上传ID
*/
public String initMultiPartUpload(String bucket, String region, String object, Multimap<String, String> headers, Multimap<String, String> extraQueryParams) {
try {
CreateMultipartUploadResponse response = this.createMultipartUpload(bucket, region, object, headers, extraQueryParams);
return response.result().uploadId();
} catch (IOException | InvalidKeyException | NoSuchAlgorithmException | InsufficientDataException |
ServerException | InternalException | XmlParserException | InvalidResponseException |
ErrorResponseException e) {
throw new RuntimeException("初始化分片上传失败", e);
}
}
/**
* 合并分片上传 - 将之前初始化的分片上传任务合并为一个完整的对象
* @param bucketName 存储桶名称
* @param region 区域 (null 表示默认区域)
* @param objectName 对象名称 (文件路径)
* @param uploadId 上传ID (由initMultiPartUpload返回)
* @param parts 分片信息数组
* @param extraHeaders 额外的请求头
* @param extraQueryParams 额外的查询参数
* @return 合并后的对象写入响应
*/
public ObjectWriteResponse mergeMultipartUpload(String bucketName, String region, String objectName, String uploadId, Part[] parts, Multimap<String, String> extraHeaders, Multimap<String, String> extraQueryParams) {
try {
return this.completeMultipartUpload(bucketName, region, objectName, uploadId, parts, extraHeaders, extraQueryParams);
} catch (IOException | InvalidKeyException | NoSuchAlgorithmException | InsufficientDataException |
ServerException | InternalException | XmlParserException | InvalidResponseException |
ErrorResponseException e) {
throw new RuntimeException("合并分片上传失败", e);
}
}
/**
* 列出分片上传 - 获取已上传的分片信息
* @param bucketName 存储桶名称
* @param region 区域 (null 表示默认区域)
* @param objectName 对象名称 (文件路径)
* @param maxParts 最大返回分片数量 (null 表示默认值)
* @param partNumberMarker 分片编号标记 (null 表示从第一个分片开始)
* @param uploadId 上传ID (由initMultiPartUpload返回)
* @param extraHeaders 额外的请求头
* @param extraQueryParams 额外的查询参数
* @return ListPartsResponse 包含的重要信息是:List<Part> 分片信息列表 可以通过part.partNumber()获取分片编号,part.size()获取分片大小,part.etag()获取分片的ETag
* 可以通过listPartsResponse.parts()获取分片信息列表
*/
public ListPartsResponse listMultipart(String bucketName, String region, String objectName, Integer maxParts, Integer partNumberMarker, String uploadId, Multimap<String, String> extraHeaders, Multimap<String, String> extraQueryParams) {
try {
return this.listParts(bucketName, region, objectName, maxParts, partNumberMarker, uploadId, extraHeaders, extraQueryParams);
} catch (IOException | InvalidKeyException | NoSuchAlgorithmException | InsufficientDataException |
ServerException | InternalException | XmlParserException | InvalidResponseException |
ErrorResponseException e) {
throw new RuntimeException("列出分片上传失败", e);
}
}
/**
* 简化版初始化分片上传
* @param bucketName 存储桶名称
* @param objectName 对象名称
* @return 上传ID
*/
public String initMultiPartUpload(String bucketName, String objectName) {
return initMultiPartUpload(bucketName, null, objectName, null, null);
}
/**
* 简化版合并分片上传
* @param bucketName 存储桶名称
* @param objectName 对象名称
* @param uploadId 上传ID
* @param parts 分片数组
* @return 合并结果
*/
public ObjectWriteResponse mergeMultipartUpload(String bucketName, String objectName,
String uploadId, Part[] parts) {
return mergeMultipartUpload(bucketName, null, objectName, uploadId, parts, null, null);
}
public boolean cancelMultiPartUpload(String bucketName, String objectName, String uploadId) {
try {
this.abortMultipartUpload(bucketName, null, objectName, uploadId, null, null);
return true;
} catch (Exception e) {
return false;
}
}
}初始化分片上传
对于分片上传任务的数据库设计,当前的版本比较粗糙。主要是对于已上传文件和分片任务的记录。
sql
create table if not exists `pet-life`.upload_task
(
id int auto_increment comment '主键id'
primary key,
chunk_index int null comment '分片索引',
chunk_etag int null comment '分片标签',
status int default 0 not null comment '上传状态(1:已经上传 0 : 未上传)',
src varchar(50) null comment '上传路径',
expired_time datetime null comment '过期时间'
)
comment '文件上传任务';
create table if not exists `pet-life`.file_record
(
id bigint auto_increment
primary key,
file_name varchar(100) null comment '文件名',
file_hash varchar(50) null comment '文件唯一标识',
src varchar(50) null comment '文件在minio中的存储路径',
file_size int null comment '文件大小',
is_merged tinyint null comment '是否合并 0 否 1 是',
upload_id varchar(30) null comment '上传id',
expired_time datetime null comment '过期时间'
)
comment '文件上传记录';获取一个上传分片的url共前端使用
java
/**
* 获取分一个分片的上传的url
* @param uploadId 上传ID
* @param chunkIndex 分片索引
* @return 上传URL
*/
private String generateUploadFileURL(String uploadId, int chunkIndex) {
try{
Map<String,String> extraQueryParams = new HashMap<>();
extraQueryParams.put("uploadId",uploadId);
extraQueryParams.put("partNumber",String.valueOf(chunkIndex + 1));
return minioClient.getPresignedObjectUrl(
GetPresignedObjectUrlArgs.builder()
.method(Method.PUT)
.bucket(bucketName)
.object(uploadId + "/" + chunkIndex)
.extraQueryParams(extraQueryParams)
.expiry(1, TimeUnit.DAYS)
.build()
);
}catch (Exception e){
throw new RuntimeException("生成上传URL失败:" + e.getMessage());
}
}初始化分上传任务逻辑:
要考虑该文件是否已经上传过了和断点续传的情况。
- 根据文件唯一标识通过数据库查询,如果已经上传过了,则直接返回访问路径
- 如果是断电续传的情况则返回完成上传的分片
- 如果从未上传过,则直接创建一个新的分片上传任务。
java
public ResponseDTO<UploadDTO> upload(FileForm fileForm) {
// 1. 校验文件是否已上传
String fileHash = fileForm.getFileHash();
UploadDTO result = new UploadDTO();
FileRecord fileRecord = fileRecordService.getBaseMapper().selectOne(new LambdaQueryWrapper<FileRecord>().eq(FileRecord::getFileHash,fileHash).ge(FileRecord::getExpiredTime,LocalDateTime.now()));
//1.1 文件记录不存在,开启新的分片上传任务
if(fileRecord == null){
// 1.1.1 文件记录不存在,开启新的分片上传任务
Map<String,Object> result1 = initChunkUpload02(fileForm.getFileName(), fileForm.getChunkCount());
String uploadId = (String) result1.get("uploadId");
List<UploadDTO.chunkInfo> chunkList = (List<UploadDTO.chunkInfo>) result1.get("chunkList");
// 1.1.2 创建上传任务记录
synchronized (fileHash){
CompletableFuture.runAsync(() -> {
for(UploadDTO.chunkInfo chunkInfo : chunkList){
UploadTask uploadTask = new UploadTask()
.setChunkIndex(chunkInfo.getChunkIndex())
.setSrc(chunkInfo.getSrc())
.setUploadId(uploadId)
.setStatus(0)
.setExpiredTime(LocalDateTime.now().plusDays(1));
uploadTaskService.getBaseMapper().insert(uploadTask);
}
}, threadPoolTaskExecutor);
// 1.1.3 保存文件记录
fileRecord = new FileRecord()
.setFileHash(fileHash)
.setFileName(fileForm.getFileName())
.setFileSize(fileForm.getFileSize())
.setSrc(null)
.setIsMerged(0)
.setUploadId(uploadId)
.setExpiredTime(LocalDateTime.now().plusDays(1));
fileRecordService.getBaseMapper().insert(fileRecord);
}
//1.1.3 保存分片上传人物
result.setUploadId(uploadId)
.setExist( false)
.setChunkList(chunkList)
.setObjectName(fileRecord.getFileName());
return ResponseDTO.success(result);
}
if(fileRecord.getIsMerged() == 1){
// 1.1文件已上传,返回已上传的URL
result.setExist(true);
result.setSrc(fileRecord.getSrc());
return ResponseDTO.success(result);
}
//1.2 文件未上传 判断是否是断点上传
List<UploadTask> uploadTasks = uploadTaskService.getBaseMapper().selectList(new LambdaQueryWrapper<UploadTask>().eq(UploadTask::getUploadId, fileRecord.getUploadId()).eq(UploadTask::getStatus, 0));
if(!uploadTasks.isEmpty()){
List<UploadDTO.chunkInfo> chunkList = new ArrayList<>();
for(UploadTask uploadTask : uploadTasks){
UploadDTO.chunkInfo chunkInfo = new UploadDTO.chunkInfo();
chunkInfo.setChunkIndex(uploadTask.getChunkIndex());
chunkInfo.setSrc(uploadTask.getSrc());
chunkList.add(chunkInfo);
}
result.setExist(true);
result.setChunkList(chunkList);
return ResponseDTO.success(result);
}
// 1.2.2 不是断点上传,返回空列表
result.setExist(false);
return ResponseDTO.fail("服务器数据库异常");
}确认每一个分片的上传
每一个分片完成上传,前端向后端发送一个请求,确认分片上传的状态。
java
public ResponseDTO<Boolean> confirmChunkUpload(ConfirmChunkForm confirmChunkForm) {
UploadTask uploadTask = new UploadTask();
uploadTask.setUploadId(confirmChunkForm.getUploadId());
uploadTask.setChunkEtag(confirmChunkForm.getChunkEtag());
uploadTask.setChunkIndex(confirmChunkForm.getChunkIndex());
if(confirmChunkForm.getSuccess()){
uploadTask.setStatus(1);
}else{
uploadTask.setStatus(2);
}
int update = uploadTaskService.getBaseMapper().update(uploadTask, new LambdaUpdateWrapper<UploadTask>().eq(UploadTask::getUploadId, confirmChunkForm.getUploadId()).eq(UploadTask::getChunkIndex, confirmChunkForm.getChunkIndex()));
return ResponseDTO.success(update > 0);
}合并分片文件
可以加上对分片任务的校验和数据库的更改,这里就不加了。
java
public ResponseDTO<String> mergeChunk(String uploadID, String objectName) {
try {
Part[] parts = bigFileClient.listMultipart(bucketName, null, objectName, null, null, uploadID, null, null)
.result().partList().toArray(new Part[0]);
ObjectWriteResponse objectWriteResponse = bigFileClient.mergeMultipartUpload(bucketName, objectName, uploadID, parts);
// 构建访问URL
String finalObjectName = objectWriteResponse.object();
String src = endpoint + "/" + bucketName + "/" + finalObjectName;
return ResponseDTO.success(src);
} catch (Exception e) {
throw new RuntimeException("合并分片失败:" + e.getMessage());
}
}